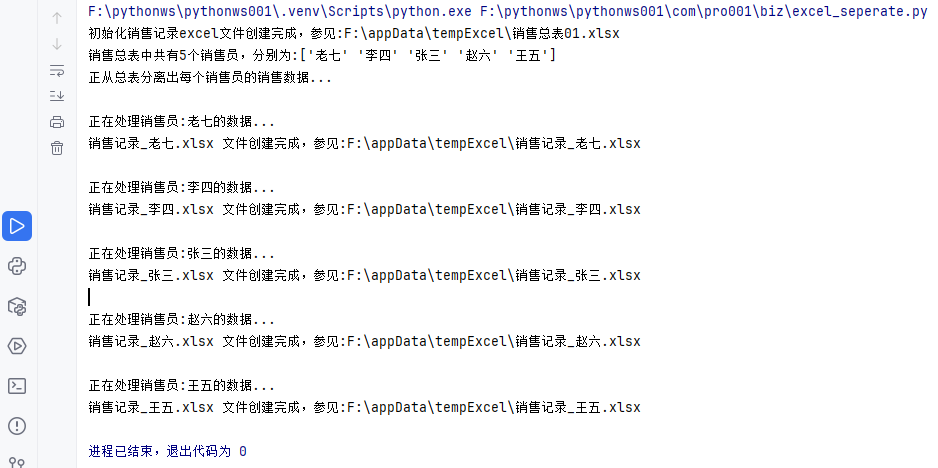
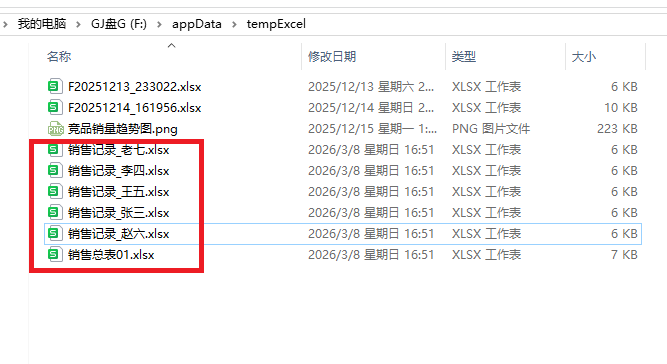
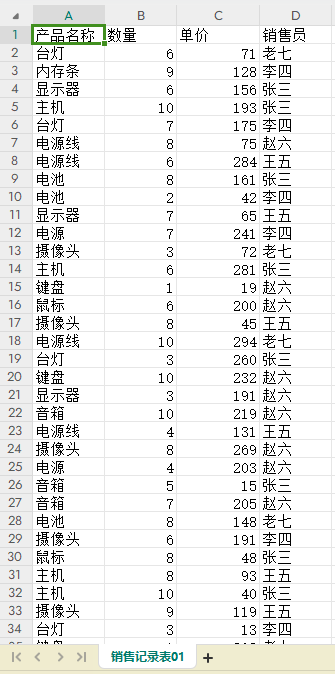
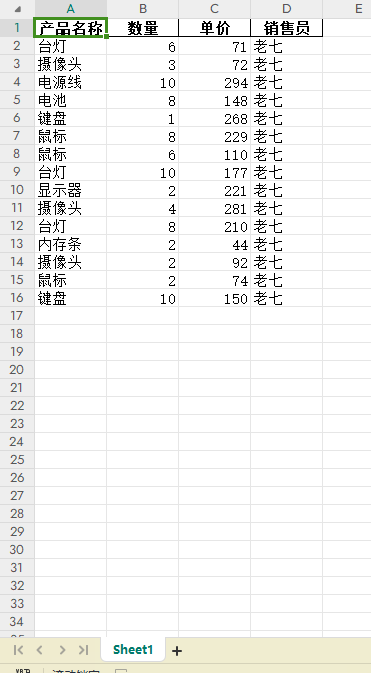
有时需要将一个excel文件数据按一定规则拆分为多个excel,比如有一个销售总表,里面含有各个销售员的销售数据,现在有需要把各个销售员的销售数据从总表中分离出来独立建立一个Excel文件,面对这个场景,
一,使用python可以快速实现,代码如下:
python
# -*- coding: UTF-8 -*-
# ========================================
# @ProjectName: pythonws001
# @Filename: excel_seperate.py
# @Copyright www.637hulian.com
# @Author: shenzhennba(Administrator)
# @Version 1.0
# @Since 2026/3/8 13:51
# ========================================
# excel根据文件内容根据某规则拆分为多个excel
# ========================================
from openpyxl import Workbook, load_workbook
import os
import random
import pandas as pd
def init_excel(save_path, excel_file_name, sheet_name):
""" 建立excel和并初始化数据内容 """
if not os.path.exists(save_path):
os.mkdirs(save_path)
if not excel_file_name:
print("请输入excel文件名,必要参数")
return
if not excel_file_name.lower().endswith('.xlsx'):
print("请输入.xlsx格式的excel文件名,必要参数")
return
if not sheet_name:
print("请输入sheet名,必要参数")
return
try:
file_path = os.path.join(save_path, excel_file_name)
#创建 workbook 对象
wb = Workbook()
# 获取当前活跃的worksheet
ws = wb.active
# 设置sheet名称
ws.title = sheet_name
#构造数据
salers = ['张三','李四','王五','赵六','老七']
products = ['键盘', '鼠标', '主机', '显示器', '摄像头',
'电源线', '音箱', '台灯', '电池', '内存条','电源']
# 建立excel表头
ws['A1'] = '产品名称'
ws['B1'] = '数量'
ws['C1'] = '单价'
ws['D1'] = '销售员'
# 增加表体数据
for i in range(2,100):
ws[f'A{i}'] = random.sample(products, 1)[0]
ws[f'B{i}'] = random.randint(1,10)
ws[f'C{i}'] = random.randint(1,300)
ws[f'D{i}'] = random.sample(salers, 1)[0]
# 数据保存并写入excel文件
wb.save(file_path)
print(f"初始化销售记录excel文件创建完成,参见:{file_path}")
except Exception as e:
print(e)
def excel_data_seperate(save_path, excel_file_name, sheet_name):
""" 根据文件内容根据某规则拆分为多个excel,
从销售总表中把各个销售员的销售数据分离并创建一个新的excel文件,每个销售员一个文件 """
if not os.path.exists(save_path):
print(f"路径不存在,请检查是否存在:{save_path}")
return
if not excel_file_name:
print("请输入excel文件名,必要参数")
return
if not excel_file_name.lower().endswith('.xlsx'):
print("请输入.xlsx格式的excel文件名,必要参数")
return
if not sheet_name:
print("请输入sheet名,必要参数")
return
try:
file_path = os.path.join(save_path, excel_file_name)
# 读取excel文件指定sheet名称的内容
df = pd.read_excel(file_path, sheet_name=sheet_name)
# 去重获取销售员列表
sale_users = df['销售员'].unique()
if len(sale_users) < 1:
print("销售总表中没有销售员信息,请检查")
return
print(f'销售总表中共有{len(sale_users)}个销售员,分别为:{sale_users}')
print(f'正从总表分离出每个销售员的销售数据...')
# 循环每个销售员,并筛选该销售员相关数据,
# 最后创建一个新的excel文件,名称格式为:销售记录_销售员名.xlsx
for sale_user in sale_users:
print(f'\n正在处理销售员:{sale_user}的数据...')
user_df = df[df['销售员'] == sale_user]
# 创建新的excel文件
new_file_name = f'销售记录_{sale_user}.xlsx'
new_file_path = os.path.join(save_path, new_file_name)
user_df.to_excel(new_file_path, index=False)
print(f"销售记录_{sale_user}.xlsx 文件创建完成,参见:{new_file_path}")
except Exception as e:
print(e)
def main():
""" 主函数 """
save_path = r'F:\appData\tempExcel'
excel_file_name = '销售总表01.xlsx'
sheet_name = '销售记录表01'
init_excel(save_path, excel_file_name, sheet_name)
excel_data_seperate(save_path, excel_file_name, sheet_name)
if __name__ == '__main__':
main()二,相关截图