文章目录
- 1、前言
- 2、3分钟快速修复
-
- [2.1 找到配置文件](#2.1 找到配置文件)
- [2.2 问题就在这里](#2.2 问题就在这里)
- [2.3 改成正确的值](#2.3 改成正确的值)
- [2.4 重启生效](#2.4 重启生效)
- [3、问题分析:OpenClaw 怎么判断"该压缩了"](#3、问题分析:OpenClaw 怎么判断"该压缩了")
-
- [3.1 上下文窗口 = 龙虾的"工作桌面"](#3.1 上下文窗口 = 龙虾的"工作桌面")
- [3.2 maxTokens = 龙虾每次回复能占多少空间](#3.2 maxTokens = 龙虾每次回复能占多少空间)
- [3.3 压缩的触发计算](#3.3 压缩的触发计算)
- 4、深入拆解:默认值太小为什么会出问题
-
- [4.1 OpenClaw 不会自动感知你的模型能力](#4.1 OpenClaw 不会自动感知你的模型能力)
- [4.2 默认值过小会发生什么](#4.2 默认值过小会发生什么)
- [4.3 maxTokens 过小的连锁反应](#4.3 maxTokens 过小的连锁反应)
- [4.4 两个值同时偏小------双倍放大问题](#4.4 两个值同时偏小——双倍放大问题)
- 5、还有哪些配置在影响压缩行为
-
- [5.1 compaction 模式](#5.1 compaction 模式)
- [5.2 contextPruning(上下文修剪)](#5.2 contextPruning(上下文修剪))
- 6、为什么这么多人踩坑
- 7、总结
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
用 OpenClaw(社区昵称"龙虾")的朋友,大概率遇到过这种场景:
你接入了自定义模型,正跟龙虾聊得火热,让它帮你改代码、读文件、做分析,没聊几轮,突然------
⚠️ 上下文已压缩
然后你发现:
- 之前给它看过的文件内容,它不记得了
- 刚讨论过的方案,它忘了
- 你让它接着干活,它一脸茫然从头问你
你的龙虾"失忆"了。
更奇怪的是:明明你用的模型本身支持超大上下文窗口(比如 128K、甚至 1M),按道理不该这么快就满。为什么才聊几轮就压缩了?
原因就藏在 ~/.openclaw/openclaw.json 里------两个你可能完全没注意到的参数,默认值太小了。
本文带你用 3 分钟定位问题,改两个数字,从此告别龙虾失忆。
2、3分钟快速修复
如果你赶时间,先跟着做,改完立刻见效。原理后面再看。
2.1 找到配置文件
打开终端,查看你的 OpenClaw 配置:
bash
cat ~/.openclaw/openclaw.json找到你自定义模型提供商下的模型配置,关注这两个字段:
json
{
"id": "your-model-id",
"contextWindow": ...,
"maxTokens": ...
}2.2 问题就在这里
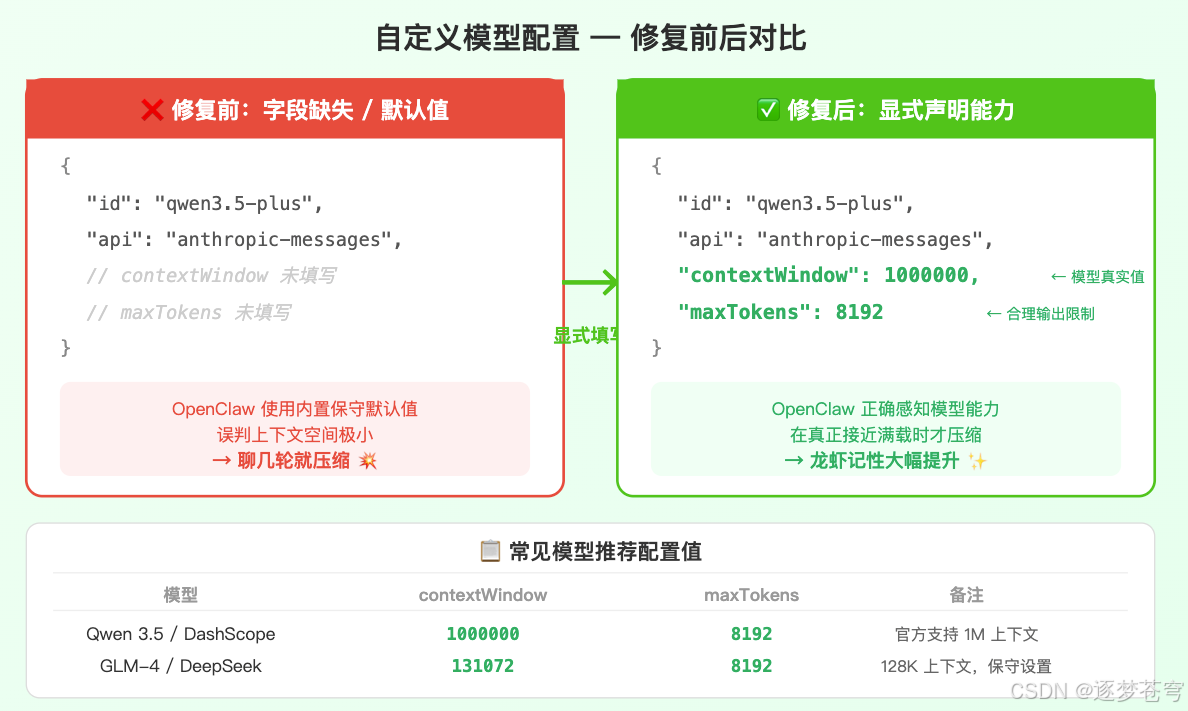
如果你的自定义模型配置里这两个字段:
- 缺失(没有填写,依赖 OpenClaw 的内部默认值)
- 或者数值很小(比如 contextWindow 只有几千、maxTokens 只有几百到一两千)
那就找到原因了。
OpenClaw 会以这两个值为依据判断"上下文快满了,该压缩了"。如果这两个值远小于你的模型实际能力,龙虾就会在空间明明还大得很的情况下,就开始提前压缩。
2.3 改成正确的值
根据你的模型实际能力,显式地在配置里写上正确的值:
json
{
"id": "your-model-id",
"api": "anthropic-messages",
"contextWindow": 1000000,
"maxTokens": 8192
}常见模型参考配置:
| 模型 | contextWindow | maxTokens | 说明 |
|---|---|---|---|
| Qwen 3.5 系列(DashScope) | 1000000 | 8192 | 官方支持 1M 上下文 |
| MiniMax-M2.5 | 1000000 | 8192 | 官方支持超长上下文 |
| GLM-4 系列 | 131072 | 8192 | 128K 上下文 |
| DeepSeek V3/R2 | 131072 | 8192 | 128K 上下文 |
原则:填写模型实际支持的值,不要留空,不要用默认值。
2.4 重启生效
修改保存后,重启 OpenClaw 即可。
改完你会发现:龙虾终于能聊很久了,不再动不动就失忆。
接下来,我们深入聊聊:为什么这两个默认值这么关键?
3、问题分析:OpenClaw 怎么判断"该压缩了"
3.1 上下文窗口 = 龙虾的"工作桌面"
大语言模型没有无限的记忆。每次你发消息、它回复,所有对话内容都会被塞进一个叫 上下文窗口(Context Window) 的空间里。
你可以把它想象成龙虾面前的工作桌面------桌面就那么大,东西放多了,就得收拾。
contextWindow 这个参数,就是你告诉 OpenClaw:这个模型的桌面有多大。
3.2 maxTokens = 龙虾每次回复能占多少空间
maxTokens 是模型单次最大输出 token 数。OpenClaw 在计算"还剩多少上下文空间"时,会提前把 maxTokens 的空间预留出来留给下一次输出。
3.3 压缩的触发计算
OpenClaw 判断是否该压缩,依赖这个逻辑:
可用上下文空间 = contextWindow - maxTokens - 系统提示词 - 工具定义 - 安全余量当对话历史填满了这个"可用空间"的一定比例,就触发 compaction(压缩)------把之前的对话浓缩成摘要,释放空间。
这就是"失忆"的本质:不是真的忘了,是被迫做了一次"记忆精简"。

4、深入拆解:默认值太小为什么会出问题
4.1 OpenClaw 不会自动感知你的模型能力
这里有一个很多人没意识到的关键点:
OpenClaw 不会自动去问你的模型"你支持多大的上下文"。它只相信你在配置文件里告诉它的值。
当你通过自定义 Provider 接入国产模型(比如通过阿里云 DashScope 接入通义千问、MiniMax 等),你需要在配置里手动声明这个模型的能力边界。
如果你没有填写 contextWindow 和 maxTokens,OpenClaw 就只能用一个内置的保守默认值来估算------而这个默认值,往往比你模型的真实能力小得多。
4.2 默认值过小会发生什么
假设你的模型实际支持 1M 上下文,但 OpenClaw 默认只给它分配了一个很小的 contextWindow(比如 8192)。
那会发生什么?
- OpenClaw 心想:"这个模型桌面很小,得小心着用。"
- 你刚聊了 3 轮,用了 5000 token,OpenClaw 一算:"已经用了 60% 了,快满了!"
- 立即触发压缩。
- 你完全莫名其妙------模型明明有 1M 的上下文,才聊了几句就被压缩了?
而实际上,你的模型桌面大得很,根本没满,只是 OpenClaw 以为满了。
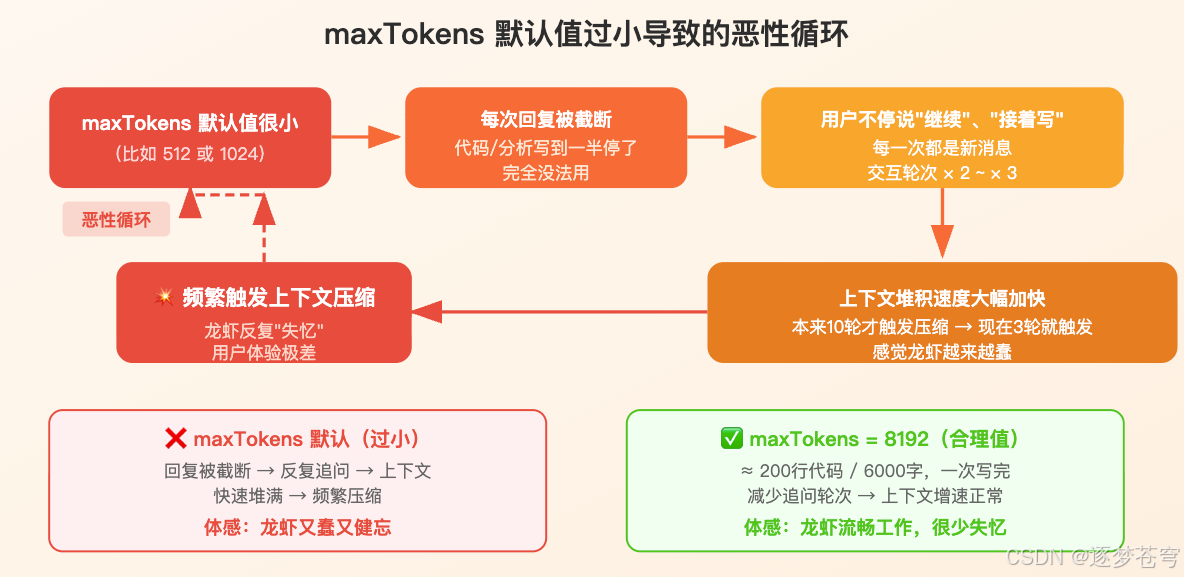
4.3 maxTokens 过小的连锁反应
maxTokens 过小同样会加剧压缩频率,而且方式更隐蔽:
maxTokens 默认值很小(比如 512 或 1024)
↓
每次回复被强制截断,代码写到一半就停
↓
用户不断说"继续"、"接着写"
↓
每一次"继续"都是一条新消息,上下文不断堆积
↓
上下文填满速度是正常情况的 2~3 倍
↓
压缩触发更频繁即使 contextWindow 配置正确,maxTokens 太小也会让你感觉龙虾在"频繁失忆"。
4.4 两个值同时偏小------双倍放大问题
当 contextWindow 和 maxTokens 同时使用了偏小的默认值,效果叠加:
contextWindow 默认值太小
↓ OpenClaw 误判上下文已接近满载
↓ 触发提前压缩
maxTokens 默认值太小
↓ 回复被截断 → 更多轮次 → 上下文填充更快
↓ 进一步加速压缩触发
两者叠加 → 龙虾聊几句就失忆,让人以为模型烂或工具有 bug本质问题只有一个:OpenClaw 对你的模型能力"估计不足",而你没有主动告诉它正确答案。
5、还有哪些配置在影响压缩行为
除了 contextWindow 和 maxTokens,openclaw.json 里还有几个相关配置值得了解:
5.1 compaction 模式
json
"compaction": {
"mode": "safeguard"
}safeguard 模式:只在即将撑满时才压缩,优先保留上下文完整性。
auto 模式:在上下文到达一定比例时渐进式压缩,过渡更平滑。
在 contextWindow 和 maxTokens 正确配置的前提下,safeguard 其实是更好的选择------能最大限度保留上下文。但如果这两个值本身就配小了,safeguard 反而会让压缩触发得更频繁、更突然。
5.2 contextPruning(上下文修剪)
json
"contextPruning": {
"mode": "cache-ttl",
"ttl": "1h"
}这个配置会让 OpenClaw 每隔 1 小时自动修剪一次缓存的上下文。长时间编码会话中,1小时前的内容可能已经被修剪。
这本身是个合理的保护机制,但如果你不知道它存在,就会觉得"龙虾怎么又忘了之前说过的事"。
6、为什么这么多人踩坑
这个问题之所以普遍,有几个原因:
1. 自定义 Provider 时没有强制填写这两个字段。
OpenClaw 不会在配置向导里提示你"记得填 contextWindow 和 maxTokens",很多人配完 API Key 和模型 ID 就以为结束了。
2. 报错信息不透明。
用户看到的只是"上下文已压缩",而不是"你的 contextWindow 配置可能偏小"。压缩就这么无声无息地发生了,没有任何提示让你去排查配置。
3. 配置文件路径隐蔽。
~/.openclaw/openclaw.json 在隐藏目录里,大多数用户用 configure 命令配好之后就忘了这个文件的存在,更不会想到去手动编辑它。
4. 国产模型的上下文能力迭代很快,文档滞后。
很多模型(比如 Qwen、MiniMax)已经支持 1M 甚至更大的上下文,但 OpenClaw 的保守默认值是按照早期模型能力设计的。你的模型早就"升级"了,配置文件却没跟上。
5. 抄配置的连锁反应。
社区里有人分享了不完整的配置(缺少这两个字段),其他人照抄,导致问题大量复现。
7、总结
你的龙虾不蠢,是它对你的模型能力"估计不足"------因为你没有明确告诉它。
| 问题 | 现象 | 修复 |
|---|---|---|
contextWindow 缺失或太小 |
模型明明有大上下文,才聊几轮就压缩 | 显式设置为模型实际支持的值 |
maxTokens 缺失或太小 |
回复频繁截断,交互轮次暴增,压缩加速 | 显式设置为合理值(建议 8192 起步) |
一份正确的自定义模型配置示例:
json
{
"id": "your-model-id",
"name": "你的模型名称",
"api": "anthropic-messages",
"contextWindow": 1000000,
"maxTokens": 8192,
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
}
}快速排查清单:
- 打开
~/.openclaw/openclaw.json - 找到你正在使用的自定义模型配置
-
contextWindow是否已显式填写(且与模型实际能力匹配)? -
maxTokens是否已显式填写(建议 8192 或以上)? - 修改后重启 OpenClaw
两个参数,五分钟,龙虾从"金鱼记忆"变"大象记忆"。
如果这篇文章帮到了你,转发给你身边同样在骂龙虾蠢的朋友。
|-----------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|
| 🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注公众号 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |  |
|