作者:来自 Elastic Jeffrey Rengifo
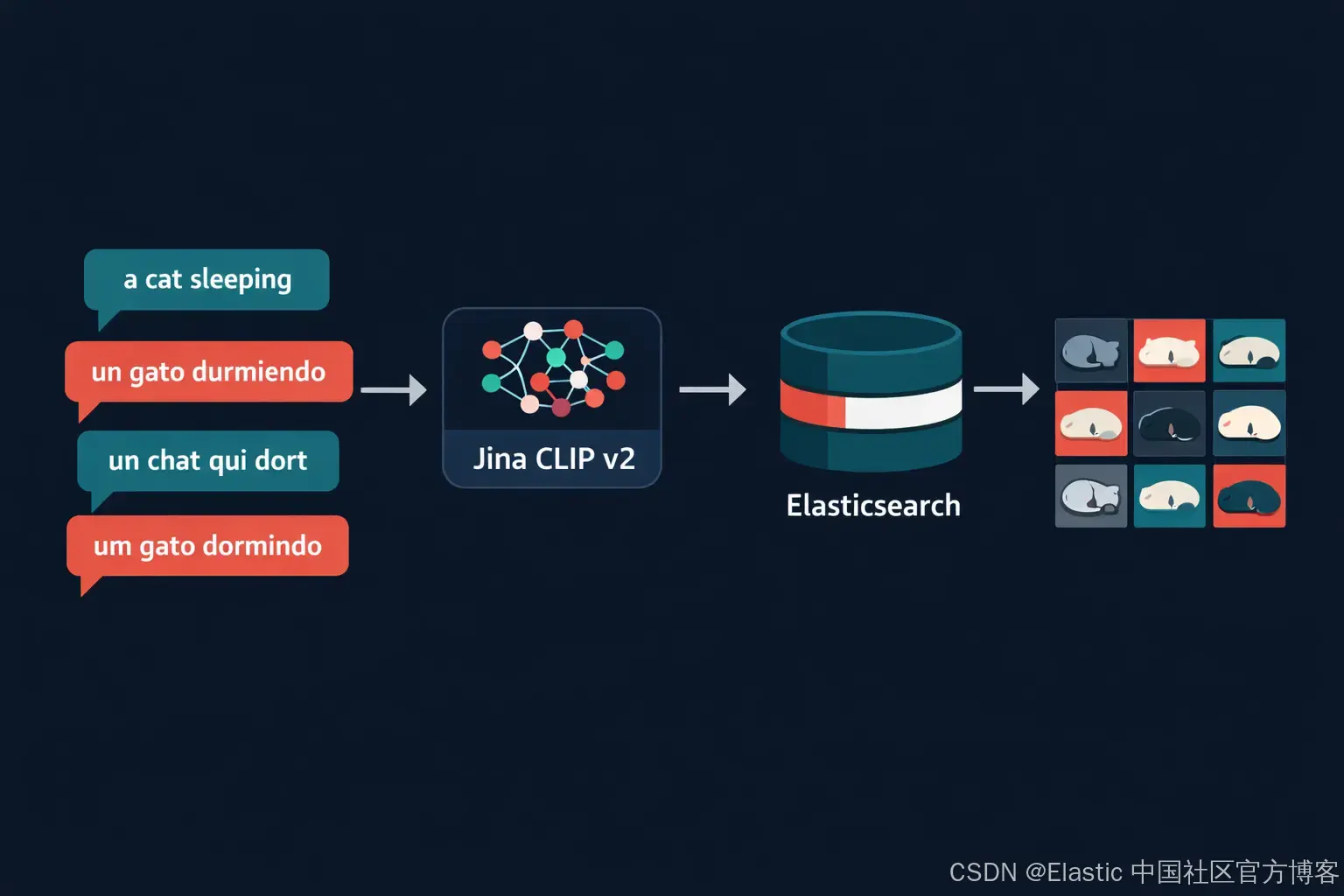
使用 Jina CLIP v2 和 Elasticsearch 构建多语言图片搜索系统。无需翻译流水线,即可使用 89 种语言查询你的图片集合,并利用 Matryoshka Representations 将索引大小减少 75%。
Elasticsearch 原生集成了业界领先的 Gen AI 工具和服务提供商。欢迎查看我们关于超越 RAG 基础,或使用 Elastic Vector Database 构建生产就绪应用的网络研讨会。
为了针对你的使用场景构建最佳搜索解决方案,现在即可开始免费的云端试用,或在你的本地机器上体验 Elastic。
在上一篇文章中,我们探讨了用于多模态搜索的 OpenAI 对比语言--图像预训练(Contrastive Language--Image Pre-training - CLIP)替代方案,其中包括 Jina CLIP v1。在本文中,我们将进一步介绍 Jina CLIP v2。这是一款多语言、多模态嵌入模型,使你能够使用同一个 Elasticsearch 索引和同一个模型,以 89 种语言搜索图片集合。我们还将介绍 Matryoshka Representations,这是 v2 的一项功能,可帮助你将索引大小减少 75%。
前提条件
你可以参考完整 Notebook 获取全部代码并跟随实践。
Jina CLIP v1 与 v2 对比
在编写代码之前,先了解有哪些变化是值得的。最重要的特性是多语言支持,但除此之外还有一些其他重要改进:
| 特性 | Jina CLIP v1 | Jina CLIP v2 |
|---|---|---|
| 语言 | 仅支持英语 | 89 种语言 |
| 最大图片分辨率 | 224×224 | 512×512 |
| 文本编码器 | JinaBERT | Jina XLM-RoBERTa |
| Matryoshka Representations | 否 | 是 |
| 嵌入维度 | 768 | 1024 |
| 最大文本长度 | 512 个 tokens | 8192 个 tokens |
从 JinaBERT 升级到 Jina XLM-RoBERTa 的文本编码器,正是实现多语言支持的关键。现在,你可以使用法语编写查询,并检索带有英语标签的图片;模型会将两者映射到同一个嵌入空间中。
在 v2 中,长度最多为 8,192 个 tokens 的查询都会被完整嵌入;如果启用了 truncate 选项,超出部分将被截断。
设置
作为向量数据库,Elasticsearch 允许我们原生存储和搜索稠密嵌入。我们使用一个具有 1024 维度并采用余弦相似度(cosine similarity)的 dense_vector 字段。对于 CLIP 风格的嵌入来说,这是一个合适的选择,因为余弦相似度会在索引时对向量进行归一化:
INDEX_NAME = "clip-v2-stock-images"
if es_client.indices.exists(index=INDEX_NAME):
es_client.indices.delete(index=INDEX_NAME)
es_client.indices.create(
index=INDEX_NAME,
mappings={
"properties": {
"image_embedding": {
"type": "dense_vector",
"dims": 1024,
"index": True,
"similarity": "cosine",
},
"tags": {
"type": "text",
"fields": {"keyword": {"type": "keyword"}},
},
}
},
)Jina Embeddings API
我们使用 Jina Embeddings API,这是一个 REST API,能够使用同一个模型同时处理文本和图片输入:
import requests
import base64
from io import BytesIO
JINA_API_URL = "https://api.jina.ai/v1/embeddings"
JINA_HEADERS = {
"Content-Type": "application/json",
"Authorization": f"Bearer {JINA_API_KEY}",
}
def image_to_base64(image, max_size=512):
"""Convert a PIL image to a base64 data URL, resizing to max_size."""
image = image.copy()
image.thumbnail((max_size, max_size))
buffer = BytesIO()
image.save(buffer, format="PNG")
b64 = base64.b64encode(buffer.getvalue()).decode("utf-8")
return f"data:image/png;base64,{b64}"
def encode_texts(texts, dimensions=1024):
"""Encode a list of text strings using Jina CLIP v2."""
data = {
"input": [{"text": t} for t in texts],
"model": "jina-clip-v2",
"dimensions": dimensions,
}
response = requests.post(JINA_API_URL, headers=JINA_HEADERS, json=data)
response.raise_for_status()
return [item["embedding"] for item in response.json()["data"]]
def encode_images(images, dimensions=1024):
"""Encode a list of PIL images using Jina CLIP v2."""
data = {
"input": [{"image": image_to_base64(img)} for img in images],
"model": "jina-clip-v2",
"dimensions": dimensions,
}
response = requests.post(JINA_API_URL, headers=JINA_HEADERS, json=data)
response.raise_for_status()
return [item["embedding"] for item in response.json()["data"]]dimensions 参数用于控制输出向量的大小,也是支持 Matryoshka 的关键,我们将在本文最后进行介绍。目前,我们使用完整的 1024 维向量。
加载数据集
我们使用 StockImages-CC0 数据集,其中包含约 4,000 张采用 CC0 许可协议的图库照片,并附带描述性标签。图片宽度约为 1200 像素,远高于 CLIP v2 的 512×512 输入尺寸,因此我们会在生成嵌入时对图片进行缩放。
为了让演示运行更快,并且结果更容易理解,我们选取了 20 张涵盖不同类别的图片:
from datasets import load_dataset
full_dataset = load_dataset("KoalaAI/StockImages-CC0", split="train")
print(f"Total images: {len(full_dataset)}")
selected_indices = [
0, # technology: smartphone, macbook
8, # coastal landscape: driftwood, sea, ocean
34, # waterfall: rock, waterfall, creek
40, # fashion: highheel, shoe, red
61, # vineyard: vine, wine, fruit
82, # fruit: raspberry, berry
90, # night sky: milky way, stars
95, # music: acoustic guitar
111, # town: hot air balloon
120, # vehicle: vw van, vintage
150, # city: eiffel tower, paris
153, # animal: puppy, canine
191, # sport: skateboard, kickflip
197, # drink: tea, honey
286, # wildlife: brown bear
305, # architecture: palace, cathedral
312, # coffee: latte, cappuccino
317, # flowers: tulip, bouquet
371, # nature: waterfall, river, cascade
418, # pet: kitten, cat
]
dataset = full_dataset.select(selected_indices)
print(f"Selected {len(dataset)} images")生成图片嵌入
下图展示了两阶段处理流程:
首先,使用 CLIP v2 对图片生成嵌入,并将其存储到 Elasticsearch 中;然后,使用同一个模型对文本查询或图片查询生成嵌入,并通过 k 最近邻(kNN)相似度搜索进行检索。
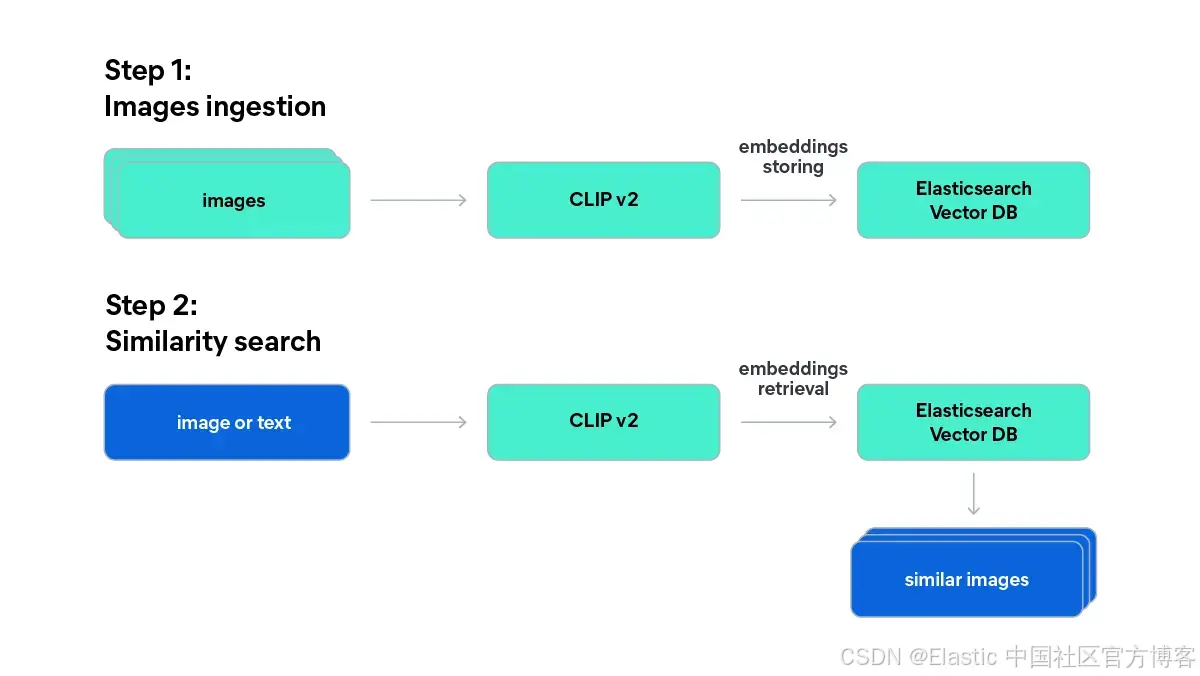
我们在一次 API 调用中对全部 20 张图片进行编码。CLIP v2 模型将图像和文本嵌入到同一个向量空间中,这正是实现文本到图像搜索的关键:
images = [item["image"].convert("RGB") for item in dataset]
image_embeddings = encode_images(images)
print(f"Generated {len(image_embeddings)} embeddings of {len(image_embeddings[0])} dimensions")
# Generated 20 embeddings of 1024 dimensions 索引文档
我们使用 Elasticsearch 的 bulk helper 一次性将所有文档批量写入索引:
from elasticsearch import helpers
def build_bulk_actions(dataset, image_embeddings, index_name):
for i, item in enumerate(dataset):
yield {
"_index": index_name,
"_id": i,
"_source": {
"image_embedding": image_embeddings[i],
"tags": item.get("tags", ""),
},
}
success, failed = helpers.bulk(
es_client,
build_bulk_actions(dataset, image_embeddings, INDEX_NAME),
refresh=True,
)
print(f"Indexed {success} documents")
# Indexed 20 documents多语言文本到图像搜索
我们使用与图像相同的 clip-v2 模型对文本查询进行编码,然后对图像嵌入执行 kNN 搜索。由于 Jina CLIP v2 将所有支持语言的文本和图像映射到同一个嵌入空间,因此不同语言的查询会检索到相同的图像:
import matplotlib.pyplot as plt
def search_by_text(query, k=3):
"""Encode a text query and search Elasticsearch."""
query_embedding = encode_texts([query])[0]
results = es_client.search(
index=INDEX_NAME,
knn={
"field": "image_embedding",
"query_vector": query_embedding,
"k": k,
"num_candidates": 50,
},
)
return results["hits"]["hits"]我们使用三组查询进行测试,每组都被翻译成英语、西班牙语、法语和葡萄牙语:
multilingual_queries = [
{
"English": "a cat sleeping",
"Spanish": "un gato durmiendo",
"French": "un chat qui dort",
"Portuguese": "um gato dormindo",
},
{
"English": "red flowers",
"Spanish": "flores rojas",
"French": "fleurs rouges",
"Portuguese": "flores vermelhas",
},
{
"English": "waterfall in nature",
"Spanish": "cascada en la naturaleza",
"French": "cascade dans la nature",
"Portuguese": "cascata na natureza",
},
]
for query_set in multilingual_queries:
print(f"\n{'='*60}")
for lang, query in query_set.items():
print(f'\n{lang}: "{query}"')
hits = search_by_text(query, k=3)
display_results(hits, query=f"[{lang}] {query}") # Function to display the images如下图所示,每个查询的四种语言版本都会返回相同的顶部结果。不同语言之间的排序分数几乎完全一致:



图像到图像搜索
除了文本查询之外,你还可以使用图像作为查询来查找视觉上相似的图片。方法是一样的:将查询图像编码到嵌入空间中,然后执行 kNN 搜索:
def search_by_image(image, k=5):
"""Encode an image and search Elasticsearch."""
query_embedding = encode_images([image])[0]
results = es_client.search(
index=INDEX_NAME,
knn={
"field": "image_embedding",
"query_vector": query_embedding,
"k": k,
"num_candidates": 50,
},
)
return results["hits"]["hits"]
# Use image at index 10 (Eiffel Tower) as query
query_image = dataset[10]["image"]
hits = search_by_image(query_image)
display_results(hits, query="Similar to query image")我们使用下面这张埃菲尔铁塔的图片来进行图像搜索:


以埃菲尔铁塔作为查询,该模型会首先返回图片本身,其次是一个教堂和一个有热气球的小镇;这两者在视觉和语义上都与城市地标接近。葡萄园和滑板公园的匹配则不那么明显;由于索引中只有 20 张图片,kNN 会始终返回 k 个结果,而不考虑相关性强弱。
Matryoshka Representations - 套娃表示
Jina CLIP v2 支持 Matryoshka Representation Learning(MRL)。其核心思想是:模型在训练时被设计为使 embedding 的前 N 个维度已经能够表达大部分信息,因此你可以截断后面的维度,从而获得更小的向量,同时几乎不损失效果。
Jina API 通过 dimensions 参数直接支持这一能力,该参数可以在 64 到 1024 之间取任意整数。
根据 Jina 的基准测试,从 1024 维降到 256 维,在文本、图像以及跨模态任务上仍能保持超过 99% 的检索质量。
要使用低维向量,你需要创建一个单独的 Elasticsearch 索引,并将 dims 设置为目标维度大小。因为 Elasticsearch 的 dense_vector 字段在创建索引时是固定维度的,你不能用 256 维向量去查询一个 1024 维的索引:
MATRYOSHKA_DIMS = 256
MATRYOSHKA_INDEX = "clip-v2-stock-images-256d"
if es_client.indices.exists(index=MATRYOSHKA_INDEX):
es_client.indices.delete(index=MATRYOSHKA_INDEX)
es_client.indices.create(
index=MATRYOSHKA_INDEX,
mappings={
"properties": {
"image_embedding": {
"type": "dense_vector",
"dims": MATRYOSHKA_DIMS,
"index": True,
"similarity": "cosine",
},
"tags": {
"type": "text",
"fields": {"keyword": {"type": "keyword"}},
},
}
},
)
# Generate 256-dim embeddings
image_embeddings_256 = encode_images(images, dimensions=MATRYOSHKA_DIMS)
print(f"Generated {len(image_embeddings_256)} embeddings of {len(image_embeddings_256[0])} dimensions")
# Index documents
success, _ = helpers.bulk(
es_client,
build_bulk_actions(dataset, image_embeddings_256, MATRYOSHKA_INDEX),
refresh=True,
)
print(f"Indexed {success} documents in {MATRYOSHKA_INDEX}")现在比较 1024 维索引和 256 维索引之间的结果:
query = "a cat sleeping"
print("Results with 1024 dimensions:")
hits_1024 = search_by_text(query, k=3)
display_results(hits_1024, query=f"{query} (1024 dims)")
print("\nResults with 256 dimensions:")
query_embedding_256 = encode_texts([query], dimensions=MATRYOSHKA_DIMS)[0]
hits_256 = es_client.search(
index=MATRYOSHKA_INDEX,
knn={
"field": "image_embedding",
"query_vector": query_embedding_256,
"k": 3,
"num_candidates": 50,
},
)["hits"]["hits"]
display_results(hits_256, query=f"{query} (256 dims)")
ids_1024 = [hit["_id"] for hit in hits_1024]
ids_256 = [hit["_id"] for hit in hits_256]
print(f"1024d ranking: {ids_1024}")
print(f" 256d ranking: {ids_256}")
print(f"Same top results: {ids_1024 == ids_256}")这些是结果:


在 256 维和 1024 维索引中,返回的最相关结果是相同的。在更大规模的部署中,256 维嵌入可以按比例减少存储占用和查询延迟,因此 Matryoshka 在生产系统中是一种很实用的优化方式,尤其是在索引规模较大的情况下。不过,仍然需要针对你的具体数据集来评估检索质量。
多模态差距
需要注意的是,CLIP 风格的双编码器模型存在一个已知限制,称为多模态差距(multimodal gap):文本和图像的嵌入在向量空间中往往形成分离的簇,这会导致跨模态相似度分数的可靠性下降。Jina 在 jina-embeddings-v4 中通过用统一模型替代双编码器架构来解决这一问题,并且正在开发多模态 v5。如果你的用例对跨模态对齐要求很高,建议关注这些更新的模型。
结论
Jina CLIP v2 在 v1 的基础上进行了扩展,支持 89 种语言的多语言能力、更大的嵌入向量、更高的图像分辨率,以及 Matryoshka embeddings,使你可以在索引大小和少量质量损失之间进行权衡。其 API 保持一致,因此你可以像使用第一版一样使用该模型。
下一步
- 阅读 Jina models guide(Search Labs 上的 Jina 模型指南),了解 Elasticsearch 中可用的所有 Jina 模型概览。
- 查看 Elasticsearch kNN search 文档,了解过滤、混合检索和重排序选项。
- 参考使用 SigLIP-2 进行多模态搜索,了解另一种 CLIP 替代方案。
- 学习 Elasticsearch 中多语言 embedding 模型部署,掌握纯文本跨语言检索方法。
- 查看embeddings 映射到 Elasticsearch 字段类型,了解如何在 dense_vector、semantic_text 和 sparse_vector 之间做选择。
这篇内容对你有多大帮助?
原文:https://www.elastic.co/search-labs/blog/image-search-multilingual-elasticsearch-jina-clip-v2