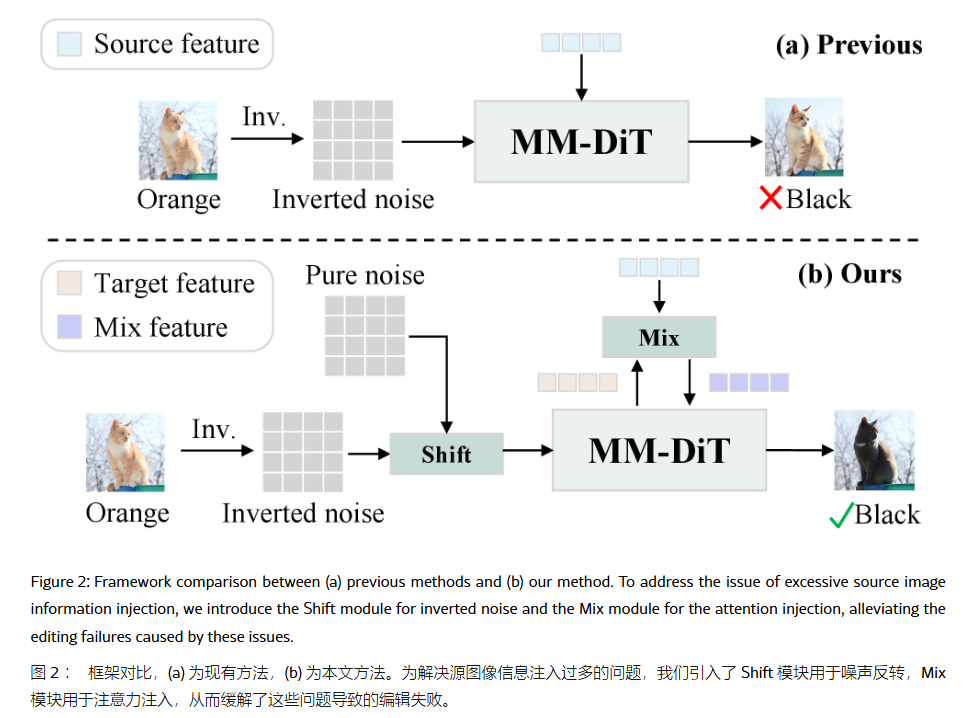
目标是解决目前 AI 编辑中一个常见的痛点:AI 太"固执"了,总是改不掉原图的某些特征。
1. 它是干什么的?
想象你有一张照片,上面是一只橘猫 坐在篱笆上。你想让 AI 把它改成一只黑猫,但背景(篱笆、草地)完全不动。
目前的 AI 编辑技术(尤其是基于最新的"流模型"如 FLUX、Sora 类架构)经常会翻车:
- 翻车情况 A: AI 改了,但改得不彻底(比如猫变成了深棕色,而不是全黑)。
- 翻车情况 B: AI 改不动,猫还是橘色的,因为它觉得"原图就是橘色,我不敢乱动"。
- 翻车情况 C: 为了改猫,把背景的篱笆也改坏了。
ProEdit 就是为了解决这个问题,既能让猫彻底 变成黑色,又能完美保留原来的篱笆背景。
2. 为什么现在的 AI 会"翻车"?(核心问题)
论文作者发现,目前的编辑方法(Inversion-based methods)有一个通病:"过度依赖原图信息"。
这就好比装修房子:
- 原来的做法: 你想把墙纸从黄色换成蓝色。但装修队(AI)在施工时,总是时不时看一眼原来的黄色墙纸,结果刷出来是黄绿色,或者干脆不敢覆盖原来的颜色。
- 技术上的原因:
- 底子没洗干净(Latent问题): AI 在反推回噪声(即生成的起点)时,保留了太多原图的结构和颜色信息。
- 看错说明书(Attention问题): 为了保持背景不变,AI 会大量照搬原图的"注意力特征"。结果在改猫的时候,它也照搬了原图"橘色猫"的特征,导致新指令(黑猫)无法生效。
3. ProEdit 是怎么解决的?(两大绝招)
作者提出了一个"即插即用"的方案,包含两个核心模块:
第一招:Latents-Shift(把"底色"洗掉)
- 原理: 既然原图的"底子"(噪声)里残留了太多"橘猫"的信息,那我就在编辑区域(猫的身上)撒一把"随机噪声"。
- 效果: 这就像是用橡皮擦把猫那一块的旧颜色擦淡一点,打乱原有的分布,让 AI 在重新生成时不再受旧颜色的干扰,能听从"变成黑色"的新指令。
第二招:KV-Mix(混合新旧指令)
- 原理: 在生成过程中,AI 需要决定关注什么。
- 对于背景(篱笆):完全照搬原图的信息,确保背景一丝不乱。
- 对于编辑主体 (猫):不要只看原图,也不要只看新指令。而是把"原图的结构"和"新指令的描述"进行混合 (Mix)。
- 效果: 这样既保留了猫的轮廓和动作,又成功注入了新的属性(黑色)。
总结
ProEdit 的核心贡献在于它发现了 AI 编辑**"改不动"是因为"记性太好(过度保留原图信息)"**,并用一套巧妙的方法让 AI 在该改的地方"失忆"(接受新指令),在不该改的地方"记忆犹新"(保留背景)。
ProEdit (arXiv:2512.22118) 针对的是基于 Flow Matching (Rectified Flow) 模型(如 FLUX.1, HunyuanVideo, Stable Diffusion 3 等采用 MM-DiT 架构的模型)在 Inversion-based Editing 任务中的一个共性痛点:源图像信息过度注入 (Excessive Source Information Injection)。
目前的 Flow-based Inversion 方法(如 RF-Solver, FireFlow, UniEdit)通常采用 "Invert-then-Sample" 的范式,并在采样过程中注入源图像的 Attention Feature 以保持结构一致性。作者认为,这种策略引入了过强的源图像 Prior,导致编辑失败(即无法改变颜色、姿态或数量)。
论文提出了一个 Training-free 的插件式方案,主要通过两个模块在 Latent 初始化 和 Attention 注入 两个层面解耦源图像信息。
1. 核心问题分析 (Problem Formulation)
在基于流模型的编辑中,编辑过程通常求解 ODE:
dZt=vθ(Zt,t)dt dZ_t = v_\theta(Z_t, t)dt dZt=vθ(Zt,t)dt
现有的 SOTA 方法为了保持背景一致性(Structure Consistency),通常会做两件事:
- Latent Re-use: 将源图像反推得到的噪声 zTz_TzT 作为生成的起点。
- Attention Injection: 在采样过程中,将源图像生成过程中的 K,VK, VK,V 特征注入到目标生成过程中。
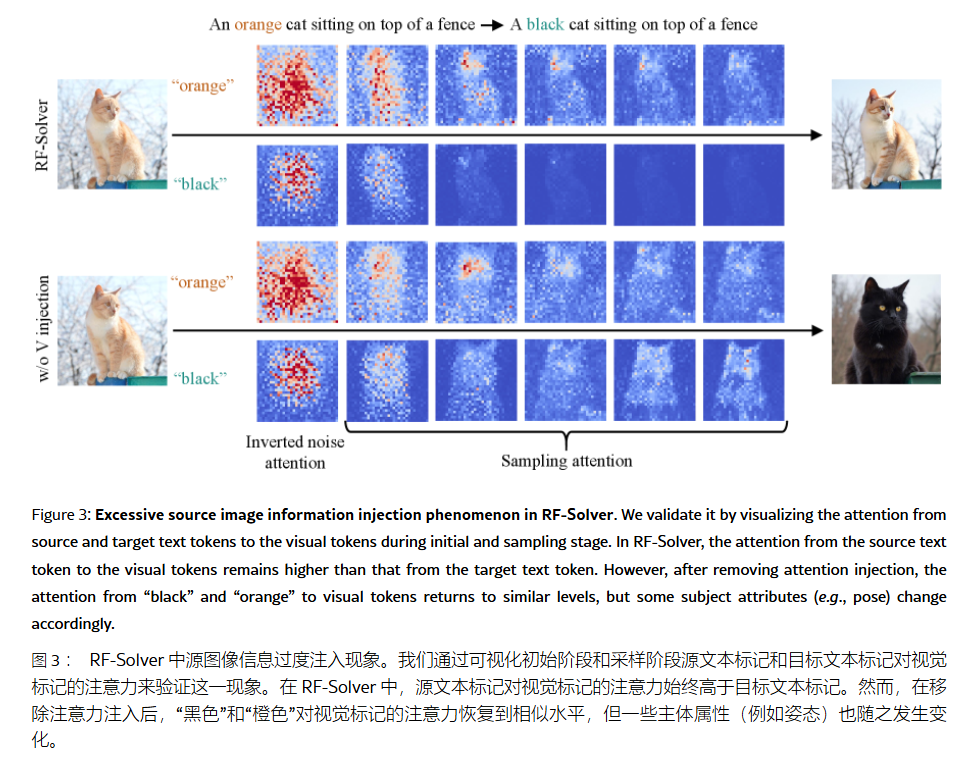
作者的发现 (Insight):
- Latent 层面: 即便是反推到 t=1t=1t=1 的 zTz_TzT,依然保留了过多的源图像语义分布(Source Distribution),这为 ODE 的积分路径提供了一个极其顽固的初始偏置。
- Attention 层面: 全局注入(Global Injection)源图像的 VVV 特征会导致模型过度关注源图像的属性(如颜色、纹理),从而忽略 Target Prompt 的引导。
2. 解决方案 (Methodology)
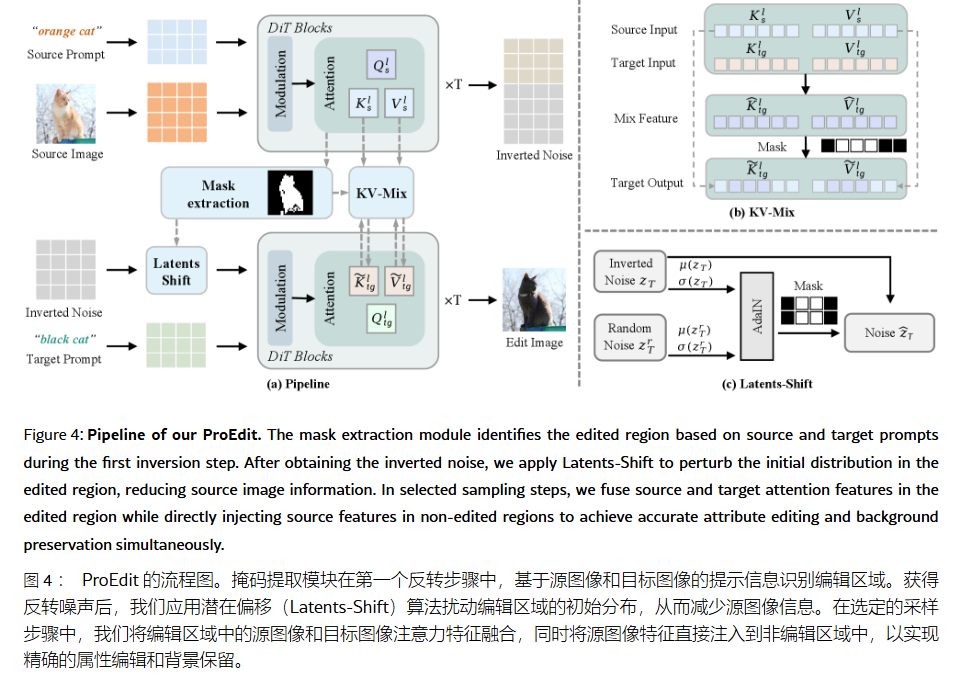
ProEdit 提出了两个核心模块来解决上述问题:
A. Latents-Shift (针对初始噪声分布的修正)
这是一个受 AdaIN (Adaptive Instance Normalization) 启发的模块。
- 动机: 打破 zTz_TzT 中保留的源图像分布,同时保留基本的结构信息。
- 操作: 在编辑区域(通过 Attention Mask 确定),将反推噪声 zTz_TzT 的统计分布(均值 μ\muμ 和方差 σ\sigmaσ)替换为随机高斯噪声的统计分布。
- 数学表达:
z~T=σ(zrand)(zT−μ(zT)σ(zT))+μ(zrand) \tilde{z}T = \sigma(z{rand})\left( \frac{z_T - \mu(z_T)}{\sigma(z_T)} \right) + \mu(z_{rand}) z~T=σ(zrand)(σ(zT)zT−μ(zT))+μ(zrand)
z^T=M⊙(βz~T+(1−β)zT)+(1−M)⊙zT \hat{z}_T = M \odot (\beta \tilde{z}_T + (1-\beta)z_T) + (1-M) \odot z_T z^T=M⊙(βz~T+(1−β)zT)+(1−M)⊙zT
其中 MMM 是编辑掩码,β\betaβ 是混合比例。这样做实际上是在 Latent 空间做了一次风格/分布的迁移,将"源图像风格"从 Latent 中剥离,只保留结构。
B. KV-Mix (针对 Attention 机制的修正)
这是对 Self-Attention (或 MM-DiT 中的 Joint Attention) 的干预。
- 动机: 全局注入会导致编辑无效,完全不注入会导致背景崩坏。需要一种空间感知的混合策略。
- 操作:
- Mask 提取: 利用 Cross-Attention Map(特别是最后一个 Double Block 的 Attention)自动提取编辑区域掩码 MMM。
- 区域差异化注入:
- 非编辑区域 (Background): 完全注入源图像的 Ks,VsK_s, V_sKs,Vs,确保背景像素级对齐。
- 编辑区域 (Foreground): 对源特征 (Ks,VsK_s, V_sKs,Vs) 和目标特征 (Ktg,VtgK_{tg}, V_{tg}Ktg,Vtg) 进行线性插值混合。
- 数学表达:
K~tgl=M⊙(δKtgl+(1−δ)Ksl)+(1−M)⊙Ksl \tilde{K}{tg}^l = M \odot (\delta K{tg}^l + (1-\delta)K_s^l) + (1-M) \odot K_s^l K~tgl=M⊙(δKtgl+(1−δ)Ksl)+(1−M)⊙Ksl
V~tgl=M⊙(δVtgl+(1−δ)Vsl)+(1−M)⊙Vsl \tilde{V}{tg}^l = M \odot (\delta V{tg}^l + (1-\delta)V_s^l) + (1-M) \odot V_s^l V~tgl=M⊙(δVtgl+(1−δ)Vsl)+(1−M)⊙Vsl
这里 δ\deltaδ 是混合强度。通过混合,模型在编辑区域既能看到 Target Prompt 的指引(通过 Ktg,VtgK_{tg}, V_{tg}Ktg,Vtg),又能保留源物体的部分结构约束(通过 Ks,VsK_s, V_sKs,Vs)。
3. 实验结论 (Key Results)
- Pipeline 优势: 该方法不需要训练,直接作用于推理阶段。
- 兼容性: 论文展示了它可以作为插件集成到 RF-Solver, FireFlow, UniEdit 等现有的 Flow Inversion 方法中。
- 性能表现:
- 在 PIE-Bench 上,相比 Baseline (如 RF-Solver),ProEdit 在 CLIP Similarity (Edited) 指标上有显著提升(说明编辑更准确),同时保持了较高的 Structure Distance 和 PSNR(说明背景保持得好)。
- 解决了"颜色改不掉"、"姿态改不动"以及"物体数量改变困难"等顽疾。
总结 (Takeaway)
从算法工程的角度看,ProEdit 的本质是对 Inversion-based Editing 归纳偏置 (Inductive Bias) 的一次精细化调整。
它指出了 "Inversion is not enough" ------ 仅仅依赖 ODE 的可逆性是不够的,因为 Flow Model 的 Latent 空间语义耦合度比传统 Diffusion 更高。通过 Latents-Shift 去除初始条件的语义粘连,再配合 KV-Mix 在生成过程中动态平衡保真度(Fidelity)与编辑性(Editability),是其成功的关键。对于正在做 FLUX 或 HunyuanVideo 相关编辑应用的工程师来说,这是一个非常值得复现和集成的 Trick。