GridFS 是用于存储和检索超过 BSON 文档大小限制 16 MiB 的文件 的规范。
GridFS 并不是将文件存储在单个文档 中,而是将文件拆分 为多个部分或数据块 ,并将每个数据块存储为单独的文档。默认情况下,GridFS 使用默认大小 255 KiB 的数据块;换言之,GridFS 将文件分割为 255 KiB 的数据块,最后一个数据块除外。最后一个数据块的大小以实际需要为准。类似地,不大于数据块的文件仅具有最后一个数据块,仅使用所需的空间以及一些附加元数据。
GridFS 使用两个集合 来存储文件。一个集合存储文件数据块 ,另一集合则存储文件元数据。
GridFS 将文件存储在两个集合中:
- chunks 存储着二进制数据块
- files 存储文件的元数据
GridFS 通过为每个集合添加一个存储桶名称前缀,从而将这些集合放置在一个通用存储桶中。默认情况下,GridFS 使用两个集合以及带名为 fs 的存储桶:
- fs.files
- fs.chunks
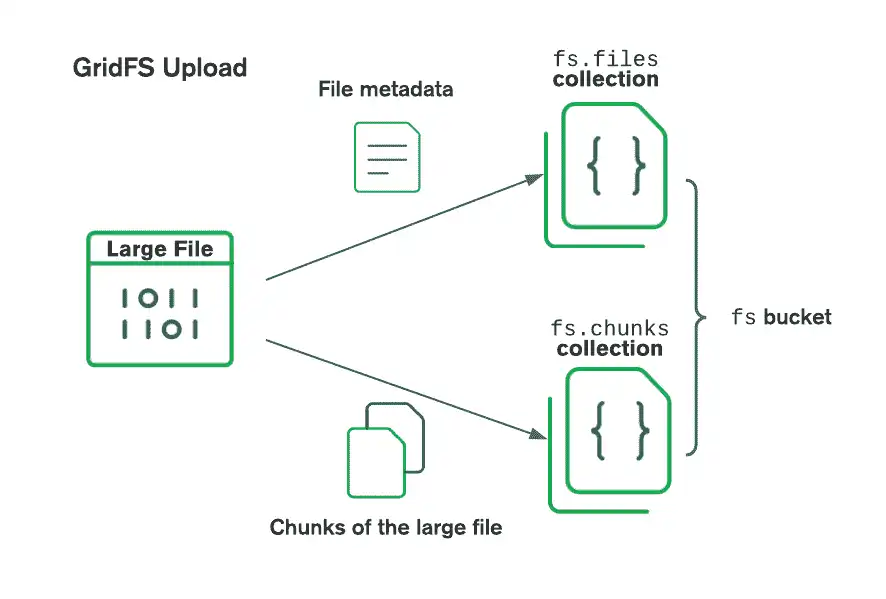
上传文件时 :
使用 GridFS 存储文件时,驱动程序会将文件拆分成较小的数据块,每个数据块由 chunks 集合中的单独文档表示 。它还在 files 集合中创建文档,其中包含文件 ID、文件名和其他文件元数据。
检索文件时:
在检索文件时,GridFS 从指定存储桶上的 files 集合中获取元数据 ,并使用该信息通过 chunks 集合中的文档重建文件。您可以将文件读取到内存中,或者将其输出到流。
chunks 集合
chunks 集合中的每个文档都代表文件中的不同数据段,如 GridFS 中所示。此集合中的文档具有以下形式:
bash
{
"_id" : <ObjectId>,
"files_id" : <ObjectId>,
"n" : <num>,
"data" : <binary>
}chunks 集合中的文档包含以下字段:
chunks._id
该数据段的唯一 ObjectId。
chunks.files_id
在 files 集合中指定"父"文档的 _id。
chunks.n
数据块的序列号。GridFS 会对所有数据块进行编号,编号从 0 开始。
chunks.data
该数据段的有效负载为 BSON Binary类型。
files 集合
files 集合中的每个文档均代表 GridFS 中的一个文件。
bash
{
"_id" : <ObjectId>,
"length" : <num>,
"chunkSize" : <num>,
"uploadDate" : <timestamp>,
"md5" : <hash>,
"filename" : <string>,
"contentType" : <string>,
"aliases" : <string array>,
"metadata" : <any>,
}files 集合中的文档包含以下部分或全部字段:
files._id
此文档的唯一标识符。_id是您为原始文档选择的数据类型。MongoDB 文档的默认类型是 BSON ObjectId。
files.length
文档的大小(以字节为单位)。
files.chunkSize
每个数据块的大小(以字节为单位)。GridFS 将文档划分为大小为 chunkSize 的数据块,但最后一个除外,它的大小视需要而定。默认大小为 255 kibibytes (KiB)。
files.uploadDate
GridFS 首次存储该文档的日期。该值的类型为 Date。
files.md5
已弃用
FIPS 140-2 禁止使用 MD5 算法。MongoDB 驱动程序已弃用 MD5 支持,并将在未来版本中删除 MD5 生成。需要文件摘要的应用程序应在 GridFS 外部实施文件摘要,并将其存储在 files.metadata 中。
filemd5 命令返回的完整文件的 MD5 哈希值。该值为String类型。
files.filename
可选。GridFS 文件的人类可读名称。
files.contentType
已弃用
可选。GridFS 文件的有效 MIME 类型。仅供应用程序使用。
使用 files.metadata 来存储与 GridFS 文件的 MIME 类型相关的信息。
files.aliases
已弃用
可选。别名字符串数组。仅供应用程序使用。
使用 files.metadata 来存储与 GridFS 文件的 MIME 类型相关的信息。
files.metadata
可选。元数据字段可以是任何数据类型,并且可以保存您想要存储的任何附加信息。如果您希望向 files 集合中的文档添加其他任意字段,请将它们添加到元数据字段中的对象中。