RAG 最适合解决的问题,不是"模型不会说话",而是"模型缺少当前任务需要的背景知识"。
如果用户的问题没问清楚,优先靠 Prompt Engineering;如果模型缺少外部资料,优先考虑 RAG;如果模型本身没有某种能力,或者希望它长期稳定地学会某种业务行为,才考虑微调。
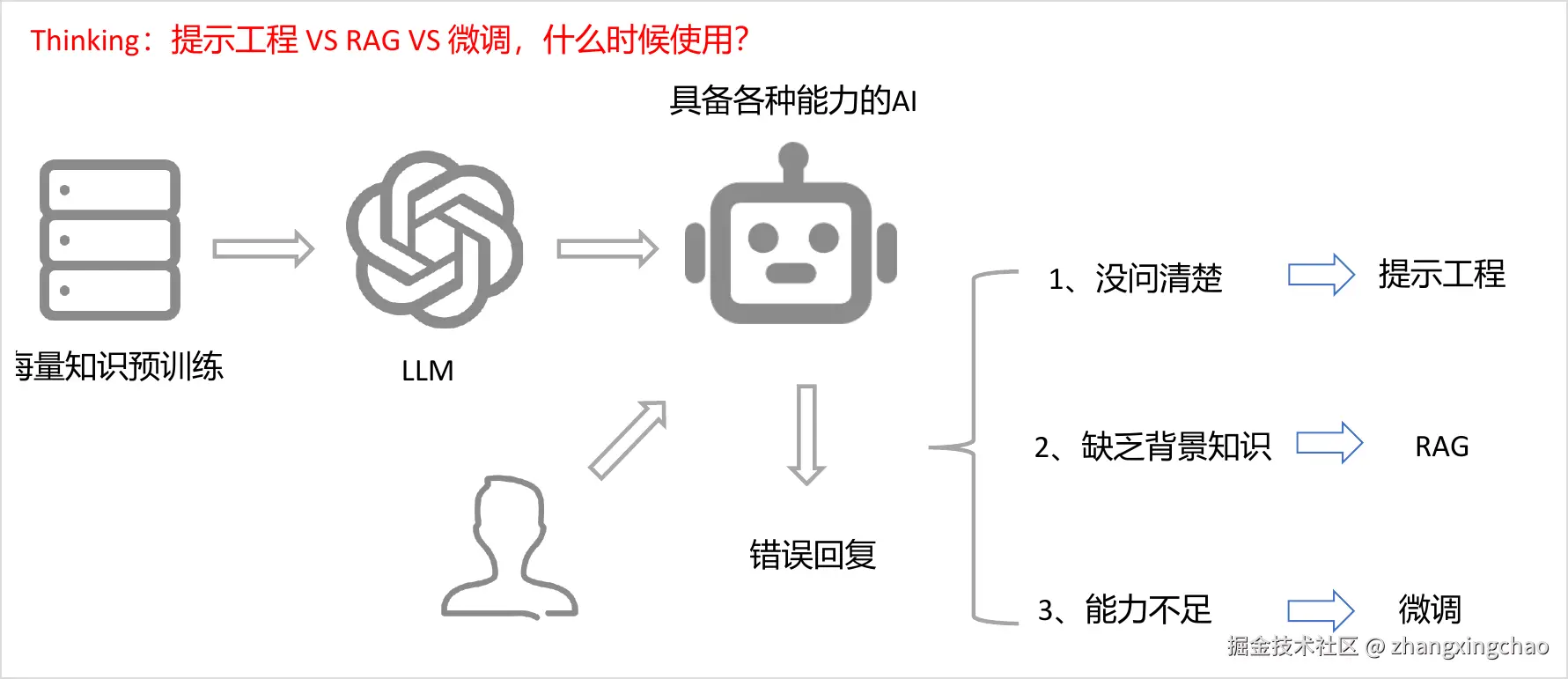
可以先记住这一条线:
text
原始文档
-> 切分成 chunks
-> 使用 Embedding 模型转成向量
-> 存入向量数据库
-> 用户提问时检索相关 chunks
-> 必要时 rerank 重排序
-> 把问题和检索结果一起交给 LLM
-> 生成最终回答也就是说,RAG 不是让大模型"凭空变聪明",而是在回答之前,先把最相关的资料找出来,塞进上下文里。
RAG 到底是什么
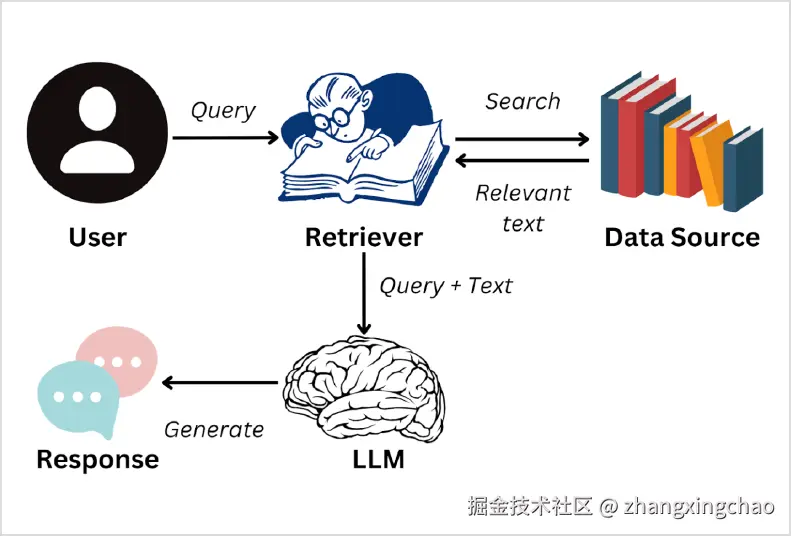
RAG 的全称是 Retrieval-Augmented Generation,中文一般叫"检索增强生成"。
它由两个动作组成:
- Retrieval:先检索外部知识。
- Generation:再基于检索到的知识生成回答。
普通大模型只依赖自身参数和当前上下文回答问题。RAG 会多走一步:先从知识库、文档库、网页或数据库里找到相关信息,再把这些信息作为上下文交给大模型。
这一步能解决三个常见问题。
第一,解决知识时效性。
模型训练完成后,参数里的知识基本就固定了。新的政策、新的产品文档、新的业务规则、新的价格信息,模型本身不一定知道。RAG 可以接入外部知识库,让知识持续更新。
第二,减少幻觉。
没有资料时,模型容易根据语言模式"猜"。有了检索到的原文片段,模型回答时就有依据,至少可以把回答约束在给定资料范围内。
第三,提高专业领域回答质量。
企业制度、客服手册、财务规则、代码文档、产品说明书,这些内容通常不是通用模型的强项。RAG 可以把领域知识临时补给模型。
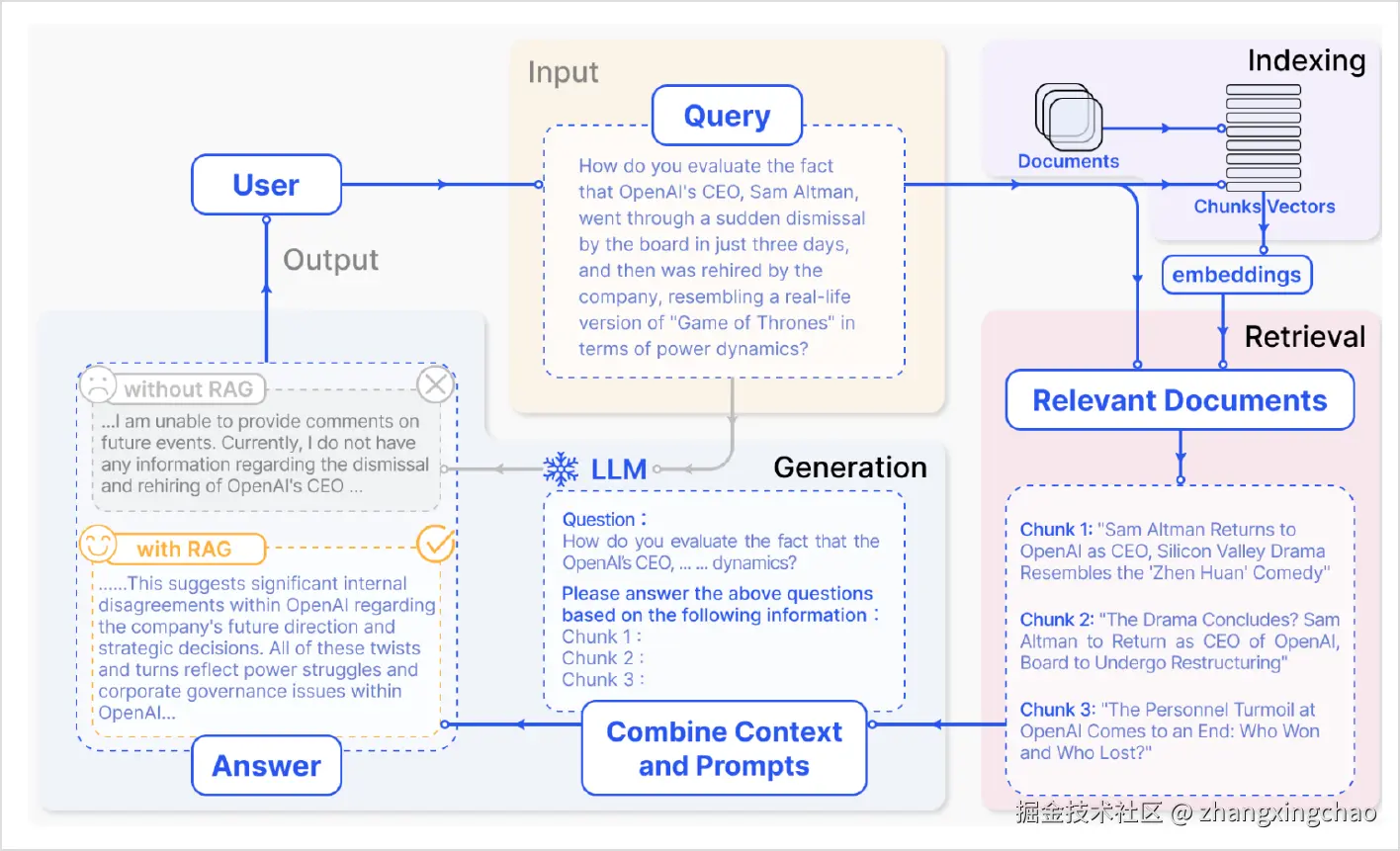
RAG 的三段流程
RAG 可以拆成三段:Indexing、Retrieval、Generation。
Indexing:把知识存起来
Indexing 是离线阶段,主要处理知识库。
一般包括这些步骤:
-
收集文档
可以是 PDF、Word、网页、数据库记录、FAQ、工单、Wiki、代码仓库说明等。
-
清洗和解析
把不同格式的文件转成文本,处理页眉页脚、乱码、空页、重复内容、表格结构等问题。
-
文档切分
把长文档切成适合检索的小块,也就是 chunks。
-
向量化
用 Embedding 模型把每个 chunk 转成向量。
-
建索引
把向量和原始文本、页码、来源文件等元数据一起存入向量数据库。
这里的重点是:向量数据库里不能只存向量,还要保存能回到原文的信息。否则检索到了向量,也不知道它对应的是哪段业务资料。
Retrieval:从大量知识里找少量有用内容
用户提问时,系统会把用户问题也转成向量,然后到向量数据库里做相似度搜索。
例如:
text
用户问题:客户经理被投诉一次扣多少分?
-> query embedding
-> 在 FAISS 中找最相似的 chunks
-> 返回 Top-K 片段这一步是粗筛,目标是快。
可以用一个更直观的例子理解:
text
1000 万个 chunks
-> 先召回 1000 个 chunk
-> 再用 rerank 模型精排如果直接让 rerank 模型给 1000 万个 chunk 打分,会非常慢。实际系统通常是"两阶段":
text
召回:快,批量过滤
重排序:慢,但打分更精确可以类比招聘:先从 1000 万份简历里快速筛出 1000 份,再让面试官精细打分。
Generation:把检索结果交给大模型回答
检索到相关片段后,要把这些片段和用户问题一起组装成 prompt。
形态大概是:
text
请基于以下资料回答用户问题。
资料:
chunk 1...
chunk 2...
chunk 3...
用户问题:
客户经理被投诉一次扣多少分?最后由 LLM 根据这些上下文生成回答。
这个过程也解释了为什么 RAG 不等于"向量数据库"。向量数据库只负责找资料,真正组织语言、总结和回答的还是大模型。
NativeRAG:一个更完整的视角
很多 RAG 图只画了"检索 -> 生成",但真实落地会更复杂。
Indexing 要考虑文档来源、切分策略、向量模型、索引结构、元数据、增量更新。
Retrieval 要考虑 query 改写、向量召回、关键词召回、混合检索、权限过滤、rerank。
Generation 要考虑上下文拼接、引用来源、回答格式、拒答策略、工具调用和结果校验。
所以 RAG 看起来只有三步,但真正做到可用,会牵涉到很多工程细节。
LLM 模型、Embedding 模型、Rerank 模型的区别
LLM 和 Embedding 模型都会把文字变成内部向量表示,但目标完全不同:Embedding 负责"找资料",LLM 负责"生成答案"。 Embedding 是检索引擎,大模型是生成引擎;拆开不是因为不能融合,而是因为拆开后更高效、更便宜、更可控。
LLM是主力生成模型:给定上下文 → 预测下一个 token → 连续生成答案",追求的是回答能力、推理能力、语言组织能力、代码生成能力
Embedding模型:给定一段文本 → 输出一个固定维度向量,追求的是:相似文本距离近,不相似文本距离远。检索、召回、聚类、分类、推荐。
Rerank 模型是精排模型,目标是对候选 chunk 做更精细的相关性打分。它更像"复核员"。
可以简单理解:
| 模型 | 主要作用 | 放在 RAG 哪一步 |
|---|---|---|
| Embedding 模型 | 把 query 和 chunks 转成向量,做相似度召回 | Retrieval |
| Rerank 模型 | 对召回结果重新打分排序 | Retrieval 后半段 |
| LLM | 基于问题和上下文生成回答 | Generation |
训练目标也不同。
LLM 通常会经历预训练、指令微调、偏好对齐等过程,目标是让模型会理解指令、生成答案、保持对话能力。
Embedding 模型更关注语义相似度,常见训练方式会让"相关文本对"距离更近,让"不相关文本对"距离更远。
Rerank 模型更关注 query-document 的匹配评分,输入通常是一组 query 和候选文档,输出相关性分数。
Embedding 模型怎么选
Embedding 模型可以在线调用,也可以本地部署。
在线方式可以用 DashScope API,例如 text-embedding-v1 到 text-embedding-v4。好处是接入简单,不需要自己部署模型;缺点是需要 API Key,也会产生 token 消耗。
本地方式可以用开源模型,比如 BGE-M3、M3E、gte-Qwen2、stella 等。好处是数据更可控,适合隐私要求高的场景;缺点是要考虑模型下载、显存、推理速度和部署复杂度。
常见选择可以这样看:
| 模型 | 特点 | 适合场景 |
|---|---|---|
| BGE-M3 | 支持多语言、长文本、混合检索,文件较大 | 高质量 RAG、跨语言检索 |
| M3E-Base | 中文优化,体积相对小 | 中文私有化部署 |
| text-embedding 系列 | 在线服务,接入简单 | 快速搭建原型、云端应用 |
| gte-Qwen2-instruct | 指令驱动能力更强 | 复杂查询、指令化检索 |
| stella-mrl-large-zh | 中文语义能力强 | 中文高级语义检索 |
Embedding 模型和 LLM 不一定来自同一个厂商。
比如可以用 Qwen 的 Embedding 模型做向量化,再用 DeepSeek 或其他模型做最终回答。它们之间没有强绑定关系,关键是接口和向量维度匹配。
常见 Embedding 模型补充
如果按使用场景来分,Embedding 模型大概可以分成几类。
通用文本嵌入模型
BGE-M3 是智源研究院推出的多语言 Embedding 模型。
它的特点是:
- 支持 100 多种语言。
- 输入长度可以到 8192 tokens。
- 支持 dense retrieval、lexical matching 和 multi-vector interaction。
- 适合跨语言、长文档、高质量 RAG 场景。
它的缺点也明显:模型文件比较大,本地部署时要考虑显存和推理速度。
text-embedding-3-large 这类在线模型,向量维度高,长文本语义捕捉能力强,英文内容表现比较好,适合英文内容优先的全球化应用。
Jina-embeddings-v2-small 的特点是模型轻量,参数量小,适合实时推理和轻量级文本处理。
中文嵌入模型
中文场景可以关注几类模型。
xiaobu-embedding-v2 针对中文语义做了优化,适合中文文本分类和中文语义检索。
M3E-Base 也是中文场景里比较常见的轻量模型,适合本地私有化部署,比如中文法律、医疗、企业制度检索等场景。
stella-mrl-large-zh-v3.5-1792 更偏向大规模中文语义分析,适合需要捕捉细粒度语义关系的任务。
指令驱动模型
gte-Qwen2-7B-instruct 是基于 Qwen 系列能力做指令优化的嵌入模型。
它的特点是更擅长理解"任务描述 + 查询"的形式,适合复杂指令驱动的检索任务,比如:
- 给定一个 Web Search 查询,检索能回答问题的 passage。
- 给定一个代码相关问题,检索相关代码片段。
- 给定复杂任务要求,检索能支撑任务执行的文档。
E5-mistral-7B 这类模型也偏复杂任务,适合 Zero-shot 检索和需要动态调整语义密度的系统。
企业级和复杂系统
企业级 RAG 通常不仅需要"语义相似",还会考虑:
- 多语言支持。
- 长文本支持。
- 混合检索能力。
- 推理速度。
- 部署成本。
- 权限和私有化要求。
所以模型选择不是单纯看榜单排名,而是要看业务数据、语言类型、响应时间、部署资源和成本。
相似度到底在算什么
以 BGE-M3 为例,可以把两组句子分别编码成向量,然后做矩阵乘法:
python
similarity = embeddings_1 @ embeddings_2.T这行代码的意思是:计算第一组句子和第二组句子之间的相似度矩阵。
比如:
text
sentences_1:
1. What is BGE M3?
2. Definition of BM25
sentences_2:
1. BGE M3 is an embedding model...
2. BM25 is a bag-of-words retrieval function...得到的结果类似:
text
[[0.626 0.3477]
[0.3499 0.678 ]]这说明:
- "What is BGE M3?" 和 "BGE M3 is an embedding model..." 相似度更高。
- "Definition of BM25" 和 "BM25 is a bag-of-words retrieval function..." 相似度更高。
RAG 检索本质上也是这个思路:把用户问题和大量 chunks 放到同一个语义空间里,找距离最近的那些片段。
BGE-M3 使用示例
BGE-M3 的基础使用方式大概是这样:
python
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel(
"BAAI/bge-m3",
use_fp16=True
)
sentences_1 = [
"What is BGE M3?",
"Defination of BM25"
]
sentences_2 = [
"BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"
]
embeddings_1 = model.encode(
sentences_1,
batch_size=12,
max_length=8192,
)["dense_vecs"]
embeddings_2 = model.encode(sentences_2)["dense_vecs"]
similarity = embeddings_1 @ embeddings_2.T
print(similarity)输出类似:
text
[[0.626 0.3477]
[0.3499 0.678 ]]这段代码的重点不是 API 写法,而是理解矩阵含义。
embeddings_1 的形状是:
text
[sentences_1 的数量, 嵌入维度]embeddings_2 的形状是:
text
[sentences_2 的数量, 嵌入维度]embeddings_2.T 是把第二组向量转置,形状变成:
text
[嵌入维度, sentences_2 的数量]最后执行矩阵乘法:
python
embeddings_1 @ embeddings_2.T得到的就是"第一组每个句子"和"第二组每个句子"的相似度矩阵。
所以:
- 第 1 行第 1 列高,说明
What is BGE M3?和 BGE M3 的介绍更相关。 - 第 2 行第 2 列高,说明
Defination of BM25和 BM25 的介绍更相关。
这正是 RAG 召回阶段要做的事。
gte-Qwen2 使用示例
gte-Qwen2 可以通过 sentence_transformers 使用。
python
from sentence_transformers import SentenceTransformer
model_dir = "/root/autodl-tmp/models/iic/gte_Qwen2-1___5B-instruct"
model = SentenceTransformer(model_dir, trust_remote_code=True)
model.max_seq_length = 8192
queries = [
"how much protein should a female eat",
"summit define",
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day...",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain..."
]
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
scores = (query_embeddings @ document_embeddings.T) * 100
print(scores.tolist())输出类似:
text
[
[78.49, 17.04],
[14.92, 75.37]
]第一个 query 和蛋白质文档分数高,第二个 query 和 summit 定义文档分数高。
gte-Qwen2 也可以用更底层的方式加载 tokenizer 和 model,然后自己做 pooling。
python
import torch
import torch.nn.functional as F
from torch import Tensor
from modelscope import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor, attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[
torch.arange(batch_size, device=last_hidden_states.device),
sequence_lengths
]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f"Instruct: {task_description}\nQuery: {query}"
task = "Given a web search query, retrieve relevant passages that answer the query"
queries = [
get_detailed_instruct(task, "how much protein should a female eat"),
get_detailed_instruct(task, "summit define"),
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day...",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain..."
]
input_texts = queries + documents
model_dir = "/root/autodl-tmp/models/iic/gte_Qwen2-1___5B-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True)
batch_dict = tokenizer(
input_texts,
max_length=8192,
padding=True,
truncation=True,
return_tensors="pt"
)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict["attention_mask"])
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())这个版本代码更长,但能看清楚底层过程:
text
文本
-> tokenizer
-> model
-> last token pooling
-> normalize
-> 相似度计算gte-Qwen2 这类指令优化模型的优势是指令理解和执行能力更强,适合复杂问答、复杂语义匹配、多语言检索等任务。局限是计算资源需求高,更适合资源比较充足的环境。
文档切分:chunk_size 和 chunk_overlap
切分是 RAG 里很容易被低估的一步。
常见做法是使用规则切分,比如:
python
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)这里有几个参数很重要。
chunk_size=1000 表示每个文本块大约 1000 个字符。
chunk_overlap=200 表示相邻文本块之间保留 200 个字符重叠,避免一句话或一个段落被切断后丢失上下文。
separators 表示切分优先级:先按段落切,再按换行切,再按句号、空格和字符切。
规则切分快、成本低,是最常用的方法。
LLM 切分质量可能更好,因为模型能理解语义边界,但成本高、速度慢。如果是上亿 token 的知识库,一般不会全量交给 LLM 切分。
DeepSeek + FAISS 搭建本地知识库检索
下面用 DeepSeek + FAISS 搭一个本地 PDF 知识库问答。
用户问:
text
客户经理被投诉了,投诉一次扣多少分?系统基于 PDF 里的制度内容回答:
text
根据文件内容,客户经理被投诉一次扣 2 分。
具体规定是:客户服务效率低、态度生硬或不及时为客户提供维护服务,有客户投诉的,每投诉一次扣 2 分。用户再问:
text
客户经理每年评聘申报时间是怎样的?系统能从文件里找到:
text
每年一月份为客户经理评聘的申报时间,由分行人力资源部、个人业务部每年二月份组织统一的资格考试。
这个案例的技术栈可以拆成四部分:
| 模块 | 技术选择 |
|---|---|
| 文档处理 | PyPDF2 提取 PDF 文本 |
| 文档切分 | RecursiveCharacterTextSplitter |
| 向量化 | DashScopeEmbeddings / text-embedding-v1 |
| 向量数据库 | FAISS |
| 生成模型 | deepseek-v3 |
| 问答链 | LangChain load_qa_chain |
整体流程是:
text
PDF 文件
-> 提取文本
-> 分割 chunks
-> 生成 embeddings
-> 创建 FAISS 索引
-> 用户问题向量检索
-> 取 Top-K 文档
-> LLM 基于上下文回答核心代码结构大概是这样:
python
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
pdf_reader = PdfReader("./客户经理考核办法.pdf")
text = ""
for page in pdf_reader.pages:
extracted_text = page.extract_text()
if extracted_text:
text += extracted_text
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
chunks = text_splitter.split_text(text)
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
knowledge_base = FAISS.from_texts(chunks, embeddings)查询时:
python
query = "客户经理被投诉了,投诉一次扣多少分?"
docs = knowledge_base.similarity_search(query, k=4)再把检索到的 docs 和用户问题一起交给 LLM:
python
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import Tongyi
llm = Tongyi(
model_name="deepseek-v3",
dashscope_api_key=DASHSCOPE_API_KEY,
)
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.invoke({
"input_documents": docs,
"question": query,
})
print(response["output_text"])这里有一个细节:如果要让回答可追溯,最好保存 chunk 对应的页码、文件名和位置。
例如:
text
chunk -> source_file
chunk -> page_number
chunk -> section_title这样回答时可以展示"来源页码",用户能回到原文核对。
这个案例里也暴露了一个常见问题:页码映射可能不准。原因通常是 PDF 提取文本后字符位置、换行、页码、chunk 边界并不完全对齐。更稳妥的做法是切分时直接把每页文本作为 Document,并把页码存在 metadata 里。
FAISS 案例的程序结构
这个本地知识库问答可以拆成三步。
Step1:文档预处理
流程是:
text
PDF 文件
-> 文本提取
-> 文本分割
-> 页码映射PDF 文本提取需要注意几件事:
- 逐页提取文本内容。
- 记录每一页对应的文本。
- 处理空页。
- 处理提取失败或乱码。
- 尽量保存来源页码,方便后续溯源。
示例函数可以这样写:
python
from typing import List, Tuple
def extract_text_with_page_numbers(pdf) -> Tuple[str, List[int]]:
"""
从 PDF 中提取文本,并记录每行文本对应的页码。
参数:
pdf: PDF 文件对象
返回:
text: 提取出的文本内容
page_numbers: 每行文本对应的页码列表
"""
text = ""
page_numbers = []
for page_number, page in enumerate(pdf.pages, start=1):
extracted_text = page.extract_text()
if extracted_text:
text += extracted_text
page_numbers.extend([page_number] * len(extracted_text.split("\n")))
else:
print(f"No text found on page {page_number}.")
return text, page_numbers这里的页码映射是一个简化实现。真实项目里更推荐把每页文本直接封装成带 metadata 的 Document。
Step2:知识库构建
流程是:
text
文本块
-> 嵌入向量
-> FAISS 索引
-> 本地持久化核心函数可以这样写:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
def process_text_with_splitter(text: str, page_numbers: List[int]) -> FAISS:
"""
处理文本并创建向量存储。
参数:
text: 提取的文本内容
page_numbers: 每行文本对应的页码列表
返回:
knowledgeBase: 基于 FAISS 的向量存储对象
"""
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
chunks = text_splitter.split_text(text)
print(f"文本被分割成 {len(chunks)} 个块。")
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
knowledgeBase = FAISS.from_texts(chunks, embeddings)
print("已从文本块创建知识库。")
knowledgeBase.page_info = {
chunk: page_numbers[i]
for i, chunk in enumerate(chunks)
if i < len(page_numbers)
}
return knowledgeBase这里做了三件事:
- 用
RecursiveCharacterTextSplitter切分文本。 - 用
DashScopeEmbeddings生成向量。 - 用
FAISS.from_texts创建向量索引。
如果需要持久化,可以把 FAISS 索引保存到本地,同时保存 metadata。
常见持久化内容包括:
.faiss:向量索引文件。.pkl:文本和元数据信息。page_info.pkl:页码映射信息。
Step3:问答查询
流程是:
text
用户问题
-> 向量检索
-> 文档组合
-> LLM 生成
-> 答案输出查询代码大概是这样:
python
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import Tongyi
from langchain_community.callbacks.manager import get_openai_callback
llm = Tongyi(
model_name="deepseek-v3",
dashscope_api_key=DASHSCOPE_API_KEY
)
query = "客户经理每年评聘申报时间是怎样的?"
if query:
docs = knowledgeBase.similarity_search(query, k=10)
chain = load_qa_chain(llm, chain_type="stuff")
input_data = {
"input_documents": docs,
"question": query
}
with get_openai_callback() as cost:
response = chain.invoke(input=input_data)
print(f"查询已处理。成本: {cost}")
print(response["output_text"])
print("来源:")
unique_pages = set()
for doc in docs:
text_content = getattr(doc, "page_content", "")
source_page = knowledgeBase.page_info.get(text_content.strip(), "未知")
if source_page not in unique_pages:
unique_pages.add(source_page)
print(f"文本块页码: {source_page}")这里的 similarity_search(query, k=10) 表示找出最相关的 10 个文档块。
load_qa_chain(llm, chain_type="stuff") 表示把这些文档块直接拼进 prompt,让模型基于这些内容回答。
如果使用的是 OpenAI 兼容模型,可以用 callback 跟踪 token 和成本;如果是其他 SDK,成本统计方式可能不同。
FAISS 案例小结
这个案例可以总结成四点。
第一,PDF 文本提取与处理。
用 PdfReader 从 PDF 里提取文本,同时记录页码。再用 RecursiveCharacterTextSplitter 把长文本切成小块,方便向量化。
第二,向量数据库构建。
用 DashScopeEmbeddings 把文本块转成向量,再用 FAISS 存储向量,支持相似度搜索。同时要保存页码和来源信息,方便用户核对答案来源。
第三,语义搜索与问答链。
用户提问后,用 similarity_search 找相关文本块,再用 load_qa_chain 把文档和问题交给模型生成答案。
第四,成本跟踪与结果展示。
如果模型服务支持 token 统计,可以跟踪调用成本。回答结果最好展示来源页码,让用户知道答案来自哪里。
可以按这个练习任务自己做一遍:
text
Step1:收集整理自己的知识库文档。
Step2:从 PDF 中提取文本并记录页码。
Step3:处理文本并创建向量存储。
Step4:执行相似度搜索,找到与查询相关的文档。
Step5:使用问答链对用户问题进行回答。
Step6:显示每个文档块的来源页码。如果页码来源不准,可以重点检查文本块页码的计算逻辑。很多时候问题出在"文本切分后的 chunk"和"原始页码记录"之间没有稳定映射。
LangChain 问答链怎么选
LangChain 里的 load_qa_chain 支持几种常见 chain_type。
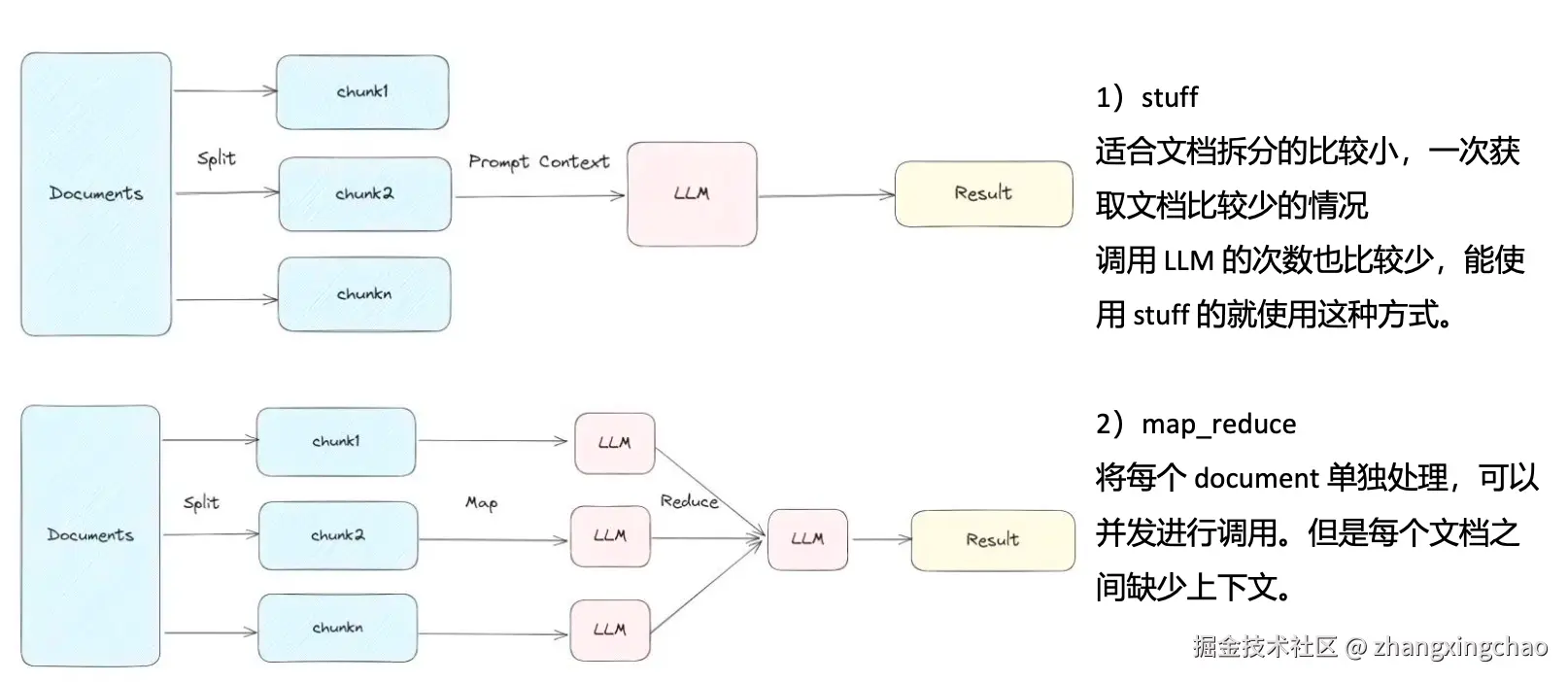
stuff
stuff 最简单:把检索到的文档直接拼进 prompt,一次交给 LLM。优点是调用次数少、逻辑简单、速度快。缺点是上下文太长时容易超过 token 限制。
适合文档块比较少、每次检索结果不多的场景。能用 stuff 的时候,优先用 stuff。
map_reduce
map_reduce 会先让模型分别处理每个 chunk,再把中间结果汇总。
优点是可以处理更多文档,也可以并发。
缺点是每个 chunk 独立处理,容易缺少全局上下文,而且调用 LLM 的次数更多。
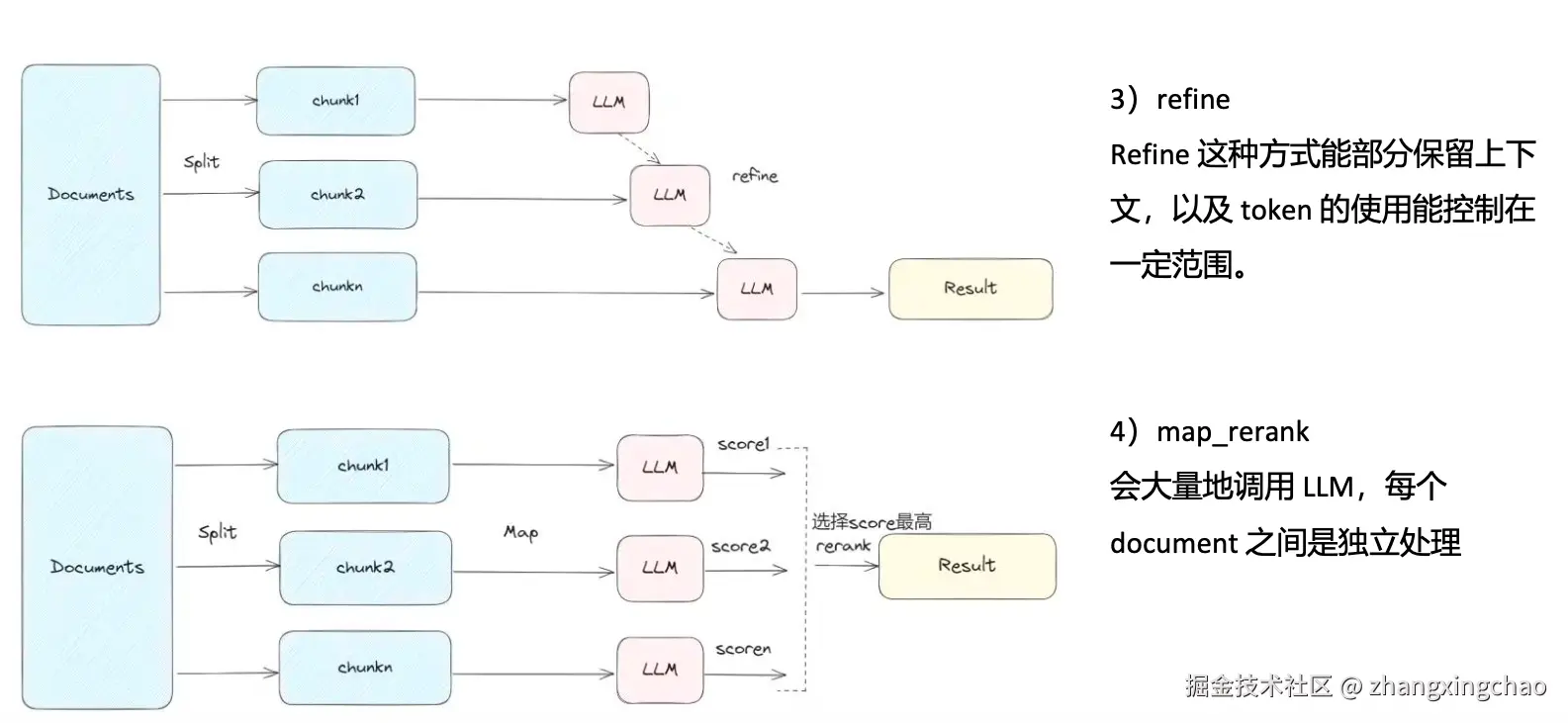
refine
refine 是先用第一个 chunk 生成初始答案,再拿后续 chunk 逐步修正答案。
优点是能部分保留上下文,适合逐步补充信息。
缺点是前面的错误可能会被带到后面。
map_rerank
map_rerank 会让模型分别对每个 chunk 做回答和评分,然后返回分数最高的结果。
优点是能选出更相关的文档。
缺点是会大量调用 LLM,成本和延迟都更高。
如果 LLM 可以处理无限上下文,RAG 还有意义吗
这个问题很常见。
答案是:仍然有意义。
原因不只是 token 长度。
1. 效率和成本
LLM 处理长上下文时,计算资源消耗会增加,响应时间也会变长。
即使模型能吃下几百万 token,把整个知识库每次都塞进去,也不一定划算。RAG 通过检索相关片段,可以减少输入长度,让模型只看和当前问题有关的内容。
js
建库阶段:
文档 token → embedding 成本,一次性为主(如果都给LLM,那每次都会大量消耗token)
查询阶段:
用户 query → embedding 成本
Query 改写 → 可选 LLM 成本
向量检索 → 数据库计算成本,不是 token 成本
Rerank → 可选 rerank token 成本
Top-K 文档 + 用户问题 → 最终 LLM 输入 token
LLM 回答 → 输出 token2. 知识更新
大模型参数里的知识来自训练数据,训练完成后不会自动更新。
RAG 连接的是外部知识库,文档可以增量更新,今天改制度,今天就能检索到。
3. 可解释性
RAG 可以把检索到的来源片段、文件名、页码展示出来。
用户可以核对:
text
这个答案来自哪个文件?
来自第几页?
原文怎么写?纯 LLM 生成过程更难追溯。
4. 定制化
不同部门、不同业务线可以维护不同知识库。客服用客服知识库,财务用财务制度库,研发用代码和技术文档库。
RAG 可以针对特定领域定制检索系统,而不是把所有信息都混进一个通用上下文。
5. 数据隐私
企业可以在本地或私有数据源上完成检索,只把必要片段交给模型,甚至全流程私有化。
这对工资、合同、客户信息、审计资料等敏感场景很重要。
所以,RAG 的价值包括:
text
省token
提高速度
支持更新
支持溯源
支持权限
支持私有化它不是长上下文的临时替代品,而是一套知识接入和检索工程。
Query 改写为什么重要
RAG 的第一步是检索。如果检索走偏,后面的生成很难补救。
问题在于:用户的问题往往是口语化的、模糊的、依赖上下文的,甚至带情绪。
但知识库里的文本通常是客观陈述,比如制度条款、说明文档、FAQ、技术文档。
所以 Query 改写的作用就是把用户问题翻译成更适合检索的表达。
可以把它理解成一个"检索前翻译官"。
常见类型有五种。
上下文依赖型
用户问:
text
还有其他设施吗?如果前面对话里讨论的是上海迪士尼"疯狂动物城"园区,那可以改写成:
text
除了疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店之外,
上海迪士尼疯狂动物城园区还有其他设施吗?这样检索时就不会只搜"其他设施"这种泛泛表达。
对比型
用户问:
text
哪个游玩的时间比较长,比较有趣?如果上下文里有"疯狂动物城园区"和"蜘蛛侠主题园区",可以改写成:
text
上海迪士尼乐园的疯狂动物城园区和蜘蛛侠主题园区,哪个游玩时间更长、更有趣?模糊指代型
用户问:
text
都什么时候开始?如果前文讨论的是上海迪士尼和香港迪士尼的烟花表演,可以改写成:
text
上海迪士尼乐园和香港迪士尼乐园的烟花表演都什么时候开始?多意图型
用户问:
text
门票多少钱?需要提前预约吗?停车费怎么收?这个问题最好拆成多个问题:
json
[
"门票多少钱?",
"需要提前预约吗?",
"停车费怎么收?"
]拆开以后,每个问题都能单独检索,结果更稳定。
反问型
用户问:
text
这不会也要提前一个月预订吧?可以改写成:
text
迪士尼乐园门票是否需要提前一个月预订?这样语气被中和了,检索目标也更明确。
Query 类型可以先识别,再改写
实际系统里,可以先让 LLM 判断 query 类型,再根据类型选择改写策略。
输出可以设计成 JSON:
json
{
"query_type": "上下文依赖型",
"rewritten_query": "除了之前提到的游乐项目之外,还有哪些其他游乐项目?",
"confidence": 0.95
}这种结构化输出更方便程序处理。
如果识别出是多意图型,就进入问题拆分;如果识别出是模糊指代型,就补全指代对象;如果识别出是反问型,就把它改成中立问题。
这里的关键不是"让模型写得更好看",而是让检索命中更准。
Query 改写 Prompt 模板
下面这些模板可以直接作为代码里的 prompt 雏形。实际使用时,可以根据业务场景替换"迪士尼"为自己的业务对象,比如企业制度、产品文档、客服知识库、代码文档等。
上下文依赖型 Query 改写
上下文依赖型问题通常包含"还有""其他""这个""刚才那个"等表达。单看当前问题不完整,必须结合历史对话才能检索。
python
instruction = """
你是一个智能的查询优化助手。请分析用户的当前问题以及前序对话历史,判断当前问题是否依赖于上下文。
如果依赖,请将当前问题改写成一个独立的、包含所有必要上下文信息的完整问题。
如果不依赖,直接返回原问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""示例:
text
对话历史:
用户:我想了解一下上海迪士尼乐园的最新项目。
AI:上海迪士尼乐园最新推出了"疯狂动物城"主题园区,这里有朱迪警官和尼克狐的互动体验。
用户:这个园区有什么游乐设施?
AI:"疯狂动物城"园区目前有疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店等设施。
当前查询:还有其他设施吗?
改写结果:
除了疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店之外,上海迪士尼乐园"疯狂动物城"园区还有其他设施吗?对比型 Query 改写
对比型问题常见关键词有"哪个""更""比较""哪个好""哪个更适合"等。
python
instruction = """
你是一个查询分析专家。请分析用户的输入和相关的对话上下文,识别出问题中需要进行比较的多个对象。
然后,将原始问题改写成一个更明确、更适合在知识库中检索的对比性查询。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史/上下文信息 ###
{context_info}
### 原始问题 ###
{query}
### 改写后的查询 ###
"""示例:
text
对话历史:
用户:我想了解一下上海迪士尼乐园的最新项目。
AI:上海迪士尼乐园最新推出了疯狂动物城主题园区,还有蜘蛛侠主题园区。
当前查询:哪个游玩的时间比较长,比较有趣?
改写结果:
上海迪士尼乐园的疯狂动物城主题园区和蜘蛛侠主题园区,哪个游玩时间更长、更有趣?模糊指代型 Query 改写
模糊指代型问题通常包含"它""他们""都""这个""那个"等词。
python
instruction = """
你是一个消除语言歧义的专家。请分析用户的当前问题和对话历史,找出问题中"都"、"它"、"这个"等模糊指代词具体指向的对象。
然后,将这些指代词替换为明确的对象名称,生成一个清晰、无歧义的新问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""示例:
text
对话历史:
用户:我想了解一下上海迪士尼乐园和香港迪士尼乐园的烟花表演。
AI:好的,上海迪士尼乐园和香港迪士尼乐园都有精彩的烟花表演。
当前查询:都什么时候开始?
改写结果:
上海迪士尼乐园和香港迪士尼乐园的烟花表演都什么时候开始?多意图型 Query 改写
多意图型问题里往往有多个独立问题,比如用顿号、逗号、问号连续提问。
python
instruction = """
你是一个任务分解机器人。请将用户的复杂问题分解成多个独立的、可以单独回答的简单问题。以 JSON 数组格式输出。
"""
prompt = f"""
### 指令 ###
{instruction}
### 原始问题 ###
{query}
### 分解后的问题列表 ###
请以 JSON 数组格式输出,例如:["问题1", "问题2", "问题3"]
"""示例:
text
原始查询:
门票多少钱?需要提前预约吗?停车费怎么收?
分解结果:
["门票多少钱?", "需要提前预约吗?", "停车费怎么收?"]多意图问题不建议强行合成一个 query,因为不同意图可能对应知识库里的不同位置。拆开检索再合并回答,通常更稳。
反问型 Query 改写
反问型问题经常带情绪,比如"不会也要......吧""难道还要......吗"。这类表达不适合直接检索,需要改成中立问题。
python
instruction = """
你是一个沟通理解大师。请分析用户的反问或带有情绪的陈述,识别其背后真实的意图和问题。
然后,将这个反问改写成一个中立、客观、可以直接用于知识库检索的问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""示例:
text
对话历史:
用户:你好,我想预订下周六上海迪士尼乐园的门票。
AI:正在为您查询......查询到下周六的门票已经售罄。
当前查询:
这不会也要提前一个月预订吧?
改写结果:
迪士尼乐园门票是否需要提前一个月预订?Query 改写的自动识别
如果不想为每一种类型都手动写判断逻辑,可以让 LLM 先识别 query 类型,再输出结构化 JSON。
python
instruction = """
你是一个智能的查询分析专家。请分析用户的查询,识别其属于以下哪种类型:
1. 上下文依赖型 - 包含"还有"、"其他"等需要上下文理解的词汇。
2. 对比型 - 包含"哪个"、"比较"、"更"、"哪个更好"、"哪个更"等比较词汇。
3. 模糊指代型 - 包含"它"、"他们"、"都"、"这个"等指代词。
4. 多意图型 - 包含多个独立问题,用"、"或"?"分隔。
5. 反问型 - 包含"不会"、"难道"等反问语气。
说明:如果同时存在多意图型、模糊指代型,优先级为多意图型 > 模糊指代型。
请返回 JSON 格式:
{
"query_type": "查询类型",
"rewritten_query": "改写后的查询",
"confidence": "置信度(0-1)"
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 上下文信息 ###
{context_info}
### 原始查询 ###
{query}
### 分析结果 ###
"""可能的输出:
json
{
"query_type": "上下文依赖型",
"rewritten_query": "除了之前提到的游乐项目之外,还有哪些其他游乐项目?",
"confidence": 0.95
}再看几个示例:
| 查询 | 识别类型 | 改写结果 |
|---|---|---|
| 还有其他游乐项目吗? | 上下文依赖型 | 除了之前提到的游乐项目之外,还有哪些其他游乐项目? |
| 哪个园区更好玩? | 对比型 / 模糊指代型 | 需要明确比较的是哪些园区,再改写成对比查询 |
| 都适合小朋友吗? | 模糊指代型 | 明确"都"指代的对象后再检索 |
| 有什么餐厅?价格怎么样? | 多意图型 | 拆成"有哪些餐厅?"和"这些餐厅的价格怎么样?" |
| 这不会也要排队两小时吧? | 反问型 | 这个项目需要排队两小时吗? |
Query 改写的目标是增强检索,不是为了让句子更优美。只要改写后的 query 更明确、更完整、更适合命中知识库,就是有效改写。
可以自己做一个练习:
text
输入一组真实用户问题
-> 判断 Query 类型
-> 改写成适合检索的问题
-> 用改写前后分别检索
-> 对比命中结果Query + 联网搜索
RAG 主要面向自己的知识库,但有些问题需要实时信息。
比如迪士尼助手里,用户问:
text
上海迪士尼乐园今天开放吗?现在人多不多?这个问题只靠本地知识库不够,因为"今天是否开放"和"现在人多不多"都具有实时性。知识库可以回答园区介绍、项目说明、历史规则,但无法保证回答当天的开放状态和当前人流量。
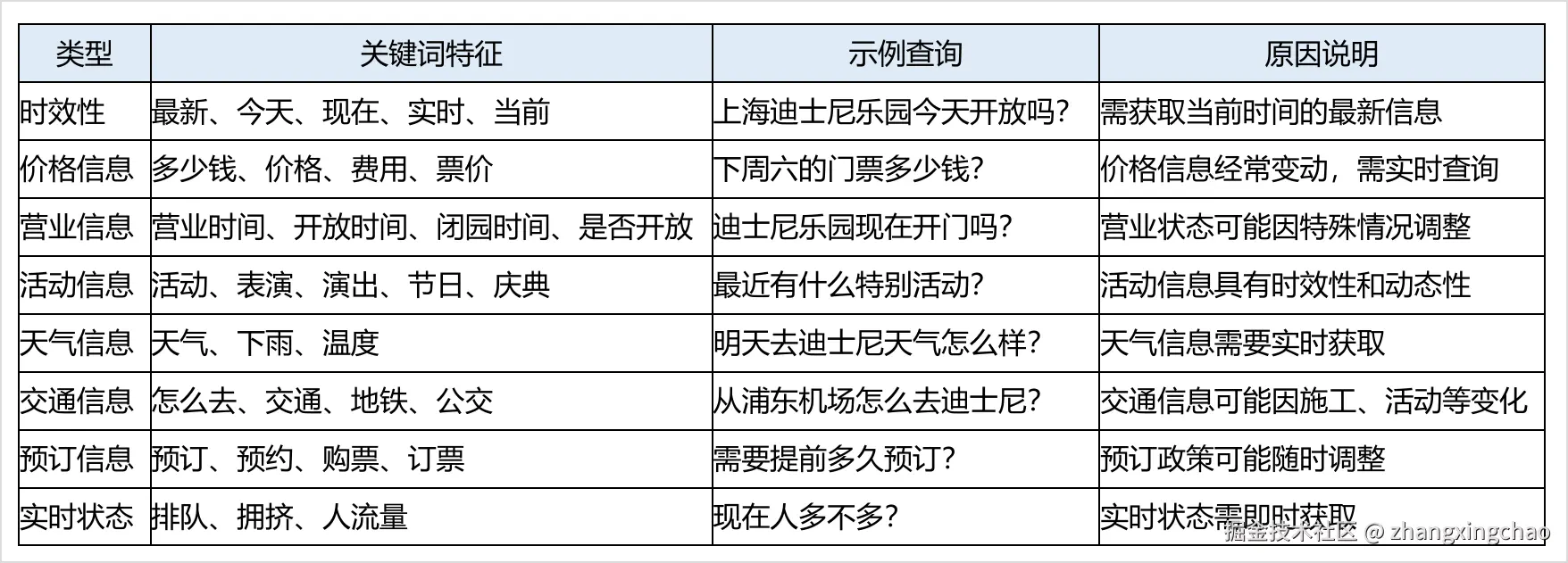
常见需要联网搜索的类型包括:
| 类型 | 常见关键词 | 示例 | 为什么需要联网 |
|---|---|---|---|
| 时效性信息 | 最新、今天、现在、实时、当前 | 上海迪士尼乐园今天开放吗? | 需要获取当前时间的最新信息 |
| 价格信息 | 多少钱、价格、费用、票价 | 下周六的门票多少钱? | 价格可能随日期、库存、活动变化 |
| 营业信息 | 营业时间、开放时间、闭园时间、是否开放 | 迪士尼乐园现在开门吗? | 营业状态可能因特殊情况调整 |
| 活动信息 | 活动、表演、演出、节日、庆典 | 最近有什么特别活动? | 活动安排经常变化 |
| 天气信息 | 天气、下雨、温度 | 明天去迪士尼天气怎么样? | 天气必须查实时或预报数据 |
| 交通信息 | 怎么去、交通、地铁、公交 | 从浦东机场怎么去迪士尼? | 交通可能受施工、管制、活动影响 |
| 预订信息 | 预订、预约、购票、订票 | 需要提前多久预订? | 预订政策和库存可能随时变化 |
| 实时状态 | 排队、拥挤、人流量 | 现在人多不多? | 需要当前客流、排队或平台数据 |
这里可以拆成三个能力:识别是否需要联网、把问题改写成搜索查询、生成搜索策略。
联网搜索能力一:识别是否需要联网
可以先做一个识别函数(伪代码):
python
def identify_web_search_needs(query, conversation_history):
"""
输入:
- query: 用户查询
- conversation_history: 对话历史上下文
输出:
- need_web_search: 是否需要联网搜索
- search_reason: 搜索原因
- confidence: 置信度,范围 0-1
"""对应的 prompt 可以这样写:
text
你是一个智能的查询分析专家。请分析用户的查询,判断是否需要联网搜索来获取最新、最准确的信息。
需要联网搜索的情况包括:
1. 时效性信息:包含"最新""今天""现在""实时""当前"等时间相关词汇。
2. 价格信息:包含"多少钱""价格""费用""票价"等价格相关词汇。
3. 营业信息:包含"营业时间""开放时间""闭园时间""是否开放"等营业状态。
4. 活动信息:包含"活动""表演""演出""节日""庆典"等动态信息。
5. 天气信息:包含"天气""下雨""温度"等天气相关内容。
6. 交通信息:包含"怎么去""交通""地铁""公交"等交通方式。
7. 预订信息:包含"预订""预约""购票""订票"等预订相关内容。
8. 实时状态:包含"排队""拥挤""人流量"等实时状态。
请返回 JSON:
{
"need_web_search": true 或 false,
"search_reason": "需要或不需要搜索的原因",
"confidence": 0 到 1 之间的置信度
}
### 对话历史 ###
{conversation_history}
### 用户查询 ###
{query}LLM 的输出可以是:
json
{
"need_web_search": true,
"search_reason": "查询今天是否开放和当前人流量,涉及营业状态和实时状态,需要联网搜索。",
"confidence": 0.98
}这里有个细节:判断逻辑不一定完全写死在代码里,也可以让 LLM 根据工具说明自己判断。Agent 场景里,Web Search 通常是一个工具,模型会根据用户问题、系统提示词和工具描述决定是否调用。
联网搜索能力二:改写搜索查询
判断需要联网后,还要把 query 改写成更适合搜索引擎的形式。
函数形态可以是:
python
def rewrite_for_web_search(query, search_type="general"):
"""
输入:
- query: 原始查询
- search_type: 搜索类型
输出:
- rewritten_query: 改写后的查询
- search_keywords: 搜索关键词列表
- search_intent: 搜索意图
- suggested_sources: 建议搜索来源
"""对应的 prompt 可以这样写:
text
你是一个专业的搜索查询优化专家。请将用户的查询改写为更适合搜索引擎检索的形式。
改写技巧:
1. 添加具体地点,例如"上海迪士尼乐园""香港迪士尼乐园"。
2. 添加时间范围,例如"今天""本周""下周六"。
3. 使用关键词组合,把长句拆成关键词。
4. 添加搜索意图,明确搜索目的。
5. 去除口语化表达,转换为标准搜索词。
6. 添加相关词汇,增加同义词或相关词。
请返回 JSON:
{
"rewritten_query": "改写后的搜索查询",
"search_keywords": ["关键词1", "关键词2", "关键词3"],
"search_intent": "搜索意图",
"suggested_sources": ["建议搜索的网站类型"]
}
### 原始查询 ###
{query}
### 搜索类型 ###
{search_type}例如:
text
原始问题:下周六的门票多少钱?需要提前多久预订?
改写查询:下周六上海迪士尼乐园门票价格及预订时间要求
关键词:上海迪士尼乐园、下周六、门票价格、预订时间、提前多久预订
搜索意图:获取特定日期的门票价格和预订政策信息
建议来源:官方网站、旅游预订平台、景点官方社交媒体账号这个改写不是为了让回答更好看,而是为了让检索更容易命中有用页面。用户的原始问题常常带有上下文、省略和口语化表达,搜索引擎更适合处理清晰的地点、时间、对象和关键词组合。
联网搜索能力三:生成搜索策略
如果只是查一次网页,改写查询就够了。若要做得更完整,可以再生成搜索策略。
函数形态可以是:
python
def generate_search_strategy(query, search_type="general"):
"""
输入:
- query: 用户查询
- search_type: 搜索类型
输出:
- primary_keywords: 主要关键词
- extended_keywords: 扩展关键词
- search_platforms: 搜索平台
- search_tips: 搜索技巧
- verification_methods: 验证方法
"""对应的 prompt 可以这样写:
text
你是一个搜索策略专家。请为用户的查询制定详细的搜索策略。
当前日期:{current_date}
搜索策略包括:
1. 主要搜索词:核心关键词。
2. 扩展搜索词:相关词汇和同义词。
3. 搜索网站:推荐的搜索平台。
4. 时间范围:具体的搜索时间范围。
请返回 JSON:
{
"primary_keywords": ["主要关键词"],
"extended_keywords": ["扩展关键词"],
"search_platforms": ["搜索平台"],
"time_range": "具体的时间范围"
}
### 用户查询 ###
{query}
### 搜索类型 ###
{search_type}举两个完整例子。
第一个例子:
text
对话历史:
用户:我想去上海迪士尼乐园玩
AI:上海迪士尼乐园是一个很棒的选择!
当前查询:上海迪士尼乐园今天开放吗?现在人多不多?识别结果:
json
{
"need_web_search": true,
"search_reason": "查询上海迪士尼乐园今天是否开放属于营业信息,"现在人多不多"涉及实时状态,两者都需要联网获取最新、准确的信息。",
"confidence": 0.98
}改写结果:
json
{
"rewritten_query": "上海迪士尼乐园 今天 开放时间 人流情况",
"search_keywords": ["上海迪士尼乐园", "开放时间", "今天", "人流量", "游客数量"],
"search_intent": "获取上海迪士尼乐园今日是否开放以及当前游客密度信息,用于出行规划",
"suggested_sources": ["官方旅游网站", "携程或飞猪等旅游平台", "大众点评或美团用户评价", "本地生活类账号"]
}搜索策略:
json
{
"primary_keywords": ["上海迪士尼乐园 今天 开放时间 人流量"],
"extended_keywords": ["上海迪士尼 当前客流", "上海迪士尼 排队时间", "上海迪士尼 今日营业"],
"search_platforms": ["搜索引擎", "官方渠道", "旅游平台", "本地生活平台"],
"time_range": "最近一周,优先当天信息"
}第二个例子:
text
当前查询:下周六的门票多少钱?需要提前多久预订?识别结果:
json
{
"need_web_search": true,
"search_reason": "查询下周六的门票价格和预订时间,涉及价格信息和预订信息,需要联网获取最新、最准确的数据。",
"confidence": 0.98
}改写结果:
json
{
"rewritten_query": "下周六上海迪士尼乐园门票价格及预订时间要求",
"search_keywords": ["下周六", "上海迪士尼乐园", "门票价格", "预订时间", "提前多久预订"],
"search_intent": "获取特定日期的门票价格和预订政策信息",
"suggested_sources": ["官方网站", "旅游预订平台", "景点官方社交媒体账号"]
}搜索策略:
json
{
"primary_keywords": ["下周六 上海迪士尼乐园 门票价格 预订"],
"extended_keywords": ["上海迪士尼 票价", "上海迪士尼 提前预约", "上海迪士尼 购票规则"],
"search_platforms": ["搜索引擎", "官方网站", "旅游预订平台"],
"time_range": "最近一周,优先官方最新页面"
}如果后面接 Tavily、Search API 或浏览器工具,就可以把这些结构化参数传给搜索工具。
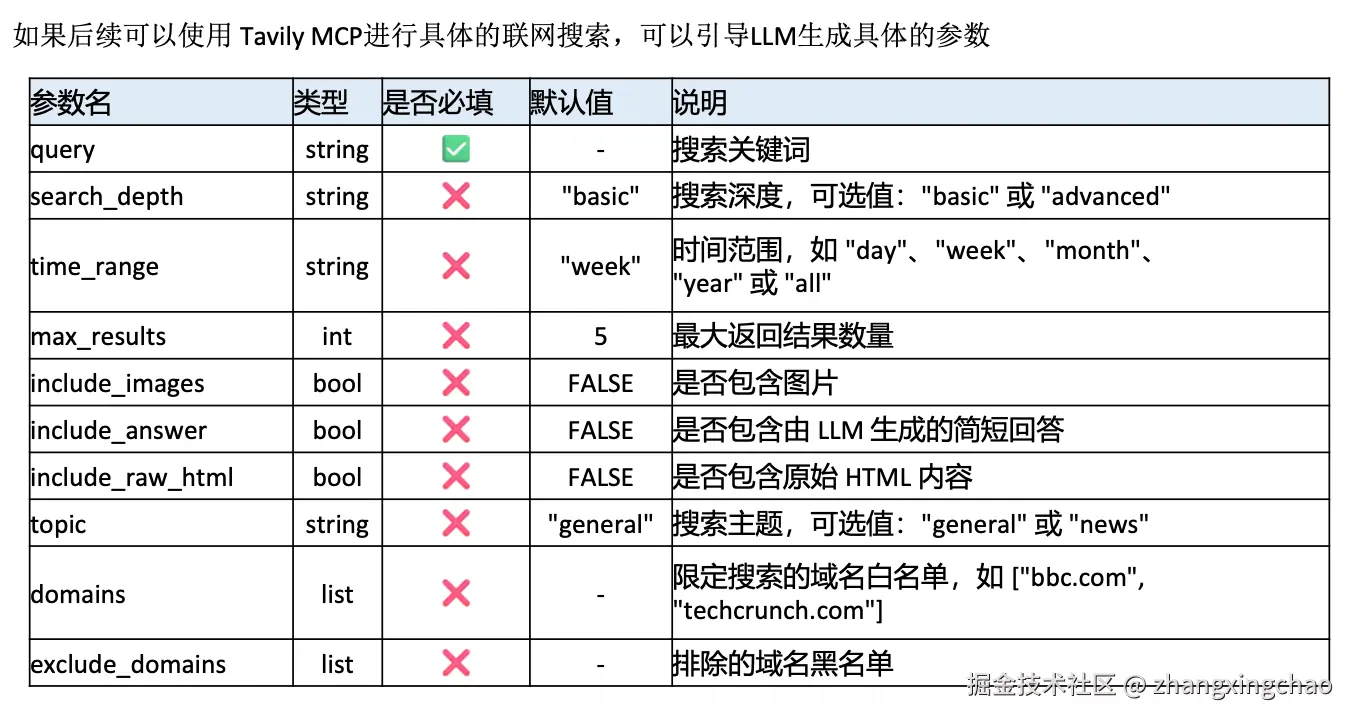
常见参数可以这样理解:
| 参数 | 作用 |
|---|---|
| query | 搜索关键词,也就是改写后的查询 |
| search_depth | 搜索深度,常见值是 basic 或 advanced |
| time_range | 时间范围,例如 day、week、month、year、all |
| max_results | 最大返回结果数量 |
| include_images | 是否返回图片 |
| include_answer | 是否返回由搜索服务生成的简短答案 |
| include_raw_html | 是否返回原始 HTML |
| topic | 搜索主题,例如 general 或 news |
| domains | 域名白名单,只搜索指定网站 |
| exclude_domains | 域名黑名单,排除不希望使用的网站 |
如果要把这个功能做成练习,可以按这个顺序实现:
text
输入用户问题
-> 识别是否需要联网搜索
-> 如果需要,改写搜索 query
-> 生成关键词和搜索策略
-> 调用搜索工具
-> 把搜索结果作为上下文交给 LLM
-> 输出回答并标注来源RAG 和 Web Search 怎么选
如果是企业内部知识,优先走 RAG。
比如员工手册、产品文档、内部 SOP、业务制度、客服话术、代码仓库说明,这些内容通常在企业自己的知识库里。
如果是实时信息,走 Web Search。
比如天气、票价、新闻、实时营业状态、交通管制、最新公告。
如果两边都有,可以先按来源可信度排序:
text
企业内部权威知识库
> 官方网站 / 官方公告
> 权威媒体 / 平台数据
> 普通网页 / 用户评论对 Agent 来说,RAG 往往是更优先的内部记忆;Web Search 是外部工具。模型是否调用搜索工具,取决于系统提示词和工具描述。
权限控制不能只靠 Prompt
RAG 系统里很重要的一点是权限控制。
比如用户问:
text
帮我查一下领导的工资。不能只在 prompt 里写:
text
普通员工不能查看工资信息。这种属于软约束,容易被绕过。
更好的做法是硬约束:
text
如果当前用户是普通员工,
那么检索阶段就不要把工资相关 chunks 放进上下文。模型看不到敏感资料,自然就无法基于敏感资料回答。
权限过滤应该发生在检索前或检索中,而不是只依赖最终生成阶段的拒答。
长会话为什么越聊越差
长会话里经常会出现一个现象:几十轮对话以后,模型可能"越用越傻",幻觉会累计。
原因是长会话里会堆积大量历史上下文,其中可能包含错误信息、过时信息、无关信息和用户临时说法。模型每一轮都要基于这些上下文继续回答,错误可能被不断放大。
实际使用时可以这样处理:
- 重要任务尽量开启新会话。
- 只保留必要的历史摘要,不要无限保留原始对话。
- RAG 检索每轮重新执行,不要长期依赖旧检索结果。
- 对关键结论要求模型引用来源。
- 对高风险动作增加人工确认。
如果只是出了一次幻觉,不一定要换模型。先检查上下文、检索结果和 prompt,很多问题是流程问题,不是模型本身突然变差。
RAG 和微调的边界
RAG 可以提供知识,但不能真正提升模型能力。
比如把公司制度放进知识库,模型能根据制度回答问题,这是 RAG 擅长的。
但如果希望模型长期学会某种专业写作风格、特定判断标准、复杂格式输出习惯,或者某类稳定能力,就可能需要微调。
可以这样区分:
| 问题 | 更适合 |
|---|---|
| 知识会更新 | RAG |
| 需要引用来源 | RAG |
| 企业内部资料问答 | RAG |
| 输出风格长期固定 | 微调 |
| 专业能力不足 | 微调 |
| 特定任务大量样本训练 | 微调 |
一个类比是:RAG 像开卷考试,把资料翻出来再答;微调像系统学习,让模型真正形成某种能力。
FAISS 能不能做增量更新
可以。
代码里常见的创建方式是:
python
knowledgeBase = FAISS.from_texts(chunks, embeddings)这是从文本块创建知识库。
后续如果 Wiki、文档库或业务资料每天增量更新,可以把新增文档解析、切分、向量化,再追加到 FAISS 索引里。
真实业务里一般还要维护这些信息:
- 文档 ID
- chunk ID
- 版本号
- 更新时间
- 来源系统
- 权限标签
- 是否删除或失效
如果只是追加不删除,系统会越来越脏。要支持"每日自动增量更新",最好把索引更新和元数据管理一起设计。
Agent 和 RAG 的关系
RAG 不是 Agent 的全部,它只是 Agent 的一个能力模块。
可以用这个公式理解:
text
Agent = LLM + RAG(记忆) + Tool(Function Call / MCP / Skill)RAG 提供知识和记忆,Tool 提供行动能力,LLM 负责任务理解、规划和生成。
例如一个企业知识助手:
- RAG 负责查制度、查文档、查历史工单。
- Web Search 负责查外部实时信息。
- Function Call 负责调用内部系统。
- LLM 负责判断该查什么、怎么组织答案、是否需要继续调用工具。
所以 RAG 是 Agent 的重要组成部分,但不是全部。
几个容易混淆的问题
LLM 和 Embedding 都会处理向量,区别在哪里
LLM 和 Embedding 模型都会在内部使用向量表示,但目标不同。
LLM 的目标是生成答案,可以理解为主力推理模型。它要根据上下文理解问题、组织语言、推理步骤,并输出自然语言结果。常见训练流程会包含预训练、监督微调、偏好对齐或强化学习。
Embedding 模型的目标不是生成回答,而是把文本映射成一个固定维度的向量,例如 1024 维、1536 维或其他维度。它主要服务于相似度计算,帮助系统从大量文本里快速过滤出相关内容。
所以在 RAG 里,Embedding 更像"过滤模型",LLM 更像"回答模型"。
text
query
-> query embedding
-> 向量相似度检索
-> 找到相关 chunks
-> chunks + query 交给 LLM
-> 生成回答Qwen 的 Embedding 必须搭配 Qwen 的 LLM 吗
不必须。
Embedding 模型和 LLM 可以分开选。比如:
text
Embedding:Qwen / BGE / text-embedding
LLM:Qwen / DeepSeek / Claude / OpenAI / 其他模型只要流程上能跑通,向量维度、接口格式、上下文拼接方式没有问题,就可以组合使用。
常见搭配是:用一个适合中文语义检索的 Embedding 模型负责召回,再用一个回答质量更好的 LLM 负责最终生成。
word2vec 和现代 Embedding 模型是什么关系
word2vec 是 Google 较早提出的一类词向量技术,主要把"词"表示成向量。
现代 Embedding 模型更强,通常可以处理句子、段落、文档片段,甚至跨语言、代码、多模态内容。RAG 里更常用的是现代文本 Embedding 模型,而不是直接用传统 word2vec 来做完整知识库检索。
可以粗略理解:
text
word2vec:偏词级别向量
现代 Embedding 模型:偏句子、段落、文档语义向量Query 里有指令,Embedding 会不会自动去掉
一般不会。
Embedding 模型本身主要做向量空间映射,不会像人一样主动理解"哪一部分是信息,哪一部分是指令",也不会天然删除用户的输出格式要求。
比如用户问:
text
帮我查看自行车是哪年发明的?用不超过 200 字回复,回复用英文。这里既有信息需求,也有输出指令。
检索阶段真正需要的是:
text
自行车是哪年发明的而"用不超过 200 字回复""回复用英文"更适合留给生成阶段。实际系统可以在 query 改写阶段把检索问题和生成指令拆开:
text
检索 query:自行车发明年份
生成约束:不超过 200 字,用英文回答有些 Agent 框架会内置类似逻辑:检索时尽量只保留知识查询部分,生成时再使用输出格式要求。
RAG 和 Web Search 同时存在时,谁优先
如果问题属于企业内部知识,通常优先 RAG,因为内部知识库的资料更贴近业务,也更可控。
如果问题涉及实时信息,才更适合 Web Search。
如果两边都查了,可以按"知识质量"比较:
text
内部权威知识库
> 官方网站 / 官方公告
> 权威平台数据
> 普通网页Agent 里经常是这样运行的:
text
用户 query
-> 判断是否需要查内部知识库
-> 判断是否需要调用 Web Search
-> 合并不同来源的信息
-> LLM 基于来源质量生成回答RAG 可以替代微调吗
不能完全替代。
RAG 能补知识,但不能真正提升模型能力。
如果只是让模型知道公司制度、产品说明、客服流程,RAG 很合适,因为这些知识会变、需要引用来源、还可能有权限限制。
如果希望模型长期掌握某种能力,例如稳定的专业判断、固定写作风格、大量同类任务的输出格式,微调会更合适。
一个更直观的类比是:
text
RAG:开卷考试,先查资料再回答。
微调:系统学习,让模型形成稳定能力。PDF、Word 里有图片和公式,怎么做 RAG
如果文档里只有普通文字,直接解析文本再切分就可以。
但如果文档里有图片、扫描件、图表、公式,就不能只依赖文本解析。常见处理方式包括:
- OCR:把图片里的文字识别出来。
- 公式识别:把公式转成 LaTeX 或可读文本。
- 图表摘要:让模型描述图表表达的信息。
- 多模态 Embedding:把图片本身也转成向量。
- 元数据保留:保存页码、图片位置、原始文件名,方便回溯。
如果只是把 PDF 里的纯文本抽出来,图片和公式信息会丢失。复杂文档要把"文本内容"和"视觉内容"都纳入处理流程。
问答对知识库也能做 RAG 吗
可以。
如果知识库本来就是问答对:
text
<question, answer>可以把问题、答案或"问题 + 答案"一起向量化。用户提问时,先找最相似的历史问题或答案,再把命中的内容交给 LLM。
还可以做两个方向的增强:
text
query2doc:根据用户问题生成可能相关的文档描述,再去检索。
doc2query:提前为文档生成可能被用户问到的问题,再存入知识库。这样能提升召回率,尤其适合 FAQ、客服知识库、工单知识库。
chunk 太碎,怎么保留上下文逻辑
普通 RAG 按 chunk 检索,确实容易把文档切碎。用户问一个需要前后逻辑的问题时,单个 chunk 可能不够。
可以考虑几种办法:
- 调整 chunk_size 和 chunk_overlap,让相邻内容有重叠。
- 保存章节标题、页码、父文档 ID 等 metadata。
- 检索命中一个 chunk 后,把前后相邻 chunk 一起带上。
- 用层级检索,先找章节,再找段落。
- 用 GraphRAG,把 chunk 和 chunk 之间的关系建成图。
核心思路是:检索不只是找"一个最像的片段",还要把这个片段放回原来的文档结构里理解。
出现幻觉就一定要换模型吗
不一定。
先检查三件事:
- 检索结果是否正确。
- prompt 是否要求模型基于资料回答。
- 上下文里是否堆积了错误信息或过时信息。
长会话里错误会累计,所以一个会话用太久后,可以开启新会话,并重新执行 RAG 检索。很多时候问题不在模型本身,而在上下文污染、检索偏差或指令不清楚。
实战检查清单
做一个可用的 RAG 系统,可以按下面这张清单检查。
知识库阶段
- 文档来源是否权威?
- 文档是否需要定期更新?
- PDF、Word、网页、表格是否能稳定解析?
- 页码、标题、来源链接是否保存到 metadata?
- 是否需要去重、清洗页眉页脚?
切分阶段
- chunk_size 是否合适?
- chunk_overlap 是否足够?
- 是否切断了关键语义?
- 表格、代码、列表是否被切乱?
检索阶段
- Embedding 模型是否适合中文和业务场景?
- Top-K 设置是否合理?
- 是否需要关键词检索和向量检索结合?
- 是否需要 rerank?
- 是否做了权限过滤?
生成阶段
- prompt 是否要求基于资料回答?
- 回答是否引用来源?
- 找不到资料时是否会拒答?
- 是否区分事实回答和推测?
- 是否限制输出格式?
评估阶段
- 有无测试问题集?
- 检索命中率怎么样?
- 回答是否忠实于原文?
- 是否存在敏感信息泄露?
- 延迟和成本是否可接受?
js
原始文档
↓
文档解析 / 清洗 / 去重
↓
切分 chunk
↓
生成 embedding
↓
存入向量库 / 搜索索引
↓
用户提问
↓
Query 改写 / Query 分析
↓
向量召回 + 关键词召回
↓
权限过滤
↓
Rerank
↓
取 Top-K 文档
↓
构造 Prompt
↓
LLM 基于资料生成答案
↓
引用来源 / 格式化输出
↓
评估与优化总结
RAG 的核心不是"把文档丢给大模型",而是把知识变成一个可检索、可更新、可溯源、可控权限的系统。
可以记住这些点:
- Prompt 解决"没问清楚",RAG 解决"缺背景知识",微调解决"能力不足"。
- RAG 分成 Indexing、Retrieval、Generation 三段。
- Embedding 模型负责召回,Rerank 模型负责精排,LLM 负责生成。
- chunk 切分会直接影响检索质量。
- FAISS 适合做本地向量检索,能支撑知识库问答原型。
- LangChain 可以少造轮子,但底层流程要先理解。
- Query 改写能明显提升检索命中率。
- 实时信息应该走 Web Search,不要硬塞进静态知识库。
- 权限控制要做硬约束,不能只靠 prompt。
- RAG 是 Agent 的知识和记忆模块,不是 Agent 的全部。
把这条链路跑通以后,再去看 LangChain、Qwen-Agent、MCP、企业知识库、智能客服、运维助手,就会清楚很多。