JVM 底层彻底理解
- [一、JVM 到底解决了什么问题(先理解本质)](#一、JVM 到底解决了什么问题(先理解本质))
-
- [JVM 的本质目标只有三点](#JVM 的本质目标只有三点)
- 核心结论
- [二、JVM 整体架构(为什么要分这些模块)](#二、JVM 整体架构(为什么要分这些模块))
-
- [JVM 为什么要分这三层?](#JVM 为什么要分这三层?)
- [JVM 为什么一定要"拆模块"?](#JVM 为什么一定要“拆模块”?)
- [三、运行时数据区(JVM 内存模型)](#三、运行时数据区(JVM 内存模型))
-
- [JVM 内存只分两大类](#JVM 内存只分两大类)
-
- [1. 程序计数器(最小,但不可或缺)](#1. 程序计数器(最小,但不可或缺))
- [2. 虚拟机栈(排错最常见)](#2. 虚拟机栈(排错最常见))
- [3. 本地方法栈(补充点)](#3. 本地方法栈(补充点))
- [4. 堆(GC 的主战场)](#4. 堆(GC 的主战场))
- [5. 方法区 / 元空间(类的存储区)](#5. 方法区 / 元空间(类的存储区))
- 总结
- 四、对象从创建到回收的完整生命周期
-
- [1. 对象创建全过程](#1. 对象创建全过程)
- [2. 内存分配方式(为什么有两种)](#2. 内存分配方式(为什么有两种))
- [3. 对象创建为什么是线程安全的?](#3. 对象创建为什么是线程安全的?)
- [五、垃圾回收机制(GC 底层原理)](#五、垃圾回收机制(GC 底层原理))
-
- [1. 如何判断对象已死?](#1. 如何判断对象已死?)
- [2. GC 算法为什么要"组合使用"?](#2. GC 算法为什么要“组合使用”?)
- [3. G1 垃圾回收器(主流)](#3. G1 垃圾回收器(主流))
- 总结
- 六、内存泄漏
-
- [1. 内存泄漏的本质定义](#1. 内存泄漏的本质定义)
- [2. 常见泄漏场景的底层原因](#2. 常见泄漏场景的底层原因)
- [3. 内存泄漏与 OOM 的关系](#3. 内存泄漏与 OOM 的关系)
- [七、逃逸分析(JIT 的核心优化能力)](#七、逃逸分析(JIT 的核心优化能力))
-
- [1. 什么是逃逸?](#1. 什么是逃逸?)
- [2. JVM 为什么关心"逃逸"?](#2. JVM 为什么关心“逃逸”?)
- [3. 三大核心优化](#3. 三大核心优化)
-
- [1. 栈上分配](#1. 栈上分配)
- [2. 标量替换(优化力度最大)](#2. 标量替换(优化力度最大))
- [3. 锁消除](#3. 锁消除)
- 总结
- [八、JVM 调优与问题排查](#八、JVM 调优与问题排查)
-
- [1. 常见 OOM 类型(先会分类)](#1. 常见 OOM 类型(先会分类))
- [2. 排查 OOM 的标准流程](#2. 排查 OOM 的标准流程)
- [3. 常用 JVM 排查工具](#3. 常用 JVM 排查工具)
- 总结
- 九、总结
一、JVM 到底解决了什么问题(先理解本质)
在 JVM 出现之前:
-
C / C++ 需要手动管理内存
-
内存泄漏、野指针问题频发且难排查
-
程序强依赖操作系统,跨平台成本高
这些问题的共同点只有一个:
复杂、易错、不可控。
JVM 的本质目标只有三点
一句话先记住:隔离、托管、优化。
-
屏蔽底层操作系统差异
程序不再直接依赖操作系统,而是运行在 JVM 之上,实现"一次编写,到处运行"。
-
自动内存管理(GC)
对象创建、回收由 JVM 统一管理,开发者只关心"是否还在使用",不再和内存细节纠缠。
-
通过运行期优化获得接近原生的性能
JVM 会在运行过程中识别热点代码并进行编译优化,长期运行下性能接近甚至等同原生程序。
核心结论
JVM 不是为了"极限快",而是为了稳定、可控、可长期运行。
它本质上是一个:
以空间换安全、以运行期分析换性能
的工程系统。
二、JVM 整体架构(为什么要分这些模块)
JVM 不是一个黑盒,而是一个高度分层、职责清晰的系统:
text
ClassLoader → Runtime Data Area → Execution Engine一句话理解这条链路:
先把类弄进来 → 给数据找地方 → 把代码跑起来
JVM 为什么要分这三层?
因为 JVM 要同时解决三类完全不同的问题:
加载、存储、执行。
-
类加载器(ClassLoader)
核心职责:把 class 文件变成 JVM 能用的 Class 对象
- 负责类的加载、校验、链接、初始化
- 支持按需加载,而不是一次性全部加载
- 通过双亲委派机制保证核心类安全
一句话记忆:
类加载器决定"类从哪来、能不能用"
高频点:
-
为什么需要双亲委派?
一句话答案:
防止核心类被篡改,保证类加载的安全性和一致性。
关键点:
- 优先由父加载器加载,避免自定义类覆盖
java.lang.* - 保证同一个类在 JVM 中的唯一性
- 优先由父加载器加载,避免自定义类覆盖
-
自定义 ClassLoader 的典型场景?
一句话答案:
隔离、扩展、动态加载。
典型场景:
- 插件化系统(不同插件使用不同依赖)
- 热加载 / 热部署
- 应用隔离(如 Tomcat、多应用容器)
-
运行时数据区(Runtime Data Area)
核心职责:给程序运行中的数据分配内存
- 方法区:类元数据、常量、静态变量
- 堆:对象实例
- 虚拟机栈 / 本地方法栈:方法调用、局部变量
- 程序计数器:线程执行位置
一句话记忆:
运行时数据区决定"数据放哪、生命周期多长"
高频点:
-
堆和栈的区别?
一句话答案:
堆存对象,栈存方法调用。
关键点:
- 堆:线程共享,GC 管理,对象实例
- 栈:线程私有,方法栈帧,自动回收
-
哪些区域线程私有,哪些线程共享?
一句话答案:
栈、程序计数器是私有的;堆和方法区是共享的。
记忆口诀:
"对象共享,调用私有"
-
OOM 和 StackOverflowError 的根源?
一句话答案:
OOM 是内存不够,SOF 是调用太深。
对应关系:
- OOM:堆、方法区内存耗尽
- StackOverflowError:递归或方法调用层级过深
-
执行引擎(Execution Engine)
核心职责:把字节码真正跑起来
- 解释执行:启动快
- JIT 编译:热点代码转为机器码
- 运行期优化:内联、逃逸分析、锁消除
一句话记忆:
执行引擎决定"怎么跑、跑得快不快"
高频点:
-
解释执行 vs JIT?
一句话答案:
解释执行启动快,JIT 执行快。
关键点:
- 解释执行:逐条解释字节码
- JIT:热点代码编译为机器码
-
什么是热点代码?
一句话答案:
被频繁执行、值得编译优化的代码。
关键点:
- JVM 通过计数器识别
- 热点才会触发 JIT
-
为什么 Java 能越跑越快?
一句话答案:
因为 JVM 会对热点代码持续做运行期优化。
核心逻辑:
- 先解释执行
- 再 JIT 编译
- 最终稳定在高性能状态
JVM 为什么一定要"拆模块"?
如果不拆,会出现三个致命问题:
- 类加载和内存强耦合,无法支持热加载
- 内存和执行强耦合,无法做运行期优化
- 执行逻辑固化,JIT、GC 无法演进
而拆分之后,JVM 获得了三种能力:
- 解耦:加载、存储、执行互不干扰
- 可扩展:ClassLoader、GC、JIT 都可替换
- 运行期优化:边跑边分析,动态决策
一句话总结
ClassLoader 负责"引入"
Runtime Data Area 负责"承载"
Execution Engine 负责"执行"
JVM 的所有高级特性(GC、JIT、热加载),
都建立在这三层解耦之上。
三、运行时数据区(JVM 内存模型)
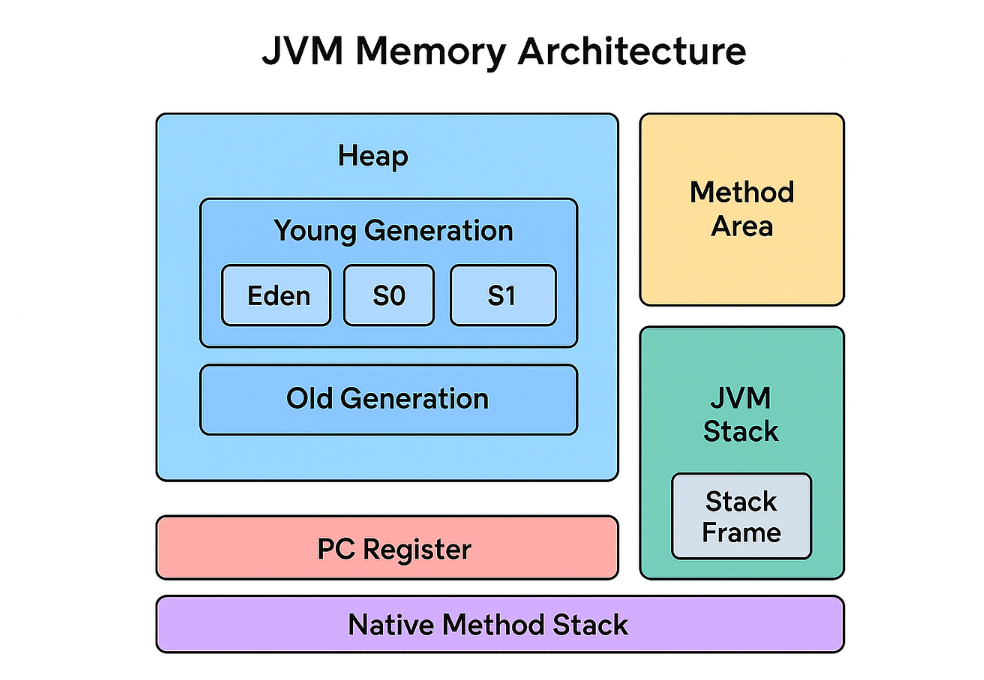
JVM 的运行时数据区不是随便划的,它直接决定了:
-
GC 怎么做
-
多线程是否安全
-
OOM 和 StackOverflowError 从哪来
JVM 内存只分两大类
一句话先记住:
-
线程私有:只和当前线程有关
-
线程共享:所有线程共同使用
这是理解 GC、并发安全、内存异常 的根本前提。
1. 程序计数器(最小,但不可或缺)
本质
- 记录当前线程正在执行的字节码位置
- 线程切换后能从正确位置继续执行
关键特点
- 线程私有
- 唯一不会发生 OOM 的内存区域
高频速答
-
为什么 Java 多线程切换不会乱?
一句话答案:
每个线程都有独立的程序计数器,保存自己的执行位置。
2. 虚拟机栈(排错最常见)
栈的基本单位:栈帧
每一次方法调用都会创建一个栈帧,包含:
-
局部变量表
-
操作数栈
-
动态链接
-
方法返回地址
局部变量表里有什么?
- 基本数据类型
- 对象引用(reference)
关键认知点:
对象在堆中,栈中只保存引用
两类典型异常(必须能区分)
-
StackOverflowError
-
方法递归过深
-
栈帧不断入栈,空间耗尽
-
-
OutOfMemoryError(与栈相关)
-
线程创建过多
-
每个线程都要分配栈空间
-
高频速答
-
栈为什么是线程私有的?
一句话答案:
方法调用链不能被多个线程共享,否则执行状态会混乱。
3. 本地方法栈(补充点)
-
为
native方法服务 -
HotSpot 中通常与虚拟机栈合并实现
主要存储 native 方法执行过程中使用的:
- 参数
- 局部变量
- 返回值
- JNI 调用相关的上下文信息
- 底层平台的调用状态。
一般不单独深挖,但要知道它属于线程私有。
native 方法是指:方法的实现不在 Java 代码中,而是由 Java 以外的语言(通常是 C / C++)实现的方法。
4. 堆(GC 的主战场)
堆的核心职责
-
存放对象实例
-
线程共享
-
GC 管理的主要区域
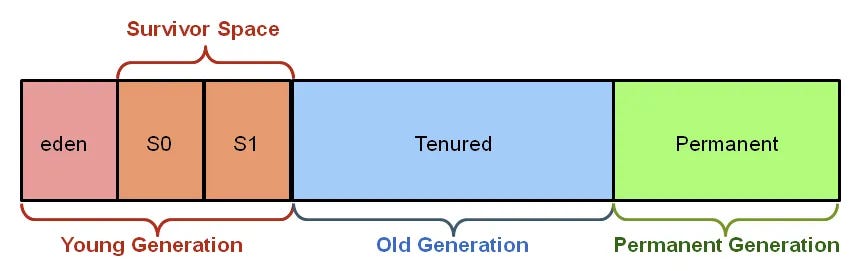
为什么堆要"分代"?
不是拍脑袋设计,而是基于一个长期统计结论:
绝大多数对象,存活时间非常短
因此 JVM 才采用分代模型来降低 GC 成本。
新生代结构与流转
新生代分为:
- Eden
- Survivor From
- Survivor To
对象流转路径:
text
Eden → S0 → S1 → Old每次 Minor GC:
-
存活对象复制到 Survivor
-
年龄加 1
-
达到阈值后晋升老年代
老年代的特点
-
对象存活时间长
-
GC 次数少,但代价高
-
Full GC 的主要区域
高频速答
-
为什么 Minor GC 快,Full GC 慢?
一句话答案:
新生代对象少且易回收,老年代对象多且存活时间长。
5. 方法区 / 元空间(类的存储区)
JDK 8 的关键变化
-
移除永久代(PermGen)
-
引入 Metaspace(元空间)
为什么要这样改?
永久代的问题:
-
空间固定
-
容易 OOM
-
与堆强耦合
元空间的优势:
-
使用本地内存
-
可动态扩展
-
更适合大量类加载(如 Spring、动态代理)
高频点
-
为什么永久代被移除?
一句话答案:
避免固定大小限制,提升类加载场景下的稳定性。
总结
计数器保执行,切线程不乱
栈管调用,堆管对象
新生代快收,老年代慢清
类信息不进堆,进元空间
这套内存模型,直接支撑了:
- GC 设计
- 并发模型
- JVM 性能优化
四、对象从创建到回收的完整生命周期
常态:
"你 new 一个对象,JVM 到底干了什么?"
1. 对象创建全过程
标准五步,一步不能少:
-
类是否已加载
没加载先触发类加载(加载、链接、初始化)
-
分配内存
在堆中为对象分配空间
-
初始化零值
实例字段设置默认值(保证对象可用)
-
设置对象头
包含类指针、GC 信息、锁信息等
-
执行构造方法
按代码逻辑完成初始化
高配点
-
对象创建的完整过程?
一句话答案:
检查类 → 分内存 → 清零 → 设对象头 → 调构造方法
2. 内存分配方式(为什么有两种)
对象分配的前提是:
堆内存是否连续。
-
指针碰撞
适用场景:
- 堆内存连续
- 如 Serial、ParNew 收集器
做法:
- 维护一个指针
- 分配时指针向前移动
特点:
- 实现简单
- 分配速度快
-
空闲列表
适用场景:
- 堆内存不连续
- 如 CMS、G1
做法:
- 维护可用内存块列表
- 从合适位置分配
特点:
- 灵活
- 维护成本更高
高频点
-
指针碰撞和空闲列表的区别?
一句话答案:
是否要求堆内存连续。
3. 对象创建为什么是线程安全的?
因为对象创建发生在多线程并发环境下。
JVM 主要提供两种方案:
-
方案一:CAS + 重试
- 通过原子操作更新内存指针
- 失败则重试
优点:通用
缺点:高并发下有性能损耗
-
方案二:TLAB(线程本地分配缓冲区)(默认)
Thread Local Allocation Buffer
核心思想:
- 每个线程在堆中预分配一小块内存
- 线程内对象分配无需加锁
特点:
- 无锁
- 分配速度快
- 大多数对象直接在 TLAB 中完成分配
高频点
-
JVM 默认是否开启 TLAB?
一句话答案:
是的,默认开启,用于提升对象分配效率。
五、垃圾回收机制(GC 底层原理)
GC 的核心只解决三件事:
对象死没死 → 怎么回收 → 何时回收得更优
1. 如何判断对象已死?
为什么不用引用计数?
引用计数的问题只有一句话:
循环引用无法回收
两个对象互相引用,但外部已不可达,
引用计数不为 0,却早该被回收。
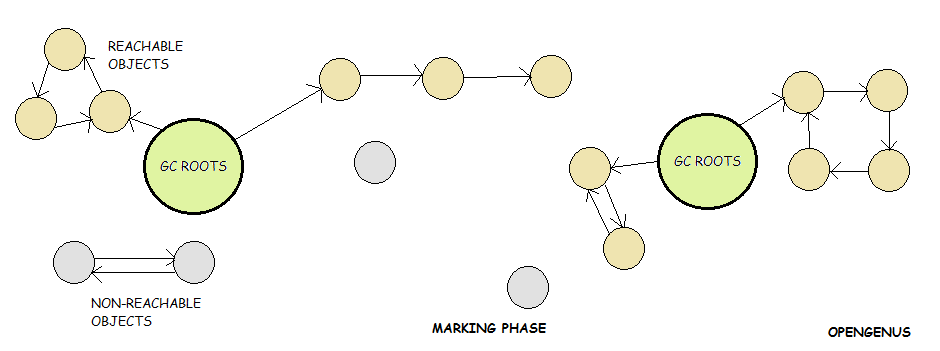
JVM 的标准答案:可达性分析
核心思想:
从一组"必然存活"的对象出发,看能不能走到目标对象。
这组起点,叫 GC Roots。
常见 GC Roots
- 虚拟机栈中的引用
- 类静态变量
- 常量池中的引用
- JNI(本地方法)引用
结论规则:
从 GC Roots 不可达的对象,才是可回收对象
高频点
-
JVM 如何判断对象是否可回收?
一句话答案:
通过 GC Roots 做可达性分析,不可达即回收。
2. GC 算法为什么要"组合使用"?
因为不同区域的对象特性完全不同。
-
新生代:复制算法
特点:
-
对象存活率低
-
回收频繁
优势:
- 只复制存活对象
- 回收速度快
代价:
- 需要额外空间(Survivor)
-
-
老年代:标记-整理算法
特点:
- 对象存活率高
- 不能频繁移动
优势:
- 避免内存碎片
- 适合长期存活对象
代价:
- 回收成本高
核心结论
没有万能 GC 算法,只有场景最优组合。
高频点
-
为什么新生代和老年代用不同算法?
一句话答案:
因为对象存活率不同,回收策略必须不同。
3. G1 垃圾回收器(主流)
G1 的出现,本质是为了解决一个问题:
在大堆内存下,如何控制 GC 停顿时间?
G1 的核心设计思想
- 把整个堆拆成多个 Region
- Region 可以是新生代,也可以是老年代
- 不再固定按代整体回收
一句话理解:
不按"代"收,按"价值"收
什么是"回收价值"?
综合考虑:
-
Region 中垃圾比例
-
回收收益
-
回收成本
优先回收 性价比最高 的 Region。
为什么 G1 停顿时间可控?
核心原因只有两点:
-
每次只回收部分 Region
-
可以根据目标停顿时间做回收计划
这也是 G1 名字的来源:
Garbage First(优先回收垃圾最多的区域)。
高频点
-
G1 为什么能控制停顿时间?
一句话答案:
通过 Region 化和按回收价值选择回收范围。
总结
-
死没死看 Roots
-
算法选型看存活率
-
G1 不按代,按价值收
六、内存泄漏
1. 内存泄漏的本质定义
一句话定义:
对象已经没有业务意义,但仍然被 GC Roots 间接或直接引用。
关键点要说清楚:
-
不是"内存不够"
-
而是引用关系断不开
-
GC 按规则工作,但规则失效于设计错误
高频点
-
什么是内存泄漏?
一句话答案:
对象该死但没死,因为还在 GC Roots 引用链上。
2. 常见泄漏场景的底层原因
-
静态引用(最基础)
为什么会泄漏?
- 静态变量生命周期 = JVM 生命周期
- 天然属于 GC Roots
一旦静态集合、静态缓存不断增长:
对象永远不可回收
高频点
-
为什么静态变量容易导致内存泄漏?
一句话答案:
因为它们是 GC Roots,生命周期过长。
-
ThreadLocal 泄漏
问题不在 ThreadLocal,而在线程池。
底层结构:
- key:ThreadLocal(弱引用)
- value:业务对象(强引用)
当:
- ThreadLocal 被回收
- 线程长期存活(线程池)
结果:
value 仍被线程引用,无法回收
正确姿势(必须说)
- 使用后 finally 中调用 remove()
高频点
-
ThreadLocal 为什么会内存泄漏?
一句话答案:
线程不结束,value 强引用还在。
-
连接、流未关闭
典型对象:
- JDBC 连接
- Socket
- IO 流
问题本质:
- 不仅占 JVM 堆
- 还占用 操作系统资源
这种泄漏,往往比 OOM 更危险。
高频点
-
为什么流不关闭问题严重?
一句话答案:
既泄漏内存,又泄漏系统资源。
3. 内存泄漏与 OOM 的关系
一句话因果关系:
内存泄漏是原因,OOM 是最终结果。
- 少量泄漏 → 系统还能撑
- 长期泄漏 → 必然 OOM
高频点
OOM 往往不是"突然发生",
而是泄漏长期积累的必然结果。
七、逃逸分析(JIT 的核心优化能力)
让 JVM 判断"对象需不需要进堆"。
1. 什么是逃逸?
标准定义:对象是否可能被方法之外访问。
不逃逸的典型特征
-
只在方法内部使用
-
不作为返回值
-
不赋值给外部变量
一句话记忆:
出不了方法的对象,就是不逃逸。
高频点
-
什么是逃逸分析?
一句话答案:
JVM 判断对象作用域是否超出方法范围。
2. JVM 为什么关心"逃逸"?
因为一旦确认 不逃逸:
对象就没必要进堆。
直接收益:
-
减少堆内存分配
-
减少 GC 压力
-
提升整体性能
高频点
-
逃逸分析的核心目的是什么?
一句话答案:
减少对象进入堆,从而减少 GC。
3. 三大核心优化
1. 栈上分配
结论型描述:
- 对象直接分配在栈上
- 方法结束自动销毁
- 不参与 GC
适用前提:
- 对象不逃逸
高频点
-
什么是栈上分配?
一句话答案:
不逃逸对象直接在栈上分配。
JVM 在逃逸分析后,不再创建对象, 而是把对象字段拆成标量 ,可能分布在栈帧、操作数栈甚至寄存器中。
2. 标量替换(优化力度最大)
核心思想:
对象可以拆,就没必要存在。
做法:
- 把对象拆成多个基本类型变量
- 对象本身彻底消失
效果:
- 零对象创建
- 零 GC 压力
高频点
-
什么是标量替换?
一句话答案:
把对象拆成基本类型,彻底消除对象。
3. 锁消除
适用场景:
-
锁对象不逃逸
-
没有多线程竞争
JIT 判断后:
直接移除 synchronized 锁。
高频点
-
JVM 为什么能安全地消除锁?
一句话答案:
因为逃逸分析确认不存在并发访问。
总结
逃不逃,看范围
不进堆,GC 少
栈分配、标量换、锁直接消
八、JVM 调优与问题排查
1. 常见 OOM 类型(先会分类)
-
Java heap space一句话含义:
堆中对象过多,GC 回收不过来。
常见原因:
- 内存泄漏
- 大对象加载
- 缓存无限增长
-
Metaspace一句话含义:
类加载太多,元空间被打满。
常见原因:
- 动态代理 / CGLIB 过多
- 类加载器无法回收
- 热部署、插件化使用不当
-
GC overhead limit exceeded
一句话含义:
GC 拼命干活,但几乎回收不到内存。
本质判断:
系统已经处在"濒死状态"
高频点
-
OOM 常见有哪些类型?
一句话答案:
堆、元空间、GC 过载。
2. 排查 OOM 的标准流程
这一步比"调参"重要十倍。
标准四步法
-
确认 OOM 类型
先判断是堆、元空间,还是 GC 问题
-
Dump 内存快照
OOM 时或手动触发 Heap Dump
-
分析对象引用链
找出占用最多、不可回收的对象
-
定位代码根因
回到代码,解决引用问题,而不是只扩容
高频点
-
线上 OOM 你怎么排查?
一句话答案:
先定类型,再看 Dump,最后回到代码。
3. 常用 JVM 排查工具
不要求你精通,但必须知道用来干什么。
-
jps-
查看 JVM 进程
-
快速确认目标进程 ID
一句话:
找 JVM 进程用的。
-
-
jstack-
查看线程栈
-
排查死锁、线程阻塞
一句话:
看线程状态。
-
-
jmap- Dump 堆内存
- 查看对象分布
一句话:
看堆里的对象。
-
jvisualvm- 图形化监控
- 内存、线程、GC 情况
一句话:
本地/测试环境快速分析。
-
arthas- 线上诊断
- 方法调用、参数、返回值
- 无需重启
一句话:
线上救火神器。
总结
OOM 先分型
排查四步走
jstack 看线程,jmap 看对象,arthas 救线上
九、总结
-
JVM 不是简单的虚拟机,而是一个持续做运行期优化的系统
-
GC 的本质不是"回收内存",而是分析对象之间的引用关系
-
内存泄漏不是没 GC,而是对象仍在 GC Roots 引用链上
-
逃逸分析是 JIT 性能优化的前提,没有它就没有高效优化
-
G1 通过 Region 化和按价值回收,成为当前服务端主流选择