SparkCore算子总结
◉ partitionBy算子
在SparkCore 中,partitionBy算子 常用于对pairRDD进行分区操作。这一算子在原有分区与新指定的分区不一致时,会触发Shuffle操作。它通过分区器来实现对数据的重新分区,这种特性在数据预处理及优化任务中尤其有用。
在操作过程中,首先我们会创建一个包含若干键值对的RDD,并明确指定其分区。随后,利用partitionBy算子,当设置不同的分区策略时,会生成新的ShuffleRDD,可用于后续的各种计算。
◉ groupByKey算子与reduceByKey函数
groupByKey算子 与reduceByKey函数在处理相同键时表现有所不同。groupByKey会将具有相同键的值聚集到一个序列中,然而并不进行合并操作;而reduceByKey则能够预聚合相同键的值,尤其在需要合并操作时显得更为高效。
案例解析:
通过一个具体的案例可以更直观地理解这两个算子的不同。假设我们有一个pairRDD,其中每个键都是一个字符串,而值为1。使用groupByKey算子会将相同键的值组合在一起,形成一个包含所有值的序列,例如,("two", CompactBuffer(1,1))。而reduceByKey算子会在内部预聚合这些值,输出如("two", 2)之类的简洁结果。
此外,与groupByKey不同,reduceByKey提供了更强大的函数设置,可以在每个键上执行特定的聚合操作,如求和、求平均等。这正是它应用广泛的重要原因。
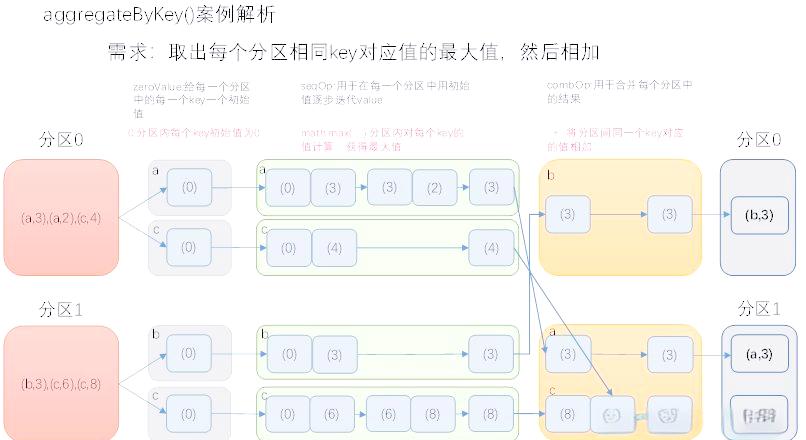
◉ aggregateByKey函数
aggregateByKey函数 提供了更为灵活的参数设置,适用于更加复杂的聚合操作。它通过结合seqOp 和combOp函数,可以在合并过程中定制化的处理每个值。这种灵活性使得在数据处理中,能够针对具体业务需求进行灵活的调整。
实际案例:
构建一个pairRDD,抽取每个分区中相同key的值的最大值,并进行求和操作,就可以很好地展示aggregateByKey的使用方式。通过设置适当的函数,能够实现对数据的复杂聚合。
◉ Developer建议与应用案例
在项目开发中,选择合适的算子可以极大提升系统的性能。基于具体需求,当需要直接将相同键的值聚集到一个序列中时,可以选择groupByKey;而当需要对键值进行预聚合时,最优先考虑reduceByKey。同时,对于更复杂的分组合并操作,可以考虑使用aggregateByKey。
实际应用示例:
通过具体实际的应用案例,如计算不同键的值的总和、平均值等,开发者可以根据需要选择合适的函数,并在项目中发挥它们的最大潜力。通过不断的实践和总结,可以选择出最优的数据处理方案,从而提高应用的整体效率。