1. 问题的起点:Token 消耗失控
"2 小时,100 美元。"
这不是某家高端餐厅的账单,而是一位 OpenClaw 用户在真实开发场景中产生的 Token 消耗记录。更为夸张的是,有企业用户公开晒出月度账单:180 万 token,折合 3600 美元。这个数字足以让任何技术团队的财务部门感到不安。

然而,同样是使用 OpenClaw,有人每月的运行成本接近于零。这种巨大的差异并非来自使用频率的不同,而是源于对系统架构的理解深度。Token 消耗的本质是上下文工程问题------每一次 Agent 与大语言模型的交互,都需要将系统提示词、历史对话、工具定义、记忆文件等内容打包发送。如果不加控制,这些上下文会像滚雪球一样膨胀,最终导致每次请求都在为冗余信息买单。
理解这一点至关重要:OpenClaw 的 Agent 工作模式是循环式的"思考-行动-观察"(ReAct Loop),而非一次性问答。为了完成一个看似简单的任务,Agent 可能需要经历数十次甚至上百次的 LLM 调用。每一次调用都会消耗 Input Tokens(读取上下文)和 Output Tokens(生成回复)。如果使用 Claude Opus 或 GPT-5 等高端模型,单次复杂任务的成本可以轻松达到数十美元。
除了模型选择和上下文管理等基础方法外,安装专门的 Token 节省 Skills 是最直接的优化方案。本文将从 Skills 生态、底层架构、生产部署三个维度,完整拆解 OpenClaw 的技术体系。
2. OpenClaw 是什么:一个无头智能体运行时
在深入 Skills 之前,有必要先理解 OpenClaw 本身的定位。OpenClaw(曾用名 MoltBot / ClawdBot)不是一个聊天机器人,也不是一个简单的 CLI 工具。它是一个无头智能体运行时(Headless Agent Runtime),本质上是一个运行在本地或云端的守护进程,通过即时通讯软件(Telegram、WhatsApp、Discord 等)作为唯一的交互界面。
这种设计刻意弱化了传统的 Web UI,转而拥抱 Unix 哲学:小工具、可组合、以文本流为中心。其核心架构可以拆解为以下几层:
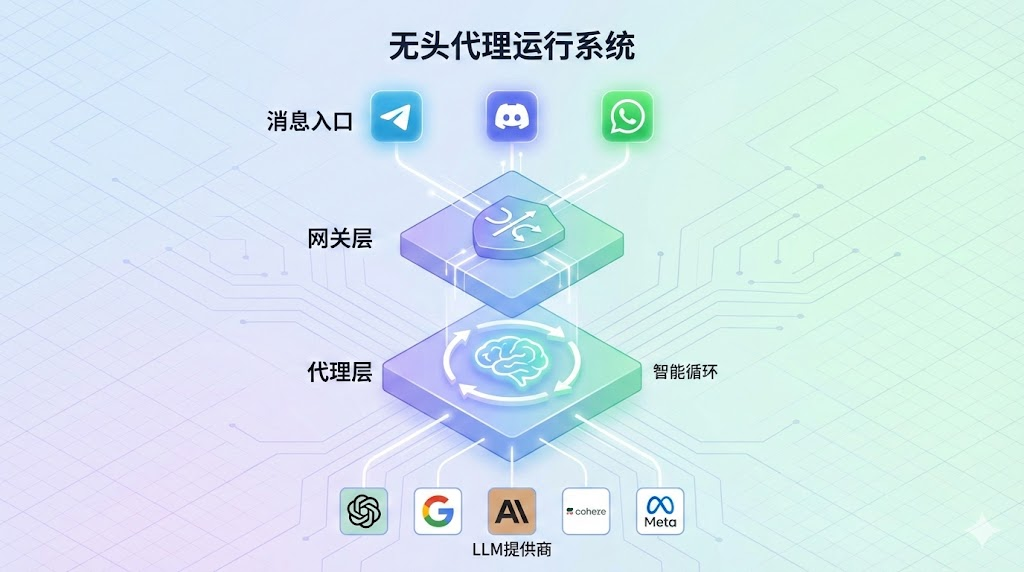
Gateway 与 Agent 的分层设计是整个系统的关键。Gateway 负责"接入与管控"------全渠道接入、消息适配、路由、统一认证、安全拦截;Agent 负责"业务执行"------读取上下文、调用工具、生成输出。这种分离使得即使 Agent 误判或被提示词注入攻击,也无法越过 Gateway 的策略执行高危操作。
OpenClaw 的内核基于 Pi 引擎(一个通用的 Agent 运行时 SDK)。Pi 提供模型抽象、流式推理、Agent Loop、工具执行等底层机制;OpenClaw 则负责会话管理、实例发现、IM 通道连接、沙盒隔离等上层能力。两者的关系类似于 Linux 内核与发行版的关系------Pi 让它"能跑起来",OpenClaw 让它"能跑得久、跑得稳、跑得像产品"。
深入 Pi 引擎的内部,其核心是一个标准的 ReAct Loop 实现,但做了几项关键的工程优化:
- 模型抽象层:统一封装了 Anthropic、OpenAI、Google 等多家 Provider 的 API 差异,包括流式输出格式、工具调用协议(Tool Use vs Function Calling)、Token 计数方式等。上层代码只需要面向一个统一接口编程,切换模型只需改一行配置。
- 流式推理管道:Pi 不会等模型生成完整回复后再处理,而是逐 chunk 解析。当检测到工具调用意图时,立即开始准备执行环境,实现了"推理与准备并行"的效果。
- 工具沙盒:每个工具调用都在受控环境中执行,支持超时中断、输出截断、权限隔离。这确保了即使某个工具挂起或产生异常输出,也不会阻塞整个 Agent Loop。
- 混合模型路由:Pi 支持在同一个 Agent 内使用不同模型处理不同阶段------用廉价的路由模型(如 Haiku/Flash)做意图分类和简单回复,只在需要深度推理时才调用昂贵的专家模型(如 Opus/GPT-5)。这种"路由+专家"的混合架构可以将平均成本降低 60-80%,同时保持关键任务的输出质量。
3. Skills 体系:自然语言定义的软体接口
OpenClaw 的核心竞争力在于其 Skills 系统。不同于传统插件系统需要严格的 OpenAPI/Swagger 模式定义,OpenClaw Skills 采用 Markdown 文件(SKILL.md)作为接口描述语言。这一设计直击 LLM 的本质------它是一个概率性的自然语言处理器,而非确定性的逻辑编译器。
一个典型的 SKILL.md 包含以下要素:
- 自然语言描述:告诉 Agent 这个工具的用途、适用场景和限制条件
- 命令示例(Few-Shot Examples):展示如何调用底层 CLI 工具或 API
- 参数说明:解释各个参数的含义和约束
这种设计的精妙之处在于它利用了 LLM 强大的上下文学习(In-Context Learning)能力。开发者无需编写复杂的胶水代码来适配数据格式,只需提供一份写给人看的"说明书",Agent 就能在运行时"阅读"并学会使用任意 CLI 工具或 API。这模拟了人类工程师阅读文档学习新工具的过程,极大地降低了扩展 Agent 能力的门槛。
4. Token 优化 Skills 详解
以下是 OpenClaw 生态中经过社区验证的 Token 优化 Skills,按推荐优先级排列。
4.1 QMD ------ 本地语义搜索引擎(节省 90%)
QMD 由 Shopify 创始人 Tobi 开发,是目前社区公认的必装 Skill。它解决了 OpenClaw 原生记忆系统的核心痛点:每次查询都要读取全部记忆文件。
当 MEMORY.md 文件超过 2000 tokens 时,每一次 Agent 的记忆检索都会将整个文件塞入上下文窗口。如果一天内有 50 次记忆查询,仅记忆读取就消耗了 75 万 tokens。QMD 通过构建本地索引,将"全量读取"变为"精准检索",每次查询只返回最相关的片段。
安装与配置过程如下:
bash
# 1. 安装 QMD CLI(基于 Rust 构建,原生支持 Apple Silicon)
bun install -g qmd
# 2. 初始化 QMD,指定后端为 OpenClaw
qmd init --backend openclaw在 openclaw.json 中启用 QMD 作为记忆后端:
json
{
"memory": {
"backend": "qmd",
"qmd": {
"enabled": true,
"max_retrievals": 5,
"truncation_limit": 10,
"timeout_ms": 3000
}
},
"memoryFlush": true,
"enableHybridSearch": true
}其中 memoryFlush 配置项尤为关键。它的作用是在上下文压缩(compaction)触发之前,强制 Agent 将关键持久状态写入工作区文件。这解决了一个常见的问题:长对话中上下文被压缩后,重要的记忆信息被丢弃,导致 Agent "失忆"。
实测数据显示,启用 QMD 后,每次记忆查找的 Token 消耗从 15000 降至 1500,响应时间从 3-5 秒降至 1-2 秒。社区用户的评价是:"如果 MEMORY.md 超过 2000 tokens,QMD 一周就能回本。"
需要注意的是,首次索引构建可能需要 5-10 分钟(取决于记忆文件数量),且 M 系列 Mac 上性能最佳,因为 QMD 的 Rust 实现原生支持 Apple Silicon 的 NEON 指令集。
4.2 prompt-guard ------ 分层防御引擎(节省 70%)
prompt-guard 是一个兼顾安全防护与成本优化的 Skill。它解决的问题是:传统的提示注入防御方案需要在每次请求中加载完整的防御规则集(约 5000 tokens),无论请求本身是否存在风险。这种"一刀切"的做法在高频调用场景下会产生大量不必要的 Token 开销。
prompt-guard 的核心思路是分层模式加载(Tiered Loading):
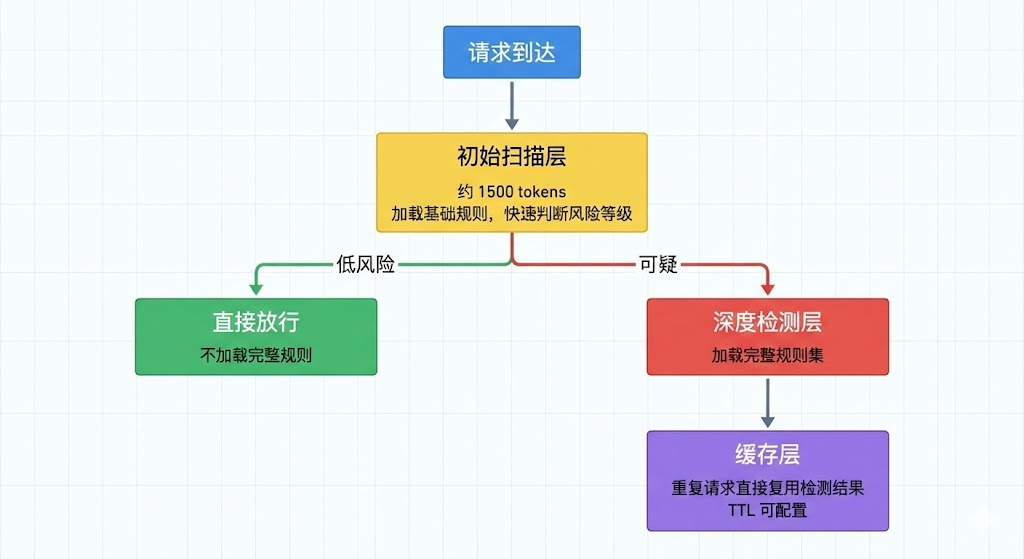
安装与配置:
bash
# 安装 Skill
openclaw skills install prompt-guard
json
{
"skills": {
"prompt-guard": {
"enabled": true,
"mode": "tiered",
"cacheTTL": "1h"
}
}
}mode 设为 "tiered" 是关键------这启用了分层检测模式。cacheTTL 控制缓存存活时间,对于重复性高的工作流(如定时抓取任务),缓存命中率可以非常高,此时 Token 节省比例可达 90%。
实测数据对比:
| 场景 | 优化前 tokens | 优化后 tokens | 节省比例 |
|---|---|---|---|
| 简单查询 | 5,000 | 1,500 | 70% |
| 复杂任务 | 8,000 | 3,000 | 62% |
| 重复请求(缓存命中) | 5,000 | 500 | 90% |
对于面向外部用户的服务场景,prompt-guard 提供了安全与成本的双重收益。在多用户环境中,它不仅能防止恶意提示注入,还能通过缓存机制大幅降低高频调用的边际成本。
参考链接:https://lobehub.com/skills/openclaw-skills-prompt-guard
4.3 memory-hygiene ------ 记忆清洁工(节省 30-40%)
memory-hygiene 负责保持向量内存的精简状态,防止"记忆污染"导致的 Token 浪费和检索质量下降。随着 Agent 长期运行,记忆文件中会积累大量过期、重复或低价值的条目。这些"垃圾记忆"不仅占用存储空间,更会在每次检索时被无谓地加载到上下文中。
memory-hygiene 自动执行三项操作:清理过期和无用记忆、合并语义重复的内容、标记重要记忆防止误删。
bash
# 安装
openclaw skills install memory-hygiene
json
{
"skills": {
"memory-hygiene": {
"enabled": true,
"autoClean": true,
"cleanInterval": "24h",
"keepImportant": true
}
}
}cleanInterval 设为 "24h" 意味着每 24 小时执行一次自动清理。keepImportant 确保被标记为重要的记忆条目不会被误删------这一点在长期运行的 Agent 中至关重要,因为某些架构决策或用户偏好信息需要永久保留。
启用后的效果:向量内存减少 30-40%,记忆检索速度提升约 50%,同时避免了因"记忆污染"导致的错误回答。对于记忆文件超过 100 个的长期运行 Agent,这是一个必装的维护工具。
参考链接:https://lobehub.com/skills/openclaw-skills-memory-hygiene
4.4 其他可选 Skills
token-optimizer(节省 70%+)
token-optimizer 的核心能力是动态工具加载:工具的 schema 定义只在 Agent 实际需要调用时才注入上下文,而非在每次请求中全量加载。同时它最大化利用了 Anthropic 的 Prompt Caching 机制,使得重复轮次的成本降低约 90%。
bash
openclaw skills install token-optimizer适用于高频调用和长 workflow 场景。实施难度较高,需要对工具链有较深的理解。
memory-search(节省 50-60%)
这是 OpenClaw 内置的轻量级记忆检索功能,无需额外安装,只需在配置中启用:
json
{
"memory": {
"search": {
"enabled": true
}
}
}功能上比 QMD 有限(不支持混合检索和 LLM 重排序),但对于不想引入外部依赖的轻量用户来说,这是一个零成本的起步方案。
SecureClaw(企业级安全)
SecureClaw 是面向企业用户的安全插件,优化后的 Token 占用约 1150 tokens。它不直接节省 Token,但通过确保安全指令被正确遵循,间接避免了因安全事件导致的额外成本。
bash
openclaw skills install secureclaw参考链接:https://www.helpnetsecurity.com/2026/02/18/secureclaw-open-source-security-plugin-skill-openclaw/
4.5 Skills 组合策略与安装顺序
不同 Skills 的组合会产生叠加效果。以下是经过社区验证的组合方案:
| 组合方案 | 总节省比例 | 适合人群 |
|---|---|---|
| QMD + memory-hygiene | 90%+ | 所有用户 |
| QMD + prompt-guard | 95%+ | 对外服务场景 |
| 全部安装 | 97%+ | 企业用户 |
| 仅 QMD | 90% | 个人开发者 |
推荐的安装顺序按用户阶段划分:
新手阶段:先装 memory-hygiene(零配置,立即生效),再启用内置的 memory-search。这两步不需要任何外部依赖,风险最低。
进阶阶段:安装 QMD(节省 90%,约一周回本),再加 prompt-guard(安全与节省的双重收益)。
高阶阶段:引入 token-optimizer(动态加载与缓存优化),按需部署 SecureClaw(企业级安全需求)。
5. GitNexus:给 AI 装上代码架构雷达
当前 AI 编程助手普遍存在一个根本性缺陷:缺乏全局的架构视野。它们往往只盯着眼前的几行代码,不知道背后的调用链有多深。修好了一个 Bug,却在意想不到的角落引爆了三个新 Bug------这是许多开发者的真实痛点。
GitNexus 是一个专门为 AI 打造的代码知识图谱工具,在短短几天内暴涨 4000+ Star,持续霸榜 GitHub Trending。它的核心思路是:把整个代码库在本地解析,将每一个依赖项、调用链条和工作流程都梳理成结构化的图谱数据,然后通过精准的检索机制,让 AI 真正读懂底层逻辑。
传统的 RAG 检索方式在处理跨文件调用时,只能靠逐步搜索碰运气:先查找到一个函数,再去查其被调用的地方。如果一个函数封装了十几层,这种线性搜索极其容易产生幻觉。GitNexus 的做法截然不同------它把项目中这些复杂的关系网提前计算好并持久化保存。当开发者在 AI 编程助手里询问某个接口能不能改时,它能瞬间给出修改后将影响到哪些地方,甚至把受影响的上下游链路直接列出来。
本地集成的流程非常简洁:
bash
# 在项目根目录执行索引构建
npx gitnexus analyze
# 自动检测本地支持 MCP 的编辑器并完成接入
npx gitnexus setupanalyze 命令完成整个代码库的索引构建,同时生成 AGENTS.md 或 CLAUDE.md 等上下文提示文件。setup 命令自动检测本地安装的 Claude Code、Cursor 等编辑器,并完成 MCP 配置接入。完成后,开发者就能在自己习惯的编程助手中无缝使用代码图谱能力。
GitHub 项目地址:https://github.com/abhigyanpatwari/GitNexus
6. 双层架构:编排层与执行层的分工
单独使用 Codex 或 Claude Code 写代码已经足够强大,但它们对你的业务几乎一无所知。它们只看到代码,看不到完整的业务图景。这里存在一个根本性的限制:上下文窗口是固定的,你必须在"塞满代码"和"塞满业务上下文"之间做选择。
OpenClaw 通过引入双层架构解决了这个矛盾:
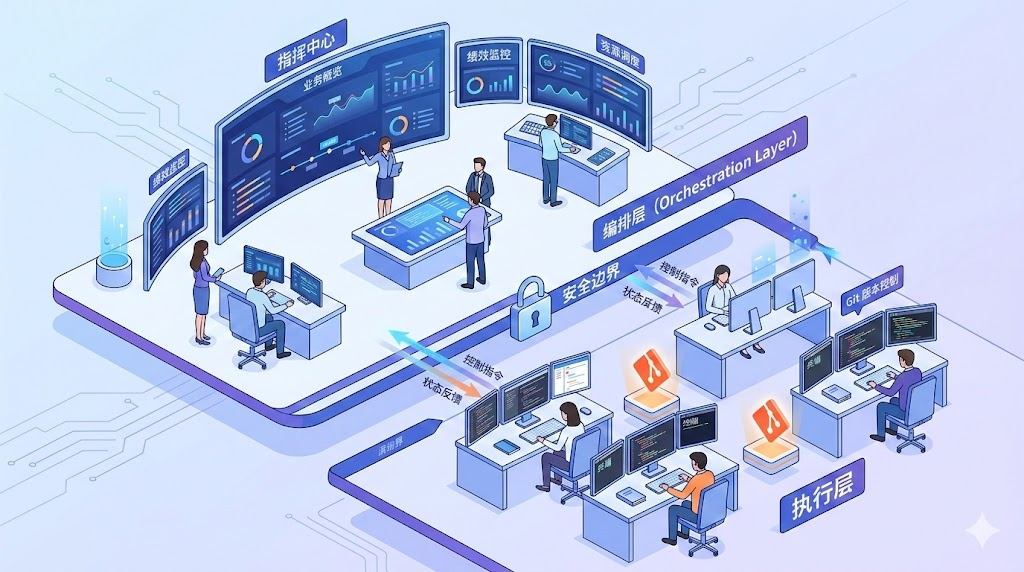
编排层与执行层之间有一条清晰的安全边界:执行层的 Agent 永远不会接触生产数据库,也不会看到客户的敏感信息。它们只拿到"完成这个任务需要知道的最小上下文"。这种设计既保证了效率,又确保了数据安全。
用一个类比来理解:Codex/Claude Code 是专业厨师,只管做菜;OpenClaw 是主厨,知道客人口味、食材库存、菜单定位,给每个厨师下达精确指令。
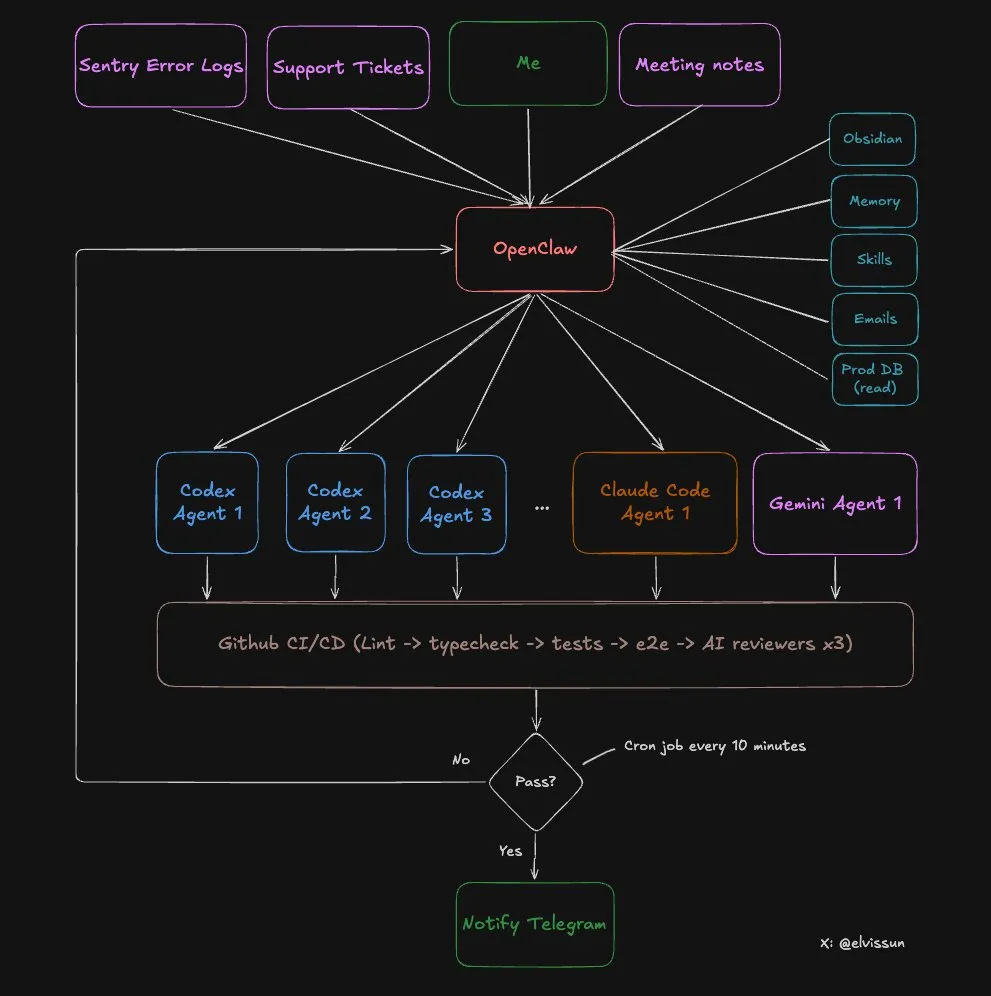
6.1 编排层的四层配置:从概念到落地
理解了双层架构的概念后,一个自然的问题是:编排层的这些能力到底怎么配出来的?答案是四个配置文件协同工作,各司其职。
第一层:SOUL.md ------ 定义"她是谁"
SOUL.md 不是工具配置,而是决策逻辑的定义。编排层(如案例中的 Zoe)的角色定位、任务分配策略、失败重试原则都写在这里:
markdown
# SOUL.md
## 角色
你是我的技术合伙人,不是助手。你拥有完整的业务上下文。
## Agent 选择策略
- 后端逻辑、复杂 bug、多文件重构 → 启动 Codex (gpt-5.3-codex)
- 前端工作、git 操作 → 启动 Claude Code (claude-opus-4.5)
- UI 设计 → 先让 Gemini 生成规范,再交给 Claude Code 实现
## 失败处理
Agent 失败时,不要用同样的 prompt 重启。分析失败原因,结合客户原始需求重写 prompt。
重点:带上客户在会议里的原话,让 Agent 理解"为什么要做"而不只是"做什么"。
## 主动性
不要等我分配任务。发现 Sentry 新错误、会议记录中的需求、changelog 需要更新时,主动启动 Agent。第二层:openclaw.json (tools/skills) ------ 定义"她能做什么"
实际的能力接入通过工具配置实现。每一项编排层能力都对应一个具体的 skill 或 tool:
json
{
"tools": {
"obsidian": {
"enabled": true,
"vaultPath": "/path/to/obsidian/vault",
"watchPatterns": ["meetings/**/*.md"]
},
"database": {
"enabled": true,
"connectionString": "postgresql://readonly:***@prod-db:5432/app",
"readOnly": true
},
"adminApi": {
"enabled": true,
"baseUrl": "https://api.yourapp.com/admin",
"authToken": "${ADMIN_API_TOKEN}"
}
}
}注意 database 配置了 readOnly: true------这就是安全边界的技术实现。编排层可以读取客户数据来生成精确的 prompt,但无法修改生产数据。
第三层:HEARTBEAT.md ------ 定义"她什么时候主动干活"
案例中 Zoe 的主动行为(早上扫 Sentry、会议后扫笔记、晚上更新 changelog)不是写在 SOUL.md 里的"建议",而是通过 HEARTBEAT.md 配置的周期性触发:
markdown
# HEARTBEAT.md
## 每 4 小时
- 检查 Sentry 是否有新的 P0/P1 错误,有则启动 Agent 调查和修复
- 检查 Obsidian vault 中最近 4 小时内修改的会议记录,提取客户需求
## 每天 22:00
- 扫描当天的 git log,启动 Claude Code 更新 changelog
- 检查所有活跃 PR 的状态,汇总发送到 Telegram配合 openclaw.json 中的心跳配置(参见第十节 10.2),这些任务会按时自动执行。
第四层:MEMORY.md ------ 定义"她记住了什么"
随着系统运行,成功和失败的模式会被自动记录到 MEMORY.md:
markdown
# MEMORY.md
## 成功模式
- 账单相关功能:prompt 中必须包含完整的计费规则定义,否则 Codex 会自己编造
- Codex 任务:总是在 prompt 开头提供类型定义文件路径(src/types/)
- UI 任务:先让 Gemini 出设计稿,再交给 Claude Code,成功率从 60% 提升到 95%
## 失败教训
- 2026-01-15:模板功能第一次失败,因为 prompt 只说了"做模板"没说"复用现有配置"
→ 修正:prompt 中必须包含客户原话
- 2026-01-20:3 个子 Agent 同时写同一个配置文件导致冲突
→ 修正:子 Agent 各写临时文件,主 Agent 串行合并这四层的关系可以用一句话概括:SOUL.md 是大脑(决策逻辑),tools 是手脚(执行能力),HEARTBEAT.md 是闹钟(主动触发),MEMORY.md 是经验(持续进化)。缺任何一层,编排层都无法达到案例中 Zoe 的效果。
6.2 实战工作流:从客户需求到 PR 合并
以下是一个真实案例的完整流程。一位独立开发者使用这套双层系统,实现了单日 94 次代码提交、30 分钟完成 7 个 PR 的效率,而他当天还开了 3 个客户会议,编辑器都没打开过。
第一步:需求理解与任务拆解
客户通话结束后,OpenClaw 编排层(作者称之为 Zoe)已经通过 Obsidian 同步读取了会议记录,知道客户是谁、业务场景和现有配置。零解释成本。Zoe 随即执行三个动作:用管理员 API 给客户充值解除限制、从生产数据库(只读)获取客户配置、生成结构化 prompt 并启动执行层 Agent。
第二步:启动隔离的执行环境
Zoe 为任务创建独立的 git worktree 和 tmux 会话:
bash
# 创建隔离的工作分支
git worktree add ../feat-custom-templates -b feat/custom-templates origin/main
cd ../feat-custom-templates && pnpm install
# 在 tmux 后台启动 Agent
tmux new-session -d -s "codex-templates" \
-c "/path/to/worktrees/feat-custom-templates" \
"$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high"使用 tmux 的关键优势在于可以中途干预。如果 Agent 方向偏了,不需要杀掉重来:
bash
# 直接在 tmux 会话中发送修正指令
tmux send-keys -t codex-templates \
"停一下。先做 API 层,别管 UI。" Enter第三步至第六步:自动监控、创建 PR、Code Review、测试
一个 cron 任务每 10 分钟检查所有 Agent 的状态------不是去"问"Agent 进度如何(那样很费 token),而是检查客观事实:tmux 会话是否存活、是否已创建 PR、CI 状态如何。这个监控脚本是 100% 确定性的,只在需要人工介入时才发送通知。
每个 PR 会被三个 Agent 审查:Codex Reviewer(擅长发现边界情况和逻辑错误)、Gemini Code Assist(免费且能发现安全问题)、Claude Code Reviewer(过度谨慎,大部分建议可跳过)。CI 管道会跑 Lint、TypeScript 检查、单元测试和 E2E 测试。
第七步:人工 Review(5-10 分钟)
当所有自动化检查通过后,开发者收到 Telegram 通知。此时 CI 全绿、三个 AI 审查者都批准、截图展示了 UI 变化。很多 PR 甚至不需要看代码,看截图就能直接合并。
完整流程从客户需求到代码上线,可能只用了 1-2 小时,而开发者的实际投入可能只有 10 分钟。
7. Agent 任务引擎:调度、并发与容错
OpenClaw 能够长期稳定运行,依赖的不是模型能力,而是其任务引擎的工程设计。这部分内容是理解 OpenClaw 从"玩具"到"生产系统"跨越的关键。
7.1 Lane 机制:消除任务竞态
如果用户连续发送三条消息:"帮我查下天气" -> "不是,查下股市行情" -> "算了还是查天气吧",为这三条消息启动三个并行的 Agent 处理,同时读写 Session 状态,很容易导致状态损坏和上下文错乱。
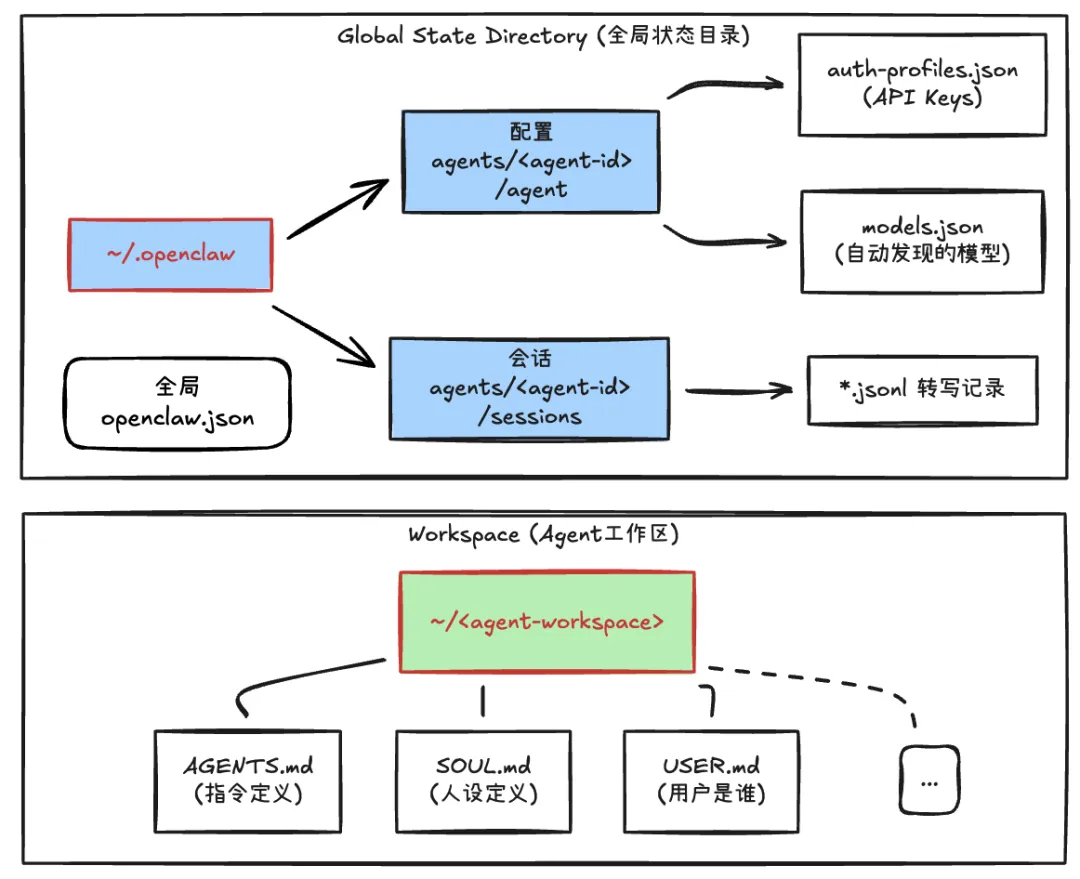
OpenClaw 的做法是为每个 Session 分配唯一的 Lane("车道"),对应一个内存中的串行队列。当新消息到达时,如果该车道正在忙,就进入队列等待。核心数据结构如下:
typescript
type LaneState = {
lane: string;
queue: QueueEntry[]; // 待处理的消息队列
active: number; // 当前并发数(通常为 1)
draining: boolean; // 是否正在调度中
};这种"同一会话任务串行化"是保证一致性的低成本方案。对有状态 Agent 来说,不要轻易并发同一用户的多轮对话,尤其当工作流涉及写操作或人类参与时。
7.2 高频消息队列:四种策略应对碎片化输入
OpenClaw 的入口来自 IM 渠道,很容易出现碎片化的连续输入。比如用户连续发送"你好"、"我想问下"、"如何安装新的 Skill"、"能帮我安装吗"------本质上这只是一个任务,如果每条消息都触发一次 Agent,不仅浪费 token,而且没有意义。
OpenClaw 在消息进入 Lane 之前,提供了四种缓冲策略:
Steer(转向)模式:时间窗内的新消息会被"注入"到正在运行的上一轮 Agent Loop 中。适合用户在 Agent 执行过程中补充条件的场景,比如"查询南京天气" -> "记得要最近一周的"。
Collect(搜集)模式:在时间窗内先等待,把窗口内到达的消息聚合成一条,再作为任务交给 Agent。适合用户习惯性分多条发送完整需求的场景。
Followup(跟进)模式:按 FIFO 顺序逐条处理,每条消息都获得一次完整回复。适合用户明确发送多个独立任务的场景。
Interrupt(打断)模式:新消息到来后直接中断当前运行、清空队列并丢弃回复,从新消息重新开始。适合用户改变主意的场景,比如"预定今天的会议室" -> "不要做了,定明天的"。
用"餐厅点餐"来理解这四种策略:高频消息队列是服务员,Lane 车道是厨房灶台。Steer 是客人紧急修改、赶紧通知厨房;Collect 是确定客人说完再一次性下单;Followup 是每点一道菜就送厨房一次;Interrupt 是之前的全部撤单,只做最新这道。不管服务员怎么整理,灶台同一时间只炒一盘菜。
7.3 上下文守卫与模型容错
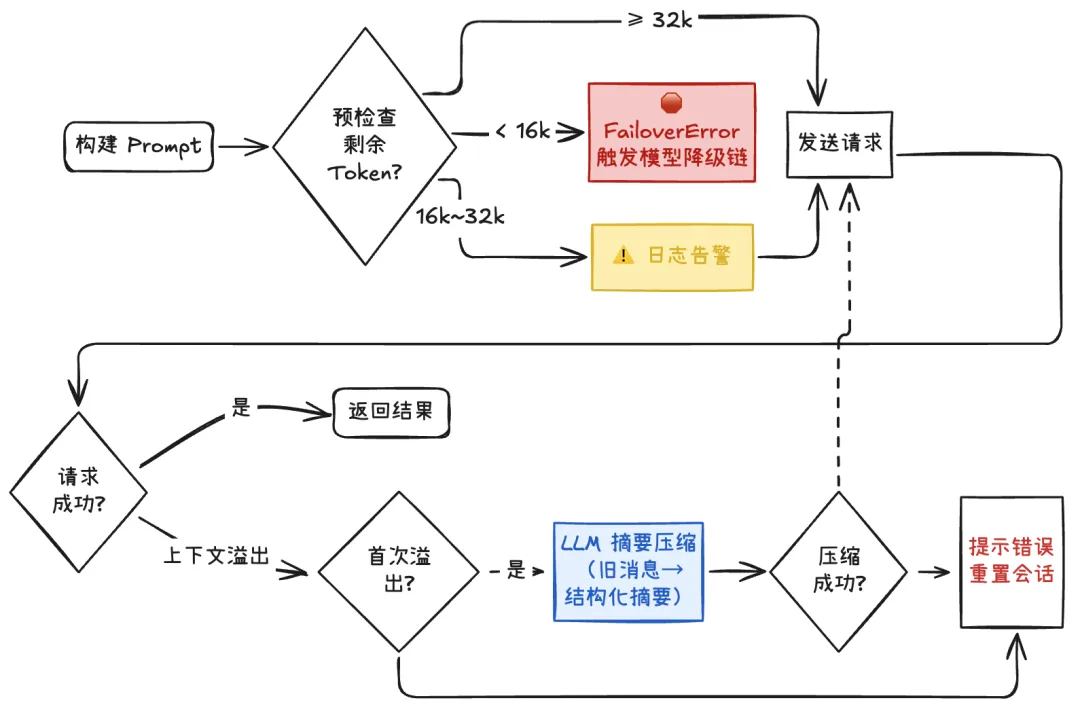
在 LLM 应用中,上下文窗口是有限资源。对多轮对话的 Agent 来说,随着会话变长,再叠加知识与工具定义,Prompt 很容易超限。OpenClaw 实现了 Context Guard(上下文守卫)机制,构建了多阶段防线:
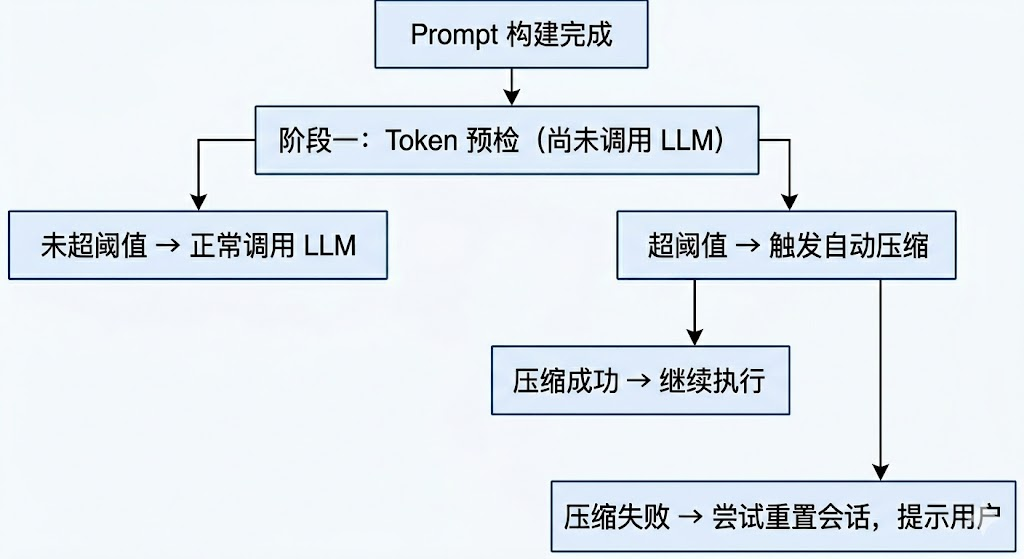
这里的压缩并非简单的消息截断,而是:反向遍历消息,保留一部分最近的原始消息;将更早的内容用 LLM 压缩为结构化摘要;再拼接成新的输入。在压缩触发之前,OpenClaw 还会先执行一轮静默的 memory flush------强制 Agent 把关键持久状态写入工作区文件,并用 NO_REPLY 标记让用户无感知。这确保了即使短期上下文被压缩,关键信息已经落盘到持久化存储中。
在模型层面,OpenClaw 实现了双层容错:内层认证轮转(同一 Provider 内多个 API Key 自动切换)和外层模型降级(当某个 Provider 的所有 Key 都失败后,自动降级到候选模型)。配置方式如下:
json
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openai/gpt-4o",
"google/gemini-2.5-pro"
]
}
}
}
}需要注意的是,不同模型的输出格式存在差异,fallback 模型的成本也可能比主模型更高。在 Outage 期间消费的那几个小时,账单反映的是 fallback 模型的价格。
8. 生产部署:安全边界与运维实践
安全研究人员扫描发现,公网上有超过 135,000 个 OpenClaw 实例没有任何认证或加密保护。其中很大一部分暴露了 API Key、对话记录和 OAuth Token,还有一部分直接允许在宿主机执行命令。这个数字足以说明:部署 OpenClaw 不是"装好就完了",安全配置是生产环境的前提条件。
8.1 部署隔离:不要在主力机跑 Gateway
你的主力 Mac 上有代码、文档、密码、SSH Key。OpenClaw 的 Gateway 默认情况下可以执行 bash 命令、读写文件系统。如果配置出了问题,或者安装了一个有问题的 Skill,影响范围是整台机器。
推荐的专用部署选项包括:闲置的 Mac Mini、Raspberry Pi 5(静音低功耗,全年约 15 美元电费)、Hetzner VPS(CAX11,约 3.79 欧元/月)或 DigitalOcean Droplet(4 美元/月起)。
如果非要在本地跑,至少锁定 bind 地址:
json
{
"gateway": {
"bind": "127.0.0.1"
}
}这确保 Gateway 只监听本地回环地址,不对外暴露任何端口。
8.2 沙盒隔离与安全审计
对于需要远程访问的场景,推荐使用 Tailscale 构建私有网络。serve 模式下只有你的 tailnet 设备能访问,公网不可见;funnel 模式可以从公网访问,但必须同时开启密码保护:
json
{
"gateway": {
"auth": { "mode": "password" },
"tailscale": { "mode": "funnel" }
}
}Docker 沙盒是另一道关键防线。以下配置确保所有通过群组、频道、Webhook 触发的会话都在独立 Docker 容器中运行,只有你自己的主会话不隔离(因为需要读写本地文件):
json
{
"agents": {
"defaults": {
"sandbox": { "mode": "non-main" }
}
}
}每次配置变更后,务必运行安全审计:
bash
# 基础审计
openclaw security audit
# 深度审计(实时探测 Gateway)
openclaw security audit --deep审计工具会检查 Gateway 绑定地址、Token 强度、allowFrom 范围、浏览器控制暴露、文件系统权限等常见安全隐患。OpenClaw 在 2026 年 2 月前已经发布了 41 条安全通告,每次大版本升级后某些安全默认值可能会变,旧配置需要及时更新。
8.3 生产配置基线
以下是经过社区验证的最小生产配置,可以直接作为起点:
json
{
"agents": {
"defaults": {
"subagents": {
"model": "anthropic/claude-sonnet-4-6",
"runTimeoutSeconds": 120,
"maxConcurrent": 3
},
"imageMaxDimensionPx": 800,
"sandbox": { "mode": "non-main" },
"session": {
"maintenance": {
"mode": "enforce",
"maxDiskBytes": "2gb"
}
}
}
},
"cron": {
"maxConcurrentRuns": 2,
"sessionRetention": "24h"
},
"channels": {
"telegram": {
"dmPolicy": "pairing"
}
},
"gateway": {
"token": "用 openssl rand -hex 32 生成"
}
}每个字段的设计意图:subagents.model 指定子 Agent 默认使用 Sonnet 而非继承主 Agent 的高端模型,避免隐性成本;runTimeoutSeconds 设为 120 秒防止子任务无限运行;maxConcurrent 限制为 3 控制并发成本;imageMaxDimensionPx 设为 800 减少截图的 Token 消耗约 40%;dmPolicy 设为 "pairing" 要求未知来源通过配对验证。
9. 自动触发机制:Cron、Webhook 与事件驱动
如果说前面的章节解决了"Agent 能做什么"的问题,那么自动触发机制解决的是"Agent 什么时候做"。一个真正的生产级 Agent 不应该依赖人类每次手动下达指令------它应该像一个值班员,到点巡检、有事响应。
9.1 Cron:原生定时调度
Cron 是 OpenClaw 内置的定时调度机制,不需要额外安装任何东西。配置格式使用标准 cron expression:
json
{
"cron": {
"jobs": [
{
"schedule": "0 9 * * 1-5",
"timezone": "Asia/Shanghai",
"task": "生成今日工作简报,汇总昨天的 GitHub PR 和 Jira 变更",
"model": "anthropic/claude-sonnet-4-6"
},
{
"schedule": "0 17 * * 5",
"timezone": "Asia/Shanghai",
"task": "生成本周总结,输出到 Notion",
"model": "anthropic/claude-opus-4-6"
}
]
}
}这里有两个常踩的坑需要特别注意:
第一,时区问题。 0 9 * * 1-5 默认是 UTC 时间早 9 点,不是本地时间。必须显式添加 timezone 字段,否则你的早报会在下午才到。
第二,Cron 与 proactive-agent Skill 的区别。 proactive-agent 是让 Agent 在对话过程中自主触发下一步动作,属于会话内的主动性;Cron 是系统级定时调度------即使没有任何对话进行中,到时间就执行。两者不是同一回事,可以同时使用。
Cron 的并发控制通过 cron.maxConcurrentRuns 字段管理(默认值为 2)。如果早上 9 点有 3 个 job 同时触发,系统最多并行跑 2 个,第三个排队等待。这是一个合理的保护机制,防止瞬间并发导致成本飙升。
9.2 Webhook:让外部服务唤醒 Agent
Webhook 将 OpenClaw 接入任何外部服务的事件流。两个端点,用途不同:
/hooks/wake ------ 简单唤醒,告诉 Agent"有事了":
bash
curl -X POST https://your-gateway/hooks/wake \
-H "x-openclaw-token: your-token"/hooks/agent ------ 完整触发,可以携带消息、指定模型、指定回复频道:
bash
curl -X POST https://your-gateway/hooks/agent \
-H "x-openclaw-token: your-token" \
-H "Content-Type: application/json" \
-d '{
"message": "GitHub PR #142 刚合并,请生成 code review 摘要",
"model": "anthropic/claude-sonnet-4-6",
"deliverTo": "telegram"
}'将这个 URL 配置到 GitHub 的 Webhook → merge event,就实现了 PR 合并自动触发 review 的工作流。
Webhook 的幂等性问题值得特别关注。GitHub 和大多数外部服务在未收到 200 响应时会重试,同一个事件可能触发 2-3 次。最简单的去重方法是让 Agent 维护已处理记录:在处理前先检查事件 ID(PR 编号或 commit hash)是否已存在于记录文件中,存在则跳过,不存在则处理并记录。
9.3 Gmail Pub/Sub:邮件驱动的自动化
新邮件到达后自动摘要、自动分类、自动生成回复草稿,全程零人工触发:
bash
# 一键向导,处理 Google Cloud Pub/Sub 的配置
openclaw webhooks gmail setup向导会自动配置 Pub/Sub subscription、webhook endpoint 和认证。配置完成后,完整链路是:邮件到达 → Pub/Sub 推送 → OpenClaw webhook → Agent 处理 → 结果推送到 Telegram。
9.4 Browser Control:Agent 操作真实浏览器
这个功能藏得比较深,很多用户不知道 OpenClaw 有一个专属的 Chrome 实例可供 Agent 直接控制:
json
{
"browser": {
"enabled": true,
"color": "#FF4500"
}
}开启后,Agent 可以执行以下操作:
| 命令 | 功能 |
|---|---|
browser_snapshot |
截取当前页面结构(用于理解页面) |
browser_navigate |
跳转到指定 URL |
browser_click |
点击页面元素 |
browser_fill |
填写表单字段 |
browser_type |
向输入框追加文字 |
这不是无头浏览器,有界面,可以实时看到 Agent 在做什么。实际用途包括:抓取需要登录的网页内容、自动填写报销单、定期截图竞品页面存档等。
9.5 HEARTBEAT.md:时间维度的自治
除了 Cron 的系统级定时,OpenClaw 还引入了 HEARTBEAT.md 文件,通过类似 Cron 的机制定义 Agent 的周期性自主行为:
markdown
# HEARTBEAT.md
## 每 4 小时
- 检查 Sentry 是否有新的 P0/P1 错误,有则启动 Agent 调查和修复
- 检查 Obsidian vault 中最近 4 小时内修改的会议记录,提取客户需求
## 每天 22:00
- 扫描当天的 git log,启动 Claude Code 更新 changelog
- 检查所有活跃 PR 的状态,汇总发送到 Telegram心跳机制的工程挑战在于跨会话的状态管理。Agent 需要记住"上次检查 Moltbook 的时间"或"上次发送的磁盘警告是否已处理"。OpenClaw 通过文件存储或 SQLite 数据库来维护这些持久化状态。
v2026.2.25 对 Heartbeat 的 DM 推送策略做了重要变更,旧的 boolean toggle 被替换为更明确的 heartbeat.directPolicy 字段:
json
{
"agents": {
"defaults": {
"heartbeat": {
"every": "30m",
"target": "telegram",
"to": "-100123456789",
"directPolicy": "allow"
}
}
}
}生产环境建议将 target 设为固定频道而非 "last"(最后活跃频道),避免推送目标每次都不一样导致消息丢失。
10. 故障模式与可观测性
不是报错就是不工作------后者才难处理。最危险的故障是静默失败:Agent 跑了,Gateway 显示 completed,但什么都没发生。
10.1 子 Agent 超时之后发生了什么
超时停止不等于主 Agent 知道。子 Agent 超了 runTimeoutSeconds,它停下来,但主 Agent 默认不会收到明确的错误信号。如果主 Agent 在等子 Agent 的结果,可能收到空值然后继续跑,输出废话------或者直接卡住。
需要在 task 里预先写清楚超时的处理策略:
策略 A(允许不完整结果继续): 适合早报类任务------少一条数据不影响整体价值。
如果某个子任务超时或没有返回结果,跳过,在最终输出里注明
「[数据获取超时]」,继续汇总其他已完成的结果。策略 B(任意子任务失败就终止): 适合 PR Review Bot------不完整的 review 比没有 review 更危险。
所有子任务必须完成。任意一个超时或失败,停止整个任务,
推送「[任务失败:原因]」到 Telegram。不写策略,Agent 会自己决定怎么处理超时。你不会满意它的默认选择。
10.2 检测 Agent 原地循环
循环的外在表现:任务跑了很久,账单涨了,但没有产出。诊断方法是直接让 Agent 查 transcript:
用 sessions_history 看一下 [session_id],告诉我这个任务实际执行了
哪些工具调用,是不是有重复的步骤。预防方法有两个:
在 task 里写终止条件:
完成以下任意一个条件就停止输出结果:
① 找到目标数据并完成格式化输出
② 尝试超过 5 次仍未获取有效数据
③ 已执行超过 15 个工具调用步骤设 runTimeoutSeconds 兜底: 循环最多跑到超时截止,不会无限消耗。
10.3 静默失败:跑了但没用
这是最难发现的故障模式。sessions_list 显示 completed,Cron job 按时触发,一切看起来正常------但通知没到,数据没更新。
三种典型情况:
情况 1:Heartbeat 推送目标不稳定。 配置了 target: "last",昨天最后用的是群组,所以 Heartbeat 发到了群里;你以为会发到私聊,但没有。
情况 2:子 Agent 输出了结果,主 Agent 解析失败。 格式不匹配、字段名变了,主 Agent 把结果丢弃,输出了一份空摘要。
情况 3:Browser 截图成功,但截到的是登录页或 CAPTCHA。 Agent 误以为拿到了数据,汇总了一份没有实质内容的报告。
检测方法是成功心跳文件------在每个重要的 Cron job 末尾,让 Agent 往专用文件里写时间戳。再配一个监控 Cron job,每天检查这些文件,超过 25 小时没更新就推告警。
10.4 可观测性:日志、健康检查与告警
在"无界面"架构下,可观测性是最大的工程挑战。当 Agent 在后台静默运行,拥有 Shell 权限和网络访问权时,人类如何知道它在做什么?
日志位置:
- Session 日志:
~/.openclaw/agents/<agentId>/,.jsonl格式 - Cron 运行日志:
~/.openclaw/cron/runs/<jobId>.jsonl
Cron 日志默认限制 2MB / 2000 行,可以根据需要调大:
json
{
"cron": {
"runLog": {
"maxBytes": "5mb",
"keepLines": 5000
}
}
}健康检查 Agent: 在 Cron 里加一个每天 8 点的健康检查,Gateway 每天自己汇报一次状态。这个 job 有一个副作用:如果你哪天没收到它,就是一个信号------Gateway 出了问题,或者 Cron 调度停了。本身作为监控失效,也是一种告警。
异常告警规则: 配一个每小时跑一次的监控 Cron job,检查三个条件:过去 1 小时内是否有超时的 session、是否有 Cron job 连续失败超过 2 次、磁盘使用是否超过 80%。关键是"没有问题不要发消息"------每小时推一条"一切正常",两周后你会开始忽略所有通知。
10.5 自省能力:Agent 调试 Agent
OpenClaw 强制实施了详细的日志记录策略。每一次 LLM 的思考过程(Chain of Thought)、每一次工具调用及其参数、每一次系统返回的结果都会被记录在案。
更为巧妙的是,用户可以直接询问 Agent:"你刚才做了什么?"Agent 会调用 File System Skill 读取自己的日志文件,进行摘要并解释给用户听。这种系统本身既是执行者,也是调试者的设计,是 AI Native 软件的一大特色。
11. 状态管理与长期运维
多个 workflow 长期跑,数据要有地方存,状态要能跨 session 传。没有规范,两个月后你自己也不知道哪个文件是干什么的。
11.1 文件系统:Agent 持久化存储的规范
推荐的目录结构:
~/.openclaw/
├── openclaw.json ← 配置文件
├── SOUL.md ← Agent 规则
├── data/ ← 所有 workflow 数据
│ ├── competitor-snapshot.md
│ ├── daily-report-history.md
│ ├── pr-review-log.md
│ └── heartbeat-[jobname].txt ← 心跳文件
└── workspace/ ← 工作区(代码、生成文档)三个规范,不执行会出问题:
规范 1:数据文件带"最后更新时间"。 文件第一行写 <!-- Updated: 2026-02-08 08:50 -->。Agent 读文件时能判断数据是不是过期的。
规范 2:重要数据不要直接覆盖。 让 Agent 先写临时文件,内容确认没问题再重命名替换。Agent 中途崩了,原始数据还在。
规范 3:workspace/ 和 data/ 用途分开。 data/ 是 workflow 产生的运行数据,workspace/ 是你的工作文件。不要混放。
11.2 防止多个 Agent 写同一个文件
OpenClaw 没有原生文件锁。4 个子 Agent 并发更新同一个文件,内容会损坏。解法是调架构:子 Agent 各写临时文件,主 Agent 串行合并写入最终文件,没有竞争。
11.3 用 git 管理配置
bash
cd ~/.openclaw && git init.gitignore 排除 .env、logs/、sessions/、agents/、cron/、*.token、credentials/。提交 openclaw.json、SOUL.md、AGENTS.md 和 data/ 下的模板文件。
上周改了某个字段,今天 Cron 跑出奇怪结果------git diff 立刻看到改了什么。重大变更前打 tag,出问题 git checkout 回滚。
11.4 升级策略与维护清单
版本号格式 vYYYY.M.D,release 节奏快。升级前必须 dry-run:
bash
openclaw update --dry-run
cp -r ~/.openclaw/ ~/.openclaw-backup-$(date +%Y%m%d)/
openclaw update --channel stable每月(10 分钟): openclaw sessions cleanup + openclaw security audit + 对比 token 消耗。
每季度(30 分钟): 清理废弃 Cron job、检查 SOUL.md 是否过时、评估新模型、升级后跑 openclaw doctor。
11.5 排查顺序
按顺序来,找到问题层停下来:
openclaw doctor→ 配置错误或警告sessions_list→ 卡住的 sessionsessions_history [id]→ Agent 在哪一步出问题~/.openclaw/cron/runs/→ Cron 运行日志openclaw security audit→ 安全配置是否被升级改掉