"The conclusions are clear: we are definitely not where we think we are in terms of WERs (Word Error Rates)."
编者按:本文摘编自由波兰Wrocław University of Science and Technology、美国Johns Hopkins University, Baltimore、波兰Poznan University of Technology等九名研究者发表在2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)的Findings论文--- "WER we are and WER we think we are"。EMNLP与ACL是国际上自然语言处理(NLP)领域最好的两个会议,均由ACL(Association for Computational Linguistics)主办。
WER是Word Error Rate的缩写,是评估语音识别(ASR)性能的主要指标。鉴于WER与单词where(在哪里)谐音,该文作者借此发出了灵魂之问:我们在哪里,我们认为我们在哪里?
该文作者站在NLP看ASR,指出应正确解读目前在常用基准数据集上报告的WER。该文观点犀利,充满思辨,并辅以实际实验结果进行论证,我们做中文摘编分享给读者。多些思辨和实事求是,将有助于跨领域学术同行、相关企业、政府及整个社会对当前语音识别乃至人工智能技术的客观认识,并有利于技术本身的健康长远发展。本摘编忠于原文,欢迎读者和专家指正。
原文链接:
https://aclanthology.org/2020.findings-emnlp.295/
摘要
对会话语音的自然语言处理(NLP)需要高质量的转录(transcript)。在本文中,我们对最近报道的现代自动语音识别(ASR)系统的很低单词错误率(WER)表示怀疑。我们概述了常用的几个基准数据集的若干问题,并在一个真实自然会话的内部数据集和HUB'05公开基准数据集上,比较了当前前沿水平(state-of-the-art)的三个商业ASR系统的性能。我们发现WER显著高于报道的结果。针对这些问题,我们提出包括创建真实、多领域、带高质量标注的数据集在内的若干行动方针,号召ASR和NLP两个领域的学术届和企业届进行跨学科合作,以推动ASR系统在下个十年的进步。
一、引言
自动语音识别(ASR)系统在过去几年取得了前所未有的进步,也可以看到一些厂商在努力展示其产品的质量和准确性。ASR系统在一些基准数据集上报告的WER低至 2%--3%。这些报告可能会给人一个错误的印象,即语音识别是一个大体上已解决的问题。但事实并非如此(Nothing could be further from the truth.)。
是什么导致了这样的误解和对准确性的严重高估?几个可能的原因包括:
-
在人机对话、人人对话两种不同形式下,人们的语音有很大不同。当人们意识到是与机器对话,比如与Alex(编著注:Alex是全球出货最多的亚马逊智能音箱)交互时,说的话比较短且结构比较标准。而人们之间的对话则灵活多变,且充满各种不连贯(停顿、修补、回窜)。
-
在Fisher、Switchboard这样的基准数据集中,参与录音的双方从预定主题中随机抽取主题进行对话,尽管这样努力去模仿真实的自然会话,其实本质还是伪造的(artificial),与现实生活中自然会话有很大不同。在真正具有挑战性的基准数据集上,如聚会谈话CHiME5测试,现代ASR报告的WER范围为46%--73%。
-
在多样性方面,基准数据集的录音人员往往同质化,但在现实生活的对话中,年龄、性别、种族、口音、非母语等带来的声学(发音)和语言(词汇和句法)的多样性也都没有在ASR评估中得到考虑。无论是在语音信号特征还是会话语义层面,基准数据集都不能代表真实世界会话的真正多样性(the true diversity)。
二、错误率的现状
图1绘制了过去几年全球不同研究小组在几个基准数据集上报告的 ASR 错误率。从这些基准数据集上的报告结果看,截至2019年,错误率都低于15%。
-
Librispeech数据包含近1000小时的英语有声读物录音(用于模型训练和测试),其WER低至2%--4%。
-
WSJ'92 and '93数据包含约73小时干净语音听写和记者会话,其WER在3%--7%。
-
TED-LIUM数据包括118小时高质量TED演讲,其WER报告为5%。
-
HUB'05电话会话数据集上,在SWBD测试集上报告的最好WER是5%,在CallHome是9%。
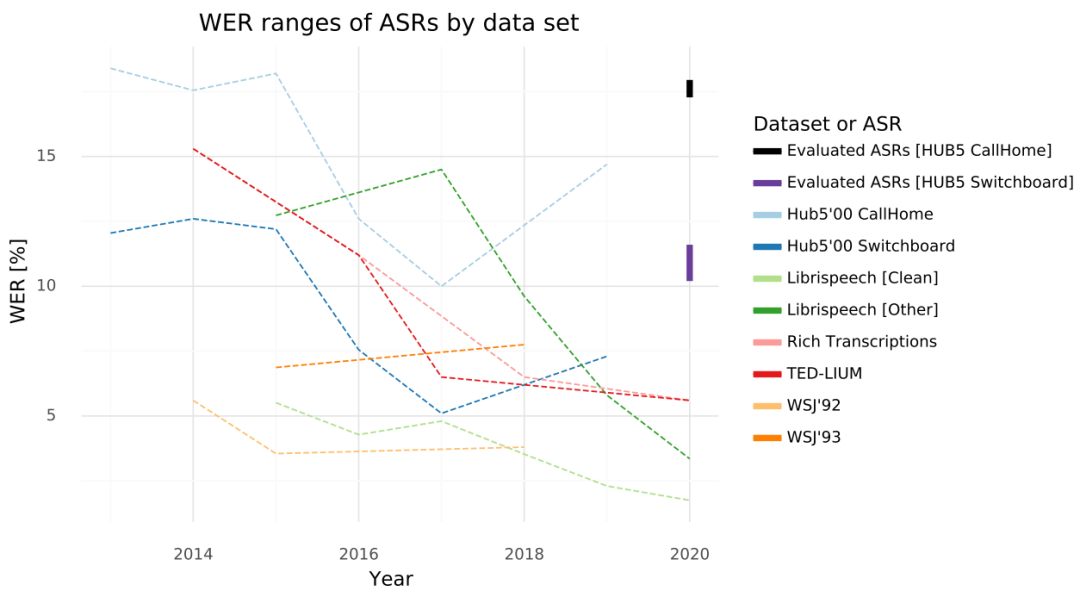
图 1:ASR系统的WER变化。数据为在WER are we 1和Papers with Code2统计的过去5 年间报告的ASR结果。为了可读性删除了野点。
1、https://github.com/syhw/wer_are_we
2、https://paperswithcode.com/task/speech-recognition
为了评估,我们采集了50通真实呼叫中心会话(Call Center Conversations, CCC),其中语音时长2.2小时,涵盖多个领域(旅游预订、金融、两类保险领域和电信领域对话)。对三种不同的当前前沿水平(state-of-the-art)的商用ASR解决方案进行测试。在CCC测试集、HUB'05 SWBD和CallHome测试集上,评估得到的WER如表1所示。
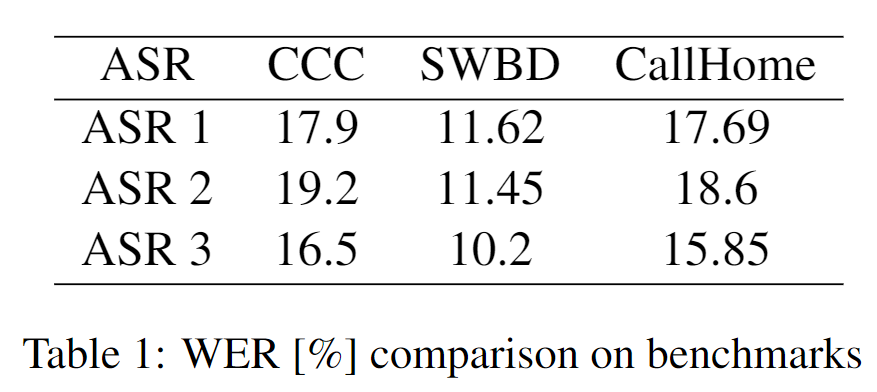
不幸的是,如表 1 所示,在评估中,商用 ASR 系统在 HUB'05 测试集上的错误率几乎是文献报告(见图 1 **)的两倍。**这可能有如下两个原因。首先,论文中报告的WER通常使用人为标注的语音分段,而在我们评估中,各系统需要自己做语音端点检测。其次,对于基准数据集,论文中报告的系统一般使用在相应训练集上估计的语言模型(LM),而商业ASR系统一般使用通用语言模型,这显著降低了各商用系统的识别性能。
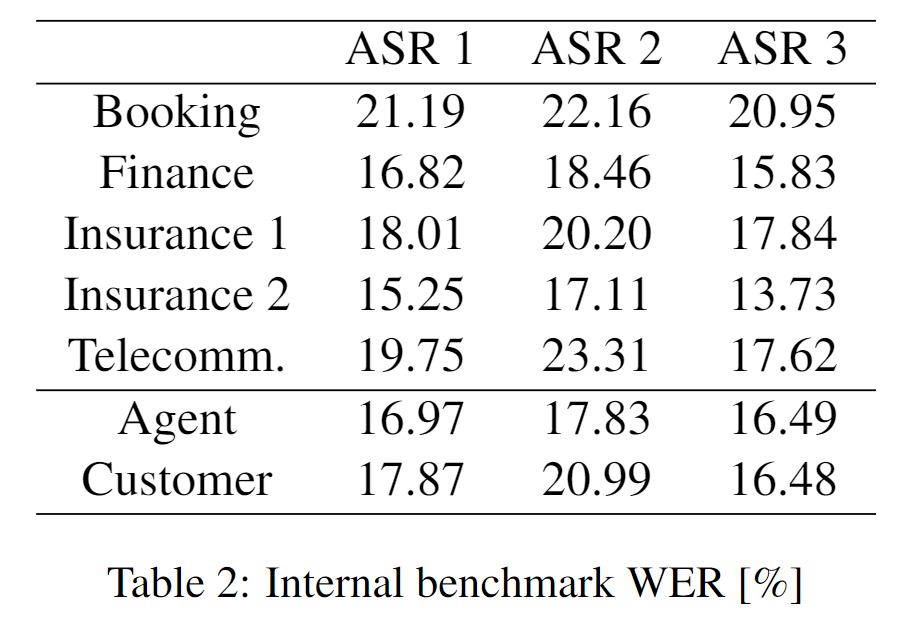
在CCC真实多领域测试集上的WER与在公共基准数据集上报告的WER,两者差距非常明显。表2给出了三个商用系统在CCC内部测试集上分领域的WER。可以看出,旅游预订和电信领域的错误率最高,这可能是由于这些语音中更多地包含日期和时间、金额、地点、产品或公司名称等有关的实体。
三、行动号召
我们认为,为了推动对人类会话语音的ASR,一个综合的行动计划应该包含下面几点:
-
准备新的富标注的音频和转录数据集,包括:词性标签、依存文法结构、实体、情感等;
-
开发能够采集会话语音的工具,众包采集真实自然会话,并象Librispeech一样公开发布;
-
组织类似于Mozilla Common Voice的众包募捐活动,以便用户可以捐赠他们的电话和转录;
-
进一步发展ASR声学与语言模型,并使NLP模型与方法能适配于会话应用;
-
为ASR+NLP联合任务,设计开放的公共基准测试方案,以便评估该领域的进展;
-
基于富标注的数据构建新的ASR性能度量,以更好地评估转语音识别转录质量的各个方面。
四、结论
结论非常明确:就 WER 而言,我们绝对没有达到我们认为的位置。
与NLP社区许多人的认识相反,现代ASR系统并不能满意地处理人类自然会话。在对多领域真实呼叫中心会话语音的识别上,我们看到了当前前沿水平的商用ASR系统的错误率远高于在传统基准数据集上的结果。我们相信,对ASR准确率过于乐观的认识将有损于会话NLP下游应用的发展。我们号召ASR和NLP两个领域的学术届和企业届进行跨学科合作,我们也讨论了若干行动计划,以推动ASR系统在下个十年的进步。