前言:
地下水水位数据是水文分析与管理决策的"底盘":补给---径流---排泄判别、含水层动态评价、超采预警与生态修复成效核验,都离不开连续、可比的水位序列。但现实中,高质量水位往往分散在年鉴、报告或扫描 PDF 里,既难批量获取,也难直接用于统计建模。把 PDF 中的水位表可靠地结构化为 Excel/数据库,等于把"可读资料"变成"可算数据",才能开展跨年对比、区域空间分析、异常识别与成果复核,并显著降低重复整理的时间成本。
数据介绍
《全国地质环境监测地下水位年鉴》汇集了度国家地下水监测工程水位监测成果,覆盖10000多个国家级监测点。年鉴按行政区划顺序编排,监测点基本信息包括统一编号、监测点位置、地面高程、监测深度(水层组顶/底板埋深)、地下水资源分区、含水介质与埋藏条件等,为开展区域地下水动态评价与对比分析提供了权威底表。监测点统一编号为12位数字:前6位对应GB/T 2260---2007行政区划代码(省、市、县),第7位标识监测大类(2为地下水),第8位为站点级别(1国家级等),第9---12位为省内监测井序号。水位以"水位标高(米)"表示;监测数据来源于自动化设备小时级采集传输,受篇幅限制,出版时采用"每5日1条"的展示方式,并给出月平均、最大、最小及水位变幅等统计指标;2月28日数据并入30日并以"*"标注。地面高程采用1985年黄海高程系,少数测流站监测深度为空。需要注意的是:早期(2005---2017)年鉴多为约千个站点规模,统计指标以"埋深"为主;自2018年起站点数量跃升至万点量级,且统一编号编码体系与记录口径发生调整,2018---2021年主要以"水位标高"呈现,更利于跨区对比与与地形/高程体系衔接。年鉴强调数据整编的长期性与复杂性,并提示四舍五入保留两位小数可能导致变幅出现0.01 m级差异。
数据获取:点击链接直达
数据说明
【属性信息】
-
统一编号:地下水动态监测站点统一编码
-
位置:监测站点地址
-
地下水水力类型:又称为含水介质及埋藏条件
-
监测深度:监测水位位置埋深
-
水文地质单元:有的年份pdf名称为地下水资源分区
-
日期:日尺度(2005-2017年日期格式不固定有的是每一天都有,有的是每5日记录一次,另外原始数据部分表格部分天可能存在不全,2018-2021年则是每5天记录一次)
-
地下水埋深:2005-2017以地下水埋深记录,2018-2021年以地下水水位记录
-
月平均埋深:该月该站点地下水平均埋深
-
月最大埋深:该月该站点地下水最大埋深
-
月最小埋深:该月该站点地下水最小埋深
-
水位变幅:该月水位变动幅度
【数据信息】
-
数据时间:2005-2021年
-
站点数量:2005-2017年每年站点个数在900-1000之间,2018-2021在1万个左右
-
数据格式:excel表格
-
站点坐标:通过高德反查及位置纠偏获得每个站点的经纬度坐标
-
坐标系:WGS84
-
数据单位:m(米)
-
数据提示:本人全部将数据进行反查,并对数据进行修复,所有数据均尊重原始书本记录,有时发现书本可能记录错误,也已经在备注中说明,均可自行查看是否合理。
处理说明
1、年鉴很难"直接用"
年鉴里的水位附表看上去是表格,但对程序而言通常是两种情况:
-
扫描图:只能 OCR
-
看似可复制的文本表格:复制出来也会列错位、换行断裂、小数点/负号混乱
-
更关键的是:OCR 的输出不是表格,是一堆文字框(每个框有坐标+文字)。你要做的是把这些框重新拼成"行-列-单元格"。
2、页面不是一种版式,而是一堆"变体"
坑 A:有的页倾斜、有的页反转(180°)
-
年鉴扫描质量不完全一致:个别页轻微倾斜,甚至出现整页倒置。
-
我做了一个"关键词命中"判断:如果识别出的文本里关键字命中很少,就再把页面旋转 180° 重新 OCR,谁命中高用谁。
坑 B:同一页可能有多张表(多个监测点)
-
水位数据页经常"一个页面包含多个监测点表格"。
-
所以不能只找一次表头,要在同一页里找多个 1--12 月表头,按表头分块提取。
3、"识别过了"与"识别少了"
坑 C:表头容易"识别过了",把别的格子内容当成月份或列内容
-
表头附近往往有其他数字(页眉、统计字样、表格右侧说明),OCR 可能把这些数字混进来,导致列中心错位,后面整表都串列。
-
我的策略是两步:表头只认 1--12 的数字
-
用已识别的月份做线性拟合(1--12 的 x 坐标应近似等距),把缺的月份中心补出来,得到"12 列的列中心线"。
-
这样哪怕 OCR 只识别出 1、2、3、6、8,也能推断出其余月份列的位置,避免整表漂移。
坑 D:月份容易识别少(特别是小字、贴线、扫描糊)
-
表头"11、12"最容易少一笔变成"1/2",或者干脆丢失。
-
所以我不强依赖"必须识别到 12 个月",而是用拟合补齐;但同时也会做一个判断:若有效月份过少,则触发兜底方案(见后文网格裁剪)。
4、四位数的噩梦:
特别对 4 位数的,因为单元格之间间距小,很容易把别的识别过来",这确实是地下水位年鉴里最常见的灾难现场之一。典型症状包括:
-
1416.98 被识别成 416.98(漏千位)
-
1416.98 被拆成两段:141 + 6.98(碎片化)
-
左右格子数字挤在一起,OCR 把边界看错,"把别的格子识别过来"(串格)
-
我的做法是"先归位、再拼接、再纠错":
-
先按列中心最近邻把每个文字框分到某个月份列
-
同一个月份列里,按 x 从左到右拼接碎片,得到候选字符串
-
对候选字符串做数值恢复(修小数点、修千位、修/10 等)
5、负号经常漏:不处理会把埋深/水位方向搞反
对细小的负号特别不稳定,尤其是:负号很短、负号贴着表格线、字体细、扫描糊
-
我做了两层处理:清洗阶段统一负号字符
-
把 --- − 等都归一到 -序列层面的异常检测
-
同一监测点的时间序列,如果出现"孤立的符号反转",且改符号后能显著贴近前后邻值,则标记"疑似符号异常",并在非常明确时做自动修复(同时写入备注,保证可追溯)。
6、统一编号容易少位数
统一编号是两张表的"主键"。但 OCR 对长数字同样不友好:少识别一位、两位、前导零丢失、甚至被 Excel 自动转成科学计数法
-
我的处理方式:
-
编号字段只提取数字
-
统一规范为固定长度(如取末 12 位,不足则按规则补齐/保留)
-
在水位页解析到的编号,如果可疑(位数不够/不稳定),就用"监测点列表页"里提取出的编号库去做反查匹配(最稳的方式是:编号+位置文本相互校验)
-
最终输出 Excel 时,我还强制把"统一编号"这一列写成文本格式,避免 Excel 自动变形。
7、漏掉某一页、某一个表格
年鉴这种超长 PDF,其中2018-2021年每一本都超过3000页,最要命的是:你以为跑完了,实际漏了几页或漏了页内某个表。
-
我做了三件事降低漏提风险:进度文件 progress.json
-
只有当该页数据已成功写入缓存 CSV 后,才记录为"已处理",断点续跑不会误跳缓存 CSV 追加写入
-
运行中不频繁写 Excel,避免 Excel 被占用导致数据没落盘页内多表头检测
-
同页多张水位表时,找多个表头并分块提取,避免"只提第一张表"
-
此外,遇到"页面倾斜导致表头没识别出来"的情况,我倾向于:宁可不写进度,让后续人工抽查或二次跑能重新捞这页,而不是把它标记为完成。
8、月统计(平均/最大/最小/变幅),做一致性校验
年鉴水位表通常在日值下方还有 4 行月统计。它的难点是:字号更小、更贴线、容易混入"年统计"一行、很容易错位(把年统计数字当成月统计)
- 行识别(优先)在最后一个日值行之后,找"在 12 个月区域内数字密度很高"的 4 行,分别对应平均/最大/最小/变幅。
-
提取后不做"反算改值",只做一致性检查并写备注,例如:
-
月最大 < 月最小(疑似错位)
-
变幅与(最大-最小)明显不一致
-
变幅过大(超过经验阈值)
-
月平均不在min,max附近
-
这样后续使用者能快速定位"需要人工复核"的月份。
9、地址到坐标:让监测点能"投点",并给坐标可靠性打分
年鉴站点信息一般都给"监测点位置"(文字地址),但经纬度不一定完整、也不一定适合直接 GIS 使用。为了让点位更好用,我做了地址地理编码,并且把"可靠性"当成一个必须输出的指标。
用高德地理编码 + 反查校验
-
流程大致是:
-
用地址调用高德地理编码得到坐标(高德返回一般为 GCJ-02,"火星坐标")再用该坐标做逆地理编码,得到返回的省/市/区县/乡镇/街道等结构化信息,用逆地理结果去和原始地址文本做一致性校验,并打分
-
地址可靠性打分:省/市/县/乡镇逐级给分
-
我做的打分逻辑比较"地质项目化",核心是:行政层级越匹配越可信。
-
GCJ-02 → WGS84:把坐标纠偏回 GIS 常用坐标系
-
高德坐标是 GCJ-02,如果要和常见底图、GPS、以及很多地学数据统一,一般需要转 WGS84。我在落库时把高德坐标做了 GCJ-02 转 WGS84 的纠偏,保证投点不会整体偏移。
仅此记录我做数据的过程
数据展示
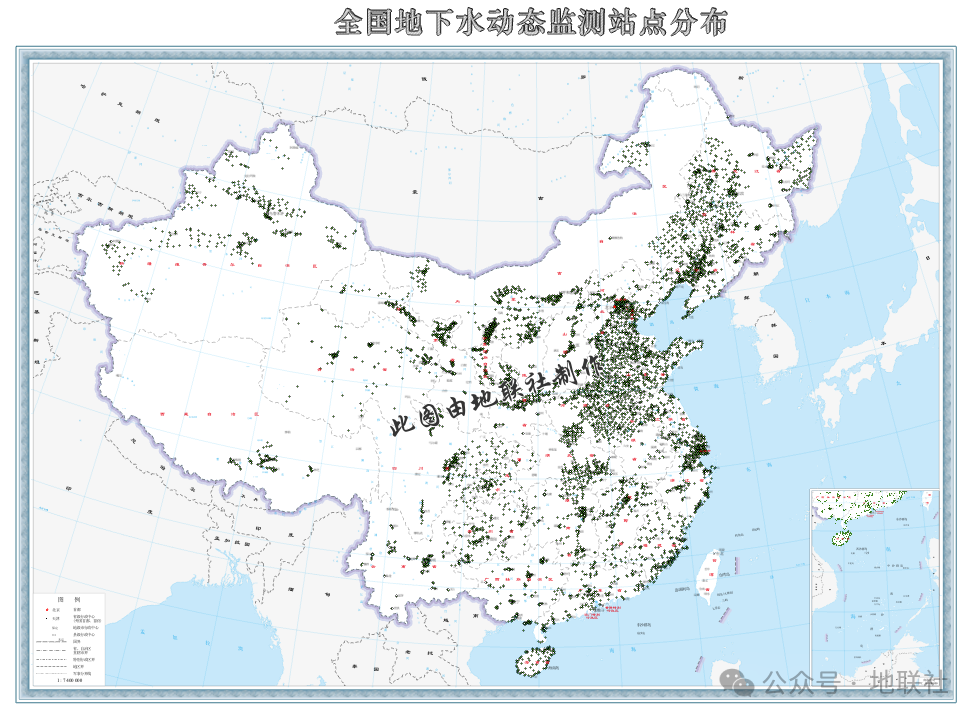
▲全国地下水监测站点点位分布图
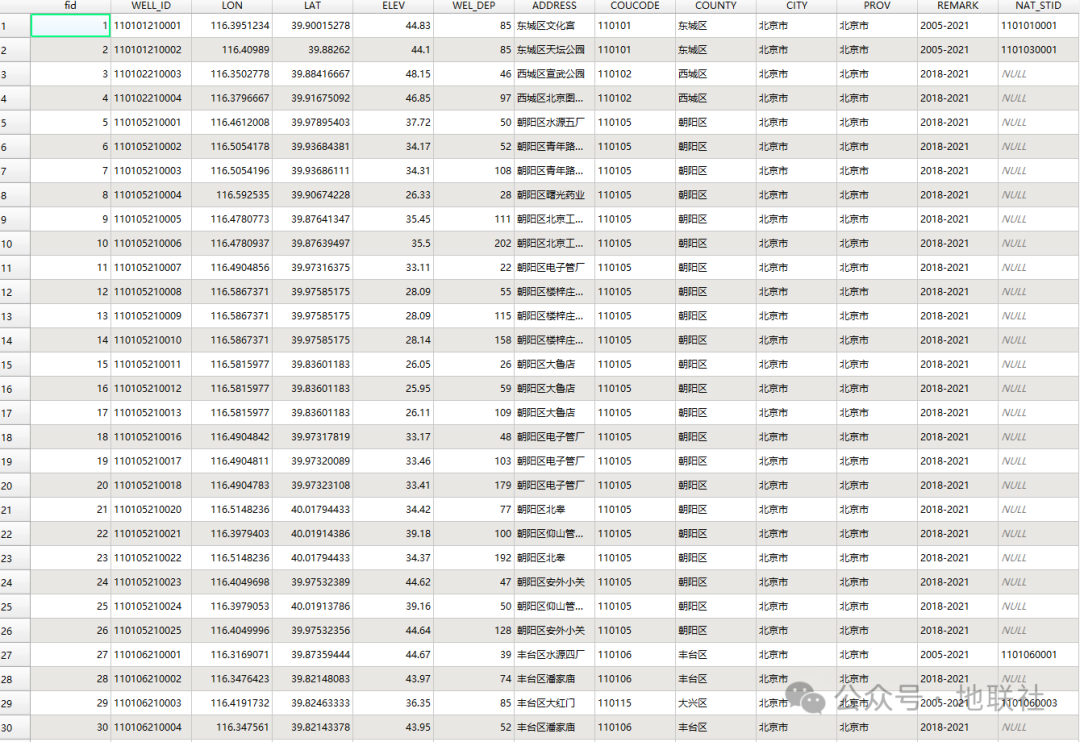
▲部分监测站点位表格展示
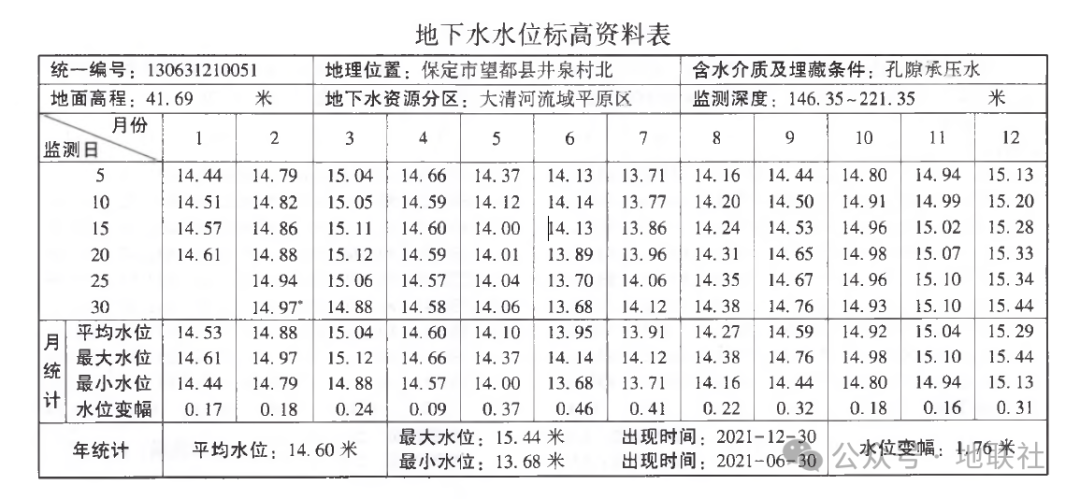
▲某一个站点(PDF)具体展示
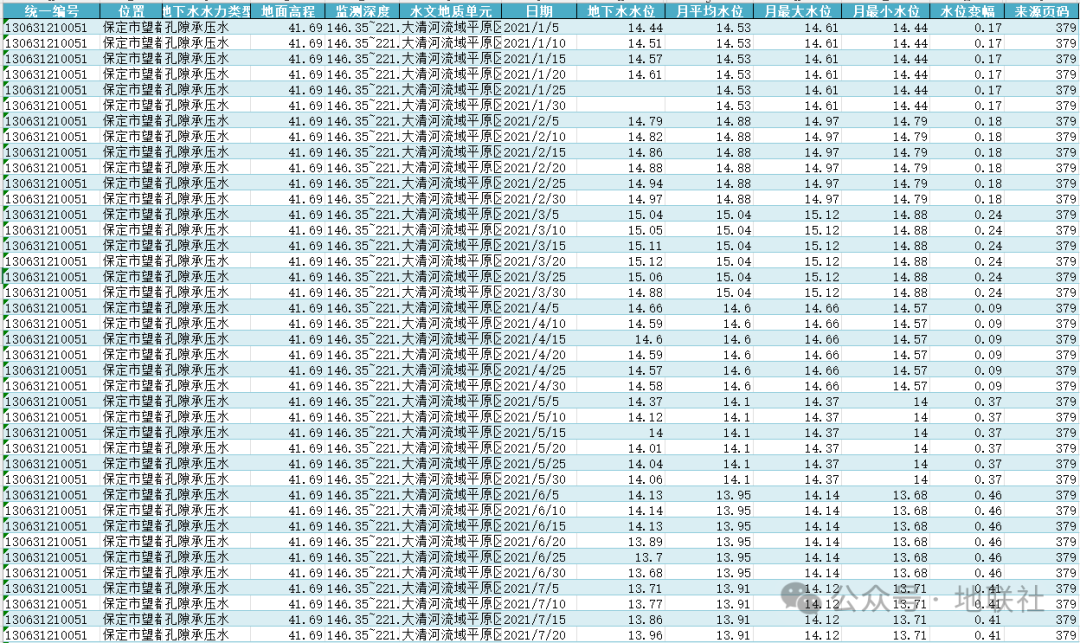
▲某一个监测站点识别的excel数据(完美匹配)
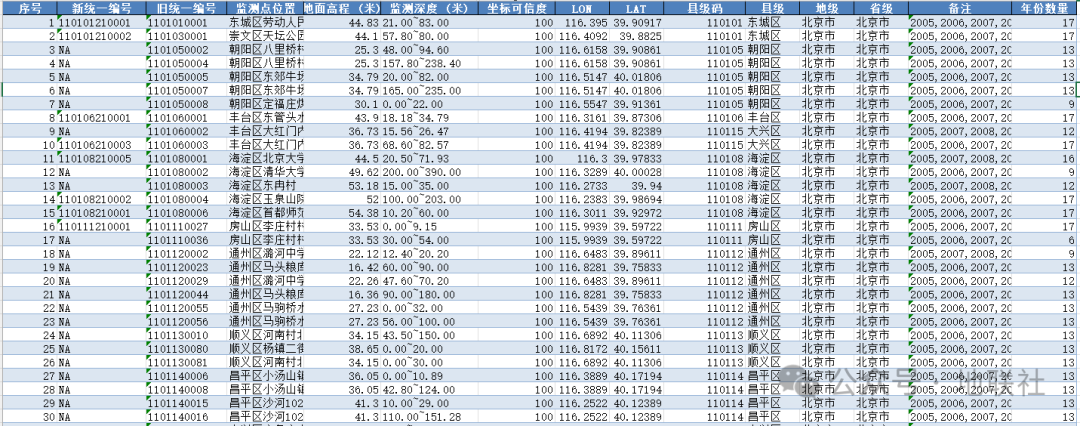
▲监测站点所有年份统计(部分站点年份仅仅1年)
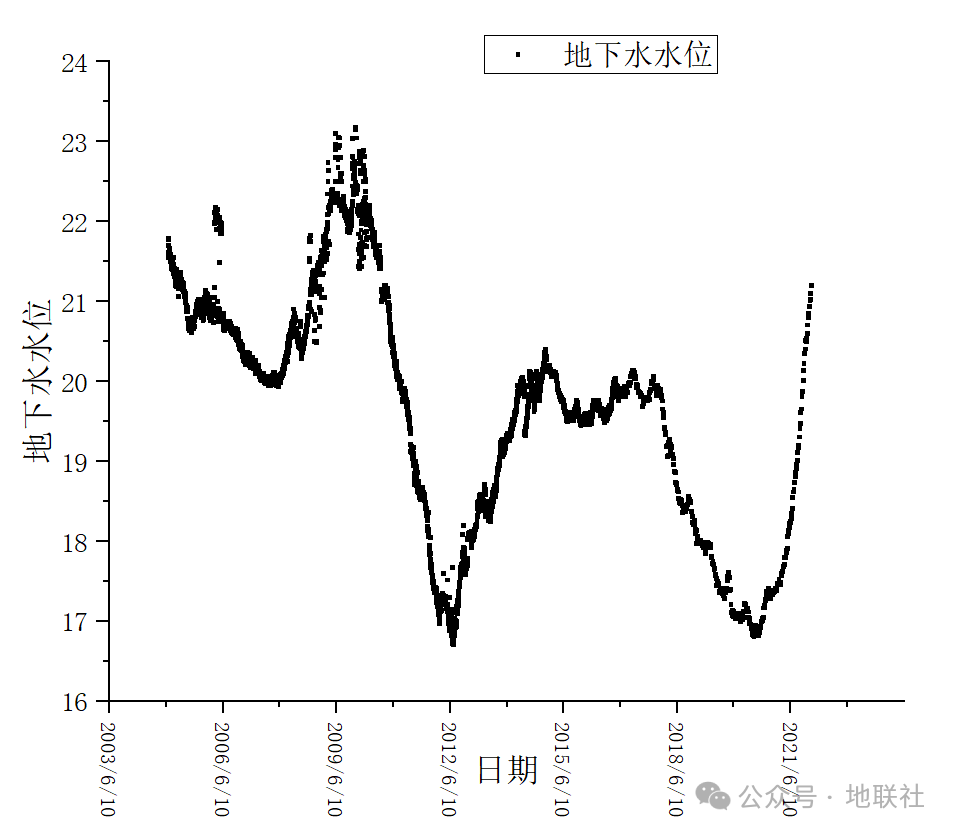
▲北京市东城区2005-2021年水位变化
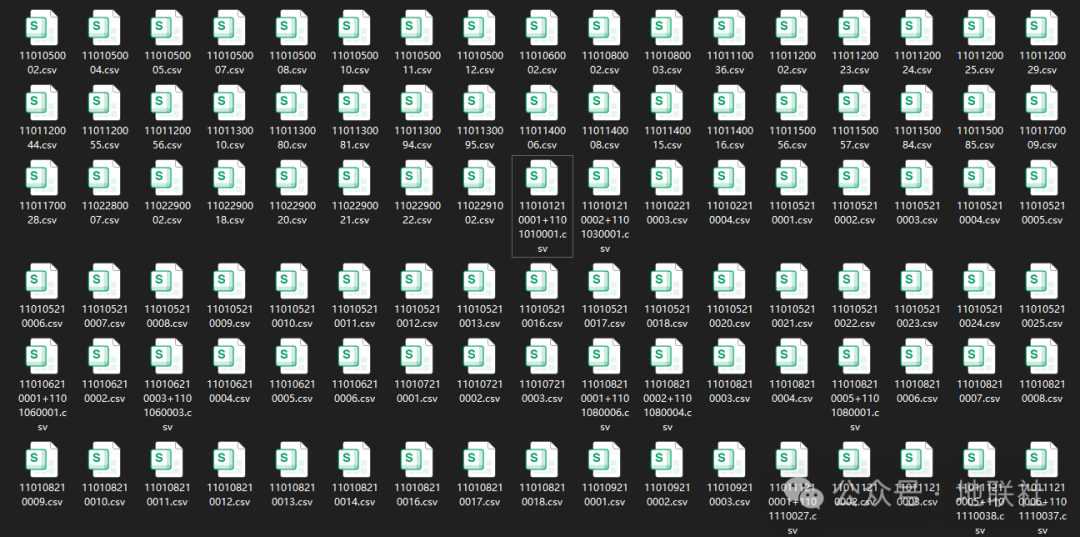
▲每个省每个市的站点数据汇总
数据引用
数据引用:《中国地质环境监测地下水位年鉴》