STL中根据模板语法实现了各种数据结构,方便直接使用,不需要自己手动实现。
01 vector
1. vector的定义与声明
在 C++ 中,vector 是一个动态数组容器 ,可以存储一系列相同类型 的元素。它是标准库<vector>中定义的模板类 。声明 vector 对象:std::vector
这里的 T 是要存储在 vector 中的元素类型(如 int、char、double、vector 等,甚至可嵌套声明二维数组(vector<vector<int>>))。
2. vector的特性
<1> 容器大小
自动调整:根据元素数量动态分配内存空间,自动维护容量变化
<2> 元素访问
- 索引访问: 通过索引访问元素(从0开始),最后一个元素索引为size()-1
- 访问方式: 可使用\[\]运算符或at()函数,at()会进行越界异常处理
注意: 使用size()返回的是unsigned int类型,若数组为空,size()-1会得到极大正数。建议循环时使用 i<size() 而非i<=size()-1,或者size()-1前强制转换为int
<3> 元素添加和删除
末尾操作:
- push_back(): 末尾添加元素(自动扩容)
- pop_back(): 删除末尾元素(需确保vector非空)
指定位置操作:
- insert(): 在指定位置插入元素(后续元素后移)
- erase(): 删除指定位置或区间的元素
大小维护: 所有增删操作都会自动维护vector的大小
<4> 容器大小管理
查询函数:
- size(): 获取元素数量
- empty(): 检查是否为空
调整函数:
- resize(): 调整大小(通常在初始化时使用)
- 注意: resize后push_back会在新size后追加,而非填充未初始化位置)
<5> 迭代器
遍历功能: 提供迭代器用于遍历容器元素
关键迭代器:
- begin(): 指向第一个元素
- end(): 指向最后一个元素之后的位置
遍历注意: 迭代器比较只能用!=,不能用<;递增只能用++it,不能用it+=1
示例:
std::vector<int> vec = {10, 20, 30};
for (auto it = vec.begin(); it != vec.end(); ++it) {
std::cout << *it << " ";
}注意
- 使用 *it 获取元素值
- 迭代器之间不能比较,遍历时只能使用!=比较和++操作
3. vector的常用函数
push_back():将元素添加到 vector 的末尾。
void push_back(const T& value);pop_back():删除 vector 末尾的元素。(必须确保vector非空)
void pop_back();begin() 和 end():返回指向 vector 第一个元素和最后一个元素之后位置的迭代器。
iterator begin();
const_iterator begin() const;
iterator end();
const_iterator end() const;4. vector 排序去重
<1> 排序
使用标准库中的std::sort函数对 vector 进行排序(默认升序排列),该函数位于头文件<algorithm>中。
#include <algorithm>
std::vector<T> vec = {...};
std::sort(vec.begin(), vec.end());<2> 去重
步骤:
- 必须先使用 sort 函数排序使相同元素相邻
- std::unique: 将重复元素移至末尾,返回首个重复元素的迭代器
- erase(): 删除重复元素区间
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {2, 1, 3, 2, 4, 1, 5, 4};
// 1. 对vector进行排序,使重复元素相邻
// 排序后vec变为 {1, 1, 2, 2, 3, 4, 4, 5}
std::sort(vec.begin(), vec.end());
// 2. 去除相邻重复元素,将不重复元素移到前面。返回指向去重后第一个冗余元素的迭代器last
auto last = std::unique(vec.begin(), vec.end());
//auto 是类型推导关键字,让编译器根据初始化值自动确定变量类型;
// 3. 删除从last到末尾的所有冗余元素,完成真正的去重
vec.erase(last, vec.end());
// 4. 使用范围for循环遍历并输出去重后的vector元素
for (const auto& num : vec) {
std::cout << num << " ";
}
return 0;
}去重组合:
vec.erase(unique(vec.begin(), vec.end()), vec.end());5. vector代码示例:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
// 创建一个空的 std::vector 对象
std::vector<int> numbers; // 当前numbers:[]
// 向向量中添加元素,添加后:[5, 2, 8, 5, 1, 2, 9, 8]
numbers.push_back(5);
numbers.push_back(2);
numbers.push_back(8);
numbers.push_back(5);
numbers.push_back(1);
numbers.push_back(2);
numbers.push_back(9);
numbers.push_back(8);
// 打印向量中的元素,输出:5 2 8 5 1 2 9 8
std::cout << "原始向量中的元素: ";
for (const auto& number : numbers) {
std::cout << number << " ";
}
std::cout << std::endl;
// 对向量进行排序(升序),排序后:[1, 2, 2, 5, 5, 8, 8, 9]
std::sort(numbers.begin(), numbers.end());
// 打印排序后的向量,输出:1 2 2 5 5 8 8 9
std::cout << "排序后的向量: ";
for (const auto& number : numbers) {
std::cout << number << " ";
}
std::cout << std::endl;
// 去除重复元素:先unique移走重复元素,再erase删除冗余
numbers.erase(std::unique(numbers.begin(), numbers.end()), numbers.end());
// unique处理后前端有效元素:[1,2,5,8,9],erase删除冗余后最终:[1,2,5,8,9]
// 打印去重后的向量,输出:1 2 5 8 9
std::cout << "去重后的向量: ";
for (const auto& number : numbers) {
std::cout << number << " ";
}
std::cout << std::endl;
// 向向量中插入元素:在第3个位置(下标2)插入3,插入后:[1, 2, 3, 5, 8, 9]
numbers.insert(numbers.begin() + 2, 3);
// 打印插入元素后的向量,输出:1 2 3 5 8 9
std::cout << "插入元素后的向量: ";
for (const auto& number : numbers) {
std::cout << number << " ";
}
std::cout << std::endl;
// 删除向量中的某个元素:删除下标4的元素(值为8),删除后:[1, 2, 3, 5, 9]
numbers.erase(numbers.begin() + 4);
// 打印删除元素后的向量,输出:1 2 3 5 9
std::cout << "删除元素后的向量: ";
for (const auto& number : numbers) {
std::cout << number << " ";
}
std::cout << std::endl;
// 检查向量是否为空
if (numbers.empty()) {
std::cout << "向量为空" << std::endl;
} else {
std::cout << "向量不为空" << std::endl; // 执行此分支,当前向量非空
}
// 获取向量的大小(元素个数),输出:5(当前元素个数为5)
std::cout << "向量的大小: " << numbers.size() << std::endl;
// 清空向量:删除所有元素,清空后:[]
numbers.clear();
// 检查向量是否为空
if (numbers.empty()) {
std::cout << "向量为空" << std::endl; // 执行此分支,向量已空
} else {
std::cout << "向量不为空" << std::endl;
}
return 0;
}操作总结:
- push_back :逐个在尾部添加元素,最终原始向量为
[5, 2, 8, 5, 1, 2, 9, 8];- sort :升序排序后变为
[1, 2, 2, 5, 5, 8, 8, 9];- unique+erase :去重后保留唯一元素,变为
[1, 2, 5, 8, 9];- insert :在指定位置插入元素,变为
[1, 2, 3, 5, 8, 9];- erase :删除指定位置元素,变为
[1, 2, 3, 5, 9];- clear :清空所有元素,最终向量为空
[]。
02 list
1. 定义与结构
list 是 C++ STL 提供的双向链表容器 ,元素以「节点」形式存储,底层通过指针链接各个节点,元素在内存中非连续存储。使用前需包含头文件<list>。
在实际开发中使用频率较低,通常会通过数组模拟链表或手写链表的方式替代。
结构具有双向性:每个节点都包含前后指针,能够支持正向和反向的双向遍历。
list 的每个节点包含三部分内容:一是存储的具体元素(element);二是指向前一个节点的指针(prev);三是指向后一个节点的指针(next)。
注意
list 的大小可以动态扩展或收缩,无需预先指定容量。
由于 list 是双向链表,因此插入和删除操作的时间复杂度是常量时间 O (1),但访问和查找操作的时间复杂度是线性时间 O (n),其中 n 是链表的大小。因此,如果需要频繁进行随机访问操作,可能更适合使用支持随机访问的容器,如 vector 或 deque。
#include <iostream>
#include <list>
int main() {
std::list<int> myList;
// 在链表尾部插入元素
myList.push_back(1);
myList.push_back(2);
myList.push_back(3);
// 在链表头部插入元素
myList.push_front(0);
// 遍历链表并输出元素
for (int num : myList) {
std::cout << num << "-";
}
std::cout << std::endl;
return 0;
}2. list 常用成员函数
- push_back (T):向链表的尾部插入元素,O(1);
- push_front (T):向链表的头部插入元素, O(1);
- pop_back ():移除链表尾部的元素;
- pop_front ():移除链表头部的元素;
- size ():返回链表中元素的个数;
- empty ():判断链表是否为空,为空时返回 true;
- clear ():清空链表中的所有元素;
- front ():返回链表第一个元素的引用;
- back ():返回链表最后一个元素的引用。
- begin ():返回指向链表第一个元素的迭代器;
- end ():返回指向链表「尾后位置」的迭代器;
- insert ():在指定位置之前插入一个或多个元素;
- erase ():从链表中移除指定位置的一个或多个元素。
3. list代码示例
#include <iostream>
#include <list>
#include <algorithm> // 包含reverse算法所需头文件
using namespace std;
int main() {
// 1. 创建空的list<int>容器
list<int> mylist;
// 当前容器状态:空
// 2. 向容器尾部循环添加元素1-5
for(int i = 1; i <= 5; ++i)
{
mylist.push_back(i);
}
// 当前容器状态:[1, 2, 3, 4, 5]
// 输出添加后的元素
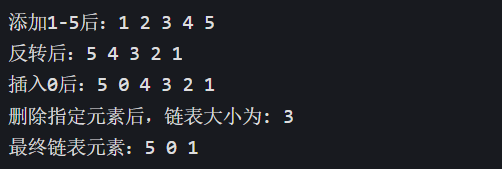
cout << "添加1-5后:";
for(const auto &i : mylist) cout << i << ' ';
cout << '\n'; // 输出:1 2 3 4 5
// 3. 反转容器中所有元素的顺序
reverse(mylist.begin(), mylist.end());
// 当前容器状态:[5, 4, 3, 2, 1]
// 输出反转后的元素
cout << "反转后:";
for(const auto &i : mylist) cout << i << ' ';
cout << '\n'; // 输出:5 4 3 2 1
// 4. 在第一个元素的后一个位置插入元素0
// ++mylist.begin():将迭代器从第一个元素(5)移动到第二个元素(4)的位置,在该位置前插入0
mylist.insert(++mylist.begin(), 0);
// 当前容器状态:[5, 0, 4, 3, 2, 1]
// 输出插入后的元素
cout << "插入0后:";
for(const auto &i : mylist) cout << i << ' ';
cout << '\n'; // 输出:5 0 4 3 2 1
// 5. 删除指定区间的元素
// ++ ++ mylist.begin():迭代器从第一个元素(5)移动两次,指向第四个元素(3)的前一个位置(4)
// -- mylist.end():迭代器从尾后位置向前移动,指向最后一个元素(1)
// erase删除[起始, 结束)区间内的元素,即删除4、3、2
mylist.erase(++ ++ mylist.begin(), -- mylist.end());
// 当前容器状态:[5, 0, 1]
// 6. 输出容器大小
cout << "删除指定元素后,链表大小为: " << mylist.size() << '\n'; // 输出:3
// 7. 输出最终的容器元素
cout << "最终链表元素:";
for(const auto &i : mylist) cout << i << ' ';
cout << '\n'; // 输出:5 0 1
return 0;
}
03 stack
1. stack 的定义与结构
stack(栈)是 C++ STL 提供的后进先出(Last In First Out,LIFO) 线性数据结构。使用栈前需要引入头文件 <stack>。栈的功能相对简洁,仅提供针对栈顶元素的操作和访问函数,不支持随机访问或遍历操作。
栈的结构可以抽象成「U 型容器」,所有操作都限定在栈顶进行:
- 栈底元素:是位于栈最底层的元素,无法直接访问或操作,只有将栈顶的所有元素依次弹出后,栈底元素才会成为栈顶,进而被访问或弹出;
- 栈顶元素:是位于栈最上层的元素,栈的所有核心操作(推入元素、弹出元素、读取元素)都是围绕栈顶展开的;
- 元素变化规则:当栈顶元素被弹出后,原本的「次栈顶元素」会成为新的栈顶;栈底元素必须等所有上层元素都被弹出后,才能成为栈顶并被操作。
2. stack的常用成员函数
所有操作函数的时间复杂度均为 O (1),具体功能如下:
-
push (x):将元素 x 推入栈顶;
-
top ():返回当前栈顶元素的值,该操作仅读取元素,不会将元素弹出栈;
-
pop ():移除当前栈顶的元素,该操作仅删除元素,没有返回值;
-
empty ():判断栈是否为空,若栈为空则返回 true,非空则返回 false;
-
size ():返回栈中元素的总数量。
#include
#include
using namespace std;int main() {
// 1. 声明存储int类型的栈
stackmyStack;
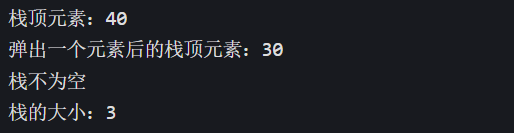
// 当前栈状态:空(无任何元素)// 2. 向栈中依次插入元素10、20、30、40 myStack.push(10); // 当前栈状态(栈底→栈顶):10 myStack.push(20); // 当前栈状态(栈底→栈顶):10 → 20 myStack.push(30); // 当前栈状态(栈底→栈顶):10 → 20 → 30 myStack.push(40); // 当前栈状态(栈底→栈顶):10 → 20 → 30 → 40 // 3. 获取并输出栈顶元素(仅读取,不弹出) cout << "栈顶元素:" << myStack.top() << endl; // 输出:40 // 当前栈状态不变:10 → 20 → 30 → 40 // 4. 弹出栈顶元素(移除40,无返回值) myStack.pop(); // 当前栈状态(栈底→栈顶):10 → 20 → 30 // 5. 再次获取并输出栈顶元素 cout << "弹出一个元素后的栈顶元素:" << myStack.top() << endl; // 输出:30 // 当前栈状态不变:10 → 20 → 30 // 6. 检查栈是否为空并输出结果 if (myStack.empty()) { cout << "栈为空" << endl; } else { cout << "栈不为空" << endl; // 输出:栈不为空 } // 当前栈状态不变:10 → 20 → 30 // 7. 获取并输出栈的大小(元素数量) cout << "栈的大小:" << myStack.size() << endl; // 输出:3 // 当前栈状态不变:10 → 20 → 30 return 0;}
注意
- 不可遍历:需通过反复弹出栈顶元素实现类似遍历效果,但会修改栈结构。
- 数组翻转技巧:将数组元素依次推入栈再依次弹出,可实现元素逆序,但实际应用中效率较低
04 queue
队列类数据结构主要包含普通队列、优先队列、双端队列三类,其中普通队列和双端队列结构简单、易掌握;优先队列出现频率极高,是核心重点掌握的内容。队列整体属于「线性有序」的数据结构,核心区别在于元素的插入 / 删除规则、优先级规则。
1. 普通队列(queue)
普通队列是遵循先进先出(FIFO,First In First Out) 规则的线性数据结构。元素只能从队尾 插入(push 操作),从队头 移除(pop 操作)。常用成员函数如下(时间复杂度均为 O (1) ):
- push (x):在队尾插入元素 x,是队列最基础的添加操作;
- pop ():移除队头元素(仅删除,无返回值);
- front ():返回队头元素的值(仅读取,不移除);
- back ():返回队尾元素的值(使用频率较低);
- empty ():判断队列是否为空,空则返回 true,非空返回 false;
- size ():返回队列中元素的总数量。
访问限制:仅允许操作队头和队尾元素,队列中间的元素无法直接访问或修改。
2. 优先队列(priority_queue)
优先队列中的元素按优先级排序,默认按元素值从大到小排列,队首始终为最大值。与普通队列不同,优先队列的弹出顺序取决于元素优先级而非插入顺序。
优先队列定义包含三个部分:元素类型、底层容器和比较函数。
比较函数决定元素优先级排序规则,其内部采用树形结构实现,但具体实现细节已被封装。队首元素(top)始终为当前极值(最大或最小值),其余元素间的大小关系无需关注。
<1> 常用成员函数:
- push (x):插入元素 x,插入后队列会自动重新排序,时间复杂度为 O (log n);
- pop ():移除队首元素(优先级最高的元素),无返回值;
- top ():返回队首元素(当前优先级最高的元素),仅读取不移除;
- empty ():判断队列是否为空;
- size ():返回队列元素个数。
<2> 优先队列修改比较函数
修改比较函数可改变优先队列的排序规则(如从大根堆改为小根堆),常用三种方法:
-
仿函数法:自定义结构体并重载 () 运算符,定义比较规则;
-
自定义函数法:编写独立的比较函数,需配合 decltype 声明队列类型;
-
直接使用 greater<T>:可快速将默认的大根堆转为小根堆(队首为最小值),头文件<functional>
#include
#include
#include// greater 必备头文件
using namespace std;// 方法1:仿函数法(核心:重载()运算符)
struct Compare {
bool operator()(int a, int b) {
return a > b; // 返回a>b → 小根堆(队首为最小值)
}
};int main() {
// ========== 方法1:仿函数法 ==========
priority_queue<int, vector, Compare> pq1;
pq1.push(30), pq1.push(10), pq1.push(20);
cout << "仿函数法小根堆队首:" << pq1.top() << endl; // 输出10// ========== 方法2:自定义函数法(C++11+) ========== auto cmp = [](int a, int b) { return a > b; }; // 定义比较规则 priority_queue<int, vector<int>, decltype(cmp)> pq2(cmp); // 需传入lambda对象 pq2.push(30), pq2.push(10), pq2.push(20); cout << "自定义函数法小根堆队首:" << pq2.top() << endl; // 输出10 // ========== 方法3:greater<T>法(最简,仅基础类型) ========== priority_queue<int, vector<int>, greater<int>> pq3; pq3.push(30), pq3.push(10), pq3.push(20); cout << "greater法小根堆队首:" << pq3.top() << endl; // 输出10 return 0;}
3. 双端队列(deque)
1. 定义与特性
双端队列是「支持两端操作」的队列,突破了普通队列 "队尾插、队头删" 的限制,是单调队列算法的实现基础,但单独考察频率较低。
2. 常见函数
在普通队列 front ()/back ()/empty ()/size () 的基础上,新增两端插入、删除函数:
- push_front ():在队头插入元素;
- push_back ():在队尾插入元素;
- pop_front ():移除队头元素;
- pop_back ():移除队尾元素;
- 访问函数仍保留 front ()(队头)、back ()(队尾),支持直接访问两端元素。
4. 相关练习
#include <bits/stdc++.h> // 万能头文件,包含queue、string等
using namespace std;
int main() {
// 关闭同步加速输入输出
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
int m;
cin >> m; // 输入操作次数
// 定义两个队列:V存储VIP用户,N存储普通用户
queue<string> V, N;
while (m--) { // 执行m次操作
string op;
cin >> op; // 读取操作类型(IN/OUT)
if (op == "IN") { // 入队操作
string name, q_type;
cin >> name >> q_type; // 读取姓名+队列类型(V/N)
if (q_type == "V") {
V.push(name); // 加入VIP队列
} else {
N.push(name); // 加入普通队列
}
} else if (op == "OUT") { // 出队操作
string q_type;
cin >> q_type; // 读取要出队的队列类型(V/N)
// 出队前检查队列非空,避免操作空队列
if (q_type == "V" && !V.empty()) {
V.pop();
} else if (q_type == "N" && !N.empty()) {
N.pop();
}
}
}
// 输出VIP队列剩余元素(从头到尾)
while (!V.empty()) {
cout << V.front() << endl; // 输出队首
V.pop(); // 弹出队首,继续输出下一个
}
// 输出普通队列剩余元素(从头到尾)
while (!N.empty()) {
cout << N.front() << endl;
N.pop();
}
return 0;
}#include <bits/stdc++.h>
using namespace std;
using ll = long long; // 防止数值溢出
int main() {
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
int n;
cin >> n;
// 定义小根堆:存储long long类型,底层vector,比较函数greater<ll>
priority_queue<ll, vector<ll>, greater<ll>> pq;
// 读取每堆果子数量,推入小根堆
for (int i = 1; i <= n; ++i) {
ll x;
cin >> x;
pq.push(x);
}
ll ans = 0; // 存储总体力消耗
// 当堆中至少有2堆时,继续合并
while (pq.size() >= 2) {
// 取出最小的两堆
ll x = pq.top(); pq.pop();
ll y = pq.top(); pq.pop();
// 累加合并消耗
ans += x + y;
// 合并后的新堆重新入堆
pq.push(x + y);
}
cout << ans << '\n'; // 输出总消耗
return 0;
}05 set
本模块内容分为四个部分:set集合、multiset多重集合、unordered_set无序集合以及三份代码示例。重点掌握set集合和multiset多重集合,unordered_set无序集合仅需了解,因其使用频率低且时间复杂度不稳定。
1. set集合
set 是 STL 中的关联容器,核心作用是存储一组唯一的元素,并按照固定排序规则自动排序:
- 排序规则:默认按升序排列,底层依赖元素的比较运算符
<实现; - 元素唯一性:不允许重复元素存在,插入重复元素时会被 set 自动忽略;
- 底层实现:采用红黑树(自平衡二叉搜索树)存储元素,既保证了元素的有序性,也让插入、删除、查找操作的时间复杂度均为 O (log n)。
<1> set集合的常用函数
- insert(x):插入元素x。
- erase(x):删除元素x。
- find(x):返回x的迭代器,若不存在则返回end()。
- lower_bound(x):返回第一个≥x的迭代器。
- upper_bound(x):返回第一个>x的迭代器。
- 辅助操作:size()、empty()、clear()、begin()、end()等基础功能。
<2> 修改set比较函数
|---------|--------------------------------------------|---------------------|
| 方法 | 实现方式 | 示例效果 |
| 简单降序 | 传入greater比较函数(如set<int, greater<int>>) | 元素按42、39、25、17降序排列。 |
| 自定义比较逻辑 | 定义仿函数(重载()运算符),例如将比较符改为>。 | 实现与greater相同的降序效果。 |
<3> 代码示例
#include <iostream>
#include <set>
using namespace std;
int main() {
// 1. 定义set容器,存储int类型元素
set<int> mySet;
// 🔴 插入元素
mySet.insert(5);
mySet.insert(2);
mySet.insert(8);
mySet.insert(2); // 插入重复元素,set会自动忽略
// 🔴 遍历集合(自动升序输出)
cout << "Set elements: ";
for (const auto& elem : mySet) {
cout << elem << " ";
}
cout << endl;
// 查找元素
int searchValue = 5;
auto it = mySet.find(searchValue); // 返回迭代器
if (it != mySet.end()) {
cout << searchValue << " found in the set." << endl;
} else {
cout << searchValue << " not found in the set." << endl;
}
// 移除元素
int removeValue = 2;
mySet.erase(removeValue);
// 再次遍历集合(移除后元素顺序仍保持升序)
cout << "Set elements after removal: ";
for (const auto& elem : mySet) {
cout << elem << " ";
}
cout << endl;
// 清空集合
mySet.clear();
// 检查集合是否为空
if (mySet.empty()) {
cout << "Set is empty." << endl;
} else {
cout << "Set is not empty." << endl;
}
return 0;
}2. multiset多重集合
multiset与set的主要区别在于允许存储重复元素,其他特性(如排序规则、底层实现)与set一致。
多重集合的常见函数基本与set相同,但需注意:
- erase(x):删除所有值为x的元素。若仅需删除单个x,需先通过find(x)获取迭代器再删除。
- 时间复杂度:插入、删除、查找均为O(log n)。
- 典型场景:lower_bound和upper_bound多用于multiset的二分查找问题。
代码示例:
#include <iostream>
#include <set>
using namespace std;
int main() {
// 1. 定义multiset容器,存储int类型元素
multiset<int> myMultiset;
// 插入元素(允许重复)
myMultiset.insert(5);
myMultiset.insert(2);
myMultiset.insert(8);
myMultiset.insert(2); // 插入重复元素,multiset允许重复存储
// 遍历多重集合(自动升序输出)
cout << "Multiset elements: ";
for (const auto& elem : myMultiset) {
cout << elem << " ";
}
cout << endl;
// 查找元素(使用equal_range)
int searchValue = 5;
auto range = myMultiset.equal_range(searchValue);
// 返回pair<迭代器, 迭代器>,first指向第一个匹配元素,second指向尾后匹配位置
if (range.first != range.second) {
cout << searchValue << " found in the multiset." << endl;
} else {
cout << searchValue << " not found in the multiset." << endl;
}
// 移除元素
int removeValue = 2;
myMultiset.erase(removeValue); // 删除所有值为2的元素
// 再次遍历集合(移除后元素仍保持升序)
cout << "Multiset elements after removal: ";
for (const auto& elem : myMultiset) {
cout << elem << " ";
}
cout << endl;
// 清空多重集合
myMultiset.clear();
// 检查多重集合是否为空
if (myMultiset.empty()) {
cout << "Multiset is empty." << endl;
} else {
cout << "Multiset is not empty." << endl;
}
return 0;
}3. unordered_set无序集合
unordered_set 是 C++ 标准库中的无序容器 ,用于存储唯一的元素,元素无固定顺序。
- 底层实现:哈希表(散列表)
- 元素特性:不允许重复,插入重复元素时会被自动忽略
- 时间复杂度:平均情况为 O(1) ,最坏情况为O(n)
不支持lower_bound、upper_bound等有序操作。因复杂度不稳定,通常优先选择set或multiset。
代码示例:
#include <iostream>
#include <unordered_set>
using namespace std;
int main() {
// 1. 定义unordered_set容器,存储int类型元素
unordered_set<int> myUnorderedSet; // 初始状态:空容器
// 插入元素
myUnorderedSet.insert(5); // 容器内容:{5}
myUnorderedSet.insert(2); // 容器内容:{5,2}(顺序由哈希函数决定,可能是{2,5})
myUnorderedSet.insert(8); // 容器内容:{5,2,8}(顺序不固定,如{8,5,2})
myUnorderedSet.insert(2); // 插入重复元素,容器无变化 → 仍为{5,2,8}
// 遍历无序集合(输出顺序不固定,由哈希函数决定)
cout << "Unordered set elements: ";
for (const auto& elem : myUnorderedSet) {
cout << elem << " ";
}
cout << endl;
// 执行结果示例(仅为一种可能):Unordered set elements: 8 5 2
// 查找元素
int searchValue = 5;
auto it = myUnorderedSet.find(searchValue); // 返回指向5的迭代器
if (it != myUnorderedSet.end()) {
cout << searchValue << " found in the unordered set." << endl;
} else {
cout << searchValue << " not found in the unordered set." << endl;
}
// 执行结果:5 found in the unordered set.
// 移除元素
int removeValue = 2;
myUnorderedSet.erase(removeValue); // 容器内容:{5,8}(删除值为2的元素)
// 再次遍历集合
cout << "Unordered set elements after removal: ";
for (const auto& elem : myUnorderedSet) {
cout << elem << " ";
}
cout << endl;
// 执行结果示例:Unordered set elements after removal: 8 5
// 清空无序集合
myUnorderedSet.clear(); // 容器内容:{}(空容器)
// 检查无序集合是否为空
if (myUnorderedSet.empty()) {
cout << "Unordered set is empty." << endl;
} else {
cout << "Unordered set is not empty." << endl;
}
// 执行结果:Unordered set is empty.
return 0;
}06 map
map 系列包含 map、multimap、unordered_map 三类关联容器,重点学习普通 map ;multimap 实际应用极少,仅作了解即可;unordered_map 虽无需深入掌握,但需知晓其特性。
1. map
map 作为关联容器,专门存储键值对 (key-value pair),每个键具有唯一性,类似数学中自变量与因变量的唯一映射关系。
容器会根据键自动排序 ,默认遵循 less<key> 规则(键从小到大排列),通常无需修改该规则;其底层通过红黑树实现(与 set 底层一致),插入、删除和查找操作的时间复杂度均为 O (log n)。map 的模板参数主要关注键类型(key)和值类型(T),compare 比较规则和 allocator 空间配置器使用默认值即可
常用成员函数
-
insert:
insert({key, value}),用于插入单个键值对;也支持通过迭代器范围批量插入,但极少使用; -
find (key):根据指定键查找对应的键值对,找到则返回指向该键值对的迭代器,未找到则返回
end()迭代器; -
count (key):统计指定键在容器中的出现次数,由于 map 中键唯一,结果只能是 0(键不存在)或 1(键存在),作用是快速判断键是否存在;
-
size ():无需传入参数,直接返回容器中键值对的总数量;
-
lower_bound (key):返回指向首个 "大于等于指定键" 的键值对的迭代器,该函数依赖 map 的有序性才能生效。
#include
#includeint main() {
// 1. 创建并初始化 map(键唯一,自动按 key 升序排序)
map<int, string> myMap = {{1, "Apple"}, {2, "Banana"}, {3, "Orange"}};
// 初始状态:{1:"Apple", 2:"Banana", 3:"Orange"}// 2. 插入元素 myMap.insert(make_pair(4, "Grapes")); // 插入后:{1:"Apple", 2:"Banana", 3:"Orange", 4:"Grapes"} // 3. 查找和访问元素(通过 key 直接访问) cout << "Value at key 2: " << myMap[2] << endl; // 执行结果:Value at key 2: Banana // 4. 遍历并打印 map 中的元素(按 key 升序输出) cout << "Traverse map: " << endl; for (const auto& pair : myMap) { cout << "Key: " << pair.first << ", Value: " << pair.second << endl; } // 执行结果: // Key: 1, Value: Apple // Key: 2, Value: Banana // Key: 3, Value: Orange // Key: 4, Value: Grapes // 5. 删除元素(按 key 删除) myMap.erase(3); // 删除后:{1:"Apple", 2:"Banana", 4:"Grapes"} // 6. 判断元素是否存在(count() 返回 0 或 1,因为 key 唯一) if (myMap.count(3) == 0) { cout << "Key 3 not found." << endl; } // 执行结果:Key 3 not found. // 7. 清空 map myMap.clear(); // 清空后:容器为空 // 8. 判断 map 是否为空 if (myMap.empty()) { cout << "Map is empty." << endl; } // 执行结果:Map is empty. return 0;}
2. multimap
与普通 map 仅有的区别是:允许相同的键重复存在,底层实现、操作的时间复杂度均与 map 一致,但几乎不会用到。
常用成员函数
-
find (key):若基于该函数的返回结果执行删除操作,需指定具体的迭代器位置,否则会删除容器中所有包含该键的键值对;
-
count (key):返回指定键的实际重复次数(区别于 map 的 0/1 结果),例如 map 存储
{1:3, 1:2, 1:-1}时,count(1)返回 3。#include
#includeint main() {
// 1. 创建并初始化 multimap(允许 key 重复,自动按 key 升序排序)
multimap<int, string> myMultimap = {{1, "Apple"}, {2, "Banana"}, {2, "Orange"}};
// 初始状态:{1:"Apple", 2:"Banana", 2:"Orange"}// 2. 插入元素 myMultimap.insert(make_pair(3, "Grapes")); // 插入后:{1:"Apple", 2:"Banana", 2:"Orange", 3:"Grapes"} // 3. 查找和访问元素(equal_range 遍历同一 key 的所有值) auto range = myMultimap.equal_range(2); cout << "Traverse elements with key 2: " << endl; for (auto it = range.first; it != range.second; ++it) { cout << "Key: " << it->first << ", Value: " << it->second << endl; } // 执行结果: // Key: 2, Value: Banana // Key: 2, Value: Orange // 4. 遍历并打印 multimap 中的元素(按 key 升序输出) cout << "Traverse multimap: " << endl; for (const auto& pair : myMultimap) { cout << "Key: " << pair.first << ", Value: " << pair.second << endl; } // 执行结果: // Key: 1, Value: Apple // Key: 2, Value: Banana // Key: 2, Value: Orange // Key: 3, Value: Grapes // 5. 删除元素(按 key 删除,会删除所有该 key 的元素) myMultimap.erase(2); // 删除后:{1:"Apple", 3:"Grapes"} // 6. 判断元素是否存在(count() 返回该 key 出现的次数) if (myMultimap.count(2) == 0) { cout << "Key 2 not found." << endl; } // 执行结果:Key 2 not found. // 7. 清空 multimap myMultimap.clear(); // 清空后:容器为空 // 8. 判断 multimap 是否为空 if (myMultimap.empty()) { cout << "Multimap is empty." << endl; } // 执行结果:Multimap is empty. return 0;}
3. unordered_map
unordered_map 是一种关联容器,用于存储一组键值对(key-value pairs),其中每个键(key)都是唯一的。与 map 和 multimap 不同,unordered_map 不会根据键的顺序进行排序,而是使用哈希函数将键映射到存储桶中。这使得 unordered_map 具有更快的插入、删除和查找操作的时间复杂度,但不保证元素的顺序。
不支持排序相关的操作(如 lower_bound),因为容器本身无有序性。
常用成员函数
insert、erase、find、count 等基础操作的用法与普通 map 一致,但没有排序、边界查找类的函数。
#include <iostream>
#include <unordered_map>
using namespace std;
int main() {
// 1. 创建并初始化 unordered_map(key 唯一,无序存储)
unordered_map<string, int> myMap = {{"Apple", 3}, {"Banana", 5}, {"Orange", 2}};
// 初始状态:元素顺序由哈希函数决定,示例可能为 {"Orange":2, "Banana":5, "Apple":3}
// 2. 插入元素
myMap.insert(make_pair("Grapes", 4));
// 插入后:新增 "Grapes":4,顺序仍不固定
// 3. 查找和访问元素(通过 key 直接访问)
cout << "Value for key 'Banana': " << myMap["Banana"] << endl;
// 执行结果:Value for key 'Banana': 5
// 4. 遍历并打印 unordered_map 中的元素(顺序不固定)
cout << "Traverse unordered_map: " << endl;
for (const auto& pair : myMap) {
cout << "Key: " << pair.first << ", Value: " << pair.second << endl;
}
// 执行结果示例(顺序不固定):
// Key: Orange, Value: 2
// Key: Banana, Value: 5
// Key: Apple, Value: 3
// Key: Grapes, Value: 4
// 5. 删除元素(按 key 删除)
myMap.erase("Orange");
// 删除后:移除 "Orange":2,剩余元素顺序仍不固定
// 6. 判断元素是否存在(count() 返回 0 或 1,因为 key 唯一)
if (myMap.count("Orange") == 0) {
cout << "Key 'Orange' not found." << endl;
}
// 执行结果:Key 'Orange' not found.
// 7. 清空 unordered_map
myMap.clear();
// 清空后:容器为空
// 8. 判断 unordered_map 是否为空
if (myMap.empty()) {
cout << "Unordered_map is empty." << endl;
}
// 执行结果:Unordered_map is empty.
return 0;
}07 pair
pair 是 C++ 标准库中的模板类,用于封装两个可不同类型的值 ,形成一个 "值对",作用是将两个关联的值绑定在一起,方便统一存储、传递或返回。包含于头文件<utility>。
- 模板参数 :
pair<T1, T2>,T1/T2分别为第一个、第二个值的类型(可相同 / 不同,如int+string、char+double)。 - 成员变量 :内置
first(第一个值)、second(第二个值),直接访问即可。 - 构造方式 :
-
默认构造:
pair<int, string> p;(值默认初始化); -
带参构造:
pair<int, string> p(3, "Mike");(3 →first,"Mike" →second)。#include
#includeint main() {
// p1: first=1, second=3.14
std::pair<int, double> p1(1, 3.14);
// p2: first='a', second="hello"
std::pair<char, std::string> p2('a', "hello");// 输出:1, 3.14 std::cout << p1.first << ", " << p1.second << std::endl; // 输出:a, hello std::cout << p2.first << ", " << p2.second << std::endl; return 0;}
-
pair支持嵌套,可将一个pair对象作为另一个pair的成员,形成更复杂的数据结构。
#include <iostream>
#include <utility>
int main() {
// 基础pair:存储两个int值
std::pair<int, int> p1(1, 2);
// 一层嵌套:外层first为int,second为内层pair<int, int>
std::pair<int, std::pair<int, int>> p2(3, std::make_pair(4, 5));
// 两层嵌套:外层first和second均为pair<int, int>
std::pair<std::pair<int, int>, std::pair<int, int>> p3(
std::make_pair(6, 7),
std::make_pair(8, 9) // 图片中代码被截断,补全为make_pair(8, 9)
);
// 访问并输出p1
std::cout << p1.first << ", " << p1.second << std::endl;
// 访问并输出p2:通过.second.first/second访问内层
std::cout << p2.first << ", " << p2.second.first << ", " << p2.second.second << std::endl;
// 访问并输出p3:链式访问多层first/second
std::cout << p3.first.first << ", " << p3.first.second << ", "
<< p3.second.first << ", " << p3.second.second << std::endl;
return 0;
}pair默认按first成员升序排序,若first相等,则按second升序排序。使用std::sort对包含pair的容器排序时,默认按此规则执行。
#include <iostream>
#include <utility> // 用于std::pair
#include <vector> // 用于std::vector
#include <string> // 用于std::string
// 定义结构体Person,表示一个人的信息
// 修改结果:创建自定义数据类型,包含姓名和年龄两个属性
struct Person {
std::string name; // 姓名
int age; // 年龄
};
int main() {
// 1. 创建存储Person对象的向量
// 修改结果:初始化空vector,后续用于存放多个Person实例
std::vector<Person> people;
// 2. 向people向量中添加Person对象
// 修改结果:vector中新增3个元素,分别是Alice(25)、Bob(30)、Charlie(20)
people.push_back({"Alice", 25});
people.push_back({"Bob", 30});
people.push_back({"Charlie", 20});
// 3. 创建存储pair的向量,每个pair包含Person对象和一个int评分
// 修改结果:初始化空vector,元素类型为pair<Person, int>,first存Person、second存评分
std::vector<std::pair<Person, int>> scores;
// 4. 向scores向量中添加pair元素
// 修改结果:vector中新增3个pair,分别关联people中对应索引的Person和对应评分
scores.push_back({people[0], 90}); // 关联Alice和90分
scores.push_back({people[1], 85}); // 关联Bob和85分
scores.push_back({people[2], 95}); // 关联Charlie和95分
// 5. 遍历pair向量并输出信息
// 修改结果:遍历scores,逐个访问pair的first(Person)和second(评分),打印姓名、年龄、评分
for (const auto& pair : scores) {
std::cout << "Name: " << pair.first.name << std::endl; // 输出姓名
std::cout << "Age: " << pair.first.age << std::endl; // 输出年龄
std::cout << "Score: " << pair.second << std::endl; // 输出评分
std::cout << std::endl;
}
return 0;
}