文章目录
- [1. Spring AI](#1. Spring AI)
-
- [1.1 Usage](#1.1 Usage)
- [1.2 同步调用](#1.2 同步调用)
- [1.3 流式响应](#1.3 流式响应)
- [2. ReactAgent](#2. ReactAgent)
-
- [2.1 工作流程](#2.1 工作流程)
-
- [2.1.1 Token 存储](#2.1.1 Token 存储)
- [2.1.2 过滤分离](#2.1.2 过滤分离)
- [2.1.3 构建输出](#2.1.3 构建输出)
- [2.1.4 BUG 说明](#2.1.4 BUG 说明)
- [2.2 同步调用](#2.2 同步调用)
- [2.3 流式输出](#2.3 流式输出)
- [2.4 总量统计](#2.4 总量统计)
- [3. Graph](#3. Graph)
-
- [3.1 同步调用](#3.1 同步调用)
- [3.2 流式输出](#3.2 流式输出)
1. Spring AI
在智能体流式对话场景中,实时输出文本内容的同时,统计输入Token、输出Token、总 Token 消耗量是计费、限流、用量监控的核心需求。
1.1 Usage
Usage 接口是 AI 模型调用中用于标准化统计 Token 消耗的核心接口:
java
public interface Usage {
// 输入文本(提问)的 Token 数
Integer getPromptTokens();
// 输出文本(回答)的 Token 数
Integer getCompletionTokens();
// 总消耗 Token 数(默认实现)
default Integer getTotalTokens() {
Integer promptTokens = this.getPromptTokens();
promptTokens = promptTokens != null ? promptTokens : 0;
Integer completionTokens = this.getCompletionTokens();
completionTokens = completionTokens != null ? completionTokens : 0;
return promptTokens + completionTokens;
}
// 模型原生的 Token 数据(兼容不同模型)
Object getNativeUsage();
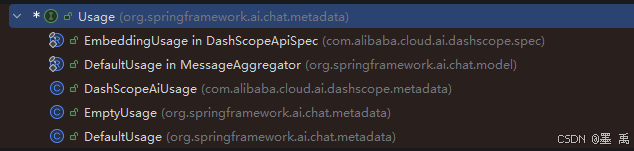
}各厂商集成模块中包含了具体实现类:
1.2 同步调用
同步调用时,可以使用 ChatResponse.getMetadata().getUsage() 方法查询到 Token 消耗信息:
java
ChatResponse chatResponse= zhiPuAiChatClient.prompt("你好").call().chatResponse();
Usage usage = chatResponse.getMetadata().getUsage();
Integer promptTokens = usage.getPromptTokens();
Integer completionTokens = usage.getCompletionTokens();
Integer totalTokens = usage.getTotalTokens();
System.out.println("提示词 消耗 TOKEN 数:"+promptTokens);
System.out.println("生成内容 消耗 TOKEN 数:"+completionTokens);
System.out.println("共计消耗 TOKEN 数:"+totalTokens);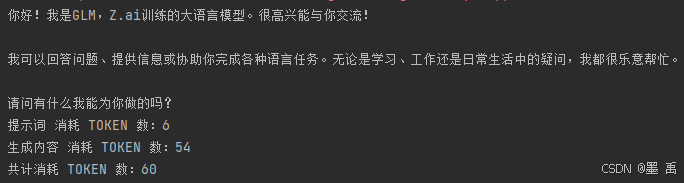
1.3 流式响应
如果是 stream 接口在处理中时,返回的是空实现,没有消耗信息:
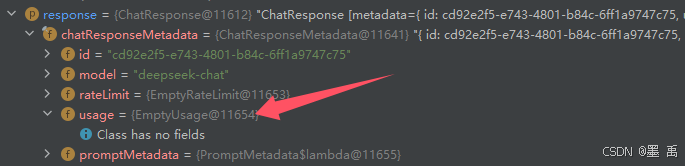
是在最后一次流中会输出本次消耗信息:

2. ReactAgent
由于存在
Bug,无法正常使用,官方最近几个月也不太活跃了,要用的话只能自己拉代码改源码了...可以参考 Github Issues
2.1 工作流程
2.1.1 Token 存储
AgentLlmNode 在同步调用处理时,会将模型响应 中的返回的 tokenUsage 存入全局状态:
java
// 执行链式处理器,将模型请求传入并获取模型响应结果
ModelResponse modelResponse = chainedHandler.call(modelRequest);
// 从模型响应中获取Token使用量:若聊天响应不为空则获取实际使用量,否则创建空的使用量对象
Usage tokenUsage = modelResponse.getChatResponse() != null ? modelResponse.getChatResponse().getMetadata().getUsage() : new EmptyUsage();
// 初始化存储更新后状态的Map集合
Map<String, Object> updatedState = new HashMap<>();
// 将Token使用量存入状态Map,键为固定值_TOKEN_USAGE_
updatedState.put("_TOKEN_USAGE_", tokenUsage);
// 将模型返回的消息存入状态Map
updatedState.put("messages", modelResponse.getMessage());
// 判断配置的输出键是否有有效值,若有则将模型消息以该键存入状态Map
if (StringUtils.hasLength(this.outputKey)) {
updatedState.put(this.outputKey, modelResponse.getMessage());
}
2.1.2 过滤分离
Graph 节点执行完成后在 NodeExecutor#handleActionResult 方法中,在合并增量状态至全局状态 方法中,会过滤分离 Token 用量数据:
java
/**
* 合并增量状态至全局状态
*/
public void mergeIntoCurrentState(Map<String, Object> updateState) {
// 过滤分离Token用量数据
Map<String, Object> filterState = findTokenUsageInDeltaState(updateState);
// 更新业务状态
this.overallState.updateState(filterState);
}自动分离_TOKEN_USAGE_不混入业务状态,可直接用于全局累加统计:
- 遍历更新状态集合,提取出固定键
_TOKEN_USAGE_对应的Usage对象 - 将提取到的
Token使用量赋值给当前类的tokenUsage属性 - 过滤掉
Token使用量数据,返回剩余的正常状态数据
java
/**
* 【临时修复方法】从状态更新中分离出 Token 使用量数据
*
* <p>FIXME 说明:这是一个临时修复方案,用于将 Token 使用量(Usage)从状态更新数据中分离出来
* @param updateState 原始的状态更新Map,包含消息、Token用量等数据
* @return 过滤掉 Token 使用量后的纯净状态Map
*/
private Map<String, Object> findTokenUsageInDeltaState(Map<String, Object> updateState) {
// 初始化过滤后的状态Map,用于存储除Token用量外的所有状态数据
Map<String, Object> filteredState = new HashMap<>();
// 遍历原始状态更新数据,分离Token用量
for (Map.Entry<String, Object> entry : updateState.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
// 判断:数据类型为Usage 且 键为固定标识 _TOKEN_USAGE_,则为Token使用量
if (value instanceof Usage && key.equals("_TOKEN_USAGE_")) {
// 将提取到的Token使用量赋值给当前对象的成员变量,供后续统计/日志使用
this.tokenUsage = (Usage) value;
} else {
// 非Token使用量的数据,保留到过滤后的状态Map中
filteredState.put(key, value);
}
}
// 返回过滤完成、不包含Token用量的纯净状态数据
return filteredState;
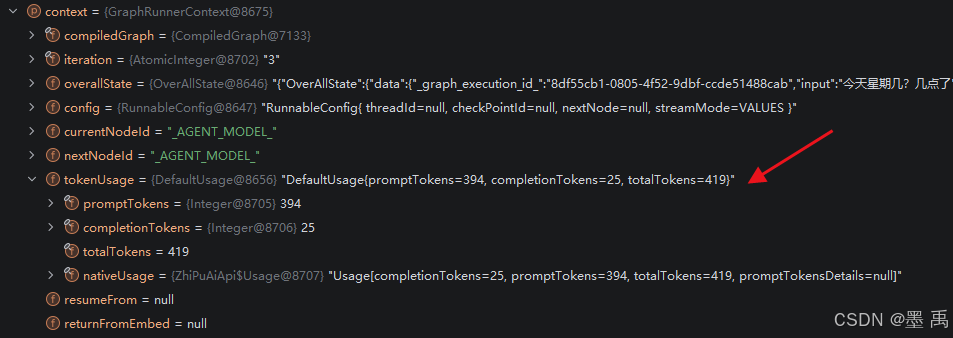
}状态中的 _TOKEN_USAGE_ 会赋值给 GraphRunnerContext 图执行上下文对象:
2.1.3 构建输出
NodeExecutor#handleActionResult 方法中会构建 NodeOutput 节点输出对象:
java
NodeOutput output = context.buildNodeOutputAndAddCheckpoint(updateState);最后的 buildNodeOutput 方法中会构建 StreamingOutput 会设置本次响应的 Token 消耗:
java
/**
* 流式输出对象构造方法
* 用于构建AI流式响应的输出实体,承载消息内容、节点信息、状态、Token用量等核心数据
* 专门服务于AI对话流式返回场景(非阻塞、逐片段返回结果)
*
* @param message AI返回的完整消息对象,包含对话内容、元数据等
* @param node 当前执行的节点名称(如AgentLlmNode、工具调用节点)
* @param agentName 智能体名称,标识当前是哪个AI智能体产生的响应
* @param state 全局状态对象,存储对话上下文、会话数据等全量状态
* @param usage Token使用量统计对象,记录本次AI调用的消耗额度
* @param outputType 输出类型枚举,标记当前是普通消息/工具调用/结束标识等类型
*/
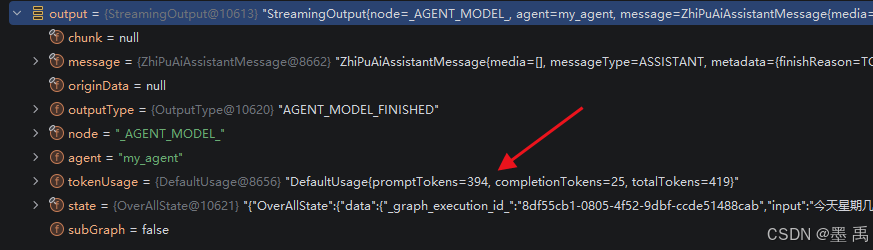
public StreamingOutput(Message message, String node, String agentName, OverAllState state, Usage usage, OutputType outputType) {
// 调用父类构造器,初始化节点名称、智能体名称、全局状态基础属性
super(node, agentName, state);
// 赋值原始完整消息对象
this.message = message;
// 从完整消息中提取流式片段(chunk),用于SSE/websocket逐段返回前端
this.chunk = extractChunkFromMessage(message);
// 原始业务数据置空(当前构造场景无需传递原始第三方数据)
this.originData = null;
// 设置当前流式输出的类型(消息片段/结束/工具调用等)
this.outputType = outputType;
// 注入本次流式响应的Token消耗统计数据,用于计费/监控/限流
setTokenUsage(usage);
}
最终该节点返回 Flux ,并递归调用 MainGraphExecutor 处理下一个节点:
java
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> mainGraphExecutor.execute(context, resultValue)));2.1.4 BUG 说明
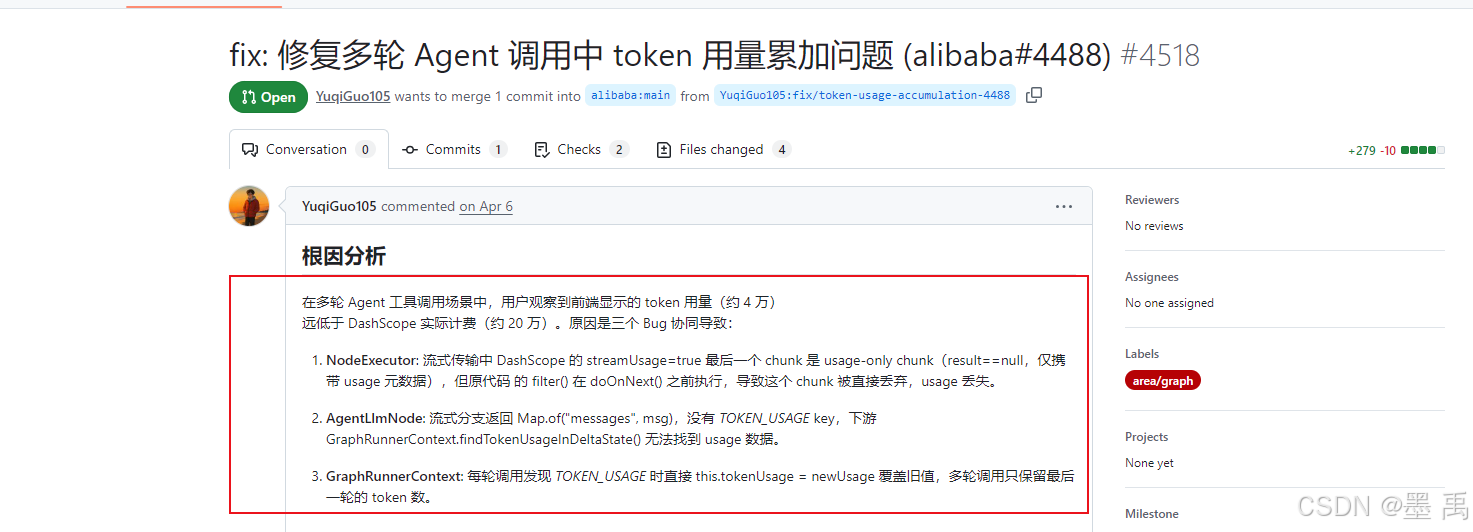
通过流程分析,可以发现一个很明显的 BUG , ReactAgent(多步骤思考 / 调用工具)会调用多次 LLM,每调用一次就产生一次 Token ,每次 LLM 节点执行完成后,tokenUsage 是直接赋值(覆盖)给执行上下文。
在同步调用时,是通过把【异步 / 流式】的执行变成【同步阻塞】调用处理的,ReactAgent 多轮调用会产生多个输出 chunk ,但 .last() 只取最后一个输出 ,原来的代码 Token 没有累加,只存在最后一个输出里,所以你拿到的永远是 最后一轮 Token 消耗量:
java
/**
* 同步调用执行节点,并返回最终的【唯一输出】
* @param inputs 输入参数
* @param config 运行配置
* @return 包装成 Optional 的最终节点输出(防止空指针)
*/
public Optional<NodeOutput> invokeAndGetOutput(Map<String, Object> inputs, RunnableConfig config) {
// 调用流式方法 → 取最后一个元素 → 阻塞等待执行完成 → 包装成 Optional 返回
return Optional.ofNullable(
stream(inputs, config) // 1. 启动流式执行(返回 Flux<NodeOutput>)
.last() // 2. 取流里【最后一个】输出(ReactAgent 最终答案)
.block() // 3. 阻塞主线程,等待整个 Agent 执行完毕
);
}除此之外,还有其他 BUG 导致,具体可以参考 Github Issues ,修复 PR 是在 2026 年 4 月 6 日提出的,截止当前未合并也未发布修复版本:
2.2 同步调用
同步调用比较简单,直接通过 NodeOutput 就能拿到 Token 消耗量:
java
NodeOutput nodeOutput = chatAgent.invokeAndGetOutput("今天星期几?几点了").get();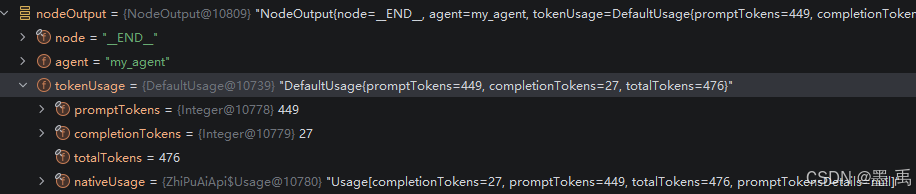
由于
BUG拿到的永远都是最后一次LLM调用
2.3 流式输出
流式输出获取 tokenUsage :
java
// 1. 获取流式流
Flux<NodeOutput> agentStream = chatAgent.stream("今天星期几?几点了");
// 2. 直接订阅打印,不封装 SSE
agentStream
.filter(nodeOutput -> !(nodeOutput instanceof StreamingOutput<?> so
&& so.getOutputType() == OutputType.AGENT_MODEL_FINISHED))
.subscribe(nodeOutput -> {
try {
String node = nodeOutput.node();
Usage tokenUsage = nodeOutput.tokenUsage();
// 处理流式输出
if (nodeOutput instanceof StreamingOutput<?> streamingOutput) {
Message message = streamingOutput.message();
if (message == null) return;
if (message instanceof AssistantMessage assistantMessage) {
String content = assistantMessage.getText();
// ====================== 直接打印!======================
System.out.println("【AI 实时输出】" + content);
System.out.println("节点:" + node + " | Token:" +
(tokenUsage != null ? tokenUsage.getTotalTokens() : 0));
}
}
} catch (Exception e) {
System.err.println("打印出错:" + e.getMessage());
}
}, error -> {
System.err.println("执行错误:" + error.getMessage());
});由于 AgentLlmNode 流式分支处理中,没有设置 TOKEN_USAGE ,所以一直都是 0 :
java
节点:_AGENT_MODEL_ | Token:0
【AI 实时输出】我来
节点:_AGENT_MODEL_ | Token:0
【AI 实时输出】帮
节点:_AGENT_MODEL_ | Token:0
【AI 实时输出】您
节点:_AGENT_MODEL_ | Token:0
【AI 实时输出】查询
节点:_AGENT_MODEL_ | Token:0
【AI 实时输出】今天是2.4 总量统计
Spring AI Alibaba 没有实现总量统计功能,只能自定义实现:
- 修改
GraphRunnerContext源码,实现累加逻辑 - 在请求层自定义
Token累加逻辑
3. Graph
3.1 同步调用
同步调用的 LLM 节点,参考 AgentLlmNode 设置 _TOKEN_USAGE_ 即可:
java
public class StreamLlmNode implements NodeAction {
private final ChatClient chatClient;
public StreamLlmNode(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
String query = state.value("query").orElse("");
// 同步调用
ChatResponse modelResponse = chatClient.prompt()
.user(query)
.call()
.chatResponse();
Usage tokenUsage = modelResponse.getChatResponse() != null ?
modelResponse.getChatResponse().getMetadata().getUsage() : new EmptyUsage();
// 你要求的逻辑
Map<String, Object> updatedState = new HashMap<>();
updatedState.put("_TOKEN_USAGE_", tokenUsage);
updatedState.put("messages", modelResponse.getMessage());
return updatedState;
}
}当前,还是一样的有
BUG
3.2 流式输出
流式输出的 LLM 节点,也是一样,需要加上 _TOKEN_USAGE_ :
java
Map<String, Object> updatedState = new HashMap<>();
updatedState.put("messages", modelResponse.getMessage());
if (StringUtils.hasLength(this.outputKey)) {
updatedState.put(this.outputKey, modelResponse.getMessage());
}
// 流式模式下 getChatResponse() 通常为 null(ModelResponse.of(Flux) 不持有 ChatResponse)。
// 实际 usage 由 NodeExecutor 的 latestUsageRef 捕获。
// 这里放入 EmptyUsage 占位,确保 _TOKEN_USAGE_ key 存在以触发下游累加逻辑。
Usage tokenUsage = modelResponse.getChatResponse() != null
? modelResponse.getChatResponse().getMetadata().getUsage()
: new EmptyUsage();
updatedState.put("_TOKEN_USAGE_", tokenUsage);
return updatedState;