本章涵盖以下内容:
- 对超过 LLM 上下文窗口的大型文档进行摘要
- 跨多份文档进行摘要
在第 1 章中,我们探讨了三类主要的 LLM 应用:摘要引擎、聊天机器人和 AI 智能体。在本章中,你将开始使用 LangChain 构建实用的摘要链,尤其会重点使用 LangChain Expression Language(LCEL) 来处理各种真实场景。所谓链(chain) ,就是一系列相互连接的操作序列:前一步的输出会成为后一步的输入------这种形式非常适合自动化诸如摘要这样的任务。这部分内容也将为下一章中构建一个更高级的摘要引擎打下基础。
摘要引擎对于自动化处理海量文档摘要至关重要。即使借助 ChatGPT 之类的工具,如果完全手工完成这类工作,也会既不现实、又成本高昂。以摘要引擎作为 LLM 应用开发的切入点,是一种非常务实的做法:它不仅能为后续更复杂的项目提供坚实基础,也能很好地展示 LangChain 的能力,而这些能力我们将在后续章节中继续深入。
在正式开始构建之前,我们会先看几种不同的摘要技术。它们分别适用于特定场景,包括大型文档、内容汇总,以及结构化数据处理等。你在第 2 章中已经通过 PromptTemplate 练习过对小文档做摘要,因此这里我们将跳过那部分,直接聚焦更复杂的示例。
3.1 对大于上下文窗口的文档进行摘要
正如第 1 章提到的,每个 LLM 都有一个提示大小上限,也就是所谓的上下文窗口(context window) 。虽然主流 LLM 的上下文窗口一直在增大,但你仍然可能遇到这样的情况:某份文档的长度超过了你所选模型的 token 限制。在这种情况下,你可以使用 MapReduce 方法,如图 3.1 所示。
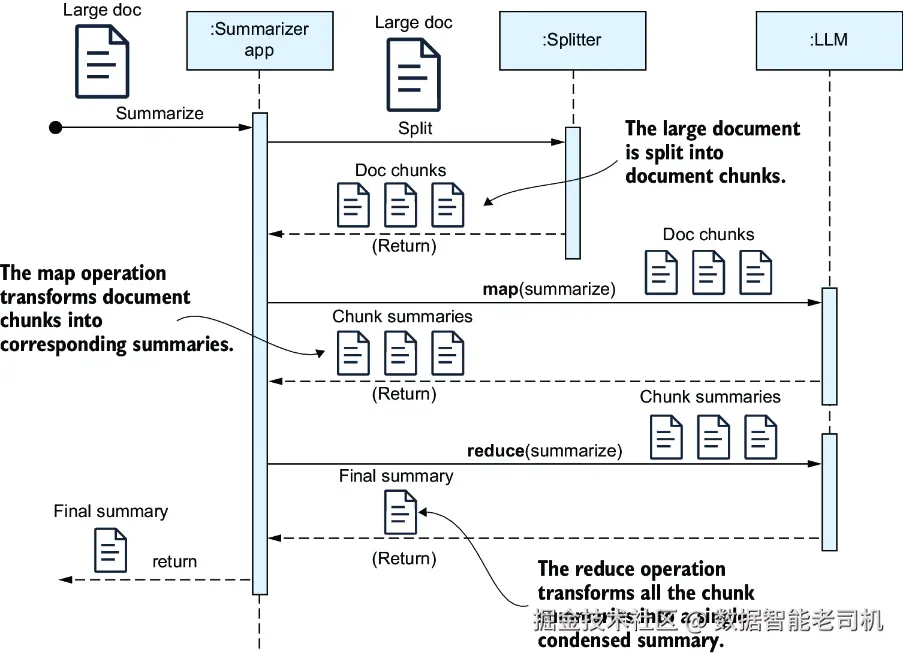
图 3.1 对超过 LLM 上下文窗口的文档做摘要时,可以先将文档切分为较小的块,对每个块分别生成摘要,然后再对这些块摘要的汇总结果进行再次摘要。
定义 LLM 的上下文窗口,是指在单次提示中能够提供给语言模型的最大文本量,其中既包括指令,也包括上下文。不同 LLM 对上下文窗口支持的 token 上限不同,而一个 token 大致可以近似看作一个单词。比如,GPT-3.5 最多可处理 16,000 个 token,GPT-4 和 Claude 3 支持最多 100,000 个 token,而 GPT-5、Gemini 等较新的模型则可以处理超过 100 万个 token。
当文档长度超过 LLM 的上下文窗口时,一种常见策略是:先把文本拆成若干可管理的块(chunks),为每个块分别生成摘要,然后再基于这些中间摘要生成最终摘要。首先,你需要借助一个分词器(tokenizer) 把文本切分成块。分词器会读取文本并将其拆分为 token,token 是文本的最小单位,通常是单词或单词片段。完成分词后,再把这些 token 按照指定大小分组成若干块。这样,你就能控制 LLM 每次处理内容的规模,并确保 token 数量始终落在模型提示上限之内。这里我会演示如何使用 TokenTextSplitter。它属于 tiktoken 包------这是 OpenAI 开发的一个分词器。
先打开终端,在本章代码所在目录下新建一个名为 ch03 的文件夹。然后创建并激活一个虚拟环境:
makefile
C:\Github\building-llm-applications>md ch03
C:\Github\building-llm-applications>cd ch03
C:\Github\building-llm-applications\ch03>python -m venv env_ch03
C:\Github\building-llm-applications\ch03>.\env_ch03\Scripts\activate
(env_ch03) C:\Github\building-llm-applications\ch03>接着安装所需包------tiktoken、notebook 和 langchain。如果你已经从 GitHub(https://mng.bz/WwvW)克隆了仓库,或者从 Manning 网站下载了代码 zip 包,那么可以直接执行:
makefile
C:\Github\building-llm-applications\ch03>pip install -r requirements.txt安装完成后,启动 Jupyter Notebook:
scss
(env_ch03) C:\Github\Building-llm-applications\ch03>jupyter notebook现在,打开或创建一个 notebook,并将其命名为 03-summarization_examples.ipynb。最后保存该 notebook。
3.1.1 将文本切分为 Document 对象
我们来用电子书文本文件 Moby-Dick.txt 对《白鲸记》(Moby Dick)进行摘要,这个文件可以从 Project Gutenberg 网站(www.gutenberg.org)下载。你可以在我 GitHub 页面中本章的子目录下找到 Moby-Dick.txt 文件(https://mng.bz/DwyV)。把这个文件放到你的 ch03 文件夹中,然后将其内容加载进一个变量:
csharp
with open("./Moby-Dick.txt", 'r', encoding='utf-8') as f:
moby_dick_book = f.read()注意 请记住,在完整的《白鲸记》文本上运行这些代码可能会比较花钱。这里提供的 Moby-Dick.txt 是一个较短版本,只包含五个章节,大约 18,000 个 token。用这个版本跑几次代码通常花费不高。不过,如果你计划进行很多次测试,可能还需要进一步缩小文件,以节省成本。每当你执行一个包含 LLMChain 模块的链时,都会产生费用。若预算允许,你也可以使用全本版本,文件名为 Moby-Dick_ORIGINAL_EXPENSIVE.txt。整本《白鲸记》大约有 300,000 个单词,也就是约 350,000 个 token。若使用 GPT-5,按每百万 token 1.25 美元计算,处理整本书的成本大约是 0.37 美元。多次运行的话,成本会逐渐累计。如果改用 GPT-5-nano,其价格是每百万 token 0.05 美元,那么成本就会降到大约 0.015 美元,便宜很多。
关于分块策略------例如按大小分块、按内容结构分块------我会在第 8 章详细讲解。这里我们先把文本切成每块大约 3,000 个 token,以模拟一个比我们即将使用的 GPT-5-nano 模型更短的上下文窗口。
3.1.2 Split(切分)
开始切分之前,需要先做一点准备工作。首先导入必要的库:
javascript
from langchain_openai import ChatOpenAI
from langchain_text_splitters import TokenTextSplitter
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnableParallel
import getpass然后通过 getpass 函数获取你的 OpenAI API key:
ini
OPENAI_API_KEY = getpass.getpass('Enter your OPENAI_API_KEY')系统会提示你输入 OPENAI_API_KEY。之后,在 notebook 的新单元格中实例化 OpenAI 模型:
ini
llm = ChatOpenAI(openai_api_key=OPENAI_API_KEY,model_name="gpt-5-nano")现在你已经可以构建第一条链了,它负责把文档切分成指定大小的块。在本章中,你会先接触 LCEL 的基础用法,下一章会更详细地展开:
less
text_chunks_chain = (
RunnableLambda(lambda x:
[
{
'chunk': text_chunk,
}
for text_chunk in
TokenTextSplitter(chunk_size=3000,
↪chunk_overlap=100).split_text(x)
]
)
)注意 LangChain 的链由实现了 Runnable 接口的组件构成。Runnable 是一个抽象 Python 类,定义了组件如何接收输入、处理输入并返回输出。任何实现了 Runnable 的类都可以成为链的一部分。RunnableLambda 允许你把任意 Python 可调用对象(callable)包装成一个 Runnable,从而方便地把自定义函数纳入 LangChain 链中。它和 Python 里的 lambda 表达式有些相似:你可以基于传入参数运行一段代码,并可选地返回输出,而不必专门写一个完整函数。借助 RunnableLambda,你无需单独定义一个类来实现 Runnable 接口,就能快速创建链中的组件。在这个例子中,被 RunnableLambda 包裹的代码通过参数 x 接收输入文本字符串,再把它传给 split_text() 函数,由后者完成文本切块。
3.1.3 Map
下一步是设置 map 链。它会针对文档的每一个块运行一个摘要提示,确保文本中的每一部分都会先被独立处理,之后再统一合并:
ini
summarize_chunk_prompt_template = """
Write a concise summary of the following text, and include the main details.
Text: {chunk}
"""
summarize_chunk_prompt =
↪PromptTemplate.from_template(summarize_chunk_prompt_template)
summarize_chunk_chain = summarize_chunk_prompt | llm
summarize_map_chain = (
RunnableParallel (
{
'summary': summarize_chunk_chain | StrOutputParser()
}
)
)在这段代码中,使用了管道操作符 | 来连接各个组件,让前一个对象的输出直接成为下一个对象的输入。例如,summarize_chunk_prompt 被"管道"到 llm 中,也就是说生成好的提示会直接发给模型。同样,模型的输出又被传入 StrOutputParser(),后者会把模型响应转换成干净的文本字符串。
注意 在这条链中,我使用了 RunnableParallel。它和 RunnableLambda 有点相似,但它作用于一个序列,并对其中每个元素进行并行处理。在这里,我们会把文本块序列输入给 summarize_map_chain,然后每个块都会由内部的 summarize_map_chain 并行完成摘要。
MapReduce
MapReduce 是一种用于处理大规模数据集的编程模型,分为两个步骤。首先是 map 操作:它把数据拆分成较小的子集,并用同一个函数分别对每个子集独立处理。这一步通常会返回一组结果,并按某个键(key)归类。接着是 reduce 操作:它把每个键对应的结果聚合成一个单一输出。最终产物是一组键值对,其中键来自 map 步骤,而值则是 reduce 步骤对 map 结果聚合后的输出。
3.1.4 Reduce
接下来设置 reduce 链,它负责对每个文档块的摘要再做一次摘要。它与 map 链的构造过程类似,但需要多做一些配置。先定义提示模板:
ini
summarize_summaries_prompt_template = """
Write a concise summary of the following text,
which joins several summaries, and include the main details.
Text: {summaries}
"""
summarize_summaries_prompt =
↪PromptTemplate.from_template(summarize_summaries_prompt_template)接着可以配置 reduce 链:
less
summarize_reduce_chain = (
RunnableLambda(lambda x:
{
'summaries': '\n'.join([i['summary'] for i in x]),
})
| summarize_summaries_prompt
| llm
| StrOutputParser()
)这条 reduce 链中包含了一个 lambda 函数,它会把 map 链生成的多个摘要合并成一个字符串。然后这个字符串会被送入 summarize_summaries_prompt 提示中,再由 LLM 对合并后的内容生成最终摘要。
3.1.5 组合 MapReduce 链
最后,我们把文档切分链、map 链和 reduce 链组合成一条完整的 MapReduce 链:
ini
map_reduce_chain = (
text_chunks_chain #1
| summarize_map_chain.map() #2
| summarize_reduce_chain #3
)
#1 Split chain
#2 Map chain
#3 Reduce chain这套配置会高效地把输入文档切分为块,对每个块分别做摘要,再把这些摘要汇总为最终摘要。其中,summarize_map_chain 上的 .map() 调用至关重要,它使得这些块能够被并行处理。
3.1.6 执行 MapReduce
至此一切都已准备就绪。你可以通过下面这条命令启动对大文档的 MapReduce 摘要(如果你使用的是 OpenAI 免费额度,这里可能会因为 429 限流报错):
ini
summary = map_reduce_chain.invoke(moby_dick_book)如果执行 print(summary),你会看到类似下面的输出:
vbnet
The introduction to the Project Gutenberg eBook of "Moby-Dick; or The Whale" by Herman Melville outlines the book's availability and updates, with the first eBook release in June 2001 and the latest in August 2021. The narrative begins with Ishmael, the narrator, who seeks solace at sea to escape his melancholic state, showcasing the ocean's allure compared to city life. He reflects on his reasons for joining a whaling voyage, driven by a fascination with whales and a thirst for adventure. After arriving in New Bedford, Ishmael faces challenges finding lodging, ultimately settling at "The Spouter Inn," where he encounters a chaotic environment and a mysterious harpooneer named Queequeg.
As Ishmael shares a bed with Queequeg, whom he initially fears to be a cannibal, he gradually overcomes his apprehensions. The morning after their first night together highlights their strange yet developing bond, as Ishmael observes Queequeg's unique customs and politeness, emphasizing themes of fate, choice, and the allure of the unknown in the whaling industry.警告 正如前面提到的,运行 map_reduce_chain 会产生费用;你想摘要的文本越长,成本就越高。因此,如果你想控制开销,建议进一步缩短输入文本(在这里就是 Moby-Dick.txt 电子书文件)。此外,也请确保你的 OpenAI API 账户中仍有正的余额,否则可能出现如下错误:RateLimitError: Error code: 429 - {'error': {'message': 'You exceeded your current quota, please check your plan and billing details [...].' 如有必要,请登录 OpenAI API 页面,进入 Settings > Billing,并至少充值 5 美元额度。
下面我们进入下一个用例:跨文档摘要。在这个场景中,目标不再是处理一份很长的文本,而是综合多个来源中的信息。
3.2 跨文档摘要
你可以很方便地学习如何在多个数据源之间做摘要,例如 Wikipedia 页面,或者本地文件中的 Microsoft Word、PDF 和 TXT 文本内容。这个过程如图 3.2 所示,与上一节中的 MapReduce 技术非常相似。
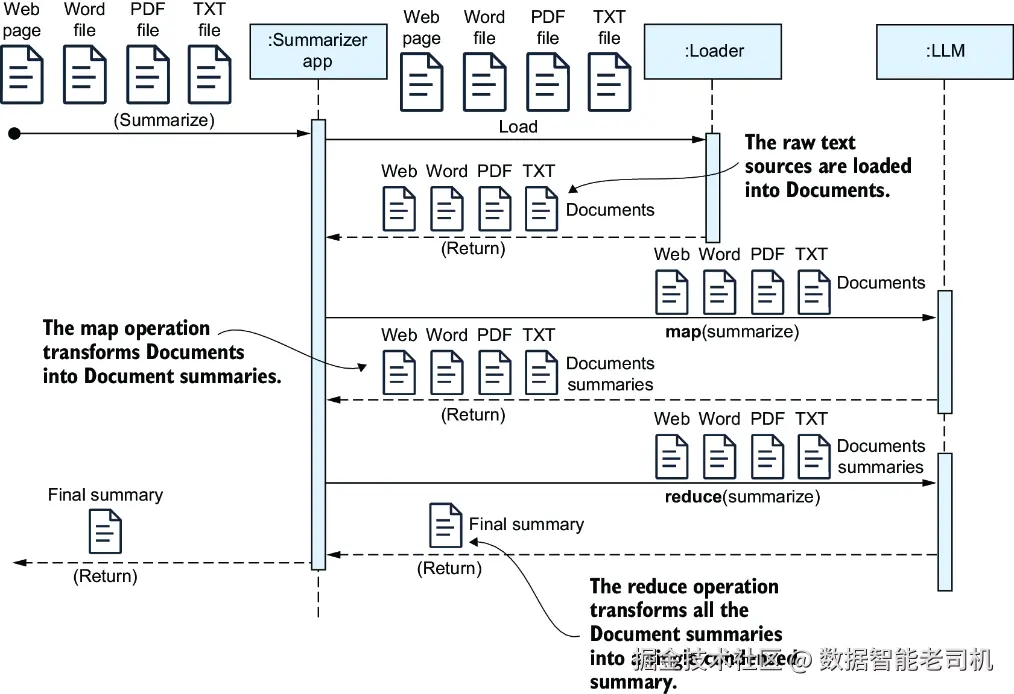
图 3.2 使用前面介绍的 MapReduce 技术进行跨文档摘要。在这种方法中,每个文档块都会经过一次 map 操作生成摘要,然后这些单独摘要会通过 reduce 操作进一步压缩成一个总摘要。
在图 3.2 的时序图中,每个原始文本源的内容都会被加载到一个对应的 Document 实例中。在 map 操作阶段,这些 Document 对象被转换为各自独立的摘要;随后在 reduce 操作阶段,这些单独摘要再被合并为一个总体摘要。
接下来,我还要介绍另一种叫作 refine 的技术,如图 3.3 所示。使用这种方法时,最终摘要是通过一种逐步迭代的方式构建出来的:每一步都会把"当前最终摘要"与"某一个文档块"的内容结合起来重新摘要。这个过程持续进行,直到所有文档块都处理完为止,最终形成完整摘要。
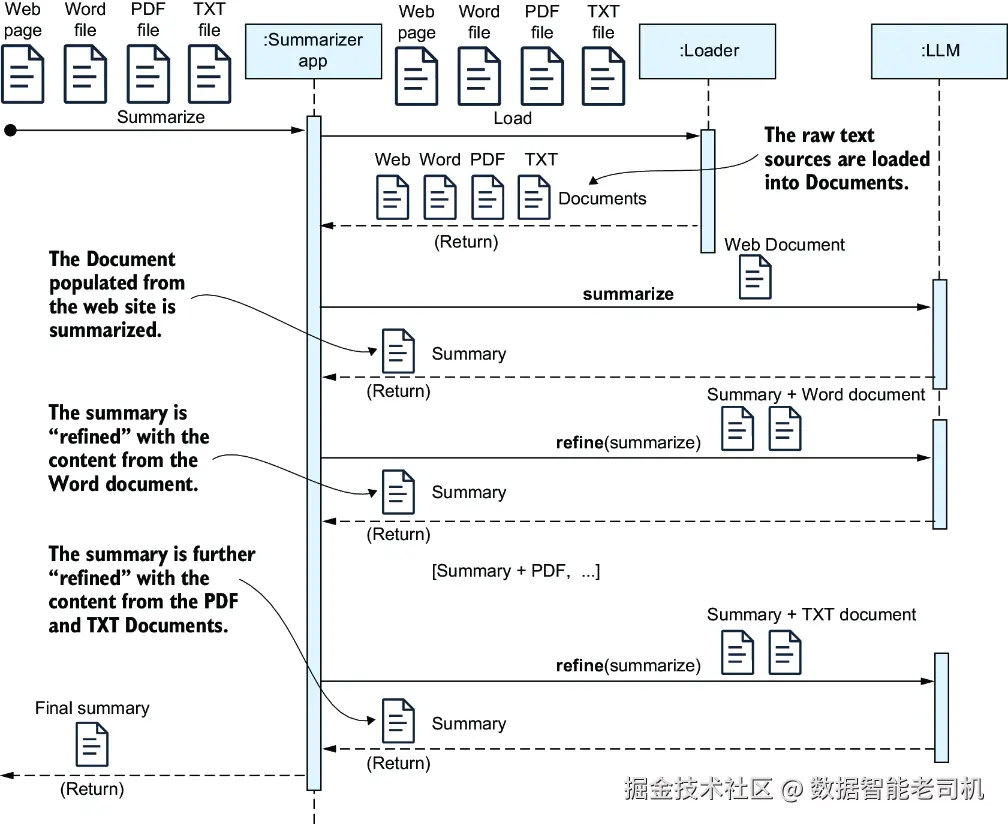
图 3.3 使用 refine 技术进行跨文档摘要
在这种方法中,你是通过不断"精炼(refine)"已有摘要来逐步构建最终结果的。每一份文档都会与当前摘要草稿一起发送给 LLM 做摘要。这个过程会持续到所有文档都处理完毕,从而生成最终摘要。MapReduce 非常适合对大规模文本进行摘要,尤其是在为了控制处理负载而可以接受一定内容损失的情况下。相比之下,refine 技术更适合这样一种需求:你希望最终摘要尽可能完整地保留每一部分内容的核心信息。
3.2.1 创建 Document 对象列表
在对单个大文档做摘要时,你通常会先把它切分成较小的块,并将每个块都视作一个单独文档。而在这里,我们一开始就面对的是一组现成文档,因此不需要再进行切分。如何创建每个 Document 对象,取决于文本来源。我将演示如何汇总来自四种不同来源的内容:一页 Wikipedia 页面,以及一个本地文件夹中的多种文件格式(TXT、DOCX、PDF)。这些内容都与意大利南部 Cilento 海岸、公元前约 500 年的一处希腊殖民地 Paestum(帕埃斯图姆) 有关。你将针对不同数据源使用合适的 DocumentLoader,从第 1 章 1.3 节中介绍过的 LangChain Document 对象模型里的众多选项中选择。
3.2.2 Wikipedia 内容
先从 Wikipedia 内容开始。虽然你也可以使用 WebBaseLoader 从网页中构造文档,但其实针对特定网站,LangChain 还提供了专门定制的 loader,例如面向 Internet Movie Script Database(IMSDb)网站的 IMSDbLoader、面向 AZLyrics 网站的 AZLyricsLoader,以及面向 Wikipedia 网站的 WikipediaLoader。
如果你已经按照 3.1 节开头的说明安装了依赖包,那么与这些 loader 相关的包应该也已经装好了,包括 docx2txt(供 Docx2txtLoader 读取 Word 文件使用)和 pypdf(供 PyPDFLoader 读取 PDF 使用)。现在你就可以导入 Paestum 的 Wikipedia 页面内容:
ini
from langchain.document_loaders import WikipediaLoader
wikipedia_loader = WikipediaLoader(query="Paestum", load_max_docs=2)
wikipedia_docs = wikipedia_loader.load()注意 WikipediaLoader 可能还会加载所请求词条中引用的其他 Wikipedia 链接对应的内容。例如,Paestum 词条中引用了 Paestum 国家考古博物馆、Lucania 地区、Lucanians 以及 Hera 和 Athena 神庙,因此会额外加载一些相关内容。也正因如此,它返回的是一个 Document 列表,而不是单个 Document 对象。为了节省摘要成本,我这里把返回文档的最大数量设为了 2,不过你也可以根据需要自行调整。
3.2.3 基于文件的内容
首先,从 GitHub 下载或拉取 Paestum 文件夹,并把它放到本地 ch03 目录中(如果你没有克隆整个仓库的话)。ch03 目录下的 Paestum 子文件夹包含三个文件:
Paestum-Britannica.docx------ 内容来自 Encyclopedia Britannica 网站。PaestumRevisited.pdf------ 摘自一篇提交给斯德哥尔摩大学的硕士论文 Paestum Revisited 。这里截取的版本只有四页,但你也可以使用同一文件夹中的完整文档PaestumRevisited-StocholmsUniversitet.pdf。Paestum-Encyclopedia.txt------ 内容取自 Encyclopedia.com。
下面是把这些文件加载成对应文档的过程:
ini
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import TextLoader
word_loader = Docx2txtLoader("Paestum/Paestum-Britannica.docx")
word_docs = word_loader.load()
pdf_loader = PyPDFLoader("Paestum/PaestumRevisited.pdf")
pdf_docs = pdf_loader.load()
txt_loader = TextLoader("Paestum/Paestum-Encyclopedia.txt")
txt_docs = txt_loader.load()这些文档变量(word_docs、pdf_docs、txt_docs)都用了复数形式,这是因为 loader 总是返回一个文档列表,即使列表里实际上只有一个元素。
注意 你可能已经注意到:这里对 Paestum-Encyclopedia.txt 是直接通过 TextLoader 创建 Document 对象数组的,那么为什么之前的 Moby-Dick.txt 却是用 Python 文件读取器直接读取呢?原因在于,前者的目的是按特定 token 数切分内容,以适配 LLM 提示长度,因此需要手动为每个切块创建 Document 对象。
3.2.4 创建 Document 列表
现在你可以把来自不同来源的所有文档合并成一个统一的 Document 列表。使用下面这段代码:
ini
all_docs = wikipedia_docs + word_docs + pdf_docs + txt_docs到这里,所有内容都已经汇总完成,你也准备好使用 refine 技术来生成摘要了。下一步就是创建一条链,用来生成最终摘要。
Document loaders
除了针对特定数据源的文档加载器之外,我也建议你去探索一下 UnstructuredLoader。它能够导入多种文件类型的内容,包括 Word、PDF、TXT 等等。
另一个可选方案是 DirectoryLoader,它内部使用的就是 UnstructuredLoader。借助它,你可以一次性加载同一个文件夹中不同格式文件的内容。
作为练习,我建议你尝试使用 UnstructuredLoader 或 DirectoryLoader,重新创建来自 Paestum Word、PDF 和 TXT 文件的这些文档。如果你打算这样做,需要先安装相关包,并参阅 LangChain 官网文档:
arduino
pip install "unstructured[all-docs]"LangChain 框架提供了大量 loader,可用于从不同数据源提取内容。我非常建议你去浏览这份列表,并尝试你感兴趣的那些 loader:https://mng.bz/EwmR。
3.2.5 逐步精炼最终摘要
现在一切都已准备就绪,你可以创建一条链,逐步生成最终摘要。先导入必要模块:
javascript
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
import getpass然后像之前一样获取 OPENAI_API_KEY,并初始化 LLM 模型:
ini
OPENAI_API_KEY = getpass.getpass('Enter your OPENAI_API_KEY')
llm = ChatOpenAI(openai_api_key=OPENAI_API_KEY,model_name="gpt-5-nano")现在定义用于摘要单篇文档的链及其对应提示:
ini
doc_summary_template = """Write a concise summary of the following text:
{text}
DOC SUMMARY:"""
doc_summary_prompt = PromptTemplate.from_template(doc_summary_template)
doc_summary_chain = doc_summary_prompt | llm接着,设置 refine 链,用于将当前摘要与新增文档内容反复组合并迭代精炼:
ini
refine_summary_template = """
You must produce a final summary from the current refined summary
which has been generated so far and from the content of an
additional document.
This is the current refined summary generated so far:
{current_refined_summary}
This is the content of the additional document: {text}
Only use the content of the additional document if it is useful,
otherwise return the current full summary as it is."""
refine_summary_prompt =
↪PromptTemplate.from_template(refine_summary_template)
refine_chain = refine_summary_prompt | llm | StrOutputParser()最后,定义一个函数:它会遍历每份文档,先用 doc_summary_chain 做摘要,再用 refine_chain 对总体摘要不断精炼:
ini
def refine_summary(docs):
intermediate_steps = []
current_refined_summary = ''
for doc in docs:
intermediate_step = \
{"current_refined_summary": current_refined_summary,
"text": doc.page_content}
intermediate_steps.append(intermediate_step)
current_refined_summary = refine_chain.invoke(intermediate_step)
return {"final_summary": current_refined_summary,
"intermediate_steps": intermediate_steps}现在你可以通过对准备好的文档列表调用 refine_summary() 来启动摘要流程:
ini
full_summary = refine_summary(all_docs)打印 full_summary 对象时,你会看到:最终摘要保存在 final_summary 下,而中间步骤则保存在 intermediate_steps 下。虽然为了便于展示,这里对结果步骤做了省略,但我还是建议你亲自观察摘要在每个阶段是如何演化的:
scss
print(full_summary )下面是一段输出示例:
vbnet
{'final_summary': "**Final Summary:**\n\nPaestum, an ancient Greek city located on the coast of the Tyrrhenian Sea in Magna Graecia, was established around 600 BC by settlers from Sybaris and originally named Poseidonia. The city flourished as a Greek settlement [... SHORTENED ...] those interested in ancient Greek culture and architecture.", 'intermediate_steps': [{'current_ refined_summary': '', 'text': 'Paestum ( PEST-əm, US also PEE-stəm ) was a major ancient Greek city on the coast of the Tyrrhenian Sea, in Magna Graecia. The ruins of Paestum are famous for their three ancient Greek temples in the Doric order dating from about 550 to 450 BC that are
in an excellent state of preservation. The city walls and amphitheatre
[... SHORTENED ...]我们已经介绍了几种摘要技术,现在不妨稍微停一下,回顾一下已经学到的内容。这正是一个很好的节点,让我们退一步思考:这些方法之间彼此是什么关系,在什么场景下各自最有效。
3.3 摘要流程图
为了结束本章,我加入了一张流程图,帮助你根据具体需求选择最合适的摘要技术,如图 3.4 所示。这里的第一个关键决策点是:你要摘要的是单份文档 还是多份文档 。如果只有一份文档,并且它能放进上下文窗口里,那么你可以直接把整份文档"塞进(stuff)"一个提示中完成摘要。如果放不下,就使用 MapReduce 方法。对于多份文档,如果它们全部都能放进上下文窗口里,也同样可以一次性塞进一个提示中;如果放不下,那么当文档数量很多时,使用 MapReduce ;如果你希望确保每份文档的核心内容都被纳入最终摘要中,那么就使用 refine 技术。
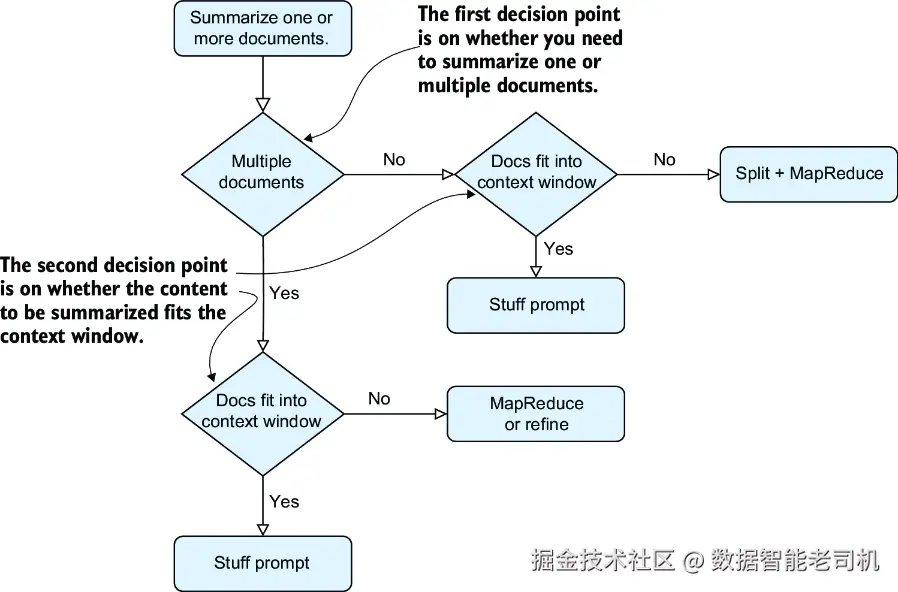
图 3.4 摘要流程图。该流程图帮助你根据是否需要摘要多份彼此独立的文档,以及输入文本是否能放进上下文窗口,来选择合适的摘要方案。
小结
- 文本摘要就是把文档压缩成更短的版本,同时尽可能保留关键信息。它适用于高管报告、文章摘要和内容预览等场景。所采用的方法会随文档数量和长度不同而变化。对于单篇短文档,可以直接通过提示完成摘要;对于中等长度文本,可借助链式处理;对于超出上下文窗口的大型语料,则适合使用 MapReduce 或 Refine 策略。
- LangChain 的
Document对象会把原始文本和元数据(来源、页码、时间戳等)打包在一起,从而在整个处理流水线中保留数据来源信息。 - MapReduce 摘要会在 map 阶段对各个文本块独立且并行地处理。reduce 阶段再把这些局部摘要合并成最终输出。这种方法适合处理超出上下文窗口限制的文档,例如上百页的报告。当你更看重并行处理速度,而不是保留全部上下文连接时,MapReduce 是合适选择。
- Refine 摘要技术则是通过顺序迭代的方式,不断把新文档纳入现有摘要中。每一步都会同时看到"当前摘要"和"下一个文档块"。
- MapReduce 用一定程度的摘要完整性,换取了并行处理速度和更低 token 成本。Refine 则保留了更多上下文,但因为是顺序处理,所以延迟更高、总 token 消耗也更大。
- 你可以通过
PromptTemplate.from_template(template_string)来创建提示模板。使用管道操作符把组件串起来,例如summarize_chunk_chain = summarize_chunk_prompt | llm,就能让提示输出直接送入模型。 - 要构建用于并行处理的 map 链,你需要先定义
summarize_map_chain来处理每个文本块,然后通过.map()把它同时应用到所有块上,并借助RunnableParallel实现并行执行。