在 B-01 到 B-04,我们一直在优化"数据已经在 GPU 这边以后"的访问效率:合并访问、共享内存、寄存器、L2 驻留。
但工程里还有一个更早的问题:数据到底何时、以什么粒度、由谁搬到 GPU 。
Unified Memory(UM)把这件事交给运行时自动处理,开发体验很好;性能上却常出现"能跑但慢、偶发抖动、首轮异常慢"的现象。
TL;DR(工程结论)
- UM 不是"免费搬运" :按需迁移(on-demand migration)的核心成本不是带宽,而是 latency + serialization。SM stall → CPU 驱动介入 → DMA 筹备 → 传输 → 页表更新/TLB shootdown 这一整条链,会把一次访问放大为不可预测的停顿。首轮访问最容易因此变慢。
- 先做 prefetch,再谈优化,但必须知道它什么时候会反噬 :
cudaMemPrefetchAsync()往往是 UM 场景里性价比最高的第一步,但在访问稀疏、数据量远超 HBM、多 GPU 所有权冲突等情况下,它可能引入 cache pollution、浪费带宽、甚至加剧迁移风暴。 cudaMemAdvise()是 hint,不是硬约束:它不改变数据内容,只影响 placement / replication / mapping 策略。收益高度依赖访问模式、设备互联方式和实际运行时判断,不生效是常态,必须用证据链说话。- 用证据链判定是否值得继续用 UM,并引入硬决策规则 :至少看
time + fault/migration 行为 + DRAM/L2,并设定显式判停条件(参见第 4 节决策函数)。不要只看单次耗时,不要只看均值。 - 跨设备/跨 NUMA 更要保守,多 GPU 写访问默认禁用 UM:多 GPU 下 UM 的 single-owner 模型极易触发页面的反复迁移(page ping-pong),除非确认只读 + ReadMostly 提示生效,否则默认转向显式管理。
1. 为什么 UM 常常"好用但不稳"
UM 的核心价值是统一地址空间与自动迁移:你用一份指针,运行时决定数据当前放在 CPU 侧还是 GPU 侧。
问题在于:自动迁移的决策点常发生在"真正访问时",也就是 page fault 触发时。
Host alloc (cudaMallocManaged)
│
▼
Kernel 首次触达某页
│
▼
Page Fault + 页面迁移(CPU -> GPU)
│
▼
Kernel 继续执行但"Page Fault + 页面迁移"这六个字背后是一条非常长的延迟链,远非一次简单的 DMA 拷贝。
1.1 Page Fault 的真实成本(为什么小粒度随机访问会炸)
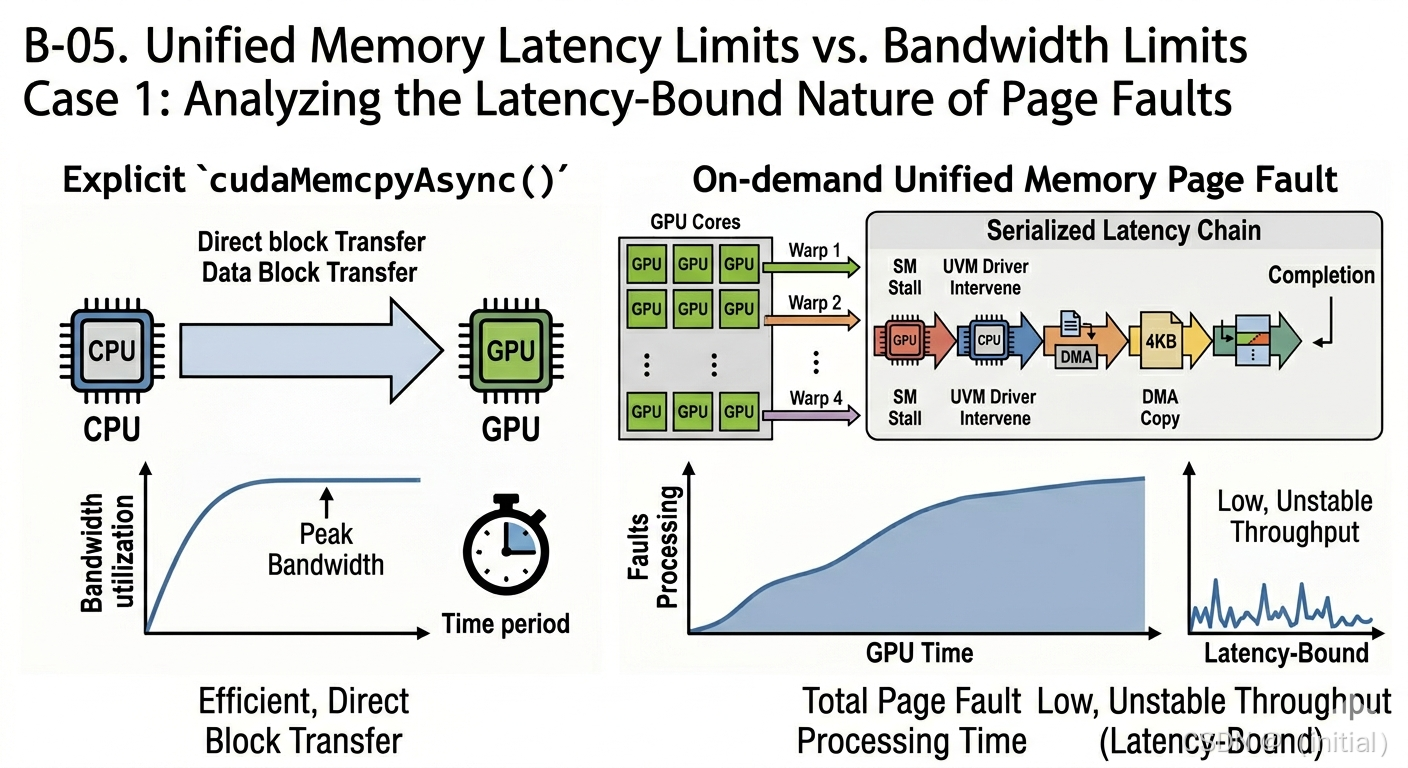
当 GPU warp 访问一个尚未映射到本地显存的 managed 地址时,硬件触发的不是一次简单的缺页中断,而是跨越硬件、驱动与操作系统的一整套动作:
- SM stall:触发 fault 的 warp 会被挂起,导致可发射 warp 数下降;当 eligible warp 不足时,SM issue slot 利用率会明显下滑。
- UVM driver 介入:中断交由 CPU 侧的统一内存驱动处理,驱动需要识别访存地址所属的页面、检查当前页面位置与所有权。
- 迁移请求建立:若页面在远端(CPU 或另一 GPU),驱动发起迁移请求,协调 DMA 引擎准备传输。
- DMA 拷贝:实际数据通过 PCIe/NVLink 搬运到目标设备显存。延迟量级从数微秒(NVLink + 小页面)到几十微秒(PCIe + 竞争)不等。
- GPU 页表更新与地址转换缓存刷新:新的物理地址需要写入 GPU 侧页表,期间可能触发相关地址转换缓存失效/刷新开销(具体机制依架构与驱动实现)。
- Warp 恢复:完成上述步骤后,挂起的 warp 才被唤醒继续执行。
关键结论 :fault 的成本不是"带宽受限"的,而是 "延迟+序列化"受限。多个 warp 对同一页面或临近页面的并发 fault,会被驱动排队处理,导致原本可并行执行的线程束被串行化。因此,访问粒度越细、随机性越强,实际吞吐率可能跌至峰值性能的几十分之一甚至更低。
这也是为什么首轮访问往往是隐藏的"性能炸弹":数百到数千个页面 fault 依次触发的累积延迟,可能让一个常规 kernel 的第一轮耗时比后续轮次高出数倍。
如果工作负载是连续、可预测访问,这个机制还能接受;
若访问离散、冷热混杂、跨设备反复触达,就会出现"迁移风暴"与明显抖动。
2. UM 的三把扳手:Fault / Prefetch / Advise
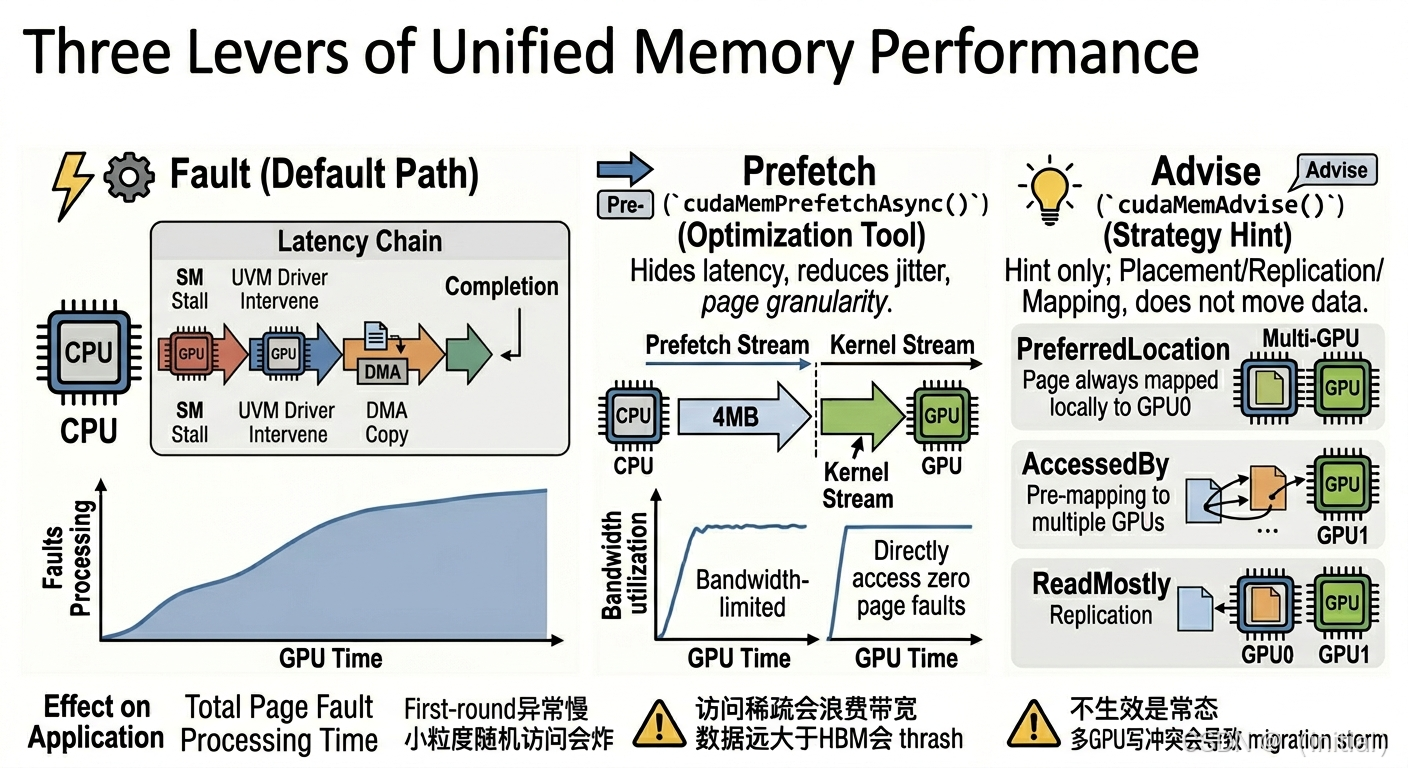
2.1 Fault(默认路径)
- 优点:代码最简单,无需任何额外管理。
- 缺点:所有迁移发生在使用点,SM stall + driver overhead 让首轮时延不可预测,小粒度访问会放大序列化效应。
适用:功能验证、小规模实验、对稳定尾延迟不敏感的离线任务。
2.2 Prefetch(工程默认优先,但非万能)
核心 API:
cudaMemPrefetchAsync(ptr, bytes, device, stream)
它能将"访问时才搬"改成"已知将访问时提前搬",很大程度上消除运行时在关键路径上的 fault 处理开销,从而降低首轮抖动。
Prefetch 的粒度限制与最适条件
cudaMemPrefetchAsync 的搬运粒度是 page granularity(通常为 4 KB、64 KB 或 2 MB,取决于平台与配置)。即使你只指定了几十个字节,运行时也会将整个包含该地址范围的页面完整搬运。这意味着:
- 若访问模式连续且与 page 边界对齐,prefetch 效率最高;
- 若访问高度稀疏,prefetch 可能搬运了大量用不到的数据,导致 带宽浪费与 cache pollution(挤占 L2/HBM,甚至换出热点数据)。
Prefetch 失效/负收益的典型场景
- 访问稀疏:prefetch 的大块数据仅少量被实际使用,换来不成比例的带宽与缓存占用。
- 数据远大于 HBM:prefetch 触发大量页面换出,形成新的迁移压力,甚至比 on-demand fault 更糟。
- prefetch 与计算同流且无 overlap:搬运串行化在关键路径上,延迟未被隐藏,反而因带宽竞争拖慢计算。
- 多 GPU 共享数据且所有权切换频繁:prefetch 导致页面的所有权被提前拉向某一设备,其他设备后续访问时触发反向迁移。
工程操作要点
- 始终将 prefetch 放在一个独立 stream 中,使其与计算流能够 overlap;并通过 CUDA event 确保 prefetch 完成后再启动依赖其数据的 kernel。
- 首轮之后的暖身迭代中,应关闭或裁减 prefetch,避免重复搬运已在目标设备的热页面。
- 当数据量接近 HBM 容量极限时,需对比显式管理下的显存占用,判断 prefetch 是否导致过量换页。
2.3 Advise(细化策略)
核心 API:
cudaMemAdviseSetPreferredLocationcudaMemAdviseSetAccessedBycudaMemAdviseSetReadMostly
它们不移动数据,而是为运行时提供关于 未来访问模式 的提示,影响页面放置、复制和映射策略。
| API | 本质 | 生效前提 |
|---|---|---|
| PreferredLocation | 指定初始 placement 及 fault 时的目标迁移位置 | 访问确实集中在该设备,且无频繁跨设备写冲突 |
| AccessedBy | 在指定设备上建立映射,避免首次访问时的 fault | 运行时在给定设备上预先建立页表映射,不保证物理驻留 |
| ReadMostly | 允许页面在多设备间复制,降低写所有权切换带来的迁移风暴 | 确认为以读为主的访问,且平台支持页面复制 |
Advise 的真实作用模型
Advise 只是 hint:运行时可以选择采纳、推迟或完全忽略。其效果取决于:
- 实际的访问模式(读/写比例、空间分布);
- GPU 数量与互联带宽;
- 驱动版本与页尺寸配置。
典型无效案例:
- 对频繁交叉写入的页面设置 ReadMostly,无法阻止所有权的反复切换。
- 在单 GPU 场景下设置 AccessedBy,额外收益几乎为零。
- PreferredLocation 设置与真实访问热点不一致,等于白设。
因此,advise 是否生效也必须通过 NSYS/NCU 做客观验证,不可假设其"优化"效果。
2.4 适用边界(不建议优先 UM 的场景)
以下场景更适合显式内存管理(cudaMalloc + cudaMemcpyAsync):
- 小对象 + 高频随机访问:page 级迁移粒度与访问粒度严重不匹配,fault 序列化成本被放大(参见 1.1 节)。
- 强实时/低抖动路径:UM 的"首轮慢、尾延迟抖动"特征不利于严格 SLA,显式管理可以完全消除 fault 不确定性。
- 多 GPU 高频 ownership 切换:非只读数据在设备间反复迁移(page ping-pong),带宽与延迟都可能恶化。
- 数据规模逼近或超过 HBM 容量:自动迁移容易触发频繁的页面换出,导致性能波动,显式管理能更精确控制驻留集。
多 GPU 场景的额外警告
UM 在多 GPU 下的默认所有权模型是 single-owner :任一时刻一个物理页面只能被一个 GPU 拥有。若两个 GPU 同时对同一页面执行写访问,运行时将被迫反复迁移页面所有权,陷入经典的 page ping-pong:
GPU0 写入 → 页面迁至 GPU0
GPU1 写入 → 页面迁至 GPU1
GPU0 再写入 → 页面迁回 GPU0每次迁移都伴随完整的 fault-迁移-页表更新流程,延迟叠加后往往使性能急剧恶化。
工程建议 :多 GPU 环境下如存在非只读的跨设备共享数据,默认不采用 UM,改用显式内存拷贝或借助 NCCL 等集合通信库;若确认全局均为只读访问,可尝试 UM + ReadMostly advise,但必须通过 NSYS 监控确认无迁移风暴后再上线。
3. 最小可复现实验设计(建议)
建议做三组对照,保持同一输入规模与同一 kernel:
- A: UM + on-demand fault
- B: UM + prefetch
- C: UM + prefetch + advise
统一输出:
kernel_time_ms- 首轮与稳态轮次的差异(建议至少跑 5 轮,含一次 warmup 排除 JIT/cache 效应)
- 可选:fault/migration 事件计数(NSYS)或相关替代信号
对照约束(必须一致):
- 除 UM 策略外,A/B/C 的输入规模、kernel、stream、迭代轮次必须完全一致。
- 每组实验前应执行一次未计时的 warmup 迭代,消除驱动初始化与页表首次建立等瞬态影响。
4. 证据链与决策规则:该看什么、怎么判
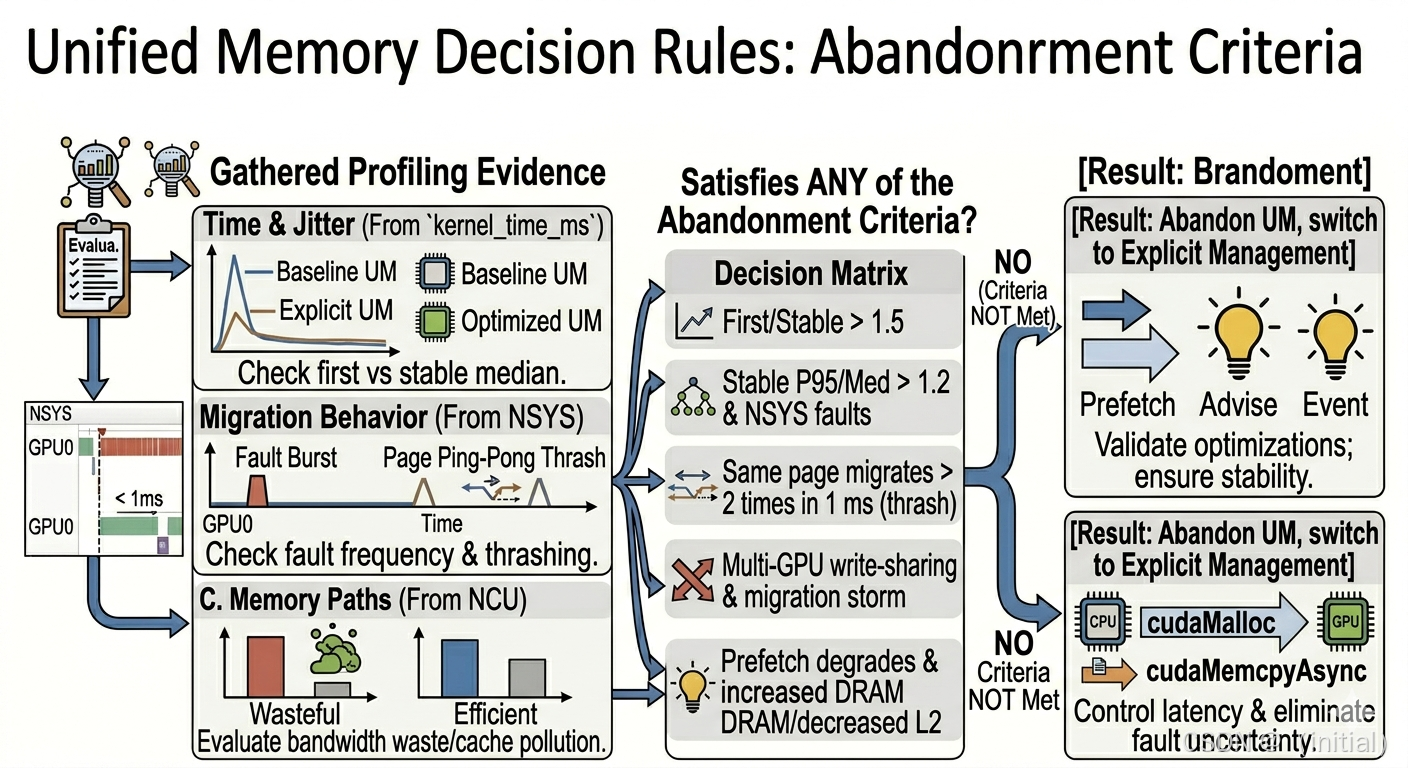
4.1 第一层:时间与稳定性
- 首轮时间是否异常高
- 多轮方差是否明显收敛
- 关键阈值:首轮 / 稳态中位数 > 1.5 视为显著异常;P95 / 中位数 > 1.2 且在稳态轮次持续出现,说明尾延迟未收敛
4.2 第二层:迁移行为(推荐 NSYS)
在 Nsight Systems 时间线上重点观察以下 track:
CUDA UVM page faultCUDA UVM page migration
关注点不是"有没有迁移",而是:
- 迁移是否集中在 kernel 执行关键路径上(时间聚类)
- 同一页面是否在短时间(如 1 ms)内反复多次迁移(thrash)
- 是否存在大量 fault 密集排列,形成"fault burst"
最小命令示例(按实际路径调整):
bash
nsys profile -t cuda,nvtx,osrt -o um_trace \
./bin/02_memory_optim_05_unified_memory_pf --mode fault --runs 54.3 第三层:内存路径(NCU)
使用 Nsight Compute 分析 kernel 的单次执行,关注:
dram__bytes_read.sum/dram__bytes_write.sum(或对应语义 metric)- L2 命中率或吞吐相关 metrics(具体名称因架构与 NCU 版本而异,建议以语义匹配而非名称为准)
配合时间变化,解读:
- 若 prefetch 后 kernel time 下降,同时 DRAM 读字节数减少或分布更平坦 → 迁移干扰降低
- 若 advise 有效(如 ReadMostly),多 GPU 下应观察到更少的迁移事件与更均衡的 DRAM 访问
提示:不同 GPU 架构及驱动版本的指标名可能变化,建议在使用前通过
ncu --query-metrics确认可用名称。
最小命令示例(按实际路径调整):
bash
ncu --set full --target-processes all \
./bin/02_memory_optim_05_unified_memory_pf --mode prefetch --runs 14.4 决策函数:何时放弃 UM
当以下任一条件持续、可复现时,应果断放弃 UM,转向显式内存管理:
- 首轮 / 稳态中位数 > 1.5,且无法通过调整 prefetch/advise 消除
- 稳态 P95 / 中位数 > 1.2,且 NSYS 确认存在 kernel 执行过程中的 fault 或迁移事件
- NSYS 显示同一页面在 1 ms 内迁移超过 2 次(thrash 认定)
- 多 GPU 场景存在非只读的跨设备访问,且 NSYS 捕捉到反复的 page migration
- prefetch 后 kernel 时间未改善甚至恶化,并在 NCU 中发现 DRAM 流量异常增大或 L2 命中率显著下跌
满足任意一条,则应放弃 UM 路径,改由显式 cudaMalloc + cudaMemcpyAsync 接管,必要时结合双缓冲或 CUDA Stream 并发隐藏传输延迟。
注:上述阈值属于工程经验默认值(用于快速判停),应结合业务 SLA、GPU 架构与驱动版本做本地化校准。
5. 一条可直接执行的实验 SOP
- 固定输入规模与 kernel 配置,执行一次未计时的 warmup 迭代。
- 跑 A(fault-only)5 轮,记录每轮 kernel time,取 first / median / p95。
- 创建独立 stream,将
cudaMemPrefetchAsync置于该 stream,并通过 event 确保 prefetch 完成后才启动计算流中的 kernel,跑 B(同参数)5 轮,记录同样指标。 - 在 B 基础上添加一条或多条
cudaMemAdvise调用(例如 ReadMostly + PreferredLocation),跑 C(同参数)5 轮,记录指标。 - 用 NSYS 观察 A/B/C 的时间线,重点关注 fault/migration 事件的时间分布;用 NCU 补充 DRAM/L2 指标。
- 对照 4.4 节的决策规则:只有 B/C 相对 A 有稳定且显著的收益,且未触发任何一个放弃条件时,才将 UM 方案推进到业务路径。
6. UM vs. 显式管理:架构决策速查表
| 维度 | UM(on-demand) | UM + Prefetch + Advise | 显式内存 (cudaMemcpyAsync) |
|---|---|---|---|
| 编程复杂度 | 低 | 中 | 高 |
| 首轮延迟 | 不可预测,极易抖动 | 可预测(prefetch 覆盖后) | 完全可控 |
| 稳态尾延迟 | 容易抖动 | 一般可控,但需验证 | 可控 |
| 多 GPU 支持 | 易退化(page ping-pong) | 仅只读场景可能可接受 | 完全可控 |
| 适用场景 | 原型、非时延敏感离线任务 | 批处理、可预测流水线 | 实时推理、多 GPU 训练、严格 SLA |
7. 常见误区(工程高频翻车点)
- 把 UM 当成"自动最优搬运":它是自动,不是最优;默认路径的核心是 latency-bound 而非 bandwidth-bound。
- 只看均值不看首轮和 P95:UM 问题往往出现在尾延迟和冷启动阶段。
- 多 GPU 下盲目共享 managed 指针:非只读场景极易引发跨设备迁移风暴,默认应避开。
- prefetch 与计算流不同步:未用独立 stream 与 event 确保顺序,搬运未真正提前,kernel 仍原地 fault。
- advise 过度乐观:hint 生效与否取决于运行时与访问模式,必须实证而非假设。
- 忽略 prefetch 的页面粒度:稀疏小对象可能搬入大量无效数据,挤占带宽与缓存。
- 在多 GPU 下对写共享数据使用 UM:这是最常见的性能灾难诱因,应直接禁止。
8. 本章配套代码(占位)
💻 配套代码:`examples/02_memory_optim/05_unified_memory_pf.cu`
当前支持参数:
--n、--iters、--mode={fault|prefetch|advise}、--runs、--warmup、--device、--csv-only,输出first/median/p95/mean。NSYS 一键采集:
examples/02_memory_optim/05_profile_unified_memory.sh
8.1 RTX 5090 参考数据(n=16M floats / 64MB, iters=32, runs=5, warmup=1)
| mode | first (ms) | median (ms) | p95 (ms) | 解读 |
|---|---|---|---|---|
| fault | 0.255 | 0.221 | 0.248 | warmup 后页面已在 GPU,稳态快 |
| prefetch | 0.224 | 0.221 | 0.223 | 与 fault 同阶,prefetch 边际收益小 |
| advise | 0.220 | 0.219 | 0.220 | PreferredLocation+AccessedBy,无 ReadMostly |
反例(已修复) :对可写 UM 误用 cudaMemAdviseSetReadMostly 时,同一配置 median ~124 ms(约 560×),与文章 §2.2 / §7 的"hint 必须匹配访问模式"一致。
8.2 冷启动(fault-only,warmup=0, runs=3)
bash
WARMUP=0 RUNS=3 bash examples/02_memory_optim/05_profile_unified_memory.sh fault| 指标 | 值 (ms) | 解读 |
|---|---|---|
| first | 29.0 | 首轮 GPU 触达:按需 fault + 页面迁移,占满关键路径 |
| median | 0.236 | 第 2/3 轮已稳态(≈0.23 ms),与 §8.1 同阶 |
| p95 | 26.1 | 尾延迟仍被首轮/迁移拖住(3 轮样本下 p95≈0.9×first) |
| mean | 9.8 | 被冷启动严重拉高,不能用均值评判 UM 稳态性能 |
排序后三轮约为 [0.23, 0.23, 29] → 首轮 / 稳态中位数 ≈ 123× ,远超 §4.4 的判停阈值 1.5。
在 um_fault_trace.nsys-rep 的 CUDA HW 行查看首轮 kernel 是否与 UVM page fault / migration 时间簇重叠。
工程含义:报告性能时必须区分 first(冷) 与 median(热);仅看均值会把 29 ms 与 0.23 ms 平均成 ~10 ms,掩盖两个数量级的真实行为。