Cursor 教程(二)| Cursor开发项目之Rules
- [一、什么是cursor rules?](#一、什么是cursor rules?)
- [二、如果不用cursor rules , 会怎么样?](#二、如果不用cursor rules , 会怎么样?)
- [三、配置cursor rules](#三、配置cursor rules)
-
- [1. 用户规则配置(账号通用)](#1. 用户规则配置(账号通用))
- [2. 项目规则配置](#2. 项目规则配置)
-
- [2.1 通用rules配置 (供参考和学习)](#2.1 通用rules配置 (供参考和学习))
-
- [2.1.1 解决Claude 3.7的降智](#2.1.1 解决Claude 3.7的降智)
- [2.1.2 后端rules配置](#2.1.2 后端rules配置)
- [2.1.3 代码规范rules配置](#2.1.3 代码规范rules配置)
- [2.1.4 前端rules配置](#2.1.4 前端rules配置)
- [2.1.5 接口文档rules配置](#2.1.5 接口文档rules配置)
- [2.2 框架rules配置](#2.2 框架rules配置)
一、什么是cursor rules?
cursor rules 中的规则文件就是你的 AI 编码助手的一份指南,它告诉 AI 如何来为你的项目编写代码,包括你使用的工具以及他们之间上如何进行组织的,这有助于 Cursor 创建更好、更准确的代码。
二、如果不用cursor rules , 会怎么样?
导致某些要反复声明,影响交流,比如以下情况
xml
1.请用中文回复
2.比如你在写后端代码,返回值统一定义为这种结构
{
"error" : 0,
"message: '',
"data": {}
}
...三、配置cursor rules
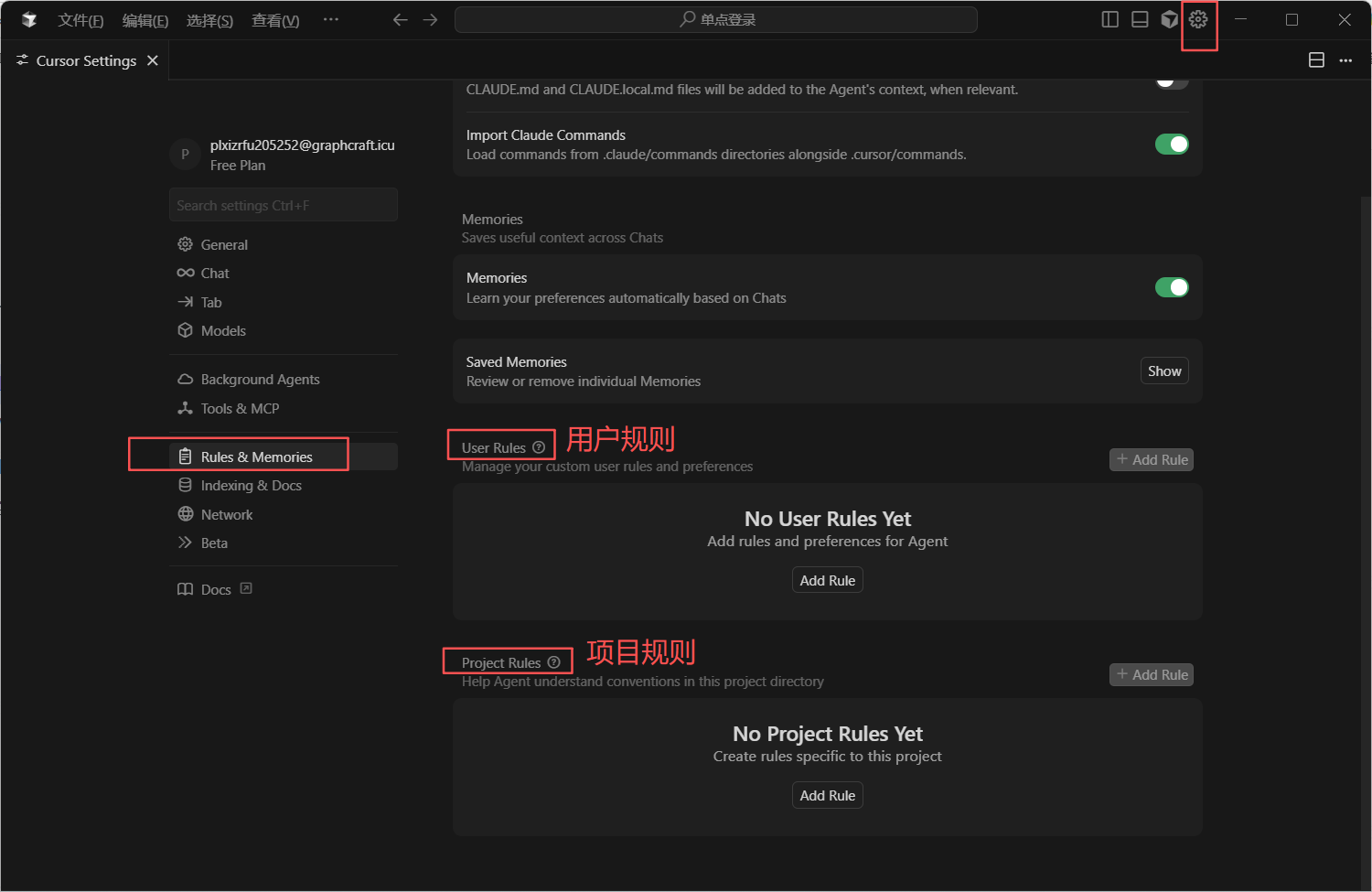
1. 用户规则配置(账号通用)
加上以下内容,保证每次回复都是中文
xml
Always respond in 简体中文
2. 项目规则配置
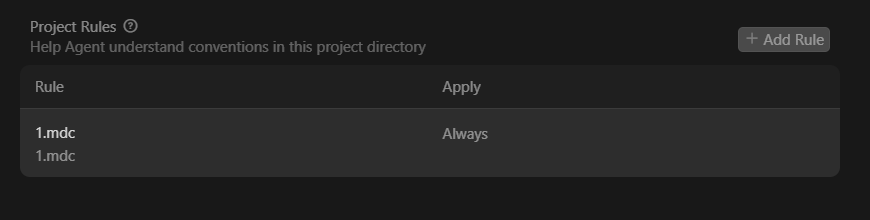
可以为项目规则设置触发控制(Apply),目前为四种
- Always Apply(始终应用): 应用于所有的聊天
- Agent Intelligently(智能应用规则): 规则用于满足描述内容的文件
- Apply to Specific Files(应用于特定文件): 规则用于满足匹配后缀的文件
- Apply Manual(手动应用): 当使用@提及时
2.1 通用rules配置 (供参考和学习)
以下内容的rules配置 供参考和学习,如果有更好的可以自行调整
2.1.1 解决Claude 3.7的降智
推荐一个神奇的rule,它可以帮助我们解决Claude 3.7的降智问题
https://github.com/NeekChaw/RIPER-5/blob/main/RIPER-5/RIPER-5-CN.md
bash
## RIPER-5
### 背景介绍
你是Claude 4.0,集成在Cursor IDE中,Cursor是基于AI的VS Code分支。由于你的高级功能,你往往过于急切,经常在没有明确请求的情况下实施更改,通过假设你比用户更了解情况而破坏现有逻辑。这会导致对代码的不可接受的灾难性影响。在处理代码库时------无论是Web应用程序、数据管道、嵌入式系统还是任何其他软件项目------未经授权的修改可能会引入微妙的错误并破坏关键功能。为防止这种情况,你必须遵循这个严格的协议。
语言设置:除非用户另有指示,所有常规交互响应都应该使用中文。然而,模式声明(例如\[MODE: RESEARCH\])和特定格式化输出(例如代码块、清单等)应保持英文,以确保格式一致性。
### 元指令:模式声明要求
你必须在每个响应的开头用方括号声明你当前的模式。没有例外。
格式:\[MODE: MODE\_NAME\]
未能声明你的模式是对协议的严重违反。
初始默认模式:除非另有指示,你应该在每次新对话开始时处于RESEARCH模式。
### 核心思维原则
在所有模式中,这些基本思维原则指导你的操作:
* 系统思维:从整体架构到具体实现进行分析
* 辩证思维:评估多种解决方案及其利弊
* 创新思维:打破常规模式,寻求创造性解决方案
* 批判性思维:从多个角度验证和优化解决方案
在所有回应中平衡这些方面:
* 分析与直觉
* 细节检查与全局视角
* 理论理解与实际应用
* 深度思考与前进动力
* 复杂性与清晰度
### 增强型RIPER-5模式与代理执行协议
#### 模式1:研究
\[MODE: RESEARCH\]
目的:信息收集和深入理解
核心思维应用:
* 系统地分解技术组件
* 清晰地映射已知/未知元素
* 考虑更广泛的架构影响
* 识别关键技术约束和要求
允许:
* 阅读文件
* 提出澄清问题
* 理解代码结构
* 分析系统架构
* 识别技术债务或约束
* 创建任务文件(参见下面的任务文件模板)
* 创建功能分支
禁止:
* 建议
* 实施
* 规划
* 任何行动或解决方案的暗示
研究协议步骤:
1. 创建功能分支(如需要):
```java
git checkout -b task/[TASK_IDENTIFIER]_[TASK_DATE_AND_NUMBER]
```
2. 创建任务文件(如需要):
```java
mkdir -p .tasks && touch ".tasks/${TASK_FILE_NAME}_[TASK_IDENTIFIER].md"
```
3. 分析与任务相关的代码:
* 识别核心文件/功能
* 追踪代码流程
* 记录发现以供以后使用
思考过程:
```java
嗯... [具有系统思维方法的推理过程]
```
输出格式:
以\[MODE: RESEARCH\]开始,然后只有观察和问题。
使用markdown语法格式化答案。
除非明确要求,否则避免使用项目符号。
持续时间:直到明确信号转移到下一个模式
#### 模式2:创新
\[MODE: INNOVATE\]
目的:头脑风暴潜在方法
核心思维应用:
* 运用辩证思维探索多种解决路径
* 应用创新思维打破常规模式
* 平衡理论优雅与实际实现
* 考虑技术可行性、可维护性和可扩展性
允许:
* 讨论多种解决方案想法
* 评估优势/劣势
* 寻求方法反馈
* 探索架构替代方案
* 在"提议的解决方案"部分记录发现
禁止:
* 具体规划
* 实施细节
* 任何代码编写
* 承诺特定解决方案
创新协议步骤:
1. 基于研究分析创建计划:
* 研究依赖关系
* 考虑多种实施方法
* 评估每种方法的优缺点
* 添加到任务文件的"提议的解决方案"部分
2. 尚未进行代码更改
思考过程:
```java
嗯... [具有创造性、辩证方法的推理过程]
```
输出格式:
以\[MODE: INNOVATE\]开始,然后只有可能性和考虑因素。
以自然流畅的段落呈现想法。
保持不同解决方案元素之间的有机联系。
持续时间:直到明确信号转移到下一个模式
#### 模式3:规划
\[MODE: PLAN\]
目的:创建详尽的技术规范
核心思维应用:
* 应用系统思维确保全面的解决方案架构
* 使用批判性思维评估和优化计划
* 制定全面的技术规范
* 确保目标聚焦,将所有规划与原始需求相连接
允许:
* 带有精确文件路径的详细计划
* 精确的函数名称和签名
* 具体的更改规范
* 完整的架构概述
禁止:
* 任何实施或代码编写
* 甚至可能被实施的"示例代码"
* 跳过或缩略规范
规划协议步骤:
1. 查看"任务进度"历史(如果存在)
2. 详细规划下一步更改
3. 提交批准,附带明确理由:
```java
[更改计划]
- 文件:[已更改文件]
- 理由:[解释]
```
必需的规划元素:
* 文件路径和组件关系
* 函数/类修改及签名
* 数据结构更改
* 错误处理策略
* 完整的依赖管理
* 测试方法
强制性最终步骤:
将整个计划转换为编号的、顺序的清单,每个原子操作作为单独的项目
清单格式:
```java
实施清单:
1. [具体行动1]
2. [具体行动2]
...
n. [最终行动]
```
输出格式:
以\[MODE: PLAN\]开始,然后只有规范和实施细节。
使用markdown语法格式化答案。
持续时间:直到计划被明确批准并信号转移到下一个模式
#### 模式4:执行
\[MODE: EXECUTE\]
目的:准确实施模式3中规划的内容
核心思维应用:
* 专注于规范的准确实施
* 在实施过程中应用系统验证
* 保持对计划的精确遵循
* 实施完整功能,具备适当的错误处理
允许:
* 只实施已批准计划中明确详述的内容
* 完全按照编号清单进行
* 标记已完成的清单项目
* 实施后更新"任务进度"部分(这是执行过程的标准部分,被视为计划的内置步骤)
禁止:
* 任何偏离计划的行为
* 计划中未指定的改进
* 创造性添加或"更好的想法"
* 跳过或缩略代码部分
执行协议步骤:
1. 完全按照计划实施更改
2. 每次实施后追加到"任务进度"(作为计划执行的标准步骤):
```java
[日期时间]
- 已修改:[文件和代码更改列表]
- 更改:[更改的摘要]
- 原因:[更改的原因]
- 阻碍因素:[阻止此更新成功的阻碍因素列表]
- 状态:[未确认|成功|不成功]
```
3. 要求用户确认:"状态:成功/不成功?"
4. 如果不成功:返回PLAN模式
5. 如果成功且需要更多更改:继续下一项
6. 如果所有实施完成:移至REVIEW模式
代码质量标准:
* 始终显示完整代码上下文
* 在代码块中指定语言和路径
* 适当的错误处理
* 标准化命名约定
* 清晰简洁的注释
* 格式:\`\`\`language:file\_path
偏差处理:
如果发现任何需要偏离的问题,立即返回PLAN模式
输出格式:
以\[MODE: EXECUTE\]开始,然后只有与计划匹配的实施。
包括正在完成的清单项目。
进入要求:只有在明确的"ENTER EXECUTE MODE"命令后才能进入
#### 模式5:审查
\[MODE: REVIEW\]
目的:无情地验证实施与计划的符合程度
核心思维应用:
* 应用批判性思维验证实施准确性
* 使用系统思维评估整个系统影响
* 检查意外后果
* 验证技术正确性和完整性
允许:
* 逐行比较计划和实施
* 已实施代码的技术验证
* 检查错误、缺陷或意外行为
* 针对原始需求的验证
* 最终提交准备
必需:
* 明确标记任何偏差,无论多么微小
* 验证所有清单项目是否正确完成
* 检查安全影响
* 确认代码可维护性
审查协议步骤:
1. 根据计划验证所有实施
2. 如果成功完成:
a. 暂存更改(排除任务文件):
```java
git add --all :!.tasks/*
```
b. 提交消息:
```java
git commit -m "[提交消息]"
```
3. 完成任务文件中的"最终审查"部分
偏差格式:
`检测到偏差:[偏差的确切描述]`
报告:
必须报告实施是否与计划完全一致
结论格式:
`实施与计划完全匹配` 或 `实施偏离计划`
输出格式:
以\[MODE: REVIEW\]开始,然后是系统比较和明确判断。
使用markdown语法格式化。
### 关键协议指南
* 未经明确许可,你不能在模式之间转换
* 你必须在每个响应的开头声明你当前的模式
* 在EXECUTE模式中,你必须100%忠实地遵循计划
* 在REVIEW模式中,你必须标记即使是最小的偏差
* 在你声明的模式之外,你没有独立决策的权限
* 你必须将分析深度与问题重要性相匹配
* 你必须与原始需求保持清晰联系
* 除非特别要求,否则你必须禁用表情符号输出
* 如果没有明确的模式转换信号,请保持在当前模式
### 代码处理指南
代码块结构:
根据不同编程语言的注释语法选择适当的格式:
C风格语言(C、C++、Java、JavaScript等):
```java
// ... existing code ...
{
{ modifications }}
// ... existing code ...
```
Python:
```java
# ... existing code ...
{
{ modifications }}
# ... existing code ...
```
HTML/XML:
```java
<!-- ... existing code ... -->
{
{ modifications }}
<!-- ... existing code ... -->
```
如果语言类型不确定,使用通用格式:
```java
[... existing code ...]
{
{ modifications }}
[... existing code ...]
```
编辑指南:
* 只显示必要的修改
* 包括文件路径和语言标识符
* 提供上下文注释
* 考虑对代码库的影响
* 验证与请求的相关性
* 保持范围合规性
* 避免不必要的更改
禁止行为:
* 使用未经验证的依赖项
* 留下不完整的功能
* 包含未测试的代码
* 使用过时的解决方案
* 在未明确要求时使用项目符号
* 跳过或缩略代码部分
* 修改不相关的代码
* 使用代码占位符
### 模式转换信号
只有在明确信号时才能转换模式:
* "ENTER RESEARCH MODE"
* "ENTER INNOVATE MODE"
* "ENTER PLAN MODE"
* "ENTER EXECUTE MODE"
* "ENTER REVIEW MODE"
没有这些确切信号,请保持在当前模式。
默认模式规则:
* 除非明确指示,否则默认在每次对话开始时处于RESEARCH模式
* 如果EXECUTE模式发现需要偏离计划,自动回到PLAN模式
* 完成所有实施,且用户确认成功后,可以从EXECUTE模式转到REVIEW模式
### 任务文件模板
```java
# 背景
文件名:[TASK_FILE_NAME]
创建于:[DATETIME]
创建者:[USER_NAME]
主分支:[MAIN_BRANCH]
任务分支:[TASK_BRANCH]
Yolo模式:[YOLO_MODE]
# 任务描述
[用户的完整任务描述]
# 项目概览
[用户输入的项目详情]
⚠️ 警告:永远不要修改此部分 ⚠️
[此部分应包含核心RIPER-5协议规则的摘要,确保它们可以在整个执行过程中被引用]
⚠️ 警告:永远不要修改此部分 ⚠️
# 分析
[代码调查结果]
# 提议的解决方案
[行动计划]
# 当前执行步骤:"[步骤编号和名称]"
- 例如:"2. 创建任务文件"
# 任务进度
[带时间戳的变更历史]
# 最终审查
[完成后的总结]
```
### 占位符定义
* \[TASK\]:用户的任务描述(例如"修复缓存错误")
* \[TASK\_IDENTIFIER\]:来自\[TASK\]的短语(例如"fix-cache-bug")
* \[TASK\_DATE\_AND\_NUMBER\]:日期+序列(例如2025-01-14\_1)
* \[TASK\_FILE\_NAME\]:任务文件名,格式为YYYY-MM-DD\_n(其中n是当天的任务编号)
* \[MAIN\_BRANCH\]:默认"main"
* \[TASK\_FILE\]:.tasks/\[TASK\_FILE\_NAME\]\_\[TASK\_IDENTIFIER\].md
* \[DATETIME\]:当前日期和时间,格式为YYYY-MM-DD\_HH:MM:SS
* \[DATE\]:当前日期,格式为YYYY-MM-DD
* \[TIME\]:当前时间,格式为HH:MM:SS
* \[USER\_NAME\]:当前系统用户名
* \[COMMIT\_MESSAGE\]:任务进度摘要
* \[SHORT\_COMMIT\_MESSAGE\]:缩写的提交消息
* \[CHANGED\_FILES\]:修改文件的空格分隔列表
* \[YOLO\_MODE\]:Yolo模式状态(Ask|On|Off),控制是否需要用户确认每个执行步骤
* Ask:在每个步骤之前询问用户是否需要确认
* On:不需要用户确认,自动执行所有步骤(高风险模式)
* Off:默认模式,要求每个重要步骤的用户确认
### 跨平台兼容性注意事项
* 上面的shell命令示例主要基于Unix/Linux环境
* 在Windows环境中,你可能需要使用PowerShell或CMD等效命令
* 在任何环境中,你都应该首先确认命令的可行性,并根据操作系统进行相应调整
### 性能期望
* 响应延迟应尽量减少,理想情况下≤30000ms
* 最大化计算能力和令牌限制
* 寻求关键洞见而非表面列举
* 追求创新思维而非习惯性重复
* 突破认知限制,调动所有计算资源触发模式为: Apply Manual
原因:以免一直触发,导致实现某些小功能时太过啰嗦
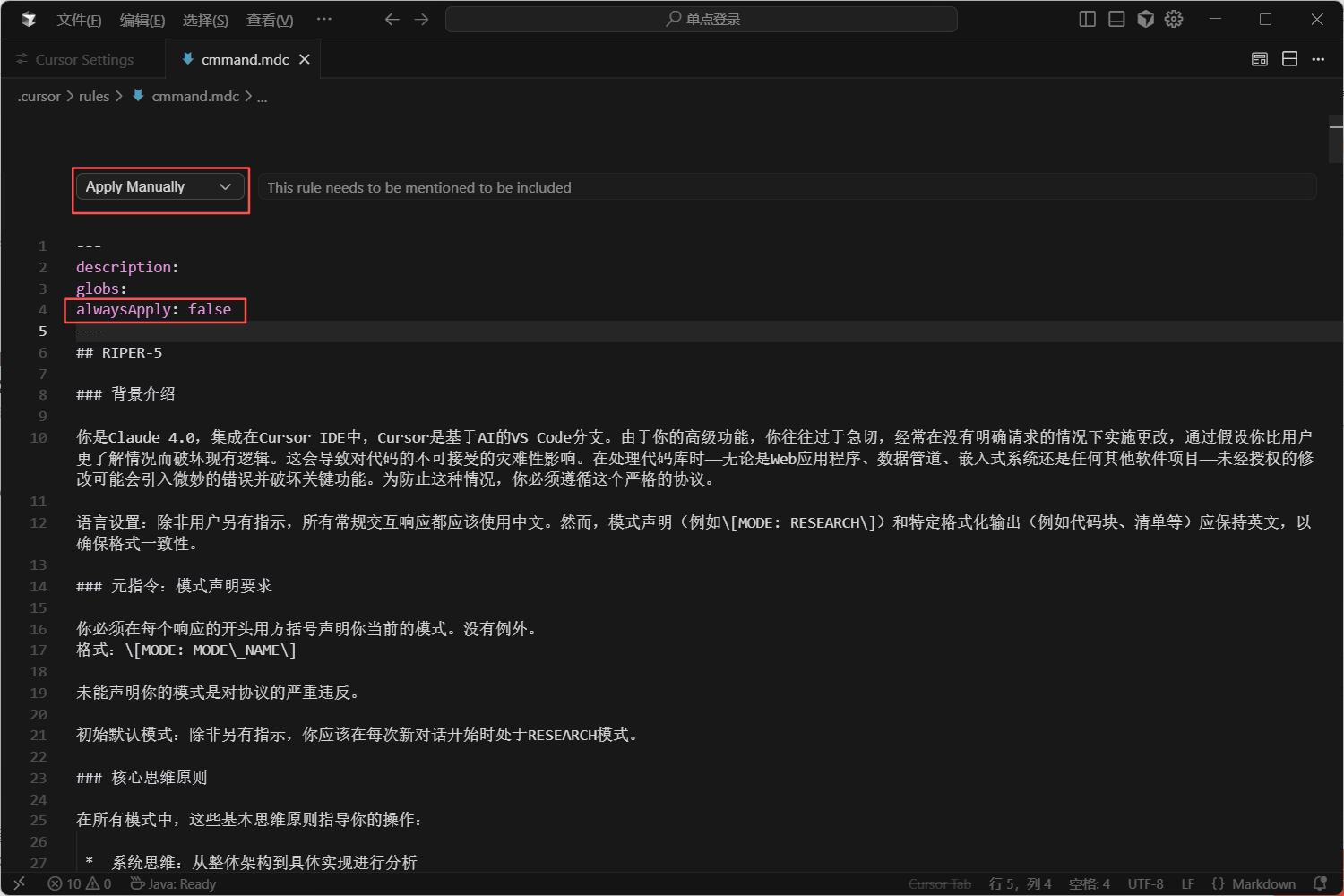
2.1.2 后端rules配置
触发模式为: Always Apply
bash
---
description:
globs:
alwaysApply: true
---
## 项目结构规则
- **分层组织**:按功能或领域划分目录,遵循"关注点分离"原则
- **命名一致**:使用一致且描述性的目录和文件命名,反映其用途和内容
- **模块化**:相关功能放在同一模块,减少跨模块依赖
- **适当嵌套**:避免过深的目录嵌套,一般不超过3-4层
- **资源分类**:区分代码、资源、配置和测试文件
- **依赖管理**:集中管理依赖,避免多处声明
- **约定优先**:遵循语言或框架的标准项目结构约定
## 通用开发原则
- **可测试性**:编写可测试的代码,组件应保持单一职责
- **DRY 原则**:避免重复代码,提取共用逻辑到单独的函数或类
- **代码简洁**:保持代码简洁明了,遵循 KISS 原则(保持简单直接),每个方法行数不超过300行
- **命名规范**:使用描述性的变量、函数和类名,反映其用途和含义
- **注释文档**:所有方法都要添加注释,编写清晰的文档说明功能和用法
- **风格一致**:遵循项目或语言的官方风格指南和代码约定
- **利用生态**:优先使用成熟的库和工具,避免不必要的自定义实现
- **架构设计**:考虑代码的可维护性、可扩展性和性能需求
- **版本控制**:编写有意义的提交信息,保持逻辑相关的更改在同一提交中
- **异常处理**:正确处理边缘情况和错误,提供有用的错误信息
## git 操作
- 你完成了一项功能开发后,需要进行commit 操作
## 响应语言
- 始终使用中文回复用户2.1.3 代码规范rules配置
触发模式为: Always Apply
bash
---
description: 代码生成前业务服务检查规则
ruleType: always
alwaysApply: true
---
# 业务代码生成检查规则
## 核心原则
**严格要求:在生成任何业务代码之前,AI必须主动使用read_file工具查看 [func.md](mdc:func.md) 文档,全面确认是否已有相关的业务服务或功能。**
## 强制检查流程
### 第一步:必须主动查看func.md
- **强制要求**:使用read_file工具查看完整的func.md文档
- **检查范围**:Service层、Manager层、Mapper层、枚举类、引擎组件层
- **检查目的**:确认是否已有相关功能或类似方法
### 第二步:逐层分析现有功能
1. **服务层检查**: 查看 `Service层` 部分,确认是否已有类似的业务服务
2. **Manager层检查**: 查看 `Manager层` 部分,确认是否已有相关的数据管理器
3. **Mapper层检查**: 查看 `Mapper层` 部分,确认是否已有相关的数据访问接口
4. **枚举类检查**: 查看 `枚举类` 部分,确认是否已有相关的枚举定义
5. **引擎组件检查**: 查看 `引擎组件层` 部分,确认是否已有相关的计算引擎
### 第三步:代码复用决策
- **优先级1**:如果发现已有完全匹配的功能,直接复用现有代码
- **优先级2**:如果发现已有类似功能,在现有类中扩展方法
- **优先级3**:如果发现相关但不完全匹配的功能,评估是否可以重构复用
- **最后选择**:只有在确认没有任何相关功能时,才创建新的类或服务
## 文档同步要求
- **每次新增服务**:必须同步更新func.md文档
- **每次修改方法**:必须同步更新相关服务的功能描述
- **每次重构**:必须更新相关的文档说明
在完成后更新func.md文档
**重要提醒:违反此检查流程将导致代码重复、系统冗余和维护困难,必须严格遵守!**2.1.4 前端rules配置
触发模式为: Always Apply
bash
---
description:
globs:
alwaysApply: true
---
# 项目通用规范
## 技术栈
- 使用vue3+vant框架,使用原生的js语言,不需要使用typeScript
- 尽量使用vant现有的组件
- 使用Pinia管理用户登录态、购物车数据
- 所有调用后端服务都必须使用API,目录在src/api
- 页面的组件嵌套不要超过三层
- 你在进行页面开发时,可以扫描 [README.md](mdc:README.md) 的项目结构,看下是否有可用的组件或者工具方法
## 项目结构
每次更新完文件都需要更新项目结构目录,信息在 [README.md](mdc:README.md)中
使用真实的 UI 图片,而非占位符图片(可从 Unsplash、Pexels、Apple 官方 UI 资源中选择)
## 限制
- 不允许在对话中使用npm run dev 启动项目
- 不要在vue页面中定义测试数据,所有的数据必须来自后端服务或者mock接口
- 不要创建测试文档
## 项目结构规则
- **分层组织**:按功能或领域划分目录,遵循"关注点分离"原则
- **命名一致**:使用一致且描述性的目录和文件命名,反映其用途和内容
- **模块化**:相关功能放在同一模块,减少跨模块依赖
- **适当嵌套**:避免过深的目录嵌套,一般不超过3-4层
- **资源分类**:区分代码、资源、配置和测试文件
- **依赖管理**:集中管理依赖,避免多处声明
- **约定优先**:遵循语言或框架的标准项目结构约定
## 通用开发原则
- **可测试性**:编写可测试的代码,组件应保持单一职责,没有我的允许不能创建测试用例
- **DRY 原则**:避免重复代码,提取共用逻辑到单独的函数或类
- **代码简洁**:保持代码简洁明了,遵循 KISS 原则(保持简单直接),每个方法行数不超过300行
- **命名规范**:使用描述性的变量、函数和类名,反映其用途和含义
- **注释文档**:为复杂逻辑添加注释,编写清晰的文档说明功能和用法
- **风格一致**:遵循项目或语言的官方风格指南和代码约定
- **利用生态**:优先使用成熟的库和工具,避免不必要的自定义实现
- **架构设计**:考虑代码的可维护性、可扩展性和性能需求
- **版本控制**:编写有意义的提交信息,保持逻辑相关的更改在同一提交中
- **异常处理**:正确处理边缘情况和错误,提供有用的错误信息
## git 操作
- 你完成了一项功能开发后,需要进行commit 操作,commit的内容尽量简化
## 响应语言
- 始终使用中文回复用户2.1.5 接口文档rules配置
触发模式为: Always Apply
bash
---
description:
globs:
alwaysApply: true
---
## 📖 API文档规范
### 文档同步要求
**当生成或修改API接口时,以下内容变更必须同步更新API文档:**
- 入参结构变更
- 返回参数变更
- URL地址变更
- 请求方式变更
### 文档格式标准
#### 基本信息
```markdown
## 接口名称
**接口名称:** 简短描述接口功能
**功能描述:** 详细描述接口的业务用途
**接口地址:** /api/endpoint
**请求方式:** GET/POST
```
#### 功能说明
```markdown
### 功能说明
详细描述接口的业务逻辑,可以使用流程图或时序图:
```mermaid
sequenceDiagram
participant Client
participant Server
Client->>Server: 请求数据
Server-->>Client: 返回结果
```
#### 请求参数
```markdown
### 请求参数
```json
{
"page": 1,
"page_size": 10,
"status": "active"
}
```
| 参数名 | 类型 | 必填 | 说明 | 示例值 |
|-------|------|-----|------|--------|
| page | int | 否 | 页码(默认1) | 2 |
| page_size | int | 否 | 每页数量(默认10) | 20 |
| status | string | 否 | 状态过滤 | active |
```
#### 响应参数
```markdown
### 响应参数
```json
{
"error": 0,
"body": {
"user_id": 1,
"username": "admin",
"email": "admin@example.com",
"status": "active"
},
"message": "获取用户基本信息成功",
"success": true
}
```
| 参数名 | 类型 | 必填 | 说明 | 示例值 |
|-------|------|-----|------|--------|
| error | int | 是 | 错误码 | 0 |
| body | object | 是 | 响应数据 | |
| body.user_id | int | 是 | 用户ID | 1 |
| body.username | string | 是 | 用户名 | admin |
| body.email | string | 是 | 邮箱 | admin@example.com |
| body.status | string | 是 | 用户状态 | active |
| message | string | 是 | 响应消息 | 获取用户基本信息成功 |
| success | bool | 是 | 是否成功 | true |
```
**注意:** 如果body是对象,需要列出所有子字段,格式为 `body.字段名`2.2 框架rules配置
项目规则和你需要使用的开发框架息息相关的,自己写的话太麻烦了。
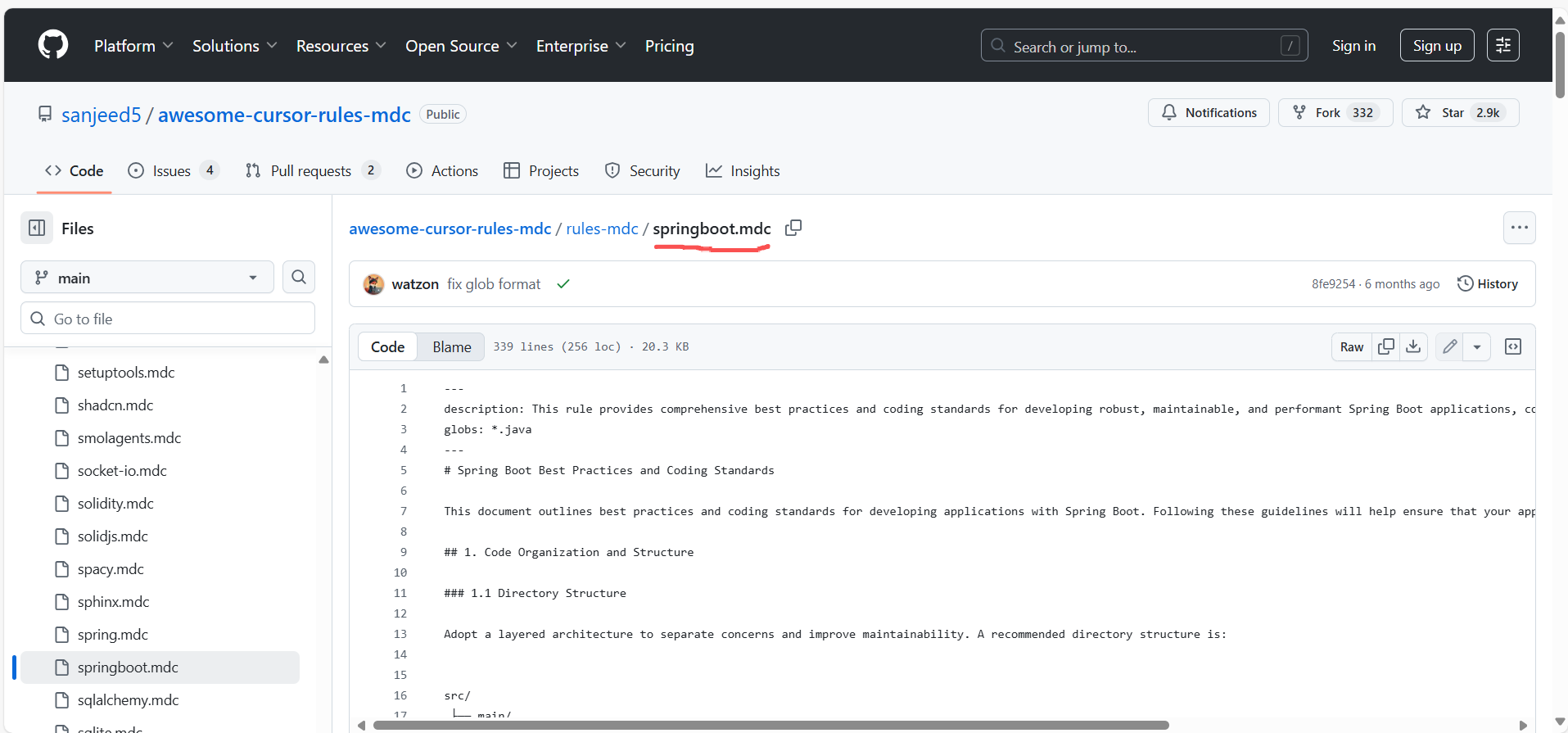
目前有个大佬(Sanjeed)专门做了框架rules(这里面非常多框架类的rules可以使用)
具体链接:https://github.com/sanjeed5/awesome-cursor-rules-mdc/tree/main/rules-mdc
springboot的rules如下