TL;DR
- 场景:电商核心交易三张表做每日增量,落地离线数仓 ODS,按 dt 分区。
- 结论:DataX 用 MySQLReader + HDFSWriter,按时间字段抽取,HDFS 目录分区化,Hive 只做分区挂载。
- 产出:3 份可复用 JSON 任务 + 一套执行顺序 + 常见坑位速查卡。
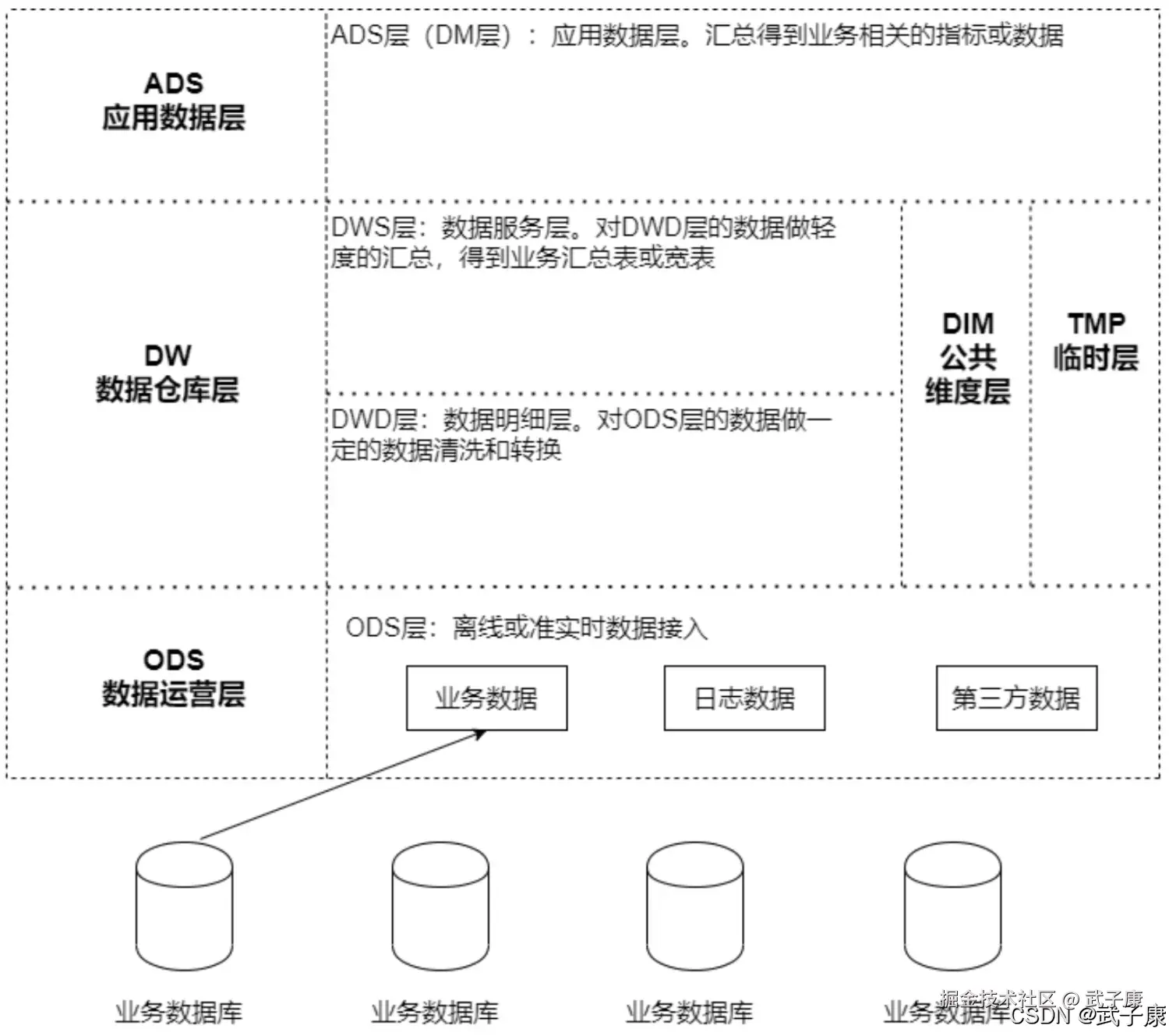
业务需求
电商系统业务中最关键的业务,电商的运营活动都是围绕这个主题展开。 选取的指标包括:订单数、商品数、支付金额,对这些指标按销售区域、商品类型分析。
在大数据的分析中,"电商核心交易"是指电商平台上所有与商品交易相关的核心行为和交易数据的集合。具体来说,核心交易涵盖了商品的浏览、加购物车、下单、支付、发货、收货等一系列行为,它们直接影响电商平台的运营效率、用户体验和商业价值。
需求板块
电商平台的核心交易可以分为以下几个主要环节,每个环节都涉及大量数据的收集、存储和分析:
- 商品浏览:用户浏览商品的行为数据,例如用户查看了哪些商品、查看时长、是否点击了相关广告或推荐商品等。这些数据能够帮助平台了解用户的兴趣点,进而优化商品推荐和个性化营销策略。
- 加入购物车:用户将商品添加到购物车中的行为。通过分析购物车中的商品,可以获取用户的购买意图和倾向,帮助商家调整商品定价、库存和促销策略。
- 下单:用户在电商平台上完成的订单生成行为。包括订单的创建、订单内容、用户的收货地址、选择的支付方式等数据。订单数据是电商交易中的核心,通常涉及大量的数据信息,要求系统能够高效地处理和存储。
- 支付:支付是交易中至关重要的环节,支付数据可以通过支付方式、支付成功与否、支付金额、支付时间等维度进行分析。这部分数据可以帮助平台评估不同支付方式的受欢迎程度,并进行相应的优化。
- 发货:商品发货数据记录了商家发货的时间、物流公司、物流单号等信息。通过对发货数据的分析,可以判断出物流时效、发货效率等关键指标,进一步优化供应链和物流流程。
- 收货和评价:用户收到商品后的评价、退换货行为等。评价数据不仅反映了商品的质量和用户满意度,还对后续的购买决策产生影响。此外,退换货数据也能够反映出商品质量问题和物流中的痛点。
增量数据导入
三张增量表:
- 订单表 wzk_trade_orders
- 订单产品表 wzk_order_produce
- 产品信息表 wzk_product_info
初始数据装载(执行一次),可以将前面的全量加载作为初次装载,每日加载增量数据(每日数据形成分区)
订单表
wzk_trade_orders => ods.ods_trade_orders 创建JSON文件:
json
vim /opt/wzk/datax/orders.json写入的内容如下所示:
json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "hive",
"password": "hive@wzk.icu",
"connection": [
{
"querySql": [
"select orderId, orderNo, userId, status, productMoney, totalMoney, payMethod, isPay, areaId, tradeSrc, tradeType, isRefund, dataFlag, createTime, payTime, modifiedTime from wzk_trade_orders where date_format(modifiedTime, '%Y-%m-%d')='$do_date'"
],
"jdbcUrl": [
"jdbc:mysql://h122.wzk.icu:3306/ebiz"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://h121.wzk.icu:9000",
"fileType": "text",
"path": "/user/data/trade.db/orders/dt=$do_date",
"fileName": "orders_$do_date",
"column": [
{
"name": "orderId",
"type": "INT"
},
{
"name": "orderNo",
"type": "STRING"
},
{
"name": "userId",
"type": "BIGINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "productMoney",
"type": "Float"
},
{
"name": "totalMoney",
"type": "Float"
},
{
"name": "payMethod",
"type": "TINYINT"
},
{
"name": "isPay",
"type": "TINYINT"
},
{
"name": "areaId",
"type": "INT"
},
{
"name": "tradeSrc",
"type": "TINYINT"
},
{
"name": "tradeType",
"type": "INT"
},
{
"name": "isRefund",
"type": "TINYINT"
},
{
"name": "dataFlag",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "payTime",
"type": "STRING"
},
{
"name": "modifiedTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
]
}
}写入的内容如下所示:  执行的过程如下所示:
执行的过程如下所示:
shell
do_date='2020-07-12'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/orders/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /opt/wzk/datax/orders.json
# 加载数据
# 目前Hive没有表 后续再执行
hive -e "alter table ods.ods_trade_orders add partition(dt='$do_date')"执行结果如下,MySQL数据加载到HDFS中: 
订单明细表
wzk_order_product => ods.ods_trade_order_product 新建JSON文件:
shell
vim /opt/wzk/datax/order_product.json写入的内容如下所示:
json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "hive",
"password": "hive@wzk.icu",
"connection": [
{
"querySql": [
"select id, orderId, productId, productNum, productPrice, money, extra, createTime from wzk_order_product where date_format(createTime, '%Y-%m-%d') = '$do_date'"
],
"jdbcUrl": [
"jdbc:mysql://h122.wzk.icu:3306/ebiz"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://h121.wzk.icu:9000",
"fileType": "text",
"path": "/user/data/trade.db/order_product/dt=$do_date",
"fileName": "order_product_$do_date.dat",
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "orderId",
"type": "INT"
},
{
"name": "productId",
"type": "INT"
},
{
"name": "productNum",
"type": "INT"
},
{
"name": "productPrice",
"type": "Float"
},
{
"name": "money",
"type": "Float"
},
{
"name": "extra",
"type": "STRING"
},
{
"name": "createTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
]
}
}对应的结果如下图所示: 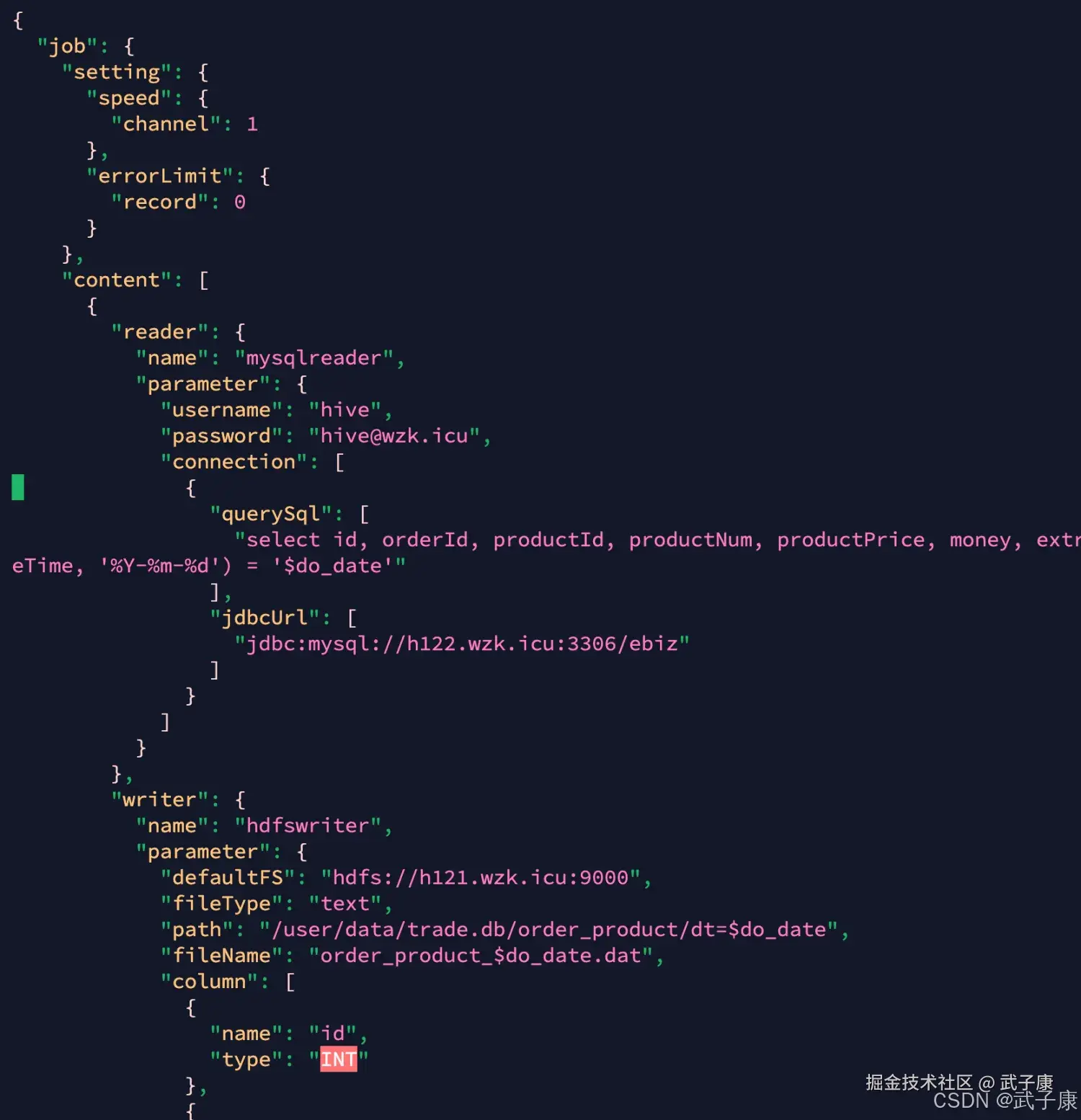 导入数据,按照如下的顺序:
导入数据,按照如下的顺序:
shell
do_date='2020-07-12'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/order_product/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /opt/wzk/datax/order_product.json
# 加载数据
# Hive后续再加载 现在还没有这些表
hive -e "alter table ods.ods_trade_order_product add
partition(dt='$do_date')"执行结果如下图: 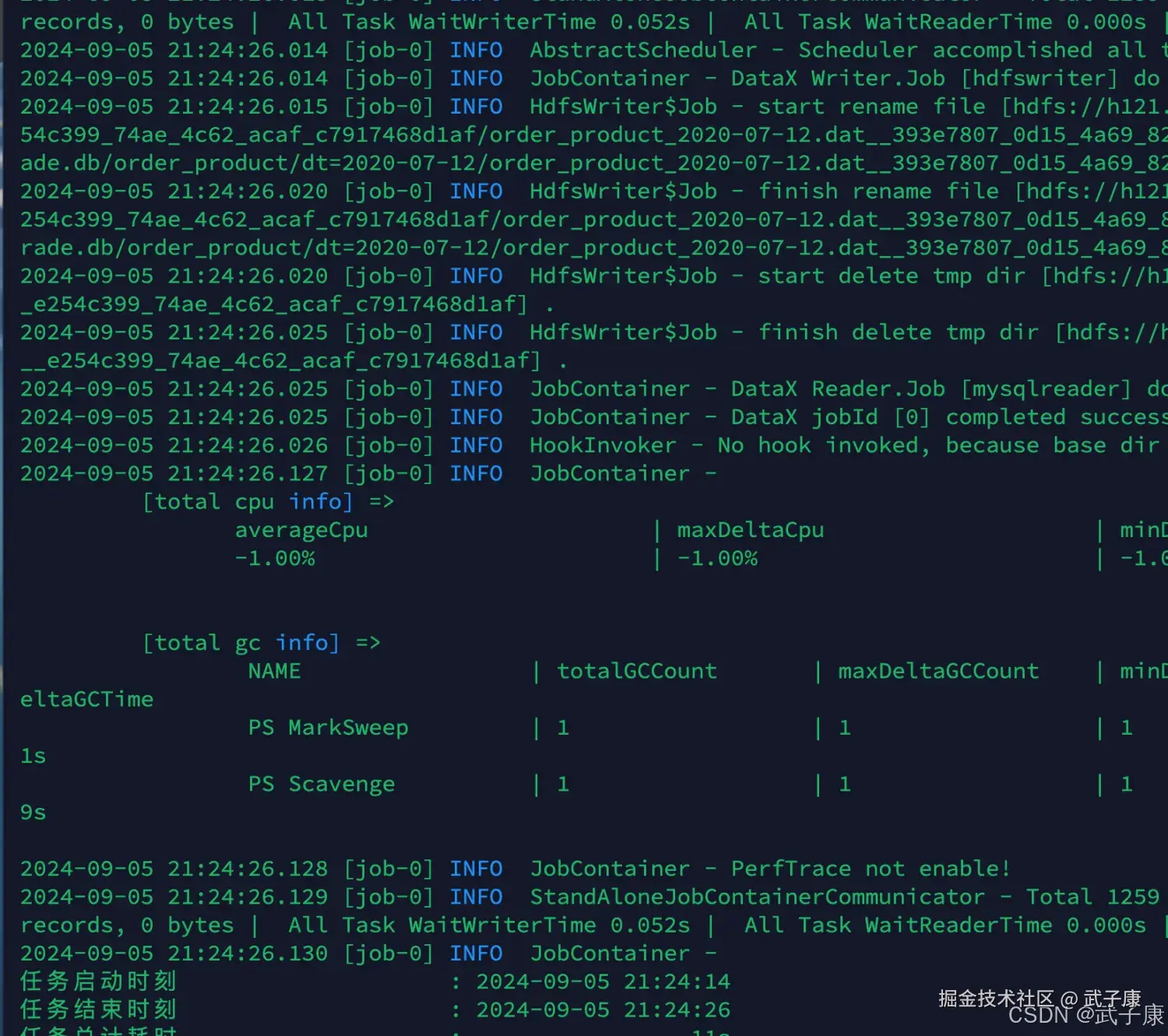
产品明细表
wzk_product_info => ods.ods_trade_product_info 新建JSON文件:
json
vim /opt/wzk/datax/product_info.json写入内容如下所示:
json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "hive",
"password": "hive@wzk.icu",
"connection": [
{
"querySql": [
"select productid, productname, shopid, price, issale, status, categoryid, createtime, modifytime from wzk_product_info where date_format(modifyTime, '%Y-%m-%d') = '$do_date'"
],
"jdbcUrl": [
"jdbc:mysql://h122.wzk.icu:3306/ebiz"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://h121.wzk.icu:9000",
"fileType": "text",
"path": "/user/data/trade.db/product_info/dt=$do_date",
"fileName": "product_info_$do_date.dat",
"column": [
{
"name": "productid",
"type": "BIGINT"
},
{
"name": "productname",
"type": "STRING"
},
{
"name": "shopid",
"type": "STRING"
},
{
"name": "price",
"type": "FLOAT"
},
{
"name": "issale",
"type": "TINYINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "categoryid",
"type": "STRING"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "modifytime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
]
}
}写入内容如下图所示: 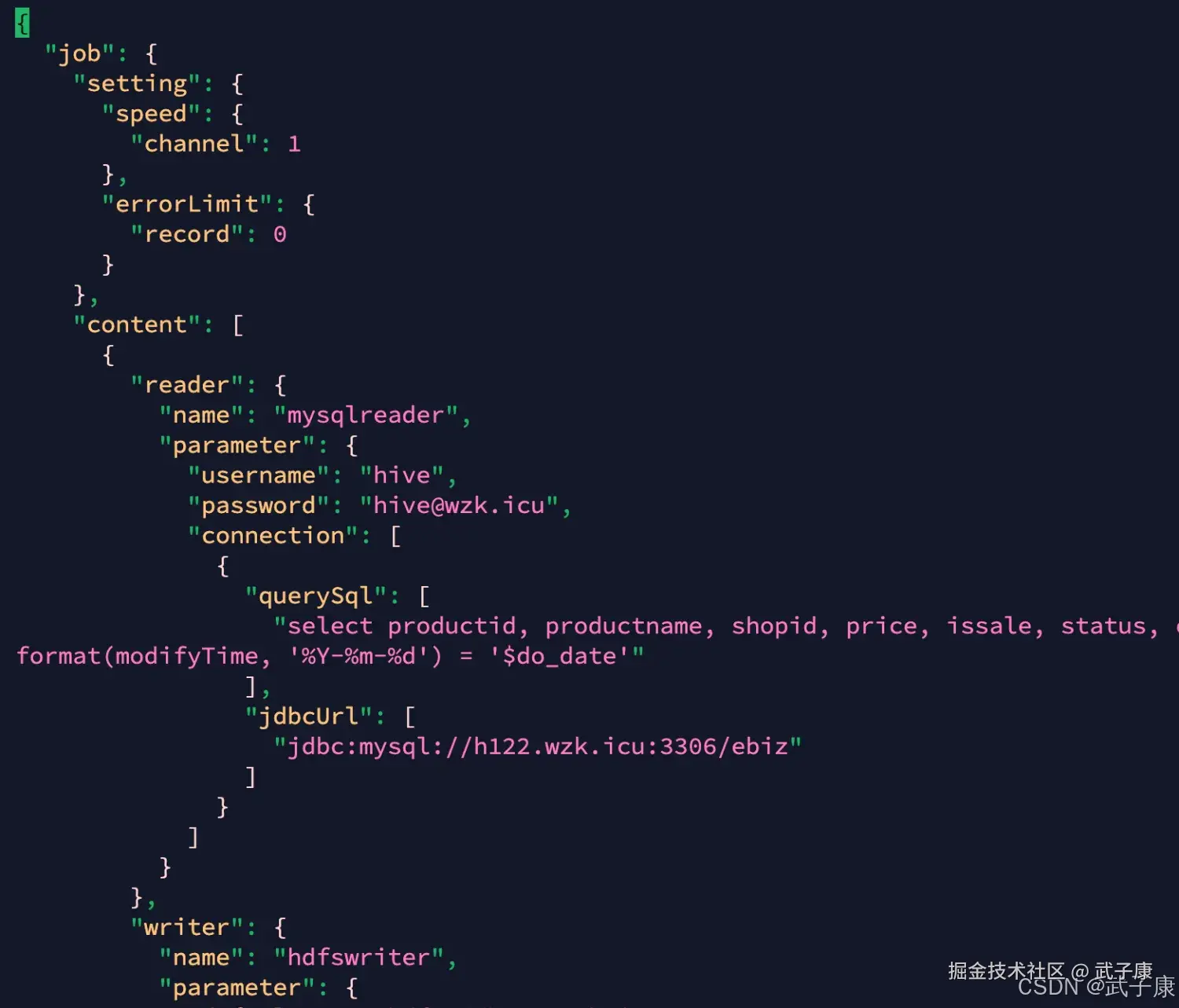 对数据进行导入,导入的过程如下:
对数据进行导入,导入的过程如下:
json
do_date='2020-07-12'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/product_info/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /opt/wzk/datax/product_info.json
# 加载数据
# hive表没有 后续再执行
hive -e "alter table ods.ods_trade_product_info add
partition(dt='$do_date')"执行结果如下图所示,MySQL数据加载到HDFS中: 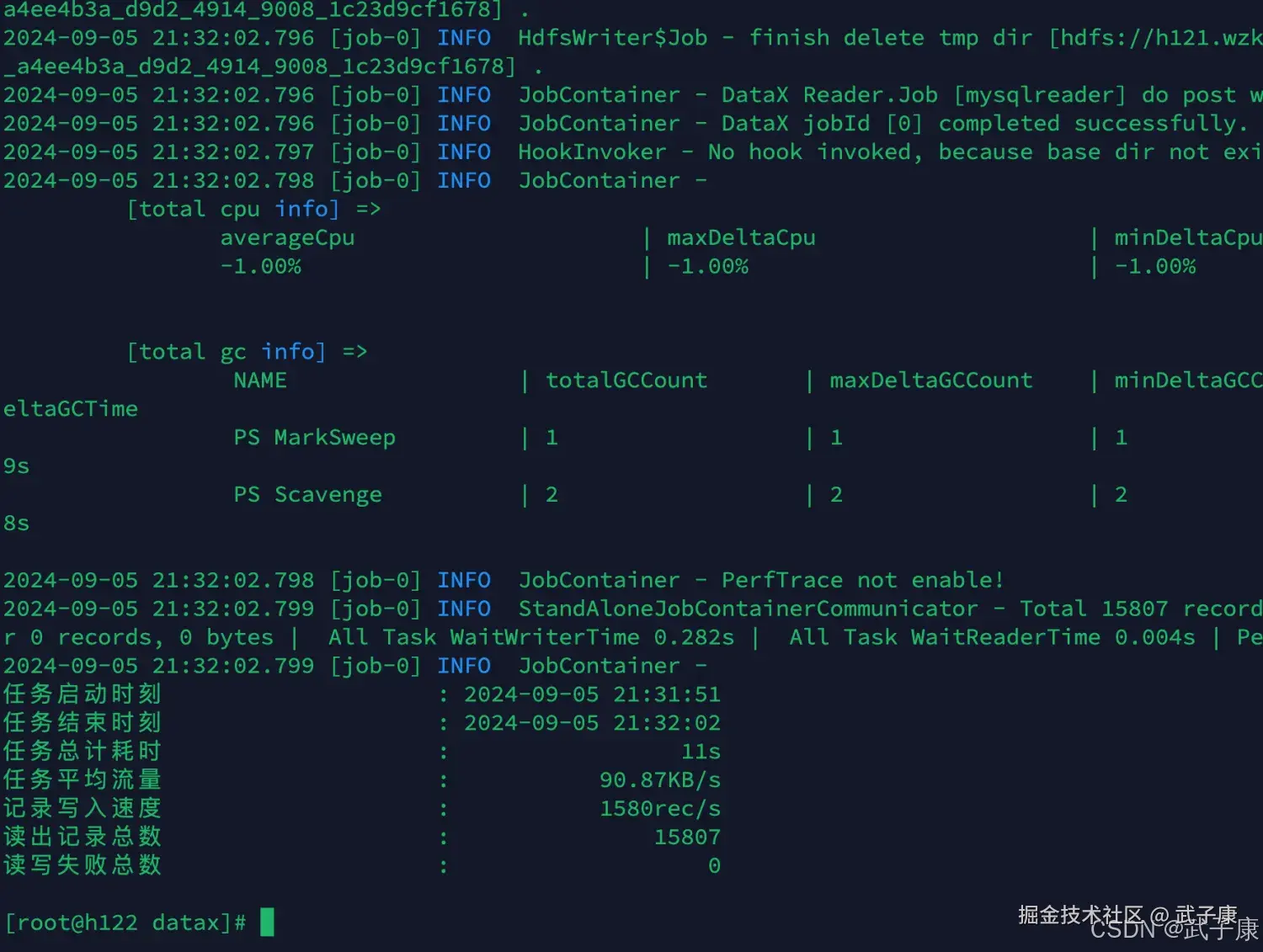
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| DataX 读取 0 条,任务成功但没数据 | 增量条件用错时间字段或当天无变更;modifiedTime/createTime 与业务更新口径不一致 | 先在 MySQL 直接执行同款 SQL,核对 $do_date 对应数据是否存在 | 明确"增量口径":订单用 modifiedTime、明细用 createTime、产品用 modifyTime;必要时引入 >= do_date and < do_date+1 |
| MySQLReader 很慢/数据库压力大 | date_format(col,'%Y-%m-%d') 让索引失效,全表扫描 | MySQL EXPLAIN 看 key 是否命中;慢查询日志 | 改为范围过滤:col >= ' dodate00:00:00′andcol<′do_date 23:59:59'(或 < date_add(...)),确保命中索引 |
| HDFSWriter 报路径不存在/权限不足 | 目录未创建或 HDFS 权限不允许写入 | hdfs dfs -ls 看目录/owner;DataX 日志看 Permission denied | 预创建目录并授权;或调整写入用户/kerberos 配置 |
| 写入文件格式正常但 Hive 查询不到数据 | Hive 分区未挂载或分区路径不一致 | show partitions / describe formatted 查看 location | 执行 alter table ... add partition(dt='...') 且保证与 path 完全一致 |
| Hive add partition 报表不存在 | ODS 表未建(正文已注明"目前Hive没有表") | show tables in ods | 先建表(外部表/分区表),再 add partition 或 MSCK REPAIR TABLE |
| 数据列错位/字段被截断 | CSV 分隔符冲突(字段含逗号/extra 字段)、类型不匹配(Float/INT) | 抽样查看 HDFS 文件首行;Hive 建表字段顺序对齐 | 选用安全分隔符(如 \001);对含 JSON/文本字段做转义或改用 parquet/orc |
| 金额精度异常(0.1 变 0.10000001) | Float 存储导致精度问题 | 对比 MySQL 与 HDFS/Hive 结果 | 金额改用 DECIMAL;DataX column type 与 Hive 表类型一致 |
| 增量重复/漏数 | writeMode=append 且同一天重跑会重复;漏数来自时间边界/时区 | 对比分区文件行数与 MySQL 当天 count;检查重跑历史 | 设计幂等:分区目录按天先清理再写;或文件名带 run_id;边界统一用 UTC/业务时区 |
| DataX 参数未替换 $do_date | -p 参数未生效或 JSON 引号/变量拼接错误 | DataX 日志输出最终 SQL/路径 | 确认 -p "-Ddo_date=..." 传参格式;JSON 中 $do_date 拼写一致 |
| 产品表字段名大小写/拼写不一致导致报错 | modifyTime/modifytime、createTime/createtime 混用 | MySQL desc table 对照字段真实名称;DataX 报 Unknown column | 统一字段名;SQL 与 column 列表严格一致 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接