Boosting 就是把简单模型依次串联,每一步都死死盯着上一步的短板(损失函数的负梯度方向),通过加权修正,最终累加出一个极其强大的集成模型。
第一部分:集成学习与Boosting的直觉
1.1 什么是集成学习
任何一个单一的机器学习模型,都只能在它的"能力范围"内表现良好。这个能力范围由模型的假设空间、优化算法和训练数据的噪声共同决定。比如:
-
线性模型无法处理非线性边界;
-
决策树容易过拟合到训练数据的细节噪声;
-
神经网络可能陷入局部最优。
单个模型总是存在偏差和方差之间的权衡,很难在所有情况下都做到完美。这就好比一个医生再高明,也可能因为知识盲区而误诊。
集成学习背后的直观哲学非常朴素,那就是中国的一句老话:"三个臭皮匠,顶个诸葛亮"。通过将多个存在缺陷的模型组合起来,往往能获得一个极其强大的预测系统。常见的集成方式主要有三种:
-
平均法: 针对回归问题,把所有模型的预测值加起来求平均,简单粗暴但有效。
-
投票法: 针对分类问题,少数服从多数,得票最多的类别就是最终结果。
-
学习法: 用一个更高层的模型去学习如何组合这些基础模型的预测结果(例如 Stacking)。
想象一个疑难杂症患者去医院看病。如果只看一位内科医生,这位医生可能会受限于自己的专业偏见而发生误诊。但如果医院组织了心血管、神经、内分泌等多个科室的"普通医生"进行联合会诊。虽然每个医生都不是全能的神医,但大家综合各自的诊断意见进行投票,最终得出的治疗方案往往比任何单一专家的结果都更可靠、更全面。
1.2 弱学习器与强学习器
在深入 Boosting 之前,我们需要明确两个概念:弱学习器和强学习器。
-
弱学习器: 指的是预测准确率仅略好于随机猜测的模型。在二分类问题中,只要它的准确率比 50% 高出那么一点点,它就是一个合格的弱学习器。
-
强学习器: 指的是预测准确率很高,能够很好地拟合数据且泛化能力强的模型。
在 1989 年,计算学习理论的先驱 Kearns 和 Valiant 提出了一个直击灵魂的核心问题:"弱学习器和强学习器是等价的吗?如果给定足够多的数据,我们能不能把一个勉强能用的弱学习器,提升(Boost)为一个极其可靠的强学习器?" 后来,Schapire 给出了肯定的构造性证明,这也直接催生了 Boosting 算法。
决策树桩是决策树家族里最简单的一种:它只做一次决策。比如判断一个人是否成年,只看身高,如果身高>150cm就判断为成年,否则判断为未成年。这样一个只有单层判断规则的"树桩",对复杂问题的分类能力极弱。
假设我们要区分猫和狗的图像,单个决策树桩可能基于"图片左上角像素的颜色是否大于128"来做判断,它的错误率大概在45%~49%之间------只比扔硬币(50%错误率)好那么一丝丝。这就是一个典型的弱学习器。
Boosting的目标就是,拿一堆这样的树桩,每一个都只抓住一点点微弱的模式,然后通过某种方式把它们变成一个能准确识别猫狗的强分类器。
一句话解释:Boosting 想证明一堆"勉强能用"的弱模型,可以通过某种机制变成一个强大的强模型。
1.3 Boosting的基本思想
如果说另一种集成学习方法 Bagging(如随机森林)是让一堆模型并行独立工作然后取平均,那么 Boosting 则是一场严密的接力赛,它的核心在于序列化训练。
① 序列化训练:后一个模型关注前一个模型犯错的样本
Boosting不是并行地训练多个模型(像医生会诊那样各看各的),而是串行 的。它训练完第一个弱学习器后,检查哪些样本被分错了,然后刻意让第二个弱学习器更关注这些错误样本。第二个弱学习器会努力在这些先前失败的样本上做得更好,但它自己又会犯新的错误;然后第三个弱学习器再集中攻克前两个都容易犯错的地方......就这样一轮一轮地"补短板"。
② 自适应地改变样本分布
这里的"更关注"是通过调整样本权重 来实现的。初始时,所有训练样本的权重相等,每个样本重要性一样。每轮训练后,被当前模型分错的样本,权重会被调大 ;分对的样本,权重会被调小 。这样在训练下一个模型时,加权错误率高的地方(即权重大的错误样本)就会得到算法的重点关注,迫使新模型优先纠正这些错误。权重的变化是自适应的,完全由之前模型的表现决定。
③ 加权组合所有模型
最终,Boosting会把每一轮得到的弱学习器都保留下来。但每个弱学习器的"话语权"并不相等:错误率越低的弱学习器,在最终投票中的权重越大。最后的强分类器,就是这些弱学习器的加权投票。
④ 与Bagging的轮廓对比(帮助厘清概念)
常常和Boosting并列出现的另一种集成方法是Bagging(如随机森林)。它们的核心区别在于:
-
Bagging :基学习器之间并行生成,通过有放回抽样制造不同训练子集,彼此独立,最后用平均或投票降低方差。各模型没有前后依赖,样本权重始终相等。
-
Boosting :基学习器串行生成,后一个模型依赖前一个,样本权重随迭代不断变化,目标是降低偏差。它是一环扣一环的错误修正链。
Boosting 是一轮一轮串行学习,每轮更关注上一轮犯错的样本,最后加权投票得出结果。
第二部分:核心算法------AdaBoost从零构建
2.1 AdaBoost的问题设定
在推导算法之前,我们需要先明确 AdaBoost 面对的是什么样的"考卷"。
二分类问题:标签必须用 +1 和 -1
AdaBoost 是为二分类设计的。为什么标签必须是 +1 和 -1,而不是常见的 0 和 1?
因为后面权重更新时要用到乘法:样本真实标签 yi乘以模型预测值 G(xi)∈{−1,+1}。如果它们一致,乘积为 +1;如果不一致,乘积为 −1。这个性质会让公式变得异常简洁。
所以,在整个 AdaBoost 中,所有标签都统一约定为 y∈{−1,+1}
训练数据集与样本权重
给定训练数据集 T={(x1,y1),(x2,y2),...,(xN,yN)},其中 xi 是样本特征,yi∈{−1,+1}
每个样本 i被分配一个权重 wi,代表它在这一轮训练中的重要性。
权重是 AdaBoost 的灵魂:初始时所有样本权重相等,随后每轮根据分类结果动态调整。
弱分类器集合
我们需要提前选定一个"弱分类器池"。弱分类器可以任意简单,只要它能在加权训练集上得到一个错误率低于 0.5 的分类结果。
最常用的弱分类器是决策树桩:仅仅基于某一个特征的某个阈值做一次分割。比如:"如果特征 x(1)>v,预测 +1,否则预测 -1"。它只有两个叶子节点,极其简单。
AdaBoost 解决的是如何用一堆简单切割线,通过改变样本重要程度,组合成一个复杂分类边界的问题。
2.2 算法步骤------逐原子拆解
AdaBoost 的核心逻辑是一个循环迭代过程。让我们逐层剖析它的数学灵魂:
输入:训练数据集 T,弱学习算法,迭代次数 T(这里的 T 不是数据集,是总轮数,后面会混用,请留意上下文)。
步骤 1:初始化权重分布
w1i=1N,i=1,2,...,N
第一轮开始前,所有样本平起平坐,每个样本的重要性都一样。如果 N=10,那么每个 w1i=0.1
步骤 2:循环 m=1 到 T 轮
(a)用当前权重分布 Dm训练一个弱分类器 Gm(x)
这里的"训练"是指,从弱分类器池中选出一个在加权 错误率意义上表现最好的分类器。
弱分类器 Gm(x)Gm(x) 的输出必须是 −1或+1。它不需要完美,只要在当前权重下错误率小于 0.5 即可。
如果找不到错误率小于 0.5 的分类器,算法终止------说明弱学习器已经无法在现有权重下学到任何东西。
(b) 计算加权错误率 : 将该分类器所有分错的样本的权重加起来。
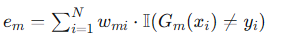
注意,这里不是简单数错几个样本,而是每个分错的样本用它的权重来惩罚。权重大的样本分错了,对 em 的贡献就大,迫使这一轮算法必须优先迁就它们。
(c) 计算分类器的"话语权" : 表现越好的分类器,在最终投票时权力越大。公式如下:
(注:当错误率 小于 0.5 时,
为正;错误率越小,
越大。)
αm 直接度量了这个弱分类器的可信度,错误率越低,它在最终决策中的声音越大。
(d) 更新样本权重: 这是 AdaBoost 的点睛之笔。分对的样本权重降低,分错的样本权重指数级放大:
-
被分错的样本,新权重等于老权重乘以
-
被分对的样本,新权重等于老权重乘以
分对的样本权重会缩小,分错的样本权重会放大。放大和缩小的倍数恰好关于 1 对称。
e) 归一化权重: 把所有更新后的权重相加得到一个总和,然后让每个样本的新权重除以
,确保所有样本的权重之和重新等于 1。
3. 构建最终强分类器
将 轮得到的弱分类器按各自的"话语权"加权求和,然后套上符号函数
sign() 做出非黑即白的判决:
最终分类结果:
假设有 10 个样本,初始权重皆为 0.1。
-
第 1 个弱分类器
切了一刀,错了 3 个样本,对了 7 个样本。
-
算错误率
-
算话语权
-
更新权重:
-
分错的 3 个样本,权重从 0.1 放大为
-
分对的 7 个样本,权重从 0.1 缩小为
-
-
归一化后,下一轮模型将死死盯住那 3 个权重变大的错题。
一句话解释:AdaBoost 的每一轮,错误率低的分类器得到更大投票权,同时分错的样本会被放大权重,逼着下一轮分类器重点关注它们。
2.3 权重更新公式的直观意义
为什么样本权重要用 指数函数来更新?看似突兀的公式背后,其实隐藏着优雅的数学本质:这等价于指数损失函数下的梯度下降。
为了避免分情况讨论(分错乘正指数,分对乘负指数),李航老师在书中给出了一个极其优美的统一形式:
如何直观理解这个式子?
-
当模型预测正确时,
-
当模型预测错误时,
如果把样本看成一个个气球,初始时大家一样大。随着迭代进行,那些总是被分对的气球会越来越干瘪,直至微乎其微;而那些处于分类边界上、极其顽固的"边缘样本"则像被打满气的巨大探空气球,牢牢占据了下一轮模型视野的绝对 C 位。
一句话解释:权重更新的本质是让模型的指数损失逐轮下降,让之前被误判的样本在后续训练中地位越来越高。
第三部分:AdaBoost 为什么有效------训练误差分析
在上一部分我们亲手跑通了 AdaBoost 的一轮迭代,看到权重如何变化、话语权如何分配。但一个核心疑问还没解开:凭什么保证这种不断叠加弱分类器的过程最终一定能得到一个好模型? 它会不会像无头苍蝇一样,一轮轮训练却永远无法收敛?这一部分,我们用数学定理来给出坚实的答案。
3.1 训练误差的上界定理
AdaBoost 能够把弱学习器提升为强学习器,这不是靠玄学,而是有极其严密的数学保证。李航老师在书中给出了一个非常漂亮且令人安心的定理:AdaBoost 最终分类器的训练误差是有上限的,并且这个上限会随着迭代次数呈指数级下降。
核心推导拆解:
-
我们先定义一个变量
-
因为弱分类器只要"比瞎猜好一点",所以
-
通过利用指数损失不等式的放缩技巧,可以推导出 AdaBoost 训练误差的一个理论上界:
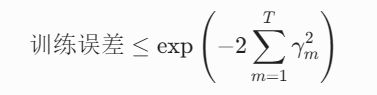
我们不需要记住每一步推导,只需要牢牢记住结论:只要 γmγ 有正的下界,训练误差就以指数速度下降。
生动实例:感受指数下降的威力
假设我们找到的弱分类器真的很"弱",每次的错误率都是 0.4(只比瞎猜的 0.5 好了 0.1)。
此时 ,那么
。
如果我们让机器咬牙坚持迭代 400 轮(T = 400),代入公式算一下训练误差的上限:
看!即使每个模型都这么差,只要积少成多迭代 400 次,整个集成模型的训练错误率就被硬生生压低到了万分之三左右。
一句话解释:只要每一轮弱分类器都比随机好一点点(
哈哈哈哈这玩意儿也算复利了。
3.2 从误差界看 AdaBoost 的抗过拟合特性
按照传统机器学习的"偏差-方差"直觉,模型不断复杂化(增加迭代轮数 T),训练误差逐渐变小,但测试误差应该先降后升,即出现过拟合。然而,AdaBoost 经常展现出一种"反常"现象:即使训练误差已经降为零,继续增加弱分类器,测试误差仍然可能继续下降。这该如何解释?
AdaBoost 似乎有一种神奇的"免疫力",它很难过拟合!
-
反常现象: 在真实的实验中,往往迭代到第 100 轮时,AdaBoost 的训练误差就已经降到了 0。但如果我们不停止,继续强行加码,迭代到 500 轮、1000 轮,它的测试误差居然还在继续下降!
-
直观解释: 学术界用"间隔理论"解释了这一现象。什么是间隔(Margin)?简单说就是样本点距离分类边界的远近。距离越远,分类越安全、越确定。
-
当训练误差降为 0 时,意味着所有样本都被分对了。但 AdaBoost 并没有满足,后续的迭代(增加更多弱分类器)虽然不能再减少错误数,但它在不断把分类边界推离样本点,使得分类间隔(Margin)越来越大。
最早的 AdaBoost 论文中,Schapire 等人用 UCI 的"letter"数据集进行实验。弱分类器采用非常简单的决策树桩。随着迭代轮数从 1 增加到 1000:
-
训练误差在约 10 轮后就降到了 0。
-
但测试误差仍然从 20% 左右持续下降到约 6%,之后缓慢趋平,直到 1000 轮也没有出现明显的上升。
如果按照传统的过拟合理论,训练误差变零后,继续增加模型复杂度必然导致测试误差急剧上升。然而 AdaBoost 却能一直"精进"。这种现象只能用间隔理论来解释:后期增加的弱分类器虽然没有纠正任何样本的分类结果,但它们调整了各个样本的间隔,使得分类边界更加稳健。
一句话解释:即使训练误差已经为零,继续增加弱学习器数量往往还能提高泛化能力,因为模型在加大分类边界(间隔)。
第四部分:统一视角------前向分步算法与加法模型
4.1 加法模型
为了从更高的维度理解 Boosting,统计学家们提出了一个通用的数学表达式,叫做加法模型(Additive Model)。
它的标准形式非常简单:
-
-
如果我们把 AdaBoost 套进这个公式,一切就严丝合缝了:
AdaBoost 中的弱分类器 就是基函数
;而计算出来的话语权
就是系数
。所以,Boosting 本质上就是一个加法模型。
一句话解释:加法模型就是用一堆简单函数的加权和来逼近复杂的决策函数。
4.2 前向分步算法
既然知道了模型长什么样,下一个问题是:怎么求解它的参数?
如果要同时优化这 M 个模型的全部参数(所有的和
),计算量是天文数字(NP-hard 问题)。为了解决这个灾难,大师们提出了一个极其聪明的贪心策略------前向分步算法
-
核心思想: 走一步看一步。既然同时优化太难,那我就一次只学一个模型。
-
优化目标: 假设前
生动实例:手工拼装的流水线
这就好比你要造一台极其复杂的机器。你不可能一口气把几千个零件同时拼好。前向分步算法的做法是:昨天拼好的底盘()今天绝不拆开重来,今天只考虑怎么把眼前这个新齿轮(
)以最佳的角度装上去,让机器的整体运转误差(L)降到最低。
一句话解释:前向分步是"走一步看一步"的贪心优化,每次只学习一个新基函数并加到已有模型里。
4.3 用指数损失函数推导AdaBoost
这是李航老师书中非常精彩的"高光时刻"。前向分步算法是一个万能框架,如果我们在里面填入不同的"损失函数"和"基函数",就能推导出各种名震江湖的算法。
那么,如果损失函数是指数函数,基函数是分类器,会发生什么?
奇迹出现了,你推导出来的就是原汁原味的 AdaBoost!
推导的核心点拆解:
-
明确目标: 在第 m 步,我们要最小化
-
提取权重: 我们可以把前半部分
-
推导最优的基分类器
-
推导最优的系数
生动实例:重新认识第二章
在第二部分中,我们似乎是凭空给出了计算 和更新权重的公式。但通过前向分步算法的推导,你会发现这一切都不是拍脑袋想出来的。只要你坚持要让模型的"指数损失"在每一轮下降得最快,数学公式会自动指引你走到 AdaBoost 的步骤上去。
一句话解释:AdaBoost 等价于用指数损失函数,通过前向分步方式逐步累加弱分类器的算法。
在第四部分,我们把 AdaBoost 重新解读为"加法模型 + 前向分步 + 指数损失 "的组合。
这个框架的美妙之处在于:只要换一个损失函数、换一种基函数,你就能得到全新的 Boosting 算法。
这就自然地引出了提升树 ------一个将基函数固定为决策树,然后根据不同任务选择不同损失函数的经典 Boosting 方法。它既是 AdaBoost 的扩展,也是后面梯度提升的前身。
第五部分:从分类到回归------提升树(Boosting Tree)
5.1 提升树模型
提升树,顾名思义,就是把 Boosting 框架里的"弱学习器"严格限定为决策树(通常是 CART 树)。
基于我们在第四章学到的"前向分步算法"框架,提升树可以极其优雅地处理两类问题:
-
分类问题: 当我们使用"指数损失函数"时,分类提升树在数学上就完全等价于以决策树为基础分类器的 AdaBoost。
-
回归问题: 当我们使用"平方误差损失函数"时,提升树的优化目标会变得极其直观,它演变成了一个不断拟合残差的过程。
一句话解释:提升树就是将弱学习器换成决策树的 Boosting 方法,回归时每步拟合残差。
5.2 回归问题提升树:残差拟合
回归问题的核心是让预测值尽可能逼近真实值。在数学上,我们最常用的衡量标准是平方损失函数:
在第 步的前向分步算法中,我们要寻找一棵新的决策树
,使得它加上前一轮的总模型
后,平方损失最小:
重点来了!如果我们令 ,上面的公式就变成了:
这里的 就是残差(Residual) 。这就意味着,第
棵树根本不需要去管原始标签
是什么,它唯一的任务就是去拟合上一轮模型留下来的"残差"。
算法步骤拆解:
-
初始化:
-
循环 M 轮:
-
算残差: 对于每个样本
-
建新树: 用训练数据
-
大更新: 将这棵新树加入总模型,
-
-
输出最终模型:
生动实例:年龄与身高的残差接力赛
假设我们有 5 个孩子的数据,特征是年龄,标签是身高:
-
年龄 X:
[10, 20, 30, 40, 50] -
身高 Y:
[140, 160, 170, 175, 180](平均值是 165) -
第 0 轮: 我们的初始模型太笨了,统一预测所有人的身高为平均值 165。
此时的残差
-
第 1 轮: 第一棵树只看残差。它发现 25 岁是个好切分点,小于 25 岁的平均残差是 -15,大于 25 岁的平均残差是 +10。
更新总预测值:年龄<25岁的预测为
-
第 2 轮计算新残差: 真实的 Y 减去现在的预测值。比如 10 岁孩子,真实 140,预测 150,新残差变为 -10(比之前的 -25 缩小了!)。新的残差表变成了
[-10, 10, -5, 0, 5]。 -
下一棵树: 继续盯着这个新的残差表去训练,不断修补,直到残差逼近于 0。
5.3 分类问题提升树简述
既然说到了回归问题,为了知识体系的完整性,我们简单闭环一下分类问题的提升树。
在分类问题中,如果我们决定使用指数损失函数 ,由于前向分步算法的数学性质,整个过程在代数推导上会完全收敛到我们第二章所讲的 AdaBoost 算法上。
区别仅仅在于:一般的 AdaBoost 可以用任何弱分类器(比如逻辑回归、甚至简单的神经网络),而"分类提升树"则是硬性规定了底层必须是一棵棵的分类决策树。
一句话解释:分类提升树在指数损失下,就是"以决策树为弱分类器的 AdaBoost"。
第六部分:更强大的通用武器------梯度提升(Gradient Boosting)
在上一章我们看到,回归提升树通过"拟合残差"巧妙地解决了平方损失下的回归问题。但现实世界充满了意外,如果我们的数据里有几个极端的异常值(Outliers),平方损失就会把误差放大,导致模型被带偏。这时候我们就需要更换损失函数。这就引出了 Boosting 家族真正的"六边形战士"------梯度提升(Gradient Boosting)。
6.1 为什么需要梯度提升
提升树(Boosting Tree)虽然好用,但它有一个致命的弱点:它太依赖"残差"了。
-
平方损失的特权: 当我们使用平方损失
-
一般损失的困境: 如果为了抵抗异常值,我们换成绝对损失
假设真实身高是 170,当前预测是 160。
如果是平方损失,下一棵树要拟合的目标就是 170 - 160 = 10。
但如果是绝对损失,数学推导会卡壳,因为绝对值函数的导数是不连续的,我们没法直接让下一棵树去拟合那个简单的差值。我们需要一种通用方法,能告诉下一棵树:"无论用什么损失函数,你顺着这个方向去拟合,就能让整体误差变小"。
一句话解释:梯度提升将"拟合残差"推广为"拟合损失函数的负梯度",使得任何可微损失函数都能套用 Boosting 框架。
6.2 负梯度作为残差的近似(伪残差)
1999 年,机器学习大神 Jerome Friedman 提出了一个极其天才的想法:既然没法直接算残差,那我们就用损失函数的"负梯度"来代替残差! 在微积分中,负梯度永远指向函数下降最快的方向。Friedman 把整个集成模型 想象成一个参数,计算损失函数对
的偏导数。
对于第 轮的第
个样本,负梯度(我们称之为伪残差
)的计算公式为:
生动实例:用负梯度验算平方与绝对损失
-
对于平方损失
求导得
加上负号,负梯度恰好等于
-
对于绝对损失
当
这就意味着,下一棵树不需要去拟合具体的误差数值,只需要拟合误差的"符号"(方向)即可。这极大地降低了极端异常值对模型的影响。
一句话解释:每一轮的伪残差就是损失函数对当前模型输出的负梯度,它就像指南针,告诉新树该往哪个方向修正错误。
6.3 梯度提升算法完整步骤(GBDT)
现在,我们将这个思想落地,这就是工业界赫赫有名的 GBDT(Gradient Boosting Decision Tree,梯度提升决策树)。
算法步骤逐原子拆解:
-
初始化常数模型: 找一个能让初始整体损失最小的常数值
-
循环迭代
-
(a) 算负梯度(伪残差): 计算所有样本的
-
(b) 拟合新树: 把
-
(c) 计算最优叶子输出值: 对每个叶子节点,寻找一个能让该区域内样本损失最小的输出值
-
(d) 更新模型: 将这棵树加入总模型中。
-
-
最终输出
生动实例:绝对损失下的一轮计算
假设有 5 个样本,当前模型预测全为 165。真实值是 [140, 160, 170, 175, 250(异常值)]。
使用绝对损失,算出的负梯度(伪残差)是:[-1, -1, 1, 1, 1]。
新树去拟合这个 [-1, -1, 1, 1, 1]。你发现了吗?那个 250 的极端异常值,在伪残差的世界里,被降维成了一个普通的 1。这就是梯度提升更换损失函数后展现出的强大鲁棒性。
一句话解释:梯度提升每次拟合损失函数的负梯度,本质上是在做"函数空间里的梯度下降",通过一步步修正来构造强模型。
6.4 梯度提升与提升树的统一
学到这里,我们可以做一次大一统了。
-
当损失函数是平方损失 时,梯度提升等价于回归提升树。
-
当损失函数是指数损失 时,梯度提升(在某种近似下)等价于 AdaBoost。
-
当损失函数是对数似然损失、绝对损失、Huber损失时......它就是那个万能的 GBDT。
生动实例:武学宗师的境界
如果说 AdaBoost 是降龙十八掌(专破二分类),回归提升树是独孤九剑(专破平方残差),那么 Friedman 提出的"梯度提升"框架就是《九阳神功》。只要你有了这个内功心法(负梯度代替残差),任何外功招式(各种奇怪的损失函数)你都能信手拈来,完美融合进 Boosting 的体系中。
一句话解释:提升树是梯度提升在平方损失下的特例,而梯度提升是整个 Boosting 思想向任意可微损失函数的终极推广。