本章目标:从 0 到 1 完成一次真实的大模型 API 调用,掌握非流式对话、流式输出、推理思考模型三种核心模式,并理解每一行代码的作用。
一、你真的了解 LLM 是什么吗?
LLM(Large Language Model,大语言模型) 是当今 AI 应用的核心引擎。它本质上是一个经过海量文本训练的神经网络,能够理解和生成自然语言。你每天使用的 ChatGPT、通义千问、文心一言,底层都是 LLM。
LLM 的几个关键特性:
| 特性 | 说明 |
|---|---|
| 无状态性 | 每次 API 调用都是独立的,模型不会自动记住上一次对话 |
| 概率生成 | 模型生成的每个词都是基于上下文的概率分布采样 |
| Token 计费 | 按输入/输出的 Token 数收费(1 个汉字约 1-2 个 Token) |
| 上下文窗口 | 模型单次能处理的最大 Token 数(如 128K Token) |
为什么使用阿里云百炼 API?
阿里云百炼提供通义千问(Qwen)系列模型,并且提供了 OpenAI 兼容模式。这意味着你可以直接使用业界最广泛的 OpenAI Python SDK,只需改两个参数就能接入百炼,无需学习新的 SDK。

添加图片注释,不超过 140 字(可选)
二、准备工作(5 分钟搞定)
2.1 安装依赖
bash
# 进入项目目录
cd ai-agent-test
# 安装核心依赖
uv sync
# 如果没有 uv,也可以用 pip:
pip install langchain-openai python-dotenv2.2 配置 API Key
bash
# 复制环境变量模板
cp .env.example .env
# 编辑 .env,填入你的百炼 API Key
# DASHSCOPE_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxx💡 如何获取 API Key? 登录 阿里云百炼控制台,在"API Key 管理"页面创建。
2.3 选择合适的模型
| 模型名称 | 特点 | 推荐场景 |
|---|---|---|
| qwen-turbo | 极速响应,价格最低 | 实时交互、大量请求 |
| qwen-plus | 均衡性能,综合推荐 | 日常开发、学习入门 ✅ |
| qwen-max | 最强理解与推理能力 | 复杂任务、代码生成 |
| qwen3-235b-a22b | 旗舰推理模型,支持思考链 | 数学、逻辑、深度分析 |
三、核心概念:对话消息结构
LLM 的对话不是简单地传一个字符串,而是传一个结构化的消息列表。每条消息有固定的角色(role):
css
messages = [ # 系统提示:定义 AI 的身份、风格、能力边界 {"role": "system", "content": "你是一位专业的 Python 编程教练,回答简洁而准确。"}, # 用户消息:用户的输入 {"role": "user", "content": "如何在 Python 中反转一个字符串?"}, # AI 消息:模型的历史回复(用于多轮对话) # {"role": "assistant", "content": "可以用切片:s[::-1]"}, # 继续对话时追加 # {"role": "user", "content": "有没有更简单的方法?"},]为什么这样设计?
- system 消息让你控制 AI 的行为,避免它偏离主题
- 将历史消息全部传入,AI 才能"记住"之前说过的话
- 这种结构清晰分离了指令、上下文和当前请求
四、Step 1:非流式对话(最简单的起点)
ini
import os
from openai import OpenAI
from dotenv import load_dotenv
# 加载 .env 文件中的环境变量
load_dotenv()
# ── 初始化客户端 ────────────────────────────────────────────────
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量读取,永远不要硬编码密钥!
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 百炼兼容端点
)
# ── 发起一次 API 调用 ───────────────────────────────────────────
completion = client.chat.completions.create(
model="qwen-plus", # 指定模型
temperature=0.7, # 控制创意度:0=严格确定, 2=最随机(学习时建议 0.5-0.8)
max_tokens=500, # 限制输出长度,避免费用超支
messages=[
{"role": "system", "content": "你是一位知识渊博的 AI 助手,用中文回答。"},
{"role": "user", "content": "用一句话解释什么是机器学习?"},
],
)
# ── 解析响应 ───────────────────────────────────────────────────
# completion 是一个对象,真正的回答在这里:
answer = completion.choices[0].message.content
print(f"AI 回答:{answer}")
# 查看 token 用量(监控成本的关键)
usage = completion.usage
print(f"Token 用量 → 输入:{usage.prompt_tokens},输出:{usage.completion_tokens},合计:{usage.total_tokens}")预期输出:
AI 回答:机器学习是让计算机通过数据自动学习规律并做出预测或决策的技术,无需人工明确编程每一条规则。
Token 用量 → 输入:29,输出:38,合计:67🔑 代码关键点解析
- temperature:这是 LLM 最常用的超参数。值越低,输出越确定(同样的问题每次答案几乎相同);值越高,输出越多样(创意写作适合用高温度)。
- max_tokens:保护措施,防止模型"停不下来"。对于简短问答,设 200-500 就够了。
- completion.choices0:模型可以同时生成多个候选回答(通过 n=3 参数),choices0 取第一个。
- completion.usage:务必关注 Token 用量,这直接影响 API 费用。
五、Step 2:流式输出(打字机效果)
非流式调用需要等待模型生成完所有文字才返回,如果生成 500 个字,你可能需要等 3-5 秒才看到任何内容。流式调用(Streaming) 让模型边生成边输出,用户体验大幅提升。
ini
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
print("AI 正在生成(流式输出):")
print("-" * 40)
# ── 关键区别:stream=True ──────────────────────────────────────
completion = client.chat.completions.create(
model="qwen-plus",
stream=True, # 开启流式输出
stream_options={"include_usage": True}, # 在最后一个 chunk 附带用量统计
messages=[
{"role": "system", "content": "你是一位科普作家,文章生动有趣。"},
{"role": "user", "content": "解释一下为什么天空是蓝色的?"},
],
)
# ── 逐块处理响应 ────────────────────────────────────────────────
total_tokens = 0
for chunk in completion:
# 每个 chunk 是一个增量更新
if chunk.choices:
delta = chunk.choices[0].delta # 本次增量
if delta.content: # 有文字内容
print(delta.content, end="", flush=True) # 不换行,立即刷新
# 最后一个 chunk 包含用量统计
if chunk.usage:
total_tokens = chunk.usage.total_tokens
print(f"\n{'-' * 40}")
print(f"总计 Token:{total_tokens}")流式响应的数据流向:
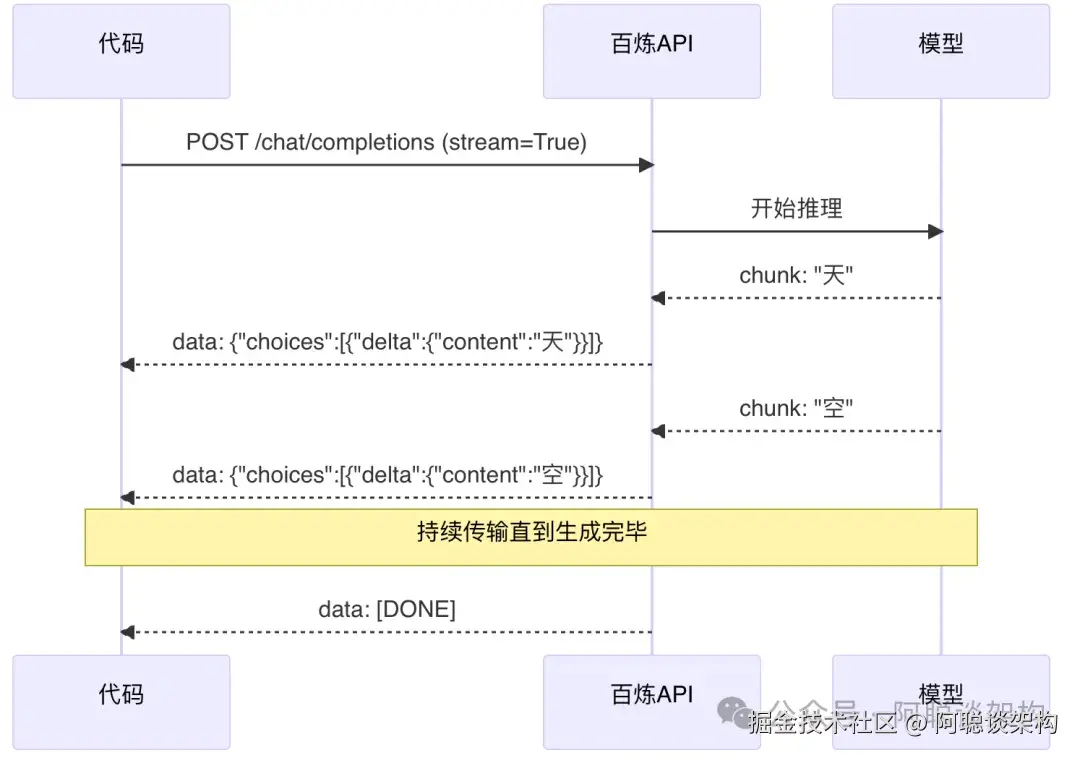
六、Step 3:思考模型(AI 的"慢思考")
代码文件:lessons/01_basic_llm/03_thinking_model.py
Qwen3 旗舰版支持"推理思考模式"(Chain of Thought)。在给出最终答案之前,模型会先进行内部推理,就像人类解题时在草稿纸上演算一样。这对数学题、逻辑分析特别有效。
python
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# ── 使用推理模型 ───────────────────────────────────────────────
completion = client.chat.completions.create(
model="qwen3-235b-a22b", # 支持思考链的旗舰模型
stream=True,
extra_body={"enable_thinking": True}, # 关键:开启推理思考
messages=[
{"role": "user", "content": "鸡兔同笼:共有头 35 个,脚 94 只,问鸡、兔各多少只?"}
],
)
print("=" * 50)
print("🧠 推理过程:")
print("=" * 50)
thinking_shown = False
answer_started = False
for chunk in completion:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
# ── 推理内容(思考链)──────────────────────────────────────
if hasattr(delta, "reasoning_content") and delta.reasoning_content:
if not thinking_shown:
thinking_shown = True
print(delta.reasoning_content, end="", flush=True)
# ── 最终答案 ───────────────────────────────────────────────
elif delta.content:
if not answer_started:
answer_started = True
print("\n\n" + "=" * 50)
print("✅ 最终答案:")
print("=" * 50)
print(delta.content, end="", flush=True)
print()两种输出的区别:
| 字段 | 内容 | 对用户是否显示 |
|---|---|---|
| delta.reasoning_content | 模型的内部推理过程(草稿纸) | 可选,通常折叠显示 |
| delta.content | 最终答案 | 必须显示 |
💡 使用场景建议:普通问答用 qwen-plus(快且便宜),遇到数学、逻辑、代码调试等需要精确推理的任务,切换到 qwen3-235b-a22b + enable_thinking=True。
七、实际应用:封装一个可复用的 LLM 客户端
在真实项目中,你通常不会直接在业务代码里写上面的样板代码。下面是一个简单的封装,供你参考和改造:
python
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
class QwenClient:
"""通义千问 API 客户端封装。"""
def __init__(self, model: str = "qwen-plus", temperature: float = 0.7):
self.client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
self.model = model
self.temperature = temperature
def chat(self, user_msg: str, system_msg: str = "你是一个助手。") -> str:
"""发送单轮对话请求,返回文字响应。"""
resp = self.client.chat.completions.create(
model=self.model,
temperature=self.temperature,
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": user_msg},
],
)
return resp.choices[0].message.content
def stream_chat(self, user_msg: str, system_msg: str = "你是一个助手。"):
"""流式输出,返回文字生成器。"""
completion = self.client.chat.completions.create(
model=self.model,
temperature=self.temperature,
stream=True,
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": user_msg},
],
)
for chunk in completion:
if chunk.choices and chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
# 使用示例
llm = QwenClient(model="qwen-plus")
print(llm.chat("什么是向量数据库?"))
# 流式使用
for token in llm.stream_chat("写一首关于编程的短诗"):
print(token, end="", flush=True)八、常见错误与排查
| 错误信息 | 原因 | 解决方案 |
|---|---|---|
| AuthenticationError | API Key 无效或未配置 | 检查 .env 文件中的 DASHSCOPE_API_KEY |
| RateLimitError | 请求频率超限 | 添加 time.sleep(1) 或减少并发请求 |
| InvalidRequestError: max_tokens | max_tokens 设置超过模型限制 | 降低 max_tokens 值 |
| 回答为空 | delta.content 为 None | 加 if delta.content: 判断 |
| 输出乱码 | 编码问题 | 确保文件保存为 UTF-8 格式 |
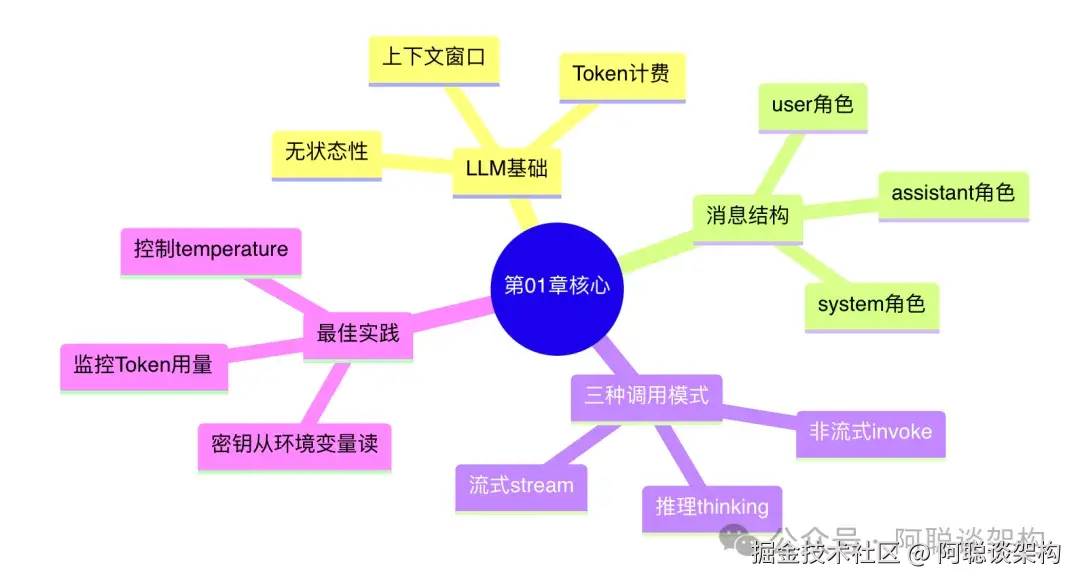
九、本章核心要点
📌 下一章预告:掌握了 API 调用之后,你会发现"如何写出好的 Prompt"才是真正决定 AI 输出质量的关键。第02章我们深入 Prompt 工程,学习模板、Few-Shot 和思维链技术。
作者:阿聪谈架构
公众号:阿聪谈架构(分享后端架构 / AI / Java 技术文章)
相关代码关注公众号:【阿聪谈架构】 回复:AI专栏代码