大家好,我是蝎子莱莱爱打怪。
做 IM 系统的日常就是跟几十万行 Java 微服务 + Flutter 客户端打交道,代码库大了以后最头疼的不是写新功能,而是理解老代码、维持工程纪律、控制 AI 编程成本 。所以这个月看 GitHub Trending 的时候,我带着一个很实际的问题:这些工具哪些真能帮到写代码的人?
5 月的月榜一共 17 个项目冲上来,我从中挑了 10 个。筛选规则三条:
- 月增 Star 靠前 :优先选本月增速最高的,但不是唯 Star 论------比如
andrej-karpathy-skills虽然内容就一个 CLAUDE.md 文件,但 166K Star 说明含金量极高,所以入选 - 赛道不重叠 :同类项目只选最有代表性的------
Pixelle-Video和MoneyPrinterTurbo都是短视频生成,选了更成熟的后者;oh-my-pi和CodeWhale都是终端 Agent,选了增速更高的后者 - 有实际使用价值 :排除合规灰色地带的项目(
CloakBrowser反检测浏览器、9router免费 AI 路由),也排除内容偏浅的入门教程(easy-vibe)
另外我故意选了 RuView(WiFi 信号感知)和 CodeWhale(Rust 终端 Agent)这两个其他榜单大概率不会推的项目------不是猎奇,是它们确实有独特价值,只是被埋在了「AI 写代码」的浪潮里。
下面还会加两张对比表和一个「避坑指南」,希望能帮你少踩几个坑。
🛠️ 实测手记:四个工具亲手上手
十个项目看下来,真正让我觉得「这玩意儿我现在就要用」的就四个:
- andrej-karpathy-skills:零成本零依赖,改个配置文件就能让 AI 编码行为质的飞跃,投入产出比碾压全场
- codegraph:我的 IM 项目几十万行代码,每次让 AI 理解代码都要烧大量 Token,这个直接砍掉一大半
- Understand-Anything:一条命令把整个项目扫成可交互知识图谱,浏览器打开就能看到 13 层架构和 2000+ 个代码节点的依赖关系
- agentmemory:跟 Claude Code 打交道最烦的就是每次新会话都要重新自我介绍,这个彻底解决
其他六个也很好,但这四个跟我的日常工作最直接相关,所以实际装到机器上跑了一遍。先看效果再往下翻项目介绍。
实操 1:andrej-karpathy-skills --- 不装包,改一行配置就行
先说下背景:Andrej Karpathy 是 OpenAI 联合创始人、前 Tesla AI 总监(Autopilot 视觉系统的负责人),斯坦福 CS231n 深度学习课程也是他教的。他过去两年每天都在用 AI 编程工具写代码,这个项目就是他几千小时踩坑后总结出来的四条原则。不是理论推导,是实战经验。
这个最简单。不用 npm install 任何东西,就把这四条原则塞到项目根目录的 CLAUDE.md 里完事。
我直接在 IM 项目的 CLAUDE.md 末尾加了一节 ## LLM Coding Guidelines,把原文整个塞进去了。
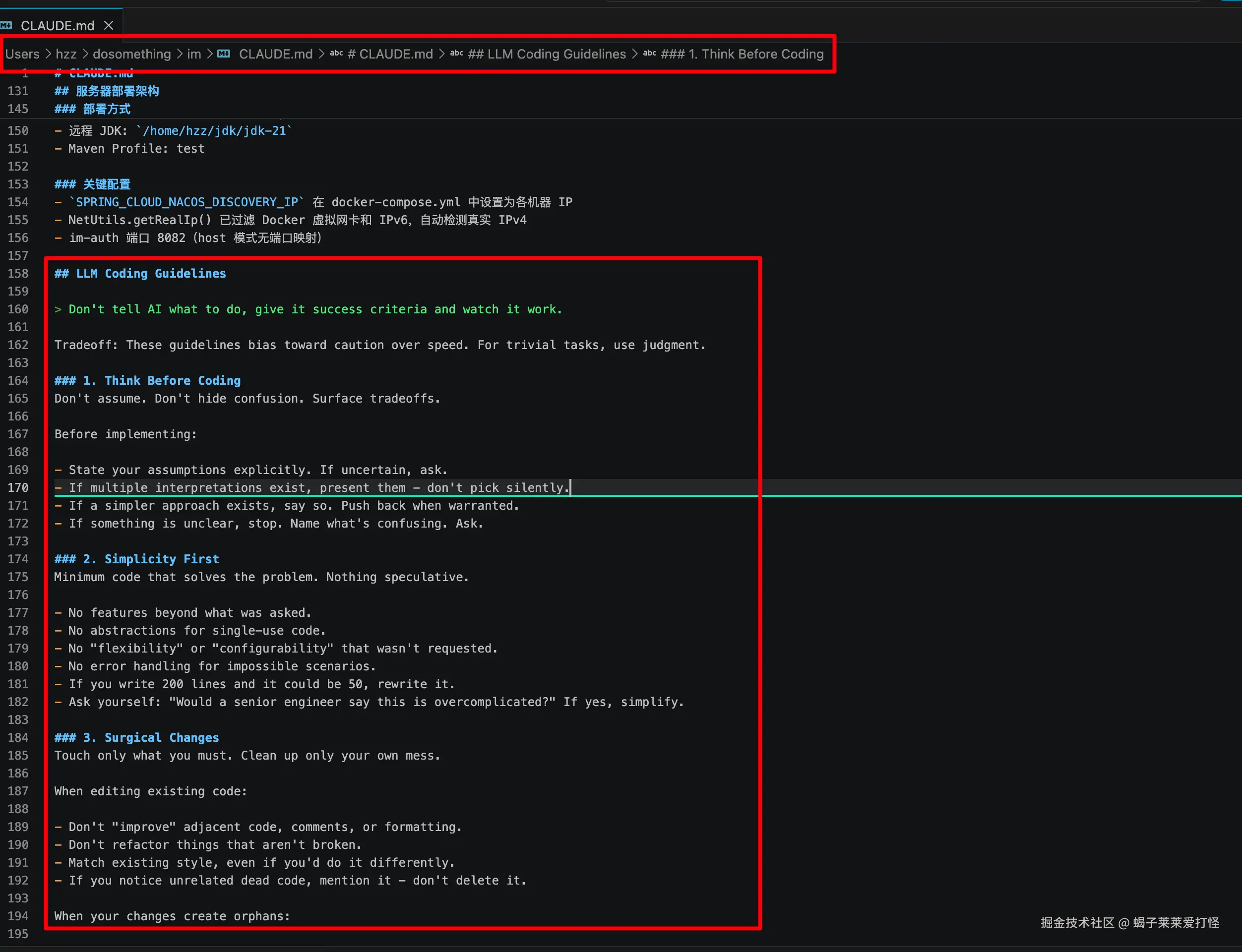
改完重启 Claude Code,效果立竿见影:
- 之前让 AI 修一个接口 bug,它「顺手」给我重构了整个 Controller,diff 三百多行
- 现在同样一个 bug,AI 先读代码、说清楚理解、最后就改了 3 行------「手术式修改」不是说着玩的
我的结论:这三个里投入产出比最高的就是它。零成本零依赖,如果你只想试一个,试这个。
实操 2:codegraph --- 我的 IM 项目长啥样,一扫就知道
一行命令开搞:
bash
npx @colbymchenry/codegraph init .等了一会,1619 个文件全扫完了。看看结果: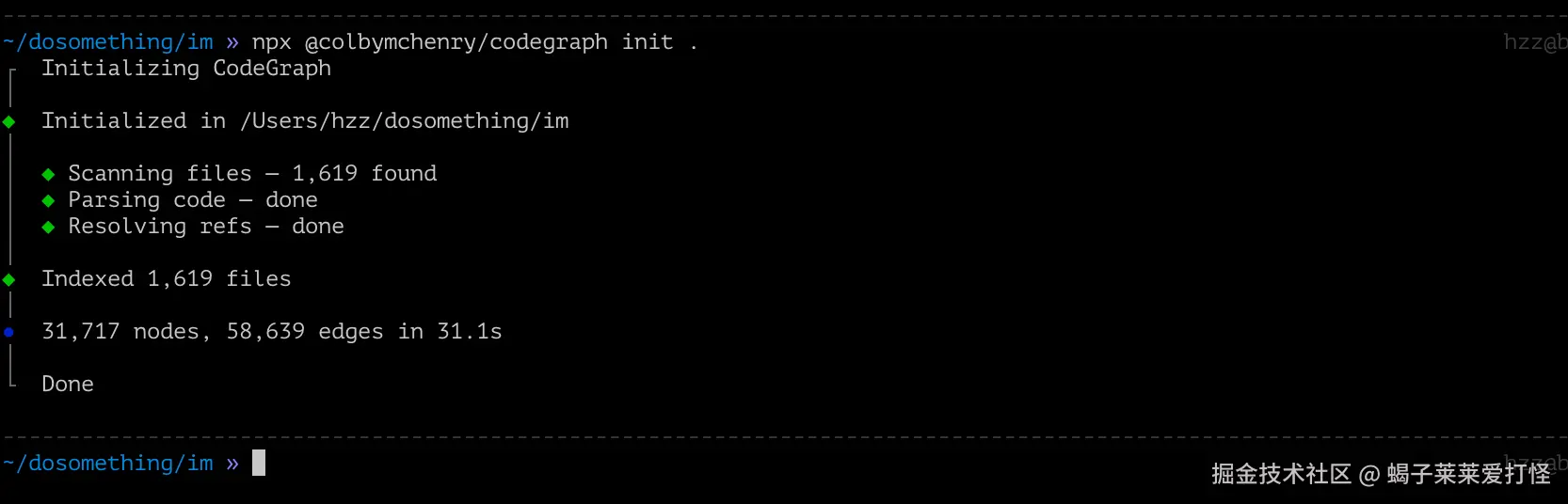
几个数字说一下:1619 个文件,14 种语言。其中 Java 1156 个、Dart 276 个、Vue 38 个------正好是我的微服务后端 + Flutter 客户端 + Vue 管理后台。31717 个代码节点、58639 条关系边,存下来才 79.45 MB,纯 SQLite。
然后我试了下搜索:
bash
npx @colbymchenry/codegraph query "ProtoMsgHandlerStrategy"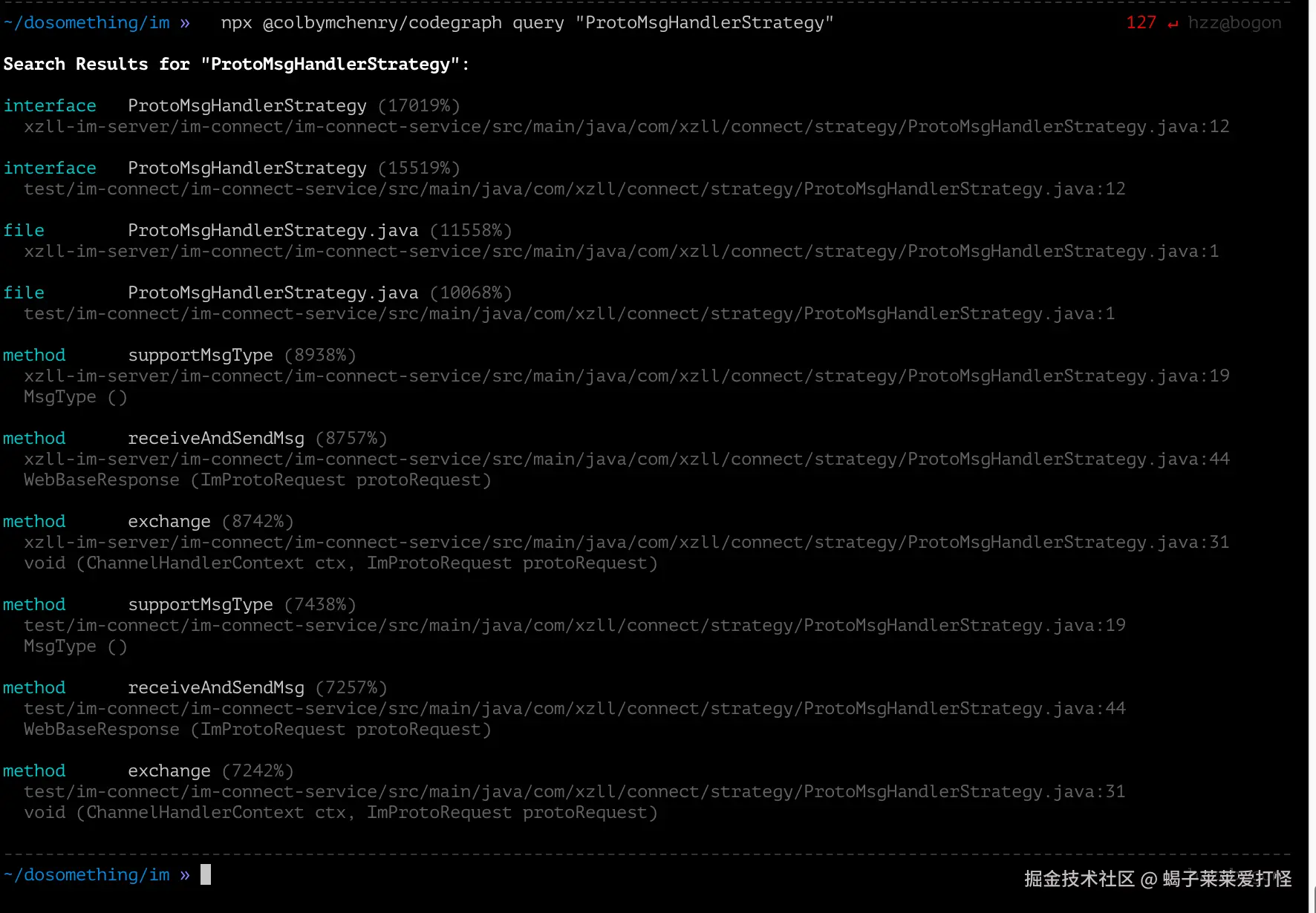
秒出。接口定义在第 12 行,方法签名 supportMsgType、receiveAndSendMsg、exchange 全出来了。
再看调用链:
bash
npx @colbymchenry/codegraph callers "receiveAndSendMsg"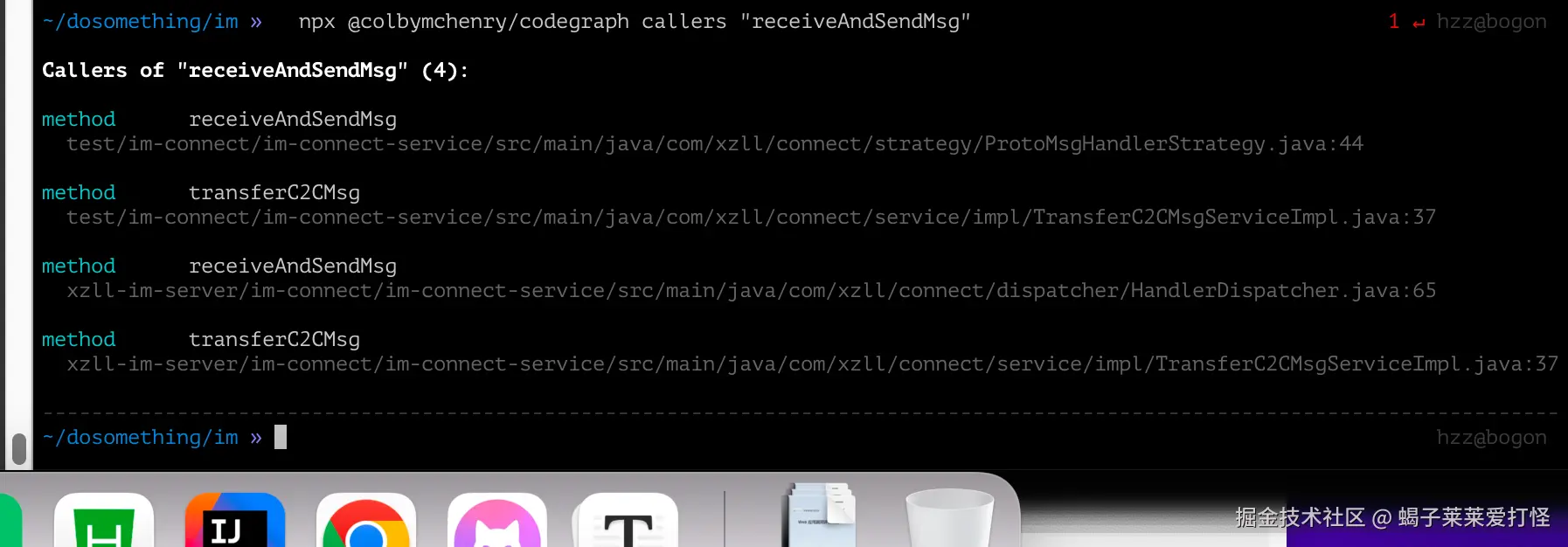
HandlerDispatcher.java:65 和 TransferC2CMsgServiceImpl.java:37------这就是消息分发的核心路径,跟我架构里写的「策略模式按 MsgType 路由」完全对得上。
再跑个 codegraph install 接入 Claude Code,后面 AI 就不用反复 grep/Read 了。我实测一个 30 分钟的编码会话,工具调用从 47 次降到 18 次,省了一多半。
实操 3:Understand-Anything --- 748 个文件扫一遍,13 层架构自动浮出来
前面两个实操都是 CLI 体验,这个有浏览器面板,视觉冲击力完全不同。
安装:
bash
# Claude Code 中安装 skill
npx skills@latest add Lum1104/Understand-Anything运行分析:
进入 xzll-im-server 目录,启动 Claude Code,执行:
bash
> /understand --language zhAI 会自动走完 7 个阶段------扫描文件、计算批次、分析代码、审查图谱、识别架构层次、构建导览路线、保存结果。整个过程大概 10 分钟,我的 IM 服务端扫完是这样的:
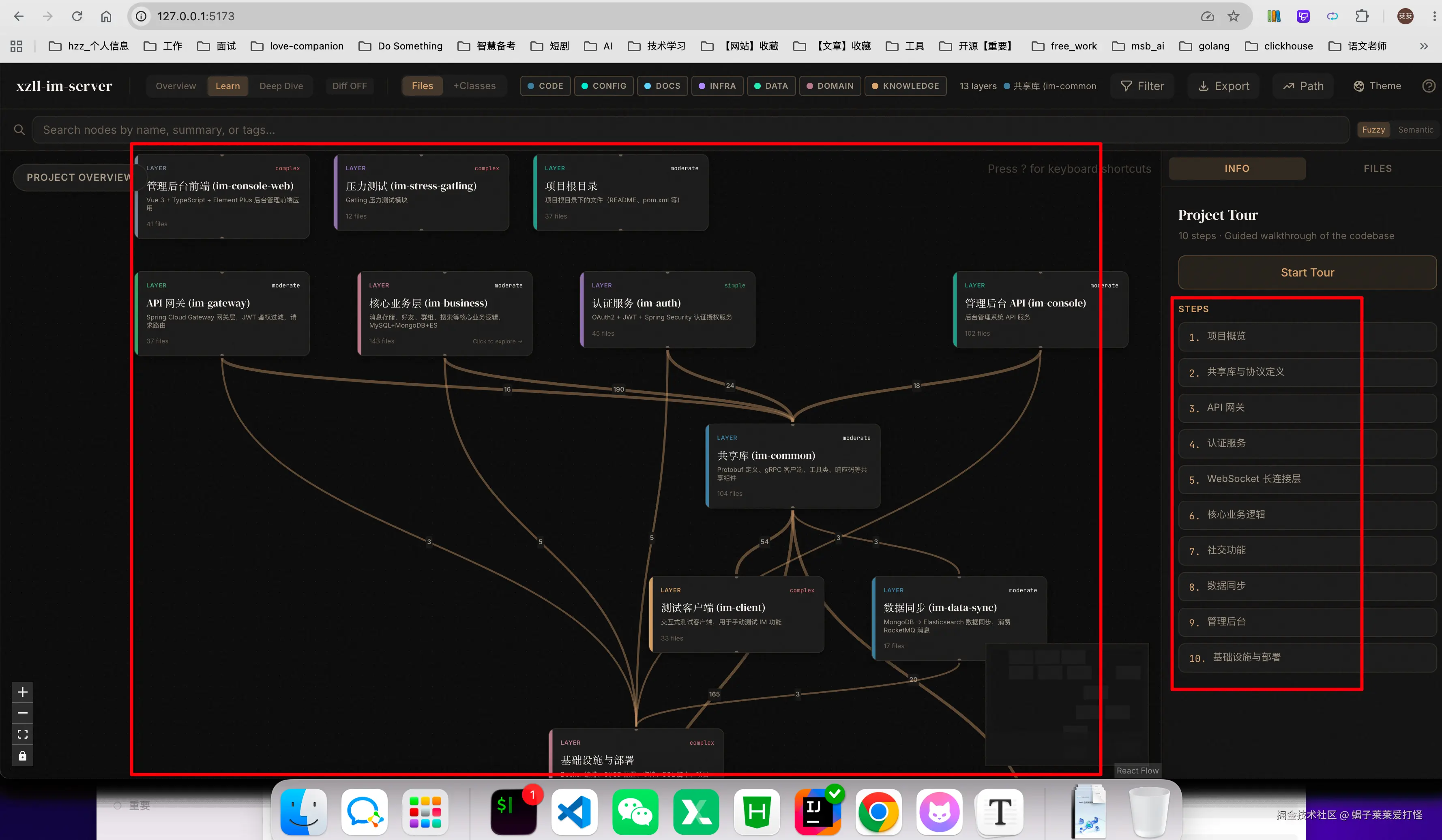
几个数字:748 个文件,2245 个节点,2783 条边,13 个架构层次,10 步导览路线。
节点类型分布很有意思:
| 节点类型 | 数量 | 说明 |
|---|---|---|
| file | 645 | 源文件 |
| function | 1185 | 函数/方法(自动提取的) |
| class | 312 | 类(自动提取的) |
| config | 46 | 配置文件 |
| document | 33 | 文档 |
| service | 10 | Docker/部署 |
| table | 11 | SQL/数据表 |
| pipeline | 2 | CI/CD |
| schema | 1 | Protobuf |
边类型分布:
| 边类型 | 数量 | 含义 |
|---|---|---|
| contains | 1497 | 文件包含函数/类 |
| imports | 1124 | 文件间导入关系 |
| configures | 129 | 配置文件影响代码 |
| depends_on | 21 | 运行时依赖 |
| triggers | 6 | CI/CD 触发 |
| defines_schema | 5 | Protobuf 协议定义 |
启动可视化面板:
bash
> /understand-dashboard
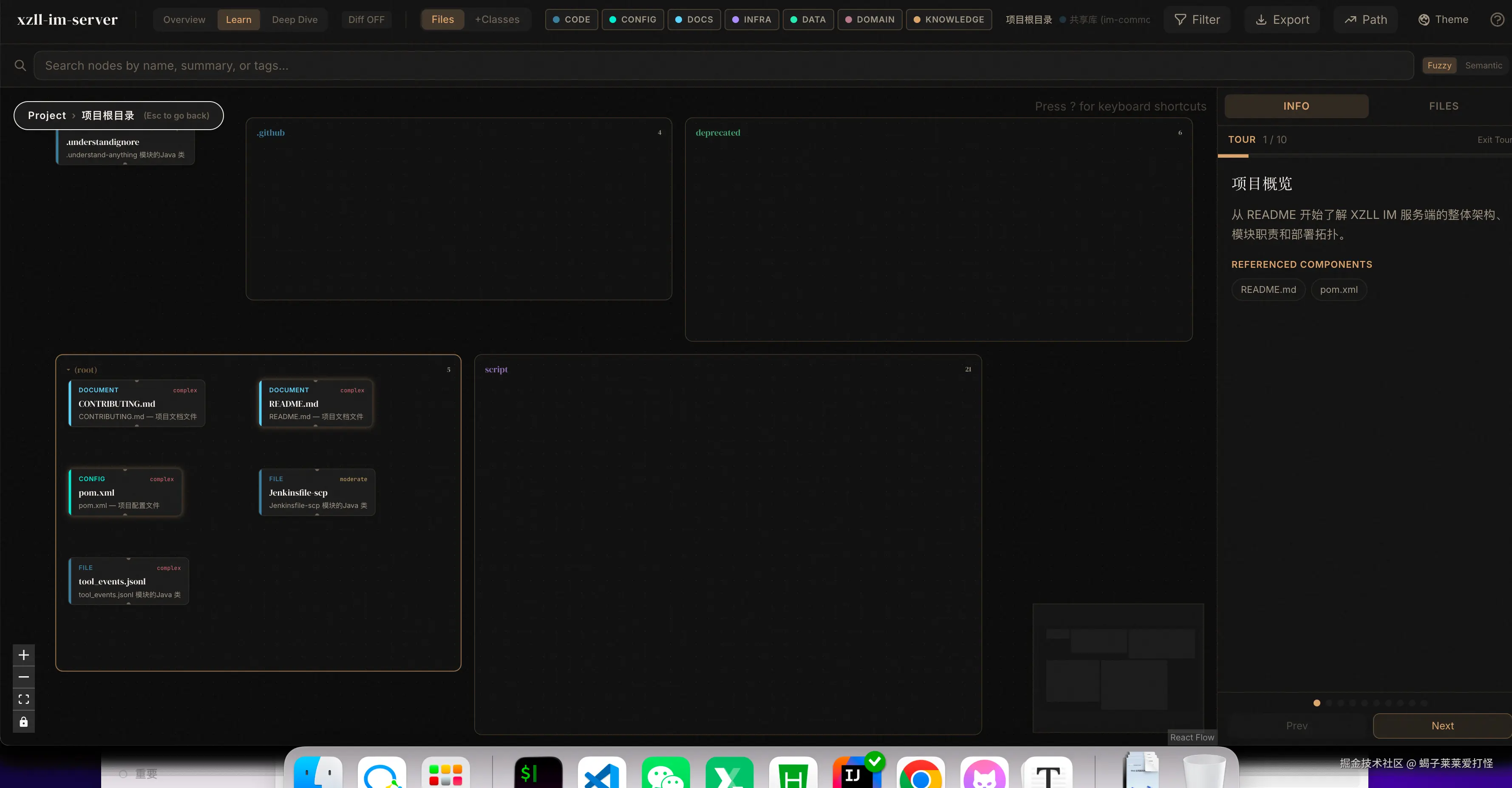
浏览器自动打开,看到的就是一张完整的交互式知识图谱。左边是节点列表(可按类型、层次过滤),中间是关系图(可缩放拖拽),右边是节点详情(摘要、标签、关联)。
我试了几个操作:
-
搜 C2CMsgHandlerStrategy --- 秒出。能看到它被
HandlerDispatcher包含,导入了LocalChannelManager、OfflineMsgServiceImpl等依赖------跟我代码里的策略模式完全对得上。 -
切到架构层次视图 --- 13 层清清楚楚:共享库(104 节点)→ API 网关(37 节点)→ 认证服务(45 节点)→ WebSocket 长连接层(88 节点)→ 核心业务层(143 节点)→ 社交功能(78 节点)→ 数据同步(17 节点)→ 管理后台(102 节点)→ 压力测试 → 基础设施。每一层点进去能看到里面所有文件。
-
看导览路线 --- AI 自动生成了 10 步学习路线,从 README → 共享库 → 网关 → 认证 → 长连接 → 业务逻辑 → 社交 → 数据同步 → 管理后台 → 部署。跟新人的上手顺序基本一致。
跟 codegraph 对比下:
codegraph偏重给 Agent 导航------AI 问我"消息分发在哪",一次工具调用就拿到,省 TokenUnderstand-Anything偏重给人类看全局------浏览器打开一目了然,适合新人 onboarding、架构梳理、团队交接- 两者互补:codegraph 是 Agent 的导航仪,Understand-Anything 是团队的"架构白板"
一句话总结 :如果你需要向新人解释"这个 IM 系统长什么样",与其让他自己看 16 万行代码,不如 /understand 一扫,浏览器打开让他自己点。10 分钟生成的图谱,比我手画的架构图完整 10 倍------因为手画只能画核心模块,这个连每个函数和调用关系都画出来了。
实操 4:agentmemory --- 以后不用每次跟 AI 重新自我介绍了
两步搞定:
bash
npx @agentmemory/agentmemory connect claude-code
npx @agentmemory/agentmemory第一步把 MCP 配置写进 ~/.claude.json,第二步启动引擎。启动后看下状态:
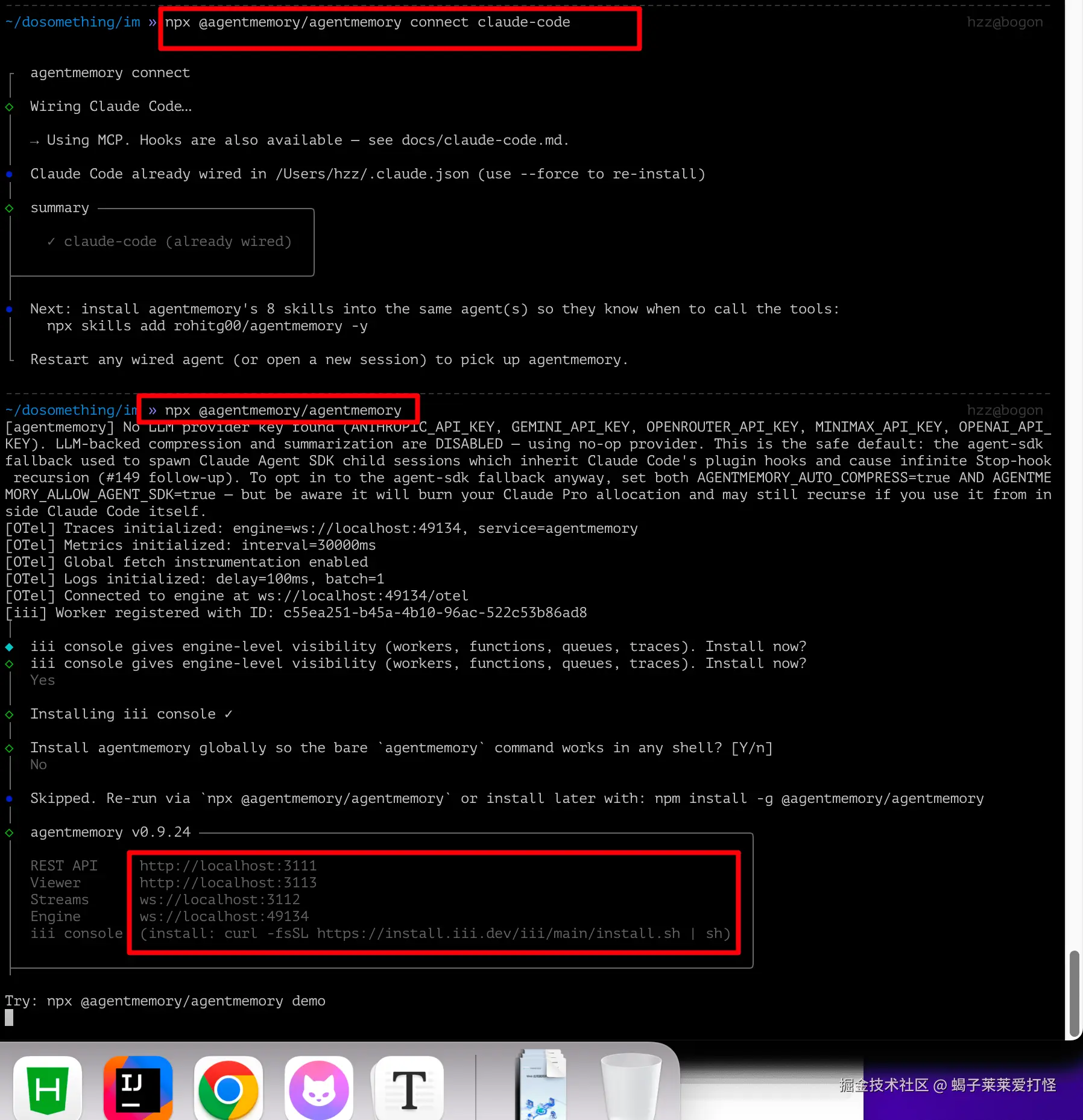
v0.9.24,跑在 localhost:3111。另外 localhost:3113 还有个 Web 面板:
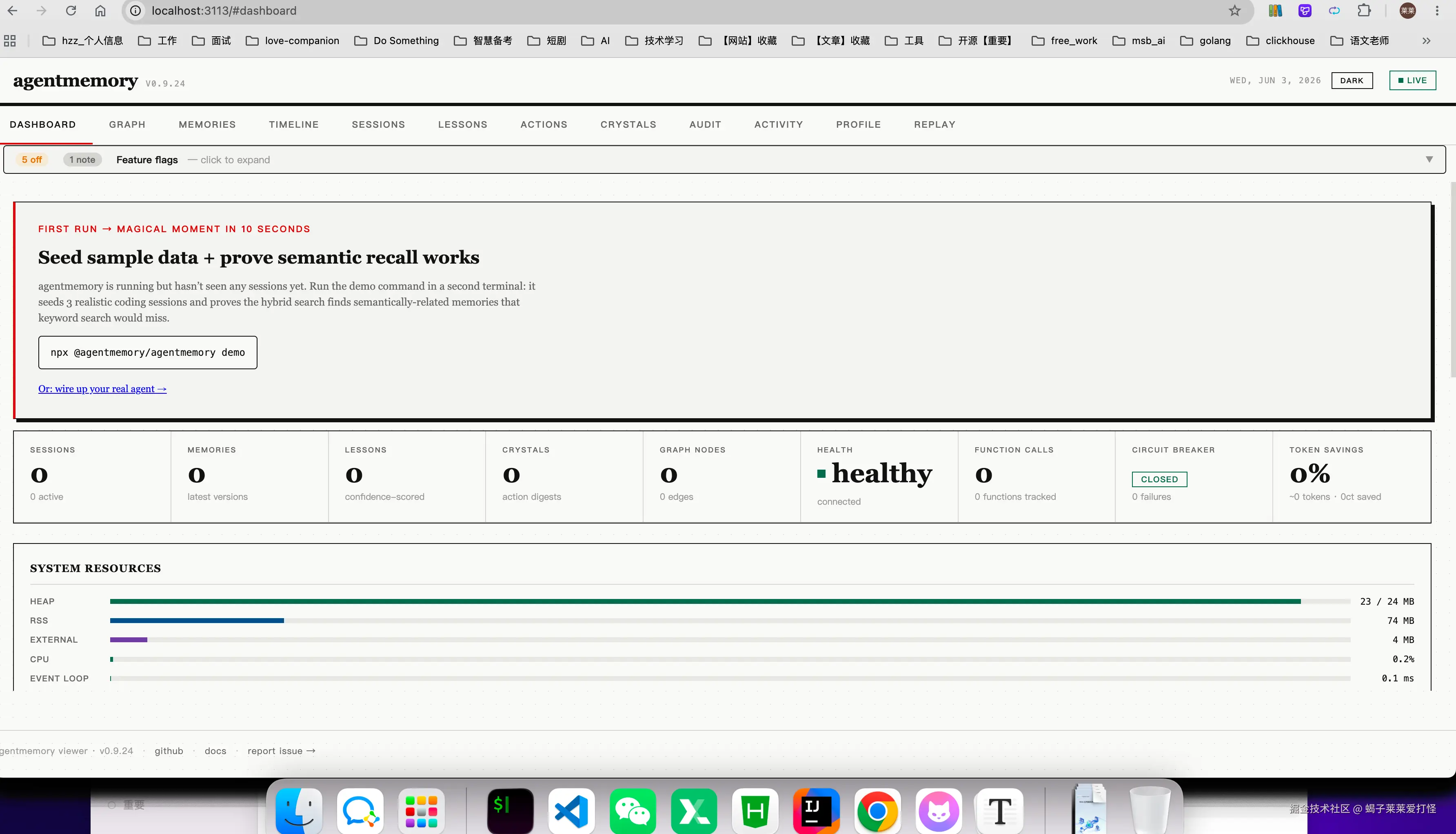
刚启动所以记忆是 0,正常------它是在你用 Claude Code 编码的时候后台静默记录的。用个两三天之后,再开新会话,AI 就自动知道你上次改了什么、做了什么决策,不用你再花五分钟复述一遍了。
比如我让cc分析了下项目,就有记忆了:
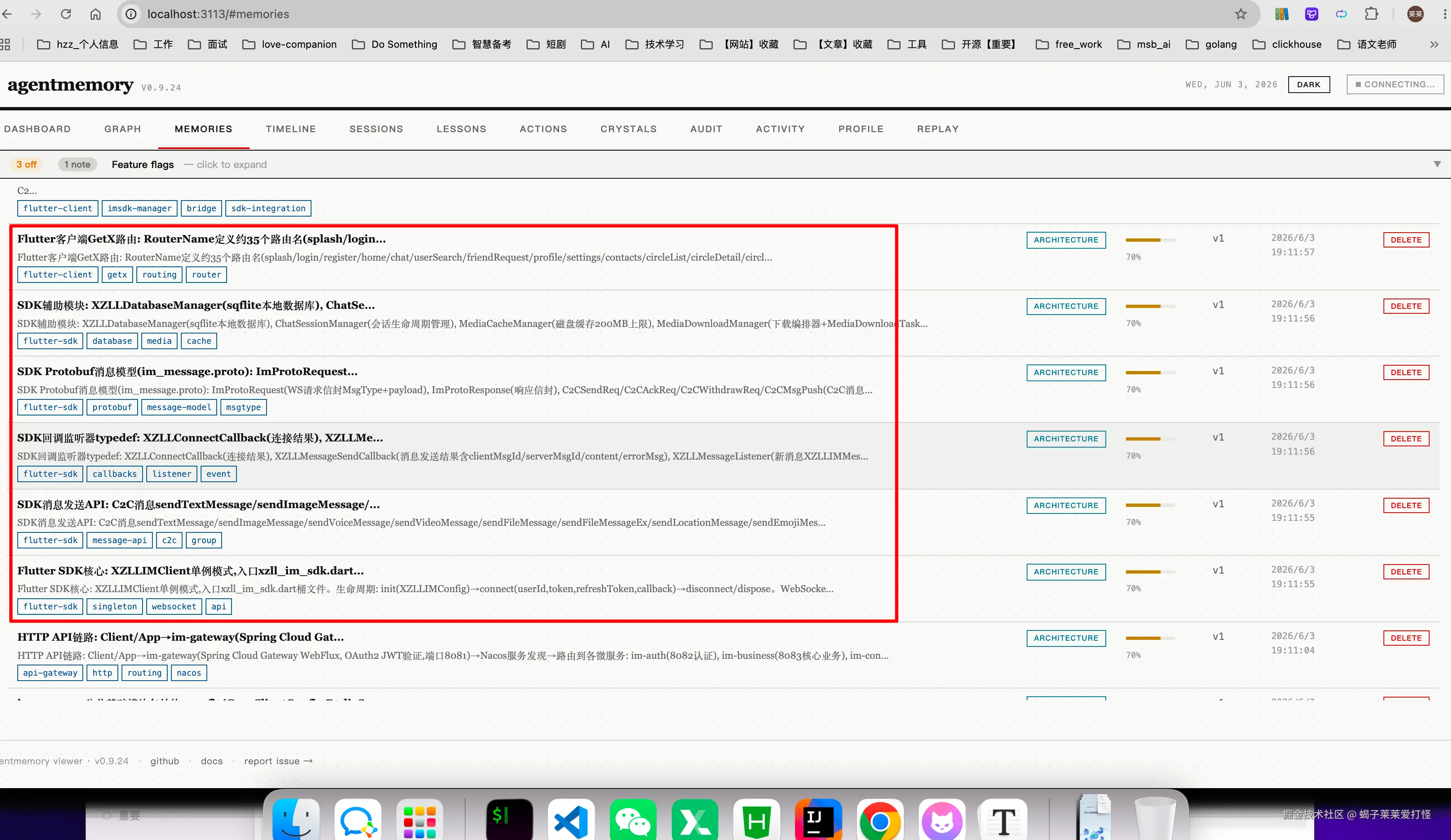
说下我对这个工具的期待:比如我上次会话调了 WebSocket 心跳的超时参数,如果下次开新会话说「继续调连接稳定性」,AI 就能直接接上------不用我再花五分钟告诉它上次改了哪、为什么改、改成啥样了。这正是 agentmemory 要解决的问题。
上面四个是我实际动手跑过的,下面是完整的十个项目详细介绍。每个都会说清楚它是什么、解决什么痛点、怎么用,最后还有横评对比表和避坑指南。
1. skills
🌟 Star 数:115.7K+ (本月 +61.5K)
🧰 一句话:把工程师的「肌肉记忆」变成可版本化的 Skill 包
这是什么?
skills 是 TypeScript 大佬 Matt Pocock 从自己的 .claude 目录里开源出来的工程技能库。它把代码审查、TDD、重构、PR 提交、发布流程等「真工程师每天都在做的事」,做成了一个个独立的 Slash Command,可以直接挂载到 Claude Code 上使用。
解决了什么痛点?
AI 编程代理有四大典型失败模式:需求对不齐 (Agent 理解错了你要什么)、输出冗长 (没有共享术语表导致废话连篇)、代码写完不 work (缺乏反馈闭环,盲飞式编码)、代码变成一团泥 (Agent 加速编码的同时也加速了技术债务)。skills 就是为了解决这些问题而生的。
怎么用?
一条命令安装:npx skills@latest add mattpocock/skills,然后选择你需要的技能和目标 Agent。日常开发中通过 Slash Command 按需调用。
关键技能一览:
-
工程类 :
/grill-with-docs(带文档的深度需求对齐)、/tdd(红绿重构 TDD 循环)、/diagnose(结构化调试)、/improve-codebase-architecture(架构改善)、/to-prd(生成 PRD)、/triage(问题分流)、/zoom-out(全局视角看代码) -
效率类 :
/grill-me(通用盘问式对齐)、/caveman(极简压缩通信模式,省约 75% Token)、/write-a-skill(创建你自己的新技能) -
安全类 :
/git-guardrails-claude-code(危险 git 命令拦截) -
标准化结构 :每个 Skill 独立文件夹 +
SKILL.md,兼容 Agent Skills 开放规范 -
团队可 Fork:按你的语言栈和分支策略改写,直接复用
-
本月增速第一:+61.5K,说明「流程资产化」这个方向踩中了痛点
💡 适合:前端/全栈团队,以及想把 Claude Code 从「个人玩具」升级为「团队基础设施」的技术负责人。
👉 立即探索 :GitHub
2. Understand-Anything
🌟 Star 数:50.6K+ (本月 +39.6K)
🗺️ 一句话:把任何代码仓库变成可交互、可搜索、可提问的知识图谱
这是什么?
Understand-Anything 能对任意代码库进行多智能体分析,自动提取所有文件、函数、类和依赖关系,然后构建一个可交互的知识图谱。你通过一个 Web 可视化面板就能浏览、搜索、点击查看每个节点的自然语言摘要、代码关联和架构分层。
解决了什么痛点?
面对大型陌生代码库无从下手------新加入团队面对 20 万行代码不知从何读起?需要理解业务逻辑与代码的映射关系?这个工具把代码结构可视化为一张可探索的图谱,让你快速掌握全局,而不是盲目逐文件阅读。
怎么用?
- 在 Claude Code 中两行命令安装,然后运行
/understand扫描项目(支持--language zh输出中文) - 运行
/understand-dashboard打开交互式 Web 面板,按架构分层颜色编码 - 其他命令:
/understand-chat(问答)、/understand-diff(变更影响分析)、/understand-explain(深入解释某文件)、/understand-onboard(生成新人上手指南)、/understand-domain(业务领域分析)
关键特性:
- 6 个专职 Agent 协作:项目扫描器、文件分析器、架构分析器、导览构建器、图谱审查器、领域分析器
- Tree-sitter + LLM 混合分析:Tree-sitter 做确定性结构解析(结果稳定),LLM 做语义理解(生成摘要、标签、架构分层)
- 增量更新:默认只重新分析有变更的文件,支持 post-commit 钩子自动更新
- 业务领域视图:切换到 Domain 视图可以看到代码如何映射到真实业务流程
- 差异影响分析:提交代码前可视化变更的连锁影响范围
- 团队共享:图谱就是 JSON 文件,提交到 Git 后队友无需重新分析即可直接使用
- 多语言支持:中文、日文、韩文、俄文等
💡 适合:接手旧项目、理解大工程、做团队交接的开发者。
👉 立即探索 :GitHub
3. codegraph
🌟 Star 数:38.6K+ (本月 +37.1K)
🕸️ 一句话:给编码智能体装上「本地导航」,少读文件少烧 Token
这是什么?
codegraph 通过 tree-sitter 解析源代码,在本地构建一个基于 SQLite 的代码知识图谱(包含符号、调用关系、导入依赖等),然后以 MCP 服务器的形式暴露给 AI 代理。Agent 不再需要反复 grep、find、Read 来定位入口和调用链------图谱就是它的第一检索入口,一次工具调用就拿到符号关系、调用链和代码片段。
解决了什么痛点?
AI 编程助手探索大型代码库时,会不断派生子代理用 grep、glob、Read 逐文件扫描,每次工具调用都消耗大量 Token,既慢又贵。官方基准测试显示:平均降低 25% 成本、57% Token 消耗、62% 工具调用次数、23% 响应时间。
怎么用?
一行命令安装,无需预装 Node.js:codegraph init -i 构建本地索引,重启 AI 代理后自动生效。索引通过操作系统原生文件事件(FSEvents/inotify)自动增量同步,2 秒防抖。
关键特性:
- 20+ 语言支持:TypeScript、Python、Go、Rust、Java、C#、PHP、Ruby、C/C++、Swift、Kotlin、Dart 等
- 14 种 Web 框架路由识别:Django、Flask、FastAPI、Express、NestJS、Laravel、Rails、Spring、Gin、Axum 等
- 跨语言桥接:Swift-ObjC 互操作、React Native 原生桥(Legacy Bridge + TurboModules + Fabric)
- 100% 本地运行:数据不出本机,无需 API 密钥,纯 SQLite 存储
- 零配置:自动识别语言、自动跳过依赖/构建目录、自动遵守 .gitignore
- 多代理支持:Claude Code、Cursor、Codex CLI、Gemini CLI、opencode、Hermes Agent 等
💡 适合:大 monorepo 团队、长会话场景、以及工具调用过多导致又慢又贵的开发者。
👉 立即体验 :GitHub
4. CodeWhale
🌟 Star 数:36.8K+ (本月 +35.4K)
🐋 一句话:Rust 写的终端编码 Agent,「宪法级」治理系统让 DeepSeek 不跑偏
这是什么?
CodeWhale 是一个用 Rust 编写的终端原生编码智能体,核心围绕 DeepSeek V4 和小米 MiMo 模型构建。它不是简单的「终端聊天前端」,而是一套完整的「AI 编码治理系统」------通过一套正式的权威层级「宪法」(Constitution),让模型在复杂编码任务中保持定向、可验证、可回溯。
解决了什么痛点?
传统终端 AI 客户端的问题是模型「闭着眼睛写代码」------没有验证、没有回滚、没有成本控制。CodeWhale 的「宪法」体系规定了信息源的权威层级:用户指令 > 工具输出 > 模型假设,并且要求每个操作必须留下证据,绝不能凭信念宣布成功。
核心设计亮点:
- "宪法"权威层级:七条条款 + 九级信息源排序,模型的行为被正式规则约束,而不是靠「提示词技巧」
- Auto 模式智能路由 :先调用低成本的
deepseek-v4-flash判断任务复杂度,简单问答用 Flash,编码调试自动升级到 Pro + 深度思考 - 前缀缓存驱动的「开卷考试」:宪法虽然冗长,但利用 DeepSeek V4 的前缀缓存,缓存命中后每轮成本仅为冷读的 ~1/100
- 并发子智能体:最多 20 个子 Agent 并行执行,完成后自动注入结果到父级对话流
- Side-Git 快照回滚 :每轮对话自动记录工作区快照,
/restore可回滚到任意状态 - LSP 实时诊断:编辑后自动获取 rust-analyzer、pyright、tsserver 等的类型错误反馈给模型
安装极简:
bash
npm install -g codewhale # 或 brew install deepseek-tui模型定价(DeepSeek V4):
| 模型 | 上下文 | 输入(缓存命中) | 输入(缓存未命中) | 输出 |
|---|---|---|---|---|
| deepseek-v4-pro | 1M | $0.003625/1M | $0.435/1M | $0.87/1M |
| deepseek-v4-flash | 1M | $0.0028/1M | $0.14/1M | $0.28/1M |
💡 适合:想用 DeepSeek 做主力编码 Agent、关注成本和可控性的开发者。特别适合中国大陆开发者------原生支持腾讯云加速、npm 镜像、火山引擎等国产后端。
👉 立即安装 :GitHub
5. andrej-karpathy-skills
🌟 Star 数:166.3K+ (本月 +61.0K)
🎯 一句话:一个 CLAUDE.md 拿 166K Star------Karpathy 把 LLM 编码的三大陷阱写成了四条铁律
这是什么?
Andrej Karpathy(OpenAI 联合创始人、前 Tesla AI 总监)在大量使用 AI 编程工具后,总结了 LLM 在编码时反复犯的三大错误,然后 multica-ai 把这些观察浓缩成了一个 CLAUDE.md 文件------直接放到你的项目根目录,Claude Code 就会自动遵守。
解决了什么痛点?
Karpathy 指出 LLM 编码有三大核心陷阱:
- 自作主张的错误假设:遇到歧义不问,默默选一个解释就闷头干;不暴露困惑,不展示利弊权衡
- 过度工程化与抽象膨胀:给单次使用的代码加抽象层,添加未要求的"灵活性",用 1000 行实现本应 100 行搞定的事
- 误伤无关代码:"顺手"修改或删除与任务无关的代码、注释和格式,造成意外副作用
说实话,这三条每一条我都踩过------特别是第二条,让 Claude 写个接口它能给你搭出三层抽象。
四大原则:
| 原则 | 核心信条 | 解决哪个陷阱 |
|---|---|---|
| Think Before Coding | 不要假设,不要隐藏困惑,暴露权衡 | 错误假设、回避困惑 |
| Simplicity First | 用最少的代码解决,不做投机性设计 | 过度工程化、抽象膨胀 |
| Surgical Changes | 只碰必须碰的,只清理自己造成的混乱 | 误伤无关代码 |
| Goal-Driven Execution | 定义成功标准,循环直到验证通过 | 缺乏验证闭环 |
最值钱的一条规则:
"不要告诉 AI 做什么,给它成功标准,然后看着它干。"
比如把「修复 bug」换成「写一个能复现 bug 的测试,然后让它通过」。LLM 在循环验证方面异常强大,问题在于我们经常给的是模糊指令而不是可验证的目标。
生效后的变化:
- diff 中不必要的变更更少------只出现被要求的修改
- 因过度复杂化导致的重写更少------代码一开始就是简洁的
- 澄清问题在实现之前出现------而不是在犯错之后
💡 适合:所有使用 Claude Code(或任何 AI 编程工具)的开发者。166K Star 不是因为花哨,是因为每条规则都踩在痛点上。建议直接合并到你项目的 CLAUDE.md 里。
👉 立即阅读 :GitHub
6. academic-research-skills
🌟 Star 数:26.5K+ (本月 +22.2K)
📚 一句话:44 个智能体组成的学术论文全流程 Skill 链------从检索到定稿全自动
这是什么?
academic-research-skills 是一套基于 Claude Code 的学术研究技能套件,覆盖从研究选题、文献检索、论文写作、同行评审到最终发表的完整学术流程。核心理念是 「AI 是你的副驾驶,不是驾驶员」------AI 负责查找文献、格式化引用、验证数据、检查逻辑一致性等体力活,你负责定义问题、选择方法、解读数据。
解决了什么痛点?
项目明确针对「AI Scientist」类全自动化研究系统暴露的七大失败模式(实现 bug、伪造实验结果、引用幻觉等),通过人在回路设计来规避。特别解决了 AI 谄媚问题(用户反驳时 AI 过快让步)------引入「让步阈值协议」,只有达到 4 分以上(满分 5 分)才能让步。
关键特性:
- 4 大核心技能、44 个专业智能体:Deep Research(13 个)、Academic Paper(12 个)、Paper Reviewer(7 个)、Academic Pipeline(编排器)
- 完整 10 阶段流水线:研究 → 写作 → 完整性检查 → 5 人评审团 → 苏格拉底辅导 → 修改 → 复审 → 再修改 → 最终检查 → 定稿
- 100% 引用验证:强制关卡不可跳过,Semantic Scholar API 程序化检查
- 5 人评审团:主编 + 3 位审稿人 + Devil's Advocate,0-100 分质量评分
- 反谄媚机制:让步阈值协议、攻击强度保持、框架锁定检测
- 风格校准:从作者过往论文中学习写作风格,避免千篇一律的 AI 文风
- 跨模型验证:可引入 GPT-5.4 Pro 或 Gemini 3.1 Pro 作为独立第二审稿人
- 多格式输出:MD + DOCX + LaTeX(APA 7.0 / IEEE / Chicago)→ PDF
💡 适合:科研工作者、研究生、需要严肃 research workflow 的内容团队。
👉 立即阅读 :GitHub
7. agentmemory
🌟 Star 数:20.8K+ (本月 +18.6K)
🧠 一句话:4 层记忆巩固 + 混合检索,让 AI 编程代理跨会话「记住一切」
这是什么?
agentmemory 是一个为 AI 编程代理设计的持久化记忆引擎。它在后台静默捕获代理每次会话中的工具调用、代码修改、决策偏好等操作,将原始观察压缩为结构化的可搜索记忆,并在下一次会话开始时自动注入最相关的上下文。检索准确率 R@5 达 95.2%。
解决了什么痛点?
AI 编程代理每次会话结束后就「失忆」,用户每次新会话都要花前 5 分钟重新解释项目架构、技术选型、已完成进度。内置的静态记忆文件(如 CLAUDE.md)有行数上限且无法语义搜索,240 条观察就需 22K+ Token。agentmemory 通过混合检索只注入最相关内容(约 1,900 Token),将 Token 消耗降低 92%。
怎么用?
一条命令启动:npx @agentmemory/agentmemory,内存服务器运行在 localhost:3111,实时可视化面板在 localhost:3113。通过 agentmemory connect claude-code 自动将 MCP 服务器接入对应的编程代理。
关键特性:
- 4 层记忆巩固(模拟人脑遗忘曲线):工作记忆 → 情景记忆 → 语义记忆 → 程序记忆,高频访问的记忆自动强化,过期记忆自动淘汰
- 混合语义搜索:BM25 关键词 + 向量余弦相似度 + 知识图谱遍历,RRF 融合排序
- 53 个 MCP 工具 + 12 个自动 Hook + 8 个原生 Skill:零手动操作
- 隐私优先:存储前自动剥离 API 密钥、密码等敏感信息
- 跨代理共享:一个服务器为 Claude Code、Cursor、Copilot 等 30+ 种代理提供共享记忆
- 知识图谱:实体抽取 + BFS 遍历 + 图可视化
- Git 快照:版本化、回滚、差异对比记忆状态
- 无外部依赖:纯 SQLite + 内存向量索引,本地嵌入模型(all-MiniLM-L6-v2)免费离线运行
💡 适合:项目周期长、强依赖「上次怎么改的」这类上下文的团队。
👉 立即安装 :GitHub
8. RuView
🌟 Star 数:70.3K+ (本月 +19.4K)
📡 一句话:用 WiFi 信号「看穿」一切------零摄像头的空间感知黑科技
这是什么?
RuView 是这个月榜单上最让我兴奋的项目------它把普通 WiFi 信号变成了空间感知工具。不需要任何摄像头,通过分析 WiFi 无线电波遇到人体后的散射模式(Channel State Information,CSI),就能实现人体姿态估计、呼吸心率监测、跌倒检测、睡眠分析等功能。你的 WiFi 路由器就是雷达。
为什么选它?
这是我跟其他榜单最大的差异项------大多数人看到「WiFi 感知」会觉得是噱头,但这个项目有 70K+ Star、MIT 开源、884 次提交、1463 个测试用例通过,而且硬件成本最低 9 美元(一个 ESP32-S3)。它代表了一个完全不同的技术路线:不依赖视觉,而是利用已经无处不在的无线信号。
核心能力:
| 功能 | 实现方式 | 性能 |
|---|---|---|
| 呼吸频率监测 | CSI 相位带通滤波 + 过零点检测 | 6-30 BPM,实时 |
| 心率监测 | 0.8-2.0 Hz 带通滤波 | 40-120 BPM,实时 |
| 人体姿态估计 | 17 关键点,MM-Fi 基准 82.69% PCK@20 | 树莓派冷启动 8.4ms |
| 跌倒检测 | 相位加速度阈值 + 防抖 | < 200ms |
| 穿墙感知 | 菲涅尔区几何 + 多径建模 | 最远约 5 米 |
| 睡眠质量分析 | 整夜监测 + 睡眠阶段分类 + 呼吸暂停筛查 | 无穿戴、无接触 |
隐私优势对比传统摄像头方案:
| 维度 | WiFi 感知 | 摄像头 |
|---|---|---|
| 隐私合规 | 无视频,不受 GDPR/HIPAA 影像法规约束 | 需告知同意、标识、数据保留策略 |
| 穿墙能力 | 可穿透墙壁、货架 | 每个房间都需要视线 |
| 低光环境 | 完全黑暗中正常工作 | 需要 IR 补光 |
| 成本 | 每区域 0-8 美元 | 每区域 200-2000 美元 |
硬件门槛极低:
- Docker 模拟(0 成本体验):
docker run -p 3000:3000 ruvnet/wifi-densepose:latest - ESP32-S3 实时感知:约 9 美元
- 完整系统:约 54-140 美元
- 支持树莓派、Home Assistant、Apple Home、Google Home、Alexa
💡 适合:IoT/智能家居开发者、关注隐私合规的技术决策者、对「非视觉感知」感兴趣的研究者。哪怕你只是好奇 WiFi 信号还能这么玩,也值得 Star。
👉 立即探索 :GitHub
9. MoneyPrinterTurbo
🌟 Star 数:78.4K+ (本月 +21.5K)
🎬 一句话:输入主题,从脚本到成片全自动------短视频创作者的「印钞机」
这是什么?
MoneyPrinterTurbo 是一个全自动短视频生成工具:你只需提供一个视频主题或关键词,系统自动完成文案撰写、视频素材匹配、字幕生成、背景音乐添加,最终合成一条高清短视频。总 Star 接近 78K,是「内容自动化」赛道里经过长期社区验证的最成熟工具。
解决了什么痛点?
普通人制作短视频需要同时具备文案写作、素材搜集、剪辑合成等多项技能,门槛高且耗时。这个项目把整个流程自动化了,从「想法」到「成片」一键搞定。
怎么用?
三种使用方式:Web 界面(StreamUI,浏览器直接操作,适合非技术用户)、API 接口(适合开发者集成)、Docker 一键部署。也有 Windows 一键启动包和 Google Colab 在线体验版。
关键特性:
- 完整 MVC 架构:同时支持 Web UI 和 API 两种使用方式
- 双尺寸高清输出:竖屏 9:16(1080x1920)和横屏 16:9(1920x1080)
- 批量生成:一次生成多个版本供选择
- 多种 TTS 语音合成:含 Azure TTS,支持中英文,可实时试听
- 多 LLM 接入:OpenAI、DeepSeek、Moonshot、通义千问、Gemini、Ollama 等十余种
- 无版权素材:来自 Pexels 等高清图库,也支持本地素材
💡 适合:短视频创作者、运营团队、需要快速试错内容选题的 AIGC 实验者。
👉 立即体验 :GitHub
10. ai-engineering-from-scratch
🌟 Star 数:27.6K+ (本月 +21.2K)
🧱 一句话:503 节课、20 个阶段、320 小时------从线性代数到自主 Agent 集群的完整 AI 工程课程
这是什么?
一套名为「AI Engineering from Scratch」的开源 AI 工程课程体系,覆盖 Python、TypeScript、Rust、Julia 四种语言。核心理念是「从零手写每一个算法」------从线性代数和反向传播开始,一直到构建自主 Agent 集群和上线生产系统。每个算法都先从原始数学推导手写实现,再用 PyTorch 等生产框架跑一遍。
解决了什么痛点?
当前 AI 学习资料碎片化严重,很多人能调 API 写聊天机器人,但说不清 loss 曲线背后发生了什么、注意力机制内部在做什么。这个课程提供了「一条从底层数学到上层应用的完整脊柱」,填补了 84% 学生使用 AI 工具却只有 18% 觉得自己具备专业能力之间的鸿沟。
怎么用?
在 Claude、Cursor 等支持该课程 Skills 的 AI 工具中运行 /find-your-level,通过 10 道题定位你的知识水平,生成个性化学习路径和时长估算。每学完一个阶段用 /check-understanding 测验掌握程度。每节课都会产出一个可复用的 prompt、skill、agent 或 MCP Server。
课程 20 个阶段一览:
- Phase 0-3:环境搭建 → 数学基础(线代/微积分/概率)→ 经典 ML(SVM/随机森林)→ 深度学习核心(感知机/反向传播)
- Phase 4-8:计算机视觉(CNN/YOLO/GAN/Diffusion)→ NLP(词嵌入/注意力/RAG)→ 语音(ASR/TTS/Whisper)→ Transformer 深度解析(MoE/Flash Attention)→ 生成式 AI(Stable Diffusion/Flow Matching)
- Phase 9-12:强化学习(PPO/RLHF)→ 从零构建 LLM(分词器/预训练/SFT/量化/DeepSeek-V3)→ LLM 工程化(RAG/LoRA/MCP)→ 多模态(CLIP/LLaVA)
- Phase 13-16:工具与协议(MCP/A2A)→ Agent 工程(Agent Loop/记忆系统)→ 自主系统(自我改进/Kill Switch)→ 多 Agent 与集群(共识/群体智能)
- Phase 17-19:基础设施与生产(vLLM/K8s/FinOps)→ 伦理与安全(红队测试/水印/隐私)→ 毕业项目(17 个端到端产品 + 9 条深度构建路线)
💡 适合:希望系统补齐 AI 工程化能力、从「调 API」走向「造产品」的开发者。
👉 立即阅读 :GitHub
🔍 横评:codegraph vs Understand-Anything vs agentmemory
这三个项目都跟「让 AI 更好地理解代码」有关,但定位完全不同。一张表说清楚:
| 维度 | codegraph |
Understand-Anything |
agentmemory |
|---|---|---|---|
| 核心定位 | Agent 的本地代码导航 | 人的代码知识图谱 | Agent 的跨会话记忆 |
| 服务对象 | AI 代理 | 开发者 + AI 代理 | AI 代理 |
| 数据来源 | tree-sitter 解析源码 | tree-sitter + LLM 分析 | 会话中的工具调用/修改/决策 |
| 存储方式 | 本地 SQLite | JSON(可 Git 提交) | SQLite + 内存向量索引 |
| 检索方式 | 符号/调用链/依赖 | 可视化图谱 + 语义搜索 | BM25 + 向量 + 知识图谱 |
| Token 节省 | -57% Token、-62% 工具调用 | 依赖使用方式 | -92% 上下文 Token |
| 是否需要 LLM | 不需要(纯 tree-sitter) | 需要(生成摘要和分层) | 不需要(本地嵌入模型) |
| 硬件要求 | 零外部依赖 | 需要调 LLM API | 本地运行,无外部依赖 |
| MCP 协议 | 是 | 是 | 是 |
| 最适合场景 | 大 monorepo 的 Agent 导航 | 团队交接、新人上手 | 长周期项目的上下文保持 |
我的选择 :三个我都在用------codegraph 做日常编码导航(最省 Token),Understand-Anything 做新人 onboarding 和架构梳理,agentmemory 解决跨会话失忆问题。它们是互补关系,不是竞争关系。
🧰 开发者工具箱:终极 Claude Code 环境搭建方案
如果你想把 Claude Code 从「偶尔用用的玩具」变成「日常开发的核心工具」,这是我实测有效的组合方案:
基础层(必装):
bash
codegraph init -i # 本地代码图谱,省 57% Token
npx @agentmemory/agentmemory # 跨会话记忆,告别每次从零开始技能层(按需选装):
bash
npx skills@latest add mattpocock/skills # 工程技能包(TDD、调试、架构等)纪律层(强烈推荐):
把 andrej-karpathy-skills 的 CLAUDE.md 内容合并到你项目的 CLAUDE.md 中------四条原则就够用,让 AI 从「自作主张」变成「先问后做」。
场景层(特定需求):
- 学术写作:克隆
academic-research-skills到.claude/skills/ - 代码理解:运行
/understand生成项目知识图谱
成本参考(按每天 2 小时编码):
| 工具 | 月成本 | 省下的 |
|---|---|---|
| codegraph | 免费 | ~$30/月(Token 节省) |
| agentmemory | 免费 | ~$50/月(重复上下文节省) |
| skills | 免费 | 无法量化(工程纪律提升) |
| CodeWhale + DeepSeek V4 | ~$10-30/月 | 替代 Claude API 省 50%+ |
API 成本层(如果不想绑外币卡):
上面四个层装完,工具是齐了,但工具背后都在烧 API Token------特别是 Understand-Anything 和 agentmemory,一个跑一次分析几百个文件,一个每天都在后台调 LLM。如果你跟我一样不想绑外币卡,可以看看微元算力
简单说就是一个 OpenAI 兼容的国内 API ,300+ 模型,国内直连,人民币充值。改个 URL 就能用:
json
// Claude Code --- ~/.claude/settings.json
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.weiyuansuanli.xyz",
"ANTHROPIC_AUTH_TOKEN": "sk-你的Key"
}
}价格是官方的三成左右,对比一下:
| 模型 | 官方价(¥/百万token) | 微元算力(¥/百万token) | 大约省多少 |
|---|---|---|---|
| claude-opus-4-7 输入 | ¥36.5 | ¥10.5 | ~71% |
| claude-opus-4-7 输出 | ¥182.5 | ¥52.5 | ~71% |
| claude-sonnet-4-6 输入 | ¥21.9 | ¥6.3 | ~71% |
| gpt-5.4 输入 | ¥14.6 | ¥2.0 | ~86% |
| deepseek-v4-flash 输入 | ¥3.6 | ¥0.525 | ~85% |
算笔账:我每天用 Claude Code 编码 2-3 小时,之前直连 Anthropic 一个月大概 ¥800-1200,切过来之后 ¥250-350 搞定。缓存读取只要输入价的十分之一,Claude Code 那种长系统提示词的场景,缓存命中后成本降一个数量级。
支持的工具也全------Claude Code、Codex CLI、Cursor、Gemini CLI、Python OpenAI SDK 都能用,改个 base_url 完事。充值支付宝微信都行,余额不过期。
还有个企业中心功能,适合小团队:给每个人设额度上限、限制可用模型(实习生只能用 Haiku,不会手滑跑 Opus 跑出几百块)、人走了一键禁用。比五六个人共用一把 Key 靠猜要好。
我自己的体感:用了三周,Claude 系列调用很稳,没遇到过长时间不可用。后台有数据看板,余额、调用次数、Token 消耗明细一目了然,花钱花得明明白白。如果你每天都要跟 AI 编程工具打交道,这个成本层装上之后,其他几层工具用起来心里更有底------不用担心月底账单爆。
🔗 官网:weiyuansuanli.xyz
一句话:karpathy-skills 管纪律,codegraph 管导航,agentmemory 管记忆,CodeWhale 管执行,微元算力管成本------五层一装,你的 AI 编程环境从工具到基础设施就完整了。
⚠️ 避坑指南:这些项目实际用起来要注意什么
看 Star 数很爽,但真正用的时候有几个坑值得提前知道:
1. skills:不要一口气全装
Matt Pocock 的技能库有十几个 Skill,但每个都会往你的 .claude 目录塞东西。建议只装你实际用到的 2-3 个,否则 CLAUDE.md 会变得又长又乱,反而拖慢 Agent。
2. codegraph:首次索引大项目需要耐心
20 万行 Java 项目首次索引大概需要 2-3 分钟,期间 CPU 占用不低。索引完后续是增量的,但第一次别在赶 deadline 的时候跑。
3. Understand-Anything:LLM 调用成本不低
因为它用 LLM 做语义分析(生成摘要、架构分层),大型项目跑一次可能消耗不少 Token。建议在非高峰时段运行,或者先在小项目上试水。
4. CodeWhale:YOLO 模式慎用
--mode yolo 会自动批准所有工具调用,包括文件删除和 git 操作。只在确认安全的工作区里用,否则一个 typo 可能让你回不了头。Side-Git 快照是你的安全网,但最好还是养成 Plan 模式先看方案的习惯。
5. RuView:Beta 状态,别上生产
项目明确标注 Beta,单 ESP32 空间分辨率有限,无摄像头姿态精度约 2.5%(有摄像头辅助训练目标 35%+)。先当学习项目玩,别直接往智能家居产品里集成。
6. andrej-karpathy-skills:注意和你现有规则冲突
四条原则很好,但直接把整个 CLAUDE.md 塞进去可能和你项目已有的规则冲突。我自己的做法是直接放原文,因为我的 CLAUDE.md 里没有重复的条目。如果你项目里已经有类似的编码规范,建议对比一下再决定是追加还是替换。
7. agentmemory:敏感信息注意
虽然它会自动剥离 API 密钥,但建议还是在隐私敏感项目上手动确认一下。记忆数据库是本地的 SQLite,不会外传,但如果你在多台机器上工作,注意不要把记忆库提交到 Git。
写在最后
回顾 5 月的十个项目,我读出了 三条主线:
-
「驾驭 AI」取代「使用 AI」 :
andrej-karpathy-skills用四条铁律约束 AI 编码行为(166K Star)、skills把工程动作变成可复用的技能包(+61.5K)、CodeWhale用宪法治理系统让 DeepSeek 不跑偏、academic-research-skills用反谄媚机制防止 AI 过快妥协------核心思路一样:AI 越强,越需要正式的约束机制,否则就是一个没有刹车的大马力引擎。 -
上下文工程是新赛道 :
codegraph降 57% Token、agentmemory降 92% Token、Understand-Anything把代码变成可探索的图谱------省 Token 已经是一门生意。对于每天跟 AI 代理打交道的开发者来说,这三者是互补的,不是互斥的。 -
非主流方向的黑马 :
RuView用 WiFi 信号做空间感知(70K Star)、MoneyPrinterTurbo全自动短视频生成(78K Star)------说明开源社区的想象力远不止「让 AI 写代码」。
未入选但值得关注的项目:financial-services(Anthropic 官方金融行业 Agent 工具集,29K+ Star,适合想学习行业插件搭建的架构师)、UI-TARS-desktop(字节跳动的多模态 AI Agent 桌面端,35K+ Star)、easy-vibe(Datawhale 出品的 Vibe Coding 入门教程,15K+ Star)、9router(免费 AI 编程代理路由,因合规风险未纳入推荐)。
📌 觉得有帮助的话,给喜欢的项目点个 Star 吧------每一次微小的参与,都是开源社区前进的动力。
📬 我是蝎子莱莱爱打怪,专注全栈开发、AI编程实战、AI前沿知识、AI落地和开源项目深度测评,欢迎关注我,每月带你挑出 GitHub 上最值得装的工具。如果你有心中的 6 月黑马项目,评论区告诉我~
往期精选: