今天继续和大家聊聊,我们开源的 pxcharts-vue 多维表格的诞生故事。
开源地址:github.com/MrXujiang/p...
演示地址:test.admin.mvtable.com/mvtable
一、开篇:那个写不动代码的凌晨
记得是5年前的一个夜晚,凌晨两点左右,我对着第46个几乎相同的表单页面发呆。
需求文档上写着:"再做一个支持关联查询的动态表格,下周上线。"
我机械地复制着上一版的CRUD代码,改字段名、调接口、写校验。Vue文件超过1000行,methods里塞着十几个功能相似但不敢重构的方法------怕牵一发而动全身。
这是我做全栈的第5年。从Vue2到Vue3,从jQuery到React,技术栈在升级,但日常还是改不完的表单、写不完的列表、调不完的接口。
我自嘲是"高级CRUD工程师",但那个凌晨,我真的写不动了。
不是身体累,是认知上的绝望:我知道接下来的5年,如果继续这样"人肉搬砖",只会从"写不动"变成"不敢写"------新技术层出不穷,而我被困在业务逻辑的重复劳动里。
转机出现在三年后。
Cursor 的Agent模式刚更新,我抱着"试试又不会死"的心态,把曾经折磨我两周的多维表格需求丢给了AI。
经过3天多和AI辩证推演之后,pxcharts-vue 的核心架构跑通了。我盯着屏幕上自动生成的Composition API代码,第一反应不是兴奋,是后怕------如果AI早来两年,我这5年到底在忙什么?
这篇文章,是我作为"全栈老兵"的AI编程账本。不吹不黑,只记录真实的效率数字、踩过的坑、以及那个凌晨之后,我对职业价值的重新思考。
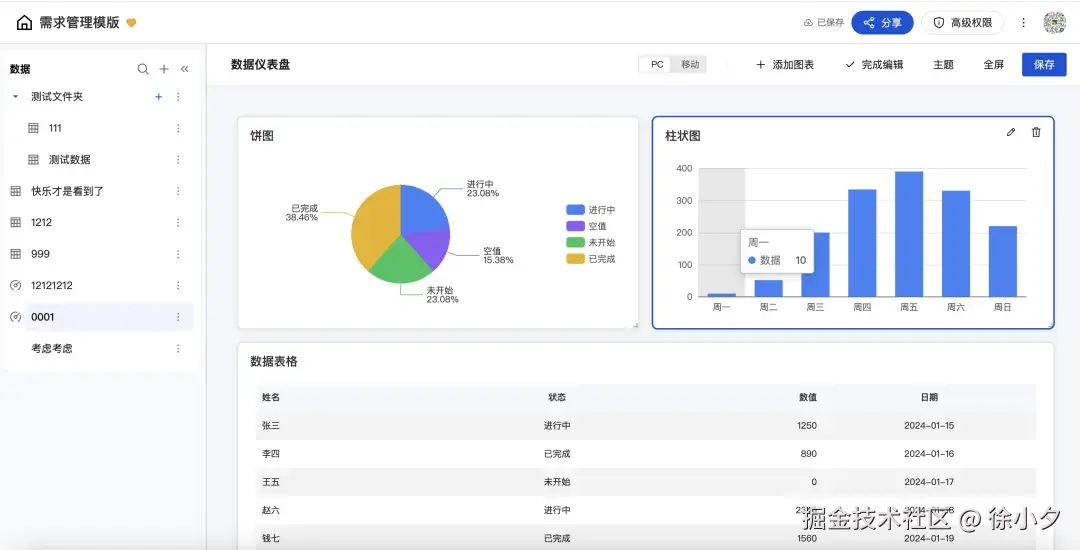
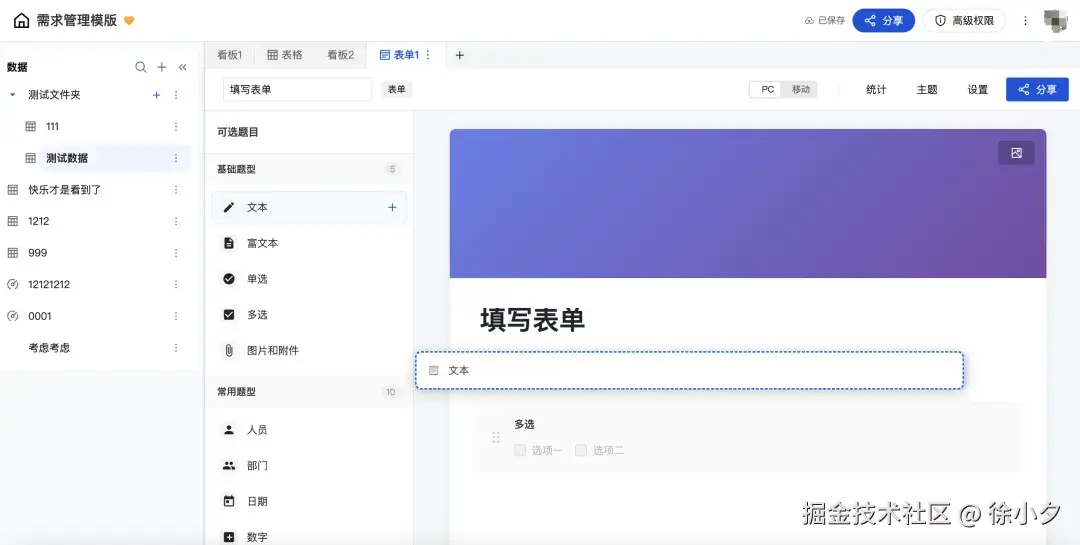
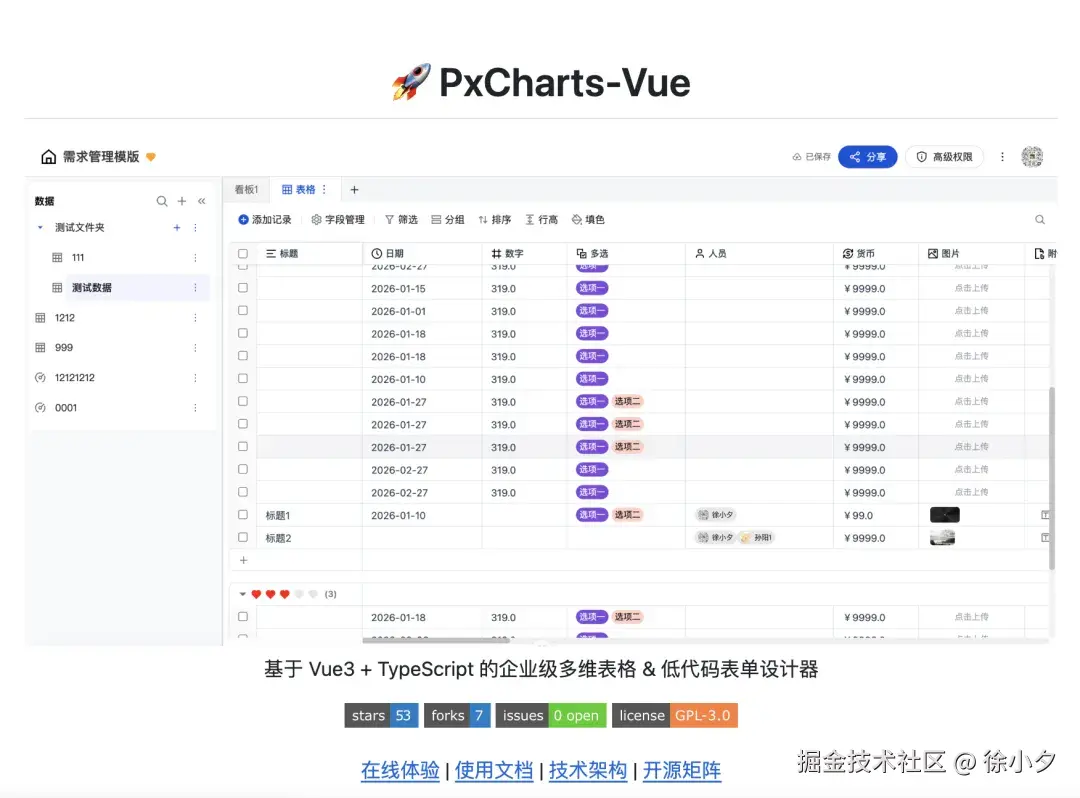
二、产品画像:pxcharts-vue是什么?(技术人的"复仇工具")
先介绍这次"复仇"的成果。pxcharts-vue 不是又一个Element Plus的封装,而是面向复杂业务场景的"关系型多维表格引擎" 。
它解决的是我5年来反复遇到的三个痛点:
1. 平面表格 vs 立体数据
传统表格是Excel思维:行是记录,列是属性。但真实业务是关系型的------订单关联客户、任务关联项目、SKU关联SPU。我们用"关联列"把这种关系可视化:选客户时自动带出合同,选商品时自动填充价格,底层是外键约束,表层是下拉选择。
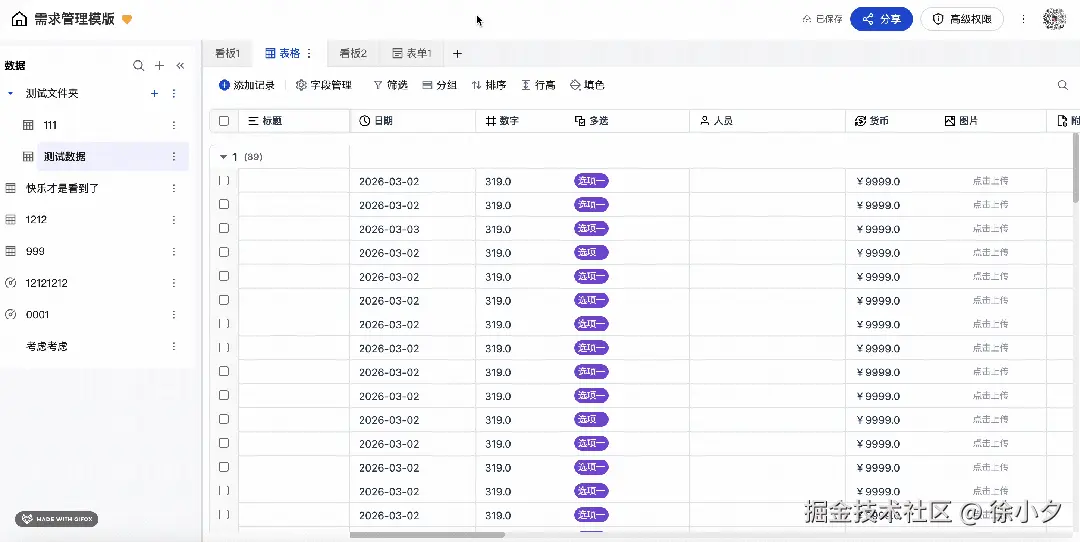
这 revenge 了我过去写过的无数遍onChange联动逻辑。
在多维表格设计中,我们完全对标了钉钉AI表格和飞书多维表格的字段设计,实现了多种表格业务字段,并支持随时编辑修改:
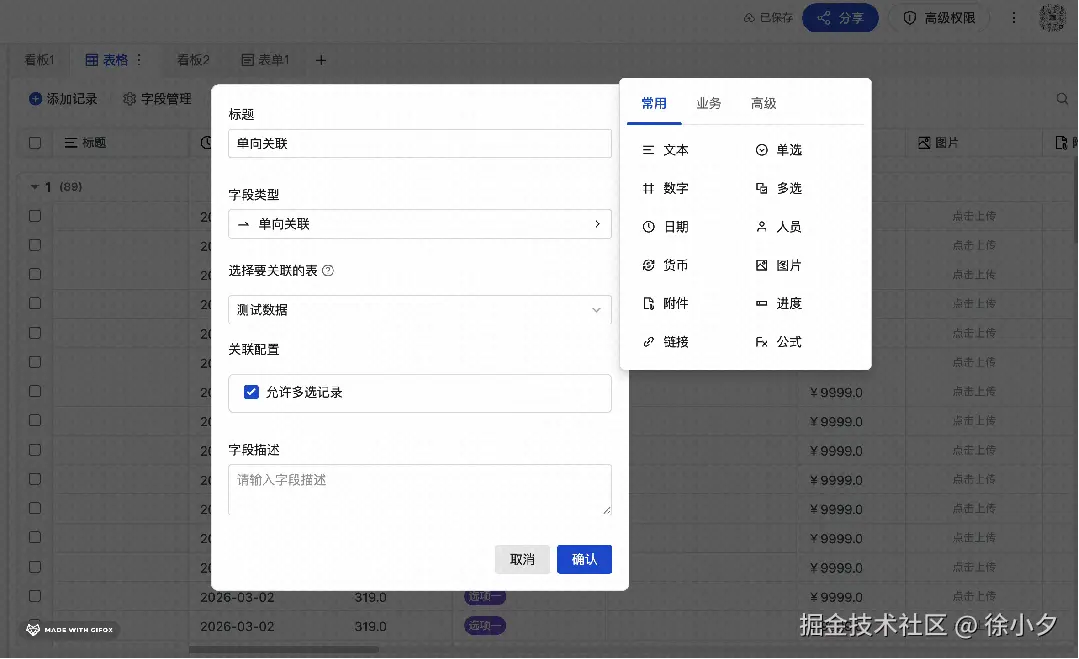
当然有些字段比较复杂,AI无法完全理解和实现,其中40%的工作量是我们手敲代码实现的。
2. 一份数据,多种视角
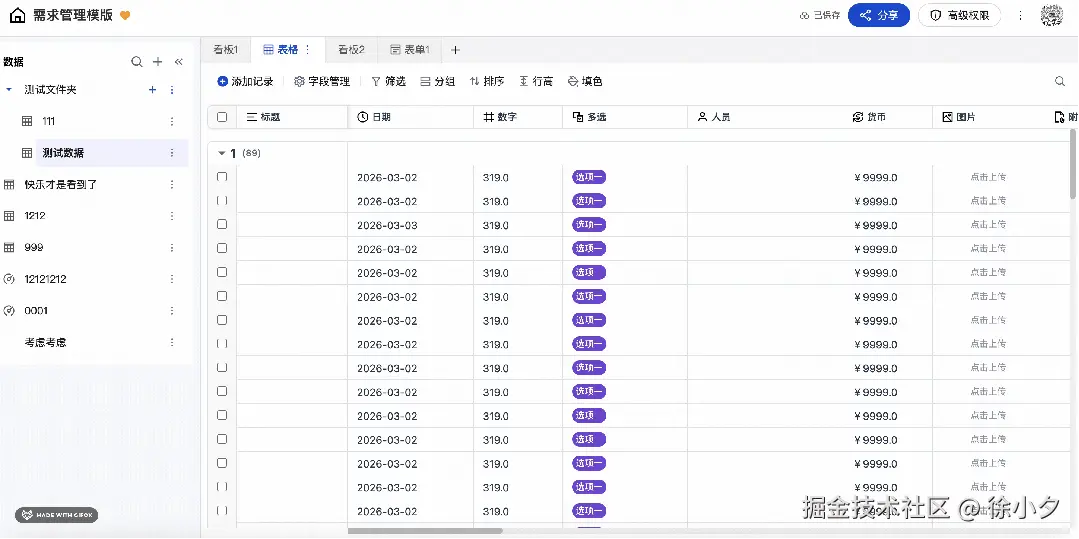
同一份项目数据,产品经理要看甘特图,运营要看看板,财务要看表格汇总。pxcharts-vue 实现了视图层与数据层解耦:底层是统一的数据模型,上层是表格、看板、表单等渲染适配器。
这 revenge 了我过去为"换个展示方式"而写的冗余接口。
3. 公式字段:把Excel能力Web化(React版本中实现了)
支持跨表引用、聚合计算、条件判断,非技术用户能配出"自动计算提成"的复杂逻辑。对于开发者,这意味着业务规则从后端Java代码前移到了前端配置层,需求变更不用重新部署。
这 revenge 了我过去凌晨两点还在改的"紧急加字段"需求。
技术栈:Vue3 + TypeScript + Vite,纯前端实现,零后端依赖,开箱即用。
三、复仇实录:一周重构的流水线与真实账本
这次开发全程在Cursor Composer的Agent模式下完成,我们自己研发的工作量占比40%。
我记录了一套"老兵式AI协作流"------不是盲目信任,是有策略地外包。
plan 1:架构设计(从"人肉画图"到"对话式架构")
过去的我: 打开Draw.io画组件关系图,纠结半小时目录结构,再花2小时搭Vite脚手架。
AI模式:
xml
我:基于Vue3实现一个多维表格内核,需要支持列定义、数据编辑、视图切换,采用模块化架构,优先使用Composition API和<script setup>语法。Cursor:生成项目结构 + 核心类型定义 + 基础组件框架耗时:30分钟 vs 过去的4小时。
关键干预: 强制要求AI先生成ARCHITECTURE.md设计文档,确认模块边界后再生成代码。这是从"边想边写"的混乱中保留下来的人类架构师尊严。
plan 2:核心功能(关联列与视图系统)
关联列功能:
css
我:需要实现表与表之间的关联,类似数据库外键约束,支持多选、级联筛选、自动回填。Cursor:生成基于Proxy的响应式关联逻辑 + 选择器组件 + 数据联动机制过去需要2天,现在4小时。 但AI生成的第一版用了递归遍历,大数据量时卡顿明显。我要求它改用虚拟滚动+懒加载 ,它给出了基于vue-virtual-scroller的优化方案。
视图系统: AI建议使用策略模式 管理不同视图,我确认方案后,它生成了TableStrategy、KanbanStrategy、GanttStrategy三个类,统一实现render()接口。
耗时:6小时 vs 过去的3天。
plan 3:公式引擎与边界加固
这是最复杂的模块。我采用Plan Mode:
- 先让AI出《公式引擎设计文档》:语法解析(PEG.js)、沙箱执行(Web Worker)、错误处理机制
- 人工Review确认安全方案(禁用eval,使用白名单函数)
- 再让AI生成代码
发现的问题: AI生成的初始版本用了new Function()执行公式,我立即叫停------这是XSS漏洞温床。CodeRabbit 的研究证实,AI代码引入安全漏洞的概率是人类代码的2.74倍。最终改用受限沙箱+语法树解析。
耗时:1.5天 vs 过去的5天。
效率账本(真实数字)
| 环节 | 传统开发(第5年的我) | AI辅助开发(复仇模式) | 效率倍数 |
|---|---|---|---|
| 脚手架与架构 | 3天 | 2小时 | 8x |
| 关联列逻辑 | 3天 | 1天 | 3x |
| 视图切换系统 | 5天 | 1天 | 5x |
| 公式引擎 | 5天 | 1天 | 5x |
| 安全加固与优化 | 2-3天 | 1天 | 2x |
| 总计 | 18-20天 | 4.2天 | 4x |
整体效率提升约230% ,与GitClear对高AI使用率开发者的调研数据(4-10倍产出提升)基本吻合。
当然客观的说,我们工程师也花了大概30%-40%的经历攻克AI无法解决的问题,但是AI Coding的整体提效还是很显著的。
四、账本B面:AI编程的隐性成本与"复仇"的代价
但这不是爽文。
一周交付的背后,我们付出了传统开发不会有的代价。这是账本必须记录的B面。
1. 安全债务:AI的"自信"是危险的
pxcharts-vue 初期版本中,AI生成的表格解析渲染器存在原型链污染漏洞------它从某个Stack Overflow回答中学到了"巧妙"的对象合并技巧,但那是有安全缺陷的过时方案。
CodeRabbit 分析了数百万行AI生成代码,发现:
- 引入XSS漏洞的概率:人类代码的2.74倍
- 硬编码机密信息的概率:人类代码的2.1倍
我的对策: 核心安全模块(公式沙箱、数据校验)必须人工Review,AI仅辅助生成单元测试用例。
2. 可维护性陷阱:你成了"代码陌生人"
Day 2下午,AI生成了50行复杂的视图切换逻辑。当时我看懂了大意,觉得"没问题"。一周后回看,我盯着那团递归+闭包的组合,完全想不起来为什么这样写、边界条件是什么。
GitClear的研究警告:AI辅助代码的撤销率(Churn rate)比人类代码高40% ,意味着更多返工。
我的对策: 强制要求AI生成 "逻辑注释" ------不是解释语法,而是解释设计决策("为什么用递归而非迭代""此处假设数据量小于1万条")。关键算法必须人工复述原理,确保"我懂我的代码"。
3. 架构一致性危机:AI的"创意"是混乱的
不同会话的AI会给出风格迥异的方案。早期关联列用Options API,后期视图系统被建议改成Composition API,导致代码风格混杂------就像一个项目里有5个不同架构师的手笔。
我的对策: 建立《AI编程规范文档》(.cursorrules),固化:
- 技术栈:Vue3 +
<script setup>+ TypeScript严格模式 - 设计模式:优先组合式函数,类仅用于策略模式
- 命名规范:组件PascalCase,组合式函数useXxx,工具函数纯函数优先
这让AI在约束内发挥,而非"自由创作"。
4. 幻觉税:为AI的"自信"买单
视图切换的虚拟滚动功能,AI生成的代码在1000条数据时完美运行,10000条时白屏。它没有考虑内存溢出边界,也没有提示"此处需要性能测试"。
这类问题只能靠人工测试发现。AI编程省下的时间,部分要返还到更严格的测试环节。
五、老兵的新战场:AI时代,全栈工程师该专注什么?
pxcharts-vue 开源后,我一直在想:如果AI能写代码,我这5年积累的经验还有什么价值?答案在开发过程中逐渐清晰------
1. 从"实现者"到"架构守门员"
AI擅长生成"能跑的代码",但不懂业务领域的架构权衡。
pxcharts-vue 的数据模型设计(平面表 vs 树形结构)、状态管理方案(Pinia vs 纯响应式)、视图渲染策略(Canvas vs DOM),这些决策需要人类对业务场景的深度理解。
新角色: 不是写代码,是设计代码的生成规则。
凭借我之前在大厂做技术架构的经验,我能很快给出AI高效的架构和解决思路,所以这也要求我们有一定的技术背景,才能更好的让AI为我们服务。
2. 从"调试bug"到"设计防错机制"
AI代码的bug更隐蔽------它很少犯语法错误,但常犯逻辑假设错误("假设用户不会同时编辑两个单元格")。我的新工作是预判这些假设,在设计阶段就加入防御性机制。
新角色: 不是修bug,是设计让bug无法发生的系统。
3. 从"技术执行"到"AI流程设计"
这次3天重构,真正的生产力提升不是来自Cursor本身,而是我设计的分层协作流程:
- 生成层(工具函数):100%信任AI
- 业务层(组件逻辑):AI生成+人工Review,70%信任
- 核心层(公式引擎):AI辅助设计,人工实现,30%信任
新角色: 不是写代码,是设计人机协作的流水线。
六、开源的思考:不止于代码,是"复仇经验"的共享
选择开源 pxcharts-vue,除了技术分享,我还想验证一个假设:AI编程时代,开源的价值会从"代码"转向"流程" 。
传统开源是"拿我的代码用",未来可能是"拿我的Prompt用"------如何让AI生成高质量的Vue3组件?如何设计安全的公式引擎?如何避免我踩过的坑?
我后续会分享《pxcharts-vue AI开发手册》,包含:
- 架构设计、高性能表格技术实践
- 安全审计清单(AI代码常见漏洞模式)
- 性能优化策略(虚拟滚动、大数据渲染、内存管理)
如果你也在用AI编程工具,欢迎来 留言区 交流。
我们可以一起探索:当AI成为标配,人类开发者的"复仇"该指向什么?
结语:账本结算,复仇之后
5年前那个凌晨两点写不动代码的我,不会想到三年后会写下这篇文章。
pxcharts-vue 的一周重构,是效率的胜利,也是一次职业价值的重新校准。AI编程确实"复仇"了CRUD的重复劳动,但它也暴露了人类开发者的软肋------我们过去引以为傲的"编码速度",在AI面前不值一提。
新的竞争力 在于:架构设计的品味、安全风险的嗅觉、人机协作的智慧,以及对自己代码的深刻理解。