爬虫阶段三实战练习题一:爬取微博热搜榜(Ajax 版)
-
- [爬取微博热搜榜(Ajax 版)目标:](#爬取微博热搜榜(Ajax 版)目标:)
- 分析步骤:
- 如下查找请求头信息和请求接口:
- 调试后的代码:
- 采集的数据结果:
- 基础补充一:
-
- [1. `json.dump()`](#1.
json.dump()) - [2. 参数详解](#2. 参数详解)
- [3. 完整示例](#3. 完整示例)
- [4. 常见应用场景](#4. 常见应用场景)
- [5. 注意事项](#5. 注意事项)
- [1. `json.dump()`](#1.
- 基础补充二:
-
- [1. `hot_list:50` ------ 切片操作](#1.
hot_list[:50]—— 切片操作) - [2. `enumerate(..., start=1)` ------ 枚举器](#2.
enumerate(..., start=1)—— 枚举器) - [3. `for idx, item in ...` ------ 解包赋值](#3.
for idx, item in ...—— 解包赋值) - 整体作用
- [1. `hot_list:50` ------ 切片操作](#1.
- 基础补充三:
爬取微博热搜榜(Ajax 版)目标:
- 爬取微博热搜榜前 50 条热搜词和热度
- 数据格式:排名、热搜词、热度值
- 要求:通过分析 Ajax 接口直接获取 JSON
分析步骤:
- 打开微博热搜榜:
https://weibo.com/hot/search - 打开开发者工具,Network → XHR,刷新页面。
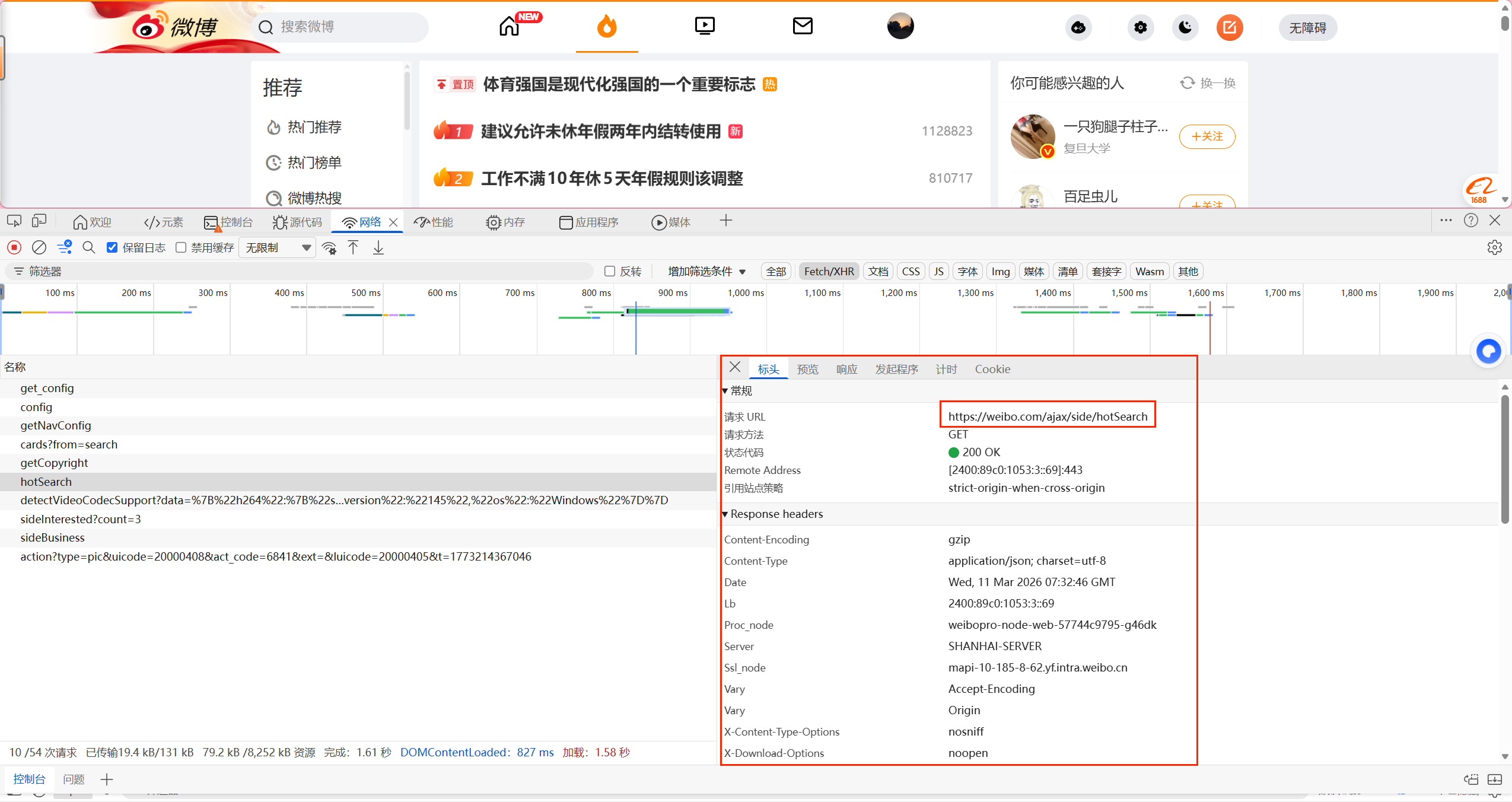
- 观察请求,找到一个类似的热搜接口。实际接口可能是
https://weibo.com/ajax/side/hotSearch(需确认)。 - 点击该请求,查看 Preview,确认返回的是热搜数据。
- 查看 Headers,复制完整的 URL、Request Headers(重点是 User-Agent、Referer、Cookie)。
- 注意:可能需要登录 Cookie,可以在浏览器登录后复制 Cookie。
如下查找请求头信息和请求接口:
调试后的代码:
python
import requests
import time
import json
'''
热搜页面url: https://weibo.com/hot/search
热搜请求接口: https://weibo.com/ajax/side/hotSearch
referer:https://weibo.com/hot/search
cookie:xxxxx
user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.0.0
'''
# 如果接口需要 Cookie,先复制到下面
cookies = {
'SUB': 'xxxxx', # 你的 Cookie
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.0.0',
'Referer': 'https://weibo.com/hot/search',
}
url = 'https://weibo.com/ajax/side/hotSearch' # 示例,可能已变
response = requests.get(url, headers=headers, cookies=cookies)
data = response.json()
'''
{
"realpos": 1,
"label_name": "",
"topic_flag": 1,
"word_scheme": "#工作不满10年休5天年假规则该调整#",
"num": 1037699,
"word": "工作不满10年休5天年假规则该调整",
"note": "工作不满10年休5天年假规则该调整",
"flag": 0,
"emoticon": "",
"rank": 0
}
'''
# 提取热搜列表
hot_list = data['data']['realtime'] # 根据实际结构调整
result = []
#
for idx, item in enumerate(hot_list[:50], start=1):
word = item.get('word', '')
hot = item.get('raw_hot', '') or item.get('num', '')
result.append({
'rank': idx,
'word': word,
'hot': hot
})
# 保存到 JSON
with open('weibo_hot.json', 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print('爬取完成,共', len(result), '条')采集的数据结果:

基础补充一:
python
json.dump(result, f, ensure_ascii=False, indent=2)这行代码的作用是将 Python 数据(通常是字典或列表)以 JSON 格式写入到文件中,并且保证写入的内容是人类可读的(包含中文且格式美观)。下面我们拆解每个部分:
1. json.dump()
json.dump() 是 Python 标准库 json 模块提供的方法,专门用于将 Python 对象序列化为 JSON 字符串,并直接写入文件。
与之对应的是 json.dumps()(多了一个 s ,代表 string),它只返回 JSON 字符串,不写入文件。
2. 参数详解
| 参数 | 含义 | 说明 |
|---|---|---|
result |
要写入的数据 | 通常是一个字典(dict)或列表(list),包含爬虫抓取的数据。 |
f |
已打开的文件对象 | 需要用 open() 以写入模式打开的文件,例如 f = open('data.json', 'w', encoding='utf-8')。 |
ensure_ascii=False |
允许非 ASCII 字符(如中文)原样输出 | 默认 True 时,会将中文等转为 \uXXXX 形式的 Unicode 转义序列;设为 False 后,中文会正常显示。 |
indent=2 |
美化输出,用 2 个空格缩进 | 默认输出是一整行紧凑的 JSON;加缩进后,层级结构一目了然,便于阅读。 |
3. 完整示例
假设我们爬取了一些热搜数据,存在列表 result 中:
python
import json
result = [
{"rank": 1, "title": "今日头条新闻"},
{"rank": 2, "title": "热门话题讨论"}
]
# 打开文件(必须指定 encoding='utf-8' 避免中文乱码)
with open('hot.json', 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2)运行后,hot.json 文件的内容将是:
json
[
{
"rank": 1,
"title": "今日头条新闻"
},
{
"rank": 2,
"title": "热门话题讨论"
}
]- 如果没有
ensure_ascii=False,中文会变成类似"\u4eca\u65e5\u5934\u6761\u65b0\u95fb"的转义符,难以阅读。 - 如果没有
indent=2,文件会变成一行很长的文本,不利于查看。
4. 常见应用场景
在爬虫开发中,我们经常需要把抓取到的数据保存到本地,便于后续分析或备份。json.dump 是最常用的保存方式之一,因为它:
- 格式通用,几乎所有编程语言都能解析。
- 与 Python 的数据结构(字典/列表)天然兼容,读取时用
json.load就能恢复。
5. 注意事项
- 文件打开方式一定要用
'w'写入模式,并指定encoding='utf-8',否则可能因编码问题导致报错。 - 如果
result包含不可序列化的类型(如自定义对象、日期时间),需要先转换为可序列化的类型,或提供自定义的序列化器。
基础补充二:
python
for idx, item in enumerate(hot_list[:50], start=1):这行代码是 Python 中一种非常常见的写法,用于同时获取元素及其序号(索引)。下面我们拆解开来看:
1. hot_list[:50] ------ 切片操作
hot_list是一个列表(比如热搜榜的条目)。[:50]表示取列表的前 50 个元素(索引 0 到 49)。
这样循环就只处理前 50 条数据,而不是整个列表。
2. enumerate(..., start=1) ------ 枚举器
enumerate是 Python 的内置函数,它可以把一个可迭代对象(如列表)组合成一个索引序列。- 默认情况下,索引从 0 开始,但这里加了
start=1,告诉枚举器从 1 开始计数。
例如:
python
hot_list = ['A', 'B', 'C']
for idx, item in enumerate(hot_list, start=1):
print(idx, item)输出:
1 A
2 B
3 C3. for idx, item in ... ------ 解包赋值
- 每次循环,
enumerate返回一个包含(索引, 元素)的元组。 for idx, item in ...把这个元组直接解包给变量idx和item。
整体作用
这行代码的意思是:
从热搜列表 hot_list 中取出前 50 条,然后从 1 开始编号,依次将编号(idx)和条目内容(item)取出来,供循环体内使用。
通常用在需要显示"排名"的场景,比如打印热搜榜:
python
for idx, item in enumerate(hot_list[:50], start=1):
print(f"第{idx}名:{item}")这样既简洁又清晰。
基础补充三:
不同网站的 Cookie 的键(名称)通常是不一样的 。每个网站的后端开发人员可以自由定义自己网站的 Cookie 名称,没有强制标准。
但是,通过观察大量网站,我们可以发现一些常见的命名规律。下面帮你梳理一下,这样以后看到类似的 Cookie 就能大概猜到它的作用了。
为什么键会不一样?
Cookie 的本质是网站存储在用户本地的一段键值对数据。之所以键名不同,主要有两个原因:
- 域名隔离 :浏览器的同源策略 决定了,
a.com设置的 Cookie 浏览器不会发给b.com。因此,不同网站的 Cookie 天然就是隔离的,键名即使冲突(比如都叫userid)也不会互相干扰。 - 开发者自定义 :每个公司的开发团队会根据自己后端框架的习惯或安全需求来命名。比如:
- 有的喜欢用简单的
sid(Session ID)。 - 有的为了安全,用一串无规则的字母,如
_uuid。 - 有的为了标识产品线,加上产品名前缀,如
taobao_***。
- 有的喜欢用简单的
常见网站的 Cookie 键示例
为了让你有更直观的感受,这里列举几个典型网站的登录凭证 Cookie:
| 网站/平台 | 常见的登录凭证 Cookie 键名 | 说明 |
|---|---|---|
| 新浪微博 | SUB |
用户登录的身份令牌,非常经典。 |
| 知乎 | z_c0 |
知乎的主要登录凭证。 |
| 哔哩哔哩 | SESSDATA |
B站的核心登录态 Cookie。 |
| 百度 | BDUSS |
百度用户的唯一身份标识。 |
| 淘宝/天猫 | thw / cna / sg |
阿里系通常由多个 Cookie 组合验证。 |
| 抖音网页版 | sessionid |
很多网站喜欢用最直白的 sessionid。 |
| GitHub | user_session |
同样很直白。 |
SID / SSID / HSID |
Google 通常是一组配合使用的安全 Cookie。 |
如何在代码中处理?
既然每个网站的键不一样,我们在写爬虫时,就需要针对目标网站"量身定做"。
方法一:手动复制(最常用)
-
在浏览器中登录目标网站。
-
打开开发者工具(F12),找到"网络"(Network)标签。
-
刷新页面,点击任何一个请求(比如
www.xxx.com)。 -
在右侧的"请求头"(Request Headers)中找到
Cookie字段。 -
把整个字符串复制下来,或者只复制那个关键的键值对。
-
在代码中构造字典:
python# 如果是微博 cookies = {'SUB': '你的实际SUB值'} # 如果是知乎 cookies = {'z_c0': '你的实际z_c0值'} # 如果多个,都写上 cookies = { 'SESSION': 'abc123', 'USER_ID': '12345', 'TOKEN': 'xxxxxx' }
方法二:自动获取(进阶)
如果是用 Selenium,可以在登录成功后用 driver.get_cookies() 获取浏览器当前的所有 Cookie,然后传给 requests 的 Session。
python
# Selenium 登录后
selenium_cookies = driver.get_cookies()
# 转换为 requests 能用的格式
requests_cookies = {}
for cookie in selenium_cookies:
requests_cookies[cookie['name']] = cookie['value']
# 然后就可以用 requests 带着这些 Cookie 去访问了
session = requests.Session()
session.cookies.update(requests_cookies)
response = session.get('目标URL')总结
- 键名确实不同,由各网站开发者定义。
- 但有规律可循 ,多抓几个网站就会发现,
SESSION、sid、token、uid等是比较通用的命名。 - 处理方式固定 :对于
requests,就是构造{'键': '值'}的字典;对于selenium,就是先登录再导出。