写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除!
文章目录
前言
现实场景中的低质量人脸图像常存在复杂退化问题,视觉效果较差。盲人脸图像修复因具备诸多应用价值和经济效益(如老照片修复、影视修复等)受到广泛关注。然而,由于图像退化类型和退化参数具有不可预测性,盲人脸图像修复的难度更高,如何使修复结果兼具真实的面部特征和身份信息仍是一大挑战。
盲人脸图像修复方法主要依赖高质量的先验信息,常见的先验类型包括几何先验、参考先验、生成先验和3D先验。

- 几何先验难以精准标定关键点或面部组件位置;
- 参考先验通常需要借助Dlib或RetinaFace网络先定位面部组件,不适用于严重退化场景,还会增加额外计算量、降低推理速度,甚至耗时超过修复网络本身;
- 生成先验虽具备人脸生成能力,但一方面过度依赖先验会限制模型的灵活性,修复效果很大程度上取决于先验模型的性能,另一方面还可能引入先验网络的缺陷(如StyleGANv1的伪影问题)。
- 尽管MFPSNet通过融合多种先验尝试弥补单一先验的不足,在一定程度上提升了性能,却牺牲了实时性------修复前获取多种先验信息需要耗费大量时间,导致模型与实际落地应用的目标渐行渐远。
因此,如何在不依赖先验信息的前提下实现盲人脸图像修复,成为一个值得深入研究的问题。
论文
论文名: Improving blind face restoration by utilizing edge semantic enhancement
论文速递: 点我转跳哦
代码通道: 暂无
论文内容
整体架构
基于边缘语义增强的人脸图像修复框架,将退化人脸图像 I L I_L IL输入编码网络得到隐向量 w w w,将 w w w与各编码块的跳跃连接特征融合,通过风格调制逐步生成高分辨率图像,最终得到指定尺寸的修复图像 I ^ H \hat{I}_H I^H。修复的目标是使图像细节尽可能接近高质量图像,采用重建损失、感知损失和对抗损失约束网络,生成细节丰富的人脸图像。
修复框架主要由编码网络、解码网络、toRGB模块和升采样操作构成。具体而言,编码网络以低质量人脸图像 I L I_L IL为输入,提取不同深度的面部结构和编码特征图,并将人脸编码至隐空间;解码网络利用编码特征图、隐向量 w w w和前一阶段的前驱特征进行风格调制,生成真实的面部细节。
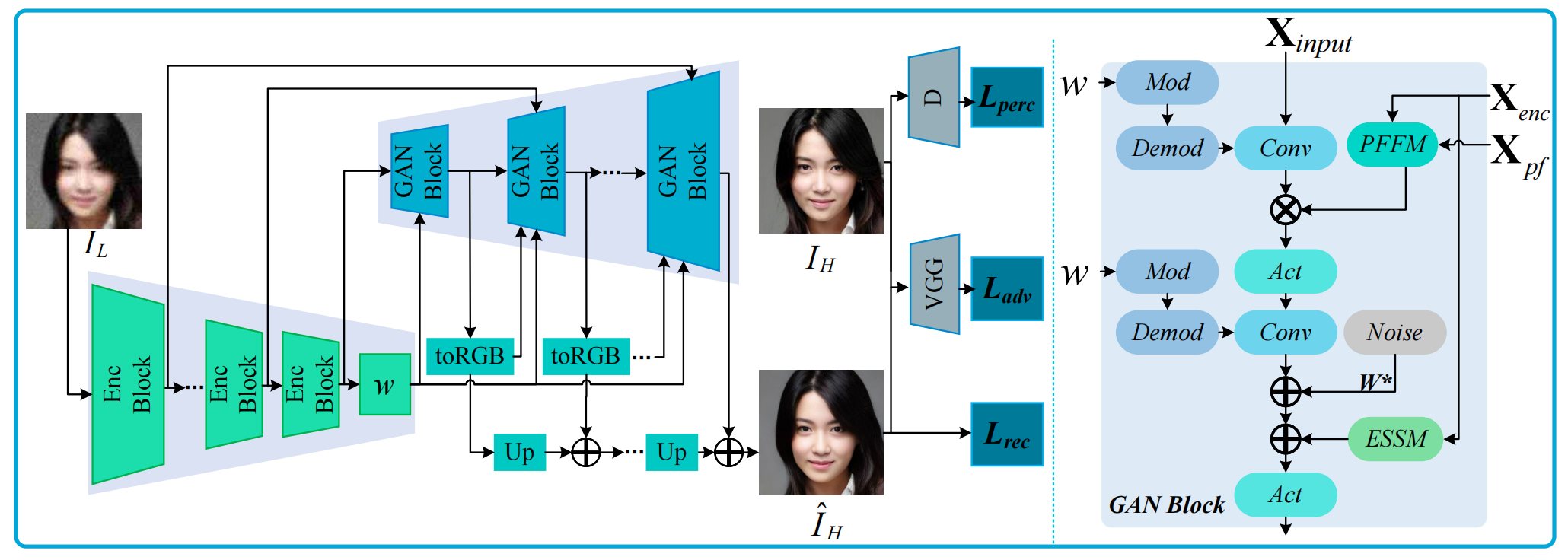
边缘语义增强机制
假设参与偏移的卷积核尺寸为 λ \lambda λ,卷积核的有效值为偏离中心的非零值,且单通道卷积核仅有一个有效值。卷积核实际位置 ( x , y ) (x, y) (x,y)与特征映射位置 ( i , j ) (i, j) (i,j)的计算次数记为 N N N,卷积核实际位置与中心的距离记为偏移距离 D D D,则位置 ( i , j ) (i, j) (i,j)处的偏移强度为:
S ( i , j ) = N × D λ , S_{(i, j)}=\frac {N\times D}{\lambda }, S(i,j)=λN×D,
D = M a x ∣ x − ⌊ λ / 2 ⌋ ∣ , ∣ y − ⌊ λ / 2 ⌋ ∣ . D=Max\left\|x-\\lfloor\\lambda / 2\\rfloor \|,\|y-\\lfloor \\lambda / 2\\rfloor \|\\right. D=Max∣x−⌊λ/2⌋∣,∣y−⌊λ/2⌋∣.
为提升卷积的全局偏移强度,提出了边缘语义增强(ESE)机制,通过对称偏移扩大感受野,避免边缘特征丢失。偏移强度呈现出中间高、边缘低的分布特征,因此边缘区域更容易形成较大的像素差异,实现边缘语义的精细化。
采用双向偏移融合两种特征,等效于实现堆叠的有效偏移率,避免特征丢失,同时扩大网络的感受野:以对称偏移为例,感受野可从 R × R R×R R×R扩大至 ( R + 2 ) × R (R+2)×R (R+2)×R,最大可达 ( R + 2 ) × ( R + 2 ) (R+2)×(R+2) (R+2)×(R+2)。
以往的方法通常利用对抗损失让网络学习人脸图像的边缘语义,从而有效区分人脸轮廓和组件边缘信息,但生成对抗网络的对抗训练往往需要更长的训练时间来提取边缘语义。即使采用小波序列、频域损失等方法生成高频信息,也难以在训练初期定位面部特征和轮廓,且往往更关注头发等细节丰富的区域。

对不同退化程度的图像进行测试,直观来看,图像轻度退化时即可实现人脸及面部特征的定位;随着退化程度加剧,面部特征的定位精度逐渐下降,网络会更多关注整体轮廓。基于ESE机制构建特征补充模块,为GAN块补充边缘信息,可近似实现通用几何先验的效果,提升无先验网络的修复性能,尤其能增强人脸的边缘语义特征。
前驱特征融合模块
以往的方法难以有效修复严重退化的图像,主要原因有两点:一方面,将图像编码至隐空间时,由于隐向量的维度较低,难以有效提供人脸信息;另一方面,跳跃连接引入了过多退化信息,而浅层特征提取无法有效规避退化信息,不可避免地导致图像退化,在严重退化场景中该问题更为突出。由于隐向量经过深度编码,信息相对干净,降低编码深度可缓解这一问题。因此,本文通过抑制跳跃连接中的退化信息,解决低质量图像的修复难题。
针对严重退化环境下如何实现面部组件定位、如何避免过度使用跳跃连接这两个问题,已有研究表明,生成器自身的特征可作为伪解析图,实现组件的粗略定位。因此,前驱特征融合模块的核心思想是:利用解码器的深度特征实现组件定位,并在图像严重退化时代行跳跃连接的功能。

前驱特征融合模块主要融合编码器特征和前一GAN块输出特征 X d e c i − 1 X_{dec}^{i-1} Xdeci−1生成的前驱特征 X p f i − 1 X_{pf}^{i-1} Xpfi−1。首先, X e n c i X_{enc}^i Xenci通过卷积生成掩码,并利用Sigmoid函数归一化,如式(8)所示:
M m a s k i = σ C o n v 3 × 3 ( X e n c i ) , M_{mask }^{i}=\sigma\left Conv_{3 × 3}\\left(X_{enc }\^{i}\\right)\\right, Mmaski=σConv3×3(Xenci),
其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅)表示Sigmoid激活函数, C o n v k × k Conv_{k×k} Convk×k表示核尺寸为 k × k k×k k×k的卷积操作。
通过卷积将前一解码块的前驱特征 X p f i − 1 X_{pf}^{i-1} Xpfi−1调整为3通道,并逐步叠加至 X p i c X_{pic} Xpic得到最终修复结果;同时将其进一步调整为掩码及其他通道的特征进行融合:
X f u s i o n i = C o n v 3 × 3 ( 1 − M m a s k i ) ⊙ X p f i − 1 + M m a s k i ⊙ X e n c i + X e n c i , X_{fusion }^{i}=Conv_{3 × 3}\left\\left(1-M_{mask}\^{i}\\right) \\odot X_{pf}\^{i-1}+M_{mask }\^{i} \\odot X_{enc }\^{i}\\right+X_{enc }^{i}, Xfusioni=Conv3×3(1−Mmaski)⊙Xpfi−1+Mmaski⊙Xenci+Xenci,
其中, ⊙ \odot ⊙表示哈达玛积。同时发现,解码阶段不应过度使用PFFM,因为 X p f i − 1 X_{pf}^{i-1} Xpfi−1是需要学习的特征,过度使用会导致模型收敛缓慢甚至无法收敛。
边缘语义补充模块
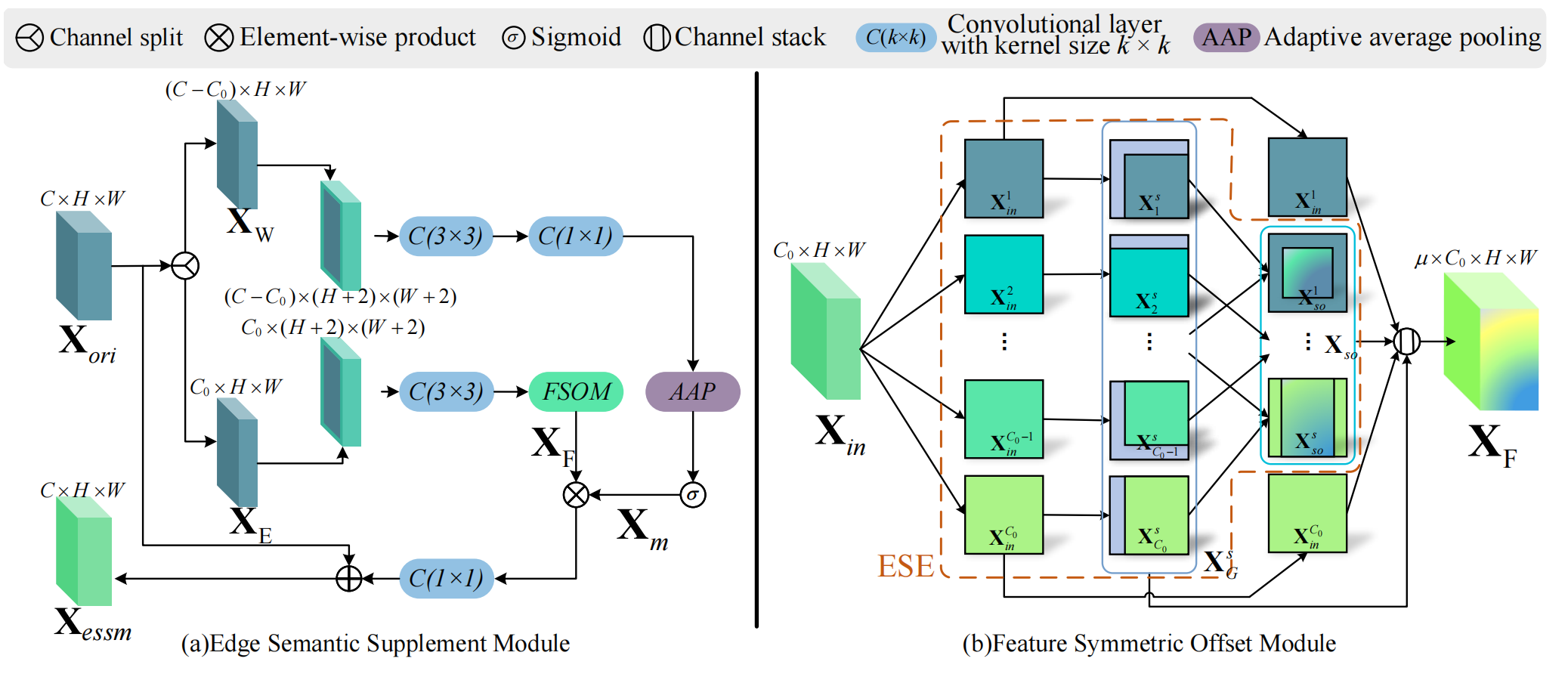
基于前驱特征融合模块设计边缘语义补充模块:前者利用深度特征实现面部特征的粗略定位,后者通过特征选择机制增强边缘语义。输入特征 X o r i X_{ori} Xori按通道分为 X W X_W XW和 X E X_E XE(结构与GhostNet相似);随后对 X W X_W XW进行范围插值填充,减少低频信息的引入;再通过无填充的3×3卷积融合上下文信息,利用1×1卷积调整特征通道;最后通过自适应池化融合全局信息,为 X E X_E XE分支提供权重信息:
X m = σ A A P ( C o n v 1 × 1 ( C o n v 3 × 3 ( R I P ( X W ) ) ) ) , X_{m}=\sigma \left AAP(Conv_{1× 1}(Conv_{3× 3}(RIP(X_{W}))))\\right, Xm=σAAP(Conv1×1(Conv3×3(RIP(XW)))),
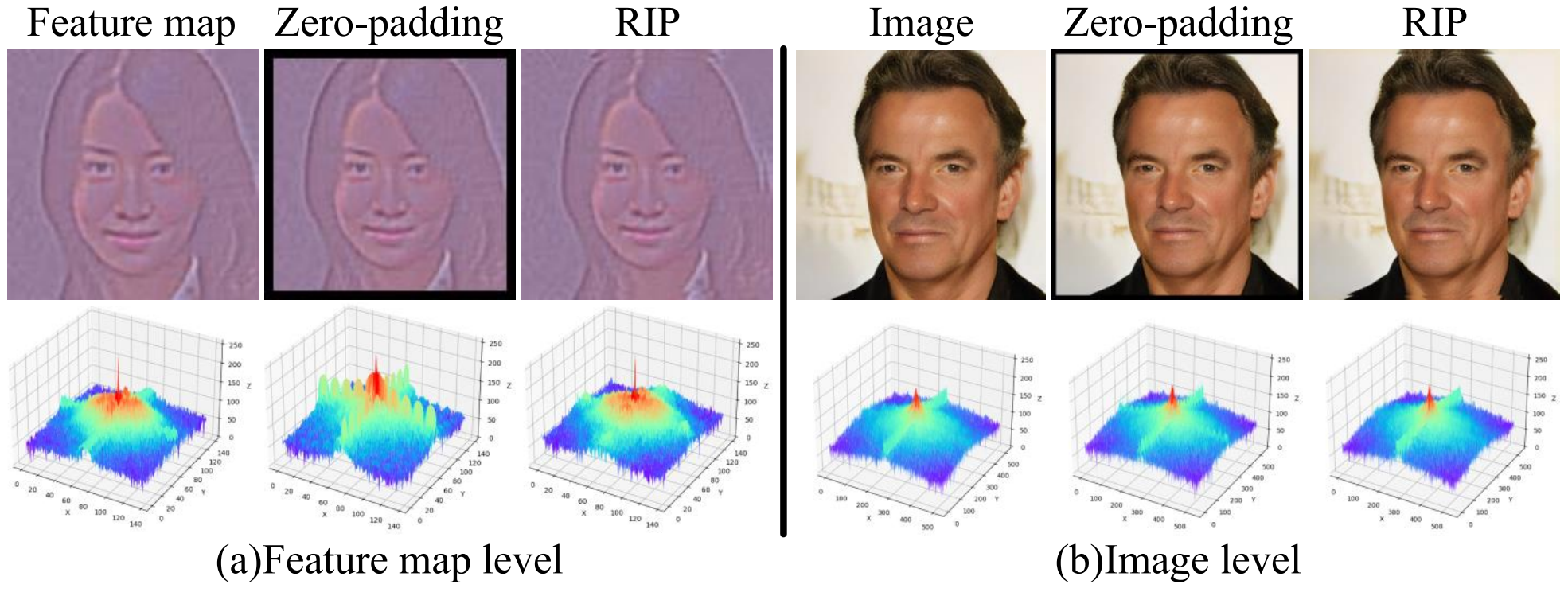
其中, R I P ( ⋅ ) RIP(\cdot) RIP(⋅)表示范围插值填充,可避免引入额外的低频信息,且更适配灰度图像的上色任务; A A P AAP AAP表示自适应平均池化。
X r i p = R ( R a n g e ( X ) ⊙ P ( X ) , X ) , X_{rip}=R(Range(X)\odot P(X),X), Xrip=R(Range(X)⊙P(X),X),
其中, P ( X ) P(X) P(X)表示通过双线性插值将尺寸为 H × W H×W H×W的输入特征 X X X插值升采样至 ( H + 2 ) × ( W + 2 ) (H+2)×(W+2) (H+2)×(W+2); R a n g e ( X ) Range(X) Range(X)表示对特征 X X X提取的像素极值范围,为输入特征 X X X的像素对赋予权重以填充内容; R R R表示替换操作,将插值后的中心区域( H r i p ∈ 1 , H + 1 H_{rip}∈1,H+1 Hrip∈1,H+1, W r i p ∈ 1 , W + 1 W_{rip}∈1,W+1 Wrip∈1,W+1)替换为输入 X X X。RIP的频域可视化结果如下:
X E X_E XE分支与 X W X_W XW分支的不同之处在于,通过设计特征对称偏移模块补充边缘信息。具体而言,对 X E X_E XE进行范围插值填充以减少低频信息的引入,随后依次通过3×3卷积融合上下文信息,结合特征偏移模块得到 X F X_F XF,如图6所示:
X F = F S O M ( C o n v 3 × 3 ( R I P ( X E ) , μ ) ) , X_{F}=FSOM(Conv_{3× 3}(RIP(X_{E}),\mu )), XF=FSOM(Conv3×3(RIP(XE),μ)),
其中, C o n v k × k ( X , μ ) Conv_{k×k}(X,\mu) Convk×k(X,μ)表示通过核尺寸为 k × k k×k k×k的卷积层将特征 X X X的通道数扩大 μ \mu μ倍; F S O M ( ⋅ ) FSOM(\cdot) FSOM(⋅)为特征对称偏移模块,该模块按通道对输入特征进行多方向偏移,偏移距离为 D D D:
X i s = C o n v ( x , y , D ) ( X i n i ) , X_{i}^{s}=Conv_{(x, y, D)}(X_{in }^{i}), Xis=Conv(x,y,D)(Xini),
其中, C o n v ( x , y , D ) Conv_{(x,y,D)} Conv(x,y,D)为人工设计的卷积,仅卷积核的 ( x , y ) (x,y) (x,y)位置为有效值,其余位置均为0,满足偏移强度 D D D; X i n i X_{in}^i Xini表示输入特征 X i n X_{in} Xin中第 i i i个通道的特征。
通过进一步选择保证特征对称性,并融合偏移方向相反的特征(实际存在更多组合方式,并非必须进行对称操作):
X s o k = X i s + X j s . X_{s o}^{k}=X_{i}^{s}+X_{j}^{s}. Xsok=Xis+Xjs.
不仅利用偏移特征,还加入少量非偏移特征 X i n s X_{in}^s Xins,进一步保证特征的中心化:
X F = X s o ∥ X G s ∥ X i n s , X_{F}=X_{so}\left\| X_{G}^{s}\right\| X_{in }^{s}, XF=Xso∥XGs∥Xins,
其中, X G s ∈ R C 0 × H × W X_{G}^{s}∈R^{C_0×H×W} XGs∈RC0×H×W, X s o ∈ R λ C 0 × H × W X_{so}∈R^{\lambda C_0×H×W} Xso∈RλC0×H×W; λ \lambda λ为边缘精细化的通道权重,对称偏移时取0.5; μ \mu μ通常取2; ∥ \| ∥表示特征通道的堆叠。
ESSM输出经 X m X_m Xm加权后的 X F X_F XF,并进一步通过1×1卷积压缩通道,以适配残差通道数:
X e s s m = C o n v 1 × 1 ( X F ⊙ X m ) + X o r i . X_{essm}=Conv_{1× 1}(X_{F}\odot X_{m})+X_{ori}. Xessm=Conv1×1(XF⊙Xm)+Xori.
实验设置
-
训练数据集:采用人脸生成任务中常用的FFHQ数据集,该数据集包含70000张1024分辨率的高质量人脸图像,将其下采样至512分辨率作为输入。同时对图像进行人工退化,以模拟现实场景中的退化图像:
-
测试数据集:从不同来源构建合成数据集和真实数据集,所用数据集的简要说明如下:
-
- CelebA-Test:从CelebA-HQ数据集中选取1560张与训练集无交集的图像,通过上述退化方法进行退化处理;
-
- Photo-Test:从网络收集587张自然退化的人脸图像(含部分老照片),并按照FFHQ的标准进行对齐;
-
- LFW-Test:从LFW数据集中选取5900张不同身份的人脸图像,按FFHQ标准对齐,其退化程度相比Photo-Test更轻微。
-
实验实现:采用Adam优化器,学习率设为0.001,训练批次大小为6;基于PyTorch框架实现所提模型,在NVIDIA GeForce RTX 3090Ti GPU上进行训练,总迭代次数为800000。
-
对比指标:对有真实标签的合成数据集,采用应用广泛的参考型指标(PSNR、SSIM、MS-SSIM)和感知型指标(LPIPS);对真实数据集和合成数据集,均采用无参考感知型指标(FID、NIQE)。
实验效果





-
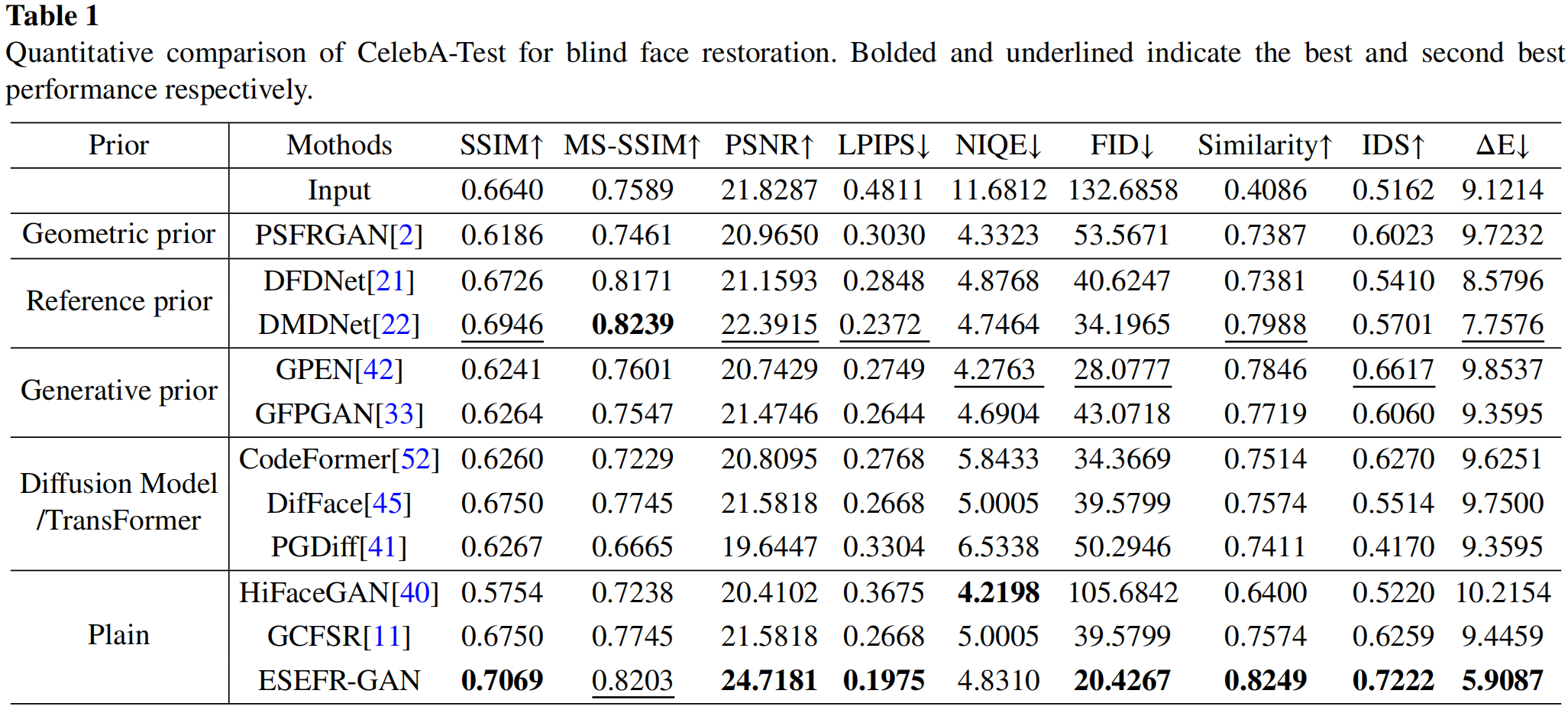
合成数据集:在图像严重退化的情况下仍能生成高可靠性的修复结果,充分展现了其在复杂场景中的强大修复能力。其中,PSFR-GAN因无法获取准确的解析图像,修复效果受影响;参考先验方法DFDNet因无法从通用字典查询中有效获取组件信息,导致无法检测正确的面部组件信息;尽管DMDNet的参数与所提方法相近,但其特定的字典构建方式在实际场景中缺乏实用性,修复结果往往效果较差甚至出现信息错误(如嘴巴区域缺乏细节,眼睛区域出现错误组件);基于生成先验的方法面部生成性能优异,但易出现瞳孔颜色异常、牙齿错位等问题;无先验方法生成的面部细节往往不够自然;基于扩散模型的方法能生成更丰富的细节,但受限于迭代去噪步数,人脸保真度可能较低。
-
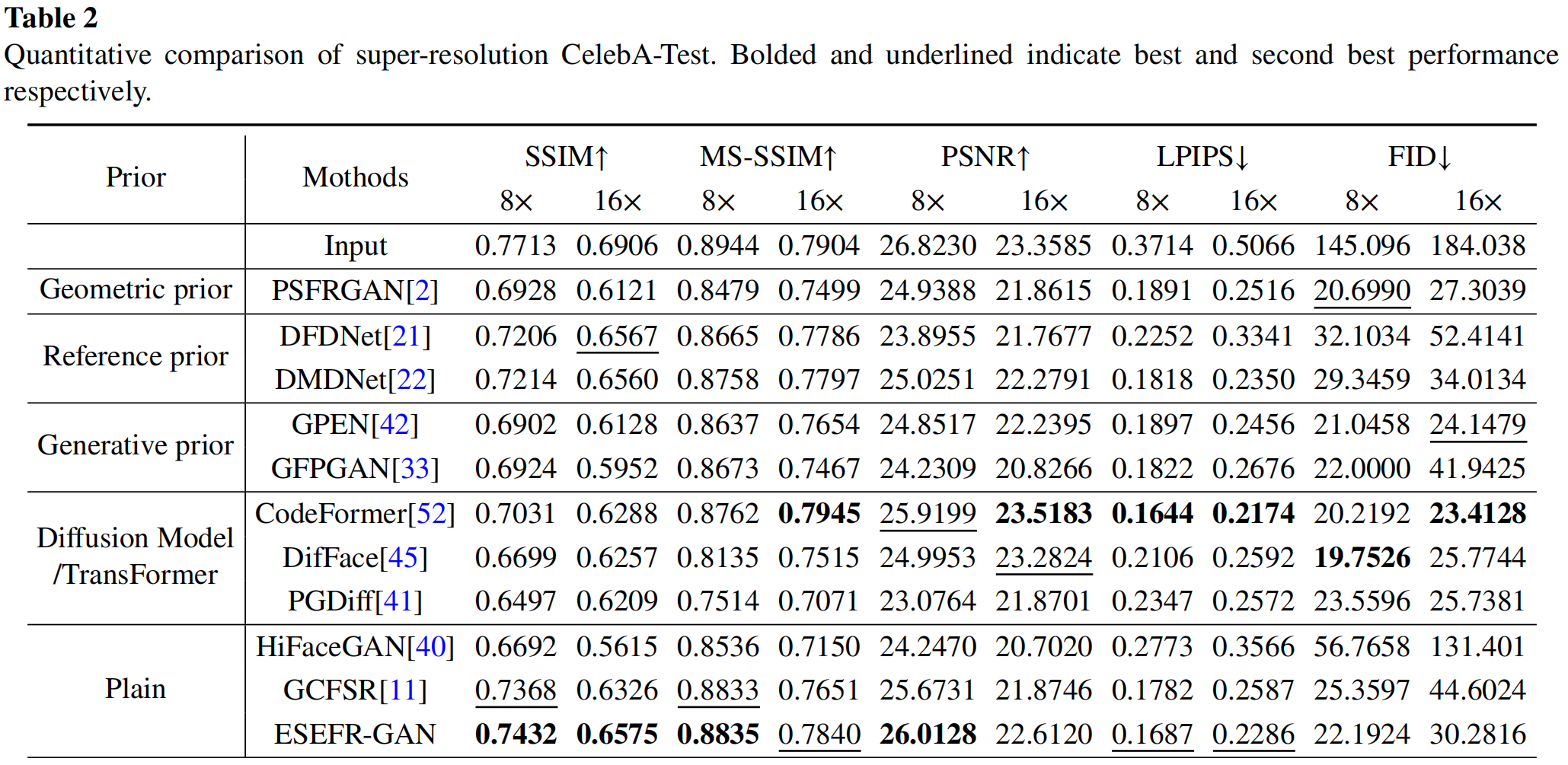
超分辨率对比实验:将512×512分辨率的图像下采样8倍和16倍后,通过插值恢复至原始尺寸。实验结果如表2所示,所提方法取得了最优的SSIM值,且LPIPS和FID值也具有竞争力。与其他方法相比,所提方法的边缘效果更优,能更好地保留身份信息、有效区分背景,且不会产生下采样导致的明显锯齿边缘。
-
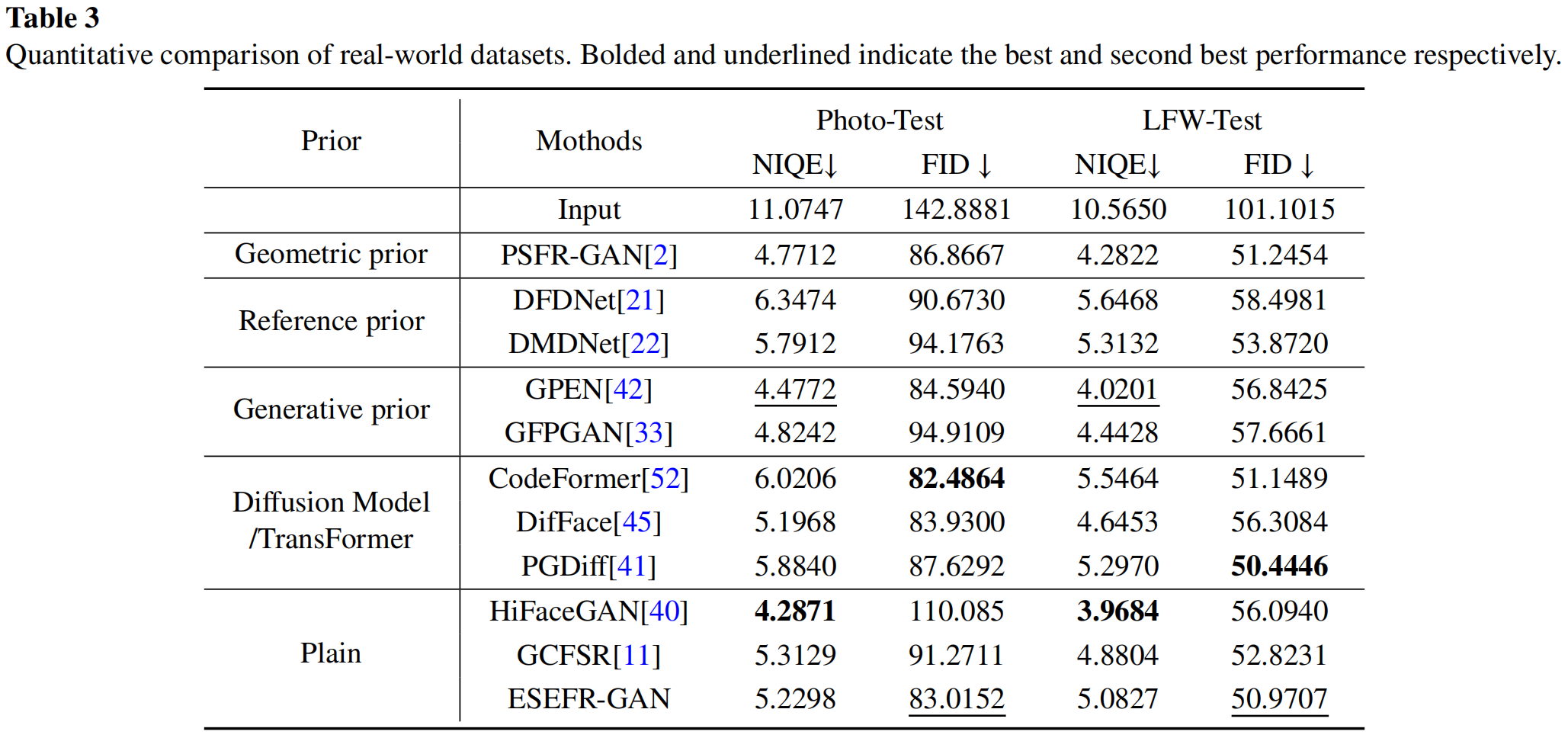
真实数据集:即使无先验信息,所提方法仍能成功实现真实照片的人脸修复和上色。具体而言,该方法能有效处理背景和人脸上的退化信息,生成更清晰的图像(如箭头标注区域和最后一行人脸区域,其他方法无法生成干净的图像,包括GPEN的修复结果也存在大量退化信息)。
研究局限
本文方法主要通过PFFM消除退化信息以提升修复质量,因此对前驱特征的纯净性要求较高;由于参数随机初始化,模型在预训练阶段可能出现不稳定性,此时对前驱特征进行截断可解决该问题。
尽管所提方法具有较强的鲁棒性,但在处理大侧脸图像时视觉效果较差,原因是FFHQ训练集中的侧脸样本数量有限。将一些正脸变换方法应用于侧脸网络作为数据预处理步骤,或许能解决这一问题。
期刊说明
期刊:Engineering Applications of Artificial Intelligence
更多详情可参考LetPub-Engineering Applications of Artificial Intelligence。
总结
总结: ESEFR-GAN 利用深度阶段特征实现面部特征的粗略定位,同时通过边缘语义增强机制逼近先验知识提供的边缘信息。针对跳跃连接带来的退化信息问题,融合前驱特征和编码特征,以应对图像严重退化的场景。在合成数据集和真实数据集上的实验结果表明,所提方法相比现有人脸修复方法,在增强人脸轮廓和色彩表现方面更具优势,且推理速度更快。
互动
-
上述对你有用吗?
-
该论文期刊的审稿速度怎么样?
-
有更多相关期刊和论文推荐吗?
欢迎在评论区解答上述问题,分享你的经验和疑问!
当然,也欢迎一键三连给我鼓励和支持:👍点赞 📁 关注 💬评论。
致谢
欲尽善本文,因所视短浅,怎奈所书皆是瞽言蒭议。行文至此,诚向予助与余者致以谢意。
参考
1 Improving blind face restoration by utilizing edge semantic enhancement
往期回顾
| 序号 | 博客名 | 点击图片转跳哦 |
|---|---|---|
| 1 | 【NeurIPS-2022】CodeFormer: 将人脸复原转化为码本预测以减少LQ-HQ映射的不确定性 |  |
| 2 | 【CVPR-2023】DR2:解决盲人脸复原无法覆盖真实世界所有退化的问题 |  |
| 3 | 【论文学习】DifFace:一个建立在后验分布上的鲁棒扩散模型 |  |
| 4 | 【论文学习】PromptIR:一种基于提示学习的一体化图像恢复方法 |  |
| 5 | 【论文学习】RAHC:一种处理五种常见天气的任意混合退化的图像修复方法 |  |
| 6 | 【论文学习】PSFR-GAN:一种结合几何先验的渐进式复原网络 |  |
| 7 | 【论文学习】Panini-Net:一种可根据退化程度动态融合特征复原方法 |  |
| 8 | 【论文学习】GCFSR:一种无需先验的强度可调的人脸超分框架 |  |
| 9 | 【论文学习】SGPN:一种形状和生成先验相结合盲脸复原的方法 | 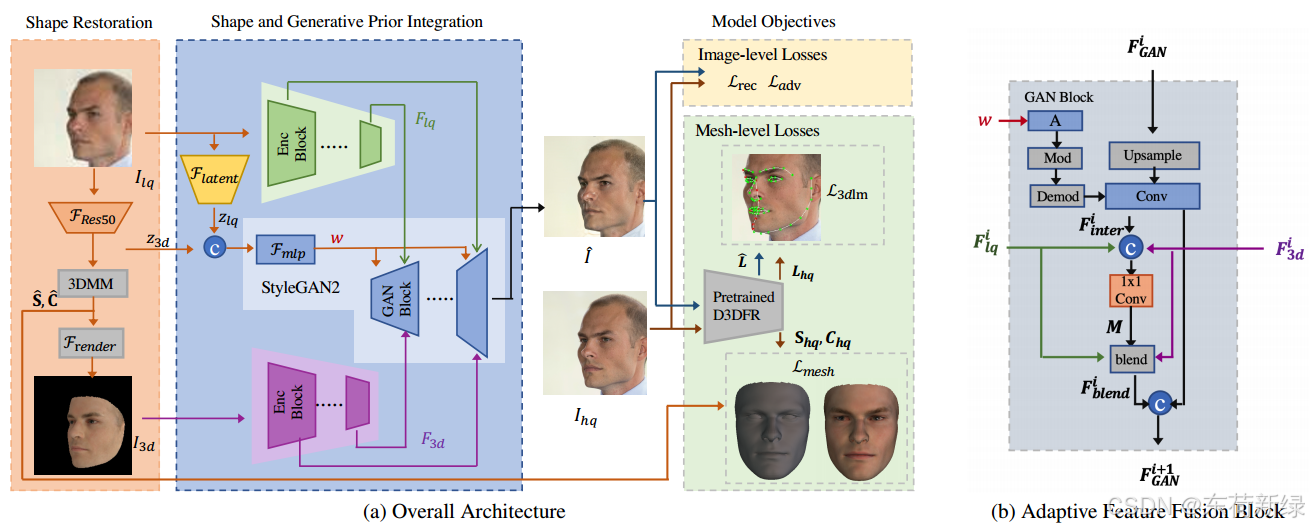 |