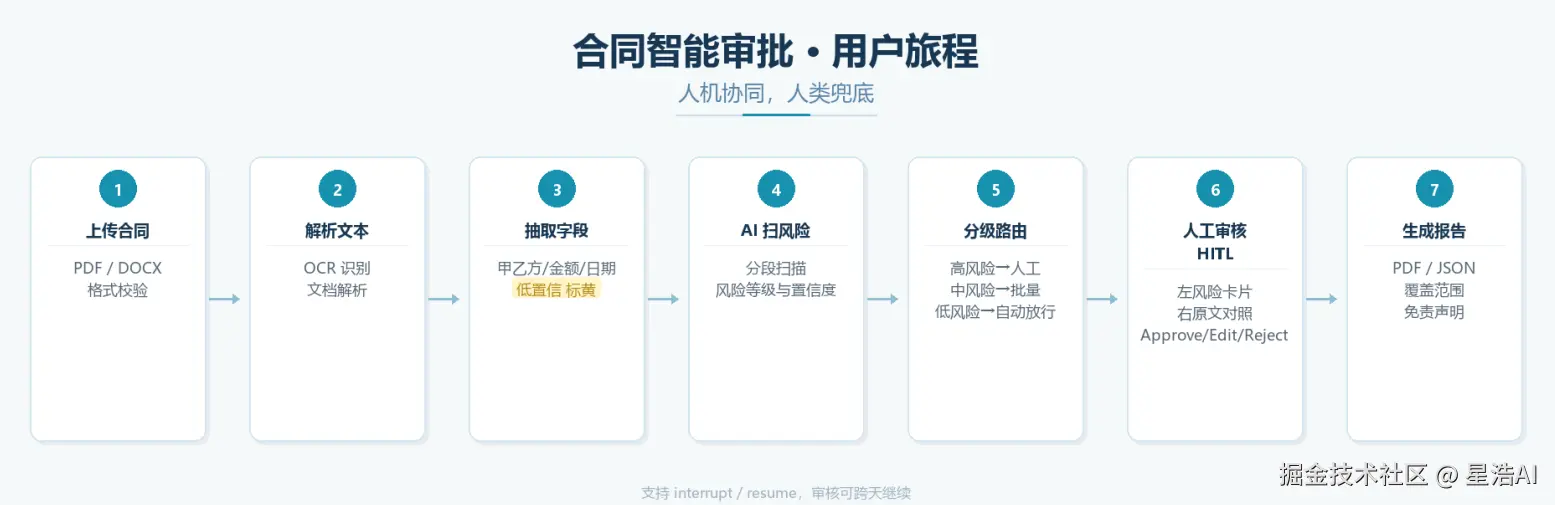
合同流程:上传 PDF/DOCX → 解析并抽取甲乙方、金额、日期 → AI 扫风险、按高/中/低分级 → 法务确认关键条款(高风险逐条审,中风险可批量)→ 生成审核报告。
需要配套源码和数据集的同学,可以点赞 + 关注,我会把完整工程发给你。
要解决什么问题?
企业做法务合同审核,有个结构性矛盾:量一大,人就审不过来;审得细,单子就堆成山 。一份中等复杂度的合同,熟手也要 2~4 小时;压缩时间,漏检率就往上走。
纯自动化也走不通------条款有模糊地带,商业意图得问业务,出了事还得查「谁在什么时候基于什么做的判断」。签字权不能交给模型,但让法务从第一页抄到最后一页找违约金,又太耗。
系统要干的事可以概括成一句:
模型做结构化提取和风险初筛,人保留对关键条款的最终控制权,全流程留痕、可审计。
| 痛点 | 现在怎么做 | 这套系统怎么帮 |
|---|---|---|
| 抄主体、找金额 | 人工逐页看 | 自动抽字段,低置信标黄让人改 |
| 找风险条款 | 通读全文 | AI 初筛 + 按高/中/低排序,双向定位原文 |
| 精力分散 | 所有条款一样看 | 三档路由,高风险强制人工 |
| 审到一半被打断 | 进度难续 | LangGraph interrupt/resume,隔天接着审 |
| 结论难溯源 | 口头或零散记录 | 每条决策落库 + 审计日志 |
| 不敢信 AI | 不知道依据 | 置信度 + 来源标签(规则 / AI) |
MVP 不碰的场景:跨境多法域合同、强监管特大单、律所对外服务------当前 Agent 能力兜不住。
谁在用?
| 角色 | 干什么 | 频率 |
|---|---|---|
| 法务审核(reviewer) | 看初筛结果,高风险逐条 Approve / Edit / Reject,导出报告 | 每天用 |
| 业务提交(submitter) | 上传合同、看进度,不做 HITL 操作 | 偶尔 |
| 管理员(admin) | 维护规则库、权限配置 | 低频 |
权限是双层的:前端路由守卫「防君子」,后端接口独立校验「防小人」------submitter 进不了 HITL 审核页,决策记录也不是谁都能看。
需求是什么?
端到端链路:
上传 PDF/DOCX → 解析抽字段 → AI 扫风险 → 分级路由 → 人工确认 → 出报告
拆成四个 MVP 场景:
场景 1:结构化提取
上传后解析文本,LLM 抽甲乙方、金额、生效日期、适用法律等字段;低置信标黄,让人核对一眼。目标是把「抄主体」从 20~40 分钟压到分钟级。
场景 2:风险初筛 + 分级路由
全文扫描,覆盖单边条款、违约金不对等、弹性表述等;每条带风险等级、置信度、原文锚点。路由规则:
- 低风险 → 自动放行
- 中风险 → 批量复核页,可勾选确认
- 高风险 → 强制 interrupt,逐条处理才能继续
场景 3:HITL 人工决策
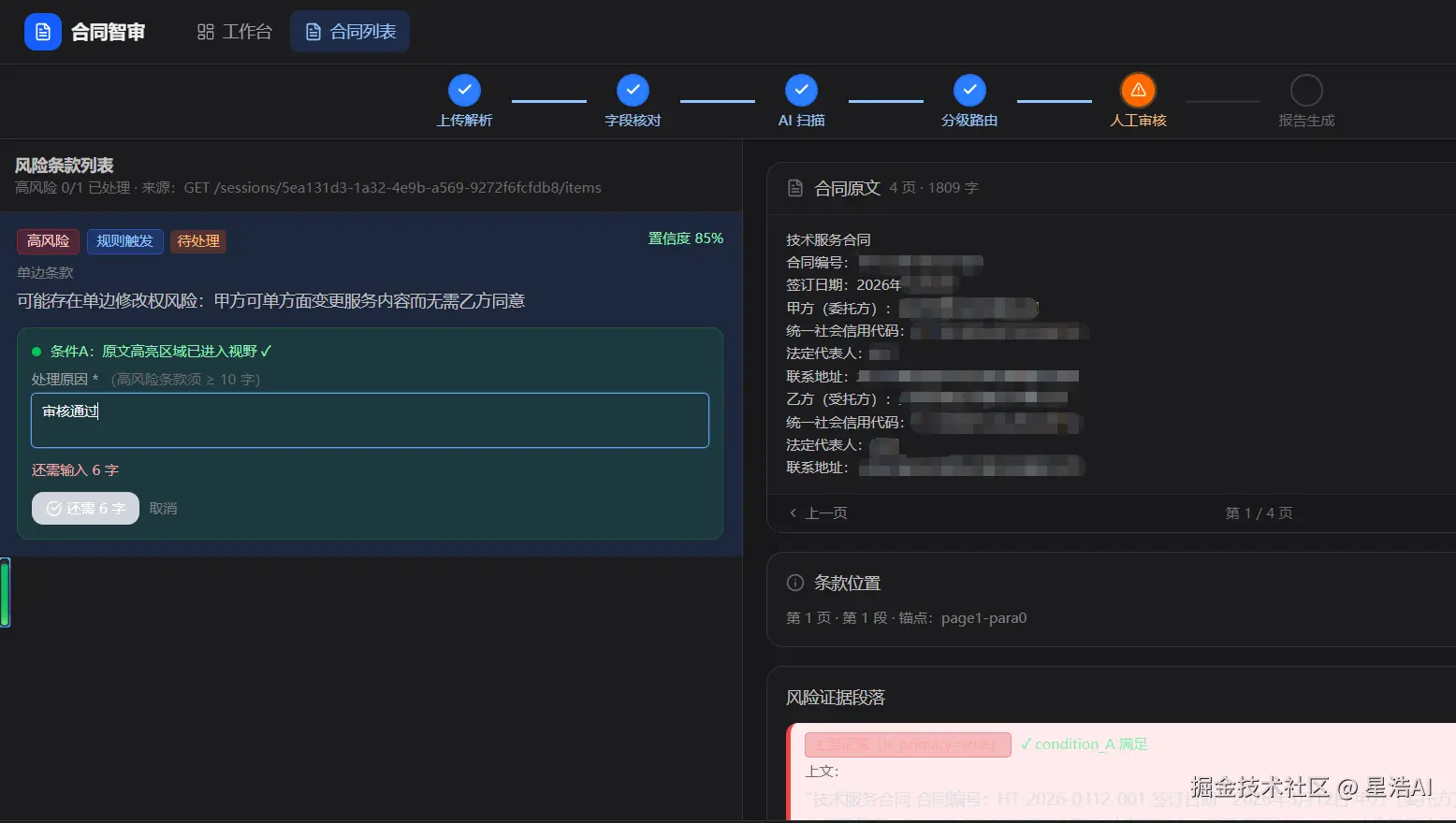
双栏对照:左卡片(风险描述 + 操作),右原文(高亮定位)。三选项:Approve (认 AI 判断)、Edit (改等级或描述)、Reject(标误报)。高风险必须填备注(≥10 字),不允许批量「全部同意」。
场景 4:报告生成
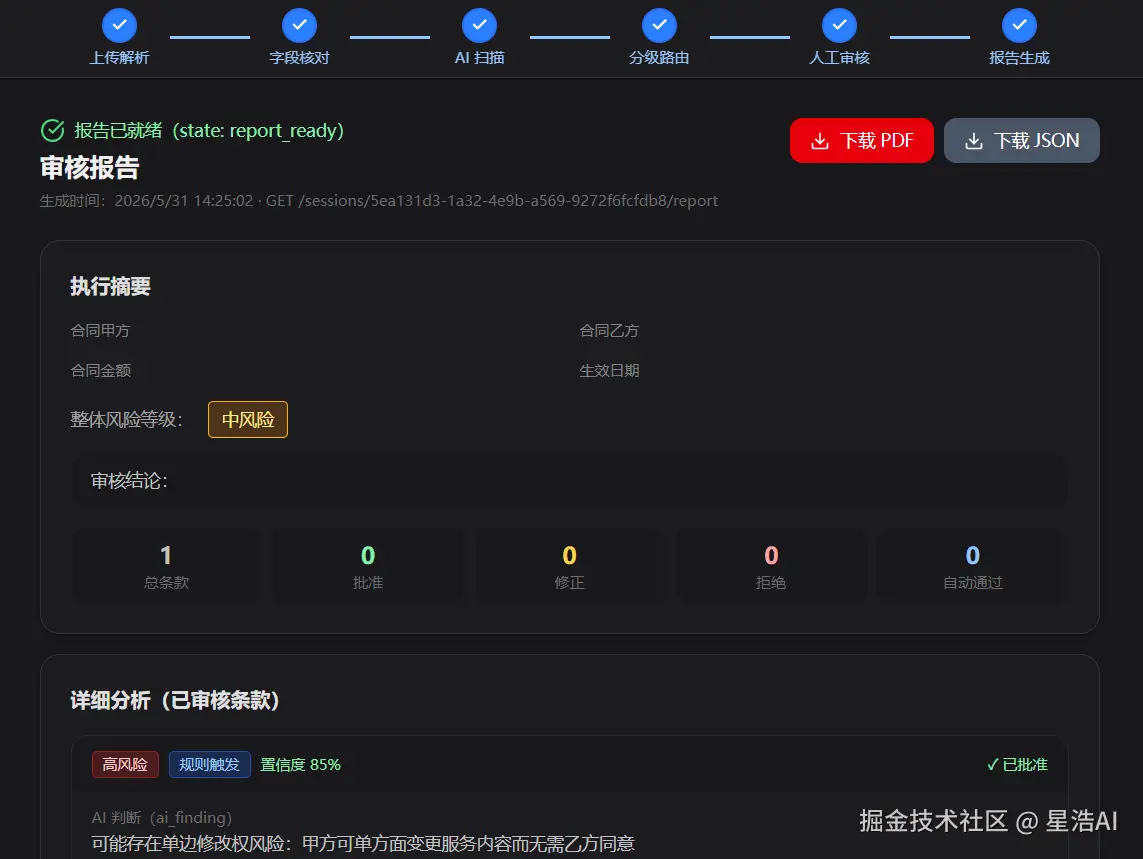
汇总 AI 判断 + 人工最终决策,带覆盖范围声明(审了啥、没审啥)和免责声明,导出 PDF / JSON。
设计红线
从业务调研和竞品分析里提炼,写进 Prompt 和交互,不能糊弄:
- 高风险必须逐条人工处理,界面层不渲染批量按钮
- AI 结论不能绝对化------「可能存在...风险」,禁止「违法」「审核通过」
- 报告必须声明覆盖范围,审了啥、没审啥写清楚
- 规则触发 vs AI 推理必须能区分(蓝标 / 紫标)
- 每步操作可追溯------AuditLog + Checkpointer
- 不做完整 CLM------只管「上传→审核→报告」,不碰电子签、模板库
- 合同原文走私有化部署,生产环境别明文扔公网 API
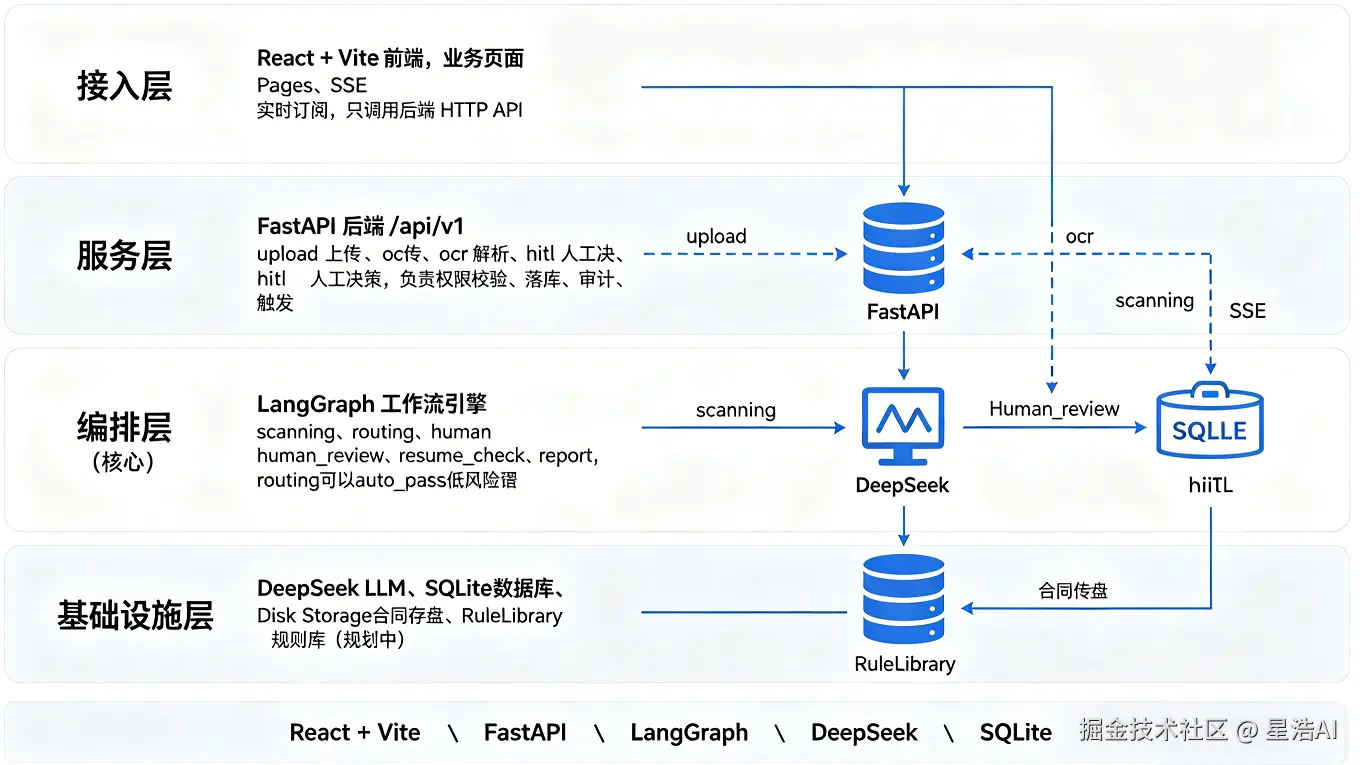
系统架构
总体思路
数据流:合同文件 → 存盘 → 解析/抽字段 → 分段扫风险 → 风险条目入库 → 人做决定(落库 + 审计)→ 校验 → 报告
控制流 :LangGraph 编排;该等人时在节点里 interrupt();决策以数据库为准 ,Checkpointer 只管流程续跑;人点齐了 Command(resume=...),经 resume_check 校验后再出报告;前端用 SSE 推进度。
规则库说明 :
RuleLibrary在数据模型和界面里已设计(Playbook、规则编码、source_type)。MVP 扫描节点以模型分段分析为主,规则引擎匹配在「后期规划」接入------接上了不用改前端交互。
后端三个模块
bash
上传模块:校验 → 存盘 → 建 Contract / ReviewSession → 调解析
↓
状态模块:LangGraph + interrupt/resume + SSE(决策落库,Checkpointer 辅助续跑)
↓
查询模块:ReviewItem / ExtractedField / ReviewReport / AuditLog 给前端读上传模块做 Magic Bytes 校验、大小限制(50MB)、加密 PDF 拦截、扫描件标记;解析和扫描解耦------解析在 LangGraph 图外面,解析挂了不会把工作流状态搞乱。
技术栈
前端 React + Vite;后端 FastAPI;工作流 LangGraph;模型 DeepSeek(OpenAI 兼容接口);数据 SQLite;合同原件存服务器磁盘。
bash
上传模块
校验 → 存盘 → 建 Contract / ReviewSession → 调解析
↓
状态模块
LangGraph + interrupt/resume + SSE(决策落库,Checkpointer 辅助续跑)
↓
查询模块
ReviewItem / ExtractedField / ReviewReport / AuditLog → 给前端读数据流(6 步)
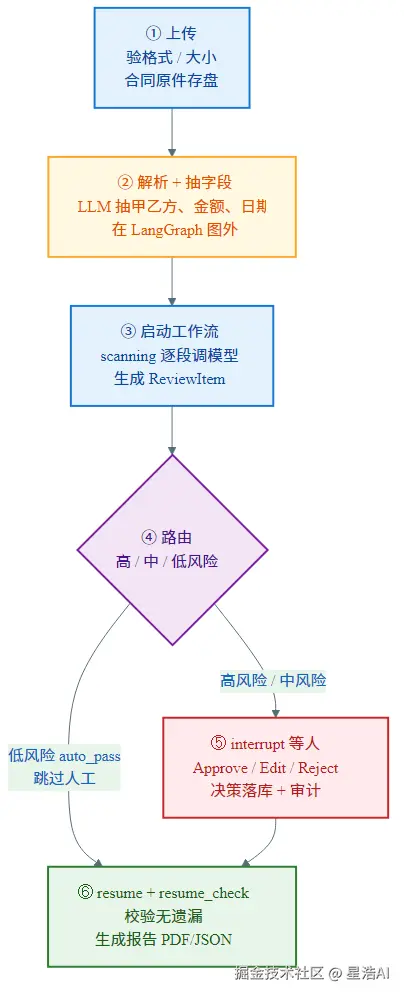
- 上传,服务端验格式、大小,合同原件存盘
- 解析拉文本,LLM 抽字段------在 LangGraph 图外面
- 解析完成后启动工作流:扫描节点逐段调模型,生成 ReviewItem
- 路由节点看高/中/低风险,决定三条路(低风险跳过人工节点)
- 该停就
interrupt,等人------每条决策先落库、记审计 - 高风险全处理完才
resume,经resume_check校验,再生成报告
lua
① 上传 → ② 解析+抽字段(图外,黄色)→ ③ 启动工作流 scanning
→ ④ 路由(菱形)
├─ 高/中风险 → ⑤ interrupt 等人(红色)
└─ 低风险 auto_pass ─────────────┐
⑤ ────────────────────────→ ⑥ resume + 报告(绿色)核心业务点
合同审核不是「调一次模型就完成」的同步任务,而是会停、会续、会分叉 的长流程------所以上了 LangGraph。竞品调研里 10 家都是「AI 先跑、人工后确认」,但跨天 interrupt/resume 几乎没对标,这是本项目最想讲清楚的技术点。
人机协作
如果只有 POST /review 同步等到底,法务下午审一半关页面,状态就没了。
LangGraph 的 interrupt() 把图冻在节点上,Checkpointer 存快照;下次 Command(resume=payload) 接着走。每个审核会话一个 thread_id,多单不混。
前端每条决策写入数据库,同时记审计日志------业务数据以库为准 ,Checkpointer 只管流程能不能续跑。高风险条款全部处理完,服务层才触发 resume。
人类兜底
模型只负责把风险点拎出来,不能替法务下定论。Prompt 限死:输出 JSON;finding 用「可能存在...」,禁止「违法」「审核通过」。
界面呈现「待你确认的风险点」,不是「AI 已经判了」。source_type 预留规则 / AI 两种来源标签------MVP 以模型推断为主,规则引擎接上后来源会真正来自 Playbook 匹配。
防 Automation Bias
HITL 最怕人形橡皮图章------界面上一键全过,底下全点同意。文档和代码里拦了几层:
- 高风险不渲染批量按钮(DOM 里就没有)
- Approve 前备注 ≥10 字,原文高亮段落得进视野
- 连续快速 Approve 会弹警示
- 后端决策接口幂等校验,重复提交拦掉
技术能拦一部分,组织培训还得跟上。
三档路由
python
if high_count > 0:
route = "interrupt" # 双栏逐条审
elif medium_count > 0:
route = "batch_review" # 批量勾选页
else:
route = "auto_pass" # 直接出报告核心代码怎么写的
工作流图
sql
START → scanning → routing → human_review → resume_check → report → END
↘ auto_pass 跳过 human_review,直接 resume_check
python
builder.add_conditional_edges(
"routing_node",
route_after_routing,
{
"auto_pass": "resume_check_node",
"batch_review": "human_review_node",
"interrupt": "human_review_node",
},
)开发期 Checkpointer 用内存实现,服务重启会丢状态;上线换数据库持久化。
人在哪介入
python
if route_result == "interrupt":
human_decisions = interrupt({
"review_type": "high_risk_review",
"session_id": state["session_id"],
"pending_item_ids": state.get("pending_item_ids", []),
"message": f"发现 {state.get('high_risk_count', 0)} 个高风险条款,请逐条审核",
})
return {"human_decisions": human_decisions}前端每条点完写入数据库;服务层检查高风险是否还有 pending------没有了才 resume:
python
def resume_workflow(thread_id: str, decisions_payload: list) -> dict:
graph = get_compiled_graph()
config = {"configurable": {"thread_id": thread_id}}
return graph.invoke(Command(resume=decisions_payload), config)扫描怎么跑
全文切成段(单段约 800 字内),MVP 逐段调 DeepSeek ,解析 JSON 写入 ReviewItem。密钥走 .env,扫描和字段抽取共用 app/config.py 的 get_llm():
python
def get_llm():
return ChatOpenAI(
model=settings.deepseek_model,
api_key=settings.deepseek_api_key,
base_url=settings.deepseek_base_url,
temperature=0.1,
)前后端边界(摘要)
| 谁 | 干什么 |
|---|---|
| 前端 | 渲染、路由守卫、SSE 订阅、防橡皮图章的 UI 约束 |
| 后端 | 业务规则、状态机、LangGraph、LLM 调用、落库、审计 |
前端不直接调模型;合同文件经后端 API 上传,不经由浏览器直传第三方。
界面效果
上传、抽取关键字段 --- 低置信标黄,让人改一眼。
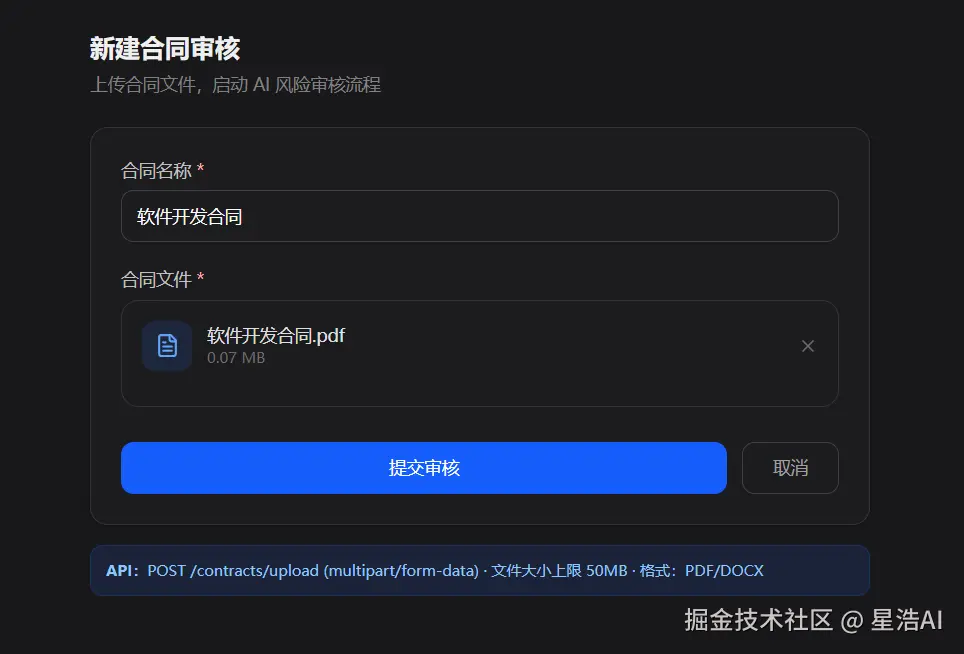
扫风险 --- 进度条跟着 SSE 走,后台扫描节点逐段分析。
人工 --- 有高风险进双栏逐条审;只有中风险进批量勾选页。
报告 --- 执行摘要 + 逐条清单 + 覆盖声明 + 免责声明,PDF / JSON 可下。
列表 --- 多份合同卡在哪一步。
从想法到能点 DEMO
- 先定红线:人机协同、人类兜底------高风险逐条过,模型只提示、不下定论
- 拆链路:上传解析留在 LangGraph 图外;扫描、路由、人工、报告装进工作流
- 落规则库 :把法务平时的 Playbook 整理进
RuleLibrary,关键词/正则先匹配,模型只扫规则没盖到的段落 - 搞通 interrupt/resume:对着 LangGraph 文档把 Checkpointer 跑起来,跨天续审才有着落
- 定交互:双栏对照、三档路由、来源标签(规则蓝 / AI 紫),参考市面产品但不抄「一键全过」
- 打通后端:上传 → 解析 → 规则库 + 模型扫描 → interrupt → resume → 报告
- 联调前端:页面假数据换真接口,SSE 推扫描进度,状态栏跟着会话走
- 拿真合同验:规则命中率、模型误报各调一轮,Reject 的数据回流改规则
需要本章配套源码和数据集的同学,可以点赞 + 关注,我会把完整工程发给你。
后期规划
- 规则库引擎接入 :Playbook 关键词/正则匹配,让
source_type真正区分来源 - Checkpointer 换数据库持久化
- 规则库加 Embedding 语义匹配
- 扫描件 OCR 加强,识别错了要提醒
- 误报回流半自动,Reject 数据进规则优化队列
- 跨条款组合风险单开知识图谱线,不和主流程绑死
- 生产环境模型私有化部署
特别说明
合同 Agent 别急着替人判,先把「该停必须停」的流程钉死。
审合同和做知识库问答不是一回事。问答追求答得全;审批追求责任清晰、关键节点有人拍板、全程留痕。先把 LangGraph 闭环跑稳,再把 Playbook 规则库叠上去。