摘要:信息检索是自然语言处理的重要应用领域,旨在帮助用户从文档库中查找相关信息。本文系统介绍了信息检索的核心概念、模型和关键技术:1. 主要模型包括布尔模型、向量空间模型和概率模型等经典模型,以及改进型和非经典模型;2. 关键技术涵盖倒排索引、停用词处理和词干提取等预处理方法;3. 重点讨论了查询优化方法,包括显式反馈、隐式反馈和伪反馈三种相关反馈机制。文章详细分析了布尔模型和向量空间模型的数学原理、优势局限及实现方法,为信息检索系统设计提供了理论框架和技术指导。
目录
[自然语言处理 ------ 信息检索](#自然语言处理 —— 信息检索)
自然语言处理 ------ 信息检索
信息检索(IR)是一种处理文档库中信息的组织、存储、检索与评估的软件程序,其处理对象尤以文本信息为主。该系统助力用户查找所需信息,但不会直接返回问题的答案,仅告知可能包含所需信息的文档的存在性与位置。满足用户需求的文档被称为相关文档,一个理想的信息检索系统应仅检索出相关文档。
通过下图,我们可以理解信息检索的流程:
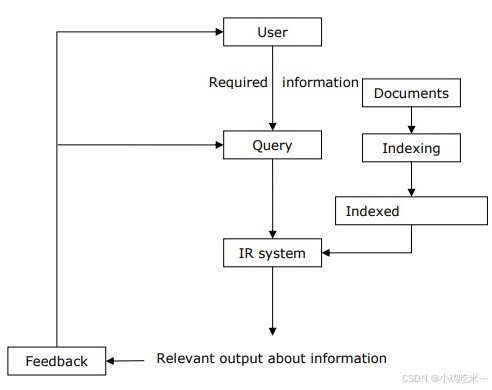
从上图中可以明确,有信息需求的用户需要以自然语言的查询语句形式提出检索请求,随后信息检索系统会以文档的形式,检索出与所需信息相关的结果作为响应。
信息检索系统的经典问题
信息检索研究的核心目标是开发一种能从文档库中检索信息的模型。本节将介绍信息检索系统相关的一个经典问题 ------即席检索问题。
在即席检索中,用户必须以自然语言输入描述所需信息的查询语句,而后信息检索系统返回与该信息相关的文档。例如,我们在互联网上进行搜索时,搜索引擎会返回一些符合需求的精准页面,但也可能出现无关页面,这一现象的根源就是即席检索问题。
即席检索的研究方向
信息检索研究中针对即席检索的研究方向主要包括以下几点:
- 用户如何借助相关反馈优化初始的查询语句设计?
- 如何实现数据库合并,即如何将不同文本数据库的检索结果整合为一个结果集?
- 如何处理部分损坏的数据?哪些模型适用于该类数据的处理?
信息检索模型
在众多科学领域中,模型都被用于从数学角度解释和理解现实世界中的某种现象。信息检索模型则用于预测和解释用户针对给定查询语句能找到的相关信息,本质上是定义检索过程上述核心问题的一种范式,主要包含以下组成部分:
- 文档模型
- 查询语句模型
- 用于对比查询语句与文档的匹配函数
从数学角度来看,一个检索模型由以下要素构成:
- D:文档的表示形式
- Q:查询语句的表示形式
- F:针对文档 D 和查询语句 Q 的建模框架,及其二者间的关联关系
- R(q,di) :相似度函数,用于根据查询语句对文档进行排序,也被称为排序函数
信息检索模型的类型
信息检索模型主要可分为以下三类:
经典信息检索模型
这是最简单且易于实现的信息检索模型,基于易于理解和掌握的数学知识构建,布尔模型 、向量空间模型 和概率模型是三种经典的信息检索模型。
非经典信息检索模型
与经典信息检索模型完全不同,这类模型并非基于相似度、概率、布尔运算等原理构建,信息逻辑模型 、情境理论模型 和交互模型均属于非经典信息检索模型。
改进型信息检索模型
该类模型是对经典信息检索模型的优化与增强,融合了其他领域的特定技术,聚类模型 、模糊模型 和潜在语义索引(LSI)模型为其典型代表。
信息检索系统的设计特征
接下来介绍信息检索系统的核心设计特征:
倒排索引
倒排索引是大多数信息检索系统的核心数据结构,指为每个词汇列出包含该词汇的所有文档,以及其在各文档中的出现频次的一种数据结构。它能大幅简化查询词汇匹配结果的检索过程。
停用词剔除
停用词是指出现频率极高、被认为对检索无实际价值的词汇,这类词汇的语义权重较低,所有停用词会被整理成停用词表。例如,冠词 a、an、the,介词 in、of、for、at 等均属于停用词。
停用词表能显著减小倒排索引的规模,根据齐普夫定律,包含数十个词汇的停用词表可使倒排索引的规模缩减近一半。但另一方面,剔除停用词有时也会删掉对检索有价值的词汇,例如,若将 Vitamin A 中的字母 A 剔除,该词汇将失去原有含义。
词干提取
词干提取是形态分析的简化形式,指通过截取词汇后缀提取词汇词根的启发式过程。例如,laughing、laughs、laughed 的词干将被提取为核心词汇 laugh。
在后续章节中,我们将介绍一些重要且实用的信息检索模型。
布尔模型
布尔模型是最古老的信息检索模型,基于集合论和布尔代数构建,在该模型中,文档被视为词汇的集合,查询语句则是基于词汇的布尔表达式。布尔模型的定义如下:
- D:词汇的集合,即文档中出现的标引词,每个标引词的存在状态仅为出现(1)或未出现(0)
- Q:布尔表达式,其中操作数为标引词,运算符为逻辑与(AND)、逻辑或(OR)和逻辑非(NOT)
- F:基于词汇集合和文档集合的布尔代数体系
在布尔信息检索模型中,结合相关反馈的相关度预测规则定义如下:
- R:一个文档被判定为与查询表达式相关,当且仅当该文档满足该查询表达式。
我们可以将查询词汇理解为对某一文档集合的明确界定,以此阐释该模型。例如,查询词汇economic(经济的) 代表所有以该词为标引词的文档构成的集合。
当使用布尔与(AND) 运算符组合词汇时,检索出的文档集合是任一单个词汇对应文档集合的子集或相等集合。例如,以social(社会的) 和economic(经济的) 为查询词汇,检索结果为同时以这两个词为标引词的文档集合,即两个词汇对应文档集合的交集。
当使用布尔或(OR) 运算符组合词汇时,检索出的文档集合是任一单个词汇对应文档集合的超集或相等集合。例如,以social(社会的) 或economic(经济的) 为查询词汇,检索结果为以其中任意一个词为标引词的文档集合,即两个词汇对应文档集合的并集。
布尔模型的优势
- 基于集合论构建,是最简单的信息检索模型
- 易于理解和实现
- 仅检索与查询语句完全匹配的结果
- 让用户对检索系统拥有掌控感
布尔模型的劣势
- 相似度函数为布尔型,无部分匹配结果,这一点可能会给用户带来使用困扰
- 布尔运算符的使用对检索结果的影响,远大于核心词汇的作用
- 查询语言具备表达性,但使用难度较高
- 对检索出的文档无排序机制
向量空间模型
由于布尔模型存在上述劣势,杰拉德・索尔顿及其同事提出了基于卢恩相似度准则的向量空间模型。卢恩相似度准则指出:两个信息表示形式在元素构成及其分布上的契合度越高,二者表达相似信息的概率就越大。
理解向量空间模型,需掌握以下核心要点:
- 文档的标引表示形式和查询语句均被视为嵌入高维欧几里得空间的向量
- 文档向量与查询语句向量的相似度,通常用二者间的夹角余弦值来衡量
余弦相似度计算公式
余弦相似度是归一化的点积,计算公式如下:
- 当文档向量d与查询语句向量q相同时,Score⟮d,q⟯=1
- 当文档向量d与查询语句向量q无共同元素时,Score⟮d,q⟯=0
基于查询语句与文档的向量空间表示
查询语句和文档可在二维向量空间中表示,以下以car(汽车) 和insurance(保险) 为标引词,结合 1 个查询语句和 3 个文档为例说明:
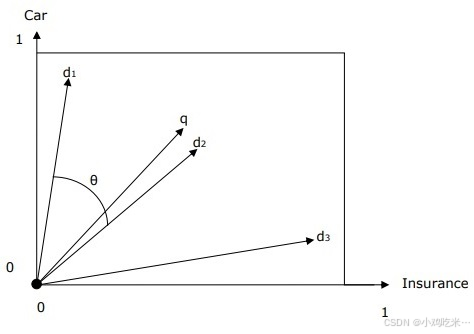
在以 car 和 insurance 为查询词的检索中,文档 d₂ 会成为排名最高的结果,因为查询语句向量 q 与文档向量 d₂的夹角最小。原因在于,car 和 insurance 两个核心概念在 d₂中均为关键信息,因此对应的权重值较高;而文档 d₁和 d₃虽也提及这两个词汇,但在各自文档中,其中一个词汇并非核心信息。
词汇加权
词汇加权指为向量空间中的词汇赋予权重值,词汇的权重越高,对余弦相似度计算结果的影响就越大。模型中应给更重要的词汇分配更高的权重,那么该如何实现这一加权规则呢?
一种方法是将词汇在文档中的出现次数作为其权重,但这种方法的效果并不理想。
更有效的方法是结合词频(tfᵢⱼ) 、文档频率(dfᵢ) 和集合频率(cfᵢ) 进行加权。
- 词频(tfᵢⱼ):指词汇 wᵢ在文档 dⱼ中的出现次数,反映了该词汇在特定文档中的重要性 ------ 词频越高,该词汇对文档内容的描述性就越强。
- 文档频率(dfᵢ):指词汇 wᵢ在文档集合中出现的文档总数,是衡量词汇信息价值的指标,语义指向明确的词汇在文档中的出现规律与语义模糊的词汇存在显著差异。
- 集合频率(cfᵢ):指词汇 wᵢ在整个文档集合中的总出现次数。
三者的数学关系为:dfi≤cfiand∑jtfij=cfi
文档频率加权的形式
文档频率加权主要有以下两种形式:
词频因子加权 若一个词汇 t 在某一文档中频繁出现,那么包含 t 的查询语句应优先检索出该文档,这是词频因子加权的核心逻辑。可将词频(tfᵢⱼ) 和文档频率(dfᵢ) 整合为一个综合权重,公式如下:weight(i,j)={(1+log(tfij))logdfiNiftfi,j≥10iftfi,j=0其中,N 为文档集合中的文档总数。
逆文档频率(idf)加权逆文档频率加权是另一种文档频率加权形式,也被称为 idf 加权。其核心思想是:一个词汇在文档集合中的出现越稀少,信息价值就越高,即词汇的重要性与出现频率成反比。
常用计算公式有两种:idft=log(1+ntN)idft=log(ntN−nt)其中,N 为文档集合中的文档总数,n_t 为包含词汇 t 的文档数量。
用户查询语句的优化
所有信息检索系统的核心目标都是准确性 ------ 即返回符合用户需求的相关文档。而如何通过优化用户的查询语句设计来提升检索效果,成为关键问题。显然,信息检索系统的输出结果依赖于用户的查询语句,设计合理的查询语句能得到更精准的检索结果。用户可借助相关反馈优化查询语句,这也是所有信息检索模型的重要研究方向。
相关反馈
相关反馈以给定查询语句的初始检索结果为基础,通过这些初始结果收集用户反馈信息,判断其是否相关,进而优化并发起新的检索。相关反馈主要分为以下三类:
显式反馈
显式反馈指由相关度评估人员提供的反馈,评估人员会明确标注检索出的文档与查询语句的相关程度。为提升检索性能,需将相关反馈信息与初始查询语句进行融合。
评估人员或系统其他用户可通过以下两种相关度标注体系,明确表达文档的相关度:
- 二元相关度体系:仅将文档的相关状态划分为相关(1)和不相关(0)两类。
- 分级相关度体系:通过数字、字母或描述性词汇对文档的相关度进行分级标注,描述性词汇可分为 "不相关""略有相关""高度相关""相关" 等。
隐式反馈
隐式反馈指从用户的行为中推导得出的反馈,这类行为包括:用户查看文档的时长、选择查看与跳过的文档、页面浏览和滚动操作等。停留时间是隐式反馈的典型例子,即用户查看搜索结果中链接页面的时长。
伪反馈
伪反馈也被称为盲反馈,是一种自动局部分析方法。该方法将相关反馈中的人工操作环节自动化,让用户无需进行大量交互,就能获得更优的检索效果。其核心优势是无需像显式反馈那样依赖专业的评估人员。
实现伪反馈的步骤如下:
- 步骤 1:将初始查询语句的检索结果视为相关结果,通常选取排名前 10-50 的结果。
- 步骤 2:从这些文档中提取排名前 20-30 的词汇,可采用词频 - 逆文档频率(tf-idf)加权法进行筛选。
- 步骤 3:将这些词汇添加至初始查询语句中,重新进行文档匹配,最终返回相关性最高的文档。