一、前言
在大数据开发的学习过程中,数据采集是整个数据链路的第一环。Flume作为Apache旗下的高可用、高可靠、分布式的海量日志采集系统,是大数据生态圈中不可或缺的基础组件。本文将结合我的实验经验,从Flume的基础架构讲起,深入讲解Taildir Source 的实战配置,并分享一个完整的监听目录文件变化并将数据实时写入HDFS的生产级配置方案。
二、Flume概述
2.1 什么是Flume?
Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统 。它基于流式架构,能够灵活简单地实现数据的实时采集。
在大数据处理的三大核心问题(采集、存储、计算 )中,Flume专门解决采集 问题。它最主要的作用就是:实时读取服务器本地磁盘的数据,将数据写入到HDFS或其他存储系统。
2.2 Flume的应用场景
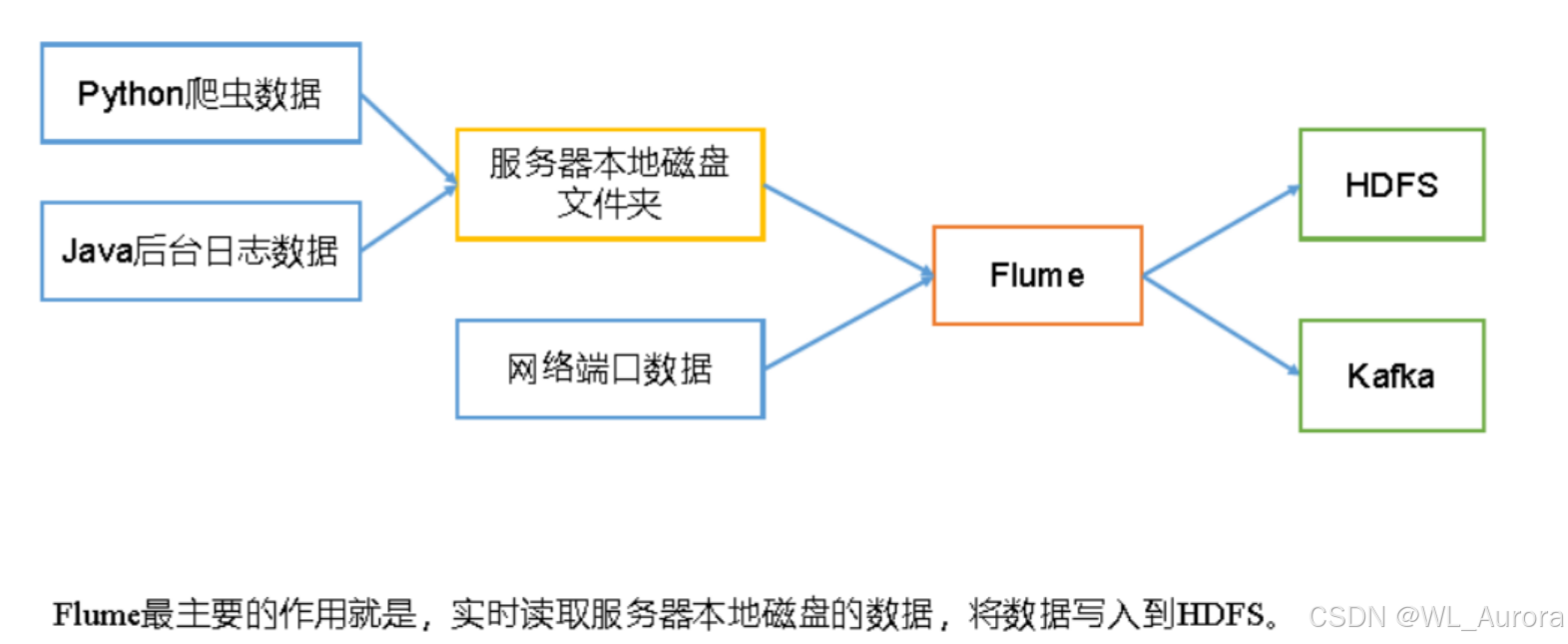
为什么不用hadoop fs -put直接上传?
因为Flume是实时 的!当本地文件发生变化时,Flume能够立即感知并将新增数据推送到HDFS,而hadoop fs -put只能一次性上传,无法实现持续监控和增量同步。
三、Flume基础架构
3.1 Agent架构
Flume的运行单元是Agent,它是一个JVM进程,以**Event(事件)**的形式将数据从外部源传递到目的地。
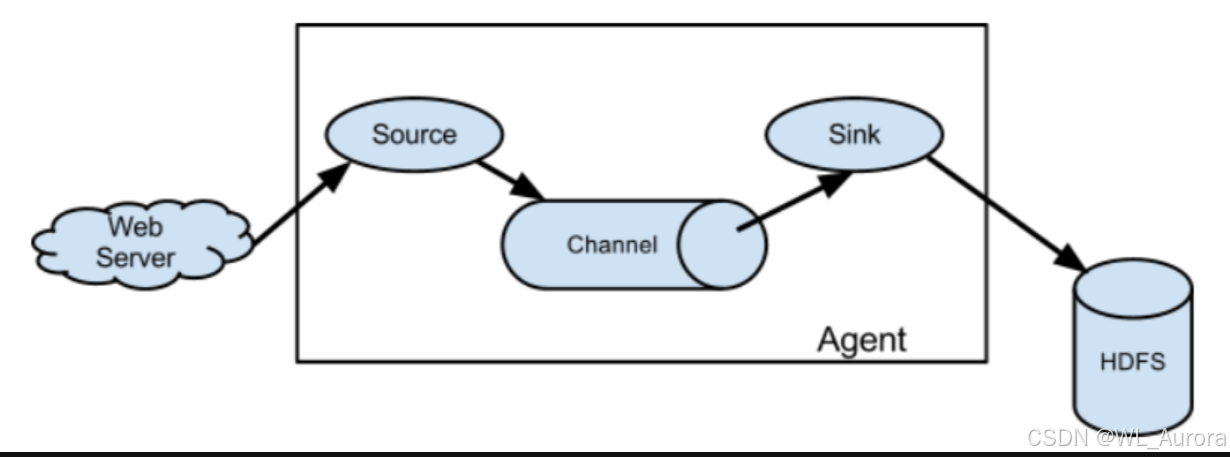
3.2 核心组件详解
| 组件 | 作用 | 常用类型 |
|---|---|---|
| Source | 负责接收数据到Flume Agent | taildir、exec、spooldir、netcat |
| Channel | 位于Source和Sink之间的缓冲区 | memory(内存,速度快但不安全)、file(磁盘,速度慢但安全) |
| Sink | 轮询Channel中的事件并批量移除,写入存储系统 | hdfs、logger、kafka、file |
| Event | Flume的数据传输单元,由Header(K-V属性)和Body(字节数组)组成 | --- |
注意:这里的"分布式"指的是Flume可以从分布式各个节点的日志数据收集起来,而不是说Flume本身需要搭建分布式集群。
四、Source类型对比与选型
在实际项目中,Source的选择至关重要。以下是三种常用Source的对比:
| Source类型 | 适用场景 | 特点 | 缺点 |
|---|---|---|---|
| Exec Source | 监控单个追加文件 | 执行Linux命令(如tail -F)实时读取 |
进程退出后Source也退出,不保证数据不丢失 |
| Spooldir Source | 监控整个目录的新文件 | 自动监听目录,上传后标记.COMPLETED |
不能监控正在写入的文件,只能处理"完成"的文件 |
| Taildir Source | 监控多个文件的变化(推荐) | 支持正则匹配多个文件,记录读取位置,支持断点续传 | 配置稍复杂 |
4.1 为什么推荐使用Taildir Source?
我们需要同时监听多个数据文件的变化。Taildir Source相比Exec和Spooldir有以下优势:
- 支持断点续传 :通过
positionFile记录每个文件的读取位置,Agent重启后从上次位置继续读取 - 支持正则匹配:可以通过正则表达式同时监控多个文件
- 实时监控:能够监控正在追加写入的文件
- 高可靠性:即使程序崩溃或机器宕机,也不会丢失数据
五、实战案例:Taildir Source + HDFS Sink 完整配置
5.1 实验环境
- 操作系统:CentOS 7
- Hadoop版本:3.1.3
- Flume版本:1.9.0
- JDK:1.8+
- 实验数据:本地采集的职位数据集
5.2 需求分析
我们需要实现以下功能:
- 使用Flume实时监控指定目录下文件的变化
- 将采集到的数据实时写入HDFS
- 配置时间戳拦截器,为Event添加时间戳头部
- 设置合理的文件滚动策略,避免HDFS产生过多小文件
5.3 完整配置文件(可直接复制使用)
在Flume安装目录下创建配置文件 job/flume-taildir-hdfs.conf:
properties
# ============================================
# Flume配置:Taildir Source + Memory Channel + HDFS Sink
# 功能:实时监控目录文件变化,数据写入HDFS
# 适用场景:大数据采集、日志实时同步
# ============================================
# 1. 定义Agent的组件名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# ============================================
# 2. Source配置:Taildir Source
# ============================================
# 指定Source类型为Taildir,监控目录中文件的变化
a1.sources.r1.type = TAILDIR
# 定义文件分组,这里定义一个分组f1
a1.sources.r1.filegroups = f1
# 指定监控目录和文件匹配规则(正则表达式)
# 示例:监控 /opt/module/flume-1.9.0/fruit_data/ 目录下所有文件
a1.sources.r1.filegroups.f1 = /opt/module/flume-1.9.0/fruit_data/.*
# 指定positionFile路径,用于记录文件读取位置(断点续传关键)
# 该文件为JSON格式,记录每个文件的inode和读取偏移量
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/fruit_position.json
# ============================================
# 3. Interceptor配置:时间戳拦截器
# ============================================
# 定义拦截器名称
a1.sources.r1.interceptors = i1
# 指定拦截器类型为Timestamp Interceptor
# 作用:在Event的headers中添加时间戳,供HDFS Sink使用
a1.sources.r1.interceptors.i1.type = timestamp
# ============================================
# 4. Channel配置:Memory Channel
# ============================================
# 指定Channel类型为Memory Channel,基于内存缓存
a1.channels.c1.type = memory
# Channel缓存事件的最大容量(队列大小)
a1.channels.c1.capacity = 1000
# Channel中每个事务能够处理事件数量的上限
# 事务容量必须 <= 事件容量,事务的作用是保证数据不丢失(支持回滚)
a1.channels.c1.transactionCapacity = 100
# ============================================
# 5. Sink配置:HDFS Sink
# ============================================
# 指定Sink类型为HDFS,将事件写入HDFS文件
a1.sinks.k1.type = hdfs
# 指定HDFS目标路径
# 注意:路径需要提前在HDFS中创建,或使用自动创建
a1.sinks.k1.hdfs.path = /flume
# 指定上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = fruit-
# 启用轮询模式,按时间滚动文件夹
a1.sinks.k1.hdfs.round = true
# 生成新文件的时间间隔(单位:秒)
# 每10秒生成一个新文件
a1.sinks.k1.hdfs.rollInterval = 10
# 当累积事件大小达到128MB时生成新文件
# 134217728 bytes = 128 MB
a1.sinks.k1.hdfs.rollSize = 134217728
# 新文件生成与Event数量无关(0表示不基于数量滚动)
a1.sinks.k1.hdfs.rollCount = 0
# 指定文件类型为DataStream(普通文本流,可直接查看内容)
# 可选:SequenceFile(序列化,不可读)、CompressedStream(压缩流)
a1.sinks.k1.hdfs.fileType = DataStream
# ============================================
# 6. 绑定Source、Sink到Channel
# ============================================
# 将Source与Channel关联(一个Source可绑定多个Channel)
a1.sources.r1.channels = c1
# 将Sink与Channel关联(一个Sink只能绑定一个Channel)
a1.sinks.k1.channel = c15.4 配置参数详解
5.4.1 Taildir Source 核心参数
| 参数名 | 说明 | 示例值 |
|---|---|---|
type |
必须设置为TAILDIR |
TAILDIR |
filegroups |
文件分组名称列表 | f1 |
filegroups.<name> |
监控目录的正则表达式 | /opt/module/flume-1.9.0/fruit_data/.* |
positionFile |
断点续传关键:记录文件读取位置的JSON文件路径 | /opt/module/flume-1.9.0/fruit_position.json |
positionFile工作原理:
json
// positionFile内容示例(JSON格式)
[
{
"inode": 12345678,
"pos": 1024,
"file": "/opt/module/flume-1.9.0/fruit_data/data1.csv"
},
{
"inode": 12345679,
"pos": 2048,
"file": "/opt/module/flume-1.9.0/fruit_data/data2.csv"
}
]Flume通过inode 唯一标识文件,通过pos 记录读取位置。即使Agent重启,也能从上次位置继续读取,保证数据不丢失、不重复。
5.4.2 Timestamp Interceptor 详解
┌─────────────────────────────────────────┐
│ Event │
│ ┌─────────────────────────────────┐ │
│ │ Header │ │
│ │ { │ │
│ │ "timestamp": "1702032000000" │ │ ← 拦截器自动添加
│ │ } │ │
│ └─────────────────────────────────┘ │
│ ┌─────────────────────────────────┐ │
│ │ Body │ │
│ │ "苹果,北京,5.50,2023-12-08" │ │
│ └─────────────────────────────────┘ │
└─────────────────────────────────────────┘时间戳拦截器在Event的headers中添加timestamp字段,HDFS Sink可以利用这个字段进行时间分区存储(如按天、按小时创建目录)。
5.4.3 HDFS Sink 文件滚动策略
HDFS Sink通过三个参数控制文件生成策略,满足任一条件即触发新文件创建:
| 参数 | 默认值 | 说明 |
|---|---|---|
hdfs.rollInterval |
30(秒) | 按时间间隔滚动文件,0表示不基于时间滚动 |
hdfs.rollSize |
1024(字节) | 按文件大小滚动,0表示不基于大小滚动 |
hdfs.rollCount |
10 | 按Event数量滚动,0表示不基于数量滚动 |
生产环境建议配置:
rollInterval = 3600(1小时):避免产生过多小文件rollSize = 134217728(128MB):与HDFS块大小对齐rollCount = 0:不基于数量滚动
5.5 启动Flume Agent
bash
# 进入Flume安装目录
cd /opt/module/flume-1.9.0/
# 启动Agent
# -n a1: 指定Agent名称
# -c conf/: 指定配置文件目录
# -f job/flume-taildir-hdfs.conf: 指定配置文件路径
# -Dflume.root.logger=INFO,console: 设置日志级别和输出位置
bin/flume-ng agent -n a1 -c conf/ -f job/flume-taildir-hdfs.conf -Dflume.root.logger=INFO,console注意 :-Dflume之间不能有空格!
六、实验验证与结果
6.1 准备测试数据
在监控目录 /opt/module/flume-1.9.0/fruit_data/ 下创建测试文件:
bash
# 创建监控目录
mkdir -p /opt/module/flume-1.9.0/fruit_data/
# 创建测试数据文件
cat > /opt/module/flume-1.9.0/fruit_data/fruit_20231208.csv << EOF
1,苹果,北京,5.50,2023-12-08
2,香蕉,上海,3.20,2023-12-08
3,橙子,广州,4.80,2023-12-08
4,葡萄,深圳,12.50,2023-12-08
5,西瓜,杭州,2.30,2023-12-08
EOF
# 模拟数据追加(Flume会实时捕获新增内容)
echo "6,草莓,成都,15.00,2023-12-08" >> /opt/module/flume-1.9.0/fruit_data/fruit_20231208.csv6.2 查看HDFS中的数据
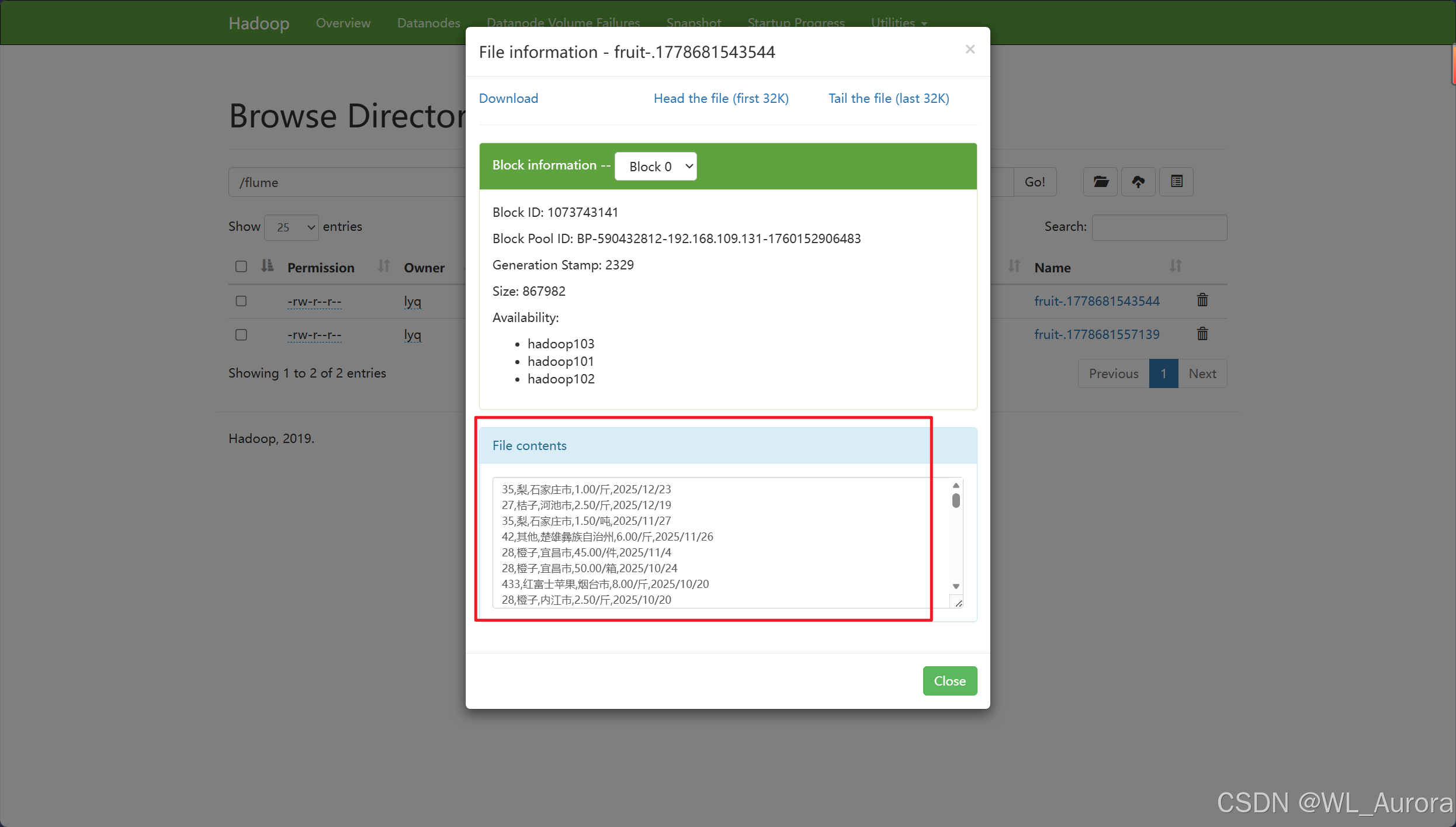
启动Flume后,数据会自动写入HDFS的 /flume 目录。通过HDFS Web UI或命令行查看:
bash
# 查看HDFS目录
hdfs dfs -ls /flume
# 查看文件内容
hdfs dfs -cat /flume/fruit-*.txt预期输出:
1,苹果,北京,5.50,2023-12-08
2,香蕉,上海,3.20,2023-12-08
3,橙子,广州,4.80,2023-12-08
4,葡萄,深圳,12.50,2023-12-08
5,西瓜,杭州,2.30,2023-12-08
6,草莓,成都,15.00,2023-12-086.3 验证positionFile
bash
# 查看positionFile内容
cat /opt/module/flume-1.9.0/fruit_position.json可以看到Flume已经记录了每个文件的读取位置,下次启动时将从该位置继续读取。
七、常见问题与解决方案
7.1 HDFS权限问题
问题现象 :Flume报错 Permission denied: user=flume, access=WRITE, inode="/flume"
解决方案:
bash
# 在HDFS中创建目录并赋予权限
hdfs dfs -mkdir -p /flume
hdfs dfs -chmod 777 /flume7.2 小文件过多问题
问题现象:HDFS中产生大量小文件,影响NameNode性能。
解决方案:
properties
# 增大rollSize和rollInterval
a1.sinks.k1.hdfs.rollSize = 134217728 # 128MB
a1.sinks.k1.hdfs.rollInterval = 3600 # 1小时
a1.sinks.k1.hdfs.rollCount = 0 # 不基于数量7.3 数据重复问题
问题现象:Agent重启后,部分数据重复上传。
原因:Taildir Source的positionFile可能未及时更新。
解决方案 :确保transactionCapacity设置合理,避免事务未提交就崩溃。
八、进阶:与MapReduce/Hive的数据清洗链路
在实际的大数据项目中,Flume采集只是第一步。完整的数据处理链路如下:
┌───────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 本地数据文件 │───▶│ Flume采集 │───▶│ HDFS存储 │───▶│ MapReduce │
│ (CSV/日志) │ │ (Taildir) │ │ (/flume) │ │ 数据清洗 │
└───────────────┘ └─────────────┘ └─────────────┘ └──────┬──────┘
│
▼
┌─────────────┐
│ Hive建表 │
│ 数据分析 │
└─────────────┘在我的实验中,完成Flume采集后,还进行了以下操作:
- 编写Java MapReduce程序进行数据清洗
- 使用Maven打包为JAR包并上传到Hadoop集群执行
- 在Hive中创建分层表(ODS层、DWD层、DWM层)
- 进行多维数据分析
九、总结
本文从Flume的基础架构出发,深入讲解了Taildir Source 的工作原理和配置方法,并提供了一个完整的生产级配置文件 。通过实际案例验证了Flume在实时监控目录文件变化、断点续传、数据写入HDFS等方面的强大能力。
核心要点回顾:
- ✅ Taildir Source支持正则匹配多个文件,通过positionFile实现断点续传
- ✅ Timestamp Interceptor为Event添加时间戳,便于HDFS按时间分区
- ✅ HDFS Sink的roll策略(时间/大小/数量)需要合理配置,避免小文件问题
- ✅ Flume是大数据采集链路的关键一环,与MapReduce、Hive无缝衔接