引言
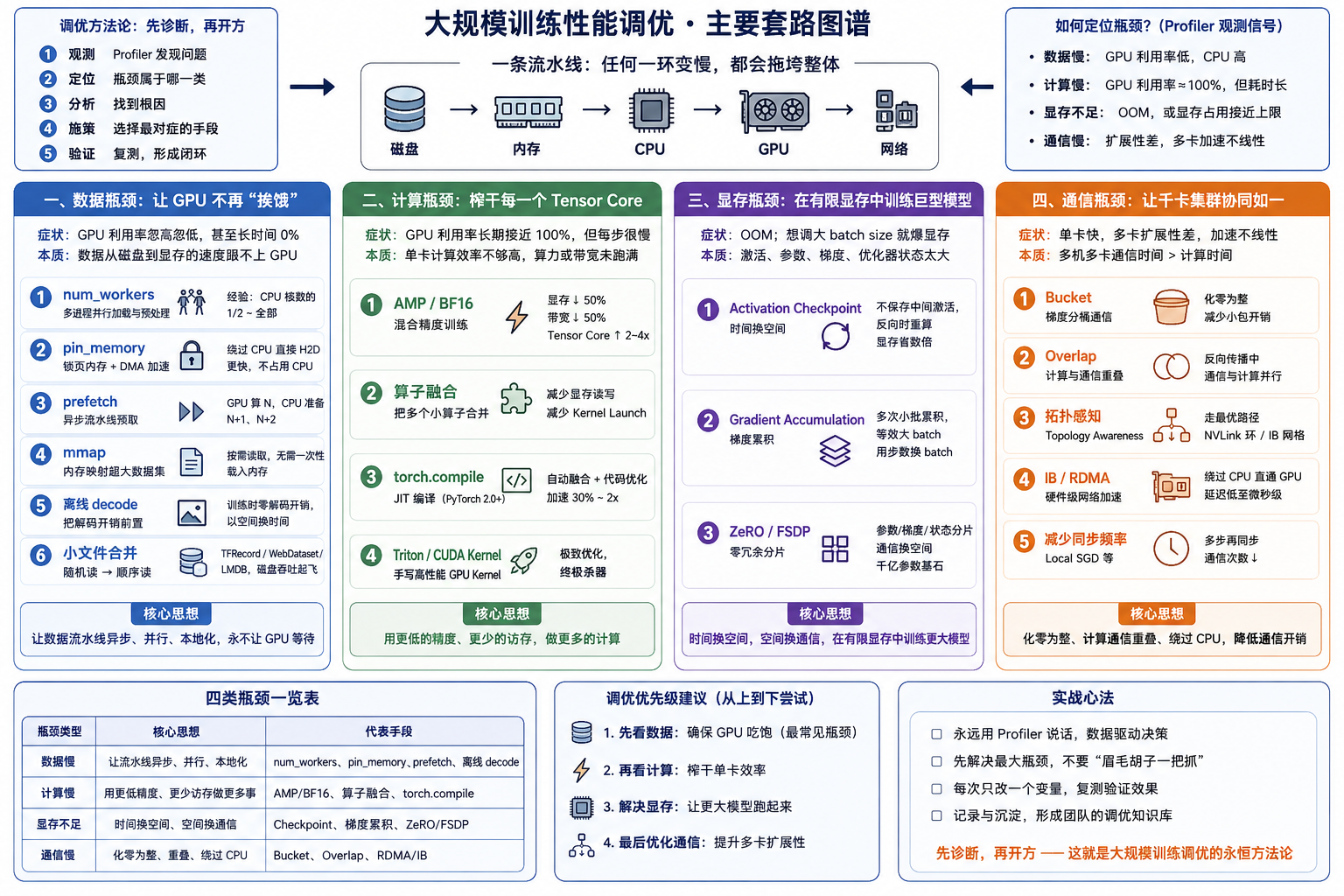
在大规模深度学习训练中,模型能不能跑、跑得快不快,从来都不只是"加几张卡"那么简单。训练一个大模型,本质上是一条由 磁盘 → 内存 → CPU → GPU → 网络 串起来的复杂流水线,任何一个环节出现短板,都会让昂贵的 GPU 算力被白白浪费。
性能调优的第一性原理只有一句话:找到瓶颈,对症下药。
通过 Profiler(如 PyTorch Profiler、Nsight Systems)观测后,性能瓶颈基本可以归入四大类:数据慢、计算慢、显存不足、通信慢。本文系统梳理每一类瓶颈背后的成因,以及工业界沉淀下来的核心应对手段------可以把它当作一份深度学习系统工程师的"兵器谱"。
一、数据瓶颈:让 GPU 不再"挨饿"
症状:GPU 利用率忽高忽低,甚至长时间在 0% 徘徊;CPU 占用却拉满。
本质:数据从磁盘读到内存、再从内存搬到显存的速度,跟不上 GPU 的计算速度。GPU 在"等饭吃"。
1. num_workers:多进程并行加载
PyTorch 的 DataLoader 默认在主进程中单线程读取数据,这显然跟不上现代 GPU 的胃口。把 num_workers 设为大于 0,就会启动多个子进程并行读取与预处理数据,吞吐量成倍提升。经验上,num_workers 通常取 CPU 核数的一半到全部之间,过大反而会因为进程切换得不偿失。
2. pin_memory:锁页内存与 DMA 加速
操作系统的内存是分页的,不活跃的页随时可能被换出到磁盘。设置 pin_memory=True 会向系统申请一块"锁住"的主机内存,绝不被换出。
只有锁页内存才能开启 DMA(Direct Memory Access,直接内存访问):数据从 CPU 内存拷贝到 GPU 显存(H2D)时,可以绕过 CPU 直接传输,速度更快,也不再占用 CPU 算力。
3. prefetch:异步流水线预取
预取的思想很朴素------当 GPU 在算第 N 个 batch 时,CPU 已经悄悄把第 N+1、N+2 个 batch 准备好了。这样 GPU 一算完上一批,下一批立刻就位,彻底消除等待。
4. mmap:内存映射超大数据集
当数据集大到塞不进内存(比如几百 GB 的 numpy 数组),可以用内存映射(mmap)把磁盘文件直接映射到进程的地址空间。按需读取,不必一次性载入,对于超大静态数据集是极其优雅的方案。
5. 离线 decode:把解码开销前置
JPEG、PNG、MP4 都是压缩格式,训练时 CPU 需要实时解压它们,开销极大。离线 decode 就是在训练前把图像或视频统一解码成原始张量(如 .npy、.pt)落盘。代价是磁盘占用变大,收益是训练时几乎零解码开销。
6. 小文件合并:把"随机读"变"顺序读"
机械硬盘和普通 SSD 最怕"海量小文件"------一百万张几 KB 的 JPEG,光寻道就能把磁盘 I/O 拖垮。
解决方法是把小文件合并成几个几十 GB 的连续大文件,常见方案有 TFRecord、WebDataset、LMDB。访问模式从随机读变成顺序读,磁盘吞吐立刻起飞。
二、计算瓶颈:榨干每一个 Tensor Core
症状:GPU 利用率长期接近 100%,但每一步耗时仍然很长。
本质:单卡的数学计算效率不够高------要么算力没跑满,要么显存带宽成了瓶颈。
1. AMP / BF16:混合精度的力量
默认训练用 FP32(32 位浮点)。自动混合精度(AMP) 会在精度可控的前提下,把矩阵乘法等计算密集层自动切到 FP16 或 BF16。带来三重收益:
- 显存占用直接砍半;
- 显存读写带宽需求砍半;
- 激活 NVIDIA GPU 上的 Tensor Core,吞吐提升 2~4 倍。
FP16 vs BF16:FP16 精度高但动态范围小,大模型训练容易梯度溢出 NaN;BF16 牺牲一些精度换取与 FP32 同等的动态范围,已成为大模型训练的事实标准。
2. 算子融合(Operator Fusion)
PyTorch 默认按算子逐个执行。一个 LayerNorm 其实拆成"减均值、求方差、除标准差"等多个小算子,每执行一个都要从显存读数据、算完再写回显存。
算子融合 把这一连串小操作合并成一个大 CUDA Kernel,在 GPU 寄存器和共享内存中一气呵成。它一举攻克了两个痛点:
- 极大减少昂贵的显存读写(克服 Memory Bound);
- 减少 CPU 下发指令(Kernel Launch)的开销。
3. torch.compile:JIT 编译的一行魔法
PyTorch 2.0 引入的 JIT 编译器。一行 model = torch.compile(model),框架就会自动分析计算图,借助 Triton 等技术自动完成算子融合并生成高度优化的底层代码。在不少模型上能拿到 30%~2x 的免费加速。
4. Triton / CUDA Kernel:终极杀器
当现成 API 怎么拼都不够快------比如要实现 FlashAttention 这种极致优化的注意力机制------就得拿出最后的武器:用 CUDA(C++)或 Triton(类 Python DSL) 直接手写 GPU Kernel,精确管理寄存器、共享内存等微架构资源。这是系统工程师与算法工程师的交叉地带,也是大厂自研框架的核心战力。
三、显存瓶颈:在有限显存中训练巨型模型
症状:动不动 OOM(Out of Memory);想调大 batch size 或换大模型就爆显存。
本质:为了求导,前向传播会缓存海量的中间激活值(Activations),加上参数、梯度、优化器状态,显存四面楚歌。
1. Activation Checkpoint:时间换空间
前向传播时,故意 不保存某些层(比如巨大的 Transformer Block)的中间激活值;反向传播需要用到时,临时再做一次前向把它算出来。
通常用约 30% 的额外计算时间,换取数倍的显存节省。训练几十层、上百层的大模型时几乎是必选项。
2. Gradient Accumulation:梯度累积
显存只够跑 batch_size=2,但模型需要 batch_size=32 才能收敛,怎么办?
跑 16 次 size=2 的小批,每次算出梯度后不更新参数,而是累加 ;累计到第 16 次时,累积的梯度等效于一次 size=32 的更新,再做一次 optimizer.step()。用步数换有效 batch size,几乎无副作用。
3. ZeRO / FSDP:零冗余分片
传统数据并行下,每张卡都保存一份完整的参数、梯度和优化器状态------这是巨大的显存浪费。
ZeRO(DeepSpeed) 与 FSDP(PyTorch 原生) 的核心思想是把优化器状态、梯度乃至参数本身切分并散布到所有 GPU 上 ,每张卡只持有一小片,用到时再从其他卡上拉过来。这是一种"通信换空间"的技术,也是训练千亿参数大模型的基石。
四、通信瓶颈:让千卡集群协同如一
症状:单卡跑得飞快,加到 64 卡、512 卡却没有线性加速,扩展性陡峭恶化。
本质:分布式训练中,多机多卡之间交换梯度与参数的时间,超过了计算本身。
1. Bucket:梯度分桶通信
网络通信有显著的"固定开销"(握手、封包、调度)。一个模型有上百万个参数张量,如果每算出一个就发一次请求,网络会被海量小包打垮。
Bucket 在底层维护一个缓冲区(比如 25MB):算出的梯度先丢进桶里,桶满了再打包一次性发送。化零为整,带宽利用率拉满。
2. Overlap:计算与通信重叠
完美并行的最高境界。反向传播是从最后一层往前算的------当第 N 层的梯度算完,立刻交给网卡发送(通信);与此同时,GPU 马不停蹄地开始算第 N-1 层(计算)。
只要通信耗时小于下一层的计算耗时,通信开销就被完全隐藏。这是 DDP、FSDP 等框架性能的命脉。
3. 拓扑感知(Topology Awareness)
机器内的 GPU 是 NVLink 直连还是走 PCIe?机器之间是 InfiniBand 还是普通以太网?
通信库(如 NCCL )如果能感知到底层物理拓扑,就会安排最优的数据接力路线:机内走 NVLink 环(Ring)、跨机走 IB 网格(Mesh),避免链路拥堵。"知道路怎么走"和"瞎跑"的差距,往往是数倍的端到端速度差。
4. IB / RDMA:硬件级网络加速
传统的网络发送链路:
GPU → CPU 内存 → 网卡 → 对端网卡 → CPU 内存 → 对端 GPU每一跳都要 CPU 参与,延迟和开销都很大。
RDMA(Remote Direct Memory Access) 让网卡直接读写对方机器的 GPU 显存,完全绕过 CPU 和操作系统内核 。InfiniBand(IB) 则是支撑 RDMA 的最高端硬件网络(交换机+网卡),延迟低至微秒级,是大模型训练集群的标配。
5. 减少同步频率
如果网络实在太差,还可以从算法层面妥协:
- Local SGD:每算 5 步才做一次全局同步,而不是每步都同步;
- 结合梯度累积:跑好几个微批次只做一次通信同步。
代价是收敛性会受影响,但在通信极度受限的环境下是务实的选择。
结语:从兵器谱到实战心法
回到一开始的那句话------找到瓶颈,对症下药。
这四类瓶颈的应对手段看起来浩瀚,但抓住几条主线就不会迷失:
| 瓶颈类型 | 核心思想 | 代表手段 |
|---|---|---|
| 数据慢 | 让数据流水线异步、并行、本地化 | num_workers、pin_memory、prefetch、离线 decode |
| 计算慢 | 用更低的精度、更少的访存做更多的事 | AMP/BF16、算子融合、torch.compile |
| 显存不足 | 时间换空间、空间换通信 | Checkpoint、梯度累积、ZeRO/FSDP |
| 通信慢 | 化零为整、计算通信重叠、绕过 CPU | Bucket、Overlap、RDMA/IB |
真正的高手,从不一上来就堆技术。他们会先用 Profiler 把"GPU 在干什么、在等什么"看清楚,再从这份兵器谱里抽出最对症的那一招。先诊断,再开方------这是大规模训练性能调优永恒的方法论。