Efficient Neural Architecture Search for End-to-end Speech Recognition via Straight-Through Gradients
郑华焕、安柯宇、欧智坚
深度神经网络学习任务中,模型性能高度依赖于神经网络结构。在传统训练中,网络结构根据人的主观思考结合大量的实验与经验进行设计,并诞生了ResNet、LSTM等经典并被广泛使用的网络结构,但人工设计网络结构往往需要大量的实验尝试与丰富的经验积累。神经结构搜索(Neural Architecture Search,NAS)旨在通过机器学习,自动化(或半自动化)地设计出适应目标任务的网络结构,并在性能上达到或超过人工设计的网络结构,以提高设计网络结构的效率。
我们结合近几年基于梯度的优秀NAS工作,包括DARTS、ProxylessNAS和SNAS等,从前向与反向传播的角度对NAS方法进行了重新思考,设计了基于直通(Straight-Through)梯度的NAS高效方法,在端到端ASR识别WSJ和SwitchBoard任务进行了评估,相较于人工设计的基线模型均取得了显著的提升。
参考此前的相关工作,我们将结构搜索的搜索空间定义为一个有向无环图(Directed Acyclic Graph,DAG),每条边表示一个可能的操作算子(OP),图中的节点表示中间特征(feature map),在此设计上,结构搜索等价于寻找最优性能的子图。
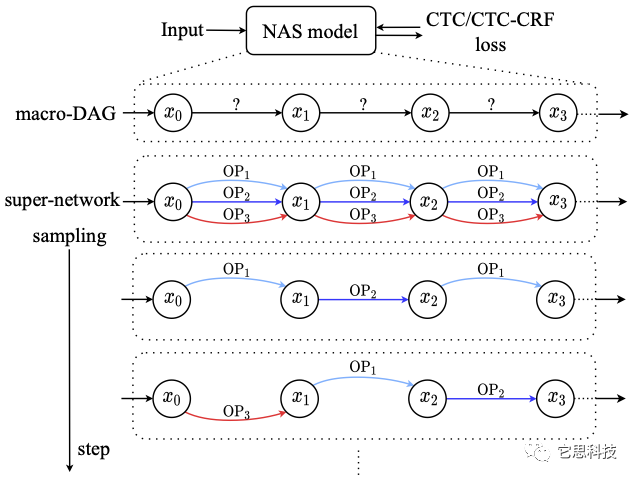
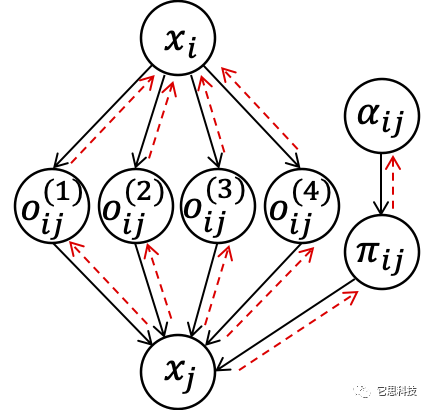
DARTS采用给每条边赋予权重,通过Softmax进行归一化,对各边进行加权求和。DARTS通过这种连续松弛(Continuous relaxation)使结构权重参与到前向计算中,并可通过反向梯度传播更新权重参数。DARTS存在两个显著的问题:
-
在计算时,所有的边都参与了每次更新,计算图包含了完整的DAG,因此其计算开销与GPU显存开销均远大于普通的模型训练;
-
尽管搜索阶段各边通过连续加权求和进行计算,但为了得到最终的模型,DARTS需要执行一步离散化操作,即选择其中权重最大的若干条边,裁剪掉不需要的边,导致了搜索与模型评估时的分歧(Searching and evaluation gap)。
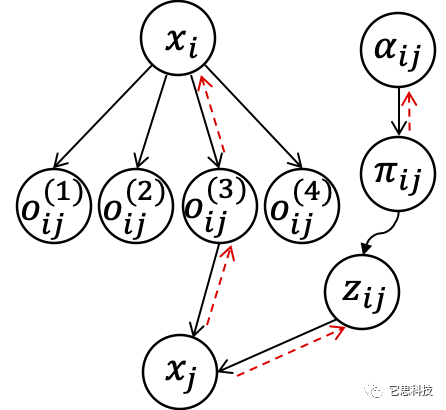
为了克服这两个缺陷,我们在前向计算时对DAG进行采样,相连节点之间每次仅根据权重采样1条边,在采样得到的子图上执行前向计算。通过采样,搜索阶段和最终模型评估阶段我们的模型参数训练都只包括了一个子图。
通过子图采样,我们消除了分歧!
反向传播时,由于采样操作的不可导性质,我们无法直接更新优化结构权重参数。因此我们引入了Straight-Through梯度的思想,前向计算保持原有的采样设计不变,但在反向传播时,我们将前向计算"认为"是和DARTS相同的连续加权求和,就可以计算出对于权重参数的梯度。在此设计上,权重参数的梯度形式上与DARTS一致,网络参数的梯度形式上和一般固定结构的模型训练一致。我们将这种基于Straight-Through梯度的NAS方法称为ST-NAS。
ST-NAS在计算开销与GPU显存开销上均显著低于DARTS为代表的连续结构搜索方法,即使相比于一般的固定结构模型训练,额外的计算开销也仅仅小幅增加,在可接受的范围内。我们在ASR任务上对ST-NAS进行了评估,结果表明,相比与基线人工设计模型,搜索得到的模型均有明显的提升。尤其在WSJ任务上,我们的模型不仅取得了目前端到端模型的SOTA性能,还在网络参数规模上小于现有的大多数模型。
可以预见,NAS将是推进端到端语音识别非常有吸引力的重要方向!
Github地址:https://github.com/thu-spmi/ST-NAS
