1.引入依赖:
<dependencies>
<dependency>
<groupId>com.easymall</groupId>
<artifactId>easymall-common</artifactId>
<version>1.0.0</version>
</dependency>
<!-- Spring AI -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<!--es 向量数据库-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
</dependency>
<!--openai-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
</dependency>
<!--ollama-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!-- Spring AI END -->
</dependencies>ollama可以不引用,按需所求,本文章使用的是阿里百炼,若本地安装可以使用ollama
2.配置springai
@Configuration
public class SpringAIConfiguration {
@Bean
public ChatClient chatClient(OpenAiChatModel openAiChatModel) {
Map<String, Object> extraBody = new HashMap<>();
extraBody.put("enable_thinking", false);
return ChatClient.builder(openAiChatModel)
.defaultOptions(OpenAiChatOptions.builder()
.extraBody(extraBody).build()).build();
}
@Bean
@Primary
public EmbeddingModel embeddingModel(OpenAiEmbeddingModel openAiEmbeddingModel) {
return openAiEmbeddingModel;
}
//本地ollama 配置
/*
@Bean
@Primary
public ChatClient chatClient(OllamaChatModel ollamaChatModel) {
return ChatClient.builder(ollamaChatModel)
.defaultOptions(OllamaChatOptions.builder().disableThinking().build())//禁用思考
.build();
}
*/
/* @Bean
@Primary
public EmbeddingModel embeddingModel(OllamaEmbeddingModel ollamaEmbeddingModel) {
return ollamaEmbeddingModel;
}*/
}提供两种方法,第一种是为本文的阿里百炼配置 注释部分为ollama方式
略微解释下为什么需要创建extraBody 因为springai中的所有配置都类似于"xxxx":xxxx 典型的map键值对结构,这里想要关闭深度思考(返回数据杂乱以及过于消耗token)
若是对langchain有了解的就会发现两者的差异,但是无需担心,代码方式不影响目前程序员的开发,必要时查看对应文档或者询问ai都可以,这里阐述两者的不同
3.大模型思路
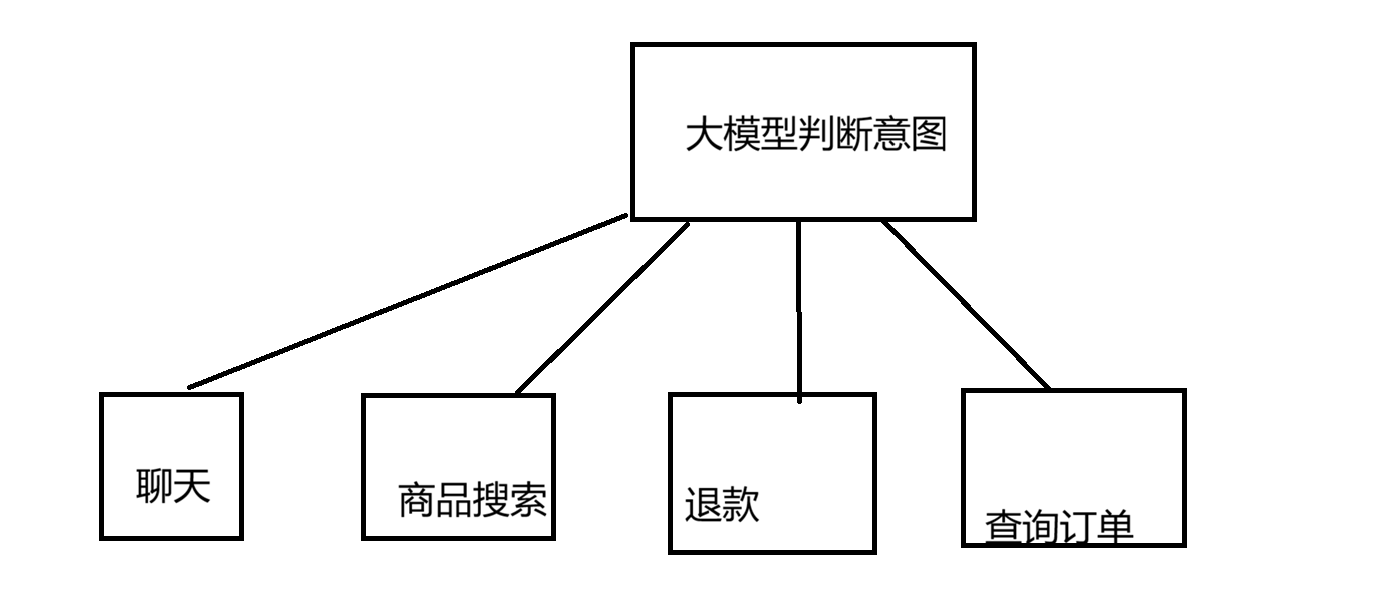
这只展现了一小部分,主要画图展现思路,本智能体的思路为让大模型判断用户输入的意图,返回对应意图的枚举,再通过switch匹对意图的枚举,每个意图对应不同的方法,使得一个大模型可以实现多种功能。本智能体一共有的功能为:聊天,商品搜索,退款,查询订单,ai智能评价,查询物流信息,取消待付款订单等等
本文章不提提示词,提示词思路上文所述,自己实现。
4.设计数据库表

5.具体功能实现:
5.1聊天接口:
public AgentMessage sendMessage(String userId, String userMessage) {
if (appConfig.getAiChatLimit() != 0) {
AgentMessageQuery agentMessageQuery = new AgentMessageQuery();
agentMessageQuery.setUserId(userId);
Integer chatCount = agentMessageService.findCountByParam(agentMessageQuery);
if (chatCount >= 10) {
throw new BusinessException("AI购物体验已经结束");
}
}
AgentMessage agentMessage = agentMessageService.saveMessage(userId, userMessage);
//异步调用模型回复消息
ExecutorServiceSingletonEnum.INSTANCE.getExecutorService().execute(() -> {
assistantAnswer(agentMessage);
});
return agentMessage;
}public void assistantAnswer(AgentMessage agentMessage) {
UserIntent userIntent = analyzeUserIntent(agentMessage.getUserId(), agentMessage.getUserMessage());
PromptTypeEnum promptTypeEnum = PromptTypeEnum.getByCode(userIntent.intent);
promptTypeEnum = promptTypeEnum == null ? PromptTypeEnum.CHAT : promptTypeEnum;
//用户意图分析完成后,提前判断一下是否取消
if (redisComponent.hasCancelMessage(agentMessage.getUserId(), agentMessage.getMessageId())) {
return;
}
switch (promptTypeEnum) {
case PRODUCT_SEARCH://搜索商品
searchProduct(agentMessage, userIntent.data);
agentMessageService.completeMessage(agentMessage.getMessageId(), agentMessage.getBizType(), agentMessage.getAssistantMessage(),
agentMessage.getBizData());
break;
case QUERY_ORDER://查询订单
queryOrder(agentMessage, userIntent.data);
agentMessageService.completeMessage(agentMessage.getMessageId(), agentMessage.getBizType(), agentMessage.getAssistantMessage(),
agentMessage.getBizData());
break;
default:
chat(promptTypeEnum, agentMessage);
}
}这里讲解一下异步调用启动的方式为什么是枚举
这里展示具体的枚举类:
public enum ExecutorServiceSingletonEnum {
INSTANCE;
private final ExecutorService executorService;
ExecutorServiceSingletonEnum() {
executorService = Executors.newFixedThreadPool(50);
}
public ExecutorService getExecutorService() {
return executorService;
}
}此枚举类非寻常枚举类,他算是一种封装启动线程的开关,INSTANCE为实例,所有的类都需要实例才能初始化,所以这个INSTANCE必不可少,可以换成自己喜欢的单词,A,B,C,D都可以,在ExecutorSercviceSingletonEnum()中就初始化了一个线程池 所以这里的意思是另起线程启动ai聊天的功能,避免与主线程闭塞
其中第一段是判断用户是否超过的轮询的次数,避免用户恶意刷屏,消耗token
private ChatClient.ChatClientRequestSpec getChatClientRequestSpec(String userId) {
String systemPrompt = getPrompt(PromptTypeEnum.GLOBAL, null, null, null);
return chatClient.prompt().system(systemPrompt).advisors(new LoggerAdvisor());
}private UserIntent analyzeUserIntent(String userId, String userMessage) {
String prompt = getPrompt(PromptTypeEnum.USER_INTENT, userId, userMessage, null);
UserIntent userIntent = getChatClientRequestSpec(userId)
.messages(getHistoryMessage(userId, prompt))
.call().entity(UserIntent.class);
return userIntent;
}
record UserIntent(String intent, String data) {
}getChatClientRequestSpec方法是一个工厂方法 ,目的是为指定的 userId创建一个预配置好全局系统角色和日志功能 的对话请求起点,确保所有从该方法发起的对话都遵循统一的基础设定并自动记录日志。这使得业务代码(如 analyzeUserIntent方法)可以专注于具体的对话内容,而无需重复配置这些通用设置。
这一段为分析用户意图,record为封装了一个简单的类,若不习惯可以直接创建一个UserIntent类,属性就为intent与data没有区别
getPrompt不粘贴了,避免过于冗余,简单方法可以自己思考如何实现,可以交给ai让ai生成一个模板
这里主要返回ai信息封装成具体类 使用了entity方法 将ai返回的内容封装成了userIntent类 本质上还是调用了大模型
返回示例(与实际开发例子无关):
{
"intent": "查询天气",
"data": "{\"city\":\"北京\",\"date\":\"2026-03-10\"}"
}
将这段代码反序列为userintent即为所得
assitanceAnswer方法即为所画图的大模型,剩下只要将自己所需的功能以此插入即可啦