从"多库掣肘"到"一库平川":金仓KingbaseES的融合数据库深度体验
说实话,干数据库架构师这行超过十年,我见过太多技术选型上的"大干快上"和"尾大不掉"。
早些年,大家信奉"专业的事交给专业的库"。于是,核心交易用Oracle,用户行为日志扔给MongoDB,物联网设备监控塞进InfluxDB,空间数据用PostGIS,到了AI时代还得再搭个Milvus做向量检索。结果就是,开发团队要维护五六套API,运维要监控七八种集群,最头疼的是做跨源分析------写个关联查询比"996"还累,数据同步的延迟和一致性问题就像悬在头上的达摩克利斯之剑。
直到深度参与了一个省级能源集团的"数据底座"统型项目,全流程跑通了电科金仓KingbaseES ,我才真正体会到什么叫" 融合数据库 "。它不是简单地把几个开源项目打包成一个安装包,而是从内核层面重新定义了"一库多能"的可能性。今天,想以一个真实使用者的身份,聊聊KingbaseES是如何帮我从"多库掣肘"的泥潭里挣脱出来的。 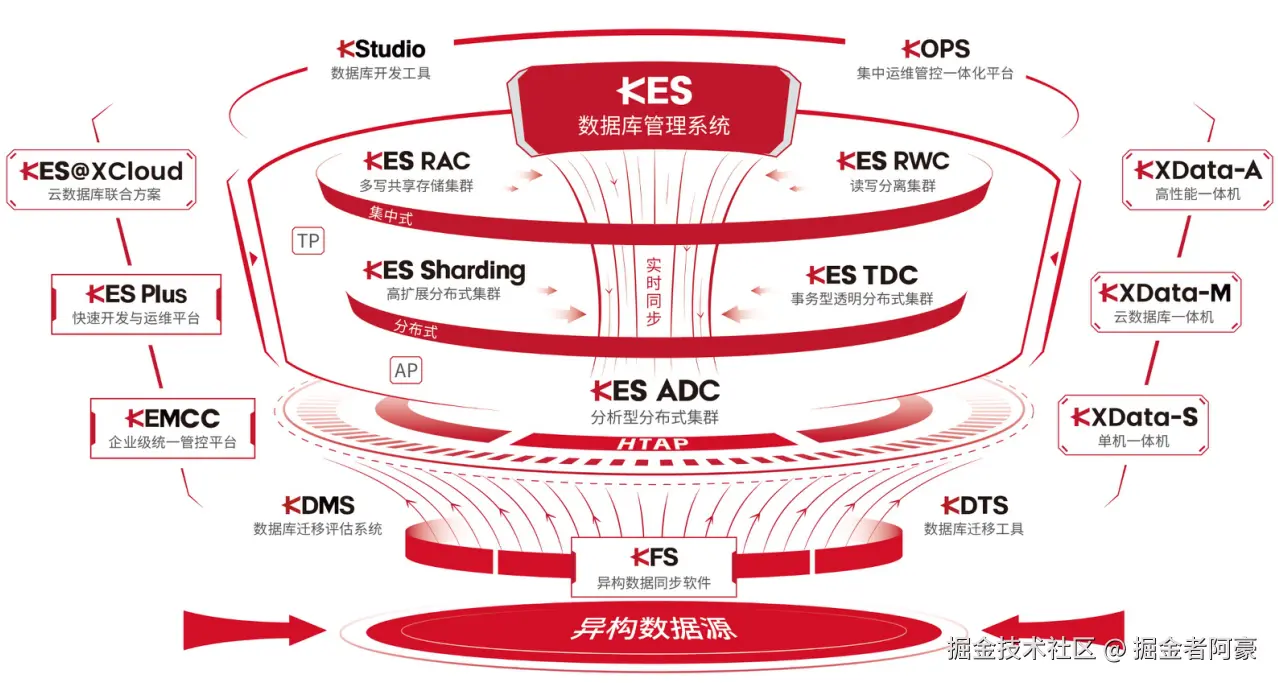
一、当我们在谈"融合"时,到底在谈什么?
很多厂商谈融合,其实是"拼盘"------JSON存不好就挂个MongoDB的壳,时序跑不快就套个InfluxDB的驱动。但金仓的做法不太一样,它的核心理念叫 "五个一体化" 。
用人话翻译一下就是:用一套标准,管所有数据;用一种语法,查所有模型;在一个集群,跑所有负载。
在最新的V9版本中,这种架构体现得尤为明显。它不是通过外部插件去适配,而是在统一的内核里,原生跑起了关系行存、列存分析、时序引擎、GIS空间和向量检索引擎 。这就好比以前我们的厨房里堆满了各种专用的厨具(榨汁机、烤箱、蒸箱),现在换成了一个集成了所有功能、而且共享同一套水槽和燃气系统的"集成灶"。
二、实战验证:那些让我惊艳的"一库多能"场景
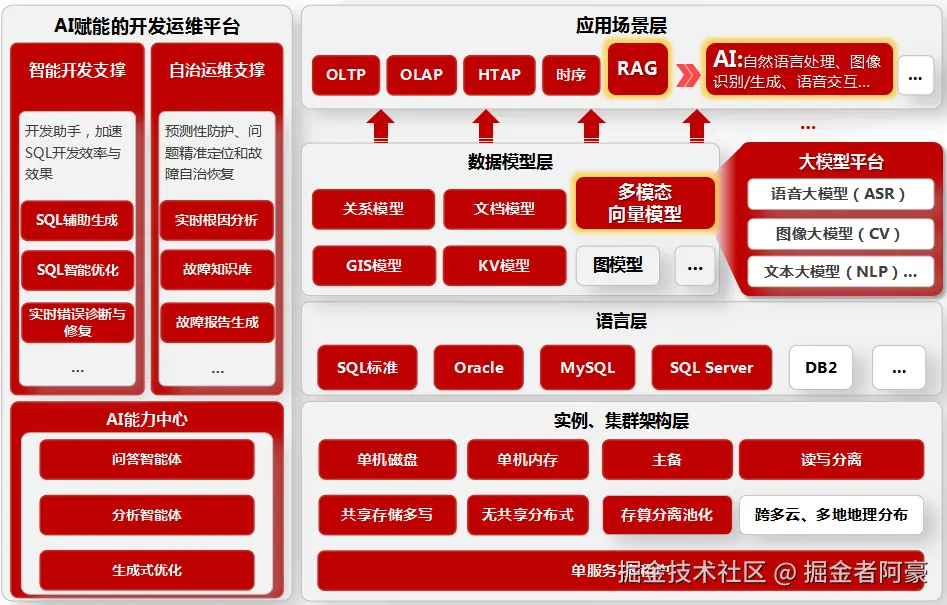
理论说再多,不如直接看代码和效果。在我们这次项目中,重点验证了几个典型场景,确实有点东西。
场景一:MongoDB协议兼容,电子证照系统"零改造"迁移
我们有一个电子证照系统,原基于MongoDB开发,存量数据几十TB,每天新增近千万条记录。按信创要求必须替换,但那套代码跑了五六年,没人敢动。
金仓的方案很巧妙。它不是把MongoDB的JSON数据导进来就完事,而是通过内核级的协议兼容,直接支持了MongoDB的Wire Protocol。
这意味着什么?这意味着我们的Java应用,连MongoDB驱动都不用换,只需要修改一下连接串的IP和端口,应用依然以为自己在跟MongoDB对话,但底下支撑的已经是具备完整ACID事务能力的KingbaseES了。
java
// 原有的 Java 代码,完全不用改
MongoClient client = MongoClients.create("mongodb://kingbase-host:27017");
MongoDatabase db = client.getDatabase("gov_db");
MongoCollection<Document> coll = db.getCollection("certificates");
// 插入一条带嵌套文档的数据
Document doc = new Document("cert_id", "CERT20250312001")
.append("holder", "某科技有限公司")
.append("attachments", Arrays.asList(
new Document("type", "pdf").append("hash", "abc123"),
new Document("type", "xml").append("hash", "def456")
));
coll.insertOne(doc);迁移效果如何? 我们配合KFS同步工具做了双轨并行验证,一周的灰度观察期内,写入吞吐量比原MongoDB集群还提升了约15%,复杂聚合查询(如按附件类型统计)更是快了近3倍。最关键的是,借助金仓原生的高可用能力,故障恢复时间从MongoDB的分钟级缩短到了RTO < 30秒 。
场景二:时序+GIS融合,一条SQL解决智慧交通"老大难"
以前我们在做车联网平台时,经常遇到这样的需求:"找出过去1小时内在某个商圈500米范围内停留超过10分钟的所有车辆"。
传统架构下,这需要先调时序库查轨迹,再把结果集拿到空间库做GIS计算,最后在应用层做Join和去重,代码复杂且效率极低。
在金仓里,由于时序引擎和GIS引擎共享同一套数据存储和计算资源,这就变得异常简单。
sql
-- 建表:一张表融合关系、时序、GIS
CREATE TABLE vehicle_track (
device_id BIGINT,
vehicle_no VARCHAR(20),
track_time TIMESTAMPTZ NOT NULL, -- 时序列
location GEOMETRY(POINT, 4326), -- 空间列
speed NUMERIC,
status JSONB -- 文档列,存车辆状态详情
) PARTITION BY RANGE (track_time);
-- 按天自动分区,提升时序查询性能
CREATE TABLE vehicle_track_20250312 PARTITION OF vehicle_track
FOR VALUES FROM ('2025-03-12') TO ('2025-03-13');
-- 查询:最近1小时,在指定商圈500米内停留超过10分钟的车
SELECT
device_id,
vehicle_no,
ST_AsText(location) as last_loc,
MAX(track_time) - MIN(track_time) as stop_duration
FROM vehicle_track
WHERE track_time > NOW() - INTERVAL '1 hour'
AND ST_DWithin(
location,
ST_GeomFromText('POINT(116.40 39.90)', 4326),
500
)
GROUP BY device_id, vehicle_no, DATE_TRUNC('minute', track_time)
HAVING MAX(track_time) - MIN(track_time) > INTERVAL '10 minutes';这个查询如果放在过去,可能需要写几百行Java代码调用不同的SDK。现在,一切都在数据库内核里完成。金仓的优化器能识别出ST_DWithin是空间操作,自动选择空间索引;识别出track_time是时序分区键,自动进行分区裁剪。实测在10亿级数据量下,这种查询响应时间能控制在1.5秒以内 。
场景三:向量检索加持,让RAG应用不再"精神分裂"
做大模型RAG最怕什么?怕业务数据和向量数据分离。用户问"我的订单为什么还没发货",你得先查向量库找相似问题,再查交易库核对订单状态,跨库操作麻烦不说,还容易出幻觉。
金仓直接把向量类型做进了内核,支持HNSW、IVFFlat等主流索引,让向量检索和业务数据检索可以在同一个事务里完成 。
sql
-- 建表:商品信息 + 图片特征向量
CREATE TABLE products (
id BIGINT PRIMARY KEY,
name VARCHAR(255),
category VARCHAR(50),
price NUMERIC,
image_vector VECTOR(512) -- AI模型提取的图片特征
);
-- 创建 HNSW 索引加速向量检索
CREATE INDEX idx_product_img
ON products
USING hnsw (image_vector vector_cosine_ops);
-- 混合检索:找"电子产品"类别下,和上传图片最像的前10个商品
SELECT
name,
price,
1 - (image_vector <=> '[0.12, 0.34, ... , 0.89]'::vector) AS similarity
FROM products
WHERE category = 'Electronics' -- 先用标量过滤
AND price < 5000
ORDER BY image_vector <=> '[0.12, 0.34, ... , 0.89]'::vector
LIMIT 10;这个<=>操作符是向量余弦距离计算。对于电商平台做"以图搜图"或者企业知识库做RAG,这种能力大大简化了技术栈。我们用百万级商品数据测试,单次检索延迟稳定在80ms以内,完全满足生产要求。
三、不只是"能跑",更是"好用":那些让DBA直呼真香的细节
作为一个从Oracle时代过来的DBA,我对工具的敏感度甚至高于数据库内核。金仓在这方面,确实下了功夫。
1. 开发体验:兼容性不是口号 我们团队核心成员多是Oracle背景。在KingbaseES里,我们可以继续写PL/SQL,用CONNECT BY做层次查询,用%ROWTYPE做变量声明,甚至DECODE函数都能直接跑 。这种"无感切换"大大降低了团队的学习成本。对于MySQL背景的同事,开启--compatible=mysql模式后,连LIMIT分页语法都能原生支持 。
2. 运维体验:从"盲人摸象"到"上帝视角" 以前排查慢SQL,基本靠猜。现在用KStudio自带的执行计划可视化,哪个步骤走了全表扫描,哪里出现了数据倾斜,一目了然。配合KEMCC统一管控平台,我们可以实时监控整个集群的健康状态,甚至能看到"过去一周哪些JSONB字段被频繁查询",从而决定是否需要为这些字段创建生成列和索引 。
3. 迁移工具:真正的"搬家公司" 以前做数据库迁移,最怕的是写各种脚本去校验数据一致性。金仓的KDMS迁移评估工具非常实用,它能直接连接源库(Oracle/MySQL/Mongo等),自动评估迁移工作量,甚至能给出改写建议 。我们在做某财务系统Oracle迁移时,两千多个存储过程,KDMS评估的自动转换率达到了92%,剩下8%需要手动调整的地方,工具也明确标出了位置和原因。
四、冷静聊聊:融合数据库的边界在哪里?
作为技术人,我们不能为了吹而吹。金仓确实很强,但它不是万能的。
-
适合什么场景?
- 混合负载严重的企业:既有高并发交易,又有实时报表,还有多模数据关联查询需求的(如金融风控、政务大数据)。
- 希望精简技术栈的团队:受够了维护多套数据库的痛苦,希望用一套技术栈覆盖80%以上场景。
- 信创替代的核心系统:需要高可用(RPO=0,RTO秒级)、高安全(等保四级、国密支持)的场合 。
-
不适合什么场景?
- 极致的全文搜索:虽然金仓支持全文检索,但如果是类似Google那样的搜索引擎场景,Elasticsearch依然是不二之选。
- 超大规模图计算:如果是千亿级节点和边的社交图谱分析,专业的图数据库(如Neo4j)在算法丰富度上可能更有优势。
写在最后
从1999年成立,到如今成为数据库领域的"国家队",电科金仓给我的感觉一直是低调务实 。在融合数据库 这条路上,KingbaseES没有停留在概念层面,而是通过多模数据一体化存储、多语法体系一体化兼容、集中分布一体化架构这"三板斧",真正解决了企业级用户在数字化转型中遇到的实际痛点 。
如果你也正被"数据孤岛"和"技术栈臃肿"所困扰,不妨去他们的官网看看。无论是想了解最新的技术白皮书,还是下载试用版亲自验证,我相信,金仓数据库都会给你带来不一样的惊喜。毕竟,在这个追求降本增效的时代,用一个库解决大部分问题,远比维护一堆"瑞士军刀"要明智得多。
官网链接:kingbase.com.cn