目录
[1、使用cursor赋能Web UI自动化(生成代码)](#1、使用cursor赋能Web UI自动化(生成代码))
[1)使⽤ WebDriver Manager ⾃动下载驱动](#1)使⽤ WebDriver Manager ⾃动下载驱动)
[2、Cursor实现Web UI自动化实战](#2、Cursor实现Web UI自动化实战)
传统的web ui自动化测试是通过编写自动化脚本来进行操作的
传统的web ui自动化测试----使用selenium编写自动化脚本,下载selenium包下载浏览器、下载驱动(1、手动下载驱动(下载和浏览器相同的版本相同的)---存在驱动失效的情况(因为浏览器可能会更新) 2、使用webdrivermanager(驱动管理---自动下载匹配的驱动))
常见操作:打开百度浏览器、输入百度网址、找到输入框输入关键词、找到百度一下按钮并点击、关闭浏览器
传统方式存在的问题和挑战:
同接⼝⾃动化测试,传统的⾃动化测试存在诸多问题
1)测试脚本维护成本⾼:传统⽅式依赖固定的选择器(XPath、CSS选择器),当⻚⾯结构变化时容
易失效;需要⼿动更新⼤量测试脚本,维护成本⾼
2)测试覆盖率有限:测试⽤例主要依赖⼈⼯设计,容易遗漏边界情况
3)测试数据管理复杂:需要⼿动准备各种测试数据,⽽且测试⽤例之间存在数据依赖,导致⽤例顺序
混乱
4)智能程度不⾜:⽆法根据⻚⾯变化⾃动调整
1、使用cursor赋能Web UI自动化(生成代码)
1.1、生成测试用例
补充:使用cursor之前先创建一个空文件夹,然后用cursor打开文件夹,在测试过程中生成的文件就会都放在这个文件夹里。生成的md文件使用typora软件打开格式更清晰(这个软件付费)
将界面截图,给ai对话。提示词:
@【截图】博客系统登录⻚⾯
根据图⽚提供的登陆界⾯设计UI⾃动化测试⽤例,⻚⾯包含标题、导航栏和登陆表单模块要求:
1)⽤例包含登陆功能(正常、异常)、导航栏的跳转、标题的验证
2)按照优先级设计⽤例数量在10以内
3)输出格式:⽤例名称、操作步骤,预期结果。内容具体,避免模糊的描述⽅式
4)将输出内容保存⾄"登录⻚⾯测试⽤例.md"⽂件中
对生成的测试用例进行检查,并修改错误的测试用例。
1.2、生成测试脚本
提示词:
@登录⻚⾯测试⽤例.md
读取登录⻚⾯测试⽤例.md⽂档内容并⽣成测试脚本,要求:
1)使⽤Python+selenium实现⾃动化脚本编写
2)⽤例遵循pytest框架运⾏规则
3)测试⽅法命名要合理
4)每个测试⽤例都要对结果进⾏断⾔
5)不使⽤复杂设计模式
6)完全遵循以上要求,不要做额外拓展
对脚本进行修改:
1)使⽤ WebDriver Manager ⾃动下载驱动
提示词:
@test_login_page.py @ 报错信息
通过 pytest 命令运⾏脚本,出现报错
2)对元素进行定位
提供⻚⾯对应的html源数据给AI,让AI⾃动获取元素的定位⽅式。
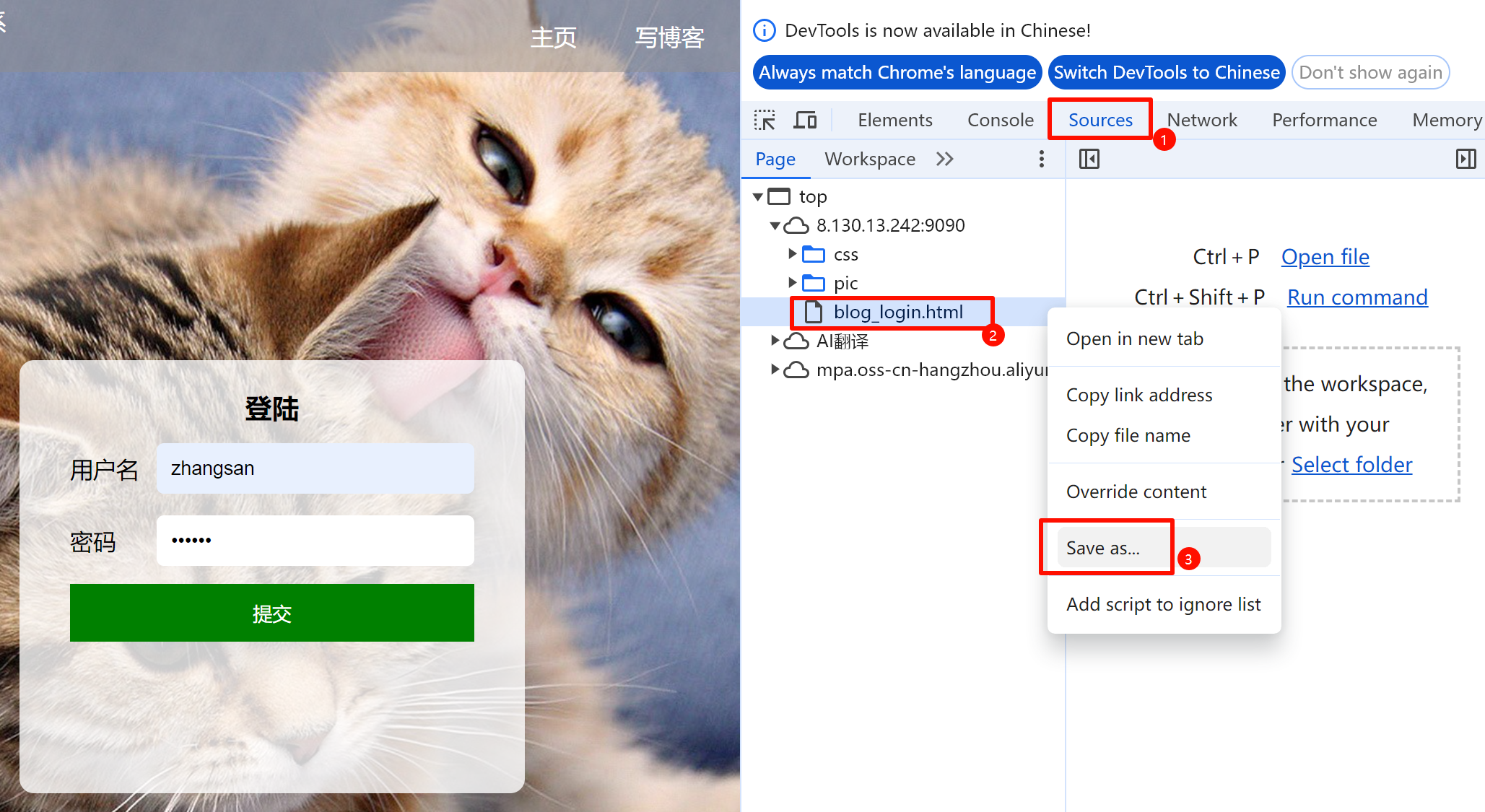
这样可以将html文件保存在项目中
提示词:
@test_login_page.py @blog_login.html
根据⻚⾯源码 blog_login.html ⽂件,修改代码中获取对应元素的⽅式,避免出现⻚⾯元素查找不到 的错误
3)参数化
提示词:
分析脚本,利⽤pytest中的参数化操作来减少⽤例数量
要求:
1)可以合并的⽤例放在同⼀个⽤例中
2)不可以合并的⽤例不做处理,避免强⾏处理降低代码可读性
4)用例依赖
我们知道,在执行列表页的测试脚本之前需要先执行博客登录页的脚本
将博客列表页截图,生成列表页的用例。
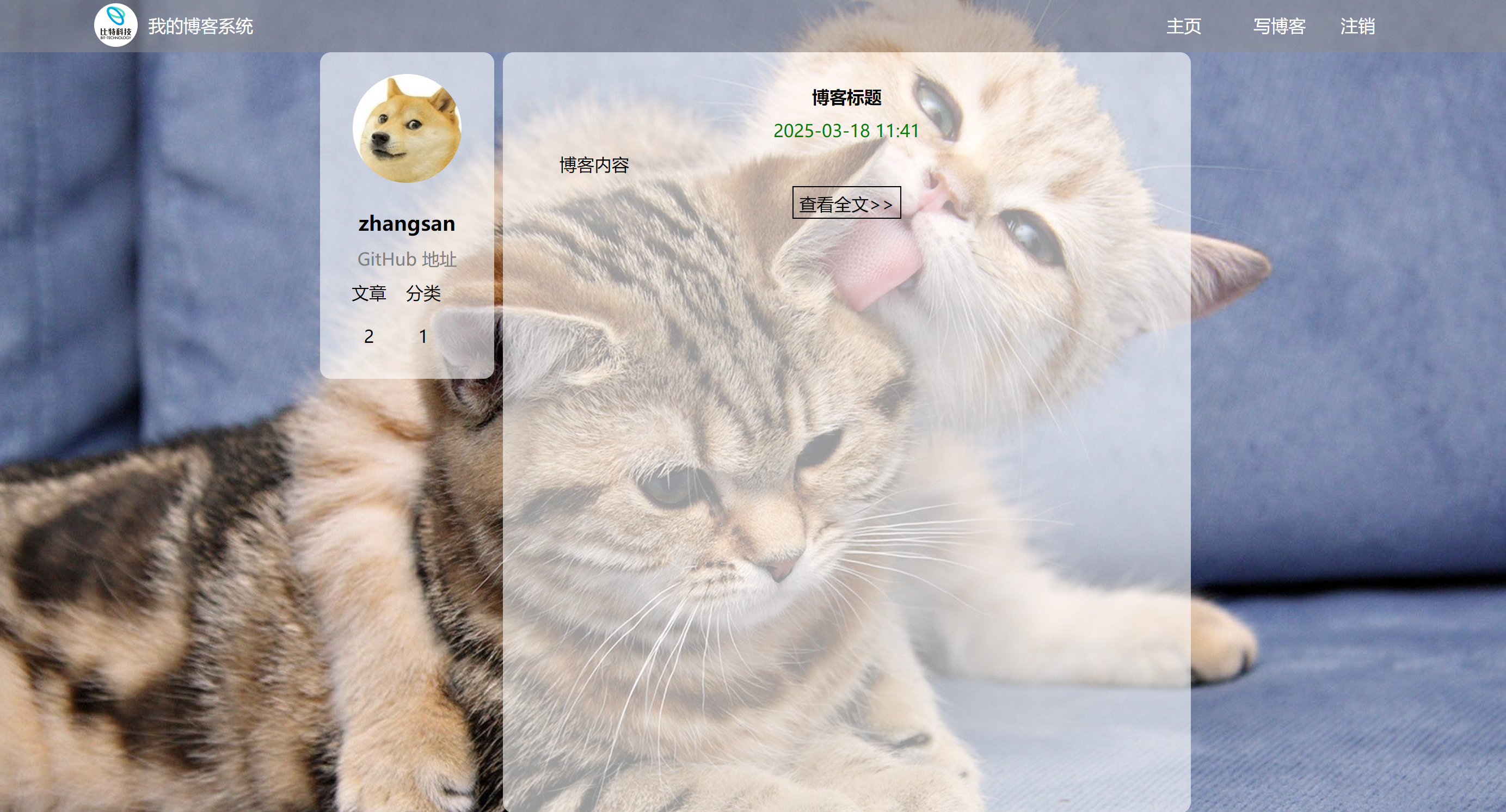
提示词:
@【截图】博客系统列表⻚⾯
根据图⽚提供的列表界⾯设计UI⾃动化测试⽤例,⻚⾯包含个⼈信息(头像、GitHub地址、⽂章、分
类)、导航栏(主⻚、写博客、注销)和博客列表(⾄少包含⼀条博客,每条博客包含标题、发布时
间、博客内容、查看全⽂按钮)要求:
1)⽤例包含博客列表信息、个⼈信息的验证
2)按照优先级设计⽤例数量在10以内
3)输出格式:⽤例名称、操作步骤,预期结果。内容具体,避免模糊的描述⽅式
4)将输出内容保存⾄"列表⻚⾯测试⽤例.md"⽂件中
对用例进行优化:标注清楚跳转页面的链接
生成列表页的测试脚本
将列表页的测试用例和列表页的html给对话,生成脚本,关键词:
@列表⻚⾯测试⽤例.md @blog_list.html
读取列表⻚⾯测试⽤例.md内容和⻚⾯源码blog_list.html⽂件,⽣成列表⻚测试脚本,要求:
1)使⽤Python+selenium实现⾃动化脚本编写
2)⽤例遵循pytest框架运⾏规则
3)测试⽅法命名要合理
4)每个测试⽤例都要对结果进⾏断⾔
5)不使⽤复杂设计模式
6)完全遵循以上要求,不要做额外拓展
如果只执行列表页的测试用例,所有的测试用例都是错误的,因为需要先进行登录

我们要使用pytest-order工具指定方法或类的执行顺序。
我们使用AI来进行设置,提示词:
使⽤pytest-order插件指定类的执⾏顺序,顺序依次为:TestLoginPage、TestListPage
从代码结构看出,每运行一个用例都需要重新创建driver对象启动浏览器,这样会导致:1)登录态不会被保存,导致列表页用例执行失败
2)大量重复的操作导致用例执行时间太长
使用pytest中的conftest.py操作类中定义的fixture标记方法管理起来,并重新修改作用域。
提示词:
背景:登录成功后才能访问列表⻚,否则会⾃动跳转⾄登录⻚,导致列表⻚测试⽤例全部执⾏失败
重新优化代码设计,要求:
1)提取测试⽂件中的启动和关闭浏览器操作,封装为fixture标记的⽅法,使得所有⽤例执⾏前启动
⼀次浏览器,执⾏结束后关闭⼀次浏览器
2)执⾏列表⻚每个测试⽤例之前需要保证已经存在登录态
3)不改变每个测试⽤例的逻辑
4)不要做过多拓展
生成结果:
1)提取浏览器启动/关闭操作到fixture - 创建了 conftest.py ⽂件,使⽤ scope="session" 确保整个测试会话期间只启动⼀次浏览器
2)访问列表⻚之前保证登录态 - 实现了 ensure_login fixture,⾃动管理登录态,确保列表⻚测试⽤例不会因登录失败⽽失败
3)不改变测试⽤例逻辑 - 保持了所有测试⽤例的原有逻辑完全不变,只修改了依赖注⼊⽅式
python
import pytest
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
import time
@pytest.fixture(scope="session")
def driver():
"""浏览器驱动fixture,整个测试会话期间只启动⼀次"""
chrome_options = Options()
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--remote-debugging-port=9222")
# 使⽤webdriver-manager⾃动管理ChromeDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.implicitly_wait(10)
yield driver
# 测试会话结束后关闭浏览器
driver.quit()
@pytest.fixture(scope="session")
def wait(driver):
"""WebDriverWait对象fixture"""
return WebDriverWait(driver, 10)
@pytest.fixture(scope="session")
def base_url():
"""基础URL配置"""
return "http://8.137.19.140:9090"
@pytest.fixture(scope="session")
def login_url(base_url):
"""登录⻚⾯URL"""
return f"{base_url}/blog_login.html"
@pytest.fixture(scope="session")
def list_url(base_url):
"""列表⻚⾯URL"""
return f"{base_url}/blog_list.html"
@pytest.fixture(scope="function")
def ensure_login(driver, wait, base_url, login_url):
"""确保登录态的fixture,在访问列表⻚之前执⾏登录"""
# 先访问登录⻚⾯
# driver.get(login_url)
# 检查是否已经登录(通过检查当前URL是否为列表⻚)
current_url = driver.current_url
if "blog_list.html" in current_url:
# 已经登录,直接返回
return
driver.get(login_url)
# 执⾏登录操作
username_input = driver.find_element(By.NAME, "username")
password_input = driver.find_element(By.NAME, "password")
submit_button = driver.find_element(By.ID, "submit")
username_input.clear()
username_input.send_keys("zhangsan")
password_input.clear()
password_input.send_keys("123456")
submit_button.click()
# 等待登录成功并跳转
time.sleep(2)
# 验证登录成功
current_url = driver.current_url
expected_url = f"{base_url}/blog_list.html"
assert current_url == expected_url, f"登录失败,当前URL: {current_url},期望
URL: {expected_url}我们需要用个人经验,对AI生成的代码进行修改。
2、Cursor实现Web UI自动化实战
2.1、需求分析与用例设计
提示词:
@blog_edit.html
@blog_login.html
@blog_list.html
@blog_detail.html
根据附件提供的html⽂件,设计各个⻚⾯的UI⾃动化测试⽤例,为后续的编写UI⾃动化测试脚本做准备,要求:
1)包含功能和界⾯等⽅⾯来设计
2)按照优先级,每个⻚⾯设计⽤例数量在10以内
3)输出格式:按照博客系统测试⽤例模板.md格式输出,内容具体,避免模糊的描述⽅式
4)将输出内容保存⾄博客系统⽂件夹下的"博客系统⻚⾯测试⽤例.md"⽂件中
对生成的测试用例需要进行手动优化
2.2、搭建项目框架
提示词:
**@博客系统⻚⾯测试⽤例.md
根据附件内容,帮我设计⼀套UI⾃动化⽬录结构。
技术栈要求:
- 编程语⾔:Python
- 测试框架:pytest
- ⾃动化测试:selenium
- 数据驱动:YAML
- 报告:Allure
- logging⽇志记录:⽇志分级输出,按天分割
- 合理使⽤异常,避免使⽤复杂的设计模式
输出:只输出⽬录结构即可**
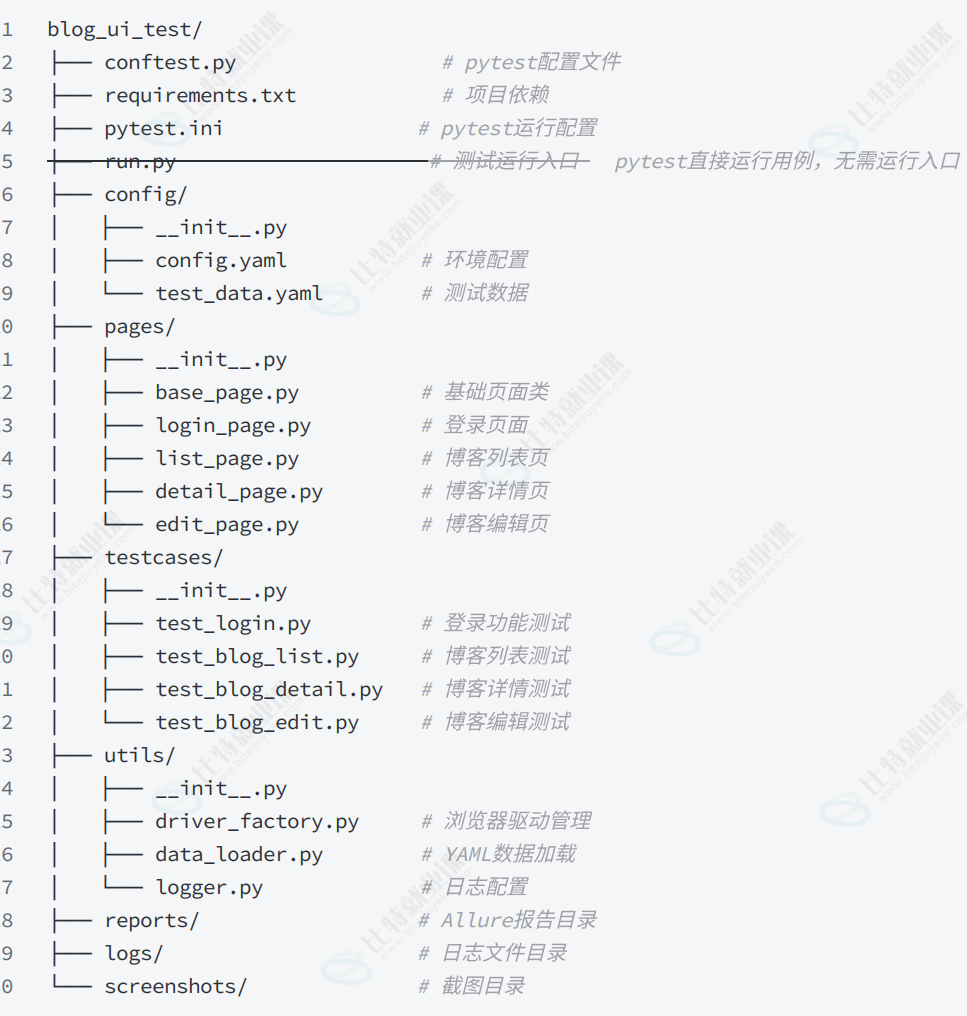
页面.py文件这些是页面对象类,封装了页面的元素定位和操作方法:----【定位器、操作方法】
python
# base_page.py - 基础类
class BasePage:
def __init__(self, driver):
self.driver = driver//定义基础页面类 BasePage,是所有具体页面类(如登录页、编辑页)的父类。__init__ 构造方法:接收 driver(浏览器驱动,如 Selenium 的 ChromeDriver)作为参数,并赋值给实例变量 self.driver,让子类可以直接使用浏览器驱动。
def find_element(self, locator):
return self.driver.find_element(*locator)//子类无需重复写 driver.find_element(),直接调用 self.find_element(locator) 即可,减少重复代码
def click(self, locator):
self.find_element(locator).click()
# login_page.py - 登录页面类
class LoginPage(BasePage)://定义登录页面类 LoginPage,继承自 BasePage,因此可以直接使用父类的 find_element()、click() 方法和 self.driver 属性。
# 元素定位
username_input = ("id", "username")//username_input 代表 "用户名输入框",用 id 定位,id 值是 username。
password_input = ("id", "password")
login_button = ("id", "login-btn")
# 页面操作
def login(self, username, password):
self.find_element(self.username_input).send_keys(username)
self.find_element(self.password_input).send_keys(password)
self.click(self.login_button)test.py文件这些是测试用例,使用页面对象来执行测试:---【测试步骤、断言】
python
# test_login.py
def test_valid_login(driver):
login_page = LoginPage(driver)
login_page.login("valid_user", "password123")
assert "Dashboard" in driver.title
def test_invalid_login(driver):
login_page = LoginPage(driver)
login_page.login("invalid", "wrong")
assert "Error" in login_page.get_error_message()数据驱动测试:
test_data.yaml文件:

python
# test_blog_edit.py
import pytest
from utils.data_loader import load_test_data
test_data = load_test_data("test_data.yaml")//调用load_test_data函数,读取test_data.yaml中的测试数据,
@pytest.mark.parametrize("post", test_data["blog"]["test_post"])//让测试函数可以多次执行,一个数据执行一次。第一个参数,是参数名。第二个是:test_data.yaml文件中的blog下的test_post下的数据,有几组数据测试函数就执行几次
def test_create_post(driver, post): //函数的命名规则满足pytest识别用例的规则
edit_page = EditPage(driver) //EditPage 是封装了博客编辑页面所有操作(如输入标题、输入内容、点击发布按钮等)的页面对象类,driver 作为参数传入,让页面对象可以操作浏览器
edit_page.create_post( //调用 EditPage 类的 create_post 方法,传入测试数据中的标题和内容,执行 "创建博客文章" 的操作(底层会模拟用户输入标题、输入内容、点击发布等步骤)。
title=post["title"],
content=post["content"]
)
assert post["title"] in driver.title
//断言(验证):检查测试数据中的文章标题是否包含在当前页面的标题(driver.title,即浏览器标签页的标题)中。
如果断言通过,说明创建文章的功能正常;如果失败,pytest 会抛出断言错误,测试用例标记为失败。环境切换:
python
# conftest.py
import pytest
from utils.driver_factory import DriverFactory
from utils.data_loader import load_config
@pytest.fixture
def driver(request):
config = load_config("config.yaml")
env = request.config.getoption("--env", default="dev")
env_config = config["environments"][env]
driver = DriverFactory.get_driver(env_config)
yield driver
driver.quit()2.3、脚本生成和优化
@ 博客系统项⽬结构 .md
@ 博客系统⻚⾯测试⽤例 .md
@blog_detail.html
@blog_edit.html
@blog_list.html
@blog_login.html
结合附件中博客系统相关⽂件,严格按照各⽂件内容要求,在当前项⽬下⽣成 web ui ⾃动化测试
由于本次提示词过多,AI生成可能不完整,我们可以追加提示词:
存在部分⻚⾯对应的测试脚本未实现完全,请继续⽣成
对存在的问题进行修复
2.4、测试报告生成
pytest --html=reports/report.html
3、chrome-mcp-server
【可以实现零代码】
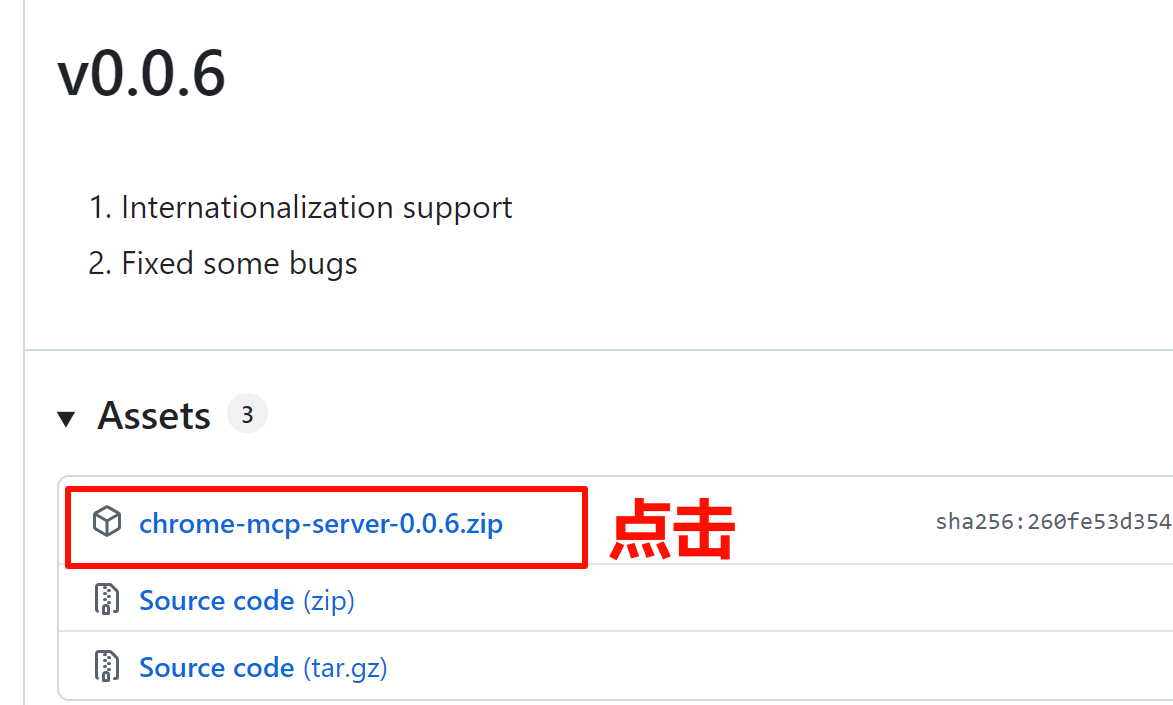
安装教程:
1、安装node.js 和谷歌浏览器
2、安装mcp-chrome-bridge
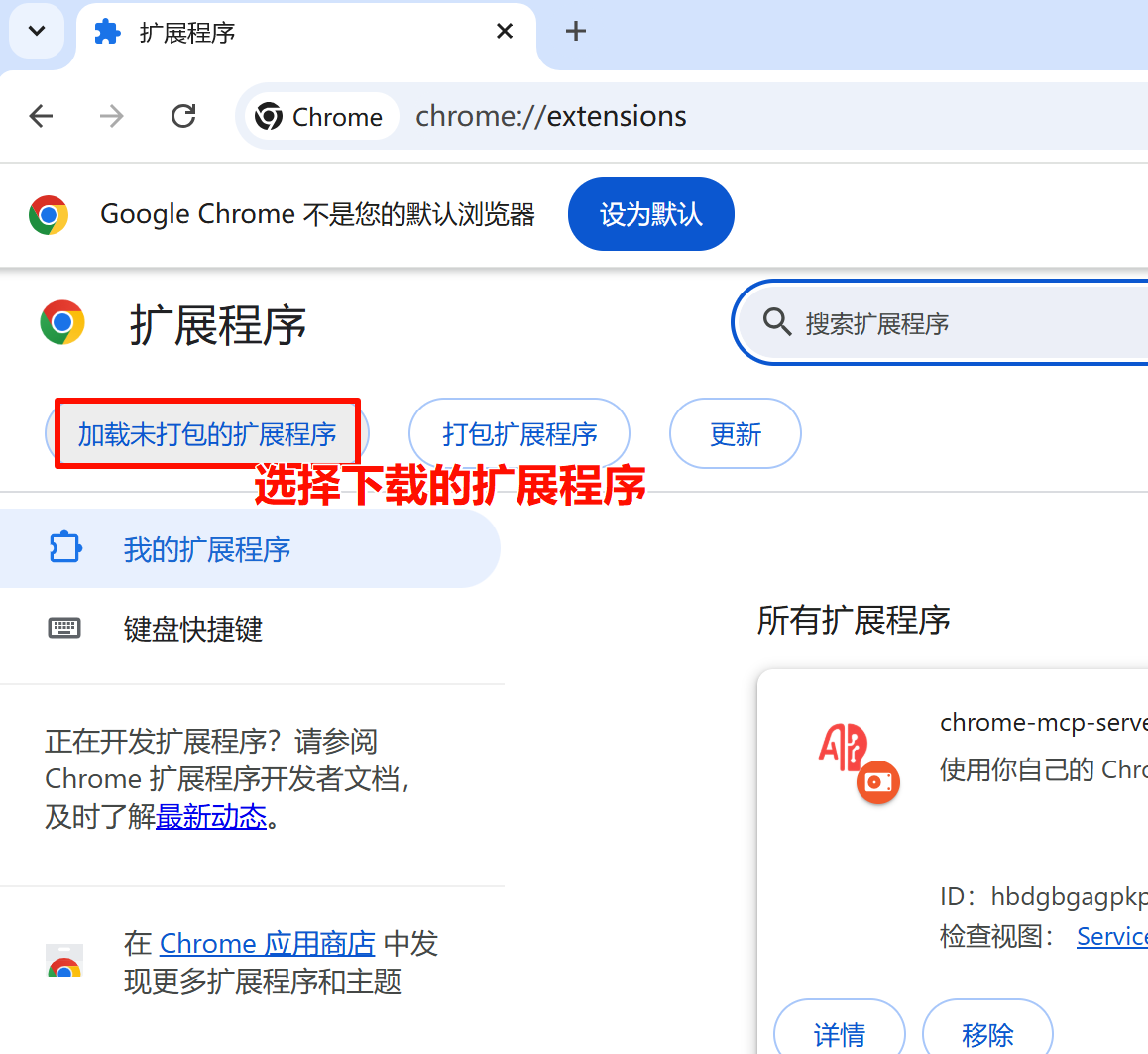
3、安装chrome扩展
下载:https://github.com/hangwin/mcp-chrome/releases
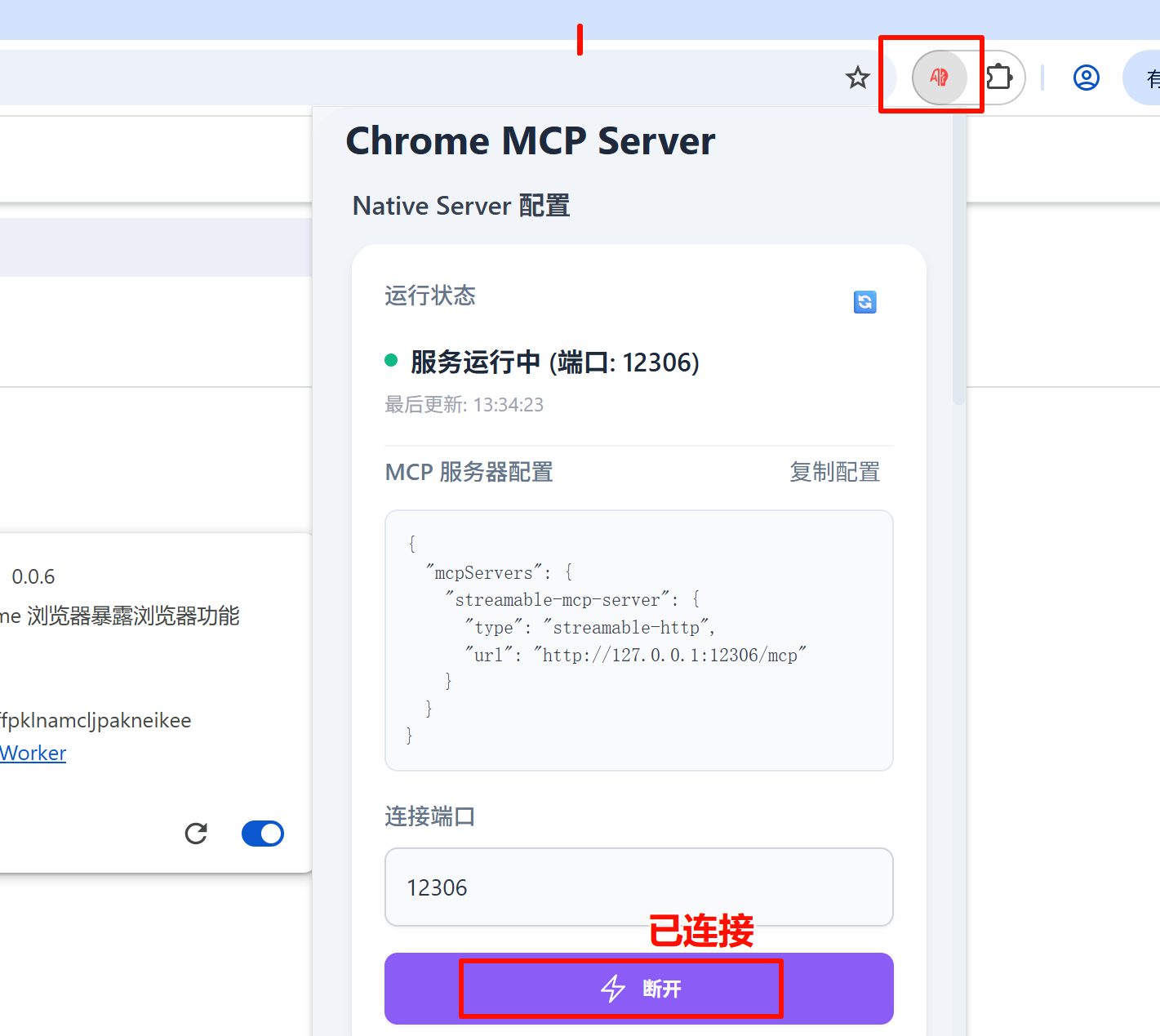
链接chrome扩展服务器:
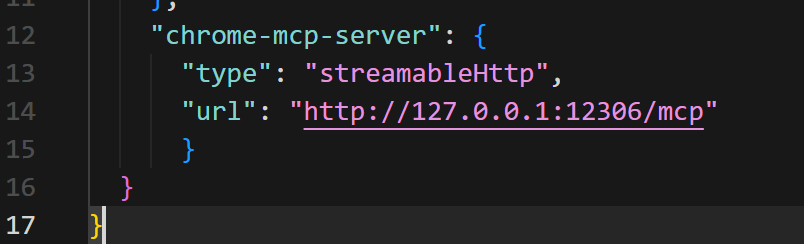
4、在cursor中添加chrome配置:
"chrome-mcp-server" : {
"type" : "streamableHttp" ,
"url" : "http://127.0.0.1:12306/mcp"
}
绿色点表示配置添加成功
chrome-mpc-server已安装成功
使用chrome-mcp-server
登录页测试用例:提示词(规定操作步骤,ai就会执行操作步骤)
使⽤ chrome MCP 执⾏以下操作
⽤例 1 :正常登录功能验证
操作步骤:
1 . 打开 chrome 访问登录⻚⾯ http://8.137.19.140:9090/blog_login.html
2 . 在⽤⼾名输⼊框中输⼊ "zhangsan"
3 . 在密码输⼊框中输⼊ "123456"
4 . 点击 " 提交 " 按钮
预期结果:
1 . 检查⻚⾯是否登录成功,⻚⾯跳转到 blog_list.html
4、零代码MCP自动化实战
生成登录页测试用例:
@登录⻚⾯图⽚ @博客系统UI测试⽤例模板.md
根据⻚⾯图⽚和测试⽤例模板,⽣成登录⻚⾯的测试⽤例
1)包含功能和界⾯等⽅⾯来设计
2)按照优先级,每个⻚⾯设计⽤例数量在10以内
生成列表页测试用例:
@列表⻚⾯图⽚ @博客系统UI测试⽤例模板.md
根据⻚⾯图⽚和测试⽤例模板,⽣成列表⻚⾯的测试⽤例
1)包含功能和界⾯等⽅⾯来设计
2)按照优先级,每个⻚⾯设计⽤例数量在10以内
生成完需要手动优化
通过chrome mcp server操作浏览器执行自动化测试,实际是模拟人手工测试的行为,即使关闭浏览器也会保存用户的访问历史和登录信息,而selenium编写的自动化脚本,每次打开浏览器都不会有登录信息,所以每次打开浏览器都需要先登录。
chrome-mcp-server不能处理页面出现的弹窗
运行自动化---提示词:
@登录⻚⾯测试⽤例.md @列表⻚⾯测试⽤例.md @详情⻚⾯测试⽤例.md @编辑⻚⾯测试⽤例.md
使⽤chrome MCP执⾏操作所有⻚⾯测试⽤例⽂件中内容
前置:打开chrome浏览器,访问⻚⾯URL:http://8.137.19.140:9090/blog_list.html,若⻚⾯
显⽰"注销"按钮,则点击
后置:关闭chrome浏览器
要求:
1)执⾏所有测试⽤例之前要进⾏⼀次前置操作,所有⽤例执⾏结束要执⾏⼀次后置操作
2)严格按照⽤例中规定的操作步骤,执⾏每⼀个测试⽤例(注意⽤例中要求的如⻚⾯刷新、重新在当前标
签⻚下访问URL)
3)分别统计执⾏成功和失败的⽤例数量
4)测试⽤例执⾏过程中只能打开⼀个标签⻚,不需要在执⾏过程中打开多个标签
chrome-mcp-server存在的问题:
1、存在bug无法处理弹窗(自动化常见场景)
2、不支持无头模式
3、自动化执行时间比传统方式长5倍