view space Z也就是 camera forward 方向的深度,而不是
length(viewPos)
这在 大 FOV 或斜角观察时 会导致 rim 厚度变化。
"边缘判定的度量空间"变了。
之前你的逻辑大致是:
-
采中心点
rawDepth -
采左/右/上/下
rawDepthLeft/Right/Up/Down -
做差:
当前像素和四邻域在 硬件深度缓冲值 上差多少。"这个量的问题是它在透视投影下是非线性的。近处一点点实际距离变化,映射到 zbuffer 里可能很大;远处很大实际距离变化,映射到 zbuffer 里可能很小。
原来你测的是:
"depth buffer 数值跳没跳"。
现在你测的是:
"相机前向距离跳没跳"。
这两者在工程语义上差很多。
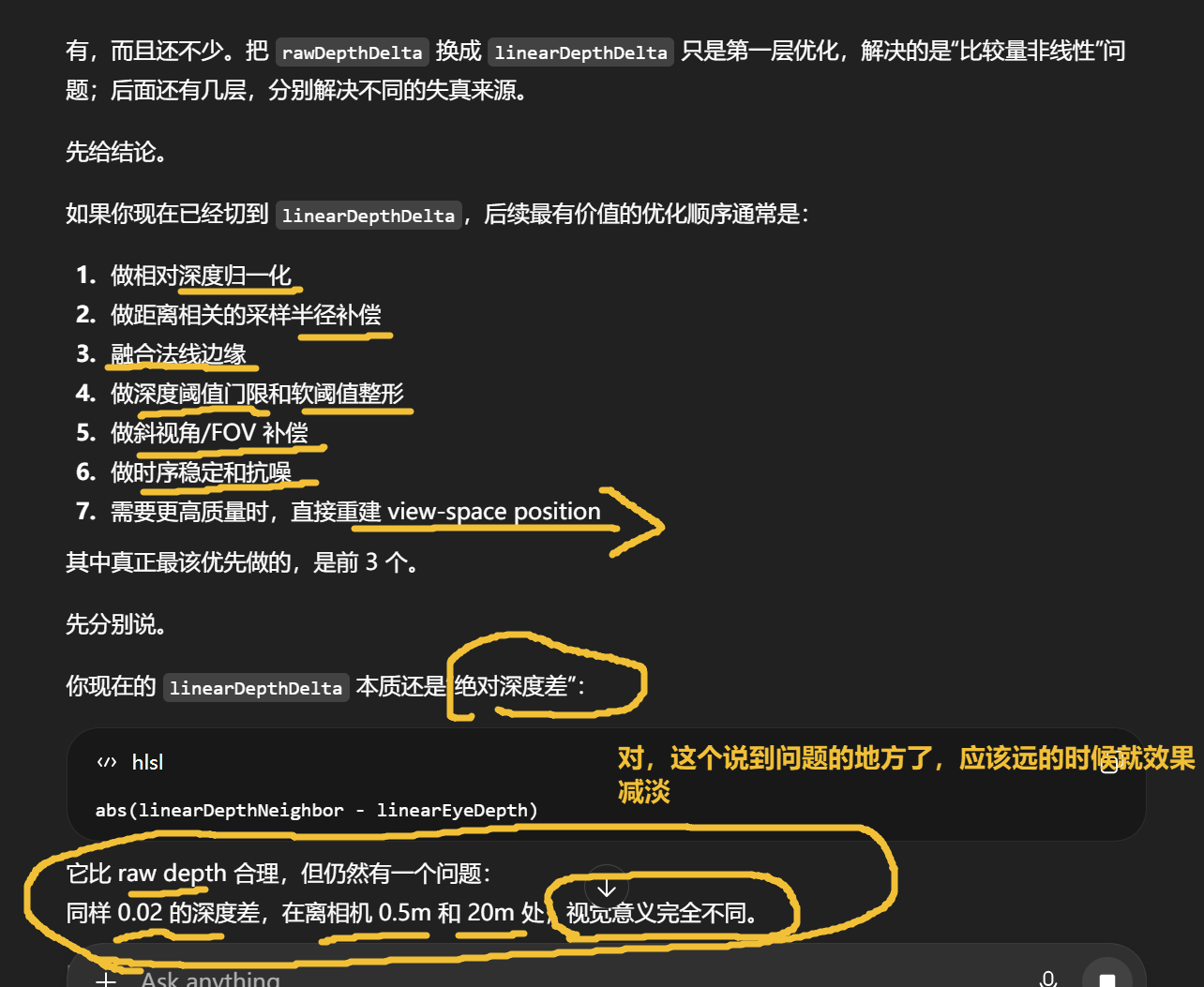
rawDepthDelta
是 GPU 深度缓冲里的差值。
它更接近"投影后 z 曲线上的变化量"。
linearDepthDelta
是线性视空间 Z 差值。
它更接近"这个像素和邻居离相机前后差了多少米"。
当然严格说不一定是"米",取决于你场景单位,但语义上就是视空间距离差。
depth discontinuity 的空间频率
half-resolution buffer 做 edge detection,然后再 upsample?GPU cache localitydepth discontinuity frequency
在 URP 里,_CameraDepthTexture 的分辨率通常不是你单独给它设一个自定义值,而是主要受这些因素控制:
- Render Scale
- 最直接。
- URP Asset 里的 Render Scale 会影响相机渲染目标分辨率,depth texture 通常跟着变。
- 相机输出分辨率 / Game 视图分辨率
- 屏幕越大,depth texture 通常也越大。
- 动态分辨率 / Upscaling
- 开了动态分辨率或上采样,depth 的实际尺寸也可能跟着变化。
- Renderer 实现细节
- 某些平台/路径下 depth 可能和 color target 同尺寸,某些情况下会有内部差异,但一般你不单独手工指定。
所以结论是:
- 可以间接调
- 通常不是"给 _CameraDepthTexture 单独设宽高"
- 最常用手段是调 URP Render Scale
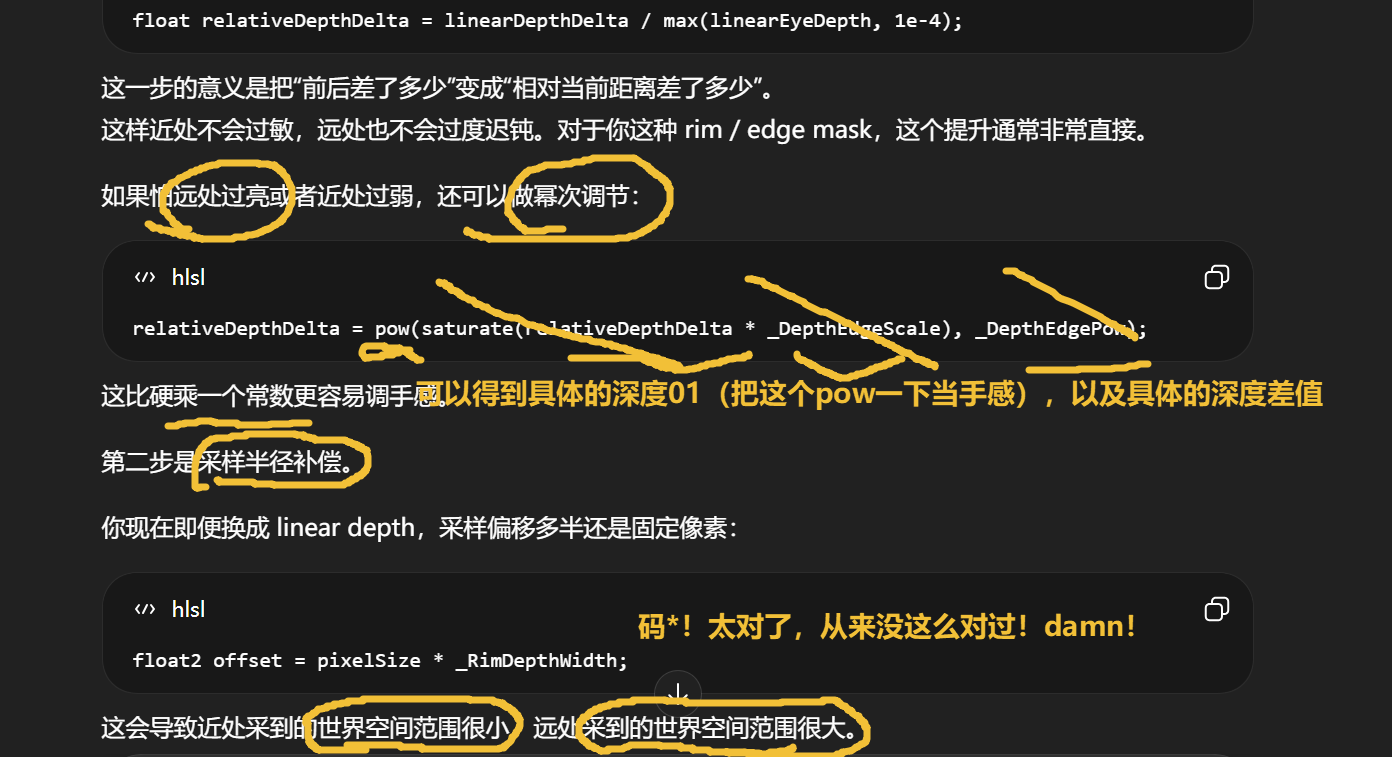
如果你的目的不是性能,而是让深度边缘更稳定,优先级通常是:
- 先用 linearDepthDelta
- 再做距离补偿
- 最后才考虑靠提高 depth 分辨率救边缘
因为分辨率提升只能缓解采样粗糙,不能解决算法本身的距离敏感性。
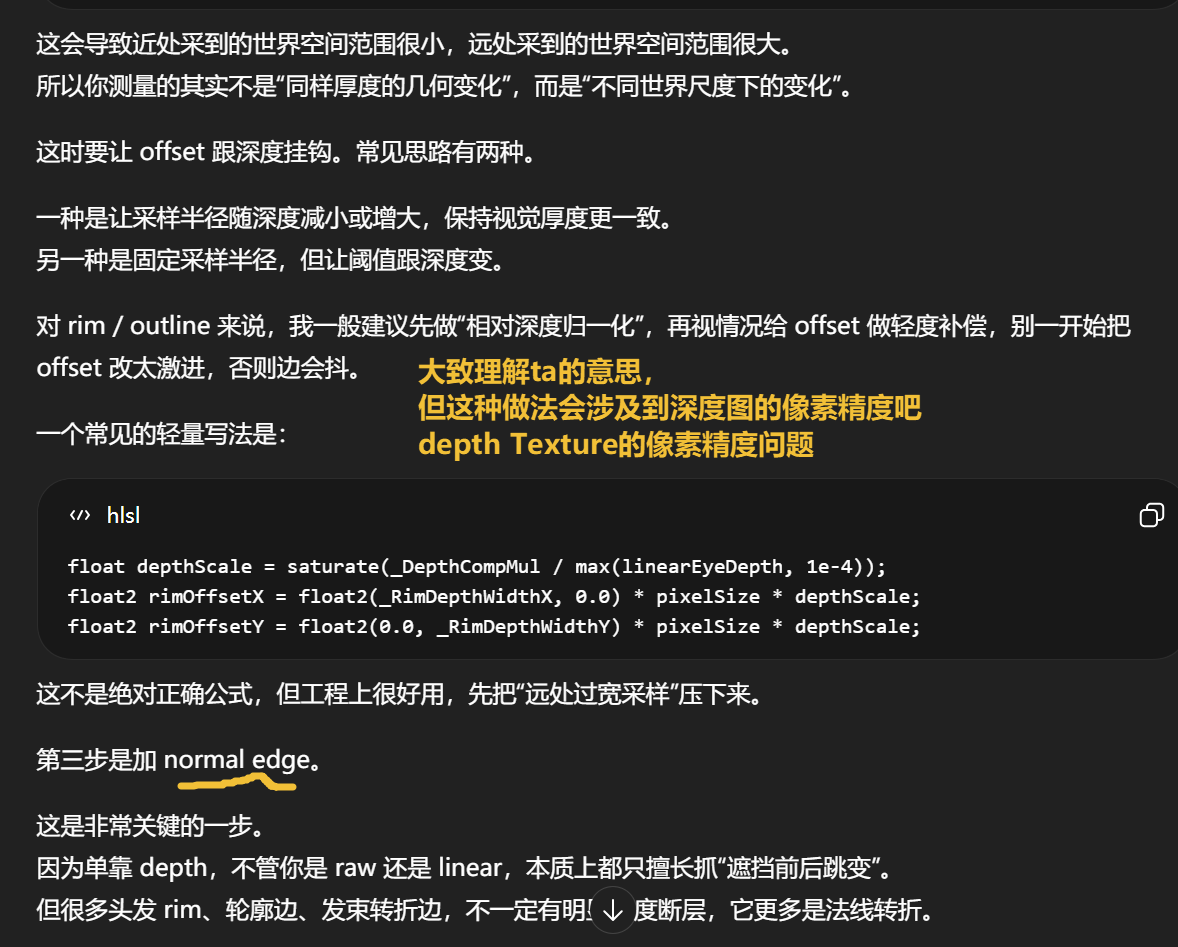
改采样半径能改变:对邻域深度变化的敏感范围
不能改变:远处物体只有很少屏幕像素时的信息缺失
不能仅凭这个 Named Attribute 节点就断定模型一定存在顶点色。
它只是"按名称读取属性"。如果属性不存在,Exists 会是 false,并且输出会是默认值。
你这个节点配置为:
-
Type:
Color -
Name:
Color
含义是:
在几何属性里读取一个名为 "Color" 的 attribute(通常就是顶点色)。
但注意两点:
-
Blender attribute 可以在 Vertex / Face Corner / Point / Instance domain 上
-
如果不存在,输出就是默认值
(0,0,0,1)(取决于上下游)
所以:
仅有这个节点 ≠ 一定存在 vertex color
Blender 里的顶点属性要先被导出成 Unity 认识的东西,shader 才能用。常见可用通道是:
- POSITION
- NORMAL
- TANGENT
- COLOR
- TEXCOORD0~7
- 有时还能借 blend weights / indices,但不建议乱用
所以实际流程是:
- 在 Blender 里把命名属性写入可导出的通道
- 导出 FBX/glTF
- Unity 导入后,这些数据变成 vertex color、uv2、uv3 之类
- shader 里从对应语义读取
最常用的映射方式
如果 Blender 属性是一个标量 mask:
如果 Blender 属性是一个向量方向:
Unity shader 里怎么读
如果你把 Blender 属性烘焙到了顶点色:
struct Attributes { float4 vertex : POSITION; float3 normal : NORMAL; float4 color : COLOR; float2 uv : TEXCOORD0; };
然后在顶点/片元里直接用:
float mask = v.color.r; float3 dir = v.color.rgb * 2.0 - 1.0;
如果你把 Blender 属性烘焙到了 UV2:
struct Attributes { float4 vertex : POSITION; float3 normal : NORMAL; float2 uv : TEXCOORD0; float4 uv2 : TEXCOORD1; };
读取:
float mask = v.uv2.x; float3 dir = float3(v.uv2.xy, 0.0);
如果是 UV3:
float4 uv3 : TEXCOORD2;
对应你这个 Blender 节点,推荐这样映射
从你前面的信息看,节点里至少有:
- Color
- UV0
- smoothnormalWS
建议映射为:
- Color -> Unity COLOR
- UV0 -> Unity TEXCOORD0
- smoothnormalWS -> Unity TEXCOORD1 或 TEXCOORD2
这样 shader 里可以写成:
struct AttributesOutline { float4 vertex : POSITION; float3 normal : NORMAL; float4 color : COLOR; float2 uv0 : TEXCOORD0; float3 smoothNormal : TEXCOORD1; };
然后:
float maskFromColor = v.color.r; float3 outlineDirOS = normalize(v.smoothNormal); float maskFromTex = SAMPLE_TEXTURE2D_LOD(_OutlineMaskTex, sampler_OutlineMaskTex, v.uv0, 0).r;
最关键的限制
如果你只是"在 Blender 里新建了一个 Named Attribute",但没有把它烘焙进导出格式支持的顶点通道,Unity 里是读不到的。
也就是说,这种写法在 Unity 里不存在:
ReadNamedAttribute("smoothnormalWS")
Unity 没这个能力。
它只认网格顶点缓冲里已经存在的流。
如何判断导入后有没有带进来
你可以在 Unity 里做最简单测试:
- 把属性先写进 vertex color
- shader 输出 color.rgb
- 如果模型显示出预期分布,说明导入成功
例如片元里临时写:
return float4(i.color.rgb, 1.0);
如果全黑,说明:
- 导出没带
- Unity 导入没保留
- 或你读错通道了
对你当前项目最实用的建议
如果是要复刻 Blender 那套 outline:
- mask 类属性写进 vertex color
- direction 类属性写进 uv2/uv3
- UV0 继续走原始纹理坐标
- shader 里不要依赖"属性名",只依赖语义通道
如果你要,我下一步可以直接:
- 告诉你 Blender 里怎么把 smoothnormalWS 烘焙到可导出通道
- 然后把 LaevatSkin.shader 改成实际读取 COLOR 和 TEXCOORD1 的 outline pass
从几个实际工程角度说明为什么常说"VS 不适合采样贴图"。
1. VS 没有像素导数(ddx / ddy)
像素着色器在纹理采样时依赖屏幕空间导数来确定 MIP Level:
LOD ≈ log2(max(|ddx|, |ddy|))
VS 中没有 ddx/ddy,因此:
-
Texture.Sample()在 VS 中通常会退化为 LOD0 或 driver heuristic。 -
如果纹理很大,会导致 明显的 aliasing 或 cache miss。
因此 VS 采样一般需要:
Texture.SampleLevel(sampler, uv, lod)
手动指定 LOD。
这会带来两个问题:
-
需要自己决定 LOD
-
不具备各向异性过滤
采样频率通常没有优势
很多人直觉认为:
VS invocation 比 PS 少 → 采样更便宜
但实际情况并不总是这样。
原因:
-
VS 是 per-vertex
-
PS 是 per-fragment
如果 mesh tessellation 很高,例如:
1M vertices
而屏幕覆盖只有:
300k pixels
那么 VS 采样反而更多。
现代 GPU(特别是 tile-based mobile GPU)在 PS 端有更好的 texture locality + cache reuse。
PS 具有明显的 2x2 quad coherence:
pixel quad
p0 p1
p2 p3
GPU 能预测邻近像素访问相邻 texel。
VS 通常访问是:
vertex order in index buffer
UV 分布往往是离散的,因此:
-
cache miss 更频繁
-
texture fetch latency 更高
插值丢失细节
VS 采样后传递给 PS:
float value = tex.SampleLevel(...);
output.value = value;
到 PS 会经过 线性插值:
interpolated_value
如果纹理变化很高频(例如 normal map / height map),会出现:
-
detail 丢失
-
shading artifact
PS 采样不会有这个问题。
VS latency 更难隐藏
一些技术里,VS 采样反而是正确的做法:
1. Heightmap / Vertex Displacement
典型例子:
terrain displacement
water waves
float h = heightTex.SampleLevel(sampler, uv, 0);
pos.y += h * scale;
只需要 低频数据。
Vertex Animation Texture (VAT)PS 有更好的 quad-based locality
关键点是 layout 一致性,不只是"声明过就行"。
在 Unity 的 SRP Batcher 体系下,UnityPerMaterial 的布局需要稳定。你现在 outline pass 虽然可能只真正用到:
-
_OutlineColor -
_OutlineWidth -
_OutlineZOffset
但如果这个 shader 其他 pass 的 UnityPerMaterial 已经包含一整套字段,那么为了避免不同 pass 对同一个 cbuffer 的解释不一致,实践上通常会让各 pass 使用相同的一份 UnityPerMaterial 声明。
所以你截图里把主 pass 的那一整串也写进来,本质是在保证:
-
同名 cbuffer
-
同字段顺序
-
同对齐布局
-
同 SRP Batcher 预期
第三,这不是为了"让 GPU 自动识别主 pass 的内存布局然后复用"那种意义上的"gpu布局",而是为了shader 编译期和运行时绑定的常量缓冲解释一致。
HLSL 常量缓冲自身的打包规则 。Unity / SRP Batcher 对 UnityPerMaterial 的约束。"布局"主要不是指 GPU cache line 或 wavefront occupancy 那种布局
-
cbuffer内字段的 offset / pack -
每个字段是否落在正确的 16-byte register slot
-
多个 pass 对同一个
UnityPerMaterial的 声明是否严格一致 -
是否产生了明显的 padding 浪费
-
是否把更新频率不同的数据混放在一起
以 16 字节为一个寄存器槽
常量缓冲可以理解为按 float4 槽位切分:
-
一个槽 = 16 bytes
-
变量会尽量往当前槽里塞
-
塞不下就开下一个 16-byte 槽
而:
hlsl
float3 a;
float2 b;
float3 后剩 4 字节,不够放 float2,所以 b 会跳到下一槽,于是有 padding。
所以一个最基本的审查动作是:
把每个字段按 16-byte slot 手工过一遍,看有没有明显的碎片。
第一原则:所有 pass 的 UnityPerMaterial 必须完全一致
这是最重要的 correctness 检查。你先不看节省空间,先看这件事。
一致的含义包括:
-
同一个
CBUFFER_START(UnityPerMaterial) -
字段名字一致
-
字段类型一致
-
字段顺序一致
哪怕只是:
-
某个 pass 少写了一个字段
-
某个字段从
float4改成half4 -
顺序换了
都可能让布局解释错位,进而导致运行时读错值,或者 SRP Batcher 退化。
这是"优秀布局"的第一条,不满足就直接不合格。
最稳的做法还是把它抽到一个公共 include 文件里,所有 pass 共用。
Frame Debugger 看 SRP Batcher 是否稳定命中直接看 DXIL / DXBC 反射信息。可以通过"Show compiled code"或导出平台 shader,再结合 DXC / DXIL reflection 工具看 buffer layout。对于熟悉 DX12 的人,这一步最可靠。
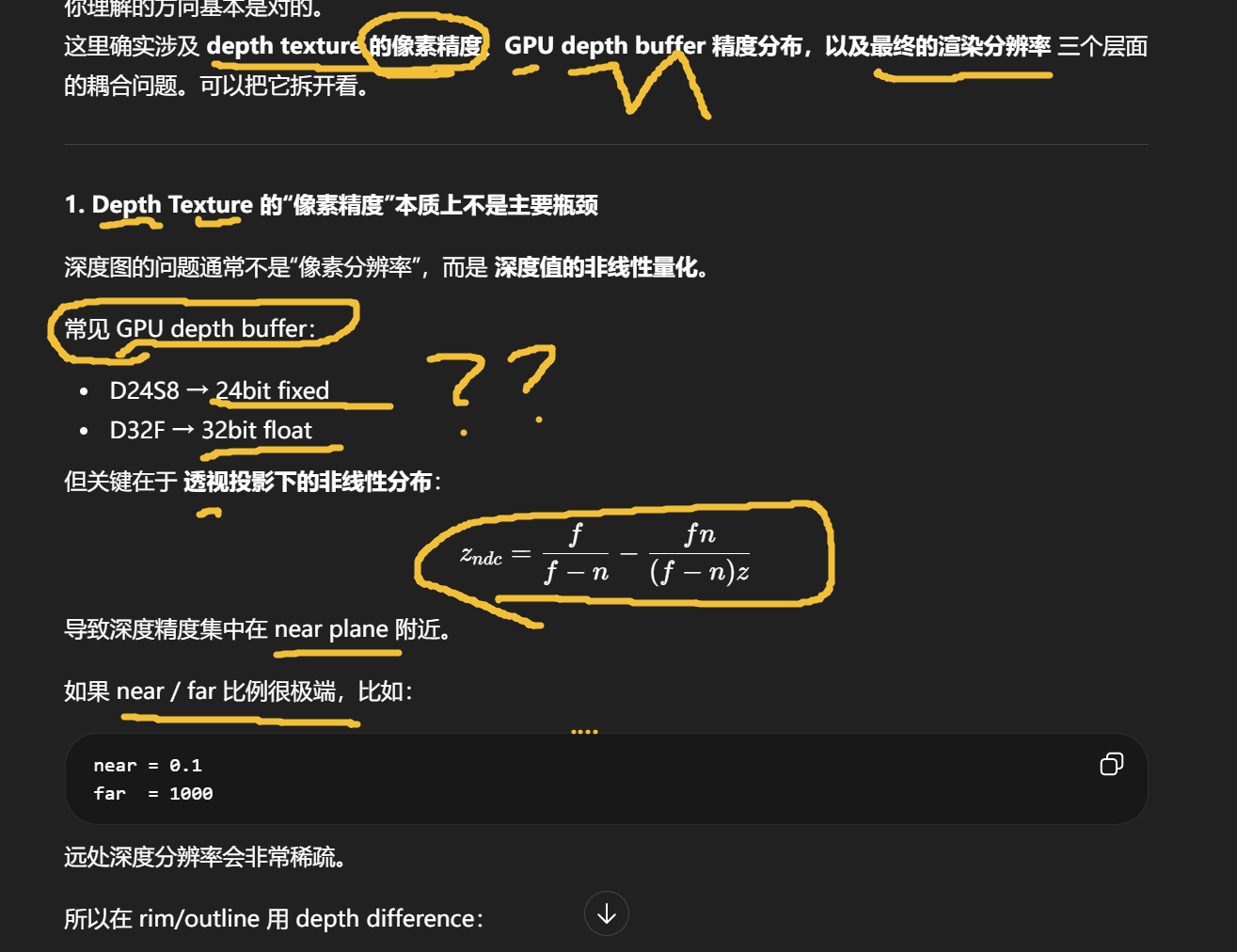
clip space z
zc
范围:
-w, w
不是线性深度。
NDC depth
z_ndc = zc / w
D3D:
0,1
OpenGL:
-1,1
仍然 非线性。
linear eye depth
这是 view space:
z_view
也就是:
-ViewPos.z
或者 Unity 常见:
LinearEyeDepth
这是 线性的相机距离。
所以关系是:
object → world → view → clip → ndc → depth buffer
你这里改的是:
clip space
不是 raw depth,也不是 linear depth。
裁剪空间里坐标是 positionCS = (x, y, z, w),经过透视除法:
ndc = positionCS.xyz / positionCS.w
就进入 NDC。
为什么z offset会导致,当模型远离屏幕的时候会大块变黑
因为你改的是投影后的深度,不是物体真实位置。
影矩阵 P 的内容,本质上就是把 view space 里的点变成 clip space 的规则。
对透视相机,典型形式可以写成:
| A 0 0 0 | | 0 B 0 0 | | 0 0 C D | | 0 0 -1 0 |
其中:
- A = 1 / (aspect * tan(fov/2))
- B = 1 / tan(fov/2)
- C 和 D 由 near / far 决定
- 不同图形 API、是否 reversed-Z,C/D 的符号和具体形式会变
它乘到 view space 点:
(xv, yv, zv, 1)
之后得到:
xc = A * xv yc = B * yv zc = C * zv + D wc = -zv
关键点就在最后这句:
w = -z_view
所以透视除法后:
x_ndc = (A * xv) / (-zv) y_ndc = (B * yv) / (-zv) z_ndc = (C * zv + D) / (-zv)
这就是"越远越小"的来源,因为 x/y 最后都除以了深度。
这也解释了你前面问的这句:
positionCS.z += offset * positionCS.w;
因为 w 大致和视空间深度成比例,所以:
(zc + offset * wc) / wc = zc / wc + offset
这样能让 NDC 深度偏移接近常量。
如果是正交相机,投影矩阵就不是这种结构了,通常更像:
| A 0 0 Tx | | 0 B 0 Ty | | 0 0 C Tz | | 0 0 0 1 |
这时:
- w 基本恒定是 1
- 不存在透视缩小
- 不需要靠乘 w 去补偿
你如果问的是 Unity 里"实际用的 P 矩阵长什么样",那要再区分:
- DirectX / Metal / Vulkan
- OpenGL
- reversed-Z 开没开
- render texture 是否翻转
所以在 Unity 里,UNITY_MATRIX_P 的具体数值平台相关,但结构和作用就是上面那套。
最核心的内容你可以记成:
P 负责: 1. x/y 按 FOV 和宽高比缩放 2. z 映射到深度范围 3. 把 w 设成和视空间深度相关,用于透视除法
在透视投影里,w 和 view space 的 z 是直接绑在一起的。
最核心的关系是:
w_clip = -z_view
这是最常见的透视投影形式。
也就是说:
- 点离相机越远
- |z_view| 越大
- w_clip 也越大
然后 GPU 做透视除法:
ndc = clip / w
于是:
x_ndc = x_clip / w_clip
y_ndc = y_clip / w_clip
z_ndc = z_clip / w_clip
所以 w 本质上就是"拿来做透视缩放的深度因子"。
乘 w 的作用,是把你在 clip space 里加的 z 偏移,变成"透视除法之后近似恒定的 NDC 深度偏移"。
你现在这句:
o.positionCS.z += _OutlineZOffset * o.positionCS.w;
如果不乘 w,直接写:
o.positionCS.z += _OutlineZOffset;
那么最后进 NDC 时会变成:
z_ndc = (z + offset) / w = z/w + offset/w
问题是:
- 近处 w 小,offset/w 很大
- 远处 w 大,offset/w 很小
也就是同一个 offset:
- 近处影响特别大
- 远处几乎没效果
这通常不稳定。
而如果你写成:
o.positionCS.z += _OutlineZOffset * o.positionCS.w;
那透视除法后:
z_ndc = (z + offset*w) / w = z/w + offset
结果就是:
- 无论远近
- 在 NDC 里都近似加了同一个深度偏移
因为远处时,深度缓冲对"谁在前谁在后"的分辨能力会明显变差,而 z offset 改的是投影后的深度排序,不是几何真实位置。
透视投影导致深度缓冲非线性分布,远处深度分辨率极低;再叠加 clip-space offset 被 w 缩小和 depth buffer 量化,因此远处更容易出现深度冲突或 offset 失效。
关键点:
mantissa 只有 23bit,所以"相对精度"是固定的,而不是"绝对精度"。
相对精度:
ϵ=2−23≈1.19×10−7\epsilon = 2^{-23} \approx 1.19 \times 10^{-7}ϵ=2−23≈1.19×10−7
也就是说:
Δx≈x×2−23\Delta x \approx x \times 2^{-23}Δx≈x×2−23
因此数值越大,可表示的最小步长越大。
举个更直观的例子:
| 数值范围 | 最小间隔 |
|---|---|
| 1.0 | 1.19e-7 |
| 10 | 1.19e-6 |
| 1000 | 1.19e-4 |
| 100000 | 0.0119 |
所以:
-
在 1 附近 可以精确到
0.0000001 -
在 100000 附近 连
0.01都表示不了
这就是你看到的现象来源。
Z-fighting(深度冲突)
深度缓冲中的值如果落在同一个 float step 内,就会被量化成同一个深度。
典型情况:
-
两个三角形真实深度差:
0.00005 -
depth buffer 在该范围的步长:
0.0001
结果:
overflow-visible!
depthA == depthB
GPU 无法稳定决定前后顺序,于是出现:
-
闪烁
-
摩尔纹
-
随视角变化的面片翻转
这在以下场景尤其明显:
-
远距离地形
-
coplanar decals
-
阴影贴图
大世界坐标抖动(Large World Jitter)
当 world position 很大时,小位移无法表示。
示例:
float pos = 100000.0
此时 float 步长约:
≈ 0.0119
如果角色移动:
pos += 0.001
结果:
pos == 100000.0
移动被量化掉。
表现为:
-
摄像机 jitter
-
物体微小振动
-
animation skinning 抖动
-
shadow map 不稳定
因此很多引擎使用:
-
floating origin
-
camera relative rendering
所以之所以要使用,z的精度问题,/w,顶点的数量,顶点之间的插值,
float的精度问题处于其次影响,
在于顶点的不连续性,数量实际上不够,/w的clip space 近大远小,
屏幕空间里远处效果不稳定、覆盖异常、描边/偏移失真、Z-fighting 这类现象,第一性原因通常不是 float 本身不够,而是透视投影经 /w 后导致的空间分布非线性:近处被放大、远处被压缩。这个压缩同时作用在深度分布、屏幕投影尺寸、顶点投影间距和三角形覆盖关系上。float 精度问题通常是放大器,不是根因。

Z 精度问题主要不是 float 在矩阵乘法过程中"不断损失精度",而是投影变换把 view-space 的深度通过一个非线性映射压缩到有限的 NDC/depth 区间里,随后再量化到有限精度的 depth buffer。positionCS=P⋅V⋅M⋅positionOS
得到的是 clip space 坐标,不是最终已经"塞进长方体"的坐标。
真正进入标准长方体 [-1,1]^3(或 API 对应的 z 范围)的是 再做一次 /w 之后的 NDC。
positionCS=P⋅V⋅M⋅positionOS得到的是 clip space 坐标不是最终已经"塞进长方体"进入标准长方体 [-1,1]^3(或 API 对应的 z 范围)是 再做一次 /w 之后的 NDC。不是投影矩阵直接把顶点塞进同一个长方体,而是它先把顶点映射到 clip space,再通过 perspective divide 把不同距离的点非线性地压进统一的 NDC/depth 范围。它先把顶点映射到 clip space,通过 perspective divide 把不同距离的点非线性地压进统一的 NDC/depth 范围。
这个"压进去"的过程才是深度问题的关键。
- 你的 fragOutline 返回的是纯色
- 没有光照
- 没有透明衰减
- 没有基于视角的隐藏
- 所以内部一旦被看到,就是整块纯黑
而 Blender 那边通常不一样:
-
你节点里有 Flip Faces
- 这不是简单"剔除前面"
- 是真的把壳体面朝向翻过来了
- 结果是壳体的"外表面"在视觉上更合理
-
Blender 视口经常默认不是完全按游戏里的实时 culling 方式显示
- 可能开了双面显示
- 可能有背面着色差异
- 可能材质本身不是纯 unlit 黑色
nity 里怎么等价做这个 Switch
做法不是"在 HLSL 里复刻 Geometry Switch",而是把它降级成"参数分支"或"渲染组织分支"。
对应你这张图,最合理的落地是:
方案 A:一个 Outline Pass,里面用参数决定逻辑
也就是不是切换两份 geometry,而是切换两种"顶点位移规则":
if (_UseMaterialFiltering > 0.5) { widthMask *= materialMask; } else { widthMask *= 1.0; }
这相当于把:
- 几何分支 A
- 几何分支 B
改写成:
- 同一份输入网格
- 但用不同的 selection/mask 算法决定哪些顶点外扩
这通常是最实用的 Unity 做法。
方案 B:拆子网格 / 拆材质
如果 Blender 的 Material Selection 真的是按某个材质槽筛区域,那 Unity 最稳的是:
- 把需要特殊描边的部分单独做 submesh
- 或单独 renderer
- 然后给它不同的 outline 参数
这样你就不需要在 shader 里"切 geometry branch"了。
很多项目里 brows 都是直接贴原色,基本不参与常规光照,尤其是二次元/风格化角色。
常见原因很现实:
眉毛通常只是贴在脸上的一层信息,不希望它跟着法线起伏被打亮打暗
如果吃正常光照,眉毛容易发灰、发脏、对比度不稳定
面部表情和妆感更依赖"设计色",不是物理受光
眉毛面积小,但视觉权重高,最怕被光照破坏形状和色值
所以常见做法是:
- 直接采样贴图原色输出
- 或只乘一个很轻的整体亮度
- 或最多只吃一点环境光,不吃主光方向项
大概会是这种:
float4 brow = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, uv); return float4(brow.rgb, brow.a);
或者稍微保守一点:
float3 color = brow.rgb * _Brightness; return float4(color, brow.a);
再多一点也可能是:
float3 ambient = SampleSH(normalWS); float3 color = brow.rgb * lerp(1.0, ambient, 0.2);
但不会像皮肤那样认真做 NdotL、高光、阴影。
尤其眉毛如果是:
- face atlas 上的一块贴图
- 单独贴片
- alpha 控制的 decal 式几何
那更常见就是"按设计稿颜色直接出"。
SampleSH 的数据来源
SampleSH 实际读取的是 Unity 的 Ambient Probe (Spherical Harmonics L2):
RenderSettings.ambientProbe
这个 probe 通常来自三个来源之一:
-
++Skybox ambient lighting++
-
++Environment Color++ / Gradient
-
++Baked GI / Light Probe++
Unity 会把这些信息转成 SH 系数给 shader。 Unity Documentation+1
shader 中读取:
unity_SHAr
unity_SHAg
unity_SHAb
...
unity_SHC
SampleSH 只是对这些系数做 ShadeSH9() 运算。
2 Lighting 窗口里的"开关"
真正影响 SampleSH 的是 Lighting → Environment Lighting
Source:
Skybox
Gradient
Color
如果是:
Skybox
Unity 会从 skybox 采样生成 SH。
Gradient / Color
Unity 会把颜色转换成 SH。
所以 即使没有 skybox,SH 也不会是 0。
3 Skybox 为空会怎样
即使你把 skybox 设成 None:
Unity 仍然会生成一个 ++ambient probe。++
最常见情况:
ambient = Environment Lighting Color
所以 SampleSH() 仍然会返回值。
Unity 文档里明确说明:
Unity 会生成 ambient probe 来保证默认情况下场景仍然有环境光。 Unity Documentation
4 什么情况下 SampleSH 接近 0
只有这些情况:
1 环境光颜色是黑色
Lighting → Environment
Source = Color
Color = (0,0,0)
SH 就几乎是 0。
2 你手动c#清空 ambient probe
代码:
RenderSettings.ambientProbe = new SphericalHarmonicsL2();
3 完全黑 skybox
如果 skybox 是黑色 cubemap。
5 与 LightProbe / Lightmap 的关系
一个容易混淆的点:
++SampleSH 并不是 LightProbe++。
Unity逻辑:
if ( LightProbe exists)
-use interpolated probe
--else if ( Lightmap exists)
---use baked GI
---- else
-----use ambientProbe
也就是说:
++ambient probe 是 fallback。++ Unity Documentation
6 stylized shader 的常见保护写法
因为 SH 有时候很暗,所以很多 stylized shader 会 clamp:
float3 ambient = SampleSH(normalWS);
ambient = max(ambient, 0.3);
或者:
float3 ambient = SampleSH(normalWS);
ambient = lerp(1.0, ambient, 0.2);
这样不会出现:
阴天 → 眉毛变灰
7 一个很多人忽略的 runtime 细节
如果你 运行时修改 skybox:
RenderSettings.skybox = newSkybox;
SH 不会自动更新。
必须调用:
DynamicGI.UpdateEnvironment();
否则 SampleSH 还是旧值。
8 一个风格化角色常见做法
为了完全稳定眉毛/妆容颜色,很多项目甚至不使用 SH:
float3 color = baseColor * _FaceAmbient;
而 _FaceAmbient 由角色系统统一控制。
原因:
SH 会随着环境变化
→ 角色脸色变化过大。
有些角色脸在室外突然发绿 / 发蓝
其实就是 SampleSH + normalWS 的方向问题。
这个在 stylized character pipeline 里非常典型。