在人工智能技术爆发的当下,AI不再是遥远的技术概念,而是深度融入开发者日常工作的"协同伙伴"。从一行行代码的自动生成到复杂逻辑的智能优化,从重复工作的批量处理到测试环节的高效赋能,AI正以不可逆转的态势重塑开发工作模式,推动整个IT行业向"高效创新"转型。作为一名深耕后端开发5年的从业者,我亲身经历了从"纯人工编码"到"AI协同开发"的迭代,尤其在TRAE等智能编程工具的实践中,深刻体会到AI技术对开发效率、代码质量乃至行业格局的颠覆性影响。
本次结合自身实战经验,围绕"AI编程工具落地"展开,聊聊TRAE智能工具如何优化开发流程、解决实际开发痛点,以及普通开发者如何快速上手TRAE,实现从"重复劳动"到"创造性工作"的跨越,契合征文"AI技术如何重塑你的工作与行业"的核心主题。
一、AI编程工具的崛起:不止是"代码生成",更是流程革新
在AI技术普及之前,开发者的日常工作被大量重复性任务占据:编写基础CRUD接口、重复的异常处理代码、繁琐的单元测试脚本,甚至是查询常用API的使用方法,这些工作占用了近60%的开发时间,导致真正用于架构设计、逻辑创新的时间被严重压缩。根据GitHub 2024年报告显示,AI编程工具的使用率已从2023年的58%提升至73%,效率提升感知率达68%,足以说明AI工具已成为开发者的"必备神器"。
目前主流的AI编程工具中,TRAE凭借其全流程自动化能力、多智能体协同优势,成为当下极具竞争力的选择。TRAE是"The Real AI Engineer"的缩写,其核心定位并非传统的代码补全工具,而是一套以AI为主导的全闭环开发体系,能实现"需求分析-任务拆解-代码实现-测试部署"的全流程自动化。它内置双智能体核心驱动,覆盖从0到100的全开发场景,同时支持多模型自由切换和全链路工具集成,相较于传统编码工具,更能实现开发流程从"线性推进"向"并行协同"的深度转变。除此之外,CodeGeeX、Tabnine等工具也各有侧重,共同构成了AI协同开发的生态。
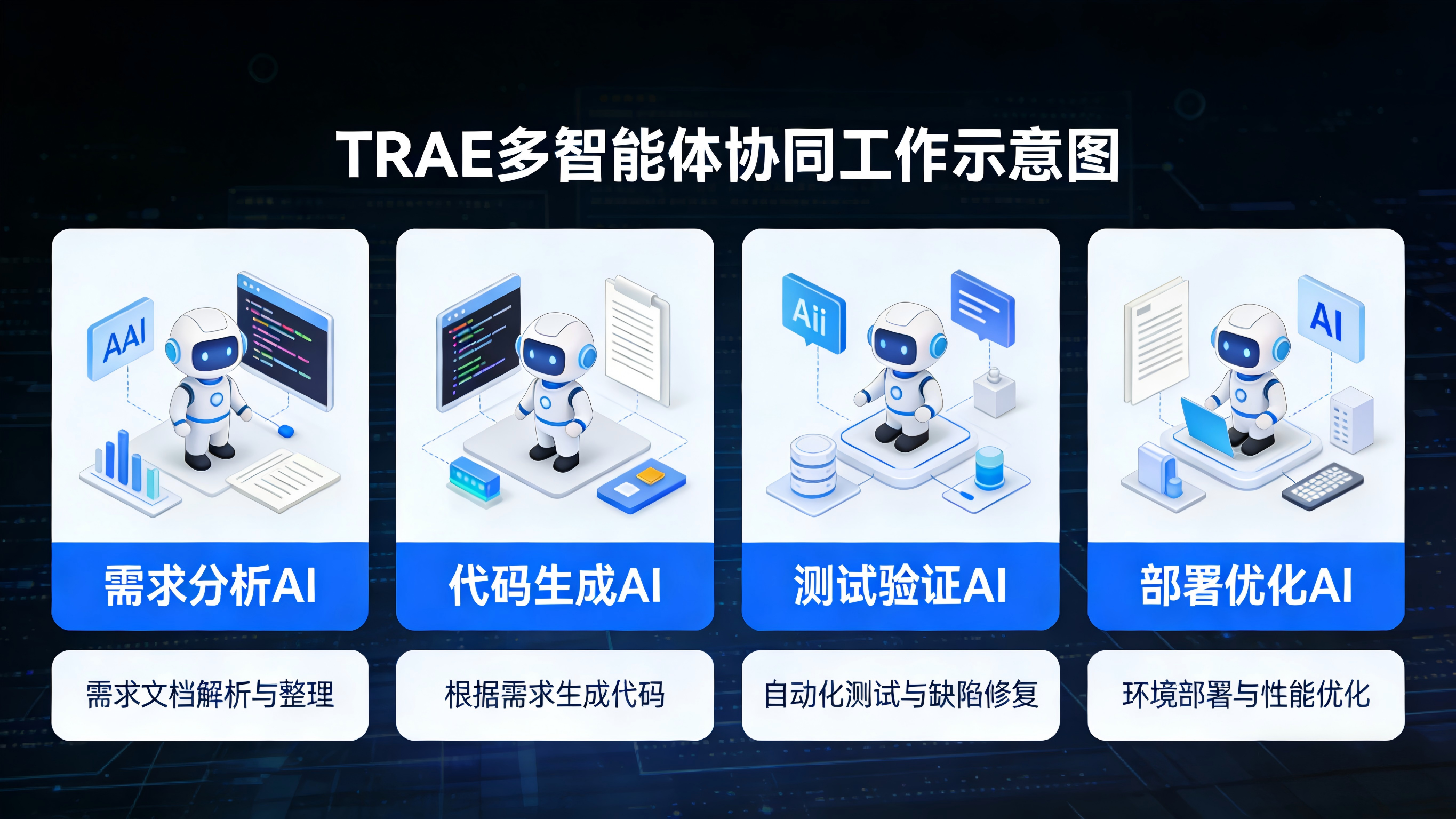
二、TRAE实战:3个核心场景,解锁开发效率密码
结合我自身的后端开发实战(技术栈:Java+Spring Boot+MySQL),TRAE的应用主要集中在3个核心场景,依托其双智能体、多模型协同等优势,每一个场景都能显著降低开发成本、提升效率,真正实现"事半功倍",以下结合具体案例详细说明。
场景1:基础代码自动生成,告别重复劳动
后端开发中,大量的重复性代码(如实体类、DTO、DAO层接口、异常处理)占用了大量时间。使用TRAE的SOLO Coder智能体后,只需输入简单的注释或类名,就能自动生成符合编码规范的完整代码,无需手动敲击每一行,且能精准适配项目已有的编码风格,避免后续格式调整的麻烦。
示例:在Spring Boot项目中,输入注释"// 定义用户实体类,包含id、用户名、密码、手机号、创建时间,遵循驼峰命名,添加 lombok 注解",TRAE会自动生成如下代码,同时可根据项目已引入的依赖,自动匹配相关导入语句,无需手动补充:
java
import lombok.Data;
import java.time.LocalDateTime;
/**
* 用户实体类
* 包含用户核心信息,用于数据库映射
*/
@Data
public class User {
// 用户唯一标识
private Long id;
// 用户名(唯一)
private String username;
// 密码(加密存储)
private String password;
// 手机号(11位)
private String phone;
// 创建时间
private LocalDateTime createTime;
}不仅如此,当编写DAO层接口时,输入"// 编写UserDAO接口,继承JpaRepository,包含根据用户名查询用户、根据手机号查询用户的方法",TRAE会自动生成接口方法,同时自动补全方法注释,甚至能根据项目的数据库配置,优化查询语句的兼容性。这种方式让原本需要30分钟的基础代码编写,缩短至5分钟以内,极大释放了开发者的时间1。
场景2:复杂业务逻辑辅助,降低编码难度
对于复杂的业务逻辑(如订单处理、权限校验、数据统计),开发者往往需要反复梳理逻辑、调试代码,容易出现逻辑漏洞。TRAE的SOLO Coder智能体支持Plan模式,开启后会先检索代码上下文、生成详细开发计划,经用户确认后再执行开发,避免逻辑漏洞;同时可调度多个子智能体分工协作,比如调用"数据库专家"修改Schema、"后端专家"优化业务逻辑,实现专业化分工1。
实战案例:在电商项目中,需要实现"订单支付回调处理"功能,核心需求包括:验证回调签名、解析回调参数、更新订单状态、记录支付日志、发送消息通知。输入自然语言描述后,TRAE自动生成详细开发计划,确认后生成核心代码,并添加了异常处理、日志记录等细节,代码如下(简化版):
java
/**
* 订单支付回调处理方法
* @param callbackParam 支付回调参数(JSON格式)
* @return 回调响应结果(符合支付平台要求)
*/
public String orderPayCallback(String callbackParam) {
try {
// 1. 验证回调签名(防止伪造回调)
boolean signValid = verifyCallbackSign(callbackParam);
if (!signValid) {
log.error("支付回调签名验证失败,参数:{}", callbackParam);
return "fail";
}
// 2. 解析回调参数
JSONObject param = JSONObject.parseObject(callbackParam);
String orderNo = param.getString("orderNo");
String payAmount = param.getString("payAmount");
String payStatus = param.getString("payStatus");
// 3. 查询订单信息
Order order = orderService.getByOrderNo(orderNo);
if (order == null) {
log.error("支付回调,订单不存在,订单号:{}", orderNo);
return "fail";
}
// 4. 更新订单状态
order.setPayStatus(payStatus);
order.setPayAmount(new BigDecimal(payAmount));
order.setPayTime(LocalDateTime.now());
orderService.updateById(order);
// 5. 记录支付日志
payLogService.savePayLog(orderNo, payAmount, payStatus, callbackParam);
// 6. 发送消息通知(异步)
messageService.sendOrderPayNotice(order.getUserId(), orderNo);
log.info("支付回调处理成功,订单号:{}", orderNo);
return "success";
} catch (Exception e) {
log.error("支付回调处理失败,参数:{},异常信息:{}", callbackParam, e.getMessage(), e);
return "fail";
}
}生成的代码不仅逻辑完整,还考虑到了异常处理、日志记录等细节,更能根据项目已有的代码规范,优化变量命名、代码缩进等细节,开发者只需根据项目实际需求,微调部分参数和方法调用,就能快速投入使用。这种方式不仅降低了复杂逻辑的编码难度,还减少了逻辑漏洞的出现,尤其适合新手开发者快速上手复杂业务。
场景3:单元测试自动生成,提升代码质量
单元测试是保证代码质量的关键,但很多开发者因为时间紧张,往往忽略单元测试的编写,导致后期出现隐蔽性bug。TRAE能够根据核心业务代码,自动生成对应的单元测试脚本,支持JUnit、Mockito等常用测试框架,同时内置Diff View差异视图,AI生成的所有代码变更都会清晰标注增删改记录,便于审查核对,即使出现问题也能快速回滚1。
示例:针对上述"订单支付回调处理"方法,TRAE自动生成单元测试代码,涵盖正常场景、签名验证失败、订单不存在等异常场景,代码如下:
java
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoExtension;
import static org.mockito.Mockito.*;
import static org.junit.jupiter.api.Assertions.*;
@ExtendWith(MockitoExtension.class)
public class OrderPayCallbackTest {
@InjectMocks
private OrderService orderService;
@Mock
private PayLogService payLogService;
@Mock
private MessageService messageService;
@Test
public void testOrderPayCallback_Success() {
// 模拟回调参数
String callbackParam = "{\"orderNo\":\"20260312001\",\"payAmount\":\"199.00\",\"payStatus\":\"SUCCESS\",\"sign\":\"xxx\"}";
// 模拟签名验证通过
doReturn(true).when(orderService).verifyCallbackSign(anyString());
// 模拟查询订单
Order order = new Order();
order.setOrderNo("20260312001");
order.setUserId(1L);
doReturn(order).when(orderService).getByOrderNo(anyString());
// 执行方法
String result = orderService.orderPayCallback(callbackParam);
// 断言结果
assertEquals("success", result);
// 验证方法调用
verify(payLogService, times(1)).savePayLog(anyString(), anyString(), anyString(), anyString());
verify(messageService, times(1)).sendOrderPayNotice(anyLong(), anyString());
}
@Test
public void testOrderPayCallback_SignInvalid() {
// 模拟回调参数
String callbackParam = "{\"orderNo\":\"20260312001\",\"payAmount\":\"199.00\",\"payStatus\":\"SUCCESS\",\"sign\":\"xxx\"}";
// 模拟签名验证失败
doReturn(false).when(orderService).verifyCallbackSign(anyString());
// 执行方法
String result = orderService.orderPayCallback(callbackParam);
// 断言结果
assertEquals("fail", result);
}
}通过TRAE生成的单元测试,能够快速覆盖核心场景,开发者只需补充少量测试数据,就能完成单元测试的编写,既节省了时间,又提升了代码的稳定性和可维护性。同时,TRAE的智能上下文管理功能,能自动压缩长对话中的冗余信息,提炼核心逻辑,避免"对话失忆",在多轮测试脚本优化中,无需反复重复需求背景。据实践统计,使用TRAE生成单元测试,可使测试覆盖度提升30%以上3。
三、TRAE使用避坑:拒绝"盲目依赖",实现人机协同
虽然TRAE能大幅提升效率,且具备自主规划、多智能体协同等优势,但在实战过程中,我也踩过一些坑,总结出3个核心注意事项,帮助开发者更好地利用TRAE,避免陷入"AI依赖"的误区,实现真正的人机协同。
1. 拒绝"直接复制粘贴",做好代码校验
TRAE生成的代码虽然高效、规范,但并非绝对正确,尤其是在复杂业务场景中,可能会出现逻辑漏洞、参数错误,或调用项目中未引入的依赖等问题。比如,TRAE生成的代码可能会适配其内置的模型规范,与项目自定义的编码规范存在细微差异。因此,无论TRAE生成的代码多么完整,都需要手动校验,重点检查逻辑合理性、参数正确性、异常处理是否全面,避免直接复制粘贴导致线上bug2。
2. 优化提示词,结合Plan模式提升生成质量
TRAE的生成效果,很大程度上取决于提示词的清晰度和完整性,尤其是其Plan模式的使用,更需要精准的需求描述。模糊的提示词(如"编写一个订单接口")会导致TRAE生成的开发计划过于通用,无法直接使用;而精准的提示词(如"使用Spring Boot 3.x编写订单查询接口,接收订单号参数,返回订单详情(包含商品信息、支付状态),添加接口参数校验和异常处理"),能让TRAE生成的开发计划和代码更贴合需求。结合TRAE支持的"4C"提示词法则:Context(明确上下文)、Constraints(指定约束)、Clarity(清晰描述)、Correctness(预判漏洞),能大幅提升生成质量。
3. 聚焦"创造性工作",让TRAE做"辅助角色"
TRAE的核心价值是"解放双手",帮助开发者处理重复性、基础性的工作,甚至能辅助完成复杂逻辑的拆解和实现,但它并非替代开发者。开发者的核心竞争力,依然是架构设计、业务理解、逻辑创新等TRAE无法替代的能力。因此,在使用TRAE时,要明确分工:让TRAE负责基础代码生成、单元测试编写、重复逻辑实现、任务拆解等工作,自己则聚焦于需求分析、架构优化、业务创新等核心环节,充分利用其多智能体、多模型协同优势,实现"AI做执行,人做决策"的人机协同模式。

四、AI重塑开发行业:效率革命背后的行业升级
从个人开发效率的提升,到整个开发行业的变革,TRAE等AI编程工具的落地,不仅改变了开发者的工作模式,更推动了整个IT行业的升级。根据IDC最新报告,到2025年,全球AI驱动的代码生成市场将达到500亿美元,其中企业级市场占比将超过60%,这一数据背后,是AI技术对开发行业的深刻重塑,而TRAE等具备全流程自动化能力的工具,正成为行业升级的核心驱动力。
一方面,TRAE降低了开发门槛,其SOLO Builder智能体可实现从0到1快速构建完整应用,只需自然语言描述需求,就能自动完成需求分析、生成PRD、编写前后端代码、配置数据库,甚至支持一键部署,让新手开发者能够快速上手复杂项目,缩短了人才培养周期;另一方面,TRAE提升了整体开发效率,其多任务并行处理能力,可同时推进"后端API修复"和"前端UI适配"等任务,打破单线程工作瓶颈,让企业能够以更低的成本、更快的速度完成项目交付,提升市场竞争力。比如,字节内部通过"用TRAE开发TRAE"的实践,大幅提升了开发效率,将复杂功能的迭代周期缩短了50%以上。
更重要的是,TRAE等工具正在推动开发模式的变革,从"单人开发"向"人机协同"转变,从"传统瀑布式开发"向"敏捷开发"升级,让开发工作更高效、更灵活、更具创新性。未来,随着大模型技术的不断迭代,TRAE将实现更精准的上下文理解、更复杂的逻辑生成,其企业版的知识库、自定义模型用量管控等功能,还将进一步适配企业级开发需求,参与架构设计、代码评审等核心环节,进一步重塑开发行业的格局。
五、总结:拥抱AI,做新时代的开发者
AI技术的爆发,不是对开发者的替代,而是对开发者的赋能。作为开发者,我们无需畏惧AI技术的变革,而应主动拥抱TRAE等智能编程工具,将其融入日常开发流程,摆脱重复性劳动的束缚,聚焦于更具创造性的工作。
从TRAE的实战应用中,我深刻体会到:AI工具不仅能提升开发效率、降低编码难度,更能推动我们不断提升自身的核心竞争力,适应行业的发展变化。TRAE的全流程自动化、多智能体协同等优势,让开发工作更高效、更可控,在AI重塑工作与行业的浪潮中,唯有保持学习的心态,熟练运用TRAE等AI工具,实现人机协同,才能在开发行业中站稳脚跟,解锁效率提升与产业升级的密码。
未来,AI与开发的融合将更加深入,像TRAE这样的智能工具将不断迭代升级,推出更多贴合开发者需求的功能和落地方案。让我们共同探索AI技术的无限可能,用AI赋能开发,用创新驱动行业升级,做新时代的开发者!