在前几篇内容中,完成了 Docker+GPU 基础环境搭建、Determined Master/Agent 单节点部署,搭建好了算力调度平台的核心底座。本次实战将聚焦算法项目的容器化改造,以 Python 编写的分类算法项目为例,完整讲解从项目代码 / 配置改造、Dockerfile 编写,到训练镜像构建、本地验证的全流程,打造可被 Determined AI 调度的标准化训练镜像,为后续提交训练任务、实现算力统一调度做好准备。
一、前置准备
- 已完成 Docker+GPU 环境配置,容器可正常调用 GPU;
- 算法项目为 Python 编写,且已整理好
requirements.txt依赖文件; - 本次使用基础镜像为
pytorch/pytorch:2.4.1-cuda11.8-cudnn9-runtime,适配 GPU 训练,可根据项目框架 / 版本需求自行替换。
二、核心改造:项目代码与配置文件
容器化训练的关键是让项目适配容器的目录挂载与 GPU 调度规则 ,需对项目的配置文件 和GPU 指定代码做针对性改造,避免因路径 / GPU 冲突导致训练失败。
2.1 配置文件改造:适配容器目录挂载
项目原有配置文件的路径为本地绝对路径 / 相对路径,容器中无法识别,需修改为容器内统一挂载路径,后续通过 Docker 将宿主机的数据集 / 输出目录映射到该路径,实现数据读写。
改造前(本地路径,容器内不可用)
yaml
train_path: './train'
data_root: 'E:/classificationmodel_learn/cat-dog-classification-master'
test_path: './test'
model_save_path: './EmptyClas_threeclas_Resnet18-20260202.pth'
csv_path: './submission.csv'
tensorboard_path: './tensorboard_info'
batch_size: 256
epochs: 100
lr: 0.001改造后(容器内挂载路径,统一规范)
yaml
data_root: "/mnt/data"
train_path: "/mnt/data/train"
test_path: "/mnt/data/test"
csv_path: "/mnt/output/submission.csv"
tensorboard_path: "/mnt/output/tensorboard_info"
model_save_path: "/mnt/output/model.pth"
batch_size: 256
epochs: 100
lr: 0.001改造说明:
- 定义
/mnt/data为数据集只读目录,用于挂载宿主机的训练 / 测试数据集; - 定义
/mnt/output为训练产物可写目录,用于存储模型文件、日志、csv 结果等; - 所有路径统一使用容器内绝对路径,避免相对路径的识别问题。
2.2 代码改造:取消硬编码 GPU 指定
Determined AI 会根据任务配置自动为训练容器分配 GPU 资源,若项目代码中硬编码指定 GPU 编号,会与平台的 GPU 调度冲突,导致镜像调用报错,需删除具体 GPU 编号,仅保留 CUDA 判断。
改造前(硬编码指定 cuda:3,平台调度冲突)
python
device = torch.device("cuda:3" if torch.cuda.is_available() else "cpu")改造后(由平台自动分配 GPU,适配调度规则)
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")三、编写 Dockerfile:构建训练镜像的核心配置
本次编写的 Dockerfile 基于 PyTorch 官方 GPU 基础镜像,完成依赖安装、项目代码复制、容器目录创建、启动命令配置,同时解决依赖冲突、配置 pip 国内源提升安装速度,完整配置如下:
3.1 配套 pip.conf:配置 pip 国内源(可选)
在项目根目录创建pip.conf文件,指定清华源,避免依赖安装超时,若无需指定可直接删除该文件及 Dockerfile 中相关配置。
plain
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
timeout = 120
retries = 10
trusted-host = pypi.tuna.tsinghua.edu.cn3.2 完整 Dockerfile 配置
在项目根目录创建dockerfile_base文件,内容如下,关键步骤已添加注释:
dockerfile
# 基于PyTorch官方GPU基础镜像,适配CUDA11.8,按需替换
FROM pytorch/pytorch:2.4.1-cuda11.8-cudnn9-runtime
# 设置容器内项目工作目录
WORKDIR /workspace/clas_code
# 复制依赖文件与pip源配置文件
COPY requirements.txt /tmp/requirements.txt
COPY pip.conf /etc/pip.conf
# 安装项目依赖:升级pip→安装项目依赖→安装determined客户端→解决numpy/pandas依赖冲突
RUN python -m pip install -U pip \
&& python -m pip install -r /tmp/requirements.txt \
&& python -m pip install -U determined==0.38.1 \
&& python -m pip uninstall -y numpy pandas || true \
&& conda install -y -c conda-forge --force-reinstall "numpy=1.26.*" "pandas=2.2.*" \
&& conda clean -a -y
# 复制项目所有代码到容器工作目录
COPY . /workspace/clas_code
# 创建容器内数据/输出目录,与配置文件中的路径保持一致
RUN mkdir -p /mnt/data /mnt/output
# 设置容器默认启动命令,-u保证日志实时输出
CMD ["python", "-u", "main.py"]注意点:
- 若基础镜像已包含部分依赖(如 PyTorch、numpy),需与
requirements.txt核对,冲突时删除requirements.txt中的对应依赖; determine客户端版本需与 Master/Agent 版本一致(本次为 0.38.1),保证平台与镜像的兼容性;mkdir -p /mnt/data /mnt/output必须执行,避免容器启动时因目录不存在导致训练失败。
四、构建训练镜像:本地构建与版本管理
完成上述改造和配置后,在项目根目录执行 Docker 构建命令,生成训练镜像,并做好镜像版本管理,方便后续迭代和回滚。
4.1 基础构建命令(本地使用)
bash
# 构建镜像:-t 指定镜像名:版本号,-f 指定Dockerfile文件,. 为构建上下文(项目根目录)
docker build -t clas_code:v1.3.3 -f dockerfile_base .
# 验证镜像构建成功:查看本地镜像列表,能找到目标镜像即说明构建成功
docker images | grep clas_code结果:

4.2 直接构建为 Harbor 适配格式(推荐)
后续需将镜像推送到 Harbor 镜像仓库,可直接在构建时指定Harbor 仓库地址 / 项目名 / 镜像名:版本号,避免后续重命名,一步到位。
bash
# 格式:docker build -t HarborIP:端口/仓库项目名/镜像名:版本号 -f Dockerfile文件 构建上下文
docker build -t HarborIP:8007/alg/clas_code:v1.3.3 -f dockerfile_base .4.3 镜像版本管理:删除无用镜像
若多次构建镜像产生冗余版本,可通过镜像名 / 版本号 / 镜像 ID 删除,释放磁盘空间:
bash
# 方式1:通过镜像名:版本号删除
sudo docker rmi clas_code:v1.3.3
# 方式2:通过镜像ID删除(更精准,避免版本号冲突)
sudo docker rmi 镜像ID五、本地验证镜像:确保镜像可正常运行
镜像构建完成后,需通过docker-compose本地启动镜像,验证代码运行、依赖完整性、GPU 调用、目录挂载是否正常,避免直接推送到平台后出现训练失败问题。
5.1 编写 docker-compose.yml 验证配置
在项目根目录创建docker-compose.yml,配置镜像映射、目录挂载、GPU 透传,内容如下:
yaml
services:
train:
# 替换为实际构建的镜像名:版本号/Harbor格式镜像
image: HarborIP:8007/alg/clas_code:v1.3.3
container_name: clas_code_train
# 容器启动命令,与Dockerfile中CMD保持一致
command: ["python3", "-u", "main.py"]
# 配置环境变量,指定torch缓存目录到输出目录
environment:
TORCH_HOME: /mnt/output/torch_cache
# 目录挂载:宿主机路径:容器内路径,ro=只读,rw=可读写
volumes:
- /home/data/xxx/xxx/catdog:/mnt/data:ro
- /home/data/xxx/xxx/outputs/clas_code:/mnt/output:rw
# GPU透传:使用宿主机所有GPU
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]配置说明:
- 宿主机路径需替换为实际的数据集 / 输出目录,确保路径存在且有读写权限;
ro只读挂载数据集目录,防止训练过程中误修改数据集;rw可写挂载输出目录,保证训练产物正常存储。
5.2 启动验证并查看结果
bash
# 启动容器并后台运行
docker-compose -f docker-compose.yml up -d
# 查看容器运行日志,验证训练是否正常启动
docker-compose -f docker-compose.yml logs -f结果:
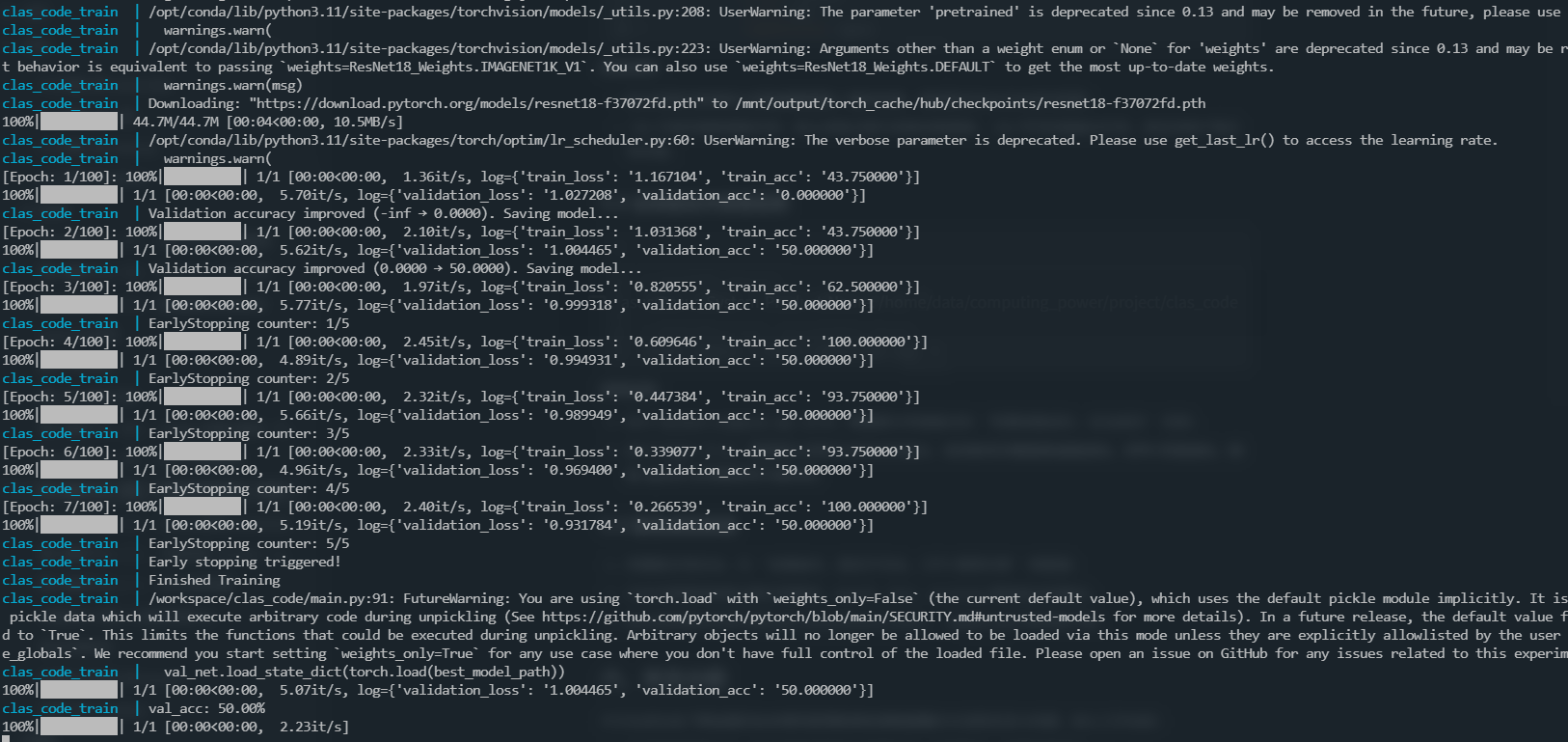
训练结果:

5.3 验证标准
- 容器能正常启动,无 "依赖缺失、路径不存在、GPU 调用失败" 等报错;
- 日志中能看到训练过程正常推进,epoch、loss、accuracy 等指标实时输出;
- 宿主机的输出目录中能生成
tensorboard_info、model.pth等训练产物。
六、本文小结
本次实战完成了算法项目从本地代码到标准化训练镜像的全流程改造与构建,核心工作包括:
- 改造项目配置文件,将本地路径替换为容器内统一挂载路径,适配数据读写;
- 改造 GPU 调用代码,取消硬编码 GPU 编号,适配 Determined AI 的 GPU 调度规则;
- 编写 Dockerfile 和 pip.conf,解决依赖冲突、配置国内源,构建标准化训练镜像;
- 实现镜像的基础构建与 Harbor 适配构建,做好版本管理;
- 通过 docker-compose 本地验证镜像,确保镜像可正常运行、GPU 可正常调用、数据可正常读写。
下一篇内容中,将讲解 Harbor 镜像仓库的安装与配置,完成训练镜像的上传、拉取闭环,让平台能从 Harbor 中拉取镜像启动训练任务。