1 背景:Langfuse 为什么越用越慢?
我们的AI分析平台每天产生数万条Trace,每条Trace包含多个Observation(Span、Generation、Event)。一条完整的RAG链路Trace响应体可以达到100KB - 1MB,包含了prompt、completion、token用量等大量数据。
问题来了:
- 同一个Trace被反复查看:分析师调试时会频繁刷新详情页
- Langfuse API 速度慢:每次请求都是全量数据库查询 + JSON序列化
- 高并发下雪上加霜:多个分析师同时看同一条热门Trace,上游直接被打满
我们需要一层透明的缓存代理,对客户端完全无感,只需要改一下Langfuse的Base URL。
2 整体架构:代理 + Worker 双服务协作
整套方案有两个服务组成:缓存代理 和预热Worker,各司其职
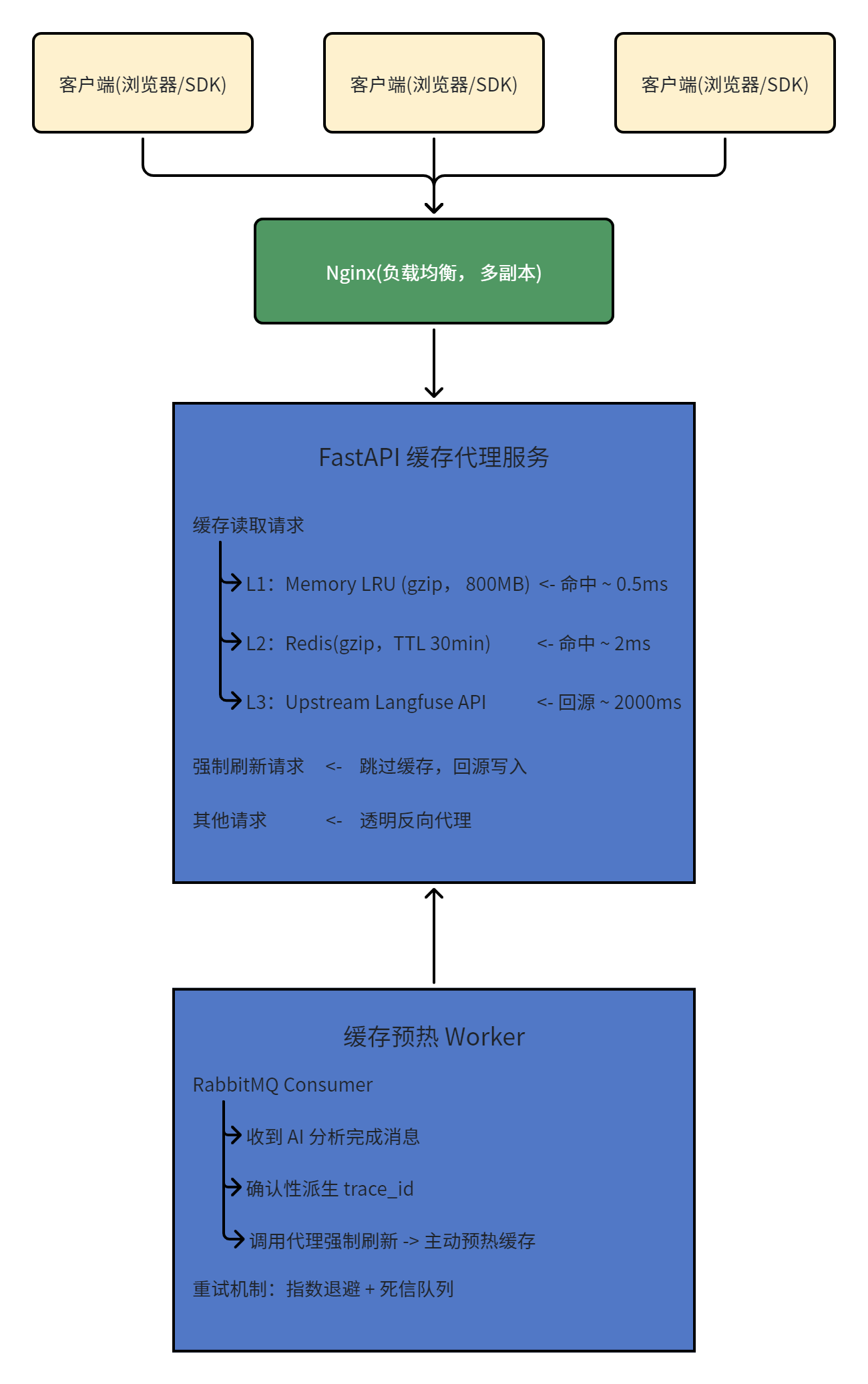
缓存代理是面向客户端的入口,他拦截所有对 Langfuse 的请求。对于 Trace 和 Observation 的详情查询,走二级缓存(内存 -> Redis -> 回源);对于其他请求(列表、写入等),直接透明转发到上游 Langfuse,客户端完全无感知。
|----|-----------------|----------|-------|----------------|----------|
| 层级 | 存储介质 | 命中延迟 | 容量 | 过期策略 | 数据格式 |
| L1 | 进程内存 | ~0.5ms | 800MB | LRU按字节淘汰 | gzip 压缩态 |
| L2 | Redis | ~2ms | 无硬性上限 | TTL 30min 自动过期 | gzip 压缩态 |
| L3 | 上游 Langfuse API | ~2000ms | - | - | 原始JSON |
L1 命中时直接从内存复制字节到 TCP 缓存区,几乎零开销;L1 未命中但 L2命中时,数据会**回填 L1,**后续请求直接走内存;都未命中才回源,回源后同事写入 L1 和 L2。
预热worker则是后台服务,他监听业务系统的消息队列。当一条 AI 分析任务弯沉后, Worker 会主动调用代理的强制刷新接口。把最新的 Trace 数据提前拉到缓存里。这样当用户打开详情页时,数据已经在内存中等着了。
核心思路:用户看 Trace 之前,缓存里就已经有数据了。两个服务解耦部署,代理负责"读时快",Worker 负责"首次也快"。
3 核心技术点:四个让我收掉头发的设计
3.1 Gzip 全链路透传:零解压,零重压缩
这是整个方案最关键的性能优化。常规做法是:从上游拿到 JSON -> 解压 -> 存缓存 -> 读缓存 -> 压缩 -> 返回客户端。每一步都在浪费 CPU。
我们的做法:数据以 gzip 压缩态在整个链路中流动,从不解压。
常规做法,每次请求都在做无用功

我们的做法,压缩态全链路透传

路由层拿到的就是 gzip 字节,直接设置Content-Encoding: gzip 返回给浏览器,由浏览器完成解压。整条李娜路只在首次回源时做一个压缩,后续命中时零 CPU 开销。
压缩级别我们选的是最低档(level=1),原因如下:
|-------------|------------------|-------------------|---------------|
| 压缩级别 | 压缩率(500KB JSON) | 压缩耗时 | 适用场景 |
| level=1 | ~79%(压到~105KB) | 最快 | 缓存场景,压缩只做一次 |
| level=6(默认) | ~82% | 约 3~4 倍于 level=1 | 通用场景 |
| level=9 | ~83% | 约 6~8 倍于 level=1 | 极致压缩率,不在意 CPU |
level=1 只做 Huffman 编码,对 JSON 之类高荣誉文本已经足够。多压几个百分点换来的空间节省,远不如剩下的 CPU 时间值钱 --- 况且我们只在首次回源时压缩一次,后续全是直读。
3.2 Per-Key 锁防缓存击穿:不同 Key 完全并发
缓存未命中时,如果 100 个请求同时打同一个 Trace,不加保护就会同时回源 100 次(缓存击穿 / 惊群效应)。
常见方案是加一把全局锁 --- 但这会导致查 Trace A 的请求也要等查 Trace B 的请求释放锁。我们的方案是 Per-Key 细粒度锁。
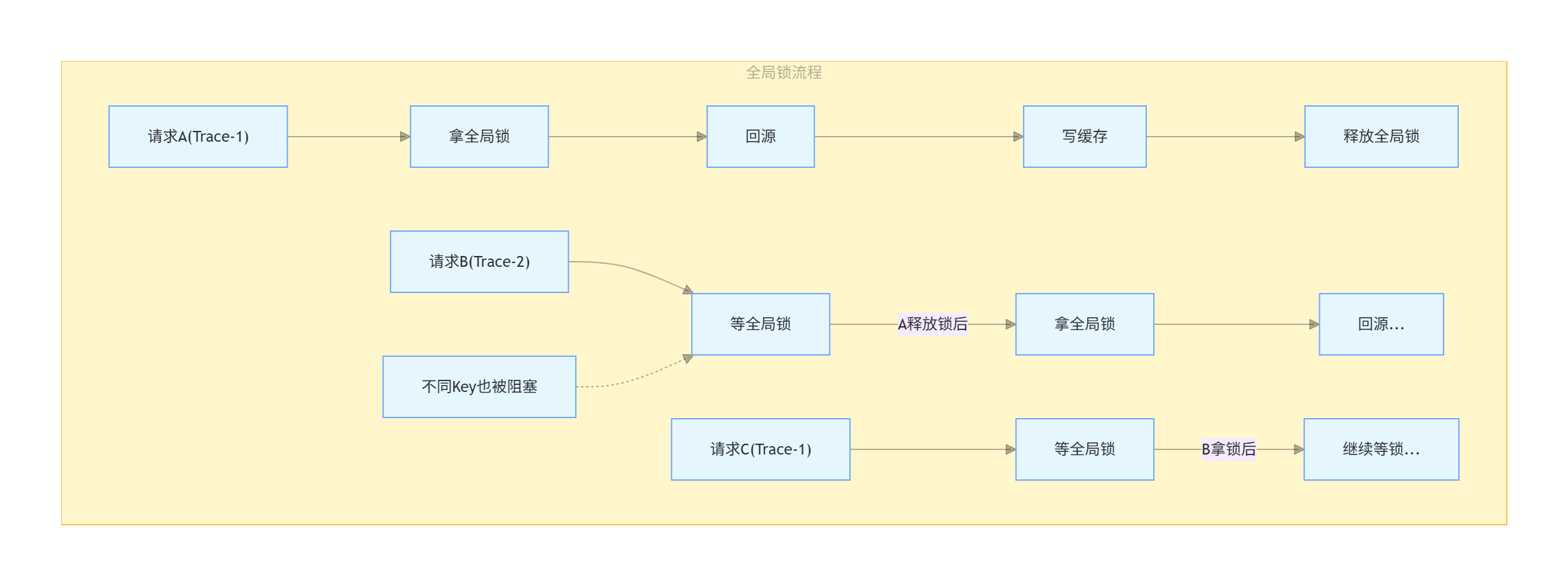
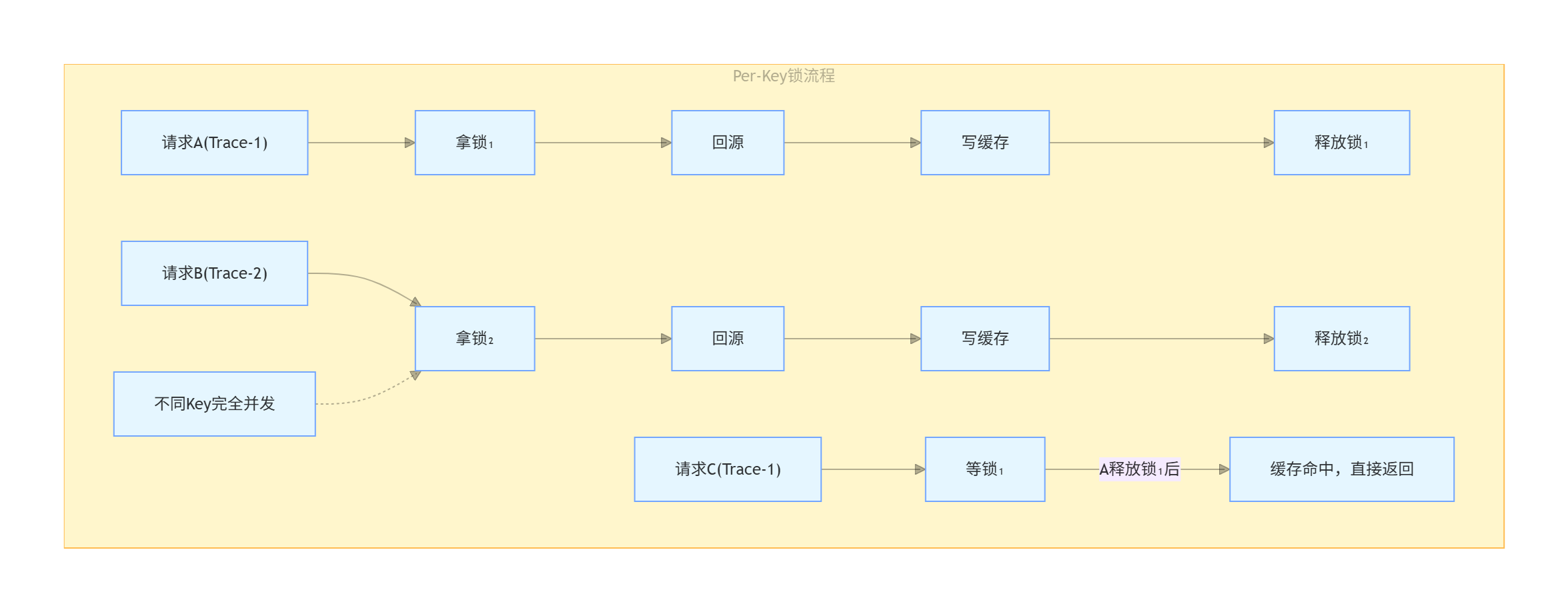
关键设计:
- 读命中走快路径,完全无锁,不会成为瓶颈
- 未命中时只锁当前 Key,查 Trace A 和查 Trace B 互不影响
- Double-Check Locking:拿锁后再查一次缓存,避免重复回源
- 锁用完即清理,防止锁字典无限增长
3.3 双 Redis 客户端:二进制 vs 文本分离
Redis 的 Python 客户端有一个坑:decode_responses=True 是连接级别的配置,不能按次切换。开了和这个选项之后,存取 gzip 二进制数据会被当 UTF-8 解码,直接损坏。
解法很直接 --- 开两个客户端连同一个 Redis:一个设 decode_responses=True 专门读写 JSON文本,另一个设 decode_responses=True专门读写 gzip 二进制。连接池配置完全相同,只有编码行为不同。比每次调用都处理编码问题更加干净,也避免了二进制数据被悄悄损坏的隐蔽 bug。
3.4 多租户缓存隔离:用 Cache Key 的命名空间
Langfuse 是多租户的,每个项目都有独立的 public_key 。我们把 public_key 直接编进缓存 Key,格式为 langfuse:trace:{public_key}:{trace_id} 。这样即使两个租户有相同的 trace_id ,缓存 Key 也不会冲突。Key 中使用 **{...}**包裹租户标识,利用 Redis Cluster 的 Hash Tag 语法确保同一租户的数据落在同一个 Slot。
4 缓存预热Worker:用户打开页面前,数据就在
缓存代理解决了"重复查询慢"的问题,但第一次查(冷启动)还是慢。预热 Worker 解决的就是这个首次访问延迟。
4.1 工作流程
没有预热:
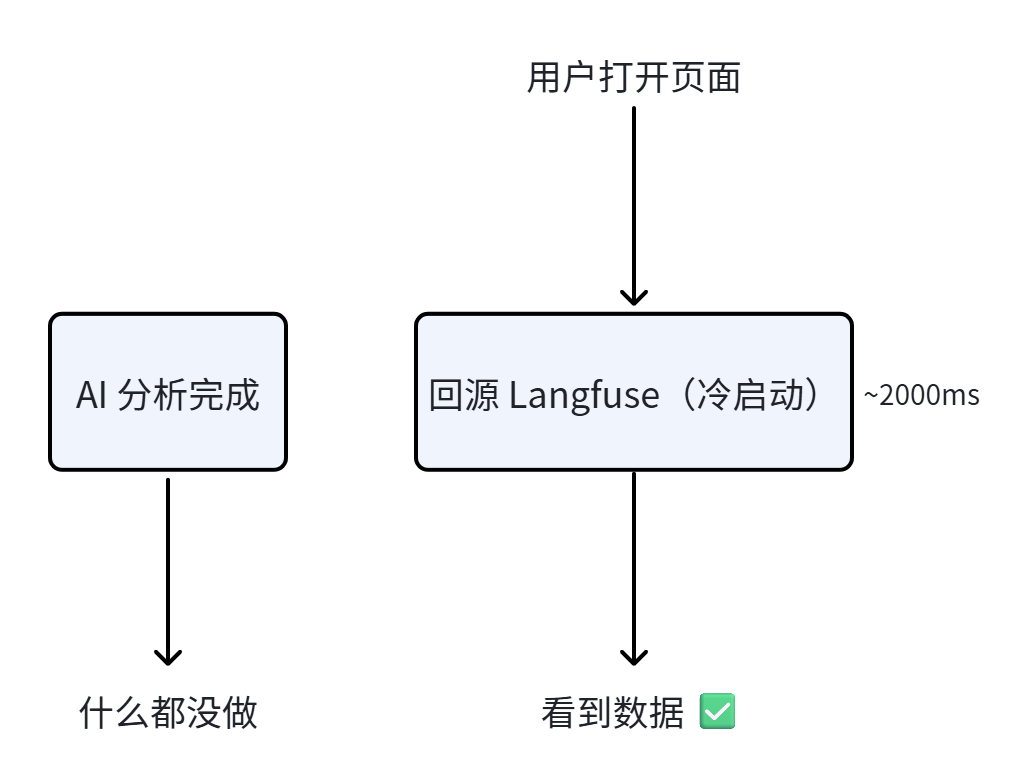
有预热:
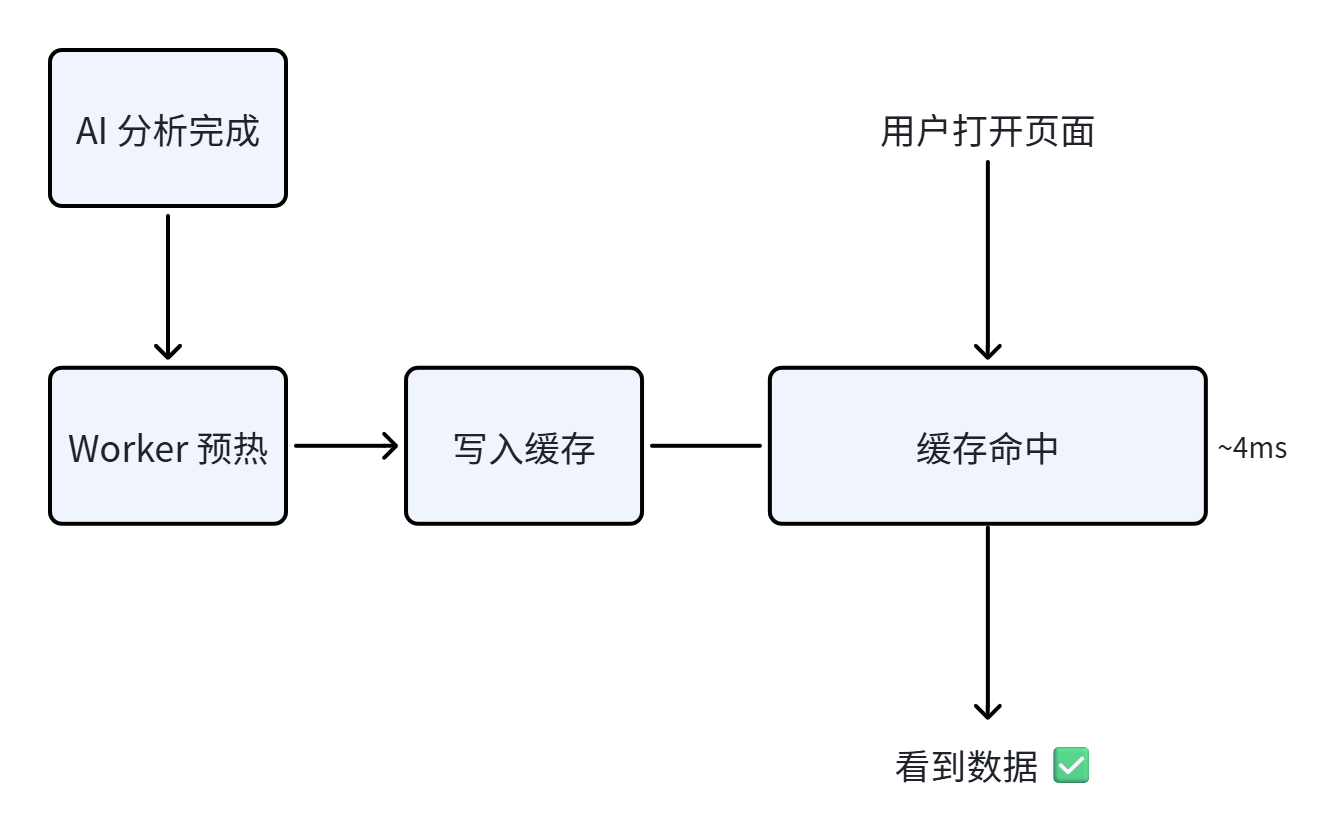
预热 Worker 在 AI 分析任务完成后,主动调用代理的强制刷新接口,把最新的 Trace 数据提前拉倒缓存里。
为什么用"强制刷新"而不是普通的"读取"接口?因为普通读取会先查缓存 --- 如果已有旧数据就直接返回,达不到预热最新 数据的目的。强制刷新会跳过缓存读取。
4.2 指数退避 + 死信队列
网络抖动、上游临时不可用是常态。Worker 的重试策略是重新发布消息实现延迟重试。
处理失败时:
如果 重试次数 >= 3 -> 投入死信队列,不丢消息
否则 -> 等待 5s * 2^ 重试次数 -> 发一条消息(带 +1 的重试次数)-> ACK 旧消息
为什么用重新发布而不是 nack{requeue-Ture}? 因为 nack 会立即重新投递,没法做延迟退避。通过"发一次消息 + ACK 旧消息"来实现间隔的重试。
4.3 trace_id 的确定性派生
Worker 拿到的是业务系统的 task_id ,需要推导出 Langfuse 里的 trace_id 。我们的做法是用 SHA-256 哈希 task_id ,取前 16 字节转成 32 位十六进制字符串作为 trace_id。
这个方案的好处:
- 零依赖:标准库即可完成,不需要引入 Langfuse SDK
- 确定性 :同一个 task_id 永远得到同一个 trace_id
- 需要约定:AI 分析服务在创建 Trace 时也用同样的算法,两边对齐
5 内存缓存的细节打磨
5.1 基于字节数的 LRU 淘汰
内存缓存的容量显示不是按条目数,而是按实际占用的字节数。写入时累加字节数,超出上线就从 LRU 端(最久未使用)开始淘汰,直到腾出足够的空间。单条数据如果超过整个缓存容量则直接跳过,不写入。
为什么不用条目数限制?看看 Langfuse 的实际数据分布就明白了:
|-------------|--------|--------------------------|---------------------|
| 淘汰策略 | 限制方式 | 800MB 空间能装多少 | 内存使用量 |
| 按条目数(1000条) | 固定条目上限 | 如果全是 1MB 大 Trace -> 爆内存 | 不可预测(5MB ~ 1000MB) |
| 按字节数(800MB) | 固定字节上限 | 大小混装,自动适配 | 始终 <= 800MB |
Langfuse 的 Trace 大小差异巨大:一条简单的 Generation 只有 5KB,一条 RAG 链路 Trace 可能1MB。按照条目数限制会导致内存使用量完全不可预测,而按字节数限制能确保内存使用始终在可控范围内。
5.2 asyncio 环境下不加锁的安全性
MemoryCache 内部的 OrderedDict 操作没有加 asyncio.Lock。这不是疏忽,是刻意为之。
Python asyncio 是单线程协作式多任务。OrderedDict 的**getitem** 、setitem 、popitem 等操作之间不包含 await ,因此在两个await 挂起点之前是原子的,无需加锁。
加锁反而引入无谓的开销和竞争。
6 透明代理:零成本改造
对于不需要缓存的请求(列表查询、写入操作等),代理使用 catch-all 路由直接头传到上游 Langfuse。这里有一个细节:HTTP 客户端库(如httpx)在收到 gzip 响应时会自动解压 ,但不会删掉 Content-Encoding:gzip 响应头。如果原样转发,浏览器会拿着一段明文尝试 gzip 解压,直接乱码。所以代理转发时需要手动剥离 Content-Encoding 等 hop-by-hop 头。
客户端只需把 Langfuse 的 Basic URL 修改即可,就可以实现 零代码改造
7 效果数据
|----------------|------------------|------------------------|
| 指标 | 优化前(直连 Langfuse) | 优化后(通过缓存代理) |
| 首次查询(冷启动) | 2000~5000ms | Worker 预热后 ~4ms |
| 重复查询(内存命中) | 2000~5000ms | ~0.5ms |
| 重复查询(Redis 命中) | 2000~5000ms | ~2ms |
| 上游压力(10人同时) | 10次请求 | 1 次请求(Per-Key 锁合并) |
| 带宽占用 | 原始JSON | 压缩约79% |
8 踩坑记录
8.1 redis.py 的 decode-responses 会损坏二进制文件
症状:存进去的 gzip 数据取出来后解压报错。
原因:decode_responses=True 把 gzip 字节当 UTF-8 解码了。
解法:双客户端,文本归文本,二进制归二进制。
8.2 httpx 自动解压但不删 Content-Encoding 头
症状:透明代理返回的数据,浏览器尝试 gzip 解压一段明文,乱码。
原因:httpx 已经把 gzip 解压了,但 content-encoding:gzip头还在。
解法:代理转发时手动剥离
8.3 分布式锁反而是累赘
最初实现了 Redis 的 SET NX EX + Lua 脚本的分布式锁来防止缓存击穿。后来发现,我们的代理实例各自有独立的内存缓存,每个实例只需要放自己的惊群就足矣。asyncio.Lock 完全胜任。 **分布式锁增加了网络往返和复杂性。**果断删掉
8.4 nack(requeue-True) 不能做延迟重试
症状:失败消息被立即重新投递,疯狂重试打爆上游。
原因:**nack{requeue=True}**没有延迟机制。
解法:重新发布一条带 x-retry-count 头的新消息 + ACK 旧消息 + asyncio.sleep实现退避
9 总结
这套方案的核心思想很简单:
- Langfuse 的 Trace / Observation 数据写入后几乎不变,适合激进缓存
- gzip 全链路透传,缓存命中时 CPU 开销趋近于零
- Per-Key 锁,防击穿的同时不牺牲并发
- 预热 Worker,让让"第一次查也快"成为可能
- 透明代理, 客户端零改造
如果你的团队也在用 Langfuse,并且遇到了查询性能问题,这套方案可以直接参考。