在做 Android 性能优化或卡顿分析 时,经常会遇到一些问题:
- 为什么 UI 会掉帧?
- GPU 为什么会成为瓶颈?
- 为什么有时 SurfaceFlinger 会导致延迟?
这些问题的根源,往往在于 Android 渲染 pipeline 的理解不完整。
Android 并不是简单地把 UI 直接画到屏幕上,而是通过一套 Buffer + Layer + 合成机制完成显示。
简单来说:
css
App 负责生产图像
SurfaceFlinger 负责合成图像
Display 负责扫描显示下面我们从 draw → GPU → 合成 → 屏幕显示 的完整链路来分析。
一、从 draw 到 GPU 渲染
在 Android 中,View 的绘制并不会直接产生屏幕像素,而是先记录绘制指令。
当系统触发一帧渲染时,UI 线程会执行:
scss
ViewRootImpl.performTraversals()最终调用:
css
View.draw(Canvas)但 draw() 做的事情并不是直接画图,而是:
scss
draw()
│
▼
RecordingCanvas
│
▼
RenderNode
│
▼
DisplayList也就是说:
draw 阶段只是把绘制操作记录成 DisplayList(绘制指令列表) 。
例如:
drawRect
drawBitmap
drawText这些命令会被保存下来,随后交给 RenderThread 执行真正的 GPU 渲染。
GPU 渲染流程
RenderThread 会读取 DisplayList,然后调用 OpenGL/Vulkan 进行 GPU 渲染:
UI Thread
│
▼
DisplayList
RenderThread
│
▼
OpenGL / Vulkan
│
▼
GPU Pipeline
│
▼
GraphicBuffer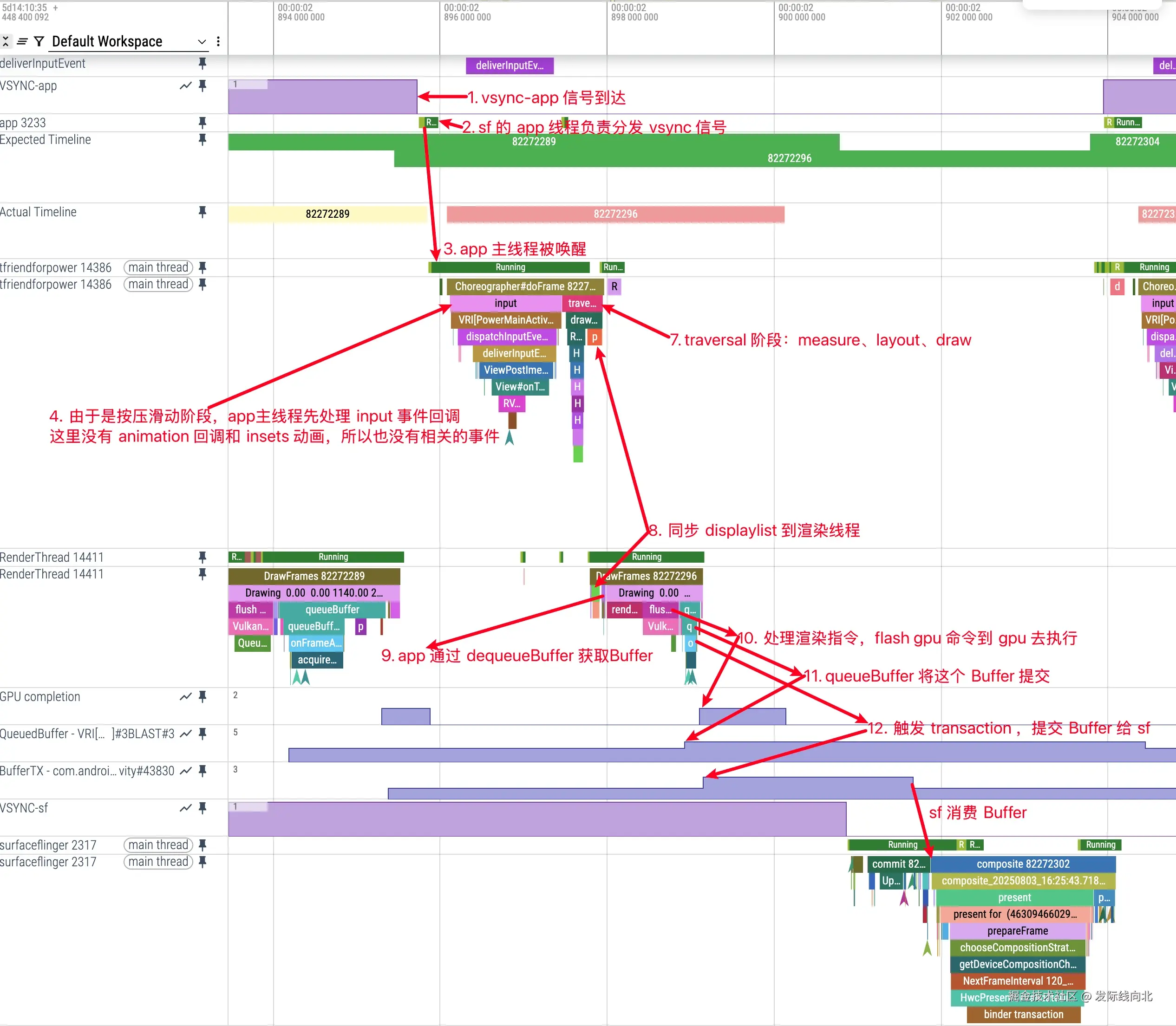
GPU 渲染完成后,会把结果写入:
GraphicBuffer这是一块可以被 GPU、SurfaceFlinger、Display 硬件共享访问的图像内存。
二、BufferQueue 与 SurfaceFlinger 合成
在 Android 中,每一个 Surface 都拥有一个 BufferQueue。
结构如下:
Producer
Consumer在 App 渲染流程中:
ini
Producer = RenderThread
Consumer = SurfaceFlingerRenderThread 在 GPU 渲染完成后会执行:
scss
eglSwapBuffers()但这里有一个容易误解的地方:
SwapBuffers 并不是传统意义的前后 buffer 交换。
真实流程是:
scss
dequeueBuffer()
│
GPU 渲染
│
eglSwapBuffers()
│
queueBuffer()也就是:
ini
SwapBuffers = queueBuffer即:
把渲染完成的 buffer 提交给 BufferQueue。
SurfaceFlinger 的作用
系统中通常存在多个 Surface,例如:
sql
Wallpaper
App Window
StatusBar
NavigationBarSurfaceFlinger 会从每个 Surface 的 BufferQueue 中获取 buffer:
WallpaperBuffer
AppBuffer
StatusBarBuffer然后进行 Layer 合成。
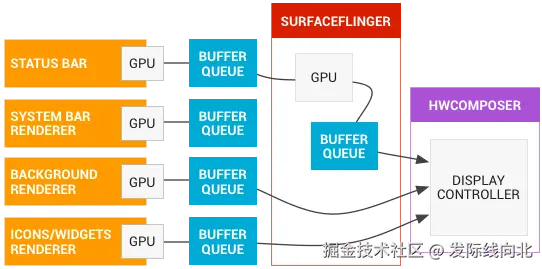
SurfaceFlinger 有两种合成方式:
1 GPU 合成(Client Composition)
arduino
多个Surface buffer
│
▼
SurfaceFlinger GPU
│
▼
新的 DisplayBuffer
│
▼
Display这种情况下:
arduino
Display 使用的是新的 buffer2 HWC 硬件合成(Device Composition)
Android 更倾向于使用 Hardware Composer。
流程:
css
SurfaceFlinger
│
▼
Hardware Composer
│
▼
Display Controller显示硬件会直接读取多个 buffer:
Plane0 → WallpaperBuffer
Plane1 → AppBuffer
Plane2 → StatusBarBuffer并在扫描屏幕时 硬件实时合成。
HWC 的价值不是减少内存占用,而是减少 framebuffer 生成,从而降低内存带宽和 GPU 负载。
三、为什么需要 Triple Buffer
很多人第一次了解 Android 图形系统时会问:
为什么需要 3 个 buffer?双 buffer 不就够了吗?
原因在于 渲染 pipeline 的并行性。
Android 渲染涉及三个阶段:
css
App / GPU 渲染
SurfaceFlinger 合成
Display 显示如果只有双 buffer:
css
BufferA → Display
BufferB → GPU当 GPU 渲染完成时,可能会遇到:
css
Display 还没读完 BufferA于是 GPU 只能等待:
pipeline stall而 Triple Buffer 可以形成流水线:
css
BufferA → Display
BufferB → SurfaceFlinger
BufferC → GPU时间线示意:
less
Display : |---A---|---B---|
SF : |---B---|---C---|
GPU : |---C---|---A---|
这样三个阶段可以并行执行:
css
GPU 渲染
SurfaceFlinger 合成
Display 扫描从而避免卡顿。
总结
Android 渲染并不是简单的 UI 绘制,而是一条完整的 图形处理流水线:
scss
draw()
↓
DisplayList
↓
RenderThread
↓
GPU 渲染
↓
GraphicBuffer
↓
BufferQueue
↓
SurfaceFlinger
↓
HWC / GPU 合成
↓
Display Controller
↓
Screen在性能分析中,这条链路的每个环节都可能成为瓶颈,例如:
- UI 线程绘制过慢
- GPU 渲染压力过大
- BufferQueue 堵塞
- SurfaceFlinger 合成压力
- Display 同步导致的 pipeline stall
理解 Android 渲染机制,可以帮助我们更准确地定位:
掉帧
卡顿
SwapBuffers 阻塞
GPU 瓶颈从而进行更有效的性能优化。
声明
文中部分图片来源于网络,仅用于技术学习与交流。
如有侵权,请联系删除。