作者:来自 Elastic Leonie Monigatti
为上下文工程编写数据库检索工具的最佳实践。学习如何设计和评估用于与 Elasticsearch 数据交互的 agent 工具。
优秀的搜索非常困难。这就是为什么我们拥有一个由搜索算法、工具甚至像 Elastic 这样的专用技术栈组成的生态系统,更不用说还有一个叫做 information retrieval 的完整领域。在现代上下文工程中, AI agents 会从许多不同来源搜索并检索上下文,包括本地文件、 Web 或 memory files。为 agents 提供工具来与数据库中存储的数据交互,使它们能够基于专有信息来支撑其答案,甚至完成分析任务。
然而,如果这些接口没有经过精心工程设计, agents 可能会搜索错误的索引,生成无效的 SQL / Elasticsearch Query Language ( ES|QL ) 查询,或者返回大量不相关的数据。在开发 Elastic Agent Builder 期间,我们多次看到这些失败模式。在与数十个内部团队合作构建用于与 Elasticsearch 数据交互的工具,并将其集成以通过 agentic workflows 改进我们的内部流程(例如我们的内部 laptop refresh 流程)时,我们发现最成功的团队会将数据库检索工具精心设计为其数据的精选接口。
在这篇博客中,我们分享在构建数据库检索工具时遵循的最佳实践。事实上,我们分享的这些原则基于在不断改进我们的预构建工具以及帮助内部团队构建自定义工具过程中观察到的常见模式。
Agentic 检索的关键挑战
编码和搜索是 agents 的最佳用例之一。尽管编码 agents 最近在新概念上取得了显著进展,例如面向 filesystem 的工具和针对代码的 embeddings,但搜索 agents(特别是用于数据库检索的 agents)尚未有显著突破的报道。
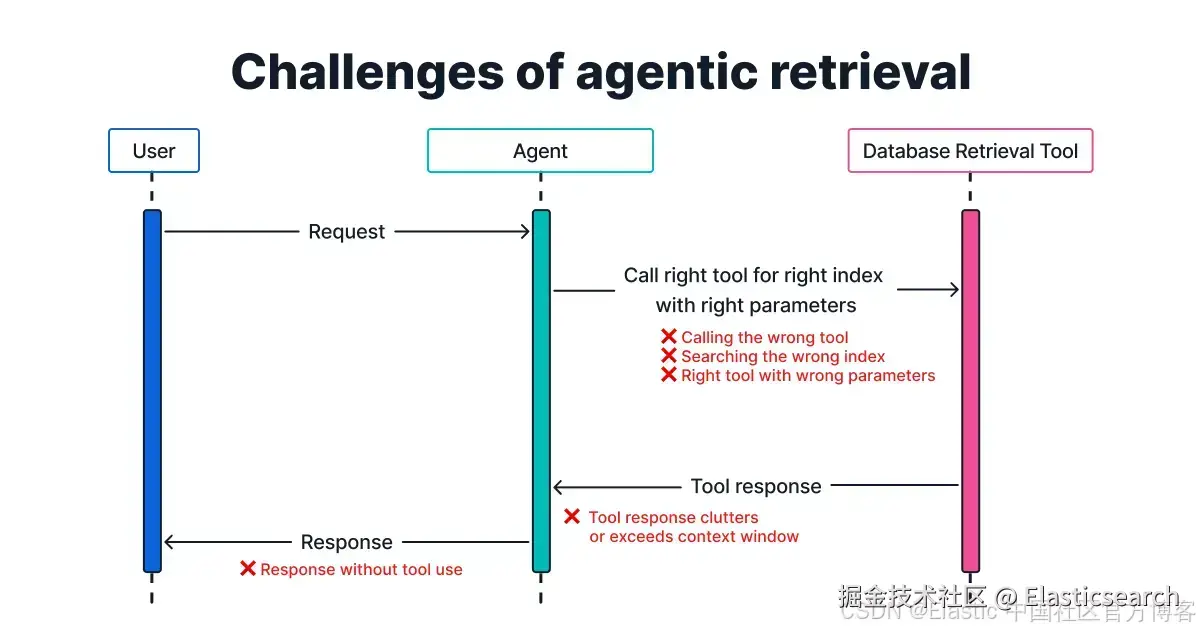
Agents 用例具有挑战性,原因有多方面:它们可能忽略可用工具来完成任务;可能调用错误的工具;也可能以错误参数调用正确的工具。除了这些通用挑战,我们认为数据库检索用例具有以下三个关键挑战:
-
识别正确的数据索引 需要 LLM 理解索引中包含的内容。但有时索引数量可能已经非常庞大,即便仅表示这些索引以供选择,也可能导致上下文长度问题。
-
生成高效查询 以平衡检索相关信息和最小化延迟及资源使用,这可能非常具有挑战性。
-
避免工具响应造成上下文膨胀 需要工具响应在上下文相关性和 token 效率上进行优化。这并不总是容易,尤其当 agent 从零生成查询时。一旦上下文不再与用户查询相关,将数据卸载以供后续参考又是另一个挑战。
在开发 Agent Builder 并将其集成到我们自身流程中时,我们多次遇到这些挑战。实际上,下面章节中分享的原则,是基于我们在迭代改进内置和自定义工具以及基于这些工具构建的内部 workflows 时观察到的常见模式总结而来的。
构建高效数据库检索工具的原则
在本节中,我们将经验转化为构建高效数据库检索工具的指导原则:决定要构建哪些工具,确保 agent 找到正确的索引进行搜索并以适当参数调用正确工具,优化工具响应,处理错误,以及保护数据安全。
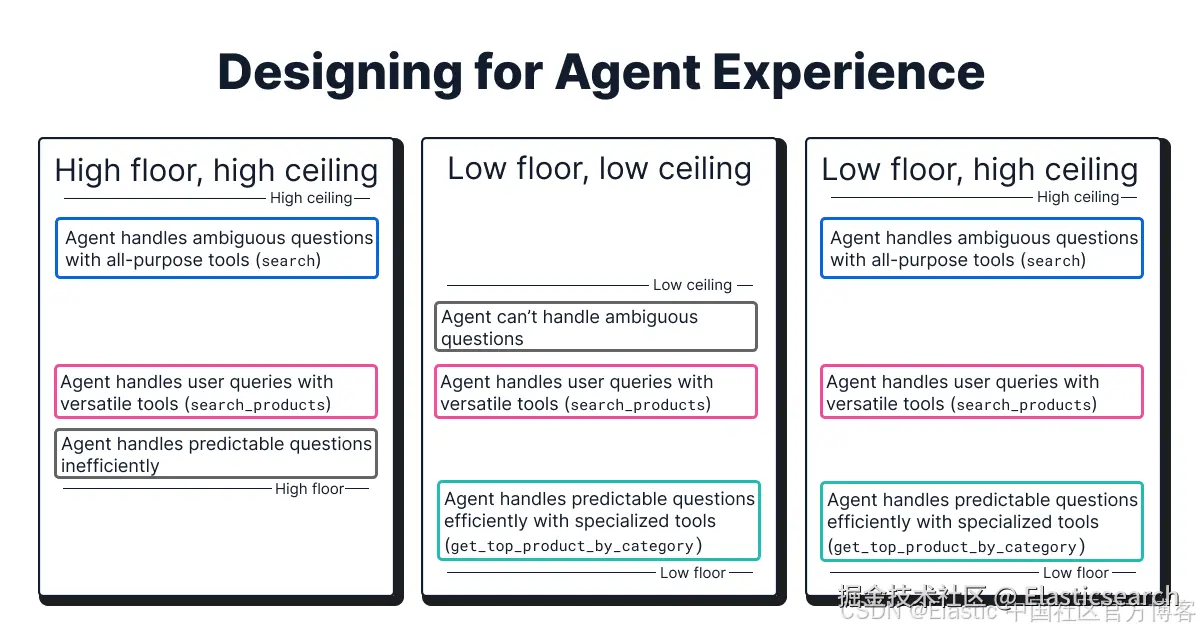
构建合适的数据库检索工具("低门槛,高上限/low floor, high ceiling")
在决定构建哪些数据库检索工具时,我们遵循 "低门槛,高上限" 原则,以提供良好的 agent 体验:
-
高上限(High ceiling) :工具不限制 agent 在最糟情况下处理模糊用户查询的潜力。在数据库检索场景中,这类工具是通用工具,例如允许 agent 从零编写完整 SQL/ES|QL 查询。这类工具的权衡是增加了 agent 的推理负担,同时可能导致更高延迟、更高成本和较低可靠性。
-
低门槛(Low floor):工具具有高可访问性,agent 可以在第一次尝试时成功使用,并且对重复用户查询的推理负担最小。在数据库检索场景中,这类工具是专用工具,例如封装特定查询的工具。这类工具的好处是比通用工具延迟更低、成本更低、可靠性更高。然而,它们需要工程投入,并且现实中工程师可能无法预见所有可能的用户查询。
例如,根据我们的经验,通用搜索工具是必需的,以便 agent 在最糟情况下处理独特且模糊的用户查询。然而,我们发现,为了减少推理负担并提高效率,创建专用工具是必要的(例如 get_top_performing_products(category))。
另一个经验教训是要考虑工具的抽象层级。在预览阶段,agent 可以访问大量原子通用工具(例如 get_index_mappings、generate_esql、execute_query 等)。在实践中,这有两个缺点:面对复杂且开放性的问题时,尽管有指导性指令,agent 仍然会混淆工具及其预期执行顺序。将多个工具组合在 agentic workflow 中还需要通过 context window 传递信息,这会导致 context window 被仅暂时重要的信息填满。为克服这种低效,我们将多个原子工具的功能封装成一个自包含的搜索工具。
找到正确的索引
虽然大多数与数据库交互的工具会专注于查询数据库,但在某些用例中,例如索引选择,工具会允许 agent 访问数据库的 metadata,以便根据用户查询和意图决定要搜索的索引。
最初,我们的简单索引选择依赖于索引名称和部分 schema 定义样本。在内部测试中效果不错,但当内部团队尝试使用时,我们发现真实用例中索引名称往往并不清晰或描述性强,而是模糊的(例如 users、logs、flight_travels 相比 web-logs-2026.01、web-logs-2026.02)。
为解决这一问题,我们开始在工具中暴露每个索引的 metadata 和 schema 定义。这显著改善了索引选择,使工程师可以在两个层面添加描述,将技术名称翻译成自然语言:
-
索引级描述:索引中存储了什么数据以及文档之间的关系。
-
字段级提示:字段的格式、预期值或业务含义的具体指导(例如,"此字段仅用于精确 ID 匹配")。
在另一次迭代中,我们决定加入数据采样。对于每个索引,我们会对每个字段的部分数据进行采样,让 agent 更清楚索引中数据的类型。虽然这显著提高了索引选择效率,但代价是增加了工具响应的数据量。
调用正确的数据库检索工具
指导 agent 调用正确的工具本身就已经很具挑战性。本节讨论了我们如何确保 agent 调用工具以使其回答有据可依,以及如何调用正确的数据库检索工具。
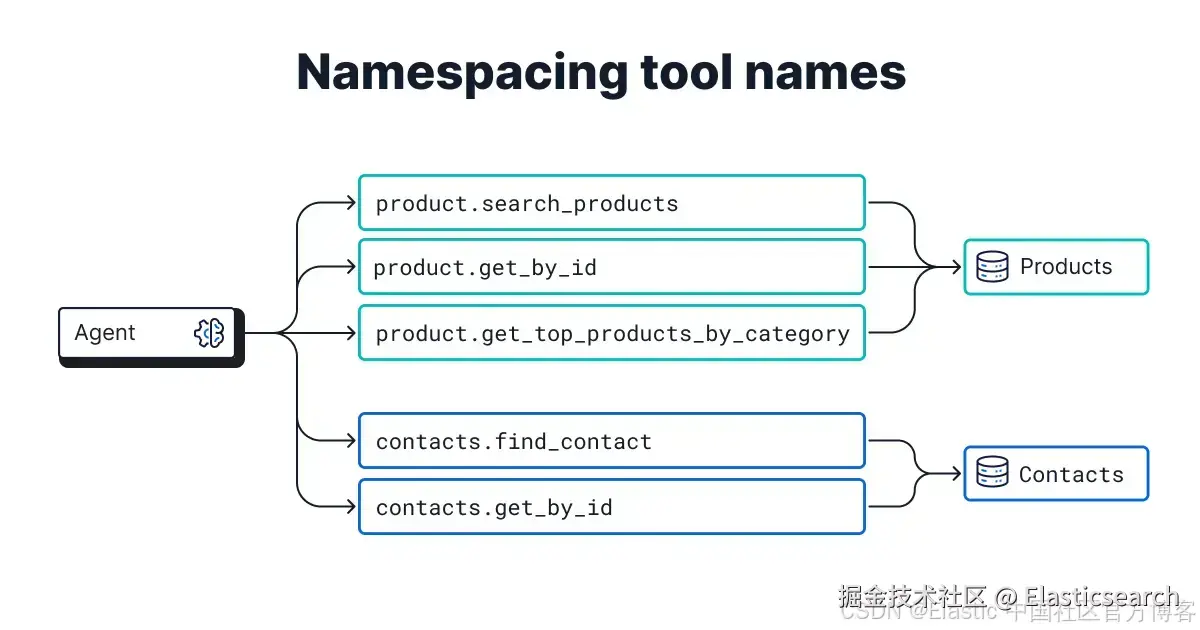
命名与命名空间:标准化标识以实现可靠选择
工具的名称就像一个可快速浏览的标题,agent 会用它来决定进一步调查哪一个。实践中,这意味着使用描述性且有区别的工具名称。此外,当工具名称在格式(例如统一使用 snake_case)和用词上保持一致时,工具选择会更可靠。使用面向动作的动词有助于 LLM 将用户意图映射到工具的用途,尽管工具名称的具体措辞在实践中不那么关键(例如,search 与 find)。
将工具进行命名空间分组,将相关工具归入统一的前缀或后缀也同样有用。在数据库场景下,根据索引或领域对工具进行命名空间管理,有助于 LLM 理解工具之间的关系,并防止命名冲突(例如 finance.search_ticker 或 support.get_ticket_details)。
工具描述:指导 agent 正确使用
描述是任何工具定义中最关键的部分,因为它指导 agent 何时以及如何使用该工具,尤其当工具名称相似时(例如 search_logs 与 find_errors)。
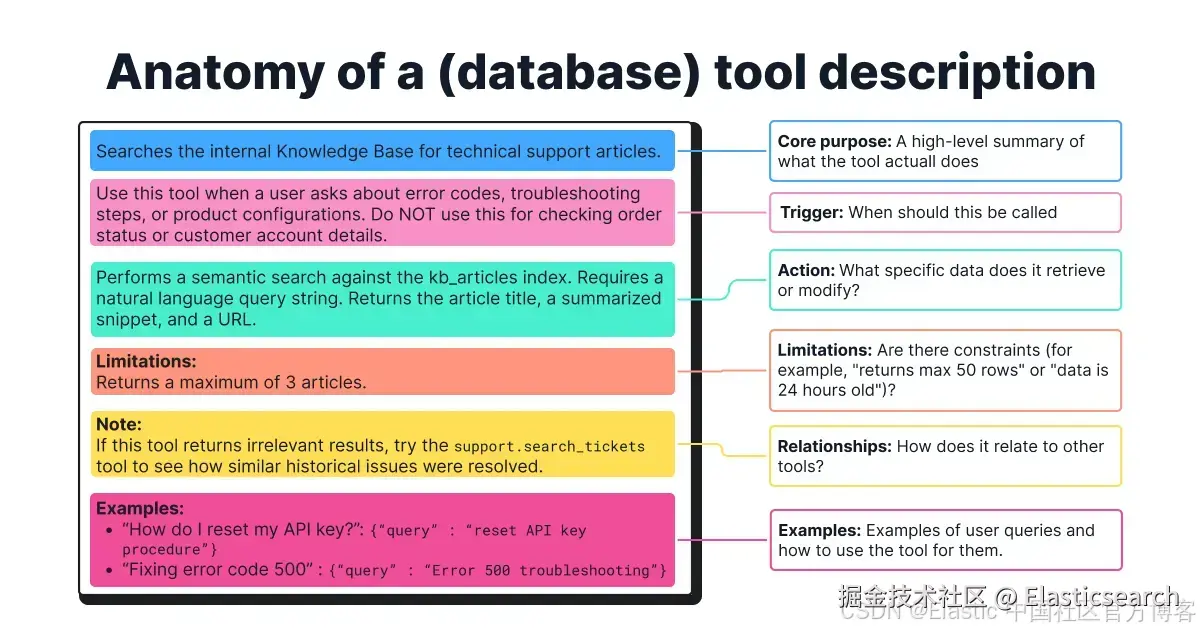
对于复杂工具,可参考以下模板:
-
核心用途:工具的高层总结,说明它的功能。
-
触发条件:工具应何时使用(以及何时不应使用)。
-
操作:工具检索或修改的具体数据,以及它可以回答的问题类型。
-
限制:重要的限制条件,例如特定查询语言或格式。
-
与其他工具的关系:某个工具是否影响其他工具,或是否存在前置条件。
-
示例:用户查询的具体 few-shot 示例,以及如何使用工具,例如如何确定最优搜索策略或何时使用哪个操作符。
关于模型敏感性说明:虽然顶级模型如 Claude 4.5 Sonnet 容错性较强,但较小模型通常需要更清晰、更详细的描述才能选择正确的工具。
添加推理参数
受 "think-augmented function calling" 论文启发,我们添加了一个推理参数。该方法通过为 LLM 提供一个 scratchpad 来处理其思路,从而提高参数准确性,并增强用户体验的透明度。
这种方式在复杂工具调用或向 agent 暴露大量工具时效果良好。然而,在简单场景下可能导致回退,对于基于思考的 LLM,其收益进一步降低。在我们的 Agent Builder 实现中,推理参数通常是可选的,并在执行前被去除,仅用于工具选择和参数填充。
json
`
1. "properties": {
2. "reasoning": {
3. "type": "string",
4. "description": "Brief explanation of why you're calling this tool"
5. }
6. }
`AI写代码支持:在 agent 提示中强化指令
我们观察到的一个常见错误是,LLM 有时会忽略可用工具,而使用其内置知识生成(虚构的)答案。例如,当被问到 "Can you tell me more information about Elasticsearch's ES|QL language?" 时,它可能会自行回答,而不是调用专门用于获取 Elastic 产品文档的工具。
为缓解这个问题,我们在 agent 的系统提示中添加了重复、明确的指令,引导 agent 在使用内置知识和基于工具响应的答案之间找到正确平衡。我们的测试显示,当向 agent 暴露多个用途相似的工具时,这种方法尤其有效。
强制使用工具
除了在 agent 提示中强化指令之外,当工具为必需时,我们发现显式绑定工具(使用 tool_choice: 'any')来强制使用工具也很有帮助。
调用数据库检索工具时使用适当的值并编写查询
另一个挑战是让 agent 能够使用适当的参数值调用工具。我们观察到一个一致的模式:参数定义的明确性、参数数量及其复杂性在减少错误中起着重要作用。
参数定义
明确的参数定义能显著提高参数的准确性。在 agent 工具中,参数定义的一般最佳实践包括:
-
清晰的名称:明确标识参数用途(例如,user_id 与 user 区分开)。
-
强类型:使用 integer、string 或 enums 等有限有效值集合类型。
-
详细描述:说明参数的含义、使用时机及方式。指定缺失值的默认值、文档格式(例如日期格式)、隐藏规则(例如,"至少需要 agent_id | user_id 中的一个"),并提供小示例。
bash
`
1. # Weak parameter description
2. "properties": {
3. "index": {
4. "description": "Name of the index",
5. },
6. }
8. # Strong parameter description
9. "properties":
10. {
11. "index": {
12. "type": "string","description": "The specific index, alias, or datastream to search. Defaults to 'main-alias' if unknown. ",
13. },
14. }
`AI写代码参数数量
当工具有大量参数(尤其是必填参数)时,agent 在调用时容易出错。一般经验是,将必填参数保持在 5 个以下,总参数不超过 10 个。
参数复杂性
尽可能降低输入参数的复杂性可以减少错误。例如,让 LLM 生成一个搜索词相比从零生成完整的 SQL 或 ES|QL 查询需要更多推理开销。尤其对于重复用户查询,"预生成" 搜索查询可以降低延迟、成本和错误率(尽管现代 LLM 已能很好地使用熟知语言,如 SQL)。
为了遵循 "低门槛,高上限" 的原则,我们倾向于将特定查询封装在一个工具中,让 agent 只提供搜索词。下面是针对同一用户查询 "根据新问题描述查找 5 条最相关的已解决 support tickets,以寻找以前的解决方案" 的不同复杂度输入参数示例。
scss
`
1. # Complex parameter
2. search_support_tickets("FROM support_tickets | WHERE status = 'resolved' AND customer_email = ?email | MATCH(issue_title, issue_description, ?problem_description) | KEEP ticket_id, issue_title, resolution | LIMIT 5",
3. )
5. # Simple parameter
6. find_similar_customer_resolved_tickets(problem_description)
`AI写代码模型敏感性
模型对参数准确性和查询生成有显著影响。我们内部基准测试显示,将 Claude 3.7 Sonnet 切换到 Claude 4.5 Sonnet 后,生成的 ES|QL 查询语法错误率从约 28% 降至约 4%。
输入验证
尽管上述技术提高了参数准确性,但仍无法完全避免错误。我们倾向于不盲目信任 LLM 的输入,而是始终进行验证和清理,以确保查询符合预期的 schema。
优化数据库检索工具响应
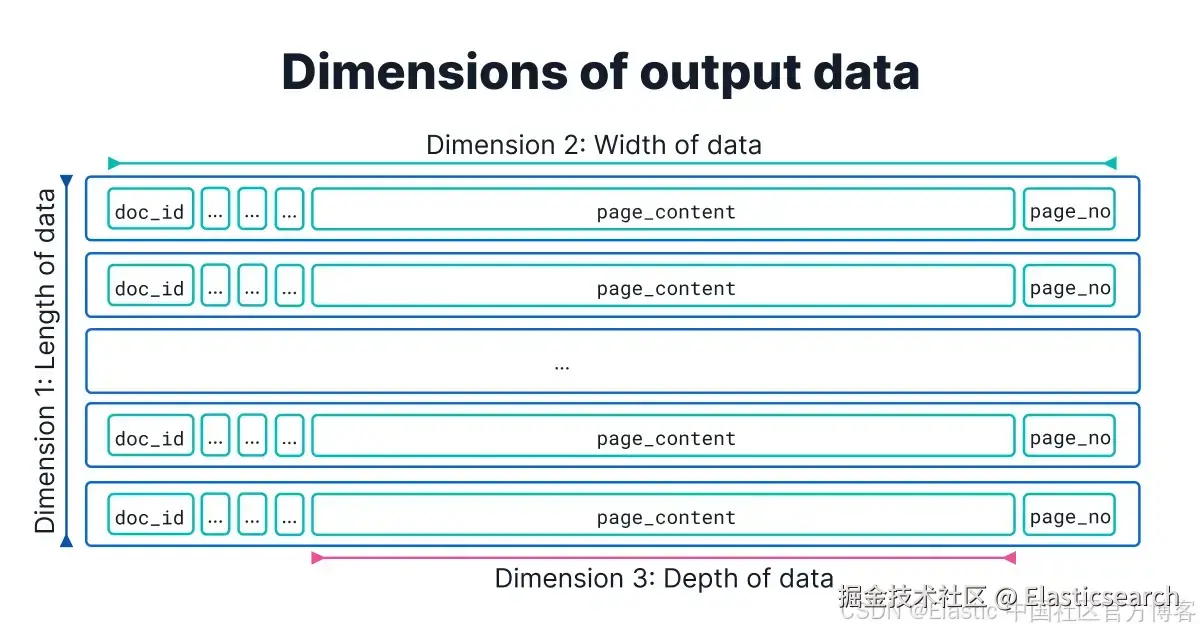
一个常见错误是忽略工具输出的大小。因为工具的输出直接进入 agent 的上下文窗口,如果不优化其上下文相关性 (质量),可能会分散 agent 注意力;如果不优化其 token 效率(数量),则会增加成本并有可能超过 LLM 的上下文窗口限制。与内部团队协作时,我们识别了三个维度来审查返回值:
第一个维度是长度 :搜索结果的数量。我们观察到团队中反复出现的陷阱是未对搜索结果进行限制,这可能导致上下文窗口溢出。虽然向量搜索查询本身通常需要限制参数,其他搜索方法往往没有。我们建议在所有查询类型中包含 limit 子句(例如 10 - 20),以防返回低信号结果并确保 token 效率。
第二个维度是宽度:每个数据对象的字段数量。与其返回所有属性(包括杂乱字段,例如时间戳和内部 ID 等),不如精选相关字段集合,这可以同时改善用户体验和 agent 行为。
示例说明:
-
返回数据对象的标识符及简洁属性集合,使 agent 在需要时可以 "及时上下文工程" 地检索完整信息,而不是让上下文窗口杂乱无章。
-
返回引用的元数据(例如大型 PDF 文档的页码)有助于建立用户信任。
-
返回搜索结果数量和状态信息,可以帮助 agent 推理查询的状态。
第三个维度是深度 :单个字段的大小。考虑文档本身很大(例如几十 MB 级别)的情况,这类文档不能完整返回给 agent,否则上下文长度会立即达到上限。为缓解这一问题,我们建议在文本摘要足够时截断长字段。我们发现 Elasticsearch 的高亮功能在这方面非常有用,无需额外调用 LLM API。
即便是较小文档,也可以让工具将数据格式化为 LLM 易于处理的格式,例如清理内容(去除 HTML 标签)、格式化可读性(例如将表格转换为 Markdown 表格或将链接格式化为 "Title"),从而提升下游性能。
仅使用这些技术中的一种通常不足以提高上下文相关性,将它们结合起来可能会降低检索召回率(例如,限制搜索结果数量可能会导致未能检索到所有相关文档)。在实际操作中,这需要评估这些方法的不同组合,以找到最佳平衡点。
处理错误并启用自我纠正
我们观察到,当 agent 遇到错误时,可能会陷入无限循环或生成幻觉响应。即便 agent 完全遵循指令,如果工具不提供任何错误信息,仅返回错误代码,或者最多只提供简短、无描述性的错误信息,agent 就无法从它不理解的错误中自我纠正。
提供详细的错误信息可以让 agent 理解错误发生的原因以及如何恢复。为此,工程师需要考虑 "不太理想" 的路径和预期的边缘情况,例如:
-
如果错误是由于搜索查询格式错误引起的,agent 应能够对失败进行推理并重新构造查询。在这种情况下,返回搜索结果数量和生成的查询可以帮助 agent 自我纠正。
-
一般来说,工程师需要考虑 "零结果" 是否是给定工具的预期行为。对于可能表示错误的空结果,提供错误信息和 agent 指令都可能有帮助。
ruby
``
1. # Example error message from tool
2. "No product data found for product ID [XYZ].
4. Review the search query [insert used search query here].
6. Ask the customer to confirm the product name, and look up the product ID by name to confirm you have the correct ID."
8. ---
9. # Example agent instruction
10. "If the product_search tool returns no results, do not state that the product does not exist.
12. First, check that the `:` operator was used for multi-value fields.
15. Second, ask the user to provide and confirm the product ID or provide an alternative identifier like product name."
``AI写代码在遇到因 API key 过期导致的 API 失败时,应严格限制重试次数(例如,最多两到三次),以防 agent 不断重复尝试失败的确定性流程。
保障数据安全
面向生产级 agent 应用的主要工程挑战在于身份传播,特别是身份验证(验证用户是谁)和授权(验证用户可以访问什么)的不同要求。虽然初始层(例如 Okta)可以提供基础身份验证,但下游系统(例如 ServiceNow、Elasticsearch 等)维护各自不统一的授权架构,并且粒度各异。
我们观察到最成功的实现是在工具逻辑中的每个触点都强制执行身份验证。这防止 agent 意外访问最终用户不允许查看的数据。通过在每个系统级别验证身份,我们确保 agent 在处理复杂、多系统工作流时也尊重隐私。需要注意的是,这带来了有意的、安全要求的延迟。
除了在每个触点验证身份外,安全管理凭证也至关重要。在工具定义中暴露敏感 API key 或在 YAML 配置文件中硬编码数据库凭证都是高风险漏洞。我们建议工程师使用安全凭证管理系统。
评估数据库检索工具
面向 agentic 系统的数据库检索工具开发是一个迭代、以评估为驱动的过程。为了评估数据库检索工具的有效性并发现问题,我们的内部团队维护包含真实用户查询及预期工具调用的评估数据集(例如,"我有资格进行笔记本电脑更新吗?"期望调用 check_eligibility 工具)。我们使用以下指标来评估数据库检索工具,并为不同 LLM 的模型选择进行基准测试:
-
工具选择准确率:特定查询类型(例如检索、分析、混合、对抗)正确选择工具的频率。
-
首次成功率:关键指标在于区分最终成功与立即成功。agent 是否首次就选择正确工具,还是需要自我修正循环?(高自我修正率表明工具描述不够清晰。)
-
每次回答的平均工具调用次数:用于追踪 agent 的效率。如果简单问题的平均工具调用次数从 1.5 跳到 4,通常表示 agent 迷失方向或工具粒度过细。
-
特定工具的召回率/精确度:针对专用数据库检索工具,我们测量标准检索指标,以确保返回的文档与 LLM 提供的参数相关。
-
失败率:严格监控工具调用的错误率(例如缺失参数),以识别哪些模型在 prompt 指令中需要更多"指导"。
上线后,Elastic 的团队会继续监控 agentic 健康状况,并在 Kibana 中记录遥测数据(例如,每次成功与失败以及 agent 完成任务所用时间)。这使 ITOps 团队能够构建仪表板来回答元问题,例如:"本周失败率是多少?","有多少笔记本电脑请求来自加州?","有多少请求被完成?",而无需构建自定义分析引擎。
总结
在 Elastic Agent Builder 迭代、以评估为驱动的开发过程中,我们发现了数据库检索工具在上下文工程中的有效性的一致模式。在实现用于搜索、检索和操作数据的工具时,我们尽量遵循以下核心原则:
-
通过遵循 "低门槛,高上限" 原则构建合适的数据库检索工具。
-
通过精心设计和强化提示及接口设计,帮助 agent 调用正确的数据库检索工具并使用适当的参数值。
-
优化工具响应以提高上下文相关性(质量)和 token 效率(数量),避免上下文泛滥。
然而,仍存在开放性挑战,我们正在积极改进这些技术:
-
上下文膨胀是影响 agent 性能的主要障碍,因为检索的数据会随着对话进展保留在上下文窗口中。未来方向是将大量数据(如工具响应或附件)动态卸载到文件存储中,并允许 agent 按需检索。
-
高效发现大量工具和数据附件对构建生产级 agent 至关重要。我们计划引入具有渐进式披露功能(仅按需加载信息)和语义元数据层的 agent 技能。
致谢
本文由 Leonie Monigatti 撰写,并感谢 Search Solutions Engineering(Sean Story、Pierre Gayvallet、Abhimanyu Anand)和 Enterprise Applications(Sri Kolagani)同事的宝贵贡献。
Agent Builder 已经正式发布。你可以通过 Elastic Cloud 试用开始使用,并在此查看 Agent Builder 文档。