-
你的 CLAUDE.md 最初只有 20 行:
- 技术栈: React + TypeScript
- 包管理: pnpm
- 提交信息遵循: Conventional Commits。
简洁、清晰,每次打开 Claude Code 都能精准命中。
-
三个月后,它涨到了 200 行。
包含了技术栈说明、编码规范、Git 提交规范、前端设计规范、API 审查清单、数据库操作注意事项、部署流程、性能优化 checklist......一个 Markdown 文件,试图覆盖你工作中的所有场景。
-
问题随之出现:不管你今天只是改个按钮颜色,这 200 行全部加载进上下文。 这就像你每天上班都背着一个装满所有工具的大书包,其实今天只需要一支笔。
这篇文章解决一个非常具体的问题:CLAUDE.md 里的哪些内容应该留下?哪些应该拆成 Skill?
一、理解CLAUDE.md的最佳状态
1.1 什么是 CLAUDE.md 的「甜蜜点」
理想长度通常在50~100 行,它包含的是:技术栈、命名规范、提交规则和测试约定,共同特征只有一个:无论今天做什么任务,Claude 都需要知道。
1.2 从甜蜜点走向膨胀点
-
问题不是某一条规则,而是累积。随着使用深入,你会不断往里加东西:
- 一次部署事故 → 加流程
- 一次数据库问题 → 加规范
- 一次 UI 混乱 → 加设计系统
-
CLAUDE.md 从Always-on context变成Everything-on context。

上图展示了 CLAUDE.md 从精炼到臃肿的演变过程。一旦你的 CLAUDE.md 从左边的状态滑向了右边,就该考虑拆分了。
1.3 膨胀信号
(1) 行数超过150行
这不是一个精确阈值,但如果你的 CLAUDE.md 已经需要滚动好几屏才能看完,大概率已经过载了。
(2) 出现低频内容
有些内容你只在特定任务时才需要。 比如部署流程,你可能一周才部署一次,但它每次对话都被加载。
(3) 开始出现领域分区
你开始用注释分隔不同领域的规则。 当你写出 <!-- 前端设计规范 --> 和 <!-- 数据库操作 --> 这样的分隔线时,说明这些内容在逻辑上已经是独立模块了。
markdown
<!-- 前端规范 -->
<!-- 数据库操作 -->(4) 出现"小文档"
有些规则非常详细。 一份完整的代码审查清单可能就占了 40 行,它本身就是一个"小文档"。一旦出现这些信号,就该考虑拆分了。
二、拆分判断
面对 CLAUDE.md 里的每一块内容,依次问自己四个问题。
2.1 问题一:每次对话都需要吗?
这是最关键的判断标准。
-
"我们用 TypeScript,包管理用 pnpm"。每次都需要,留在 CLAUDE.md。
-
"部署到生产环境时,先跑 smoke test,再切流量,切流量分三步......"。这些只在部署时需要,候选 Skill。
-
核心原则:
- CLAUDE.md 是"始终在线"的,所以里面应该放"始终需要"的内容。如果某段内容只在特定场景触发,它就不该占用每次对话的上下文。
- Skill 按需加载
2.2 问题二:内容有多长?
即使某段内容不是每次都用,如果它只有两三行,留在 CLAUDE.md 也无妨,上下文代价很小。
markdown
# CLAUDE.md 中的简短约定(可以留)
- 数据库查询必须使用参数化查询,禁止字符串拼接 SQL
- 所有 API 响应必须包含 request_id 字段 这种一两行的规则,即使不是每次都用,也不值得单独做成 Skill。
- 但如果是这样的内容,例如较长的checklist:
markdown
# API 审查清单(40 行,适合抽成 Skill)
## 安全性检查
- [ ] 所有端点是否都有认证?
- [ ] 权限校验是否在 Controller 层?
- [ ] 输入参数是否做了校验和清洗?
- [ ] 是否有速率限制?
...(后面还有 30 多行) 面对40 行的详细清单,只在做 API 审查时才需要,这就是典型的 Skill 候选。
2.3 问题三:"约定"还是"流程"?
-
约定是简短的、声明式的规则:
markdown- 变量命名用 camelCase - 组件文件用 PascalCase - CSS 类名用 kebab-case -
流程是有步骤的、过程式的操作指南:
markdown## 部署流程 1. 切到 release 分支 2. 运行 pnpm build,确认无报错 3. 执行 smoke test 4. 用 kubectl 滚动更新,先更新 canary pod 5. 观察 10 分钟监控指标 6. 确认无异常后全量发布 7. 更新 CHANGELOG 约定适合放在 CLAUDE.md,简短、通用、始终有效。流程适合做成 Skill,详细、场景化、按需调用。
2.4 问题四:多个项目需要复用它吗?
如果某段内容只在当前项目用,按前三个问题判断就够了。
但如果你发现自己在好几个项目的 CLAUDE.md 里写了类似的内容,比如通用的代码审查规范、Git 工作流、性能优化清单------那就值得做成一个全局 Skill ,放在 ~/.claude/skills/ 下,所有项目共享。
# 全局 Skill 的存放位置
~/.claude/skills/
├── code-review/
│ └── SKILL.md
└── perf-check/
└── SKILL.md 这样你不需要在每个项目里重复维护同一份规则。
三、实操演示:一次真实的CLAUDE.md"瘦身"过程
说了这么多理论,来看一个具体的拆分案例。
3.1 瘦身前
假设你的 CLAUDE.md 长这样(约 200 行):
markdown
# 项目说明
技术栈:React 18 + TypeScript + Tailwind CSS
包管理:pnpm
测试框架:Vitest
部署平台:AWS ECS
# 编码规范
- 变量命名 camelCase,组件 PascalCase
- 禁止 any,必须显式类型标注
- 函数最大行数 50 行
...(共 15 行)
# Git 提交规范
- 使用 Conventional Commits 格式
- feat/fix/refactor/docs/test
...(共 10 行)
# 前端设计规范
## 间距系统
- 基础单位 4px,间距只能是 4 的倍数
## 字体层级
- H1: 32px/40px bold
- H2: 24px/32px semibold
...(共 50 行)
# API 审查清单
## 安全性
- 认证、授权、输入校验...
## 性能
- N+1 查询、分页、缓存...
...(共 40 行)
# 数据库操作规范
- 参数化查询
- 迁移脚本命名规则
- 索引策略
...(共 30 行)
# 部署流程
1. 构建 → 2. 测试 → 3. 镜像推送 → ...
...(共 25 行)
# 性能优化 checklist
- 首屏加载、bundle 分析、图片优化...
...(共 20 行) 用四个问题逐块扫一遍:
| 内容块 | 每次都需要? | 多长? | 约定/流程? | 结论 |
|---|---|---|---|---|
| 项目说明 | 是 | 5 行 | 约定 | 留 |
| 编码规范 | 是 | 15 行 | 约定 | 留 |
| Git 提交规范 | 是 | 10 行 | 约定 | 留 |
| 前端设计规范 | 写前端时 | 50 行 | 混合 | 拆 |
| API 审查清单 | 审查时 | 40 行 | 流程 | 拆 |
| 数据库操作规范 | 写 DB 代码时 | 30 行 | 混合 | 拆 |
| 部署流程 | 部署时 | 25 行 | 流程 | 拆 |
| 性能优化 checklist | 优化时 | 20 行 | 流程 | 拆 |
3.2 瘦身后
CLAUDE.md(约 35 行):
markdown
# 项目说明
技术栈:React 18 + TypeScript + Tailwind CSS
包管理:pnpm
测试框架:Vitest
部署平台:AWS ECS
# 编码规范
- 变量命名 camelCase,组件 PascalCase
- 禁止 any,必须显式类型标注
- 函数最大行数 50 行
- import 顺序:外部库 → 内部模块 → 类型 → 样式
...
# Git 提交规范
- 使用 Conventional Commits 格式
- feat: 新功能 | fix: 修复 | refactor: 重构
- 提交信息用英文,首字母小写
...-
Skill 目录结构:
.claude/skills/
├── frontend-review/
│ └── SKILL.md
├── api-review/
│ └── SKILL.md
├── db-ops/
│ └── SKILL.md
├── deploy/
│ └── SKILL.md
└── perf-check/
└── SKILL.md
以 frontend-review 为例,SKILL.md 的内容:
markdown
---
name: frontend-review
description: 审查前端代码的设计规范合规性,包括间距、字体、配色、响应式和交互状态
---
## 间距系统
- 基础单位 4px,所有间距必须是 4 的倍数
- 组件内间距:8px / 12px / 16px
- 组件间间距:16px / 24px / 32px
## 字体层级
- H1: 32px/40px bold
- H2: 24px/32px semibold
- Body: 16px/24px regular
- Caption: 14px/20px regular
## 配色规范
- 主色:#1a73e8
- 语义色:success #34a853 / error #ea4335 / warning #fbbc04
## 审查要点
- [ ] 间距是否对齐 4px 网格
- [ ] 字体层级是否正确
- [ ] 按钮是否有 hover/active/disabled 状态
- [ ] 是否适配移动端断点(640px / 768px / 1024px)
...四、拆分后怎么用
日常使用方式几乎没有变化,反而更清爽了。
4.1 日常开发(默认模式)
打开 Claude Code,CLAUDE.md 自动加载。35 行的核心约定,轻量、精准,不会在上下文里塞一堆你今天用不上的东西,上下文更轻。
4.2 按需调用 Skill
-
要做前端审查时:
/frontend-review 帮我审查一下 src/components/Header.tsx 的样式
-
要部署时:
/deploy 帮我把当前版本部署到 staging 环境
-
要做 API 审查时:
/api-review 检查 src/routes/users.ts 的安全性和性能
4.3 自动匹配机制
Skill 的 description 会参与语义匹配。描述越准确,自动加载越稳定。 如果你在对话中提到"审查一下这个 API 的安全性",Claude 可能会自动加载 api-review Skill,不需要你手动输入斜杠命令。
五、三个常见误区
5.1 误区一:所有东西都做成 Skill
有人看到 Skill 机制后很兴奋,把 CLAUDE.md 拆得一干二净,连"用 camelCase 命名"这种两行的约定都做成了 Skill。
结果是:每次对话都要手动加载好几个 Skill,反而比一个 CLAUDE.md 更麻烦。
高频、简短的约定就该放在 CLAUDE.md 里。 它们的上下文代价很小,但如果缺失,Claude 每次都可能犯错。
5.2 误区二:CLAUDE.md 里堆太多"以防万一"的内容
"万一 Claude 要写数据库代码呢?还是把规范放着吧。"
这种想法可以理解,但代价是:你 90% 的对话都在为 10% 的场景买单。那些"以防万一"的内容加起来可能有 100 多行,每次都挤占上下文窗口。
上下文不是免费的。 不相关的内容不仅浪费 token,还可能分散 Claude 的注意力,影响它对当前任务的理解。
5.3 误区三:只用 CLAUDE.md 或者只用 Skill
这两者不是二选一的关系,而是各有分工:
-
CLAUDE.md 是"始终在线的常识",不需要你做任何操作,每次自动生效
-
Skill 是"按需调用的专家",特定场景下提供深度指导
一个健康的配置通常是:一个精炼的 CLAUDE.md 打底,加上几个针对特定场景的 Skill。
六、总结:一张决策图
当你拿不准某段内容该放哪里时,按这个流程走:
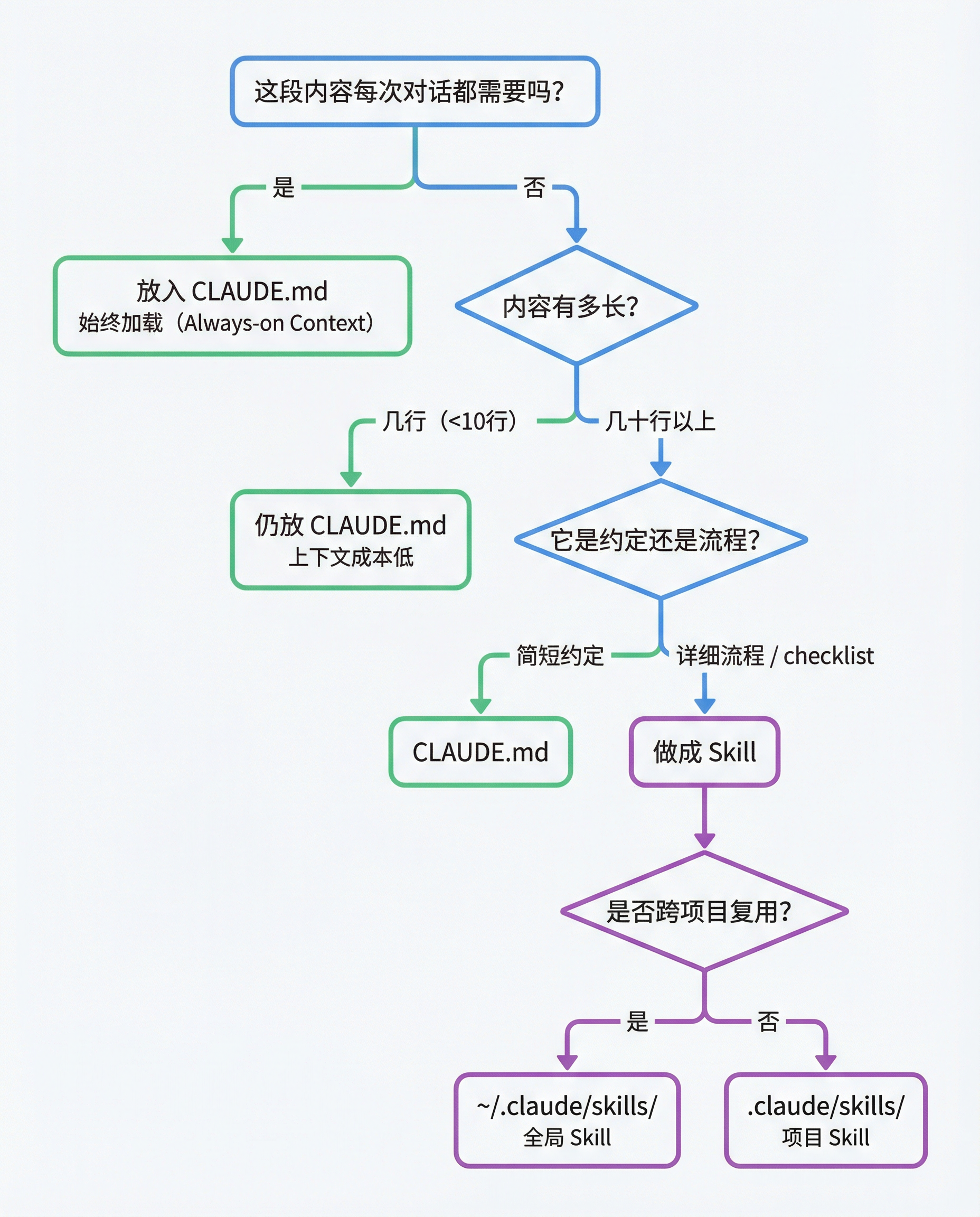
最后要说一点:不需要一步到位。 你不必今天就把 CLAUDE.md 拆得完美。正常使用,等你觉得 CLAUDE.md 太长了、某些内容明显只在特定场景用到了,再拆出来就好。渐进式优化,比一开始就过度设计更实际。
CLAUDE.md 是常识,Skill 是专家。让常识始终在线,让专家按需登场。