SphericalHarmonicsL2 中的 L2 代表 Level 2 (或 2nd Order ),即 二阶球谐函数。
球谐函数(SH)通过一组系数来模拟环境光(通常是来自环境探针或光照探针的间接光)。
- L0 (1个系数):仅表示环境光的平均亮度(无方向感,像个发光的球)。
- L1 (4个系数):增加了基础的方向性(类似一个模糊的方向光,能分出明暗面)。
- L2 (9个系数):增加了更细腻的明暗过渡和方向细节(Unity 标准的探针质量)。
Unity 中,SphericalHarmonicsL2 结构体用于存储这 9个系数 (通常是 RGB 三个通道,总共 27 个浮点数)。
当你调用 SampleSH() 时,它本质上是利用这 L2 阶的 9 个数据点,根据物体表面的法线方向,还原出该方向上应该受到的间接光颜色。
- 主流标准:L2 是实时渲染中的"黄金标准"。它足以模拟出自然的漫反射光照(Diffuse GI),且计算开销极低。
- 为什么不用 L3 或更高?:更高阶(如 L3, L4)虽然更精确,但计算量呈平方级增长,且对于平滑的漫反射材质来说,肉眼几乎看不出区别。
Spherical Harmonics L2 使用的 9个数据点(系数)
代表了球面空间中不同频率的特征球面
第 0 阶 (1个系数) :常数项。代表球面的平均亮度(Ambient 基调)。
1 阶 (3个系数) :线性项。代表 X、Y、Z 三个轴向上的光照差异(基础方向感)。
2 阶 (5个系数)二次方项。代表更复杂的对比度和方向细节(如四个斜角方向的明暗变化)。
虽然说是 9 个系数,但在 Unity 的 SphericalHarmonicsL2 结构体中,你会看到它存储了 27 个值。
这是因为光照是有颜色的,所以 R、G、B 每个颜色通道 都需要独立的 9 个 SH 系数。
在 Unity 的底层(尤其是针对移动端优化时),这 9 个系数并不是简单排列的。为了计算效率,Unity 通常将它们分为三部分传给 GPU:
- SHAr: (R通道的前4个系数,包含 L0 和 L1)
- SHAg: (G通道的前4个系数)
- SHAb: (B通道的前4个系数)
- SHBr, SHBg, SHBb: (三原色对应的 L2 阶剩下的 5 个系数)
- SHC: (第9个残余系数,通常用于最后的微调)
直观理解
你可以把这 9 个数据点想象成一个 "可变形的球体":
- 开始是一个正圆球(L0)。
- 根据 L1 的 3 个系数,球体被拉长或推向某个方向。
- 根据 L2 的 5 个系数,球体表面被压出凹凸和棱角。
最终这个"变形球"的形状,就代表了来自四面八方的光照强度。
-
SH :一种数据表示形式 ,不是单独的光照系统。主要用于表示低频环境漫反射 。Unity 里 ambient probe、light probe 本质上都大量用 SH。Unity Documentation+1
-
Baked GI :总称,表示把 GI 预先烘焙出来。它的结果可以落到 Lightmap 、Light Probe 、Ambient Probe 等载体里。Unity Documentation+1
-
Light Probe :存的是空间中的间接漫反射光 ,主要给动态物体 或不能吃 lightmap 的物体。数据格式通常是 SH。Unity Documentation+1
-
Lightmap :存的是表面上的 baked lighting ,主要给静态物体 。本质是贴图,不是 SH。Unity Documentation+1
-
Reflection Probe :存的是环境反射信息 ,本质更接近 cubemap / prefiltered env map,主要给镜面反射,不是给 diffuse 漫反射。
SH 理解成"编码格式",而不是"某一种 probe"。
Baked GI 是什么层级
Baked GI 是上位概念。
它表示:场景的全局光照,尤其是间接光、bounce light、环境贡献,不在运行时现算,而是离线或预计算。
Unity 官方文档里,ambient probe、light probes、lightmaps 都属于这套烘焙体系的结果承载形式。Unity Documentation+1
所以关系是:
overflow-visible!
Plain text
Baked GI
├─ Lightmap (表面上的 baked 结果)
├─ Light Probe (空间中的 baked 结果)
└─ Ambient Probe (全局默认环境 probe,SH)
而 Reflection Probe 通常和 GI 系统相关,但它主要服务于反射,不是 diffuse GI 的主载体。Unity Documentation+1
Lightmap:存"表面上的光"
Lightmap 存的是:
某块静态表面最终接收到的 baked lighting
包括常见的:
-
间接光
-
baked 直射光(取决于模式)
-
AO/阴影信息的一部分
它的特征是:
-
依附在几何表面 UV 上
-
只适合静态物体
-
本质是 texture,不是 SH
-
精度高,细节高,可以有阴影边界和高频变化
Unity 官方文档明确区分了:
lightmaps 存的是"光打到场景表面" ;
light probes 存的是"光在场景空间中传播" 。Unity Documentation+1
所以你可以记成:
-
Lightmap = surface lighting cache
-
Light Probe = volumetric sample of indirect diffuse
Reflection Probe 经常和 Light Probe 混着记,但两者根本不是一类东西。
如果你从 shader 视角看,会更清楚。
7.1 SH / Light Probe / Ambient Probe
输出的是 diffuse 环境项:
overflow-visible!
hlsl
float3 ambient = SampleSH(normalWS);
这个 ambient 背后来源可能是:
-
ambient probe
-
interpolated light probes
-
某些 GI 系统提供给 shader 的 SH 数据
但形式上都可视为"SH diffuse ambient"。
7.2 Lightmap
通常是:
overflow-visible!
hlsl
float3 bakedGI = SAMPLE_GI(lightmapUV, vertexSH, normalWS);
或对应管线包装函数。
如果对象有 lightmap,很多管线会优先用 lightmap 数据,而不是单纯从 probe 来。因为 lightmap 的表面分辨率更高。
7.3 Reflection Probe
通常是:
overflow-visible!
hlsl
float3 refl = SAMPLE_TEXTURECUBE_LOD(_ReflectionCubemap, dir, mip);
或者通过管线封装函数拿反射向量采环境图。
这部分是 specular / IBL 线,不是 SampleSH 那条线。
8. 一个非常实用的对照表
你可以直接这么记:
| 名词 | 本质 | 主要存什么 | 主要给谁用 | 数据形式 |
|---|---|---|---|---|
| SH | 表示方法 | 低频方向光照函数 | ambient/light probe 等 | 球谐系数 |
| Baked GI | 上位系统 | 预计算全局光照结果 | 静态和动态对象 | 多种载体 |
| Lightmap | 表面缓存 | 表面上的 baked lighting | 静态物体 | 纹理 |
| Light Probe | 空间采样 | 空间中的间接漫反射 | 动态物体/LOD | SH |
| Ambient Probe | 全局默认 probe | 场景级环境漫反射 | 默认环境光 fallback | SH |
| Reflection Probe | 反射环境缓存 | 环境镜面反射 | 有 specular 的材质 | cubemap |
这个表基本就把关系捋顺了。
9. 放到你关心的 stylized face / brow 上怎么理解
如果是眉毛、妆容、睫毛这种风格化元素:
-
不想吃主光 N·L
-
不想吃复杂阴影
-
只想有一点环境存在感
那通常只会用:
overflow-visible!
hlsl
float3 ambient = SampleSH(faceNormalWS);
color = baseColor * lerp(1.0, ambient, k);
这里吃的是 SH / probe 的 diffuse ambient。
它不会用到:
-
Reflection Probe,因为眉毛一般不做镜面环境反射
-
Lightmap,因为这类通常是角色动态面部,不走静态 lightmap
-
完整 Baked GI surface result,因为目标是"保设计色",不是物理正确
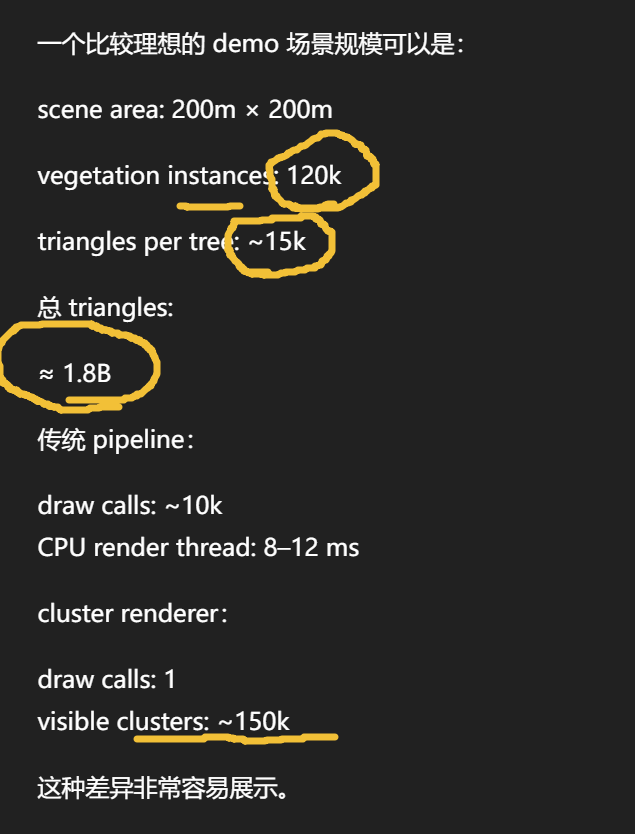

"很多 instance → 合并 draw call → FPS 提升"
那确实很像 Unity GPU Instancing / Indirect Draw,
需要把问题从:
"如何减少 draw call"
升级为:
"如何把几何处理从 object-level pipeline 变成 cluster-level GPU pipeline"。
geometry 被拆成很多 cluster。
例如:
一棵树
15k triangles
被拆成:
≈ 200 clusters
每个 cluster:
≈ 64 triangles
然后 GPU 做:
frustum culling
cone culling
LOD
如果最后:
只有 40 clusters visible
那么 GPU 实际 raster:
40 × 64 ≈ 2560 triangles
而不是:
15000 triangles
这里的核心价值不是 draw call,而是:
triangle reduction。
一个真正合理的问题应该是:
传统 instance pipeline 的可见性粒度太粗。
object-level culling
→ geometry waste
而 cluster pipeline:
cluster-level visibility
这就是 Nanite / mesh shader pipeline 的核心。
一个更准确的问题描述可以是:
传统 instance-based rendering 中,可见性判断通常在 object-level 进行,导致大量不可见三角形仍然被 GPU 处理。如何通过 cluster-based geometry pipeline 实现细粒度 GPU culling,从而减少无效几何处理?
不是:
"减少 draw call"
而是:
"减少无效 triangle processing"。
这才是 Mesh Shader 的意义。
传统 pipeline:
object-level LOD
一棵树:
LOD0
LOD1
LOD2
整个模型切换。
而 cluster renderer 可以:
cluster-level LOD
近处 cluster:
LOD0
远处 cluster:
LOD2
这会进一步减少 triangles。
How can we reduce wasted triangle processing in large geometry scenes by performing cluster-level visibility on GPU?
而不是:
How to reduce draw calls.
所以如果一棵树:
15000 triangles
100k instances
即使使用 HISM:
GPU 仍然会 transform
overflow-visible!
1.5B triangles
只是 draw call 从 100k 变成几百。
这就是为什么 instancing 并不能解决 几何规模问题。
Nanite 解决的是:
geometry scalability
它的 pipeline大致是:
mesh
→ clusters (~128 triangles)
GPU:
cluster visibility
→ software raster occlusion
→ material pass
也就是说 Nanite 的核心是:
overflow-visible!
cluster-level visibility
而不是 instancing。
所以 Nanite 的优势来自:
triangle reduction
例如:
原始 mesh:
10M triangles
屏幕上只需要:
200k triangles
Nanite 会只 raster 那 200k。
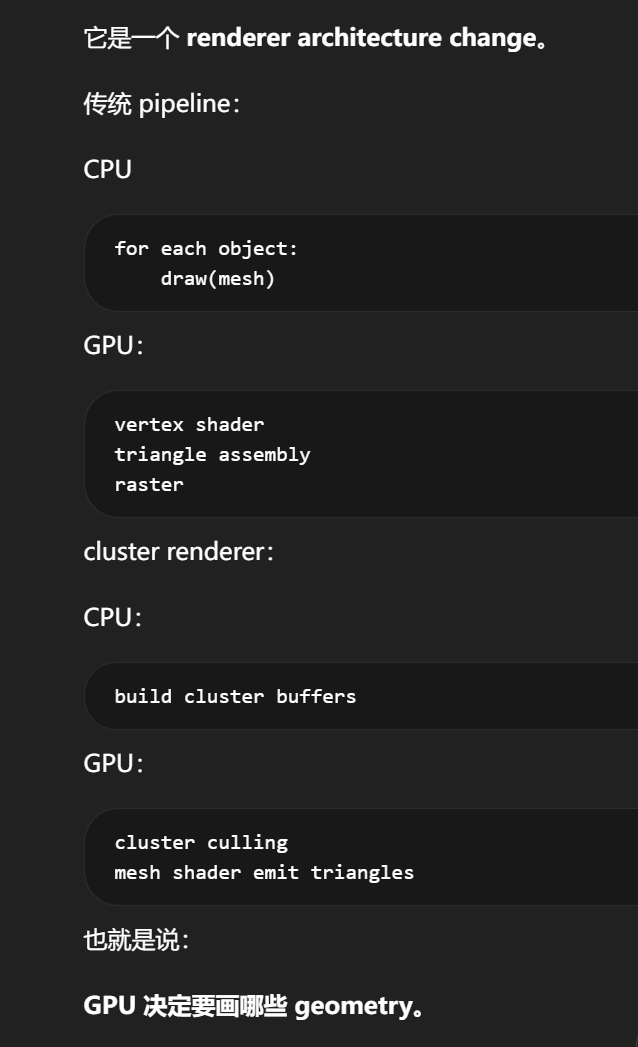
写 cluster renderer,而不是 shader,是正确的理解。
这确实不是:
Unity instancing
或 compute instancing
它是一个 renderer architecture change。
demo 场景必须"人为制造瓶颈"。
因为如果你直接用 UE:
-
HISM
-
Nanite
-
LOD
-
culling
UE 已经做了大量优化。
结果就是:
你根本看不到 renderer 改进。
所以 demo 场景需要:
刻意关闭 UE 的一些系统。
例如:
-
不使用 Nanite
-
不使用 HISM
-
不使用 LOD
然后让传统 pipeline 真的变重。
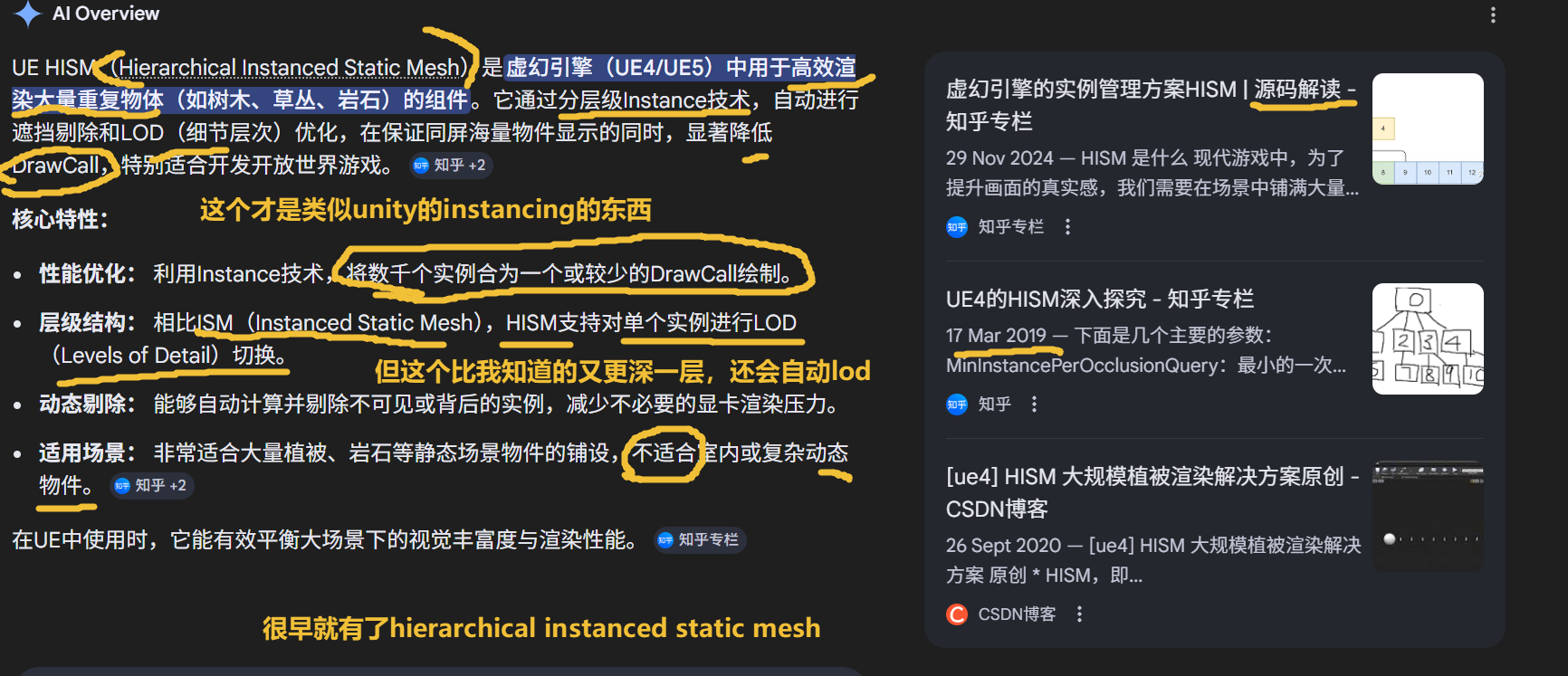
核心结论是HISM通过树状数据结构实现高效剔除,但仅适合植被等海量实例场景,室内或少量实例场景并不适用。与普通InstanceStaticMeshComponent的区别(支持不同LOD消失距离)树状结构:类似kdtree但分支因子默认16,通过FClusterNode管理实例序号和子节点编号,避免重组instance buffer;剔除时通过节点包围盒快速计算,UE4 4.22新增的动态合并实例功能。通过层级树结构减少每帧剔除计算量
通过层级树结构减少每帧剔除计算量是CPU端的核心工作。HISM(Hierarchical Instanced Static Mesh Component)的层级树结构本质是一种空间加速算法,通过将海量实例(如植被)组织为类似kdtree的树状结构(默认分支因子为16),让CPU能快速定位并剔除不可见实例,从而降低每帧需要提交给GPU的渲染数据量。
具体来说,CPU通过以下步骤实现高效剔除:
- 层级包围盒管理:树中每个节点(FClusterNode)存储子节点编号和实例序号范围,并维护一个包围盒。当相机视角变化时,CPU从根节点开始遍历,通过判断节点包围盒是否与视锥体相交,快速排除完全不可见的子树,避免对每个实例单独检测。
- 批量遮挡查询:结合遮挡查询(Occlusion Query)技术,CPU会对节点包围盒进行批量可见性判断。例如,若一个节点的包围盒被其他物体完全遮挡,其下所有实例可直接剔除,无需逐个处理。
- 平衡计算负载:通过调整树的分支因子(如InternalBranchingFactor)和最小实例数量(MinInstancePerOcclusionQuery),CPU可在剔除精度与计算开销间找到平衡。例如,当节点实例数量较少时,直接渲染而非执行复杂查询。
这种设计的优势在于将O(n)的线性遍历优化为O(log n)的树状检索,尤其在十万级以上实例场景中能显著降低CPU的每帧剔除耗时。但需注意,层级树构建和维护本身会占用额外内存,且仅适用于静态实例;对于动态物体或少量实例,其开销可能超过收益。
为何不直接在GPU端处理?因为GPU擅长并行计算密集型任务(如像素渲染),而遮挡剔除需要复杂的空间逻辑判断和动态决策,更适合CPU主导。不过,现代引擎也开始探索CPU与GPU协同剔除(如GPU生成Hi-Z深度图辅助CPU判断),但核心的层级树遍历和实例筛选仍由CPU完成。
用 foliage paint,UE 确实会自动使用 HISM 。HISM 仍然是 object-level pipeline。只减少 draw calls
ReSharper 是 JetBrains 做的一个 IDE 代码分析与重构插件 ,最早是给 Visual Studio 用的。它本质上不是编译器,也不是调试器,而是一套 静态分析 + 代码理解 + 重构工具层 。后来 JetBrains 把它的核心做成了独立 IDE ------ Rider。
Visual Studio 本身有一套 IntelliSense 导航系统,例如:
-
Go To Definition
F12 -
Go To Implementation
Ctrl+F12 -
Find All References
Shift+F12 -
Go To Symbol
Ctrl+T -
Peek Definition
Alt+F12
这些和 ReSharper 的功能对应。
Visual Studio 的插件体系叫:
VSIX extension
问题是:
-
API 非常复杂
-
UI 扩展困难
-
编辑器 API 比较旧
-
线程模型复杂
-
调试难度大
很多开发者吐槽:
写 VS 插件比写普通应用还难。
而 VS Code 插件:
-
TypeScript
-
几百行代码
-
就能做一个完整插件
这也是为什么 几乎所有 AI coding 工具都先支持 VS Code。
例如:
-
Copilot
-
Cursor
-
Codeium
-
Tabnine
-
Codex
全部先做 VS Code。
VS Code 用户规模更大(对 AI 工具更重要)
现在开发者市场:
VS Code > JetBrains IDE > Visual Studio
VS Code 用户量是最大的。
AI 公司做 IDE 插件时会优先考虑:
开发成本低
用户多
插件生态成熟
VS Code 完全符合。
S Code 是跨平台
VS Code:
Windows
Linux
Mac
Visual Studio:
主要是 Windows
AI 工具更希望:
一套插件跑三平台
VS Code 更合适。
Rider安装没有难度,直接下一步到底就完事,不过你不得不安装vs2022,因为本质上Rider只是调用的msbuild来构建项目,后台编译器是.NET那一套,windows上就是这么的情况,免不了的(如果想用g++,mingw什么那路就绕太远了,不如直接用linux)。
Unity 是脚本热重载(managed runtime reload)
UE Live Coding 是 C++ 二进制补丁(native hot patch)
因此它们的能力范围不同。
先说 Unity 的行为。
Unity 的脚本是 C# + Mono / IL2CPP runtime。当你修改脚本时:
-
编译 C#
-
重新加载程序集
-
重新初始化脚本实例
这个过程叫 domain reload(可关闭)。所以 Unity 可以做到:
-
修改函数实现
-
修改字段
-
修改逻辑
然后场景里的对象自动更新。因为对象本身是 托管对象,Unity 可以重新绑定。
所以你会看到:
写代码 → 保存 → Unity 自动编译 → 场景继续运行。
UE 不是这样。
UE 的代码是 C++ 原生代码。运行时已经加载的是:
GameModule.dll
Engine.dll
这些二进制代码已经被操作系统加载到进程内存中。
C++ 没有类似 C# 的 runtime 可以重新加载函数。
Live Coding 的做法是:
-
编译修改过的 C++ 文件
-
生成新的 object code
-
生成 patch dll
-
把新的函数地址 覆盖旧函数入口
也就是:
old function → jump → new function
因此 Live Coding 本质是 runtime function patching。
UE 编辑器里按:
Ctrl + Alt + F11
会触发:
Live Coding compile
然后新的代码会被 patch 到运行中的 editor。
但这种机制有很多限制。
第一类限制:结构变化不安全
如果你修改了:
-
class layout
-
UPROPERTY
-
virtual table
-
struct size
Live Coding 很可能失败,或者产生未定义行为。
例如:
C++
class AMyActor : public AActor
{
int A;
};
改成:
C++
class AMyActor : public AActor
{
int A;
int B;
};
这种情况通常必须 重新编译并重启 editor。
Unity 不会遇到这个问题,因为 C# 对象由 runtime 管理。
当你在 IDE 改了 C++代码,UE 不会自动编译。
Unity 是:
保存脚本
→ Unity 自动编译
UE 是:
保存C++
→ 什么也不会发生
你必须主动触发编译:
-
Ctrl + Alt + F11→ Live Coding -
或 UE 编辑器点 Compile
-
或 VS Build
所以 Live Coding 只是触发编译的一种方式。
Live Coding只适合修改函数逻辑
例如:
C++
float GetSpeed ()
{
return 600.f ;
}
改成:
C++
return 900.f ;
流程:
Ctrl+Alt+F11
→ 编译 patch
→ 函数替换
→ 立刻生效
不需要重启 Editor。
改"类结构"是另一件事
例如:
原来:
C++
class AMyActor : public AActor
{
int Health;
};
改成:
C++
class AMyActor : public AActor
{
int Health;
int Armor;
};
这里改变了:
sizeof(class)
member offset
memory layout
运行中的 Actor 已经在内存里:
Actor instance
↓
内存结构固定
Live Coding 不会重新创建这些对象。
因此:
-
新成员不会出现在已有实例
-
Blueprint 不会刷新
-
可能甚至崩
通常需要:
关闭 UE Editor
Build
重新打开
关卡/渲染数据的构建。
快速打开和符号跳转 。
Ctrl + P:按文件名快速打开文件。
Ctrl + Shift + O:跳转到当前文件里的函数或符号。
Ctrl + T:在整个工程里搜索类、函数、变量。
这三个组合起来,可以完全替代传统 IDE 的项目浏览。
vscode多光标编辑。
Alt + Click:在多个位置放光标
Ctrl + D:选择下一个相同单词
Ctrl + Shift + L:选择所有相同单词
这在改变量名、批量插入代码时非常高效。
代码折叠和结构导航。
Ctrl + Shift + [ / Ctrl + Shift + ] 可以折叠或展开代码块。
配合侧边栏的 Outline 视图,可以快速查看当前文件的结构。对于大文件或 shader 特别有用。
VS Code 可以定义构建任务,比如编译 C++、运行脚本、打包项目。通过 tasks.json 可以配置,例如一个简单任务可以调用编译脚本或构建工具。之后只需要 Ctrl + Shift + B 就能执行。调试系统完全通过配置文件管理。插件提供功能
↓
插件把功能注册成 command
↓
命令面板负责调用这些 command命令面板本身只是一个 命令调度器,而大部分命令其实来自插件。
插件没有 UI 也能工作
很多插件其实 只有命令,没有界面。
例如:
一个代码生成插件可能只提供:
Generate Class
Generate Getter
Generate Constructor
用户通过命令面板触发。
跳转历史 。
有时候跳转多次后需要回退:
-
Alt + ←返回上一个位置 -
Alt + →前进
类似浏览器的前进后退。
查找引用(Find References) 。
快捷键 Shift + F12。
可以查看某个函数或变量被哪些地方调用。
例如:
C++
ApplyDamage ()
会列出所有调用位置。
查看定义(Peek Definition) 。
快捷键 Alt + F12。跳转到定义(Go to Definition) 。
快捷键 F12。
当光标在函数或变量上时,可以跳到它的定义位置。
时候跳转多次后需要回退:
-
Alt + ←返回上一个位置 -
Alt + →前进
类似浏览器的前进后退。
在 Ctrl + P 后输入:
Plain text
:120
可以直接跳到第 120 行。
或者:
Plain text
@functionName
可以跳到当前文件中的函数。
例如:
-
C++:clangd 或 C/C++ extension
-
C#:C# Dev Kit / OmniSharp
-
Python:Python extension
如果没有语言服务器,VS Code 只能做文本搜索,而无法理解代码结构。
VS Code 的搜索和跳转主要依赖三种机制:
-
文件索引(Ctrl+P)
-
语言服务器符号索引(F12、Ctrl+T)
-
文本搜索(Ctrl+Shift+F)
alt+←
回退跳转,,,这样的东西我居然没有早就知道,,,aaaa
查找引用(Find References) 。
快捷键 Shift + F12。
可以查看某个函数或变量被哪些地方调用。
例如:
C++
ApplyDamage ()
会列出所有调用位置。
改成"像文件快速打开那种模糊匹配"
这种更像 Ctrl+P 的 Quick Open,不是普通全文搜索。
VS Code 的 Search 本身主要是文本搜索,不是完全意义上的"任意模糊检索器"。它更偏:
- 关键字搜索
- 正则
- 大小写
- 全词匹配
- 文件包含/排除
在 VS Code 里,Ctrl+P 对应的命令本质上是:
- Quick Open
- 用来按文件名做模糊查找并打开文件
所以你把它理解成:
- P = path
- 或者 P = project file lookup
会比较好记,但这更多是记忆法,不是官方定义。
-
Go to Symbol in Editor...
这是你最常用的那个。
作用:在当前打开文件里跳转到符号,比如函数、变量、类、方法、shader 里的结构项。
可以理解成"当前文件内大纲搜索"。
-
Go To Symbol in Accessible View
这是无障碍视图里的版本。
作用:给屏幕阅读器/辅助访问模式用,在 Accessible View 这个特殊界面里跳转符号。
普通使用基本碰不到,可以几乎忽略。
-
Terminal: Open Detected Link...
这是终端里的命令。
作用:当焦点在 VS Code 内置终端时,打开终端里识别到的链接,比如文件路径、URL、报错跳转位置。
为什么它们能共用 Ctrl+Shift+O:
因为 when 条件不同。
- 在编辑器聚焦时,触发 Go to Symbol in Editor
- 在无障碍视图聚焦时,触发 Accessible View 那条
- 在终端聚焦时,触发 Terminal: Open Detected Link
所以它们不是硬冲突,而是"同键不同场景"。
你可以把它粗暴记成:
- 编辑器里:Ctrl+Shift+O = 当前文件符号搜索
- 终端里:Ctrl+Shift+O = 打开终端识别出来的链接
- 无障碍视图里:给辅助功能用
对你这个 shader 场景还要补一句:
- .shader / .hlsl 的"定义、引用、符号"能力,取决于 VS Code 对这类语言的支持插件
- 所以 Ctrl+Shift+O 往往只能给你"部分结构化符号"
- Shift+F12 在 shader 文件里不一定像 C# 那么准
- 很多时候反而 Ctrl+F / Ctrl+Shift+F 更直接