在Java8中,Collection新增了两个流方法,分别是Stream()和parallelStream()。
什么是Stream?
在Java8之前,我们通常是通过for循环或者Iterator迭代来重新排序合并数据,又或者通过重新定义Collections.sorts的Comparator方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。
Java8中添加了一个新的接口类Stream,他和我们之前接触的字节流概念不太一样,Java8集合中的Stream相当于高级版的Iterator,他可以通过Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
Stream的聚合操作与数据库SQL的聚合操作sorted、filter、map等类似。我们在应用层就可以高效地实现类似数据库SQL的聚合操作了,而在数据操作方面,Stream不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
Map < String, List < Student >> stuMap = new HashMap < String, List < Student >> (); for (Student stu: studentsList) { if (stu.getHeight() > 160) { //如果身高大于160 if (stuMap.get(stu.getSex()) == null) { //该性别还没分类 List < Student > list = new ArrayList < Student > (); //新建该性别学生的列表 list.add(stu); //将学生放进去列表 stuMap.put(stu.getSex(), list); //将列表放到map中 } else { //该性别分类已存在 stuMap.get(stu.getSex()).add(stu); //该性别分类已存在,则直接放进去即可 } } }
1.串行实现
Map<String, List<Student>> stuMap = stuList.stream().filter((Student s) -> s.getHeight() > 160) .collect(Collectors.groupingBy(Student ::getSex));
2.并行实现
Map<String, List<Student>> stuMap = stuList.parallelStream().filter((Student s) -> s.getHeight() > 160) .collect(Collectors.groupingBy(Student ::getSex));
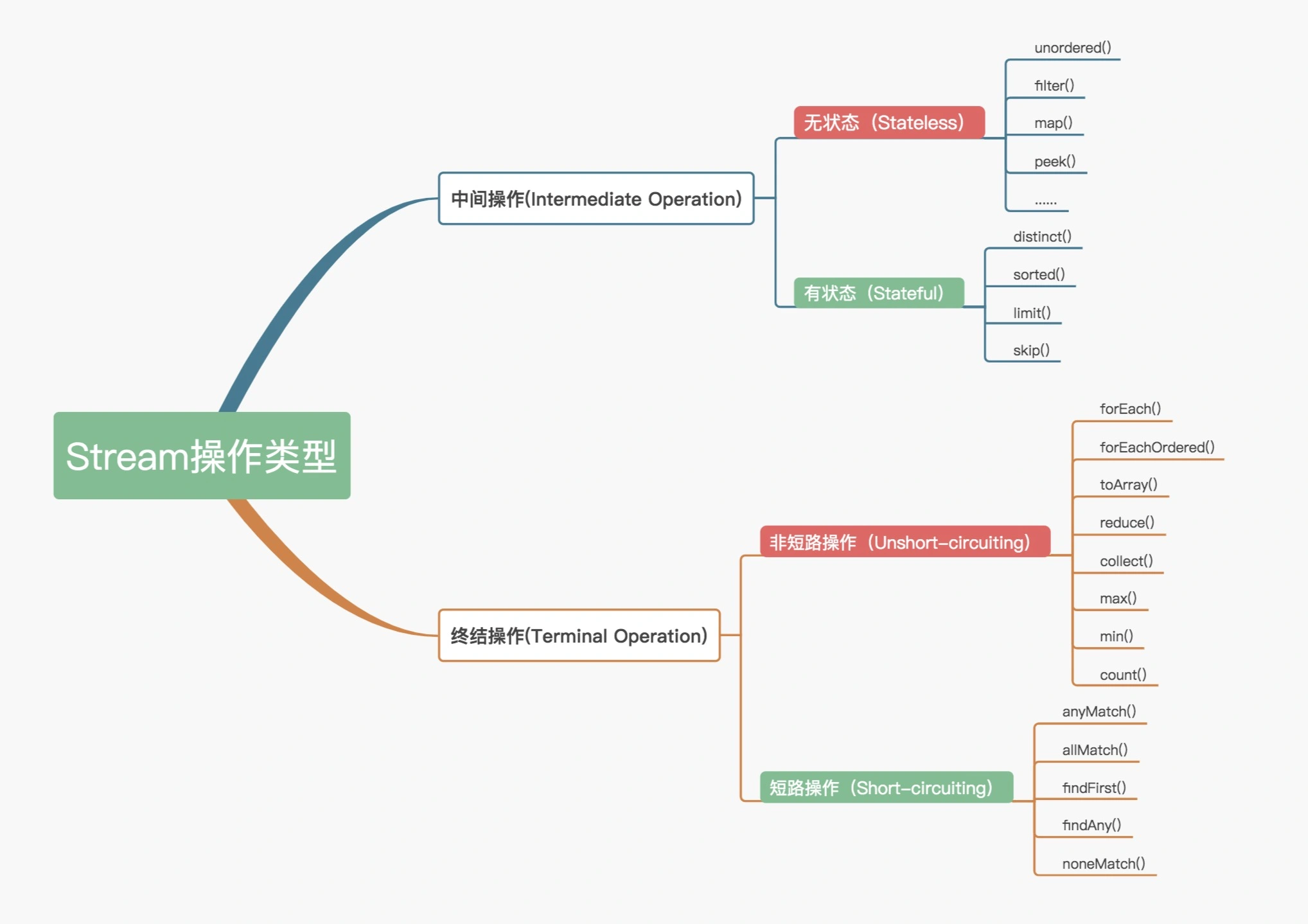
Stream操作分类
官方将Stream中的操作分为两大类:中间操作(Intermediate operations)和终结操作(Terminal operations)。中间操作只对操作进行了记录,即只会返回一个流,不会进行计算操作,而终结操作是实现了计算操作。
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,前者是指遇到某些符合条件的元素就可以得到最终结果,后者是指必须处理完所有元素才能得到最终结果。操作分类详情如下图所示:
**在串行处理操作中,**Stream在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过Java8中的Spliterator迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。
在 并行 **处理操作中,**Stream对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream将结合ForkJoin框架对集合进行切片处理,ForkJoin框架将每个切片的处理结果Join合并起来。最后就是要注意Stream的使用场景。