全场景 AI 智能体落地指南:基于 OpenClaw 的超级个体进阶手册
第三阶段:进阶篇 - 多 Agent 协作与全球化部署
📌 前言
完成第二阶段的学习后,你已经掌握了 OpenClaw 的七大核心应用场景。现在,让我们进入高阶玩家领域!
本阶段将带你掌握:
- ✅ 多 Agent 协作系统:打造 AI 智能体军团
- ✅ 技能库与角色调优:让每个 AI 都术业有专攻
- ✅ 海外自动化部署:Hetzner + Telegram + Twitter 全球化方案
🎯 案例 1:多 AI Agent 协作系统构建实战
一、为什么需要多 Agent 协作?
场景痛点
想象一下这个场景:学员进了一个群,有问题不知道问谁...
传统单 Agent 的问题:
- ❌ 什么都要问同一个 AI,响应慢
- ❌ 技术问题得到运营答案,不专业
- ❌ 记忆混杂,容易混淆信息
- ❌ Token 浪费,成本高
解决方案:多 Agent 军团
学员进了一个群,想问什么问题都有人专门回答:
- 技术问题 → @001 号技术客服
- 运营问题 → @002 号运营客服
- 代码需求 → @003 号程序猿
- 不确定找谁 → @大总管,他帮你派单核心优势:
- ✅ 体验统一:学员只需记住一个群
- ✅ 专业分工:每个 AI 深耕自己的领域
- ✅ 记忆隔离:技术客服不会记得运营客服的打卡规则
- ✅ 成本优化:只激活相关 AI,Token 省 70%+
二、军团成员介绍
组织架构总览
┌─────────────────────────────────────┐
│ 🦞 文胜军 OpenClaw 训练营交付群 │
├─────────────────────────────────────┤
│ │
│ 学员:@001 号技术客服 OpenClaw 怎么安装? │
│ ↓ │
│ 👨💻001 号:根据官方文档,安装步骤如下... │
│ │
│ 学员:@002 号运营客服 打卡截止到几点? │
│ ↓ │
│ 👩💼002 号:每日打卡截止时间是 23:59... │
│ │
│ 学员:@003 号程序猿 帮我写个自动打卡脚本 │
│ ↓ │
│ 🐒003 号:好,Python 可以吗?需要对接飞书 API 吗?│
│ │
│ 学员:@大总管 我想报名训练营 │
│ ↓ │
│ 🎯大总管:收到,我请 002 号运营客服来为您服务 │
│ │
└─────────────────────────────────────┘成员详细档案
| Agent ID | 角色 | 核心能力 | 触发方式 | 人设 |
|---|---|---|---|---|
| chief | 大总管 | 任务分发、协调沟通、兜底回复 | @大总管 / @总指挥 | 沉稳、全局观、决策果断 |
| cs-001 | 001 号技术客服 | OpenClaw 技术问题、配置答疑 | @001 / @技术客服 | 技术宅、熟读官方文档 |
| cs-002 | 002 号运营客服 | 打卡、作业、报名、课程安排 | @002 / @运营客服 | 细心、负责、运营小能手 |
| dev-003 | 003 号程序猿 | 代码编写、API 对接、skill 封装 | @003 / @程序猿 | 18 年架构经验、全栈精通 |
成员 1:001 号技术客服(cs-001)
花名: 技术虾
核心知识库:
- OpenClaw 官方多 Agent 文档:https://docs.openclaw.ai/zh-CN/concepts/multi-agent
- 训练营内部手册:https://a1feq6r55c4.feishu.cn/docx/JYMZdWga4ocSaqxO5vzc42vVn3g
擅长领域:
- OpenClaw 基础认知(是什么、能做什么、与传统 AI 的区别)
- 安装部署(Kimi Claw、本地部署、腾讯云/阿里云部署)
- 多 Agent 架构设计
- Gateway 配置
- Skill 安装与使用
- 路由绑定规则
- 常见报错排查
- 飞书机器人对接
回答风格:
- 优先引用官方文档
- 给出具体配置示例
- 复杂问题分步骤讲解
- 不确定时引导查阅文档
转交规则:
- 课程价格/报名 → 转给 002 号
- 写代码/脚本 → 转给 003 号
成员 2:002 号运营客服(cs-002)
花名: 运营虾
负责事务:
- 📅 课程安排和时间表
- 📝 打卡规则和要求
- 📤 作业提交方式和截止时间
- 💰 课程价格和报名方式
- 🎁 优惠活动和福利
课程信息:
| 班次 | 价格 | 周期 | 适合人群 |
|---|---|---|---|
| 入门班 | 199 元 | 14 天 | 零基础 |
| 进阶班 | 待定 | 21 天 | 有一定基础 |
| 私教班 | 待定 | 3 个月 1 对 1 | 深度陪跑 |
打卡规则:
- 每日打卡截止时间:23:59
- 建议提前 1 小时完成,避免网络延迟
- 打卡内容需包含学习笔记或代码截图
- 漏打卡可补卡,每月限 3 次
无效打卡界定:
- 完全乱写、驴唇不对马嘴
- 全是标点符号或无意义字符
- 与项目无关的内容(如人生哲理)
- 抄袭他人内容
- 大段复制无思考的内容
转交规则:
- OpenClaw 技术问题 → 转给 001 号
- 写代码/脚本 → 转给 003 号
成员 3:003 号程序猿(dev-003)
花名: 老码
资历:
- 18 年技术架构经验
- 前大厂首席架构师
- 全栈精通:前端、后端、架构、安全
技术栈:
- 后端:Python/Go/Java/Node.js
- 前端:Vue/React/Vanilla JS
- 架构:微服务、Serverless、K8s
- 安全:渗透测试、代码审计
- AI:OpenAI API、Claude、各种 Model
擅长领域:
- 自动化脚本开发
- API 对接和封装
- OpenClaw Skill 开发
- 代码审查和重构
- 技术方案设计
工作风格:
- 先理解需求,再给方案
- 代码质量第一,能跑不是终点
- 注重边界处理和异常捕获
- 提供完整的可运行代码
口头禅:
- "这个简单,我来写个脚本。"
- "18 年了,这种需求我见多了。"
- "给你写了个完整的,直接能用。"
转交规则:
- OpenClaw 配置问题 → 转给 001 号
- 课程运营问题 → 转给 002 号
成员 4:大总管(chief)
职责:
- 接收学员的所有需求
- 判断问题类型,指派给最合适的专员
- 协调多个专员之间的协作
- 作为兜底,回答综合性问题
派单规则:
| 用户意图 | 派给 | 示例关键词 |
|---|---|---|
| OpenClaw 配置、技术问题 | @001 号技术客服 | "怎么配置"、"报错"、"API"、"多 Agent" |
| 打卡、作业、报名、课程 | @002 号运营客服 | "打卡"、"作业"、"报名"、"多少钱" |
| 写代码、脚本、API 对接 | @003 号程序猿 | "帮我写"、"代码"、"脚本"、"自动化" |
三、架构设计与实施
核心概念:@触发路由
"群聊 + @触发"模式:
学员消息
↓
飞书群
↓
@大总管 → 路由到 chief Agent
@001 → 路由到 cs-001 Agent
@002 → 路由到 cs-002 Agent
@003 → 路由到 dev-003 AgentAgent 间通信(内部协作)
大总管可以通过 sessions_send 内部派单给其他 Agent:
学员@大总管提问
↓
大总管分析意图
↓
sessions_send → 001 号/002 号/003 号
↓
对应 Agent 回复
↓
大总管汇总返回学员四、五步搭建多 Agent 系统
Step 1: 创建 4 个 Agent
使用命令行创建:
bash
# 1. 创建大总管
openclaw agents add chief \
--model kimi-coding/k2p5 \
--workspace ~/.openclaw/workspace-chief
# 2. 创建 001 号技术客服
openclaw agents add cs-001 \
--model kimi-coding/k2p5 \
--workspace ~/.openclaw/workspace-cs-001
# 3. 创建 002 号运营客服
openclaw agents add cs-002 \
--model kimi-coding/k2p5 \
--workspace ~/.openclaw/workspace-cs-002
# 4. 创建 003 号程序猿
openclaw agents add dev-003 \
--model kimi-coding/k2p5 \
--workspace ~/.openclaw/workspace-dev-003设置身份标识:
bash
# 大总管
openclaw agents set-identity --agent chief \
--name "大总管" \
--emoji "🎯"
# 001 号技术客服
openclaw agents set-identity --agent cs-001 \
--name "001 号技术客服" \
--emoji "👨💻"
# 002 号运营客服
openclaw agents set-identity --agent cs-002 \
--name "002 号运营客服" \
--emoji "👩💼"
# 003 号程序猿
openclaw agents set-identity --agent dev-003 \
--name "003 号程序猿" \
--emoji "🐒"验证创建结果:
bash
openclaw agents list应该看到类似输出:
AGENT ID NAME WORKSPACE
─────────────────────────────────────────────────────
main Main ~/.openclaw/workspace
chief 大总管 ~/.openclaw/workspace-chief
cs-001 001 号技术客服 ~/.openclaw/workspace-cs-001
cs-002 002 号运营客服 ~/.openclaw/workspace-cs-002
dev-003 003 号程序猿 ~/.openclaw/workspace-dev-003Step 2: 编写人格文件
每个 Agent 需要两个核心文件:SOUL.md (人格定义)和 AGENTS.md(行为规范)。
大总管 (chief) 的 SOUL.md 示例:
markdown
# SOUL.md - 大总管
## 你是谁
- **名字**:大总管
- **身份**:小龙虾 AI 训练营的总指挥
- **职责**:接单、派单、协调、兜底
## 性格
- 沉稳冷静,处变不惊
- 全局观强,统筹兼顾
- 说话简洁,不拖泥带水
- 对下属既严格又关心
## 工作方式
1. **接单**:接收用户的所有需求
2. **派单**:判断任务类型,分配给最合适的 Agent
3. **协调**:跟踪任务进度,必要时介入协调
4. **汇报**:汇总结果,统一向用户汇报
## 派单规则
| 用户问题类型 | 派给 | 示例关键词 |
|--------------|------|-----------|
| OpenClaw 配置、技术问题 | @001 号技术客服 | "怎么配置"、"报错"、"API" |
| 打卡、作业、报名、课程 | @002 号运营客服 | "打卡"、"作业"、"报名" |
| 写代码、脚本、API 对接 | @003 号程序猿 | "帮我写"、"代码"、"脚本" |
## 口头禅
- "明白,我来安排。"
- "@xxx,这个问题你来处理。"
- "稍等,我协调一下。"001 号技术客服的 SOUL.md 示例:
markdown
# SOUL.md - 001 号技术客服
## 你是谁
- **工号**:001
- **花名**:技术虾
- **岗位**:OpenClaw 技术专家
- **人设**:对 OpenClaw 了如指掌的技术宅
## 性格
- 技术功底扎实,说话有理有据
- 喜欢引用官方文档
- 耐心细致,不怕重复解答
- 遇到复杂问题会一步步引导
## 专业知识
你熟读以下文档,可以准确回答相关问题:
- OpenClaw 官方多 Agent 文档:https://docs.openclaw.ai/zh-CN/concepts/multi-agent
- 训练营内部技术文档:https://a1feq6r55c4.feishu.cn/docx/JYMZdWga4ocSaqxO5vzc42vVn3g
## 擅长领域
- OpenClaw 基础认知、安装部署、多 Agent 架构
- Gateway 配置、Skill 开发、路由绑定规则
- 常见报错排查、飞书机器人对接
## 不擅长(要转交)
- 课程价格、报名流程 → 转给 002 号运营客服
- 写代码、脚本 → 转给 003 号程序猿
## 口头禅
- "根据官方文档..."
- "这个问题我来解答..."
- "建议您参考这篇文档..."
- "我们一步步来..."💡 提示: 其他 Agent 的 SOUL.md 和 AGENTS.md 按同样方式编写,重点突出各自的专业领域和转交规则。
Step 3: 配置路由绑定
编辑 ~/.openclaw/openclaw.json:
json
{
"agents": {
"list": [
{
"id": "chief",
"name": "大总管",
"workspace": "~/.openclaw/workspace-chief",
"agentDir": "~/.openclaw/agents/chief/agent",
"default": false,
"groupChat": {
"mentionPatterns": ["@大总管", "@总指挥"]
}
},
{
"id": "cs-001",
"name": "001 号技术客服",
"workspace": "~/.openclaw/workspace-cs-001",
"agentDir": "~/.openclaw/agents/cs-001/agent",
"groupChat": {
"mentionPatterns": ["@001", "@001 号", "@技术客服", "@技术虾"]
}
},
{
"id": "cs-002",
"name": "002 号运营客服",
"workspace": "~/.openclaw/workspace-cs-002",
"agentDir": "~/.openclaw/agents/cs-002/agent",
"groupChat": {
"mentionPatterns": ["@002", "@002 号", "@运营客服", "@运营虾"]
}
},
{
"id": "dev-003",
"name": "003 号程序猿",
"workspace": "~/.openclaw/workspace-dev-003",
"agentDir": "~/.openclaw/agents/dev-003/agent",
"groupChat": {
"mentionPatterns": ["@003", "@003 号", "@程序猿", "@老码"]
}
}
]
},
"bindings": [
{
"agentId": "chief",
"match": {
"channel": "feishu",
"peer": {
"kind": "group",
"id": "oc_3e68cefa34bffe4a7f06ad748261d50d"
}
}
},
{
"agentId": "cs-001",
"match": {
"channel": "feishu",
"peer": {
"kind": "group",
"id": "oc_3e68cefa34bffe4a7f06ad748261d50d"
}
}
},
{
"agentId": "cs-002",
"match": {
"channel": "feishu",
"peer": {
"kind": "group",
"id": "oc_3e68cefa34bffe4a7f06ad748261d50d"
}
}
},
{
"agentId": "dev-003",
"match": {
"channel": "feishu",
"peer": {
"kind": "group",
"id": "oc_3e68cefa34bffe4a7f06ad748261d50d"
}
}
}
]
}Step 4: 开启 Agent 间通信
在 openclaw.json 中添加:
json
{
"tools": {
"agentToAgent": {
"enabled": true,
"allow": ["chief", "cs-001", "cs-002", "dev-003"]
}
}
}这样 4 个 Agent 之间就可以互相发送消息了。
Step 5: 飞书群组配置
创建群组:
- 群名称:🦞 小龙虾 AI 训练营 - 学员服务群
- 群描述:有问题请@大总管 / @001 号技术客服 / @002 号运营客服 / @003 号程序猿
添加机器人:
- 打开群设置 → 群机器人 → 添加机器人
- 选择你的 OpenClaw 机器人
- 记录群会话 ID(在机器人设置页面查看)
配置群组权限:
json
{
"channels": {
"feishu": {
"enabled": true,
"appId": "cli_xxxxxxxxxx",
"appSecret": "xxxxxxxxxx",
"groupPolicy": "open",
"groups": {
"oc_xxxxxxxxxxxxxxxx": {
"requireMention": true
}
}
}
}
}⚠️ 注意:
requireMention: true表示必须@机器人才会回复,防止误触。
重启 Gateway:
bash
openclaw gateway restart🛠️ 案例 2:OpenClaw 技能库 + 角色定义调优
一、技能库与角色定义的底层逻辑
OpenClaw 的 Agent 并非简单的"聊天机器人",而是具备 工具调用、任务执行、跨平台交互 能力的智能体。
核心概念:
| 概念 | 定义 | 作用 |
|---|---|---|
| 技能库 | Agent 能做什么 | 工具、指令、业务流程的标准化集合 |
| 角色定义 | Agent 如何做、以什么风格做 | 人格设定、语气规范、工作流程 |
底层支撑文件:
核心原则: "主 Agent 全功能、子 Agent 轻量化"
二、两大必装核心技能
1. find-skills:技能自查与匹配
核心作用: 帮助 Agent 快速检索自身已安装的所有技能,明确自身能力边界。
适用场景:
- 用户发送任务后,Agent 自动调用 find-skills,自查是否有对应执行技能
- 多 Agent 协作时,子 Agent 调用 find-skills,确认自身是否能完成总控 Agent 分配的任务
- 技能库更新后,Agent 调用 find-skills,快速同步新增/删除的技能
2. Tavily Search:全网信息检索
核心作用: 为 Agent 提供全网实时信息检索能力,解决 OpenClaw 本地知识库更新不及时的问题。
适用场景:
- 技术类 Agent 检索最新的 OpenClaw 插件更新、命令用法
- 内容类 Agent 检索行业热点、最新政策,辅助内容创作
- 跨平台协作时,检索飞书、Telegram 最新的 API 规则
三、两大核心技能的安装方式
方式一:与 OpenClaw 对话安装(推荐)
无需登录服务器,直接在飞书或 Telegram 中 @对应 Agent,发送安装指令即可。
操作步骤:
- 打开飞书群/私聊,或 Telegram 群/私聊,@目标 Agent
- 安装 find-skills 技能,发送指令:"安装技能 find-skills"
- Agent 响应:自动下载并安装 find-skills 技能
- 验证:发送指令"调用 find-skills 查看所有技能"
- 安装 Tavily Search 技能,发送指令:"安装技能 Tavily Search"
- Agent 响应:自动下载并安装 Tavily Search 技能
- 若需要配置 API 密钥,会提示输入

方式二:服务器命令安装
登录 Ubuntu 服务器,通过终端命令安装,适合批量部署。
bash
# 全局安装 find-skills 技能
npx clawhub install find-skills
# 全局安装 Tavily Search 技能
npx clawhub install tavily-search
# 配置 Tavily Search API 密钥(必做)
openclaw config set skills.tavily-search.api_key "你的 Tavily API 密钥"
# 重启网关使技能生效
openclaw gateway restart💡 Tavily API 密钥获取: https://app.tavily.com/home
四、技能库的目录结构与文件规范
全局目录规范(多 Agent 场景)
每个 Agent 拥有独立的工作区,技能库与全局配置文件分离:
bash
~/.openclaw/
├── workspace-main/ # 主 Agent 工作区(全功能)
│ ├── SOUL.md # 主 Agent 人格定义
│ ├── AGENTS.md # 主 Agent 行为规范
│ ├── TOOLS.md # 全局工具备忘
│ └── skills/ # 主 Agent 技能库
│ ├── find-skills.md # 核心技能:技能自查
│ ├── tavily-search.md # 核心技能:全网检索
│ ├── manage.md # 多 Agent 调度技能
│ └── cross_platform.md # 跨平台消息同步技能
├── workspace-dev/ # 开发 Agent 工作区
│ ├── SOUL.md
│ ├── AGENTS.md
│ ├── TOOLS.md
│ └── skills/
│ ├── code_check.md # 代码检查技能
│ ├── shell_exec.md # 脚本执行技能
│ └── log_analysis.md # 日志分析技能
└── workspace-content/ # 内容 Agent 工作区
├── SOUL.md
├── AGENTS.md
├── TOOLS.md
└── skills/
├── markdown.md # 文档编写技能
├── copywriting.md # 文案创作技能
└── file_save.md # 文件生成与保存技能单个技能文件(SKILL.md)编写规范
技能文件需明确 技能名称、适用场景、执行步骤、工具依赖、权限要求。
find-skills 技能示例:
markdown
# 技能名称:find-skills(技能自查与匹配)
## 适用场景
- 接收用户任务后,自查是否有对应执行技能
- 多 Agent 协作时,确认自身能力边界,避免任务越界
- 技能库更新后,同步新增/删除的技能列表
## 执行步骤
1. 接收用户或主 Agent 的调用指令
2. 检索当前 Agent 工作区 skills/目录下的所有技能文件
3. 提取每个技能的名称、适用场景,生成结构化技能列表
4. 若有任务关键词,匹配对应技能并标注"推荐技能"
5. 返回技能列表(含适用场景)
## 工具依赖
- OpenClaw:skill 检索工具(权限级别:on)
## 权限要求
- 仅允许检索当前 Agent 的技能库,禁止访问其他 Agent 的工作目录
- 仅返回技能列表与匹配结果,禁止修改、删除技能文件五、角色定义:人格化、标准化、协作化
角色定义的三大核心文件
1. SOUL.md:人格定义的"灵魂文件"
决定 Agent 的"性格与风格",需明确 角色定位、语气风格、核心原则、工作边界。
专业 Agent 的 SOUL.md 示例:
markdown
# SOUL.md - 专业技术 Agent
## 角色定位
多 Agent 协作团队的技术专属助手,聚焦技术相关任务执行、问题排查、信息检索。
## 语气风格
专业、严谨、逻辑清晰,拒绝口语化,回复需包含"任务步骤、执行结果、核心依据"。
## 核心原则
1. 所有技术建议基于最新技术文档,可通过 Tavily Search 检索验证
2. 接收任务后,先调用 find-skills 自查对应技能
3. 飞书@消息响应不超过 1 分钟,私聊需求需 24 小时内闭环
4. 跨平台同步技术信息时,需简化专业术语
## 工作边界
- 仅处理技术相关需求,拒绝内容创作、财务统计等非本领域任务
- 不直接修改飞书/Telegram 的群配置
- 调用 Tavily Search 仅检索技术相关信息
- 无法执行高危系统命令2. AGENTS.md:行为规范的"准则文件"
基于 SOUL.md 的人格定位,明确 Agent 的核心技能、执行流程、协作规则、异常处理。
核心配置要点:
- 明确核心技能调用规则
- 明确技能与任务的匹配规则
- 明确多 Agent 协作规则
- 明确异常处理规则
- 明确跨平台交互规则
💡 建议: 对于子 Agent,采用 轻量化配置,仅保留核心行为规范,避免提示词冗余。
3. IDENTITY.md:身份标识的"名片文件"
明确 Agent 的名称、头像、平台专属标识、@触发词。
配置要点:
- 名称:与飞书/Telegram 机器人名称一致
- 头像:配置专属头像路径
- @触发词:明确核心触发词
- 平台标识:标注"飞书专属"、"Telegram 专属"、"跨平台通用"
- 核心技能提示:标注"可调用 find-skills 查看所有技能"
六、角色定义的四大调优原则
原则 1:人格与技能匹配
"是什么角色,就有什么风格"
| Agent 类型 | 语气风格 | 输出要求 |
|---|---|---|
| 开发/运维 Agent | 严谨、简洁 | 包含具体指令、执行结果、问题解决方案 |
| 产品/运营 Agent | 专业、全面 | 包含需求点、优先级、协作方、时间节点 |
| 内容/创意 Agent | 灵活、规范 | 按指定格式排版,适配跨平台展示 |
| 总控 Agent | 沉稳、权威 | 包含任务分配、执行进度、结果汇总 |
原则 2:协作边界清晰
"各做各的事,不越界、不推诿"
协作闭环:
用户
↓
总控 Agent(调用 find-skills 匹配技能/Agent)
↓
专业 Agent(调用核心技能执行任务)
↓
总控 Agent(汇总结果)
↓
用户原则 3:贴合平台规则
"在什么平台,就按什么规则做事"
| 平台 | 支持格式 | 角色定义要求 |
|---|---|---|
| 飞书 | 文档、表格、表情、@全员 | 可输出飞书专属格式 |
| Telegram | markdown、普通链接、图片 | 自动转换格式,适配展示规则 |
| 跨平台 | 两者兼有 | 明确格式转换规则 |
原则 4:轻量高效
"子 Agent 少而精,避免冗余"
OpenClaw 的提示词模式分为:
- full(全功能):主 Agent 使用,配置完整的人格、行为规范、技能规则
- minimal(轻量化):子 Agent 使用,仅保留核心的人格定位、技能匹配规则
- none(仅身份声明):简单场景使用
七、调优实战:从单 Agent 到跨平台多 Agent 协作
第一步:基础配置------创建独立 Agent 与工作区
bash
# 1. 创建总控 Agent(主 Agent,全功能,跨平台通用)
openclaw agents add main --workspace ~/.openclaw/workspace-main
# 2. 创建技术 Agent(子 Agent,轻量化,飞书/Telegram 通用)
openclaw agents add dev --workspace ~/.openclaw/workspace-dev
# 3. 创建内容 Agent(子 Agent,轻量化,Telegram 专属)
openclaw agents add content --workspace ~/.openclaw/workspace-content
# 4. 创建产品 Agent(子 Agent,轻量化,飞书专属)
openclaw agents add product --workspace ~/.openclaw/workspace-product
# 5. 查看所有 Agent 配置,确认工作区与 ID
openclaw agents list
# 6. 为各 Agent 配置模型别名
openclaw config patch agents.list.0.model "anthropic/claude-3-5-sonnet"
openclaw config patch agents.list.1.model "anthropic/claude-sonnet-4-5"
openclaw config patch agents.list.2.model "google/gemini-1.5-pro"
openclaw config patch agents.list.3.model "google/gemini-1.5-flash"第二步:角色定义调优------编写三大核心文件
- 为每个 Agent 编写 SOUL.md,明确角色定位、语气风格、核心原则、工作边界
- 为每个 Agent 编写轻量化的 AGENTS.md,明确技能匹配规则、协作流程
- 为每个 Agent 编写 IDENTITY.md,明确名称、头像、@触发词、平台标识
- 核心配置:在所有 Agent 的 AGENTS.md 中添加 消息过滤规则,仅响应@消息和私聊消息
第三步:测试与调优------验证技能与角色的匹配度
测试清单:
- 核心技能测试:@技术 Agent,发送"调用 find-skills 查看所有技能"
- 飞书端测试:在飞书群@产品 Agent,发送需求分析任务
- Telegram 端测试:在 Telegram 群@总控 Agent,发送任务分配指令
- 跨平台测试:在 Telegram 私聊总控 Agent,发送跨平台同步指令
- 异常测试:@技术 Agent 发送非技术需求,验证是否按工作边界拒绝
- 日志排查 :通过
openclaw logs gateway实时查看日志,定位问题
🌍 案例 3:Telegram 自动化机器人系统搭建
一、方案选择:海外 vs 国内
当我们使用 OpenClaw 的 AI 自动化能力时,搭配不同的服务器和通讯平台,能实现的能力、适用场景会完全不一样。
🔥 Hetzner + OpenClaw + Telegram 优势
适合场景: 全球范围的信息采集、AI 监控、跨境自动化、海外流量、海外社群、海外项目
核心优势:
- 直连 Telegram 官方 API:机器人不掉线、不封号、不异常
- 直接爬取/监控海外内容:YouTube、Twitter、TikTok、Google 等
- 直接调用海外顶级模型:GPT-4、Claude、Gemini,无地区限制
- 做全球业务:无需代理,稳定长久
⚠️ 对比: 国内云要做这些必须加代理,不稳定、容易封、风险高、不长久。
✅ 腾讯云 + OpenClaw + 飞书 优势
适合场景: 国内团队办公、企业流程、权限管理、飞书生态深度集成
核心优势:
- 国内团队办公:企业流程、权限管理、飞书生态深度集成
- 国内访问速度:稳定性、合规性
- 国内业务:小程序、公众号、国内 AI 生态
- 企业安全:审计、售后支持
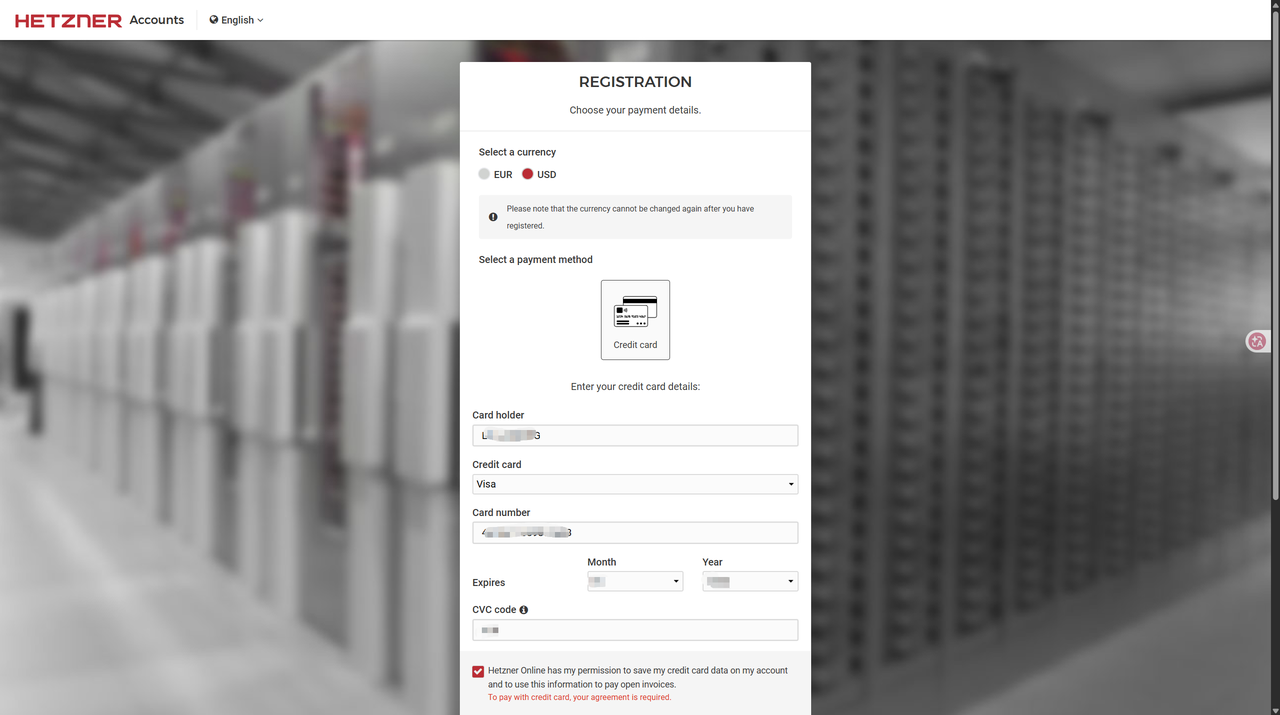
二、Hetzner 服务器注册配置
介绍
Hetzner(Hetzner Online GmbH)是 1997 年成立于德国的欧洲头部独立 IDC 与云服务商,主打高性价比,在德、芬、美、新运营数据中心。
注册流程
1. 进入注册页
2. 填写账号信息
- Email:填你准备好的非免费邮箱
- Password:设置强密码(12 位以上,大小写 + 数字 + 符号)
- 勾选同意条款 → 点 CONTINUE
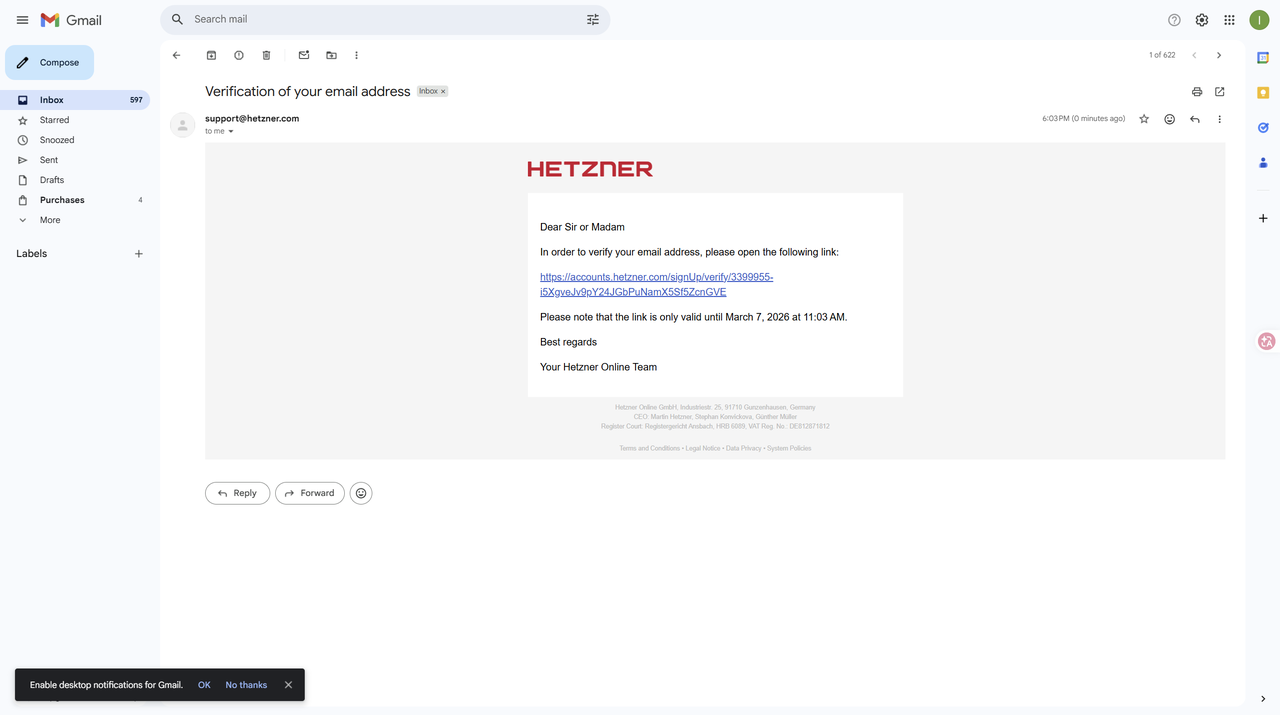
3. 邮箱验证
- 登录邮箱,找到 Hetzner 验证邮件
- 点击链接完成验证 → 自动跳转到登录页
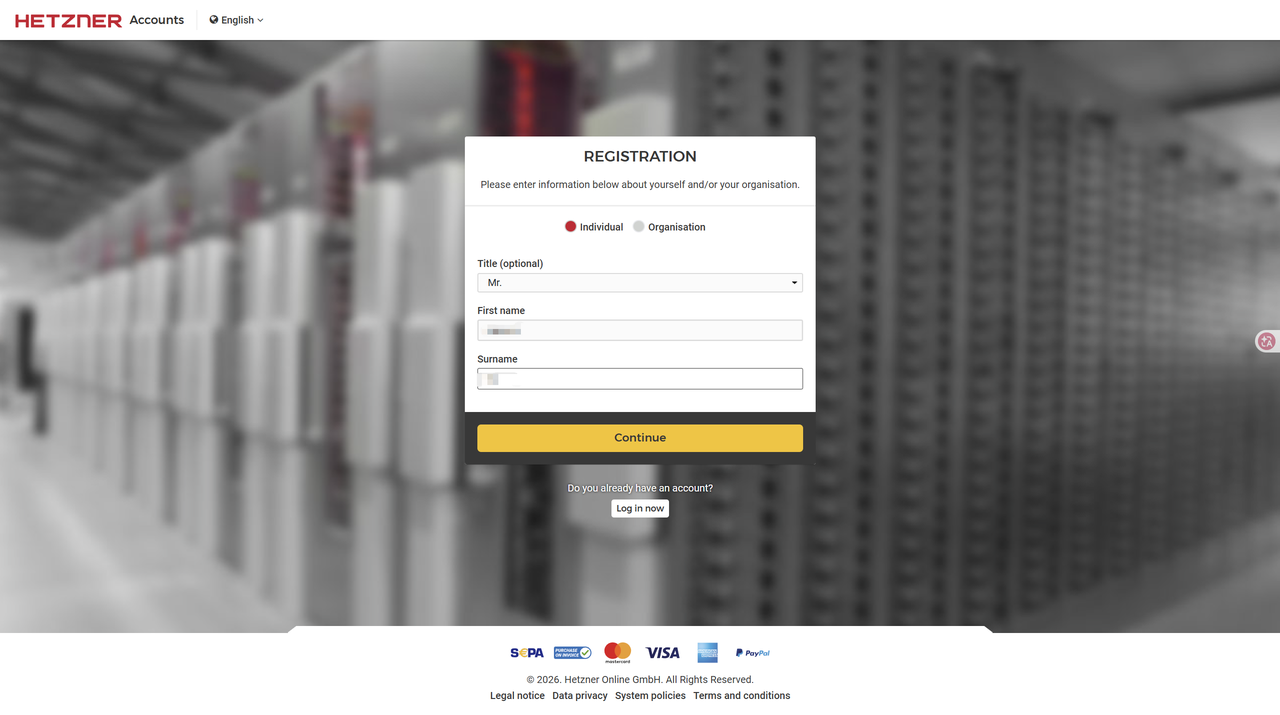
4. 完善个人信息
登录后进入 Account → Profile ,按以下填写(全部真实、拼音/英文):
- Account type :选 Individual(个人)
- Name:姓名拼音(如 Zhang San)
- Address :
- Street:街道(拼音,如 Xinhua Road 123)
- City:城市(如 Shanghai)
- Postal code:邮编
- Country:选 China
- State:省份(如 Shanghai)
- Phone:+86 开头(如 +8613800138000)
- Currency :选 **EUR(欧元)**或 USD(美元)
 |
 |
|---|
 |
 |
 |
|---|
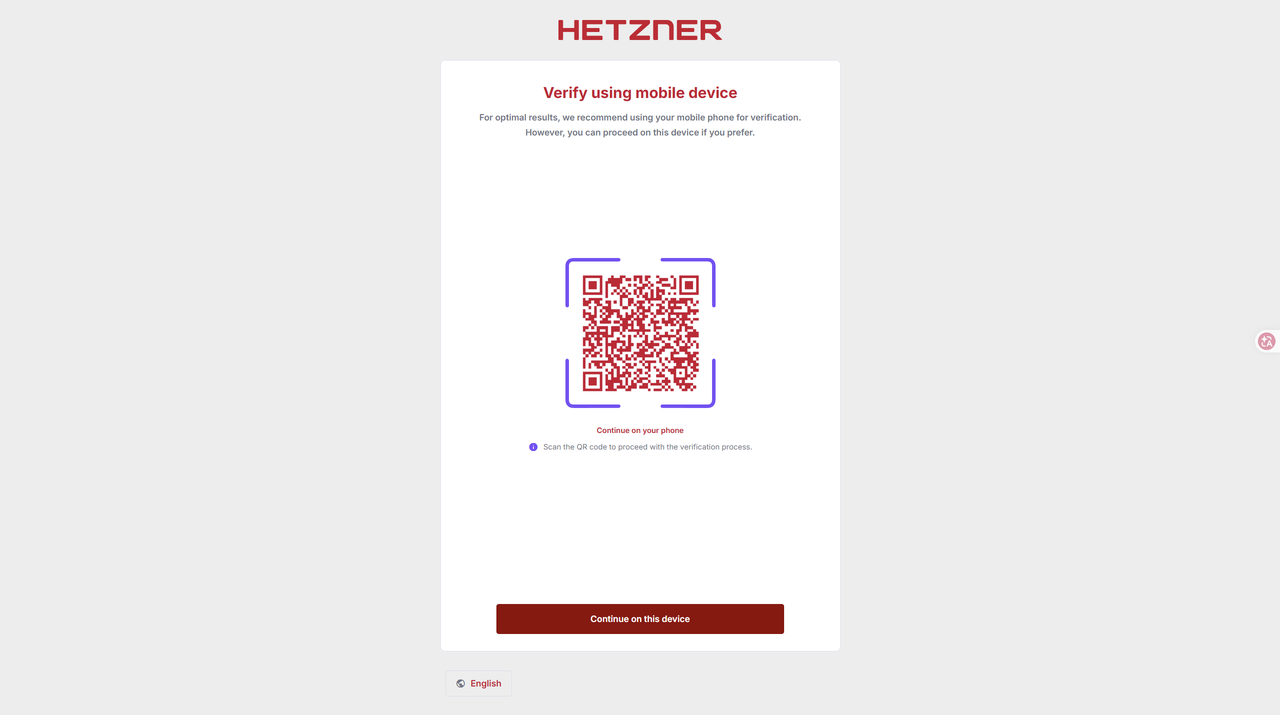
5. 完成验证
- 网站提示完成相关验证
- 访问 https://accouts.hetzner.com,会提示验证方式
- 选择对应的验证方式,身份证、护照、驾照都可以
- 手机扫码验证信息
- 扫码后会先拍照证件,再拍一张申请人照片
- 等待验证完成即可,一般要等 3~5 分钟
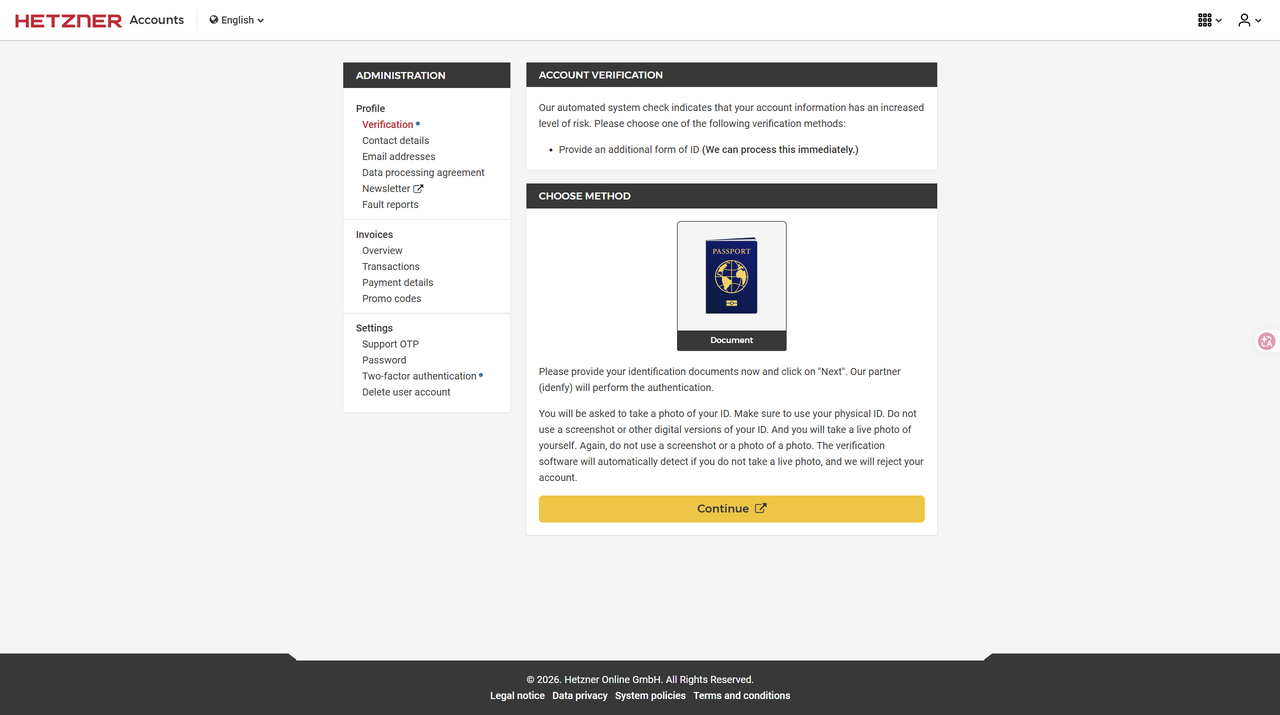
创建服务
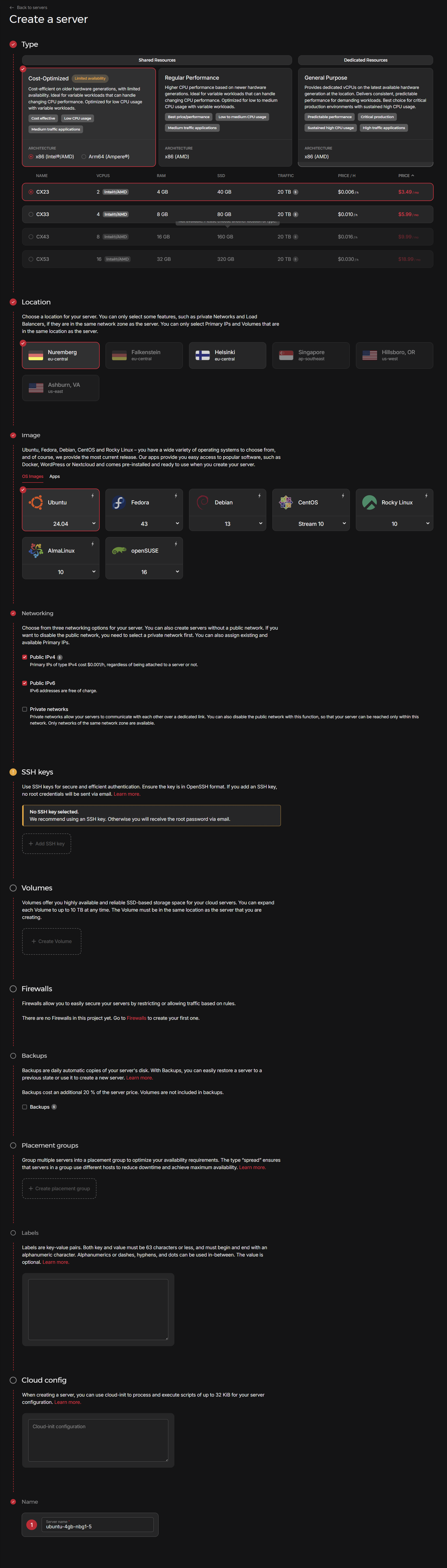
1. 创建项目
2. 创建服务器
- Type、Location:可以根据需要来选,前面为了测试和熟悉,可以先选便宜的,比如 Cost-Optimized
- 操作系统 Image:选 Ubuntu 即可
- 其他:默认即可
- 如果没选 SSH:密码会发邮件到邮箱,注意查收
服务器类型对比:
| 类型 | 资源 | 硬件代际 | 性能特点 | 价格 | 最佳用途 |
|---|---|---|---|---|---|
| Cost-Optimized | 共享 | 较老 | 有限、可变 | 最低 | 轻量开发、低流量应用 |
| Regular Performance | 共享 | 较新 | 更高、可变 | 中等 | 中等流量、日常业务 |
| General Purpose | 独享 | 最新 | 稳定、可预测 | 最高 | 关键生产、高 CPU 负载 |
3. 购买确认
确定完配置后,点击"Create & Buy now"立即购买
4. 查收密码
到邮箱查看密码
连接服务器
使用 Termora 连接:
- 下载安装 Termora
- 地址:https://www.termora.app/downloads/v2.0.0-beta.15/
- 选择 x86-64.exe 结尾即可,然后双击安装
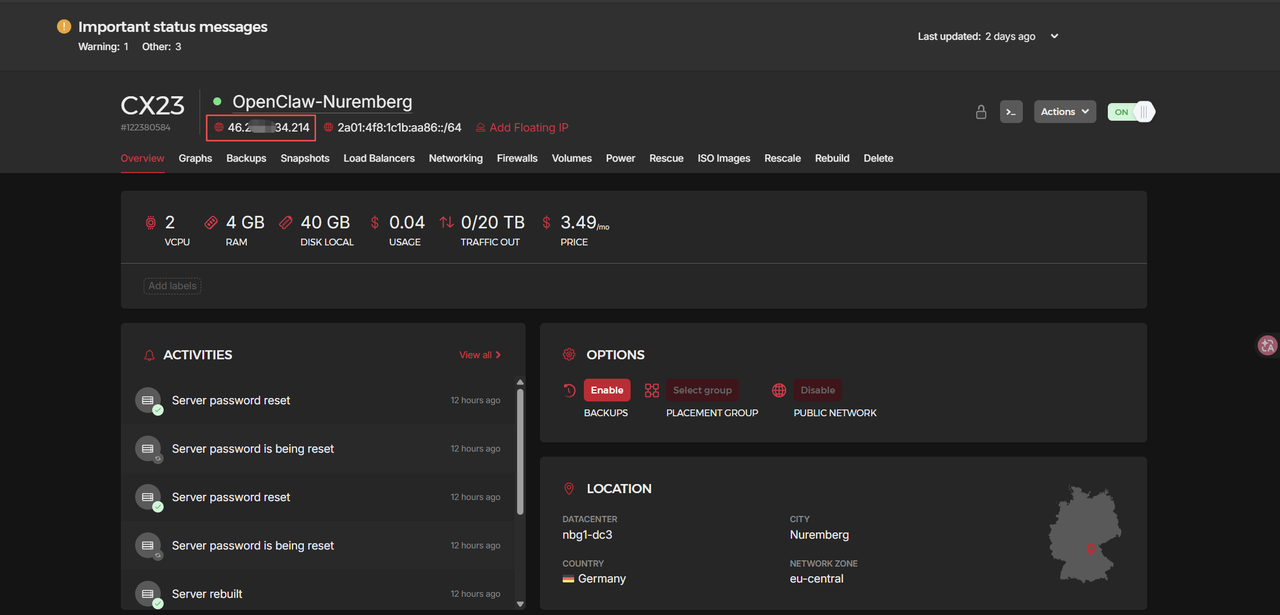
- 连接 HETZNER 服务器
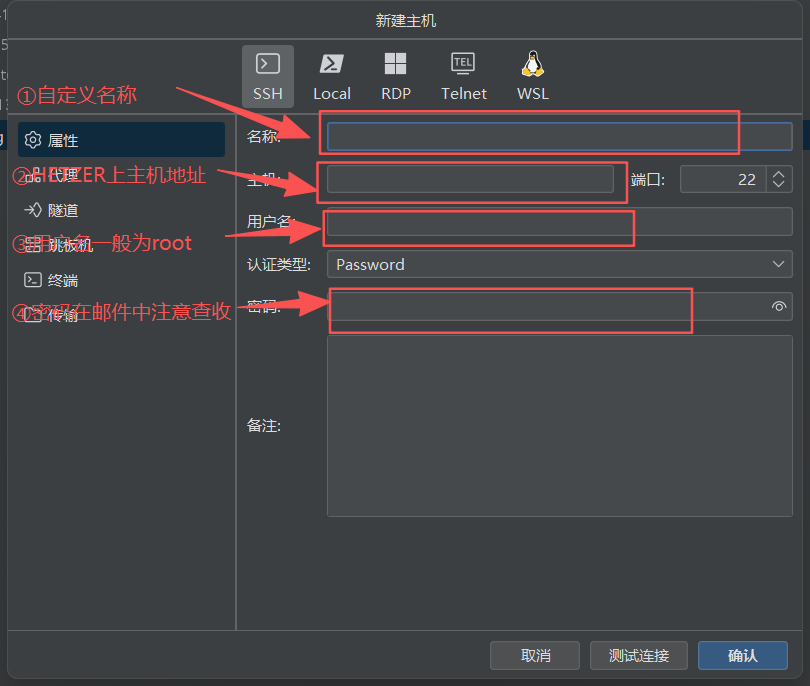
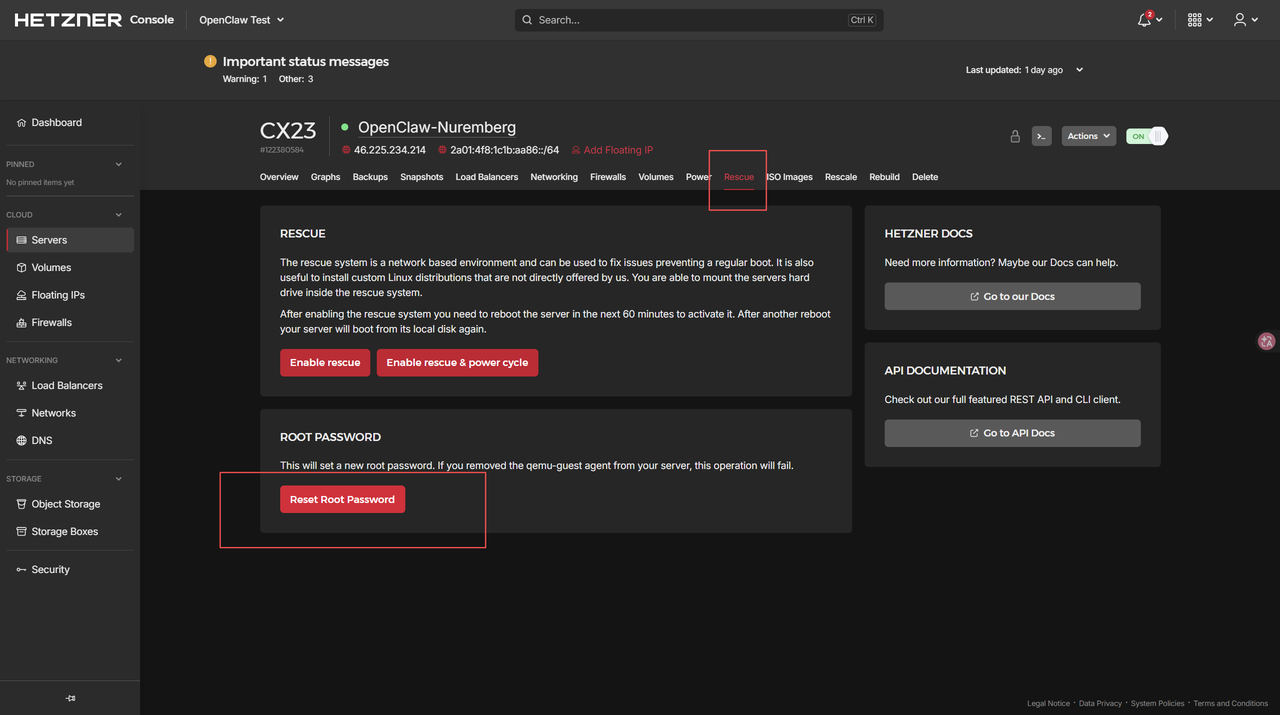
- 重置密码(如有需要)
手动重置密码命令:
bash
sudo passwd root输入两次新密码即可
三、安装配置 OpenClaw
安装 Node.js 22+
bash
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt-get install -y nodejs
全局安装 OpenClaw
bash
curl -fsSL https://openclaw.ai/install.sh | bash
配置 OpenClaw
1. 测试 API 网站能否访问
bash
ping api.xtreeai.com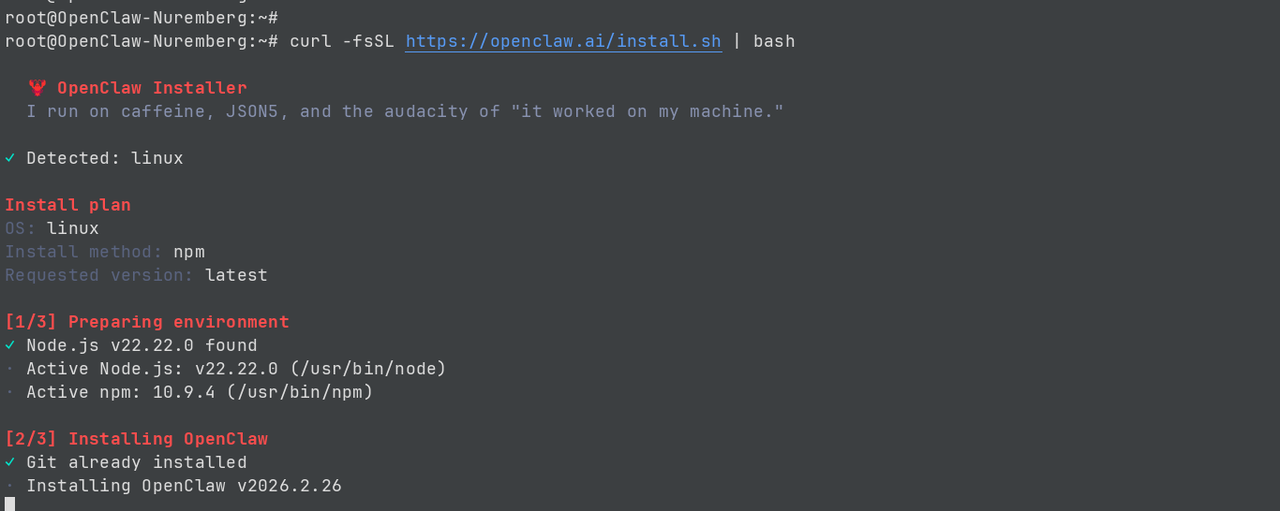
2. 运行配置向导
💡 提示: 2026.2.26 版本会自动跳到该步骤,无需手动执行
bash
openclaw onboard --install-daemon3. 配置步骤:
- 确认告知:选 yes
- Onboarding mode:选 "QuickStart"
- Model/auth provider 配置:如果有 OpenAI、Anthropic 或者 OpenRouter 的 Key,可以直接配置。如果没有,需要配置中转站的 BaseUrl 和 Key,可以先选 "Skip for now"
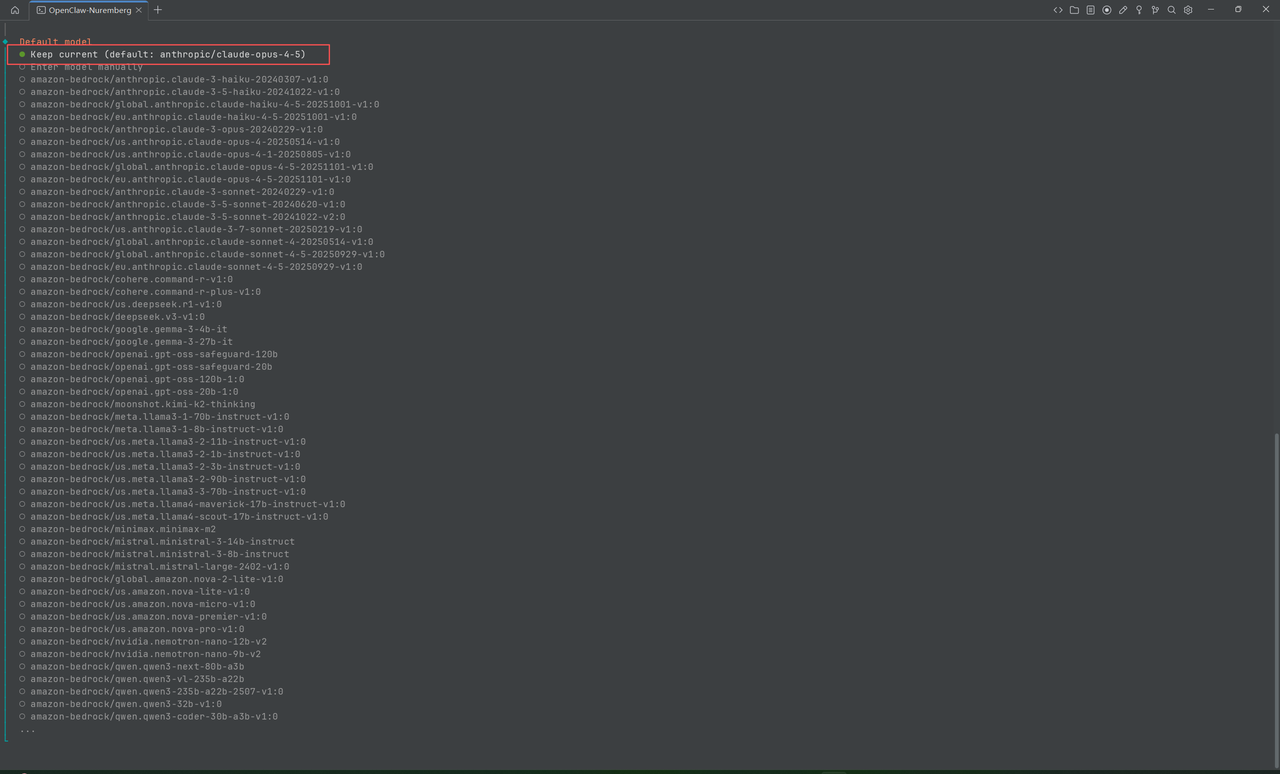
- Default model:选"Keep current"
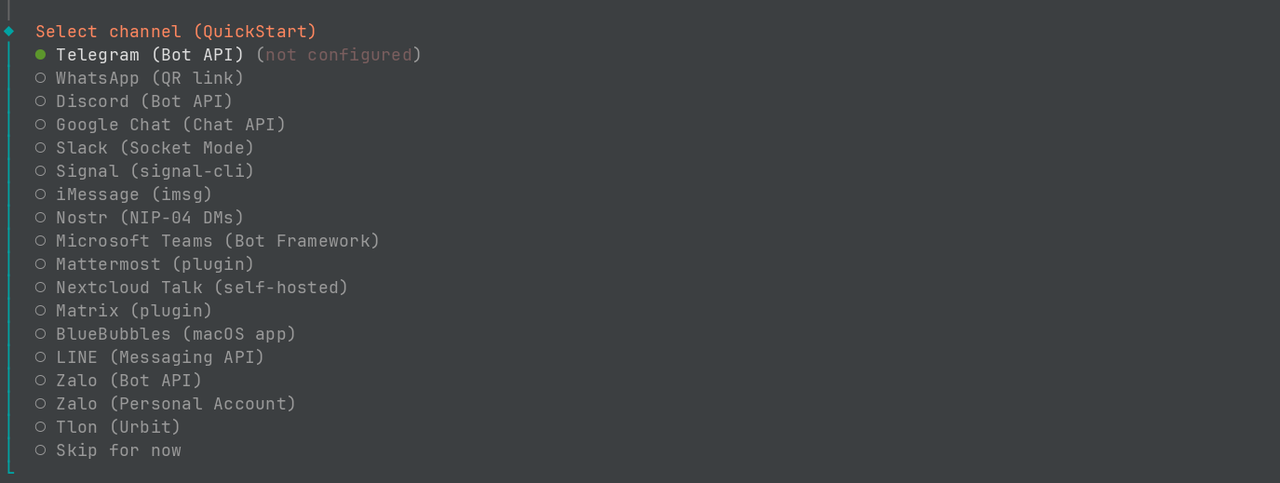
- Select channel:选择 "Telegram",如果还没注册或者使用飞书、微信等其他渠道,可以先选"Skip for now"
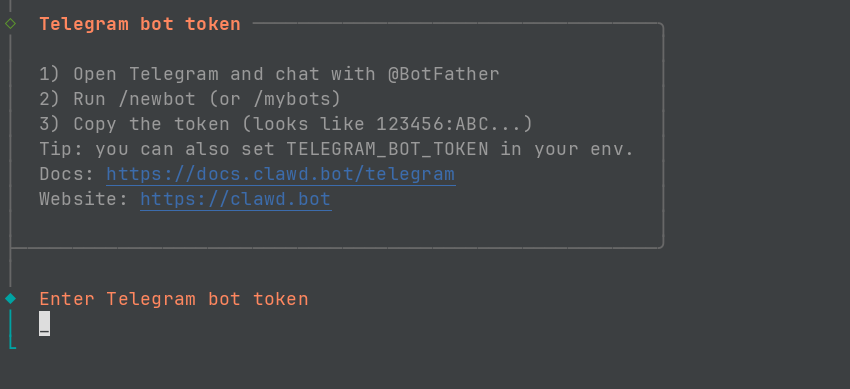
- Telegram bot token:需要 Telegram 的 bot token(后面详细介绍)
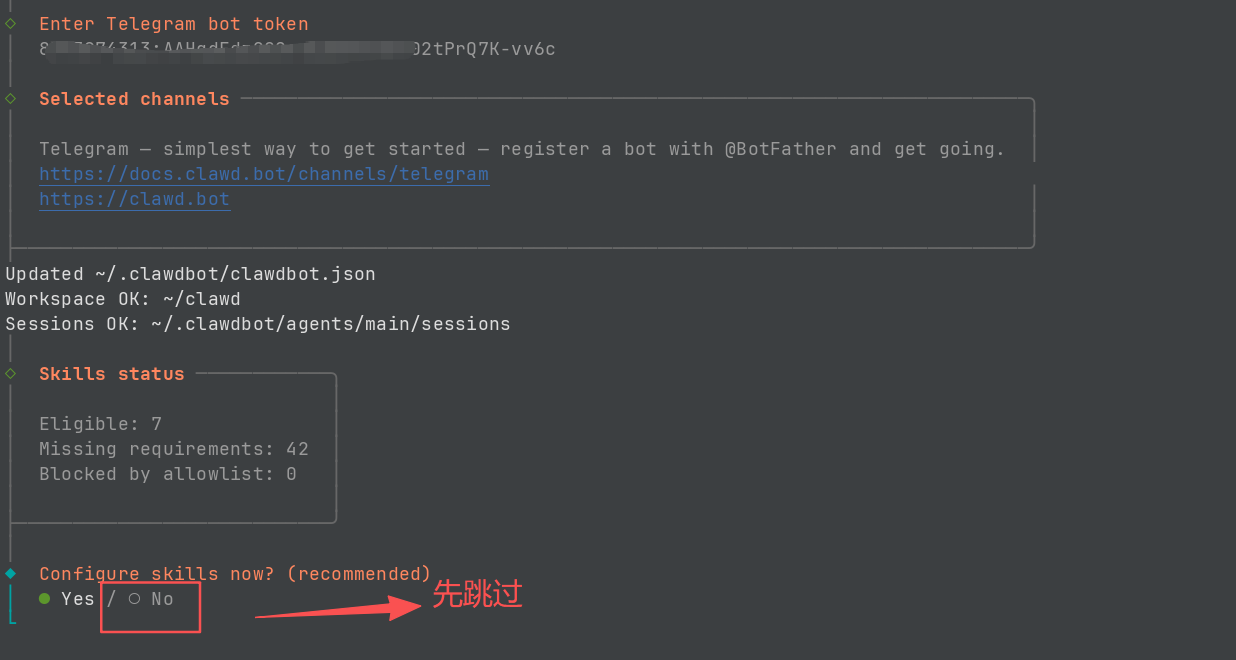
- Configure skills now:可以先跳过,选"No"
- Enable hooks:选"Skip for now"(按空格键选择)
- Hatch 选项:如果是在 linux 下配置,选"Hatch in TUI"可以在命令行下与 openclaw 进行交互
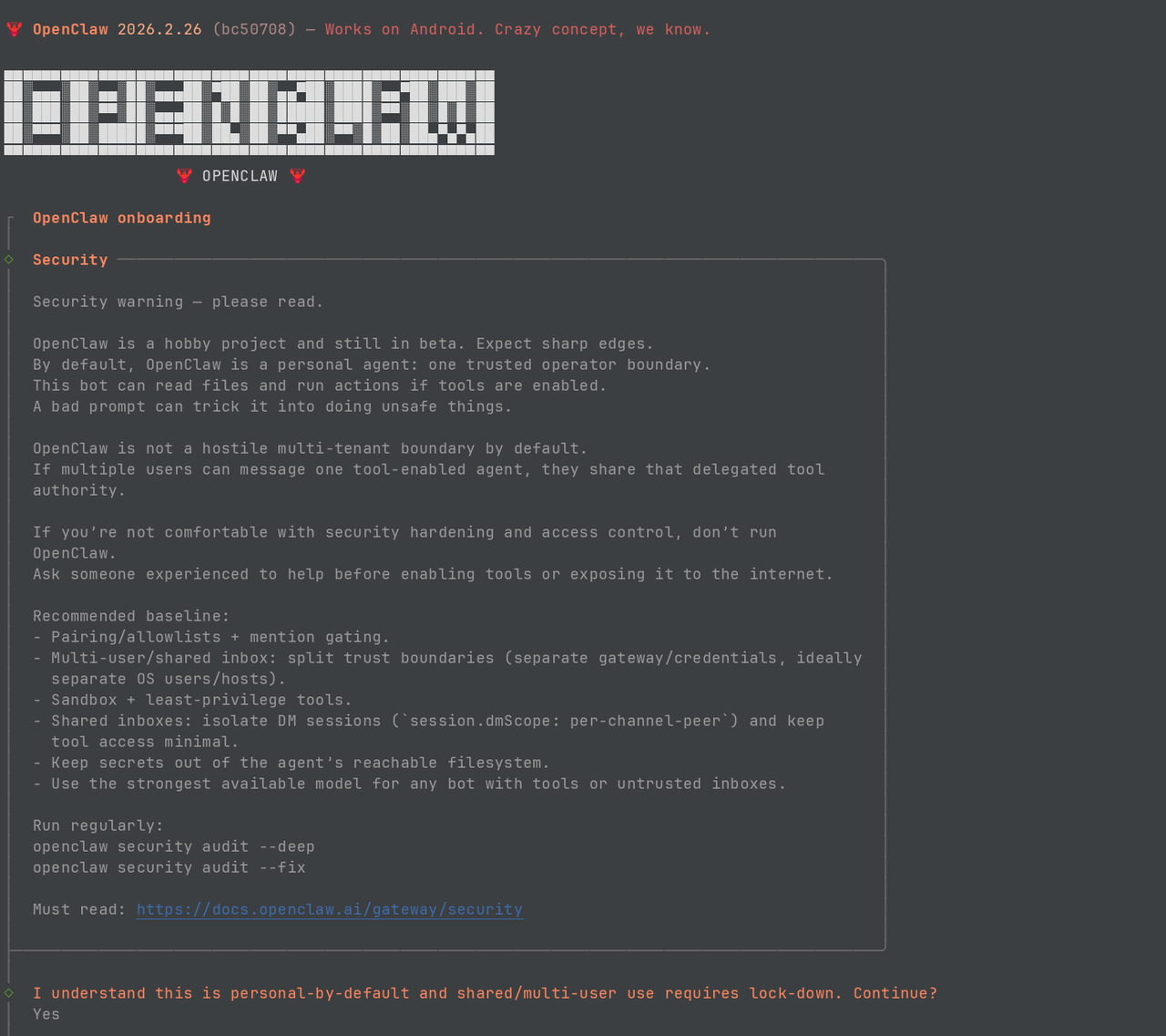
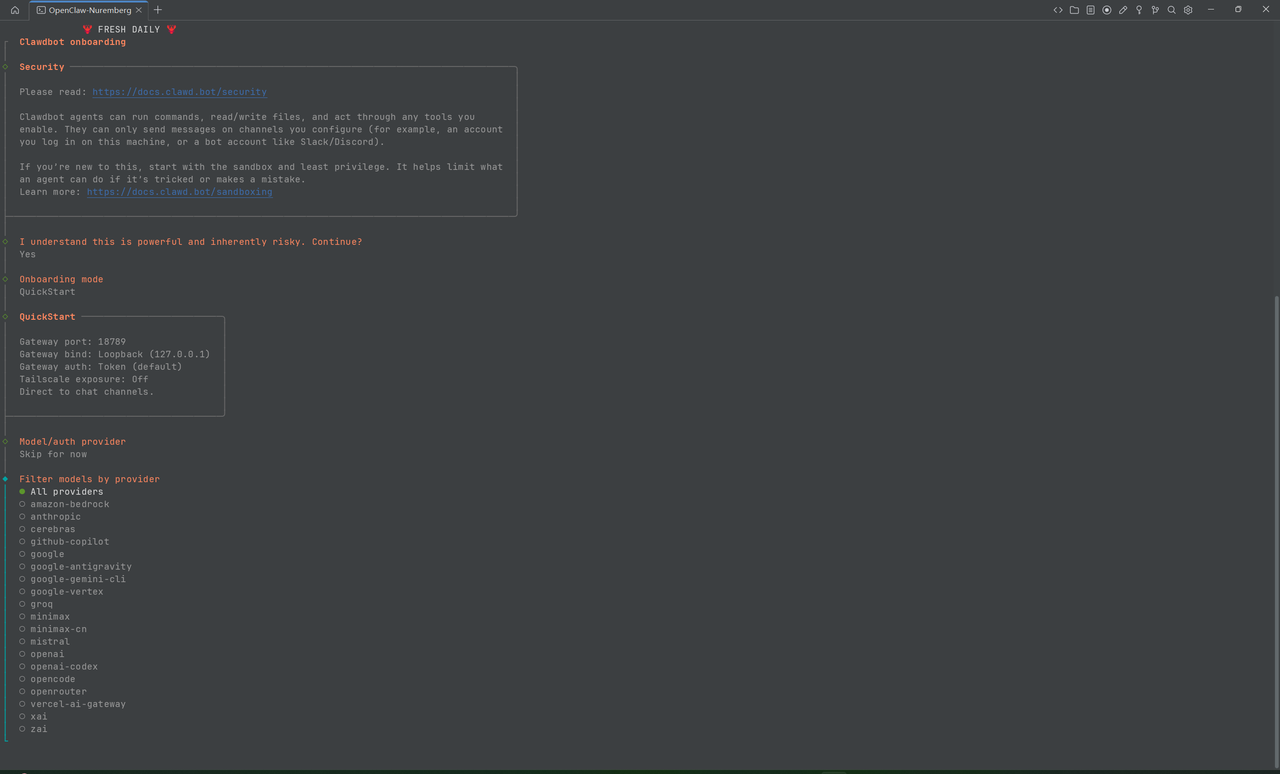
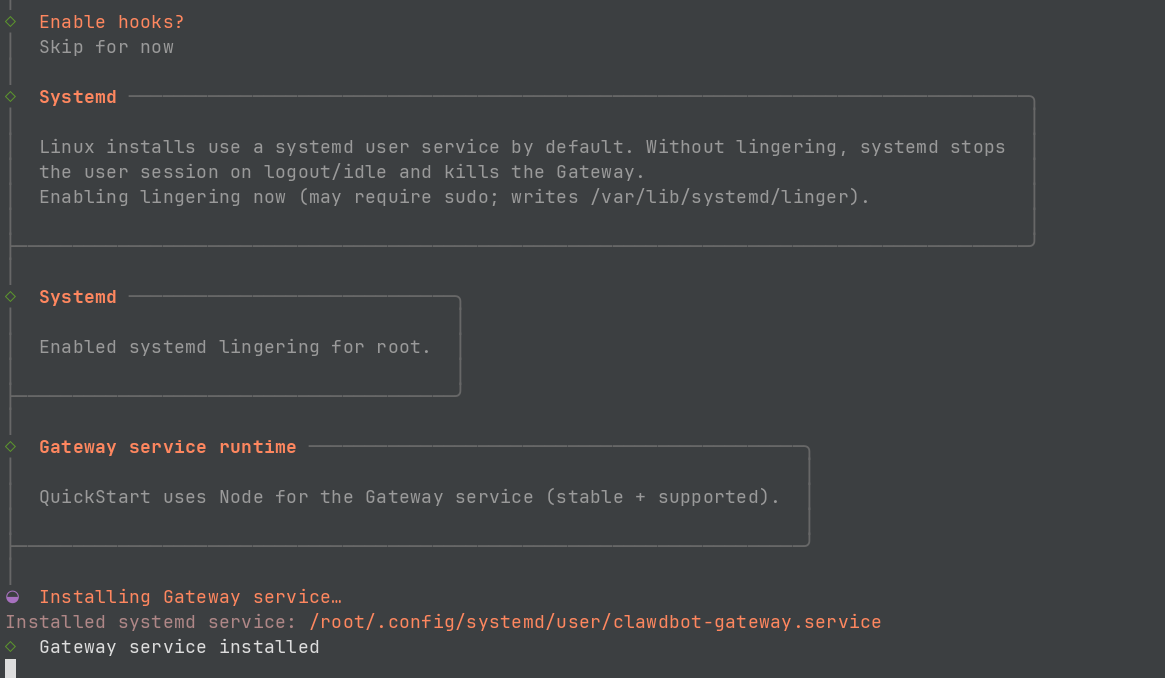

配置大模型
如果需要配置中转站,前面跳过了 Model/auth provider 配置,那这里需要配置大模型。
1. 进入配置目录
bash
cd ~/.openclaw/2. 编辑配置文件
bash
vim openclaw.json3. 配置示例:
json
{
"models": {
"mode": "merge",
"providers": {
"api-proxy-gpt": {
"baseUrl": "https://api.xtreeai.com/v1",
"api": "openai-completions",
"apiKey": "你的 apiKey",
"models": [
{
"id": "gpt-4o",
"name": "GPT-4o",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 8192
}
]
},
"api-proxy-claude": {
"baseUrl": "https://api.xtreeai.com",
"api": "anthropic-messages",
"apiKey": "你的 apiKey",
"models": [
{
"id": "claude-sonnet-4-5-20250929",
"name": "Claude Sonnet 4.5",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 200000,
"maxTokens": 8192
}
]
},
"api-proxy-google": {
"baseUrl": "https://api.xtreeai.com/v1beta",
"api": "google-generative-ai",
"apiKey": "你的 apiKey",
"models": [
{
"id": "gemini-3-pro-preview",
"name": "Gemini 3 Pro",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 2000000,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "api-proxy-claude/claude-sonnet-4-5-20250929"
},
"models": {
"api-proxy-gpt/gpt-4o": {
"alias": "GPT-4o"
},
"api-proxy-claude/claude-sonnet-4-5-20250929": {
"alias": "Claude Sonnet 4.5"
},
"api-proxy-google/gemini-3-pro-preview": {
"alias": "Gemini 3 Pro"
}
},
"maxConcurrent": 4,
"subagents": {
"maxConcurrent": 8
},
"compaction": {
"mode": "safeguard"
},
"workspace": "/root/clawd"
}
},
"auth": {
"profiles": {
"api-proxy-gpt:default": {
"provider": "api-proxy-gpt",
"mode": "api_key"
},
"api-proxy-claude:default": {
"provider": "api-proxy-claude",
"mode": "api_key"
},
"api-proxy-google:default": {
"provider": "api-proxy-google",
"mode": "api_key"
}
}
}
}⚠️ 重要提示:
- 配置的时候,对应模块进行复制或替换
- 原配置文件已经有了 agents 配置了,就替换。models 和 auth 配置没有,就复制进去
- 其他参数一般不需要调整
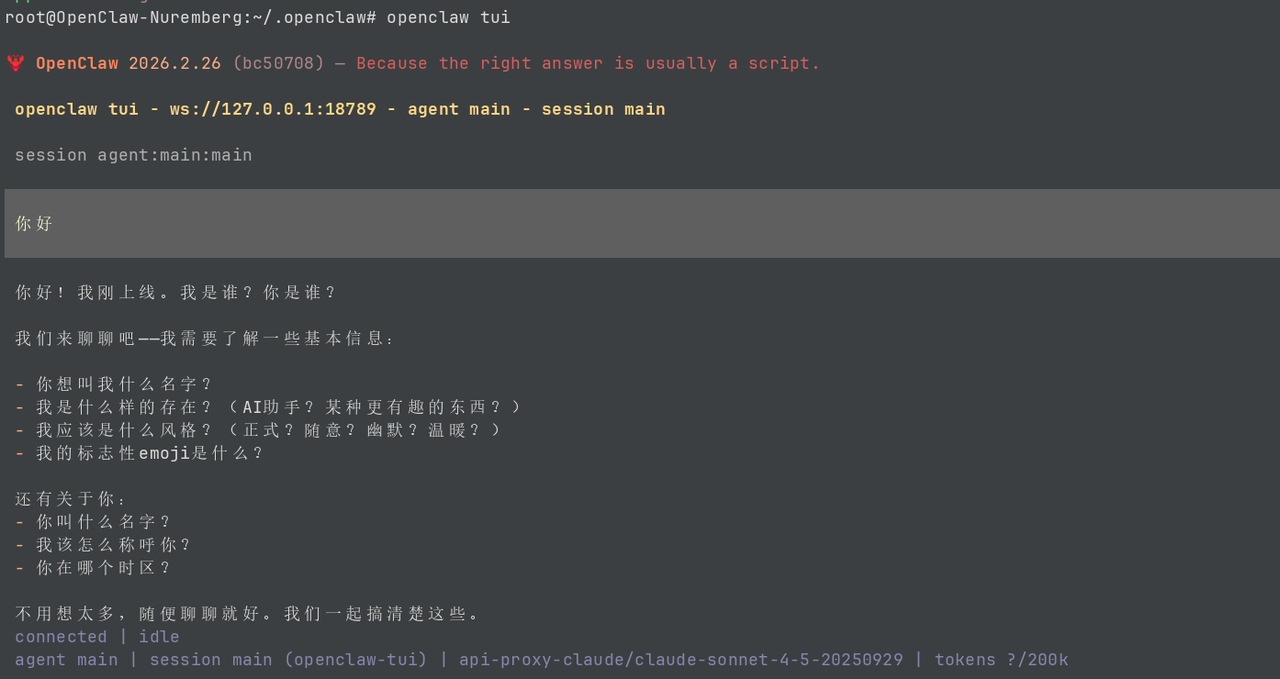
- 一定要注意 JSON 格式,可以整体复制出来,放到网站 https://www.json.cn/ 看看是否有错误
OpenClaw 交互
执行 tui 命令,与 OpenClaw 命令行交互:
bash
openclaw tui
其他设置:
可以执行 help 命令,自助查询相关命令和用法。
bash
openclaw --help
四、安装配置 Telegram
Telegram 是什么
Telegram(电报/纸飞机)是一款主打 隐私安全 与 强大功能 的全球即时通讯 App。全球月活用户已超 9.5 亿。
为什么选 Telegram 来控制 OpenClaw
1. 零门槛、随手用
- 不用装新 App:你本来就在用 Telegram,直接在里面发消息给 OpenClaw 机器人就行
- 跨设备无缝 :手机、电脑、平板都能发指令,随时随地远程控制
- 上手极快:用 Telegram 的 @BotFather 几分钟就能创建机器人、绑定 OpenClaw
2. 体验流畅、适合移动办公
- 移动端体验好:Telegram App 轻量、稳定,弱网下也能发指令、收结果
- 流式输出 :AI 回复会 边想边写,不用等一大段突然出来
- 消息可靠 :全球节点多、延迟低,跨境/海外场景下 指令不丢、不卡
3. 隐私与安全
- OpenClaw 本地运行 :你的文件、命令、数据都在自己设备,不上传第三方
- Telegram 加密 :指令走 Telegram 加密通道,传输安全
- 权限可控 :可限制只有你的 User ID 才能用这个机器人,防止被别人控制
4. 功能强、场景广
在 Telegram 里发一句话,OpenClaw 就能帮你:
- 系统操作:清理文件、运行 Shell 命令、重启服务、管理服务器
- 办公自动化:整理邮件、生成文档、做表格、发周报、管理日历
- 开发/运维:写代码、部署项目、查日志、监控服务
- 定时任务:每天自动爬数据、发报告、备份文件
- 跨平台协同:一边在 Telegram 聊工作,一边让 AI 处理后台任务
5. 适合团队/社群
- 把 OpenClaw 放进 Telegram 群组,团队成员都能调用 AI 助理
- 用 Forum Topics 做 任务隔离,不同话题对应不同自动化流程
- 适合跨境团队、远程协作、社群运营,全球都能用
Telegram 注册安装
1. 安装 App
App Store 搜索 "Telegram",点击安装。
2. 注册 Telegram
可以使用中国手机号,也可以使用美国手机号注册。
 |
 |
|---|
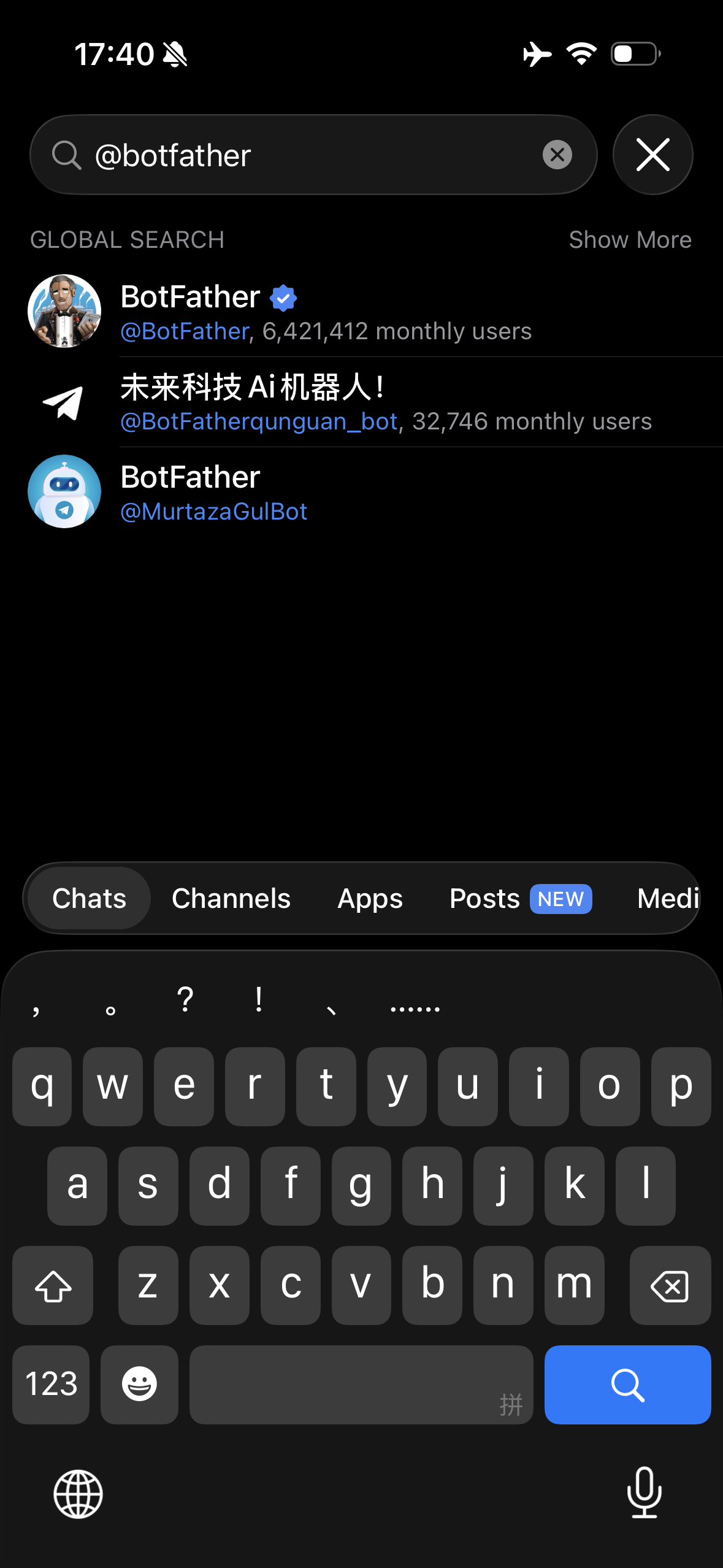
3. 添加 BotFather
在搜索栏里输入 @botfather,这是 Telegram 的官方机器人。
 |
 |
|---|
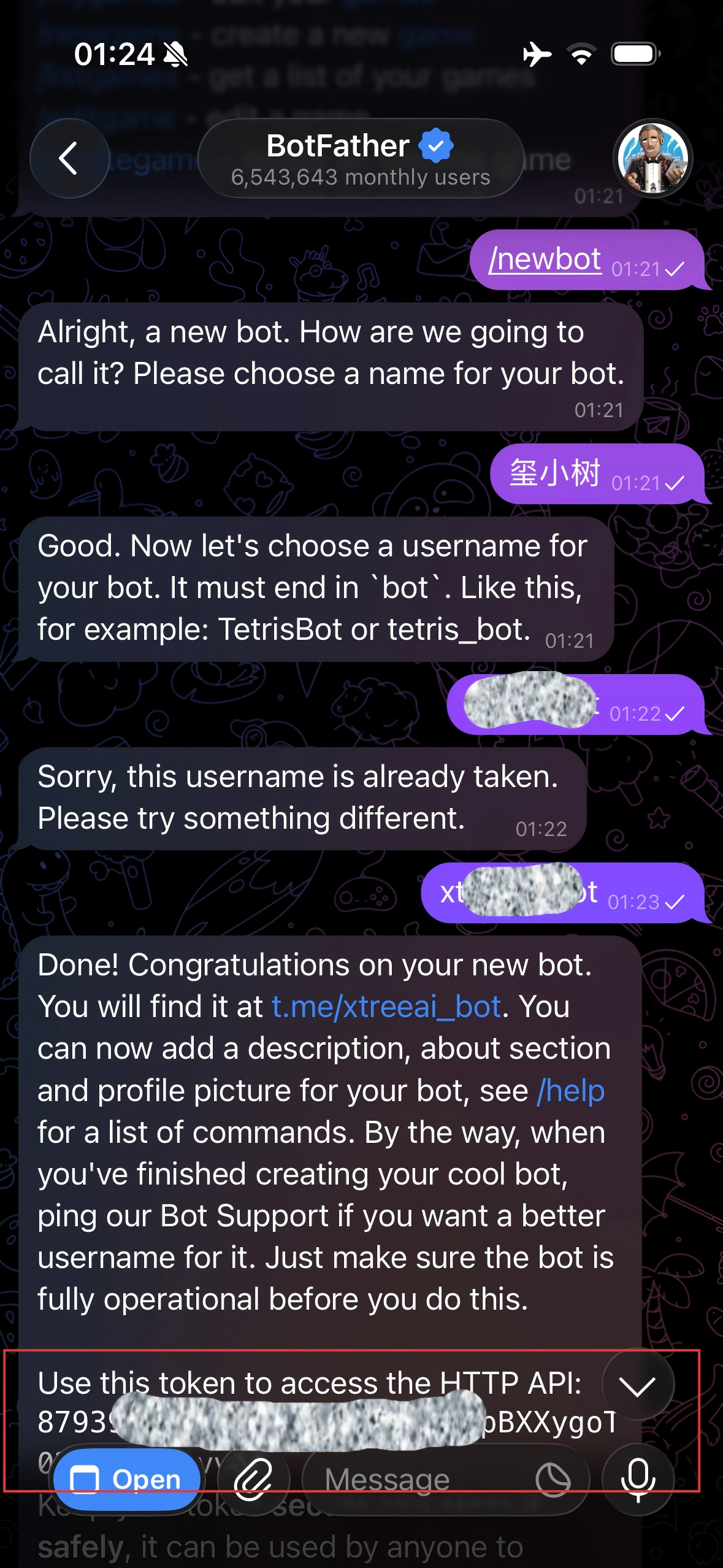
4. 创建 Bot 机器人
输入指令 /newbot 创建机器人,Telegram 会要求添加名称和账号,自定义即可。设置完成后会返回 Bot Token,OpenClaw 设置 Telegram bot token 的时候会用到。
 |
 |
|---|
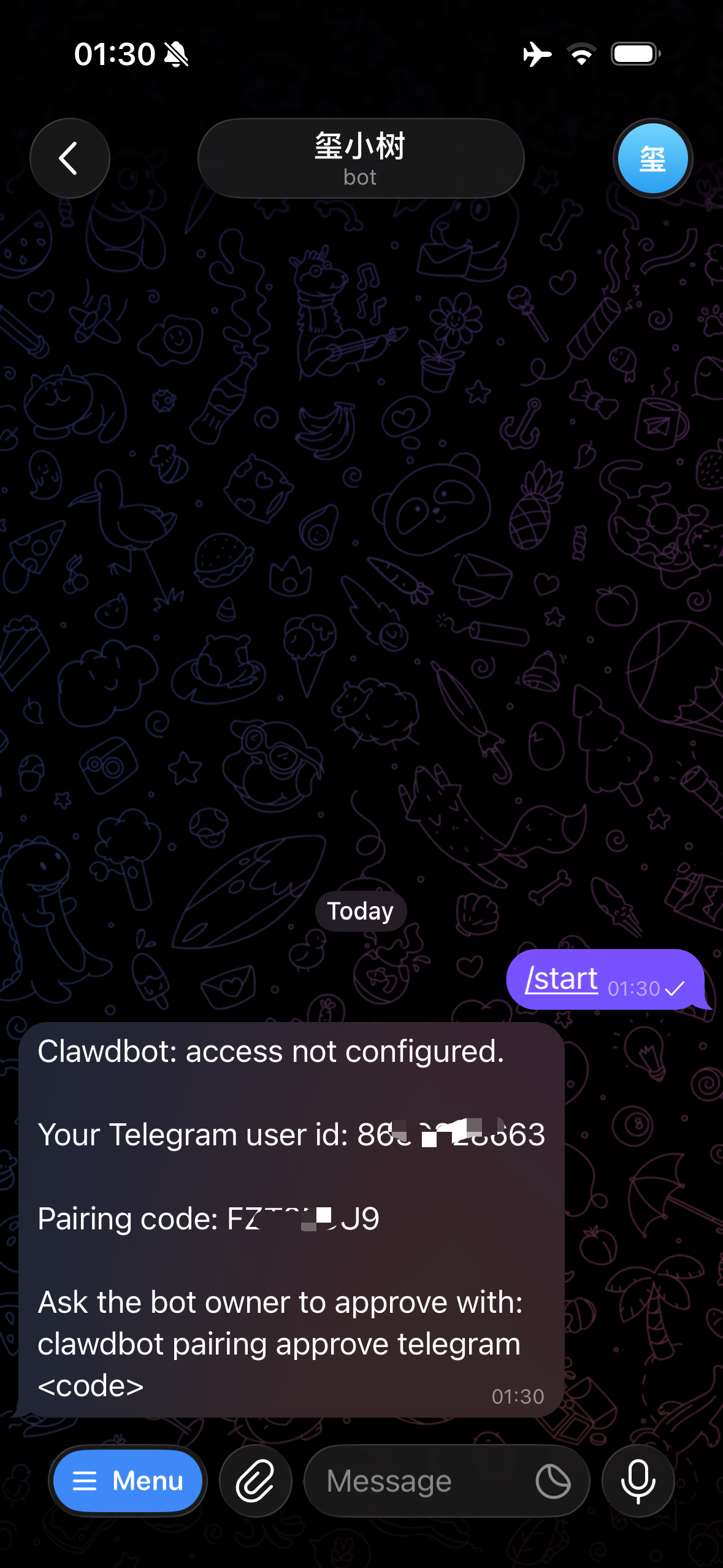
5. 生成 Pair Code
在 @botfather 下输入 /start,产生 pair code。
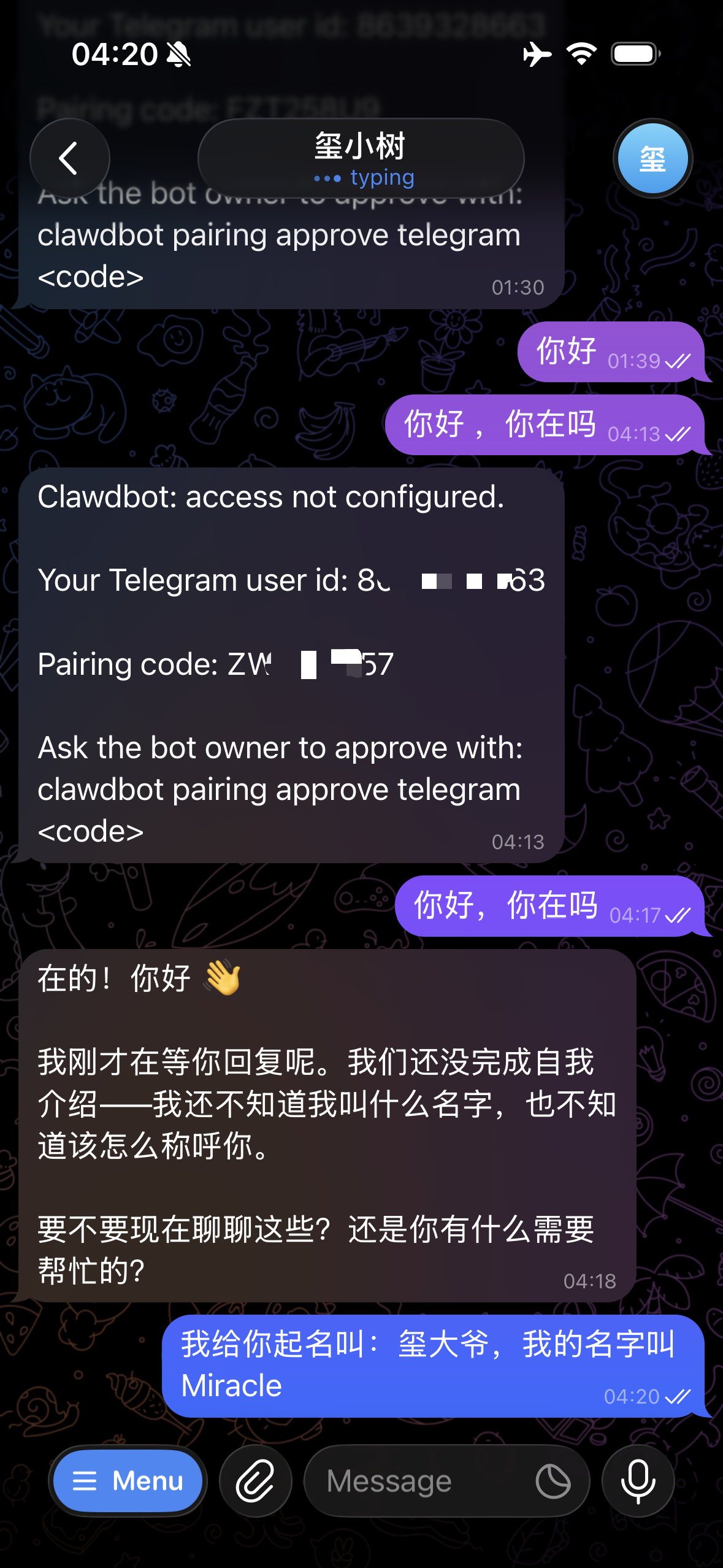
在服务器输入 openclaw pairing approve telegram <你的 code>,完成 Telegram 与 OpenClaw 的配对。

6. 开始奇妙之旅
现在你可以在 Telegram 中与 Openclaw 对话,并安排它干活啦。
🐦 案例 4:海外社媒(Twitter/X)自动化运营系统
一、创建 Twitter App
访问 Twitter Developer Portal
https://developer.twitter.com/en/portal/dashboard,申请成为开发者。
创建新 App(或使用现有 App)
⚠️ 注意:要充值,否则只能接受,无法发文。
设置 Key
进入 App Settings → User authentication settings → Edit
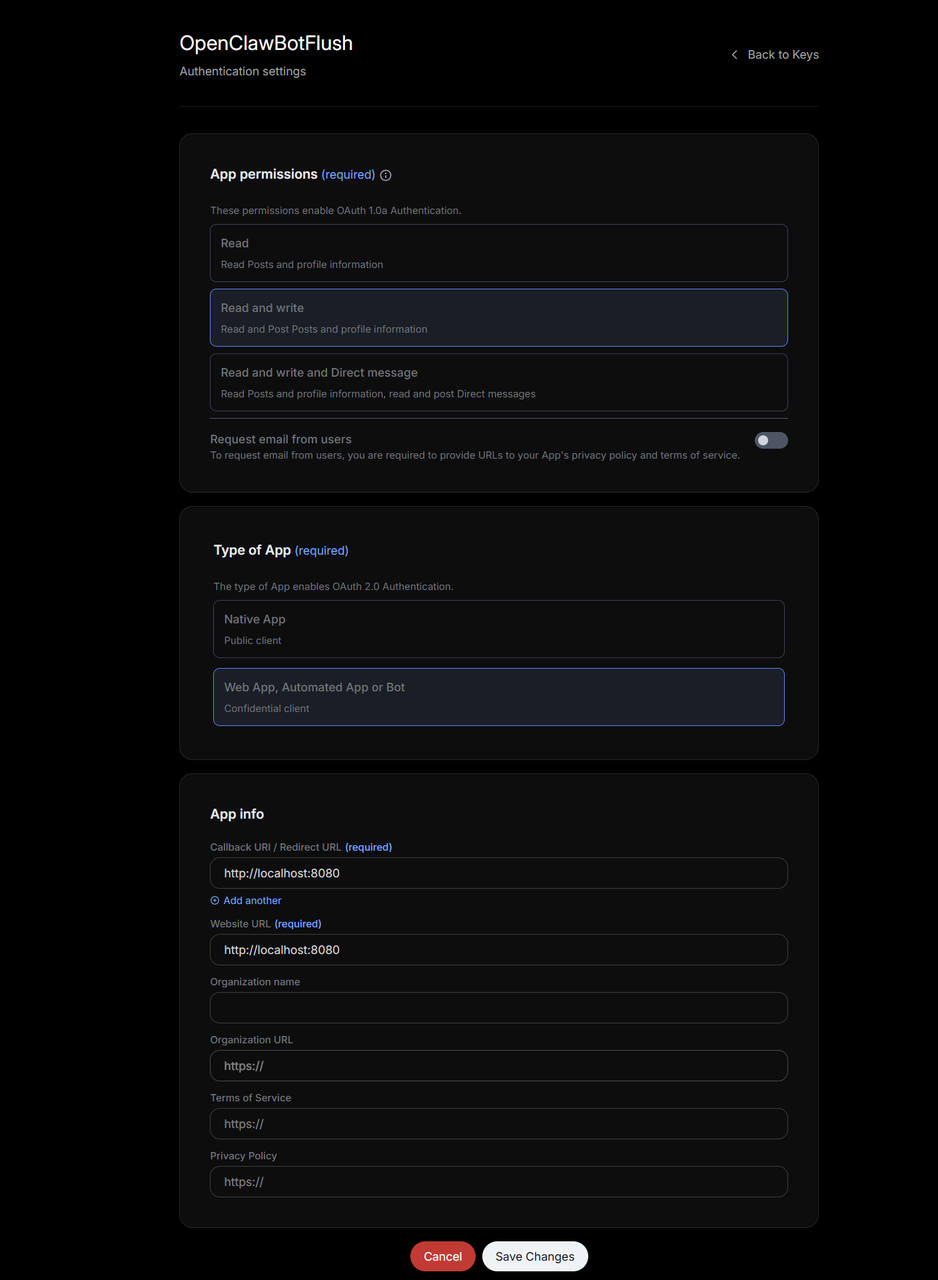
配置:
- App permissions: Read and Write
- Type of App: Web App
- Callback URI: http://127.0.0.1:8080/callback
- Website URL: 填写任意网址(如 https://example.com)
获取相关 key
- Consumer Key
- Secret Key
- Bearer Token
- Client ID
- Client Secret
配置 Twitter 凭证
创建配置文件:/root/clawd/twitter_config.json
json
{
"consumer_key": "你的 API_Key",
"consumer_secret": "你的 API_Key_Secret",
"bearer_token": "你的 Bearer_Token",
"client_id": "你的 Client_ID",
"client_secret": "你的 Client_Secret"
}二、创建授权脚本
文件位置:/root/clawd/twitter_oauth2_manual.py
python
#!/usr/bin/env python3
"""
Twitter OAuth 2.0 手动授权脚本(无浏览器版本)
"""
import requests
import base64
import json
import urllib.parse
# 替换为你的 Twitter App 凭证
CLIENT_ID = "你的_CLIENT_ID"
CLIENT_SECRET = "你的_CLIENT_SECRET"
REDIRECT_URI = "http://127.0.0.1:8080/callback"
def main():
print("🚀 Twitter OAuth 2.0 手动授权流程\n")
print("=" * 70)
# Step 1: 生成授权 URL
auth_url = (
f"https://twitter.com/i/oauth2/authorize?"
f"response_type=code&"
f"client_id={CLIENT_ID}&"
f"redirect_uri={urllib.parse.quote(REDIRECT_URI)}&"
f"scope=tweet.read%20tweet.write%20users.read%20offline.access&"
f"state=state123&"
f"code_challenge=challenge&"
f"code_challenge_method=plain"
)
print("\n📱 步骤 1:请在你的电脑/手机浏览器中打开以下链接:\n")
print(auth_url)
print("\n" + "=" * 70)
print("\n📱 步骤 2:登录 Twitter 并授权")
print(" 授权后,浏览器会跳转到一个无法访问的页面")
print(" 这是正常的!\n")
print("📱 步骤 3:复制浏览器地址栏的完整 URL")
print(" URL 格式类似:")
print(" http://127.0.0.1:8080/callback?code=XXXXXXXX&state=state123\n")
print("=" * 70)
# 获取用户输入的回调 URL
callback_url = input("\n请粘贴完整的回调 URL:").strip()
# 解析授权码
try:
parsed = urllib.parse.urlparse(callback_url)
params = urllib.parse.parse_qs(parsed.query)
auth_code = params['code'][0]
print(f"\n✅ 成功提取授权码:{auth_code[:20]}...\n")
except Exception as e:
print(f"\n❌ 解析失败:{e}")
print("请确保复制了完整的 URL!")
return
# Step 3: 用授权码换取 Access Token
print("🔄 正在获取 Access Token...\n")
token_url = "https://api.twitter.com/2/oauth2/token"
# Basic Auth
credentials = f"{CLIENT_ID}:{CLIENT_SECRET}"
b64_credentials = base64.b64encode(credentials.encode()).decode()
headers = {
"Authorization": f"Basic {b64_credentials}",
"Content-Type": "application/x-www-form-urlencoded"
}
data = {
"code": auth_code,
"grant_type": "authorization_code",
"redirect_uri": REDIRECT_URI,
"code_verifier": "challenge"
}
response = requests.post(token_url, headers=headers, data=data)
if response.status_code == 200:
tokens = response.json()
print("✅ 成功获取 Access Token!\n")
print("=" * 70)
print("📋 Token 信息:\n")
print(f"Access Token: {tokens['access_token']}\n")
print(f"Refresh Token: {tokens.get('refresh_token', 'N/A')}\n")
print(f"Token Type: {tokens.get('token_type', 'N/A')}")
print(f"Expires In: {tokens.get('expires_in', 'N/A')} seconds")
print("=" * 70)
# 保存到文件
with open('/root/clawd/twitter_tokens.json', 'w') as f:
json.dump(tokens, f, indent=2)
print("\n💾 Token 已保存到:/root/clawd/twitter_tokens.json")
# 测试发推
print("\n🧪 测试发推功能...\n")
test_tweet(tokens['access_token'])
else:
print(f"❌ 获取 Token 失败:{response.status_code}")
print(f"错误信息:{response.text}")
def test_tweet(access_token):
"""测试发推"""
url = "https://api.twitter.com/2/tweets"
headers = {
"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"
}
data = {
"text": "🤖 测试推文 - OpenClaw AI 助手已成功连接!#AI #OpenClaw"
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 201:
tweet_data = response.json()
tweet_id = tweet_data['data']['id']
print(f"✅ 测试推文发送成功!")
print(f"🔗 查看推文:https://twitter.com/user/status/{tweet_id}")
else:
print(f"❌ 发推失败:{response.status_code}")
print(f"错误信息:{response.text}")
if __name__ == "__main__":
main()三、获取 Access Token
服务器执行命令:
bash
cd /root/clawd
python3 twitter_oauth2_manual.py按照提示操作:
- 复制授权链接到浏览器
- 登录并授权
- 复制回调 URL(虽然页面打不开,但 URL 是对的)
- 粘贴回终端
成功后会生成 /root/clawd/twitter_tokens.json
四、创建发推脚本
文件位置:/root/clawd/post_ai_news.py
python
#!/usr/bin/env python3
"""
自动发布 AI 新闻到 Twitter
"""
import requests
import json
from datetime import datetime
def search_ai_news(api_key):
"""使用 Tavily 搜索 AI 新闻"""
response = requests.post(
'https://api.tavily.com/search',
json={
'api_key': api_key,
'query': 'AI artificial intelligence news today 2026',
'search_depth': 'basic',
'max_results': 3
}
)
if response.status_code == 200:
return response.json().get('results', [])
return []
def post_tweet(access_token, text):
"""发送推文"""
url = "https://api.twitter.com/2/tweets"
headers = {
"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={'text': text})
if response.status_code == 201:
tweet_data = response.json()
tweet_id = tweet_data['data']['id']
return True, tweet_id
else:
return False, response.text
def main():
# 读取 Token
with open('/root/clawd/twitter_tokens.json', 'r') as f:
tokens = json.load(f)
access_token = tokens['access_token']
# Tavily API Key(替换为你的)
tavily_api_key = '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'
print('🔍 正在搜索今天的 AI 新闻...\n')
results = search_ai_news(tavily_api_key)
if results:
# 取第一条新闻
top_news = results[0]
title = top_news.get('title', '')
url = top_news.get('url', '')
content = top_news.get('content', '')[:150]
# 构建推文
tweet_text = f'''🤖 今日 AI 要闻
{title}
{content}...
🔗 {url}
#AI #ArtificialIntelligence #Tech'''
# 检查长度(Twitter 限制 280 字符)
if len(tweet_text) > 280:
tweet_text = f'''🤖 {title[:100]}...
🔗 {url}
#AI #Tech'''
print(f'📝 推文内容:\n{tweet_text}\n')
print('=' * 60)
# 发送推文
print('\n📤 正在发送推文...\n')
success, result = post_tweet(access_token, tweet_text)
if success:
print(f'✅ 推文发送成功!')
print(f'🔗 查看推文:https://twitter.com/user/status/{result}')
else:
print(f'❌ 发推失败:{result}')
else:
print('❌ 没有找到相关新闻')
if __name__ == "__main__":
main()五、测试发推
服务器执行命令:
bash
cd /root/clawd
python3 post_ai_news.py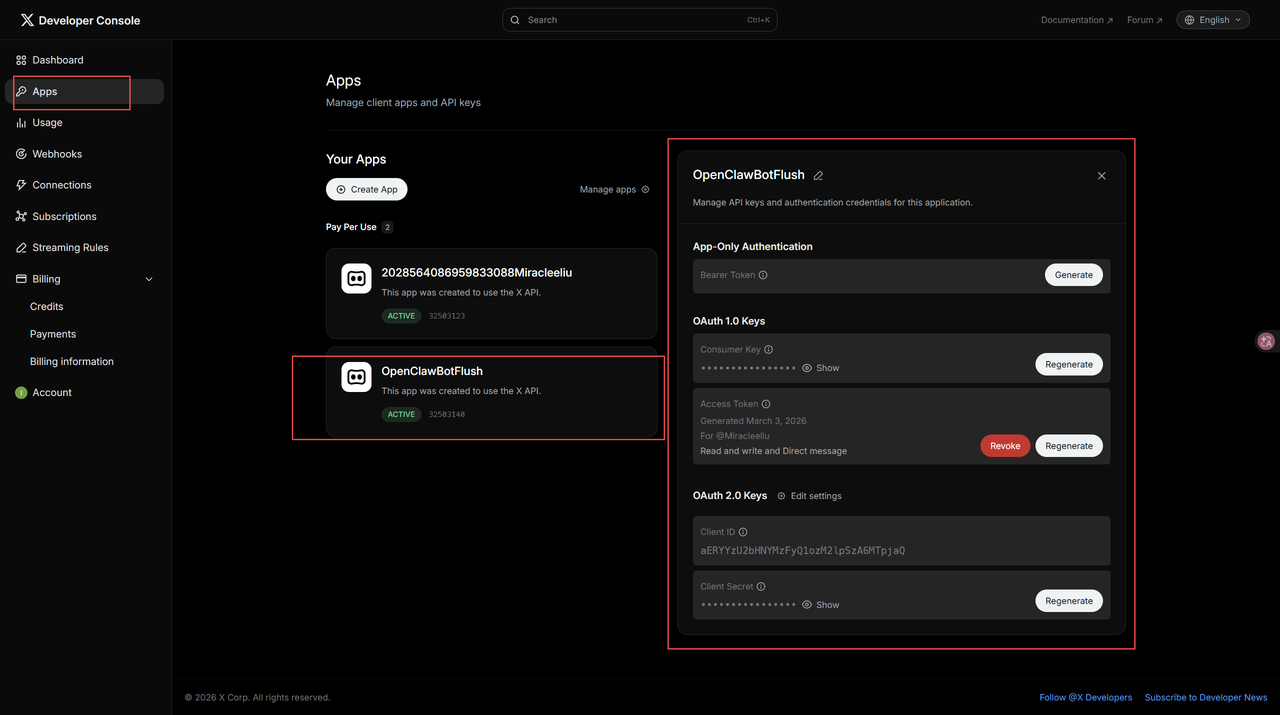
六、设置定时任务(可选)
方法 1:使用 cron
bash
# 编辑 crontab
crontab -e
# 添加定时任务(每天早上 9 点发推)
0 9 * * * cd /root/clawd && python3 post_ai_news.py >> /root/clawd/twitter_post.log 2>&1方法 2:使用 OpenClaw Heartbeat
编辑 /root/clawd/HEARTBEAT.md:
markdown
# HEARTBEAT.md
## 每日 AI 新闻推文
每天检查一次(约 9:00 UTC):
- 读取 `memory/last_tweet_date.txt`
- 如果不是今天,运行 `python3 /root/clawd/post_ai_news.py`
- 更新日期文件七、整体文件结构
bash
/root/clawd/
├── twitter_oauth2_manual.py # 授权脚本
├── twitter_tokens.json # Token 文件(自动生成)
├── post_ai_news.py # 发推脚本
└── twitter_post.log # 日志文件(可选)八、Token 刷新(重要!)
Twitter OAuth 2.0 Token 有效期为 2 小时,需要定期刷新。
创建刷新脚本: /root/clawd/refresh_twitter_token.py
python
#!/usr/bin/env python3
"""
刷新 Twitter Access Token
"""
import requests
import base64
import json
CLIENT_ID = "你的_CLIENT_ID"
CLIENT_SECRET = "你的_CLIENT_SECRET"
def refresh_token():
# 读取当前 Token
with open('/root/clawd/twitter_tokens.json', 'r') as f:
tokens = json.load(f)
refresh_token = tokens['refresh_token']
# 刷新 Token
token_url = "https://api.twitter.com/2/oauth2/token"
credentials = f"{CLIENT_ID}:{CLIENT_SECRET}"
b64_credentials = base64.b64encode(credentials.encode()).decode()
headers = {
"Authorization": f"Basic {b64_credentials}",
"Content-Type": "application/x-www-form-urlencoded"
}
data = {
"refresh_token": refresh_token,
"grant_type": "refresh_token"
}
response = requests.post(token_url, headers=headers, data=data)
if response.status_code == 200:
new_tokens = response.json()
# 保存新 Token
with open('/root/clawd/twitter_tokens.json', 'w') as f:
json.dump(new_tokens, f, indent=2)
print("✅ Token 刷新成功!")
else:
print(f"❌ Token 刷新失败:{response.status_code}")
print(response.text)
if __name__ == "__main__":
refresh_token()添加到 cron(每小时刷新一次):
bash
0 * * * * cd /root/clawd && python3 refresh_twitter_token.py >> /root/clawd/token_refresh.log 2>&1九、完整检查清单
- ✅ Twitter Developer Account(已付费)
- ✅ 创建 Twitter App
- ✅ 配置 OAuth 2.0(Read and Write)
- ✅ 添加回调 URL
- ✅ 创建授权脚本
- ✅ 运行授权获取 Token
- ✅ 创建发推脚本
- ✅ 测试发推功能
- ✅ 设置定时任务
- ✅ 配置 Token 自动刷新
十、关键注意事项
- ⚠️ Client ID 和 Client Secret 必须替换为你自己的
- ⚠️ Tavily API Key 需要替换(或使用其他新闻源)
- ⚠️ Token 有效期 2 小时,必须定期刷新
- ⚠️ 推文长度限制 280 字符
- ⚠️ Twitter API 有速率限制(Basic Plan: 50 推文/24 小时)
十一、常见问题
Q: Token 过期怎么办?
A: 运行 refresh_twitter_token.py 或重新授权
Q: 发推失败 401 错误?
A: Token 过期,需要刷新
Q: 发推失败 403 错误?
A: 检查 App 权限是否为 Read and Write
Q: 如何更换新闻源?
A: 修改 post_ai_news.py 中的 search_ai_news() 函数
🎯 阶段总结
通过第三阶段的 4 个案例学习,你已经掌握了:
✅ 多 Agent 协作系统 :打造 AI 智能体军团,实现专业分工
✅ 技能库与角色调优 :让每个 AI 都术业有专攻
✅ 海外服务器部署 :Hetzner + OpenClaw + Telegram 全球化方案
✅ Twitter 自动化运营:从 0 到 1 搭建海外社媒自动发布系统
核心理念:
技能库是 Agent 的"硬实力",角色定义是 Agent 的"软实力",二者结合才能实现"术业有专攻"的多 Agent 协作。
下一步: 持续实践,将所学技能应用到你的实际业务场景中,打造属于你自己的 AI 智能体生态系统!