在当前的大模型应用开发中,许多开发者对 Prompt Engineering 的理解仍停留在"如何把问题描述得更清楚"。但在真实的商业级应用落地中,我们需要解决的是意图误判、格式污染、上下文粘连以及端到端渲染崩溃等深层次的工程问题。基于多模态生成系统的底层调优经验,本文梳理了一套关于大模型系统解耦与高可用架构的工程实践方案。
目录
[一、 显式思维链与系统可观测性](#一、 显式思维链与系统可观测性)
[二、 少样本(Few-Shot)的克制与 Format-as-Example 模式](#二、 少样本(Few-Shot)的克制与 Format-as-Example 模式)
[三、 业务逻辑解耦与前端 UI 安全降级](#三、 业务逻辑解耦与前端 UI 安全降级)
[1. 构建隐性翻译机制](#1. 构建隐性翻译机制)
[2. 执行前端安全降级](#2. 执行前端安全降级)
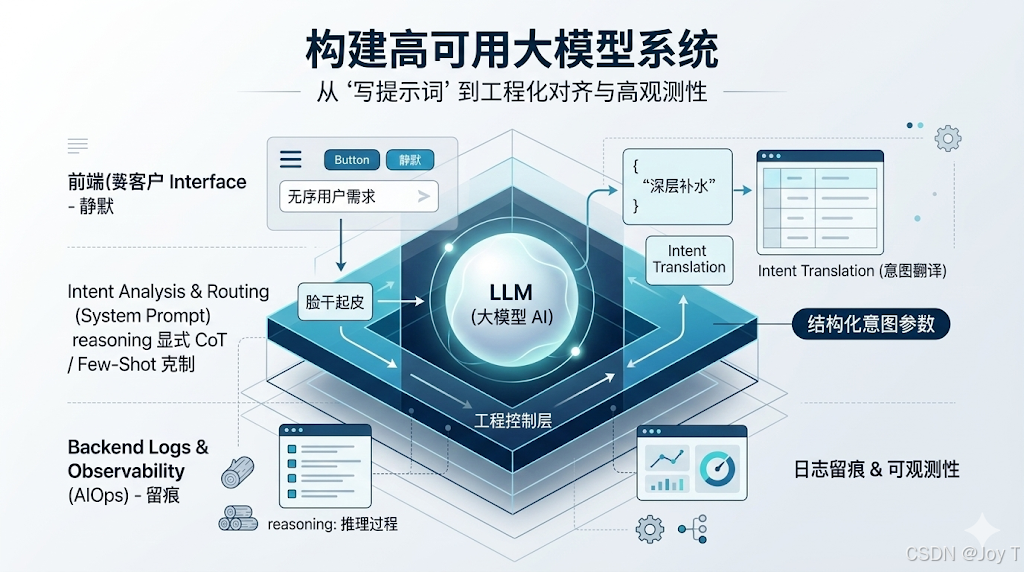
一、 显式思维链与系统可观测性
在复杂的路由解析和意图识别任务中,直接让大模型输出最终结论(如判断是"闲聊"还是"触发业务表单"),极易导致大模型逻辑崩溃或误判。
工程解法:引入显式思维链(Explicit CoT)
在工程实现上,可以在底层系统的 Prompt JSON 结构中前置植入 reasoning(推理过程)字段,构建显式思维链(Explicit CoT)。这种机制强制模型"先思考,后输出":
-
前端静默,后端留痕 :在数据流转层面,前端页面代码被设计为仅读取内容载体或业务初始化字段进行视图渲染,向终端用户完全隐藏 AI 的推理过程。包含 reasoning 的完整 JSON 数据会被后端日志系统完整抓取。
-
赋能 AIOps :这个微小的结构调整,极大地提升了系统的可观测性。在发生路由误判或参数提取异常时,研发人员可通过后端日志精准定位大模型推理链路的偏差节点【也就是看模型是怎么想错的,以此进一步优化System Prompt】,使调试工作具备高度的可追溯性,高度契合智能运维(AIOps)的工程标准。
二、 少样本(Few-Shot)的克制与 Format-as-Example 模式
在约束大模型输出复杂 JSON 格式时,新手常犯的错误是在 Schema(结构模板)的 Value 中添加引导说明,例如:"topic": "推测的主题(如:新品发布)"。这在生产环境中是极其危险的,大模型极易产生"模板模仿"幻觉,直接输出带有括号的污染数据,破坏前端渲染。
工程解法:Schema 定义骨架,Few-Shot 定义血肉
-
纯净的 Schema :彻底剥离模板中的解释性词汇,只保留绝对干净的键值结构。
-
Format-as-Example :直接利用 Prompt 尾部的实战案例(Few-Shot)来接管格式示范。大模型通过阅读真实的业务对话及标准 JSON 响应,能完美领悟字段的填充规范。
-
克制使用 Few-Shot:添加过多的案例会导致三大致命风险:
-
过拟合幻觉(Over-fitting):模型学会了"抄袭"案例中的具体业务词汇(如强行在无关场景插入"骨质疏松"),丧失了泛化能力。
-
注意力稀释(Attention Dilution) :过长的案例会冲淡模型对顶部"合规红线"等强指令的注意力。
-
Token 成本飙升:大幅拖慢推理响应并增加 API 成本。
-
-
最佳实践 :针对强逻辑约束,只放 1 个极度标准的黄金 Shot 即可;而对于代码生成(如 HTML/Tailwind 渲染)任务,为防止模型偷懒照抄版式,Zero-Shot 配合强规则约束反而是更优解。
三、 业务逻辑解耦与前端 UI 安全降级
一个成熟的大模型系统,必须在"傻瓜式"的客户端易用性与底层 AI 的专业严谨性之间找到绝佳的平衡点。通过在 Prompt 中明确划分不同字段的职责,可以实现深度的业务逻辑解耦,为用户体验筑起护城河。
工程解法:显式痛点翻译与 UI 降级转化
1. 构建隐性翻译机制
系统可以允许模型在处理面向用户的交互标签时保持通俗宽泛 ,同时在不可见的底层字段中,强制将用户的口语化表述自动"翻译"为极具深度的行业级干预方案。这种双向映射既不增加用户的认知负担,又死死守住了输出结果的专业底线。
2. 执行前端安全降级
大模型在处理多模态界面生成时,极易因复杂的视觉修饰词陷入渲染歧途。在意图解析阶段,必须果断剥离那些容易引发系统异常的抽象视觉词汇(如"轮廓"),将其强制降级并映射为标准的纯色角标、常规文本标签等前端绝对安全的 UI 组件。这种防御性设计,从源头掐断了渲染灾难的可能。