第一部分:智能体(Agent)范式与多代理协作工程
要让只能做"文字接龙"的大模型去执行复杂的现实任务(如调度代码、查数据库),我们需要给它套上 Agent 框架。
1. 三大基石范式的概念与演进
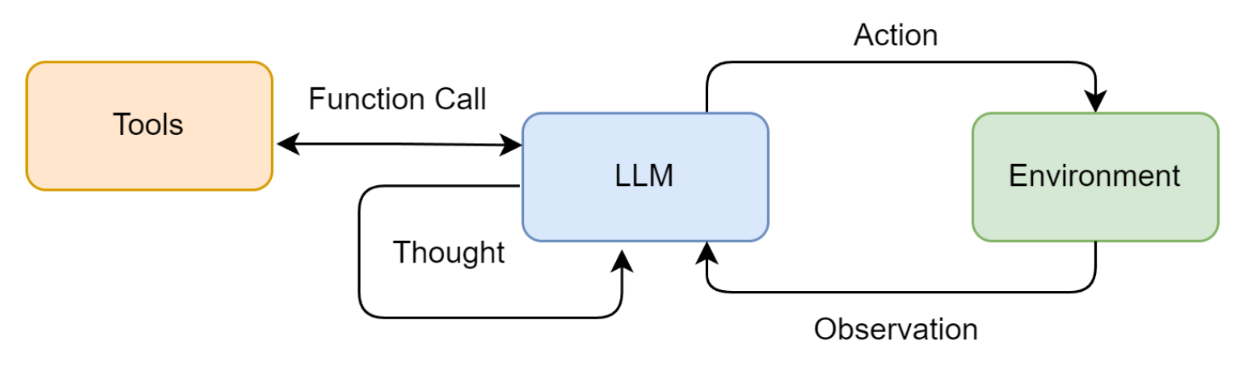
① ReAct (Reasoning and Acting / 推理与行动)
-
概念机制: 让模型"边想边做"。模型每执行一步,必须严格遵循
Thought (思考)->Action (调用工具)->Observation (观察结果)的循环。 -
过去的做法: 依赖文本正则解析。大模型在文本里输出特定的字符(如
Action: Search[Python]),系统用正则表达式抓取出来去执行。 -
现在的演进 (Native Tool Calling): 摒弃了不稳定的正则解析。现在的模型(如 OpenAI o1, DeepSeek)在底层训练时就被植入了原生函数调用能力,能够直接、稳定地输出标准化的 JSON 格式指令,极大降低了系统崩溃率。
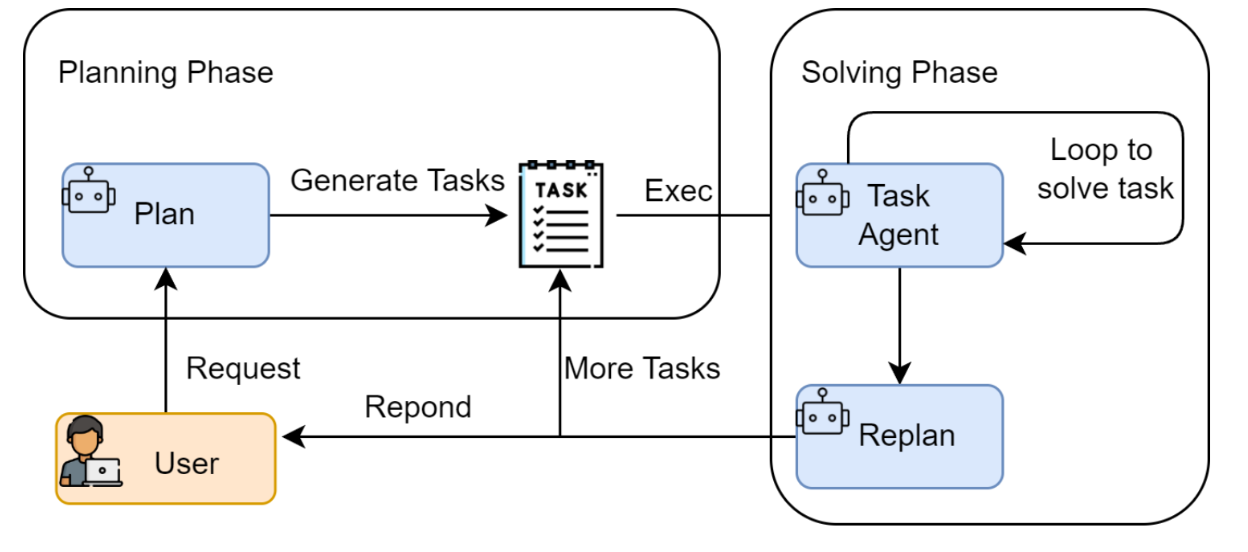
② Plan-and-Solve (计划与求解)
-
概念机制: "三思而后行"。将任务拆解为两步:先让一个"规划者"把复杂任务拆解成线性的 1、2、3、4 步子任务,然后再交给"执行者"按顺序无脑执行。
-
过去的做法: 静态线性执行。一旦第 2 步报错,后面的 3 和 4 就会像多米诺骨牌一样全部雪崩。
-
现在的演进 (RePlan & Reasoning Chains): 变成了动态重规划 。在执行过程中一旦遇到报错,模型会立刻触发
RePlan重新生成后续步骤;或者直接利用现代大模型的内部深度推理链(隐式思维链)在内部完成试错。
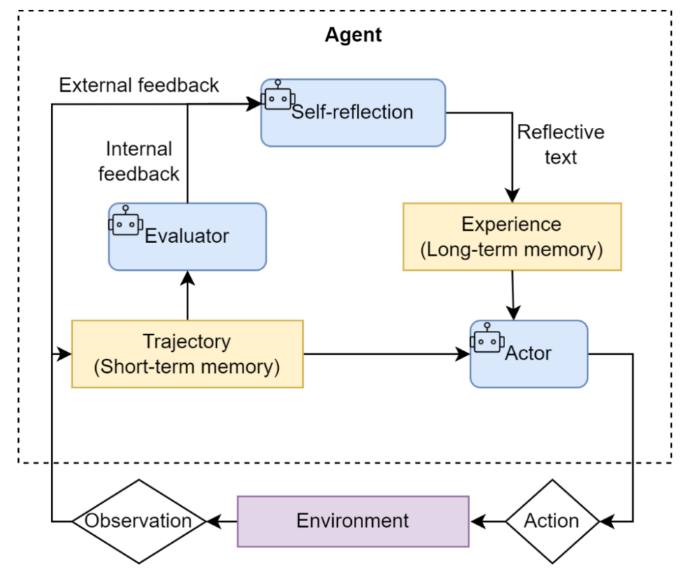
③ Reflection (反思机制)
-
概念机制: 引入"自我批评"。模型输出初稿后,系统强制要求它扮演"评审员"角色,指出初稿的错误,然后据此生成修改版,形成螺旋上升的闭环。
-
现在的演进 (状态机化与客观终止): 从简单的"自我对话"变成了严密的图结构。现在的系统(如 LangGraph)将反思设计为独立节点,并且引入客观物理检验作为终止条件(比如:只有当生成的 Python 代码在沙盒里跑通,且置信度分数 > 0.85 时,反思循环才允许结束)。
2. 现代生产级复杂架构:LangGraph + Tool RAG + Supervisor
面对工业级复杂任务(如同时调度虚拟电厂算法和生成研报),单体 Agent 会因为认知过载而崩溃,现在的标准解法是这套组合拳:
-
Supervisor (多代理包工头): 摒弃了"全能单体"。系统设立一个 Supervisor 节点,它只做任务分发,不干具体活。它把数据清洗派给 Data_Worker,把交易逻辑派给 Algo_Worker。互不干扰。
-
Tool RAG (动态工具箱): 当系统拥有 500+ 个 API 工具时,全塞给模型会导致上下文爆炸。系统将工具说明书向量化,模型在干活前,先通过语义检索(RAG)自动召回最相关的 3-5 个工具带着上阵。
-
LangGraph (底层状态机): 充当维持秩序的物理引擎。它把多 Agent 协作变成一张"有向图",并维护一个"全局共享黑板(State)"。任何模型崩溃,都能从黑板上的最新状态断点续传。
第二部分:多模态图文生成与理解的"大一统"
为了让模型既懂文字又懂图片,目前工业界存在两条泾渭分明的底层架构路线。
1. 路线 A:连续派(缝合怪路线)
这是目前开源界快速迭代的实用路线,核心思想是 "不同模态各司其职,中间靠翻译官强行对齐"。
-
看图机制 (ViT + 投影层):
-
ViT (视觉 Transformer): 把图片切成 16x16 的小块,提取出连续的浮点数特征向量。
-
投影层 (Projection Layer): 由于语言大模型看不懂 ViT 的向量,中间必须加一个"翻译转换矩阵"。过去用简单的线性层,现在升级为了表达力更强的 MLP 或 Q-Former,将图像向量强行拉伸成大模型能懂的维度。
-
-
画图机制 (Stable Diffusion 在潜空间雕刻):
-
语言模型输出一段提示词向量,交给外挂的 Stable Diffusion 画师。SD 画师在一个极小的潜空间 (Latent Space) 里,将一团随机噪点,根据提示词的引导,一点点"去噪雕刻"出清晰的特征,最后放大成高清图片。
-
演进: 雕刻噪点的核心网络,已经从过去的 UNet 升级为了泛化能力更强的 DiT (Diffusion Transformer)。
-
2. 路线 B:离散派(原生大一统路线)
这是通向 AGI 的终极解法,核心思想是 "万物皆 Token,图片彻底变成文字"。
-
查字典机制 (VQ-GAN / VQ Tokenizer):
-
不再使用连续的浮点数。系统内置一本拥有 8192 个"图像词汇"的字典(Codebook)。
-
图片切块后,强行去字典里找最相似的标准向量,然后只输出该向量的整数 ID (例如
4096)。此时,图片已经被生生压缩成了一串和文字一模一样的 ID 序列。
-
-
极致的混排训练机制:
- 将图像 ID 序列和文字 ID 序列拼在一起,大模型只做一件事:预测下一个 ID 是什么(Next-Token Prediction)。
-
训练字典的硬核魔法:
-
EMA (指数移动平均): 训练时,不使用传统的梯度下降去更新字典。而是暴力计算当前批次特征的"物理重心",让字典里的标准向量稳稳地向这个重心移动。
-
承诺损失 (Commitment Loss): 给编码器套上紧箍咒,强迫它提取特征时必须尽量靠近字典里的标准向量,防止特征发散。
-
第三部分:视频生成的时空魔法
视频绝不是"每秒简单生成 60 张图片",否则算力会立刻穿透地球。视频模型充满了工程学上的极度压缩与欺骗。
1. 核心机制:时空压缩与级联流水线
-
时空胶囊 (3D VAE): 模型不再切分 2D 的平面像素块,而是切分包含时间维度的"三维豆腐块"。比如将连续的 24 帧中背景不动的部分极度压缩,将时间和空间冗余一并剔除。
-
级联生成 (Cascaded Pipeline) 分工:
-
主模型 (通常为 DiT): 只负责推演物理规律。拼尽全力生成一个低分辨率(如 256p)、低帧率(如 24fps)的"骨架视频"。
-
TSR (时序超分 / 插帧模型): 专门负责无中生有。在骨架帧之间脑补过渡画面,丝滑提升至 60fps。
-
SSR (空间超分模型): 专门负责高清重制,把马赛克画质提升至 4K。
-
2. 时间一致性(防闪烁)的"三大神装"
如果不管控,模型生成的视频每一帧发色和衣服都会变。
-
ControlNet (物理骨架锁定): 用计算机视觉算法抽出人物的动作骨架(火柴人)或边缘线稿。在生成每一帧时,强制模型必须顺着这个特定的物理骨架去填色。
-
Temporal Attention (时空注意力互相偷看): 扩散模型在生成视频时是一批帧同时生成的。系统在网络里加入"时间层",强制第 2 帧在生成头发时,必须去"参考"第 1 帧的特征分布,把发色死死焊住。
-
滑动窗口与 IP-Adapter:
-
滑动窗口: 长视频接力生成时,每次把前一个批次的最后几秒作为已知条件输入,像拉链一样咬合。
-
IP-Adapter: 输入一张设定图,直接锁定脸部特征和服装材质,保证角色越往后长得越不像别人的问题。
-