最近一直在用OpenClaw,由于 token 费用较高,以及对模型效果追求,想在Claude、GPT-5这类顶级模型,和国内性价比高的模型之间无缝自由切换,找到了一些专门做大模型聚合中转的服务商。
但是,最近一篇来自CISPA亥姆霍兹信息安全中心的研究论文指出,你用的模型,可能不是供应商声称的那个模型。
这不是偶然现象。当你以为找到了一个「物美价廉」的解决方案时,可能正在踏入一个精心设计的骗局。
Shadow API:影子API,第三方LLM API服务,声称提供官方模型访问但实际可能替换模型,因其底层模型的不透明,又是API方式向用户提供服务,故称为 Shadow API。

01、中转API的经济学:三种骗钱套路
Shadow API提供商的商业模式,本质上是利用信息不对称赚钱。研究员们总结出了三种典型的经济欺骗机制,每一种都精准击中了用户的痛点。
第一种叫「信息溢价方案」。提供商收取溢价费率,但悄悄地用类似或更新年份的更便宜替代品替换更有能力的模型。
比如,某个API声称提供Gemini-2.0-flash,但实际上交付的是Gemini-2.5-flash,价格比率却是7.1--7.25倍。用户以为自己用了旧版本但价格便宜,其实是用了更高版本但付了更多钱。
第二种叫「折扣替换方案」。提供商按官方费率收费,但用低成本开源后端替换高级模型。
比如,某个中转平台声称按平价提供GPT-5,但通过LLMmap指纹识别,实际后端是GLM-4-9B。这就像你花了正品的钱,买到的是高仿A货,卖家还按正品价格收费。
第三种叫「转售加价方案」。提供商施加适度的附加费,但仍然悄悄地替换底层模型。
比如,某个API对GPT-5收取1.09倍官方费率,看起来只加了一点价,但实际交付的是降级的后端。这就像代购说只收9%的服务费,但给你寄的是山寨货。
研究员们算了一笔具体的账。用官方价格分析GPQA上的GPT-5查询(1273次查询),某个Shadow API按官方费率收费(价格比率=1.00×),但只交付了官方输出量的38%。
用户按官方费率支付了14.84美元 (1273次查询),但只收到实际令牌量价值5.70到7.77美元 的输出。也就是说,每1273次查询,提供商就能赚7.07到9.14美元。
相对于任务准确率归一化,和官方端点比,Shadow API每实际交付一美元价值,产生的错误是2-4倍。
这意味着,你不仅花了冤枉钱,还得到了更差的结果。
02、黑箱里的秘密
Shadow API 不是凭空出现的。它们背后有一套成熟的开源基础设施系统。
论文的研究发现,17个Shadow API服务中,11个建立在开源AI模型聚合和再分发系统之上,主要是 OneAPI 及其衍生产品 NewAPI。
OneAPI 是一个为自托管部署设计的开源工具,它把来自各种商业LLM提供商的接口统一成标准的OpenAI兼容格式。
这个系统支持API密钥管理、二次再分发、请求路由和自动重试等关键功能。听起来很美好对吧?
这些功能确实让用户用起来更方便了,但同时也大大增加了被利用、转售和滥用的可能性。
因为这些功能,请求不再直接从用户到官方API,而是经过了多层路由。你根本不知道你的请求去了哪里,有没有被篡改,甚至,你调用的到底是不是你以为的那个模型。
更可怕的是合规性和透明度问题。
为了评估Shadow API的合规状态,安全中心检查了关于提供商身份、公司注册和服务相关披露的公开信息。
结果发现,已识别的17个服务中有15个由个人运营,没有透明的身份信息,也没有可验证的来源。
只有一个提供商通过中国的互联网内容提供商备案持有有效的公司注册。
这意味着大多数Shadow API在没有有效合规验证或治理保障的情况下运作。
提供商生态系统表现出高运营波动性,两个服务已经停止运营。而且,所有提供商频繁更改上游模型来源,而没有向用户提供关于这些更改的详细或透明通知。
这就像你从一个没有营业执照、没有固定摊位的流动小贩手里买东西。今天他还在这儿,明天可能就不见了。
你今天买的是这个,明天可能就换成了那个。出了问题,你连找谁都不知道。而一旦出了问题,影响的不只是你一个人。
03、除了准确率,还有什么能揭穿骗局?
性能下降只是表象。怎么才能确定你用的模型被掉包了?这时候,除了看准确率,还有更多维度可以验证。
首先是模型指纹识别技术,也就是LLMmap。通过精心设计的查询,分析模型的「说话方式」,就能准确识别出背后到底是哪个模型。
什么是LLMmap?这是一种新颖的精确高效 LLM 指纹识别方法:通过向目标应用发送事先构造号的查询,并分析大模型的响应,以最少的交互------通常在3~8次查询之间就能准确识别底层LLM版本。
LLMmap 设计有任意系统提示、随机采用程序、超参数的系统,以及采用检索增强生成(RAG)或者思维链提示(Co T)等高级框架的系统。感兴趣的可以看文末的论文原文。
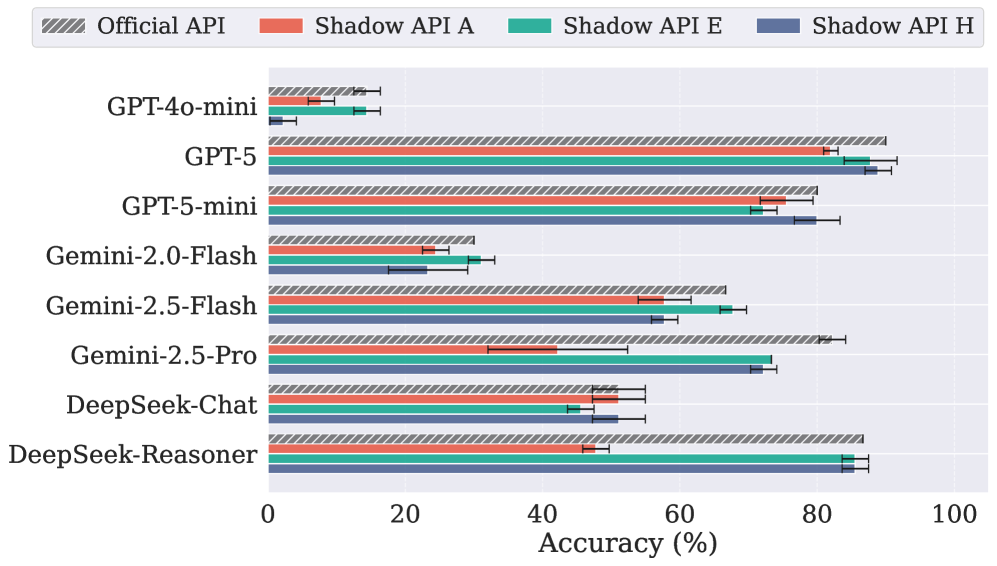
(a)AIME 2025
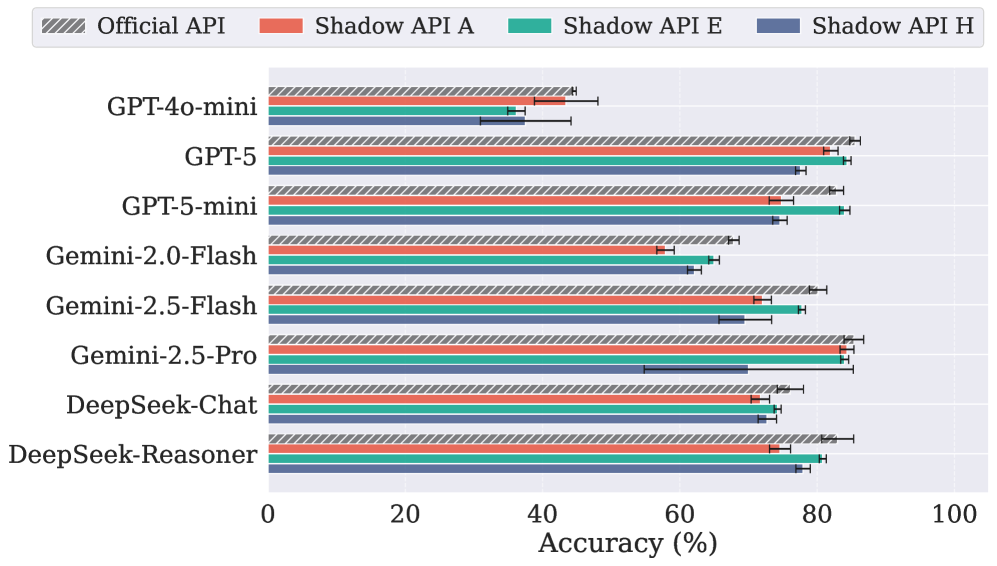
(b)GPQA (Diamond)
官方API 和 Shadow API在(a)AIME 2025和(b)GPQA基准测试上的性能对比。
用这个工具,研究员们去查那24个Shadow API端点 。结果发现:45.83%的端点没能通过指纹验证,另外12.50%表现出与官方模型的显著偏差。
但LLMmap不是唯一的方法。研究员们还用了另一种方法叫MET(模型相等性测试),这是一种统计检验,看看Shadow API的输出和官方模型是不是来自同一个分布。
具体来说,MET执行两样本假设检验:当分布相等的零假设被拒绝时,Shadow API的输出在统计上与官方模型的输出可区分,提供身份不一致性的独立证据。
两种方法在74.1%的案例中达成一致,Cohen's κ=0.512,表明这两种独立方法之间存在中度到实质性的一致性。
还有更简单的方法,不需要复杂的机器学习技术------看推理延迟和令牌计数。
官方API对于相同问题通常表现出一致的推理延迟和令牌计数,而Shadow API表现出不规则的尖峰。标准差分析证实了这种不稳定性,揭示Shadow API经常表现出甚至超过官方2.0倍的波动性。
这就像人的心跳。健康的人心跳是规律的,虽然会有变化,但总体稳定。如果心跳突然变得忽快忽慢,没有规律,那可能就是出问题了。
模型也是一样。对同一个问题,官方模型的推理时间和输出长度应该是相对稳定的。如果忽长忽短,波动很大,那很可能后端在不停地切换模型。
研究员们还做了一个联合分析,看看模型身份如何与观察到的性能偏差相关联。
在某些情况下,匹配的模型身份与一致的行为相吻合。比如,当模型身份匹配并且行为保持稳定时,Shadow API可以表现得与官方端点密切。
相反,当模型身份不匹配时,行为通常相应地下降。在推理评估期间,身份不匹配与推理崩溃强烈相关。
比如,当某个Shadow API提供的DeepSeek-Reasoner指纹识别为DeepSeek-Chat时,它的AIME 2025准确率显著下降。
但这种一致性在Shadow API之间不稳定。模型替换并不总是表现为立即可见的性能下降。同样,匹配的模型身份也不保证忠实的行为。
比如,Gemini-2.5-flash就说明了这一点。在某些Shadow API中,指纹识别匹配声称的模型系列,余弦距离接近官方API,然而敏感领域的准确率急剧下降。
这表明仅凭身份检查不能确保行为一致性。
那么,知道了这些,我们该怎么办?
04、当研究变成赌博:可复现性危机
Shadow API的问题,不只是骗点钱那么简单。它对整个科学研究体系的冲击,可能才是最深远的。
论文的建议很直接:Shadow API根本就不应该被用于任何研究工作流。基本解决方案是直接使用官方API。
如果必须使用,需要先走一套严格的验证流程:用LLMmap测模型指纹、用统计检验看输出分布、多次测试看稳定性、验证服务商资质。这四步里有任何一步不达标,就不能用。
对于研究者,论文还建议做预注册。任何依赖LLM API查询的研究,在收集数据之前就要完整记录:用了哪个API、声称是什么模型、什么时候用的、价格是多少,都要明明白白写出来。
而且在做实验之前,要确认这个API通过了验证。最后,至少要报告三次独立测试的结果,让读者和审稿人能判断这个后端靠不靠谱。
除了个人实践,论文还呼吁更广泛的研究社区采用结构性保障。
会议组织者和程序主席应更新审稿人指南,将未披露或未验证的第三方API端点标记为可复现性风险,类似于未验证的数据集来源那样处理这种使用。
官方模型提供商可以通过放松地理访问限制、提供学术定价层以及提供研究人员可以查询以独立确认模型身份的轻量级官方验证端点来进一步减少影子市场需求。
但在那之前,我们每个人都要面对一个现实:当我们使用Shadow API时,我们的研究可能从一开始就建立在沙子上。
研究员们算了一笔总体研究成本。数据集涵盖187篇依赖通过Shadow API提供商的基于LLM的管道的论文。
保守地假设这些论文中的30% 在检测到身份不一致性时需要重新执行(n≈56,相对于经验观察到的45.83% 指纹失败率的下限),总体直接成本,包括API重新运行(每篇论文50--500美元 )和研究人员时间(约40小时 ×50美元/小时 =每篇论文2,000美元 ),范围从115,000美元到140,000美元。
这还不算下游5,966次引用的可复现性成本,其中静默模型替换可能在没有任何可见错误信号的情况下静默地破坏相关实验结果。
这意味着,整个学术社区可能在不知不觉中,基于不可靠的结果,构建了一个巨大的空中楼阁。
最后
在《三国演义》里,诸葛亮唱过一出空城计。城门大开,自己在城楼上弹琴,司马懿以为有埋伏,就退兵了。
但那是小说。在真实的科研世界里,我们不能玩空城计。我们的结论必须建立在坚实的基础之上。
在这个AI的时代,「知彼」和「知己」同样重要。我们不仅要知道怎么用AI,还要知道我们用的到底是谁。
LLMmap给了我们一个工具,让我们能够识破「假脑子」。但更重要的是,它提醒我们------信任是宝贵的,不能轻易交给来路不明的东西。
毕竟,你不会随便吃一个陌生人给你的药。同样,你也不应该随便用一个来路不明的AI。
最后,如果朋友们对国外模型不是刚性需求,购买国内大模型、云计算厂家的Code Plan 方案也是一个不错的选择:模型能力跟顶尖模型相差无几,价格也更亲民。
国内大模型(如MiniMax、智谱、通义千问等)的价格大约是国外顶尖模型(如OpenAI的GPT系列、Claude、Gemini等)的 1/10至1/20,也合适日常工作生活中使用 OpenClaw 的养虾人。
参考资料:
-
- "真金白银,虚假模型:Shadow API中的欺骗性模型声称",USENIX Security 2025 :https://arxiv.org/html/2603.01919v2
-
- "LLMmap:大型语言模型的指纹识别技术",USENIX Security 2025:https://arxiv.org/html/2407.15847v4
阅读推荐: