在罕见病药物(孤儿药)的研发与商业拓展中,战略决策的质量直接决定了数亿资金的投向与数年研发周期的成功与否。然而,支撑这些关键决策的信息基础,却长期面临结构性困境。
行业决策的共性痛点
信息碎片化与验证成本高昂
当前,研发战略与商业拓展团队在评估项目时,普遍需要分别访问FDA、EMA、PMDA、TGA等监管机构网站,使用不同检索逻辑获取孤儿药认定、上市批准、适应症及市场独占期数据;将获得的PDF报告、HTML表格、文档摘要进行人工提取、翻译与整理,耗时易错;基于非实时、非连续的数据点,手动计算市场独占期到期时间,推测竞争窗口,结论脆弱。
这一流程导致的直接问题包括:
决策延迟:完整数据搜集周期常需数人/周,错过项目评估黄金窗口。
风险评估不足:易遗漏关键区域市场信息(如日本独占期政策差异),或误判竞争药物到期时间。
内部沟通低效:决策依据分散于数百个网页与文档中,难以向管理层直观呈现全局。
关键决策场景
数据需求分析
以评估一个针对"纤维化罕见病"的临床前项目为例,团队必须厘清以下核心问题:
该疾病在全球主要市场的标准患者基数是多少?(美、欧、日、澳口径不同)
目前已上市及在研的同类疗法有哪些?分别处于哪个阶段?
最关键却最易被模糊处理的数据:现有药物的市场独占期何时到期?
其中第三点是风险与机会的锚点。若独占期将于2年内集中到期,意味着市场即将出现结构性空窗;若独占期还有8---10年,则进入壁垒极高。
路径重构
从数据整理到决策洞察
药智数据孤儿药与罕见病数据库可以实现以下转化:
旧路径:
数据源(分散)→人工搜集与整理(高成本、易错)→静态表格(难解读)→经验性判断(高风险)
新路径:
标准化数据库(集中)→结构化查询(实时)→数据驱动决策(可验证)
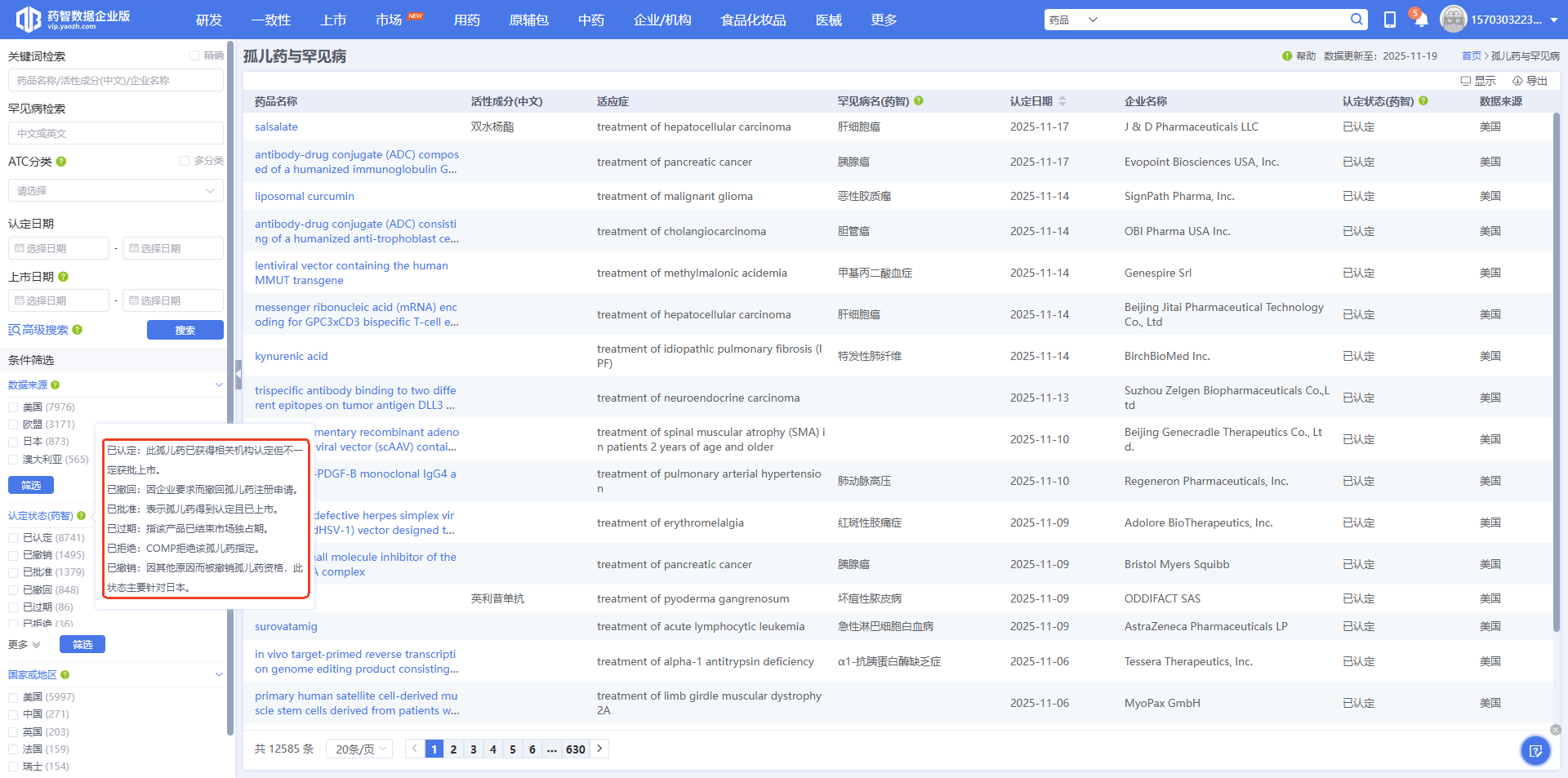
图 1 批量查看孤儿药的认定状态
解决方案的核心
将时间与政策变量结构化
真正的决策效率提升,不在于提供更多数据,而在于将影响决策的关键变量进行结构化处理,孤儿药和罕见病数据库按治疗领域、活性成份展示已上市/在研产品,已上市产品给出具体的上市日期。
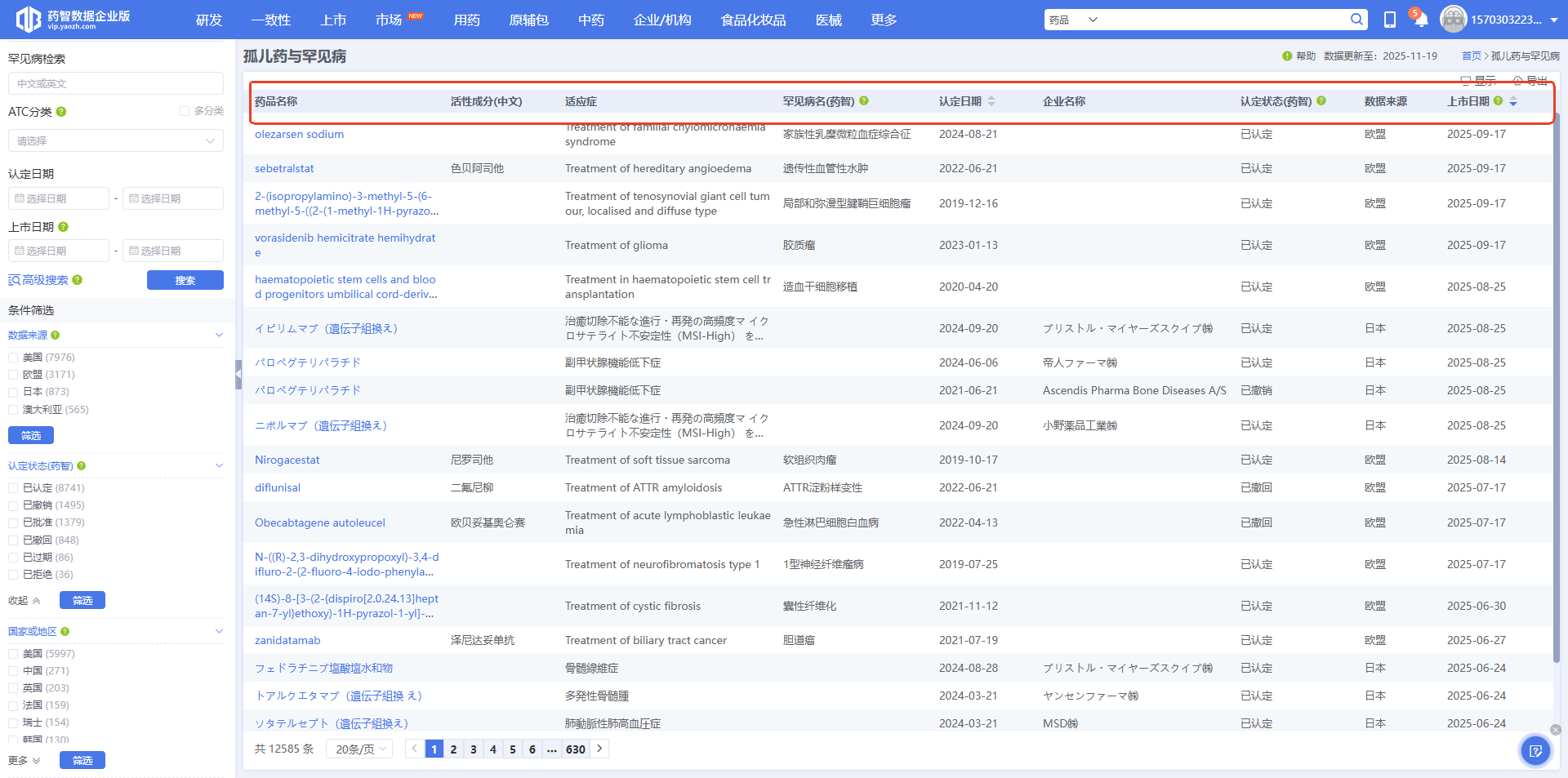
图 2 结构化展示
识别市场空白与竞争红海区域
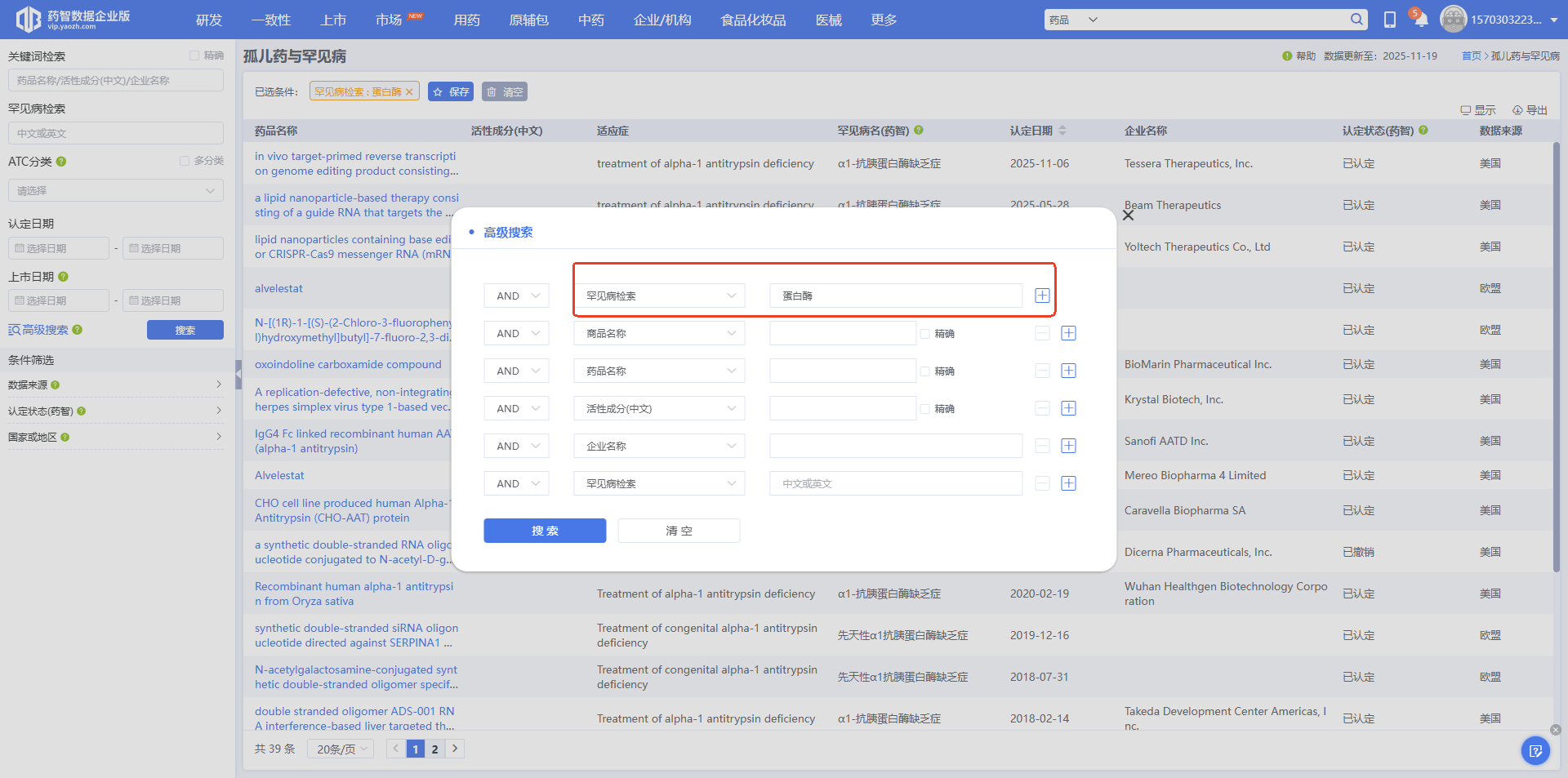
图 3 查找罕见病认证的孤儿药情况
孤儿药和罕见病数据库可以多个维度帮助研发团队:
- 立项评估:基于真实的竞争时间窗口而非猜测,评估项目战略价值
- 资源分配:识别政策保护期重叠度高的区域,优化全球开发序列
- 风险评估:量化市场进入的时序风险,制定对冲策略
对于商业拓展团队:
- 项目尽调:快速验证合作方提供的市场潜力数据
- 价值评估:基于剩余独占期时间计算市场独占权价值
- 谈判支持:用数据支撑估值调整与区域权益划分主张
孤儿药研发本质上是数据密集型、政策敏感型、时间关键型的战略投资。当行业共识从"经验驱动"转向"证据驱动"时,决策质量的下一个阶梯,必然建立在对多源异构数据的实时、结构化处理能力之上。
降低信息不对称,本质上是将有限的专家注意力,从"信息搜集与整理"的重度劳动中释放出来,重新聚焦于真正创造价值的"模式识别与战略判断"上。当一张图表能回答"机会在哪里、风险有多大、时机是什么"这三个核心问题时,战略决策便从一门艺术,更接近一门可重复、可验证的科学。