Hi,我是阿昌,今天记录下大模型里面几个经常看到,但是一开始又很容易混在一起的概念词汇。
比如平时调用大模型 API 的时候,经常会看到这些参数:
Token上下文窗口PromptlogitssoftmaxTemperatureTop-pTop-kRepetition PenaltyPresence PenaltyFrequency Penaltylogprobs
这些词看起来像是模型底层原理,但其实和做 AI 应用开发非常相关。
因为它们会直接影响三个东西:
- 请求花多少钱
- 模型输出稳不稳定
- 结果会不会跑偏、重复、截断
下面就简单按调用大模型的流程,把这些概念梳理一下。
一、先把大模型调用过程说简单点
一次普通的大模型调用,大概可以理解成下面这个过程:
text
用户输入 Prompt
↓
文本被切成 Token
↓
Token 放进上下文窗口
↓
模型根据上下文计算下一个 Token 的分数
↓
通过 softmax 把分数转成概率
↓
根据 Temperature / Top-p / Top-k 等参数进行采样
↓
一个 Token 一个 Token 生成最终回答所以大模型不是一次性"写出一整段话",而是不断预测:
理解了这一点,后面的参数就好理解很多。
二、Token 是什么?
那 Token是啥?
Token可以简单理解为模型处理文本的最小单位。
它不完全等于中文里的"字",也不完全等于英文里的"单词",而是模型分词器切出来的一小段文本。
比如:
text
我喜欢Java可能会被切成:
text
我 / 喜欢 / Java也可能因为不同模型的分词器(Tokenizer)不同,被切成其它形式。
这里要注意:
大模型计费、上下文长度、输出长度,通常都是按 Token 算的,不是按字数算的。
所以平时看到模型价格里写的"每百万 Token 多少钱",说的就是输入 Token 和输出 Token 的成本。
一般来说:
- 输入越长,
input tokens越多,成本越高 - 输出越长,
output tokens越多,成本越高 - 上下文越大,模型处理压力越大,延迟也可能越高
所以做 AI 应用时,不要无脑把所有内容都塞给模型。
三、上下文窗口是什么?
上下文窗口可以理解为模型一次请求最多能"看见"的 Token 总容量。
比如一个模型支持 128K 上下文,不代表它能无限记住所有内容,而是一次调用时最多能容纳 128K Token 左右的内容。
这个窗口里通常要放这些东西:
System Prompt:系统角色、回答规则、输出格式User Prompt:用户真实问题历史消息:多轮对话里的前文RAG Context:检索出来的知识片段工具定义:Function Calling、MCP 工具描述等输出预算:给模型生成回答预留的 Token
可以把上下文窗口想象成一个固定容量的桶。
桶里不仅要放用户的问题,还要放系统提示词、历史对话、知识库内容,最后还得给模型回答留位置。
所以实际预算可以简单记成:
text
上下文窗口 >= 输入 Token + 最大输出 Token如果是推理模型,比如一些带思考过程的模型,还要额外考虑:
text
上下文窗口 >= 输入 Token + 推理 Token + 最大输出 Token这里的推理 Token不一定会展示给用户,但它依然可能消耗模型的输出预算。
所以在工程上,比较稳的做法是:
- 先定好
max_tokens,也就是最多让模型输出多少 - 再计算输入内容能放多少
- 超出预算时,优先减少 RAG 片段、历史消息、长文本字段
- 不要赌模型自己会"看重点"
四、Prompt 是什么?
Prompt就是我们给模型的提示词。
它不只是用户输入的一句话,还可以包括系统规则、示例、上下文资料、输出格式要求。
比如:
text
你是一个 Java 技术专家。
请用简单易懂的方式解释下面这段代码。
输出格式:
1. 代码作用
2. 执行流程
3. 可能的问题这就是一个很简单的 Prompt。
一般来说,Prompt 写得越清楚,模型越容易输出稳定结果。
尤其是结构化输出场景,比如让模型返回 JSON,就不要只写:
text
帮我提取用户信息而是应该写清楚字段、类型、缺失值怎么处理、不要输出额外解释等。
Prompt 本质上是在约束模型行为。
采样参数是在控制模型"怎么选词",Prompt 是在告诉模型"应该做什么事"。
五、logits 和 softmax 是什么?
模型生成回答时,不是直接生成一句话,而是一步一步选下一个 Token。
每一步模型都会给词表里的候选 Token 打分。
这个原始分数就叫logits。
比如模型要补全:
text
今天天气真__它可能给几个候选 Token 打分:
| 候选 Token | logit 分数 |
|---|---|
| 好 | 5.0 |
| 不错 | 3.2 |
| 棒 | 2.1 |
| 糟糕 | 0.5 |
| 紫色 | -8.0 |
这个分数越高,说明模型越觉得这个 Token 适合出现在当前位置。
但 logits 只是分数,不是概率。
要把分数变成概率,就需要经过softmax。
转换后大概就会变成:
| 候选 Token | 被选中的概率 |
|---|---|
| 好 | 62% |
| 不错 | 20% |
| 棒 | 10% |
| 糟糕 | 5% |
| 紫色 | 接近 0% |
最后模型会根据这个概率分布进行采样,决定真正输出哪个 Token。
所以可以简单理解:
text
logits:模型打出来的原始分数
softmax:把原始分数转换成概率
采样参数:控制最终从概率池里怎么选六、Temperature 是什么?
Temperature可以理解为控制模型输出的"随机程度"。
它会影响 softmax 前的分数分布。
p(t) = softmax(z_t / T Temperature )
- T ≈ 1:保持原始分布。
- T < 1:分布更尖锐,更倾向选择高概率 Token(更"稳")
- T > 1:分布更平坦,低概率 Token 更容易被采样到(更"野")
简单说:
Temperature越低,模型越保守,越倾向选择最高概率 TokenTemperature越高,模型越发散,低概率 Token 也更容易被选中
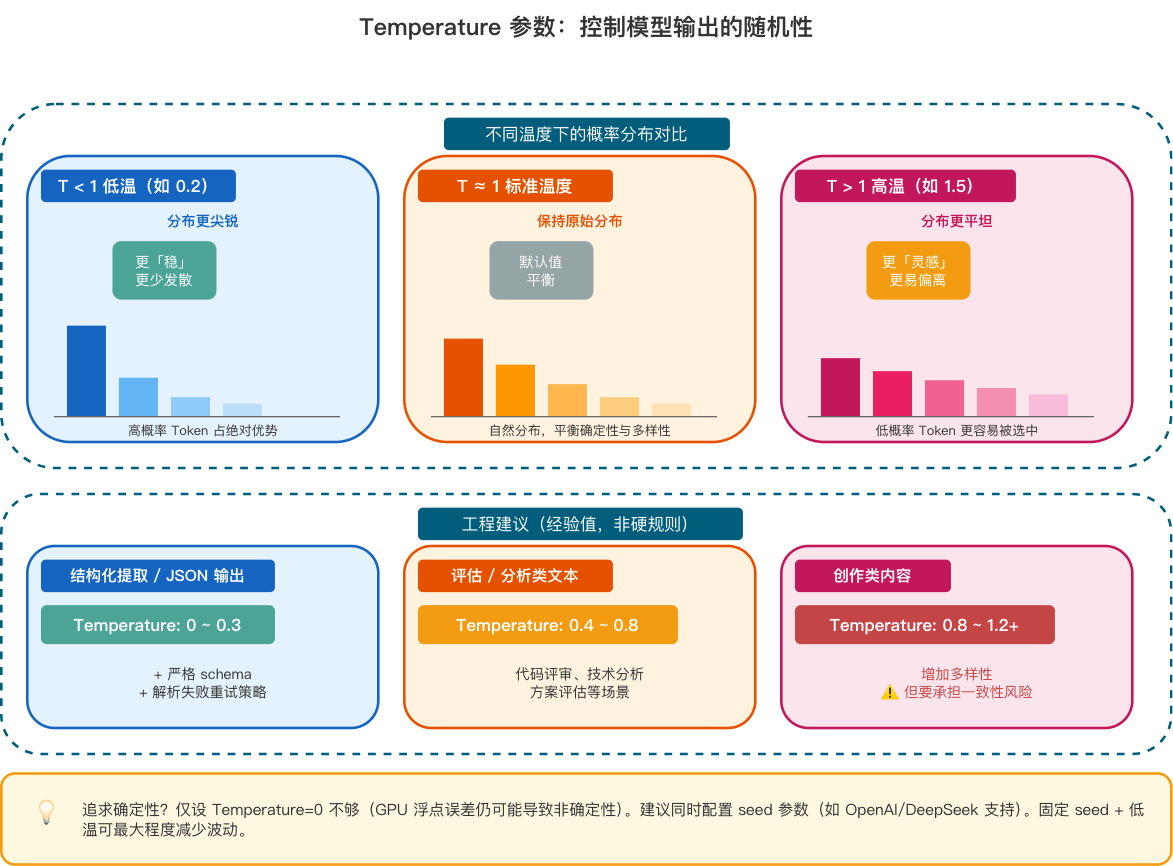
常见理解:
| Temperature | 效果 | 适合场景 |
|---|---|---|
| 0 ~ 0.3 | 很稳定,随机性低 | JSON、信息抽取、分类 |
| 0.4 ~ 0.8 | 稳定和表达兼顾 | 技术分析、代码评审、摘要 |
| 0.8 ~ 1.2 | 更有变化,更有创意 | 文案、头脑风暴、创作 |
比如还是这个句子:
text
今天天气真__低温时,模型大概率每次都输出"好"。
高温时,模型可能输出"不错""棒",甚至偶尔输出一些不太常规的词。
所以如果你希望模型稳定输出 JSON,不建议把温度调太高。
如果你希望它帮你想 20 个广告语,那温度可以适当调高。
七、Top-p 是什么?
Top-p也叫 nucleus sampling,可以理解为按累计概率选择候选池。
它不是固定保留几个 Token,而是从概率最高的 Token 开始往下加,直到累计概率达到 p。
比如:
| 候选 Token | 概率 | 累计概率 |
|---|---|---|
| 好 | 62% | 62% |
| 不错 | 20% | 82% |
| 棒 | 10% | 92% |
| 糟糕 | 5% | 97% |
| 紫色 | 接近 0% | 接近 100% |
如果设置:
text
Top-p = 0.9那模型会保留累计概率达到 90% 左右的候选。
在这个例子里,大概率就是保留:
text
好 / 不错 / 棒然后在这些候选里面重新采样。
Top-p 的特点是比较灵活:
- 如果模型非常确定,可能只保留 1 个候选
- 如果模型不太确定,候选池会变大
所以实践中 Top-p 用得比较多。
记忆方法:Top-p(percentage百分比),就快速理解为保留前多少百分比
八、Top-k 是什么?
Top-k更简单,就是只保留概率最高的 k 个候选 Token。
比如:
text
Top-k = 3那就只保留概率最高的 3 个候选,其它全部丢掉。
它和 Top-p 的区别是:
| 参数 | 控制方式 | 特点 |
|---|---|---|
| Top-k | 固定保留 k 个候选 | 简单直接,但不看概率分布形状 |
| Top-p | 保留累计概率达到 p 的候选集合 | 更灵活,会根据模型确定程度变化 |
如果模型第一名概率已经 95%,Top-k=3仍然会保留 3 个候选;但Top-p=0.9可能只保留第一名。
所以 Top-p 更像是"按信心动态控制候选池"。
记忆方法:Top-k(kill杀死),就快速理解杀死保留几个
九、Penalty 系列参数是什么?
Penalty 系列参数主要用来解决模型"复读"的问题。
有时候模型会一直重复同一句话,或者在长回答里重复相同观点,这时就可以通过惩罚参数降低已经出现过的 Token 的分数。
常见有三个:
| 参数 | 作用 | 通俗理解 |
|---|---|---|
| Repetition Penalty | 惩罚已经出现过的 Token | 说过的词,再说就扣分 |
| Presence Penalty | 只要出现过就惩罚,不关心出现次数 | 鼓励模型聊新内容 |
| Frequency Penalty | 出现次数越多,惩罚越重 | 重复越多,扣分越狠 |
但这里要注意,不是所有场景都适合开 Penalty。
比如结构化 JSON 输出里,字段名本来就需要重复出现:
json
{
"name": "阿昌",
"score": 90
}如果惩罚太强,模型可能反而不敢重复必要字段,导致 JSON 格式变差。
再比如 RAG 问答场景,本来就希望模型忠实引用检索内容,如果开太强的 Presence Penalty,可能会鼓励模型"讲点新的",反而增加幻觉。
所以比较保守的建议是:
不确定的时候,Penalty 保持默认,优先通过 Prompt、低温度、输出长度控制来解决稳定性问题。
十、logprobs 是什么?
logprobs是 log probabilities 的缩写,也就是对数概率。
它可以理解为模型对自己生成某个 Token 的"确信程度"。
一般来说:
- logprob 越接近 0,说明模型越确定
- logprob 越小,比如 -5、-8,说明模型越不确定
这个参数不是每个模型 API 都支持,但如果支持,在一些场景里很有用。
比如做信息抽取:
text
金额:1000 元如果模型生成"1000"对应的 logprob 很低,说明它其实不太确定,可能需要人工复核。
常见应用场景:
- 置信度评估:判断模型对某个结果是否有把握
- 异常排查:发现某批输入下模型整体置信度下降
- 候选对比:查看 Top-N 候选 Token,用于二次排序
不过 logprobs 也会让响应体变大,并且不同厂商支持情况不同,使用前要看具体 API 文档。
十一、停止条件和截断风险
除了采样参数,还有两个工程上经常踩坑的点:max_tokens和stop。
max_tokens是最大输出 Token 数。
它是硬上限。
如果模型写到一半达到上限,就会被直接截断。
常见问题:
- JSON 少一个右括号
- 列表只输出了一半
- 句子还没说完就结束
stop是停止词。
比如设置模型生成到某个字符串就停止。
它可以用于控制输出边界,但如果设置不好,也可能提前截断关键内容。
所以结构化输出场景,不只要关注 Temperature,还要关注输出长度和停止条件。
十二、采样参数配置建议
下面是一个偏工程实践的配置参考,不是绝对标准。
| 场景 | Temperature | Top-p | Penalty | 其它建议 |
|---|---|---|---|---|
| JSON / 结构化输出 | 0 ~ 0.3 | 1.0 | 默认 | 配合 schema、解析失败重试 |
| 信息抽取 / 分类 | 0 ~ 0.3 | 1.0 | 默认 | Prompt 写清楚字段和边界 |
| 代码评审 / 技术分析 | 0.4 ~ 0.7 | 0.9 | 默认 | 让模型按步骤分析,但最终输出要收敛 |
| 摘要 / 报告生成 | 0.4 ~ 0.8 | 0.9 | 默认 | 控制输出长度,避免啰嗦 |
| 多轮对话 | 0.6 ~ 0.8 | 0.9 | 适度开启 | 控制历史消息长度,必要时摘要历史 |
| 创意写作 / 头脑风暴 | 0.8 ~ 1.2 | 0.95 | 按需开启 | 接受多样性,后续做人工筛选 |
| RAG 问答 | 0.2 ~ 0.6 | 0.9 | 不建议乱开 | 优先保证忠实检索内容 |
| 推理模型 | 看模型限制 | 看模型限制 | 看模型限制 | 很多推理模型会忽略采样参数,主要靠 Prompt 控制 |
别处总结摘要:
text
要稳定:低 Temperature + 明确 Prompt + 严格输出格式
要创意:高 Temperature + 较高 Top-p + 接受后处理
要防重复:先优化 Prompt,再谨慎考虑 Penalty
要省钱:控制输入 Token、输出 Token、历史消息和 RAG 片段十三、总结
核心就是:
大模型不是魔法,它是在有限上下文窗口里,根据概率一个 Token 一个 Token 生成结果。
所以做 AI 应用开发时,要重点关注三件事。
-
第一,
Token是成本和容量单位。输入、输出、历史消息、RAG 内容都会消耗 Token,所以不能只按字数或者段落数来估算成本。
-
第二,
上下文窗口是有限资源。上下文越大不代表越可以乱塞内容,真正上线时还是要做 Token 预算、历史裁剪、RAG 片段去重和输出长度控制。
-
第三,
采样参数决定输出风格和稳定性。Temperature控制随机程度,Top-p和Top-k控制候选池,Penalty 控制重复,logprobs可以辅助判断置信度。
如果是生产环境,优先级应该是:
text
先写好 Prompt
再控制 Token 预算
再设置合理的 Temperature / Top-p
最后才考虑 Penalty、logprobs 等高级参数