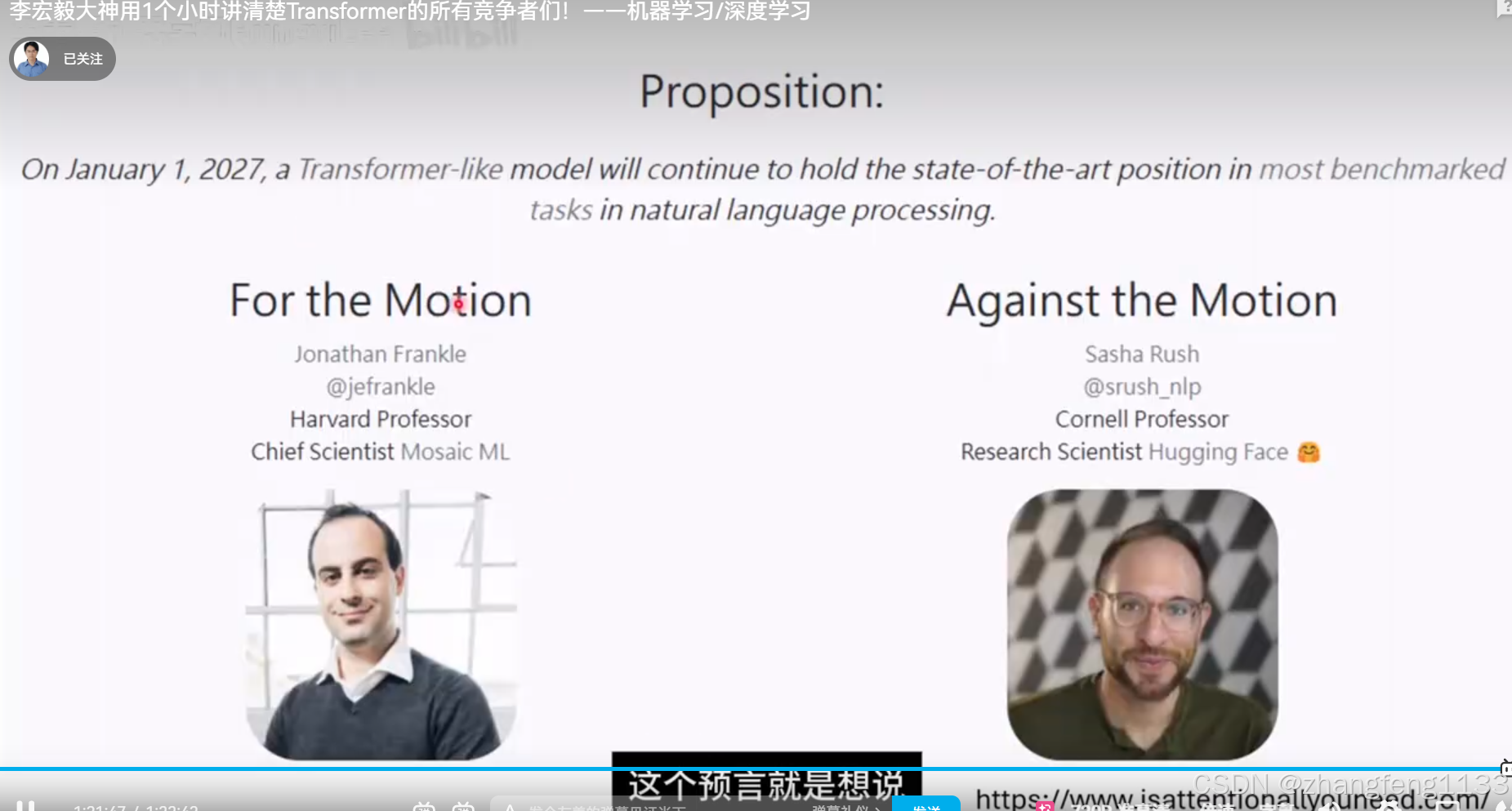
还有外国人还是会万玩, du公司股份,看 2027年 transformer 还是霸榜
可以使用bili2text工具从指定B站视频中根据语音提取文字资料,该工具输入链接即可使用,免费且能一步到位地实现Bilibili视频转文字。其项目地址为:https://gitcode.com/gh_mirrors/bi/bili2text

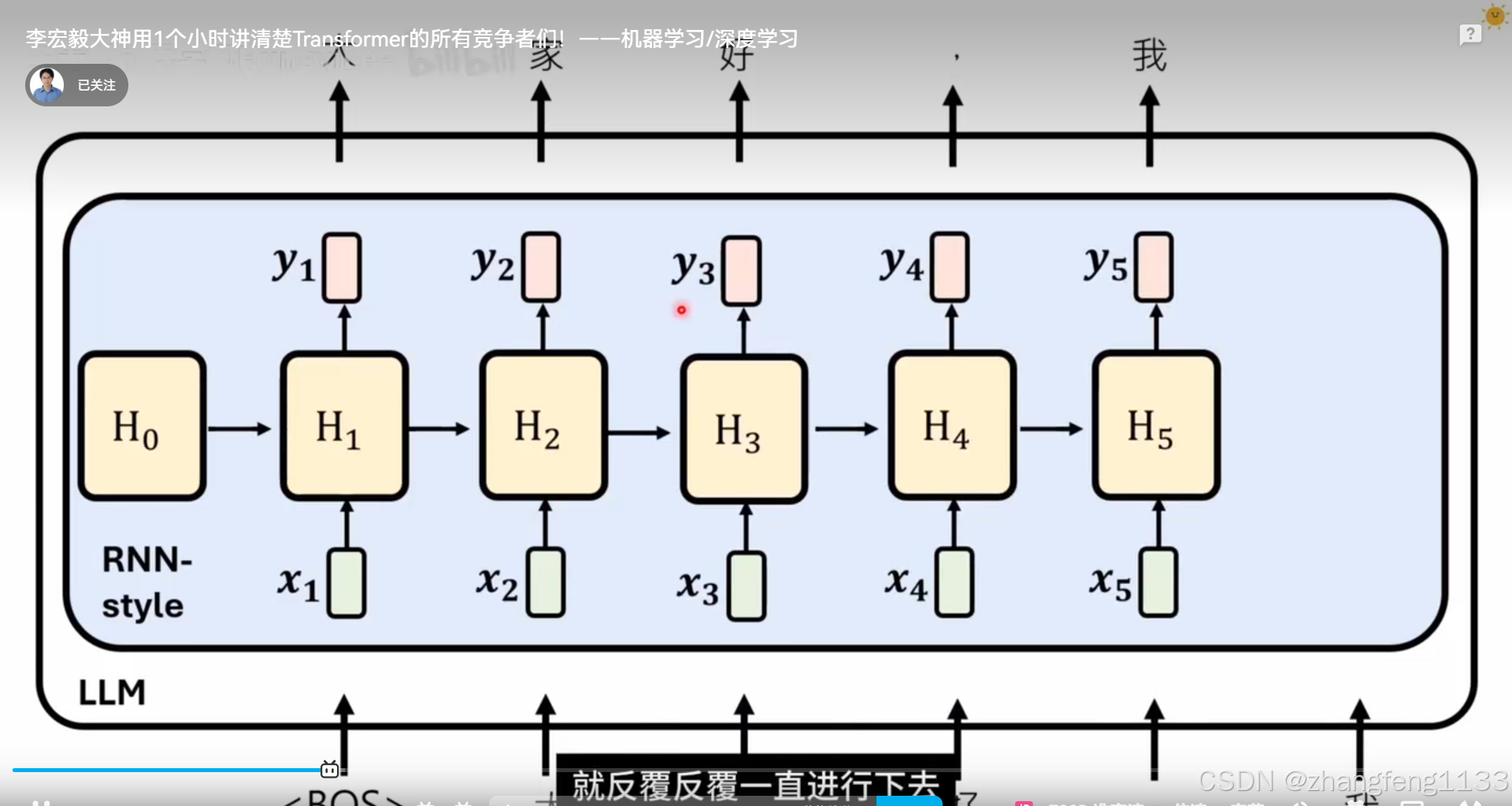
memba 通过RNN讲解 ,而不是从工程学的smm 角度讲解
每一个模型为了解决一个问题,存在都有他的理由

残差网络
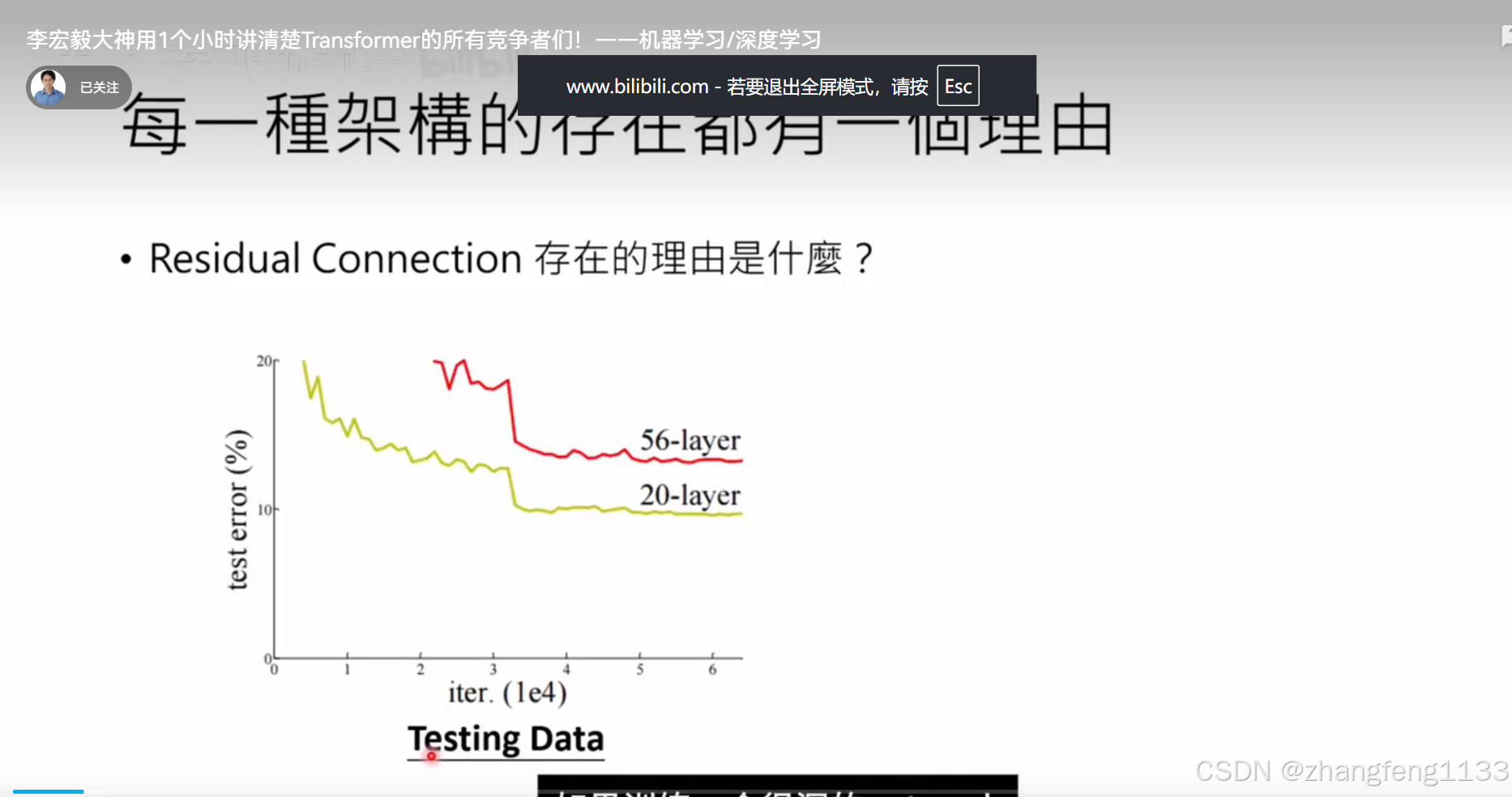
解释为什么要有残差网络,提供了可视化 loss变化

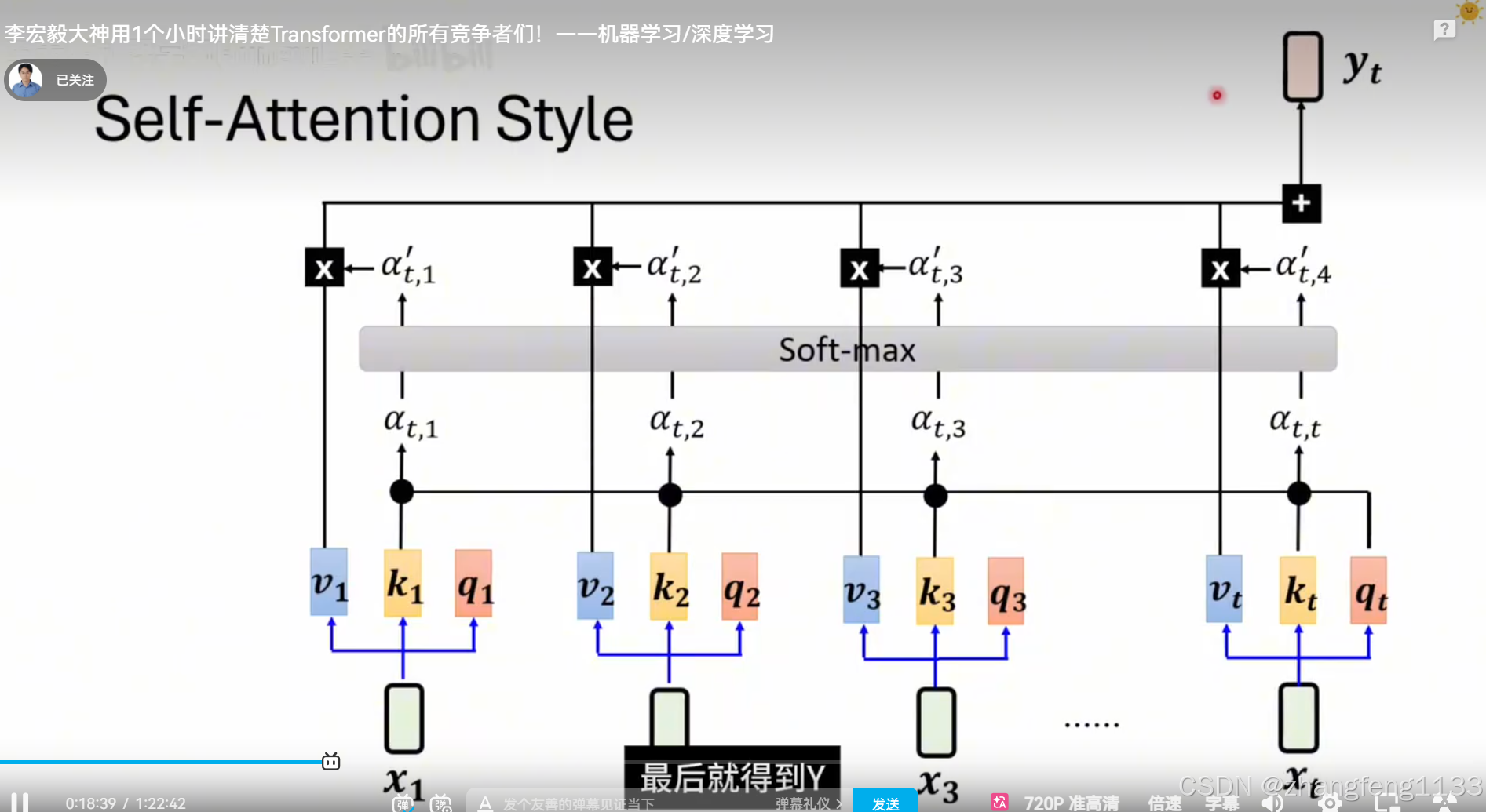
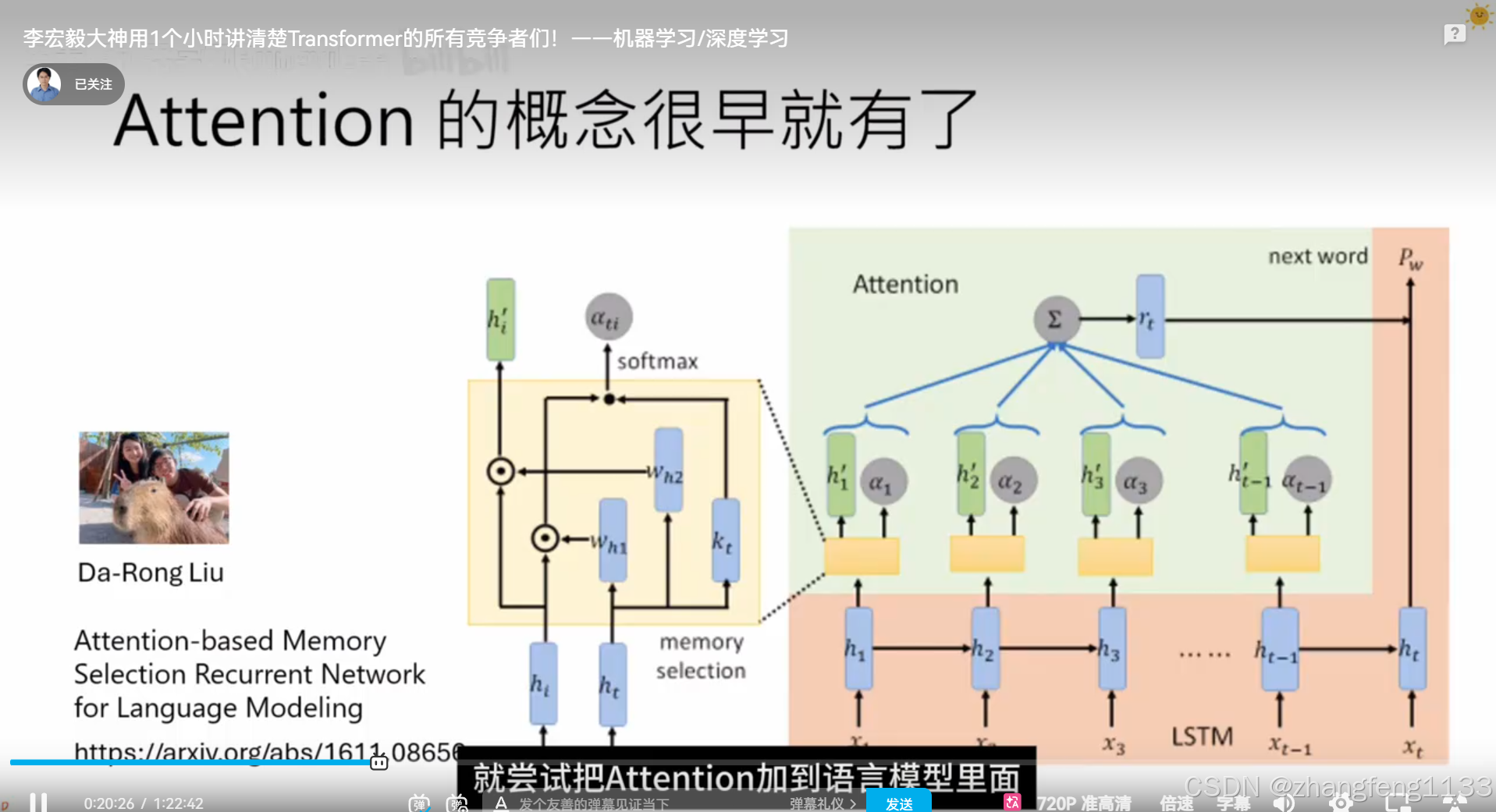
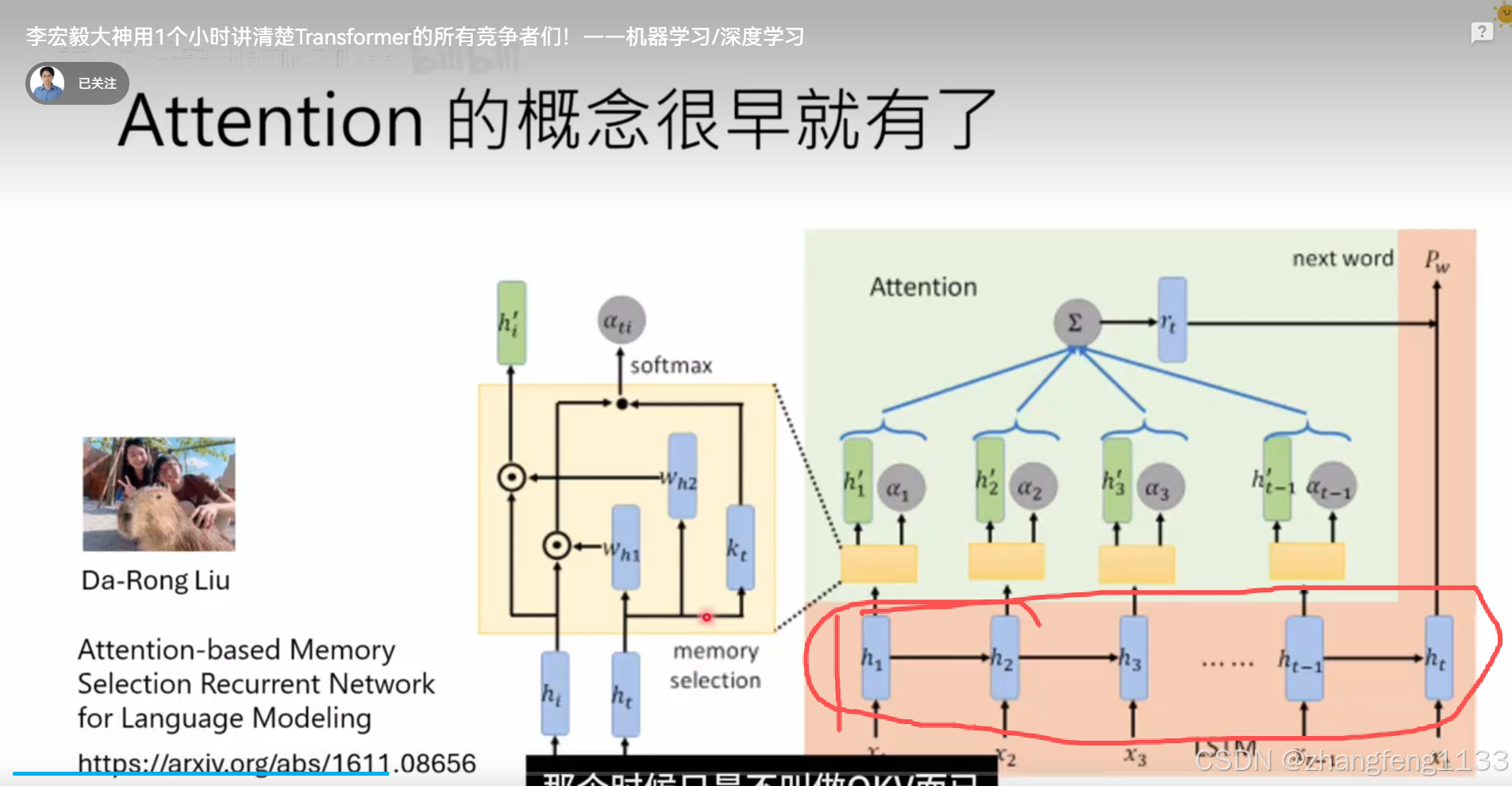
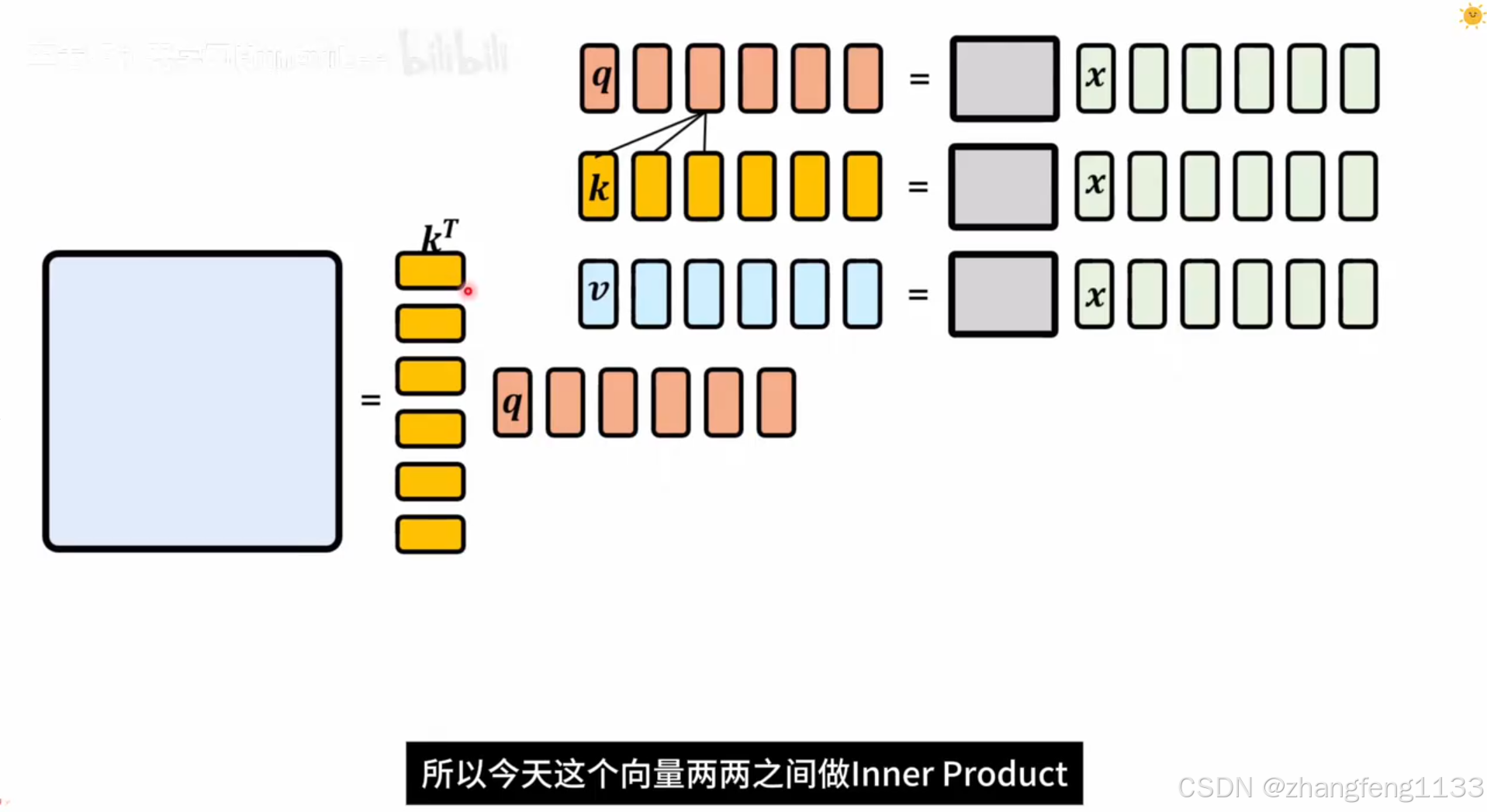
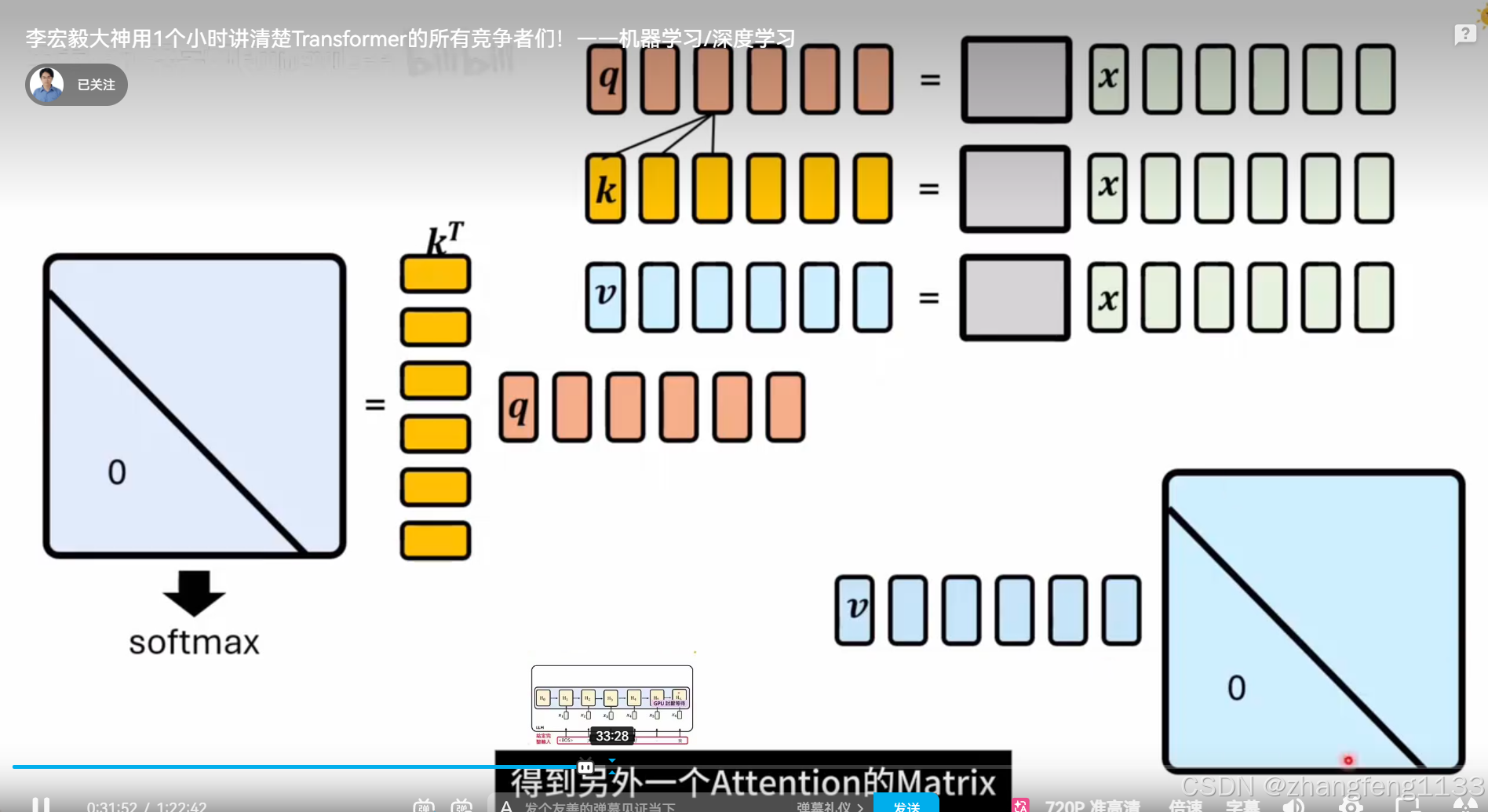
self-attenion
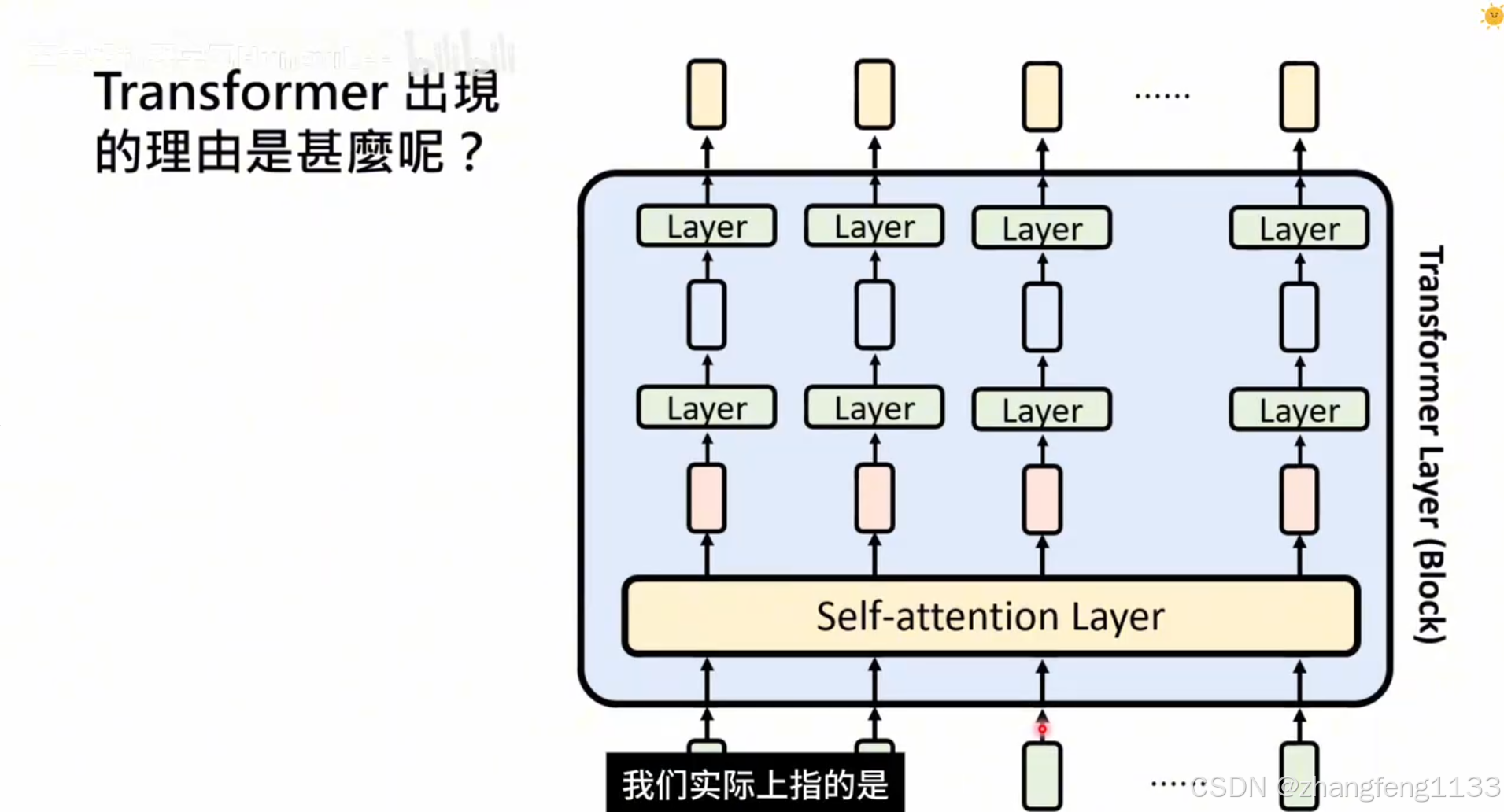
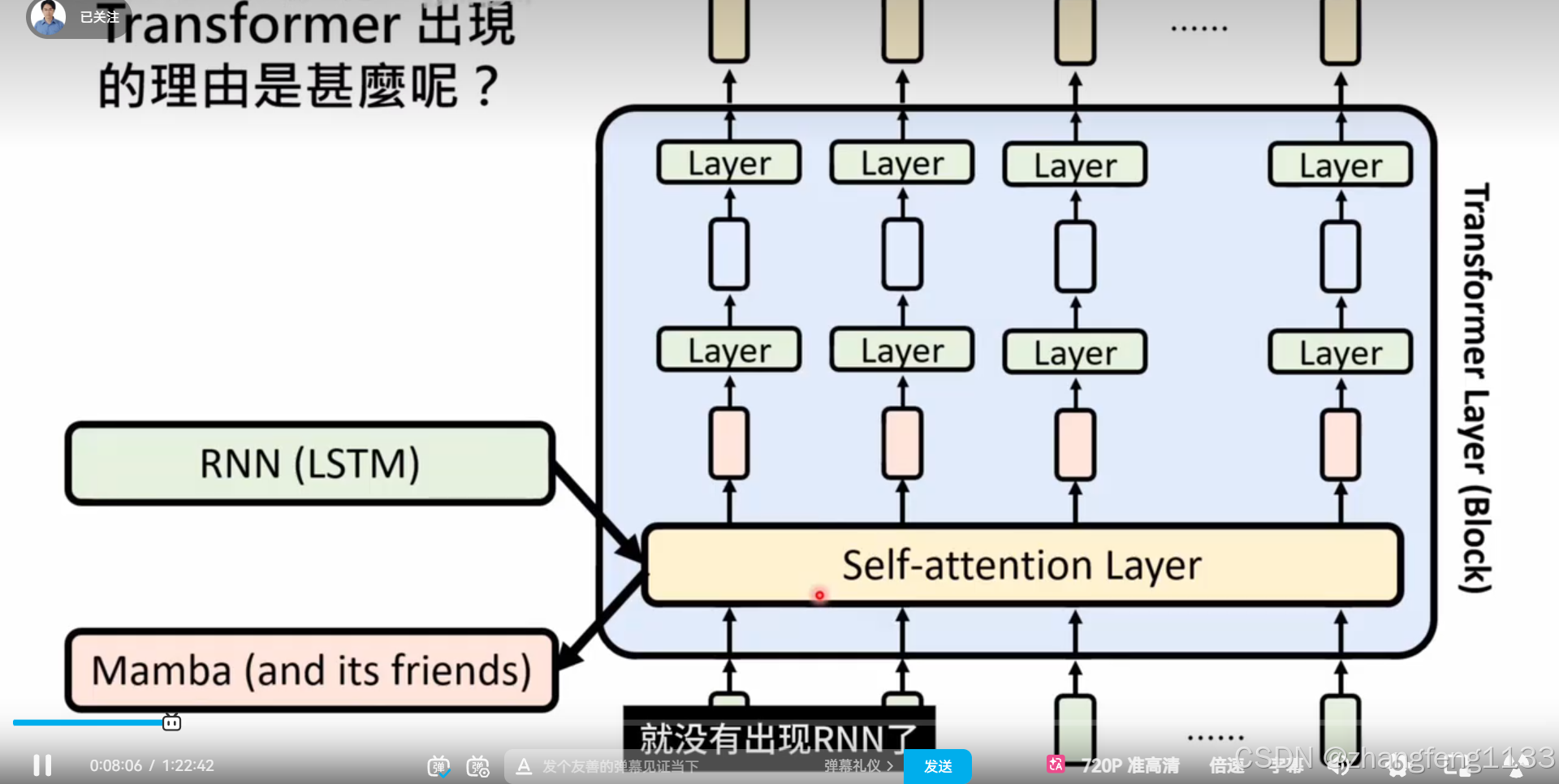
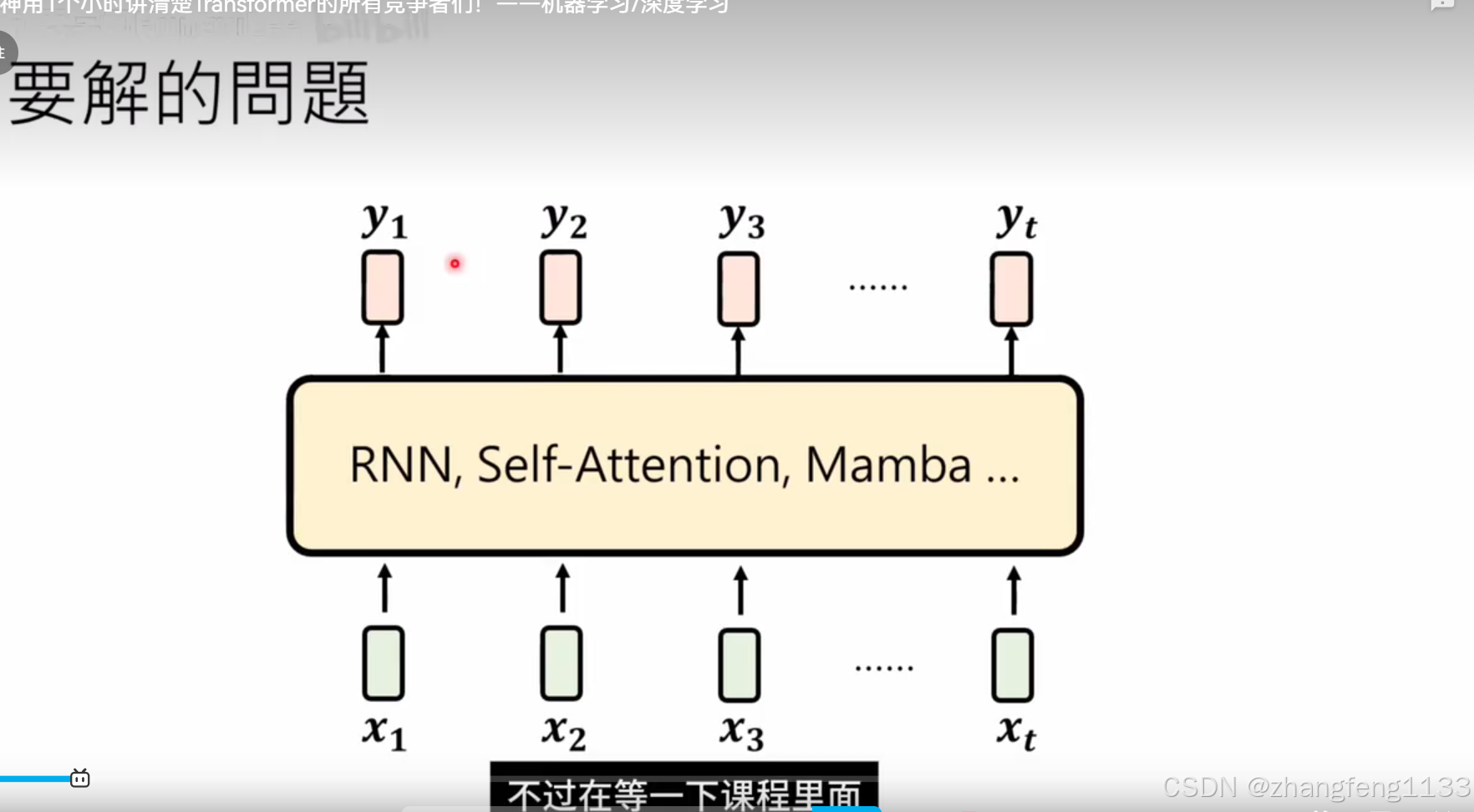
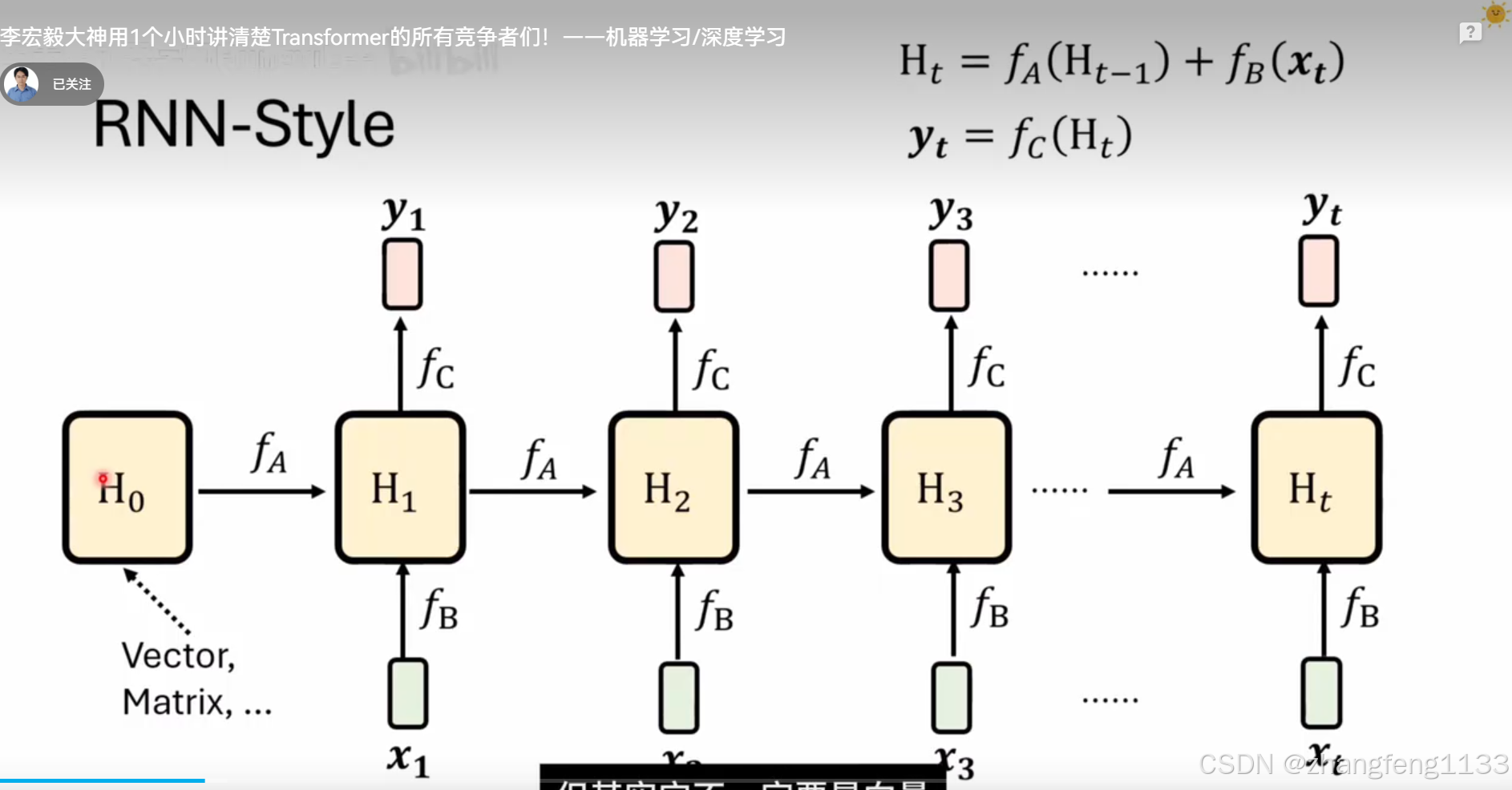
RNN
self-attention
\\
 ### selft-attenion
### selft-attenion
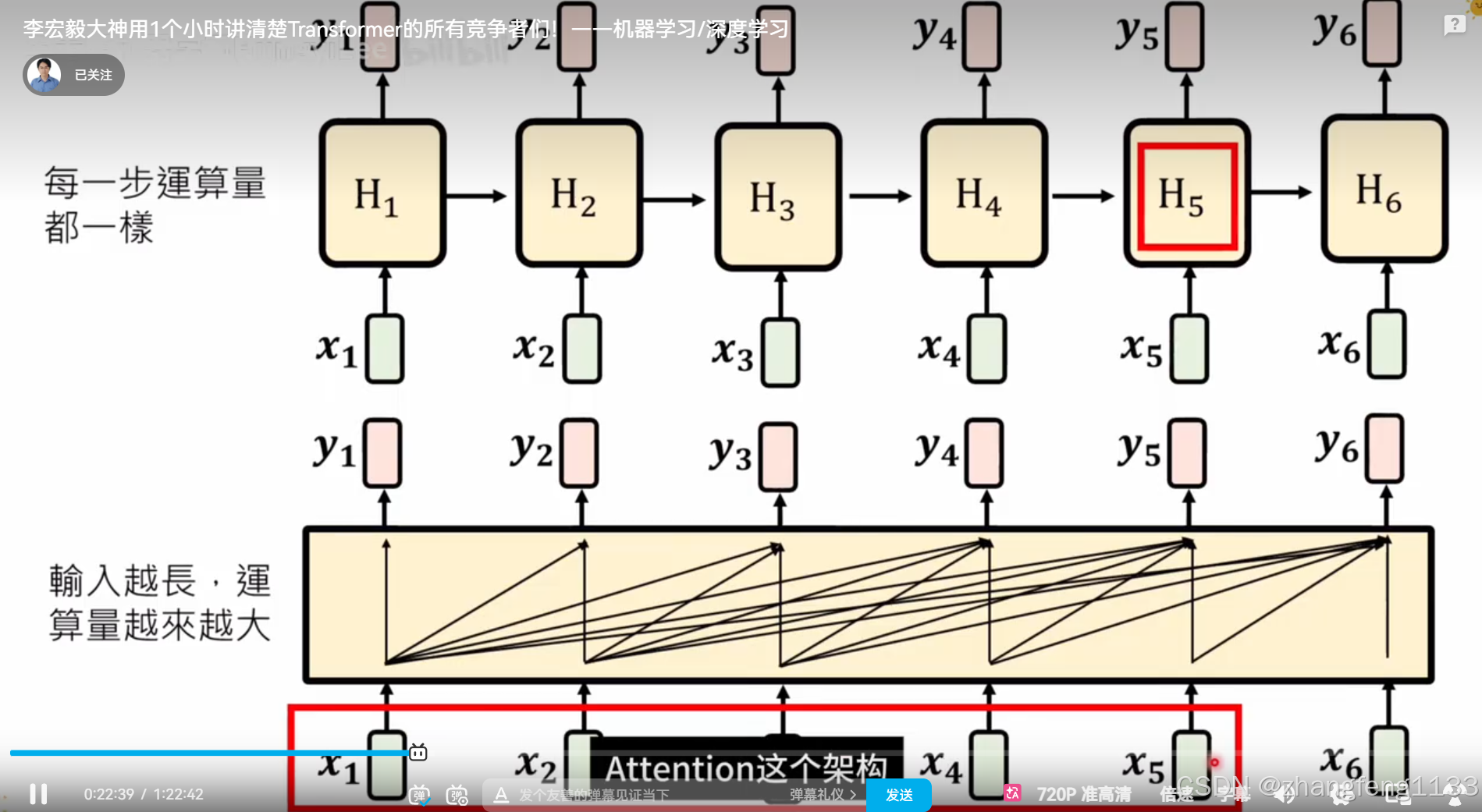
更加并行计算(台湾叫平行化)

在这里插入图片描述


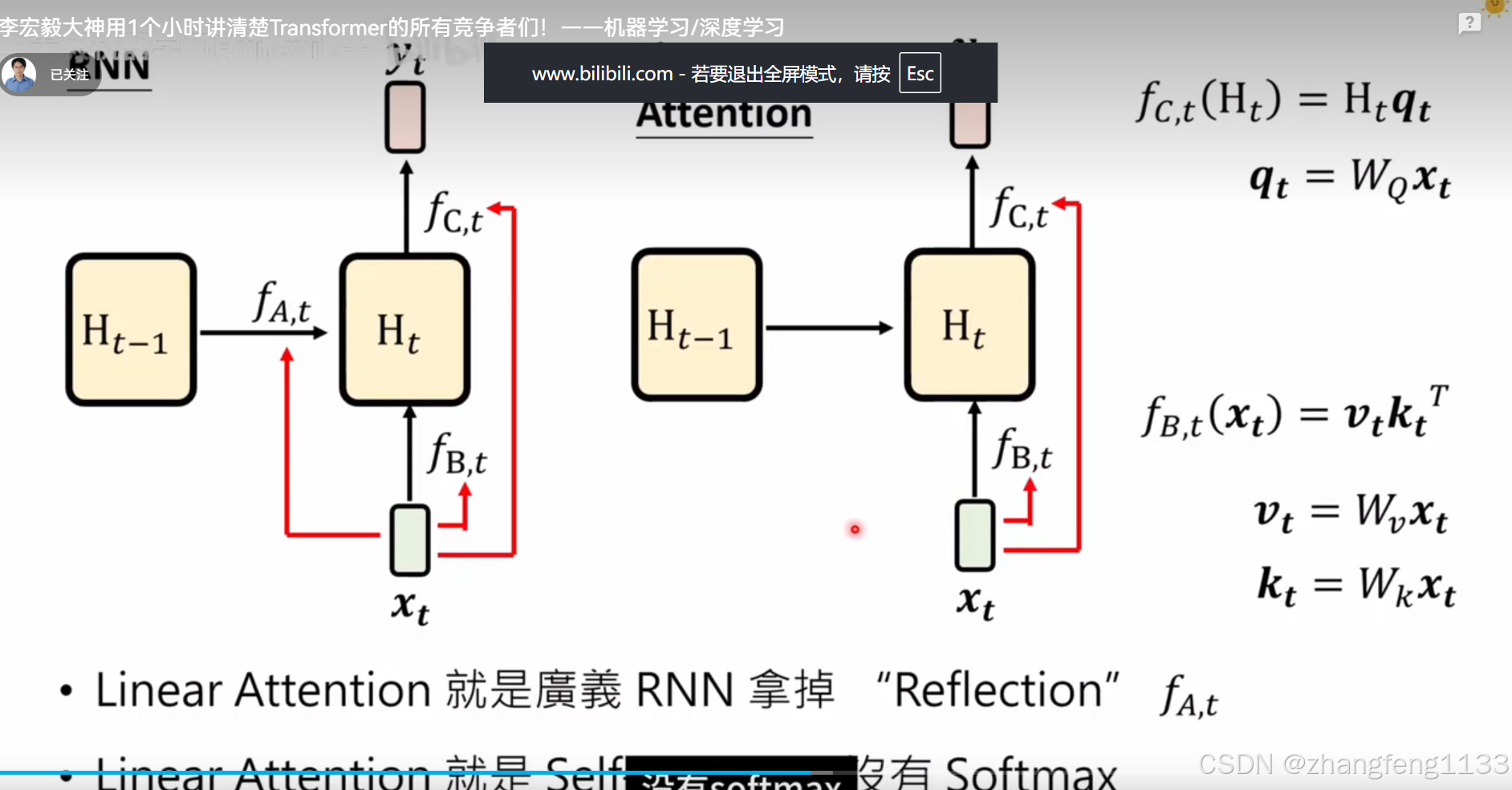
RNN 改进 linear attention


简化函数 fa 去掉 相当 不做运算 ht-1 -= ht-1 不做计算




扫描算法,不作介绍,后面有i更加简单的


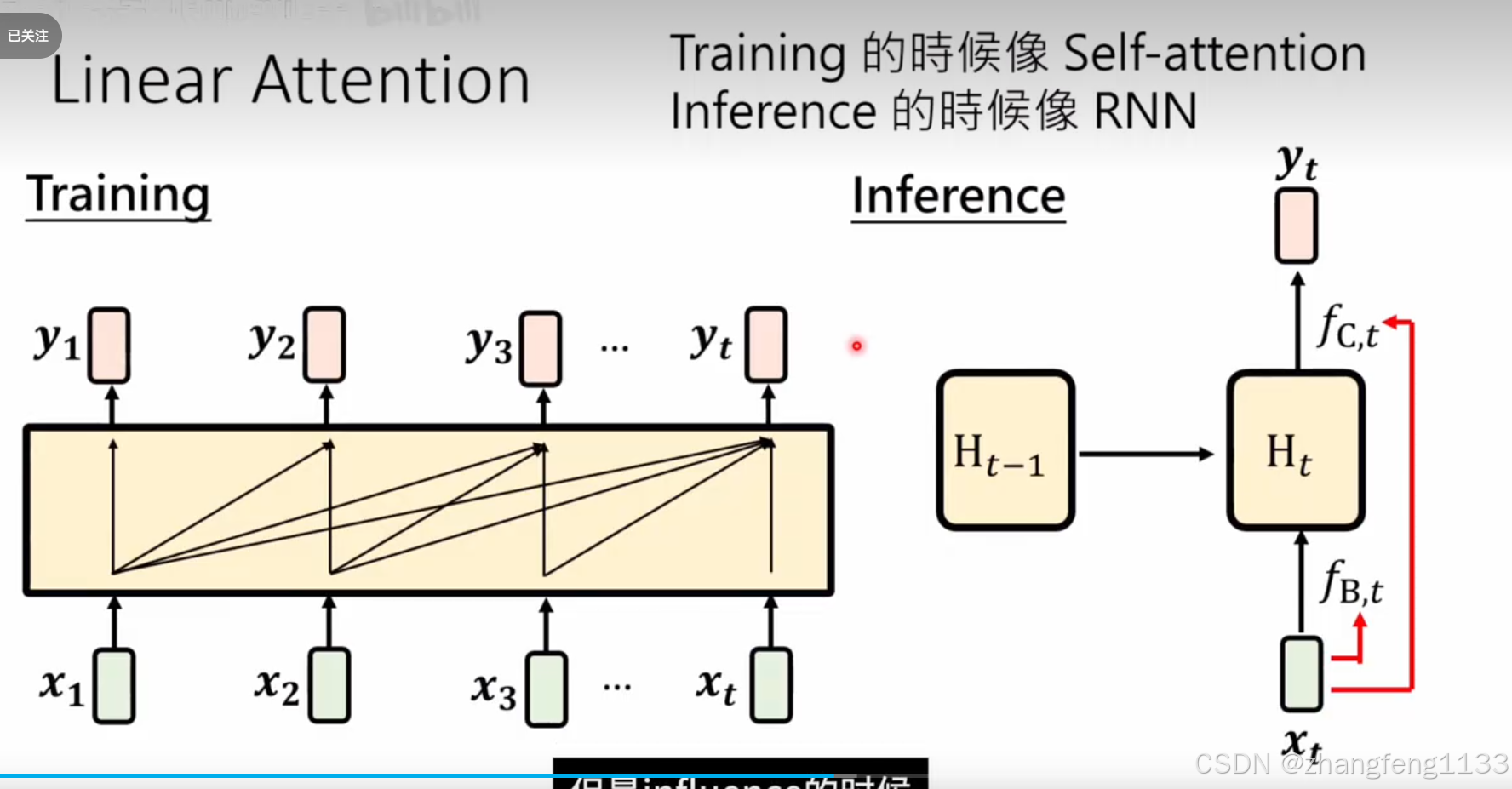
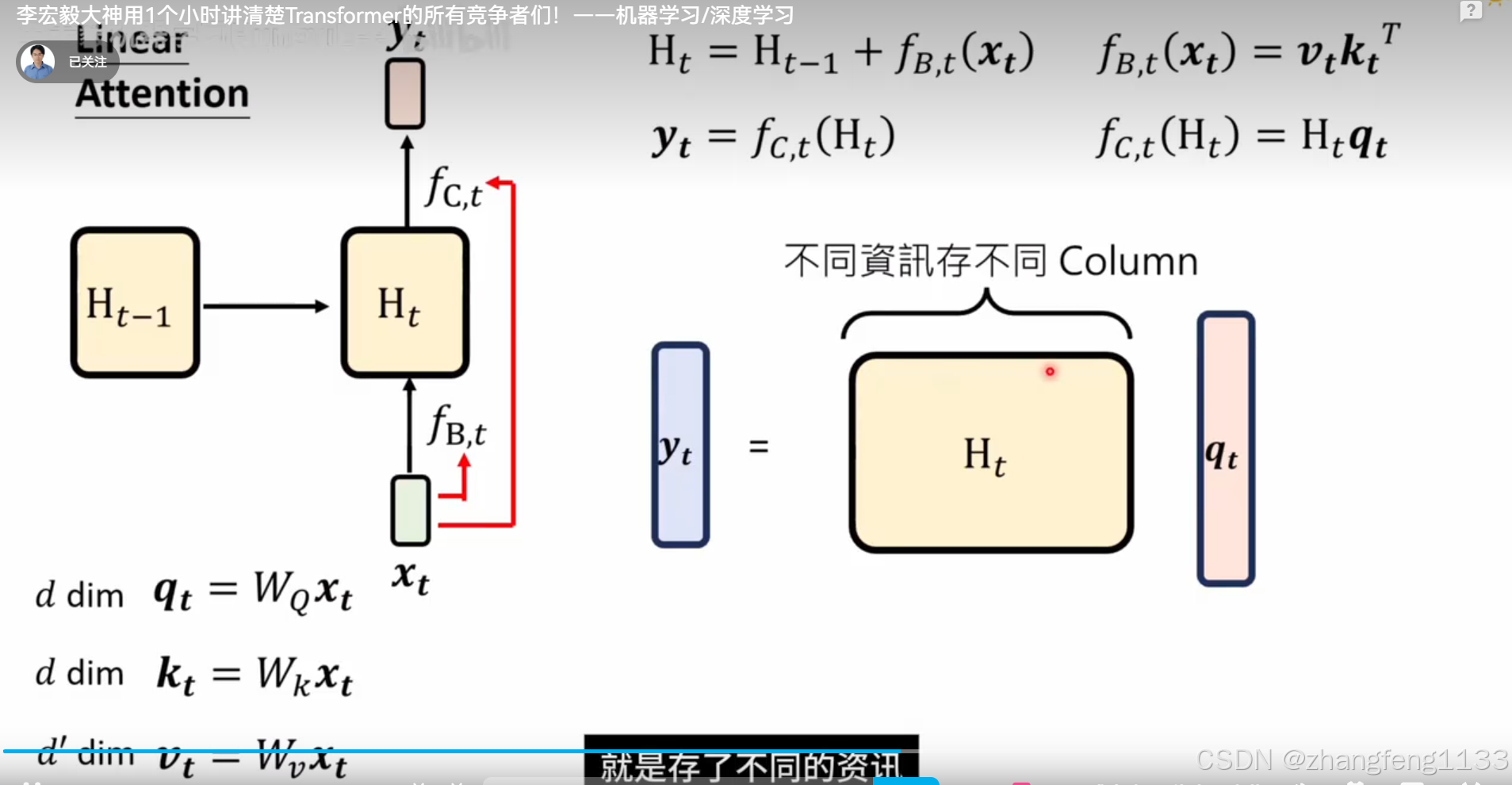
linear attention 2020年

记忆有限 transformer 一样。其实就是少了softmax
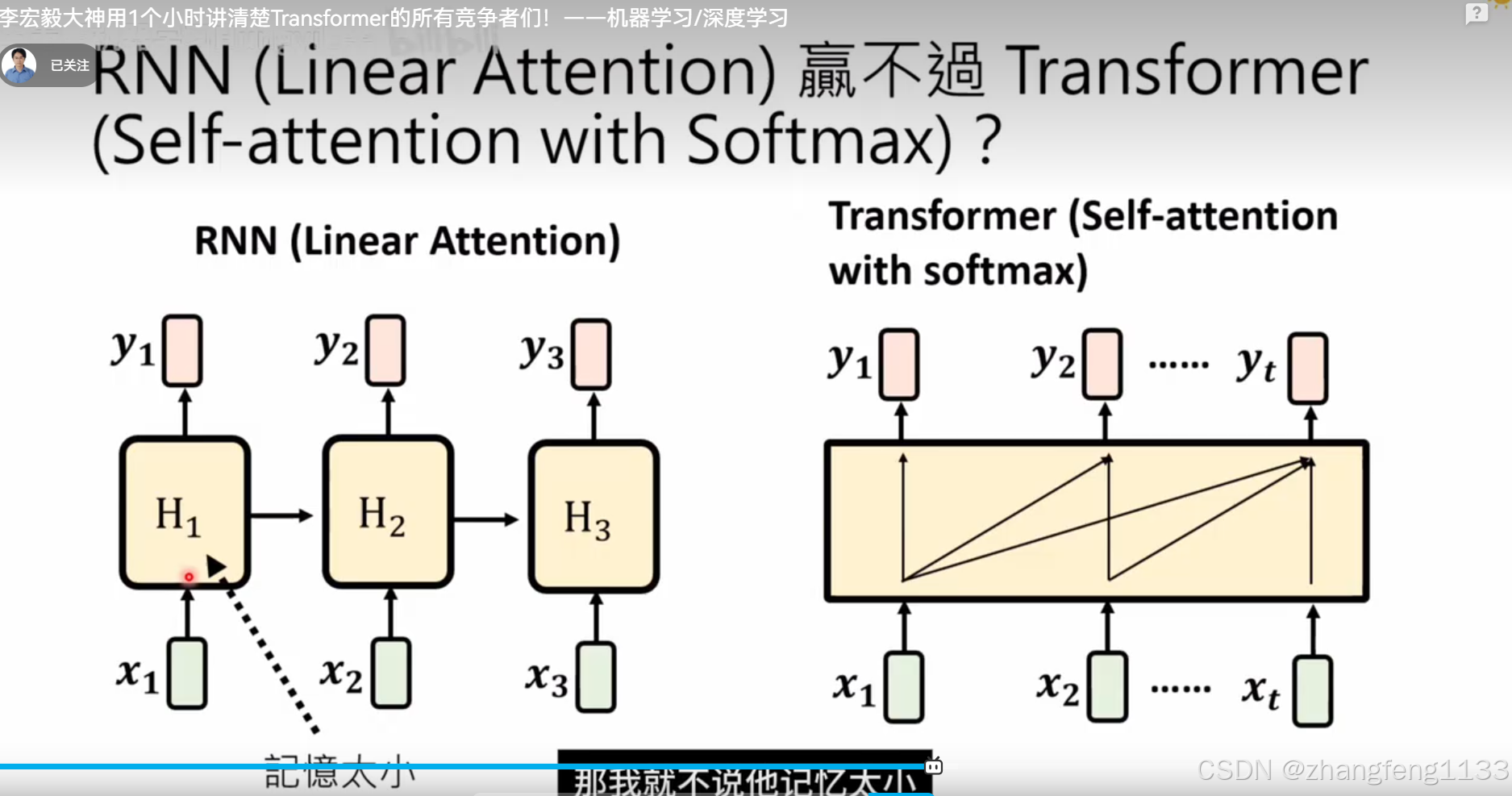
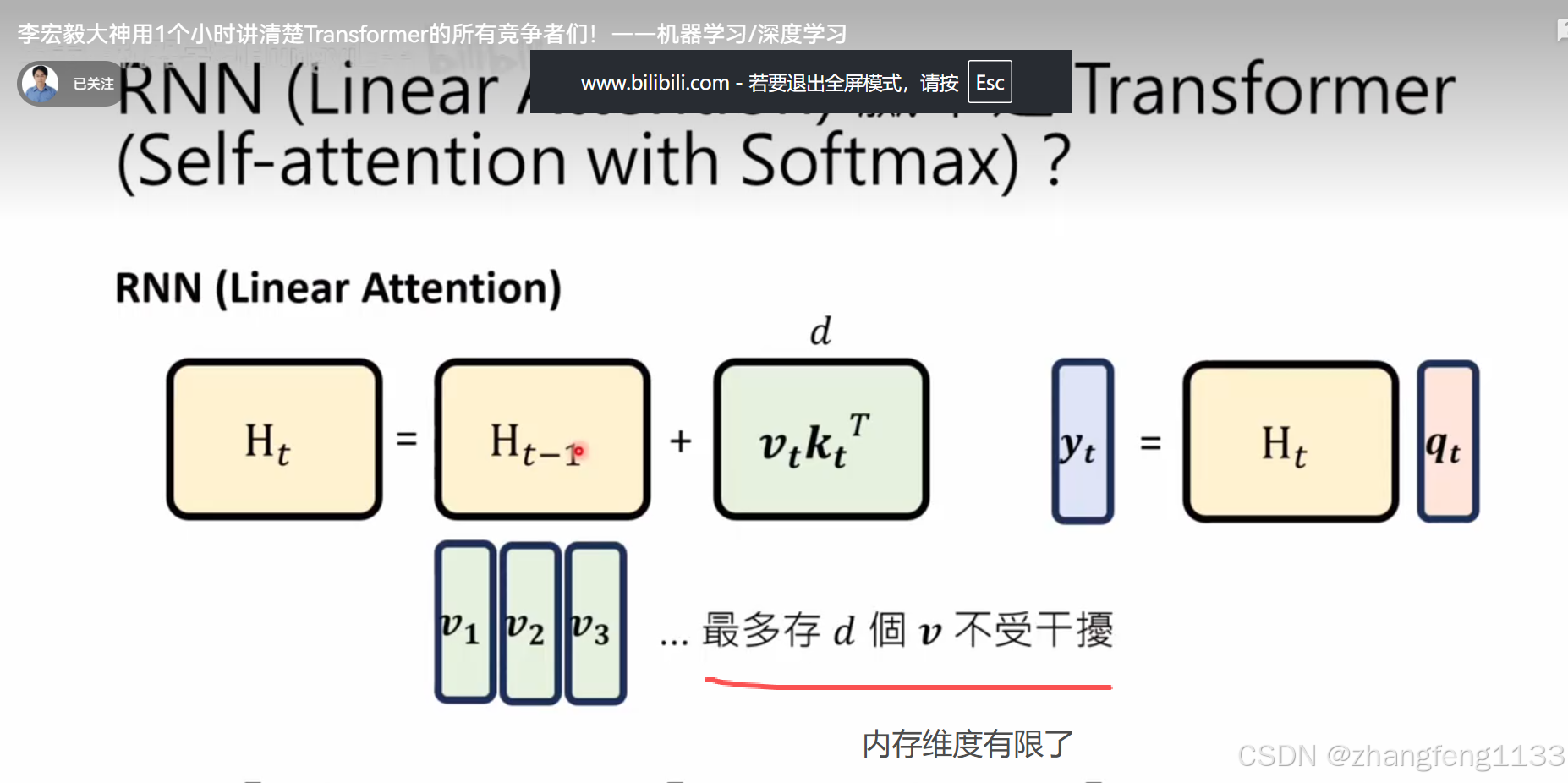
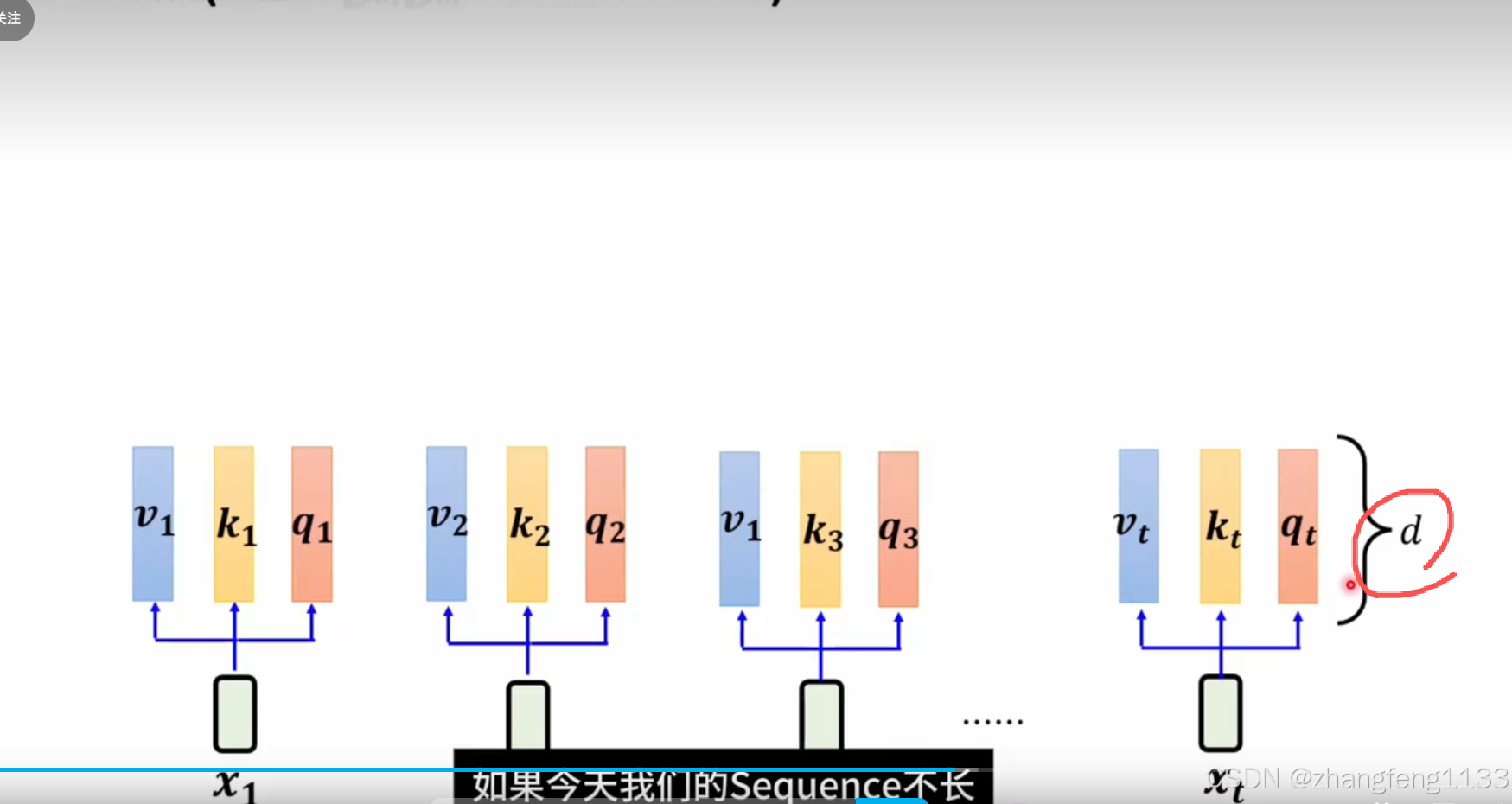
长度够长 数据会重复 ,t>d
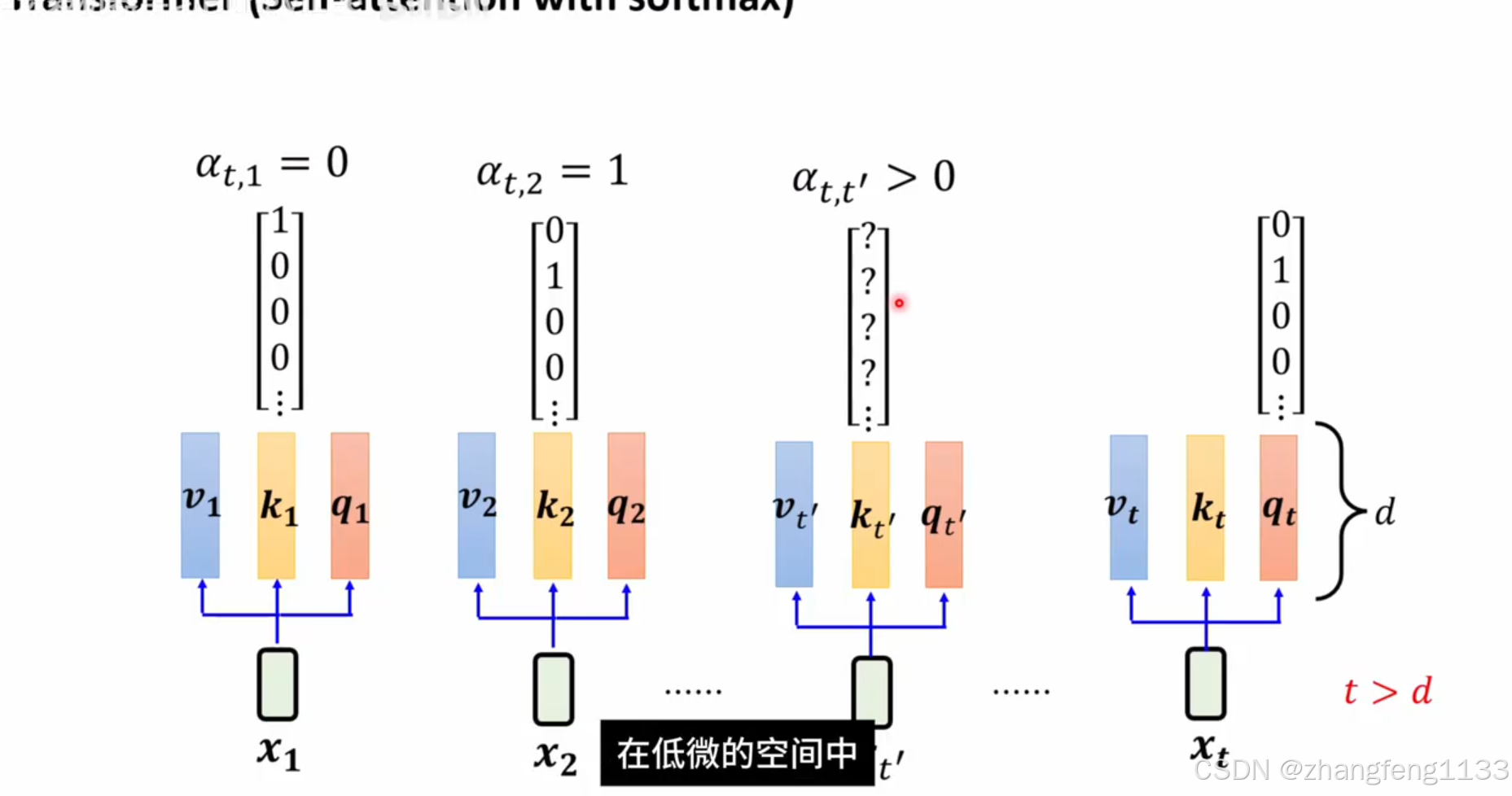
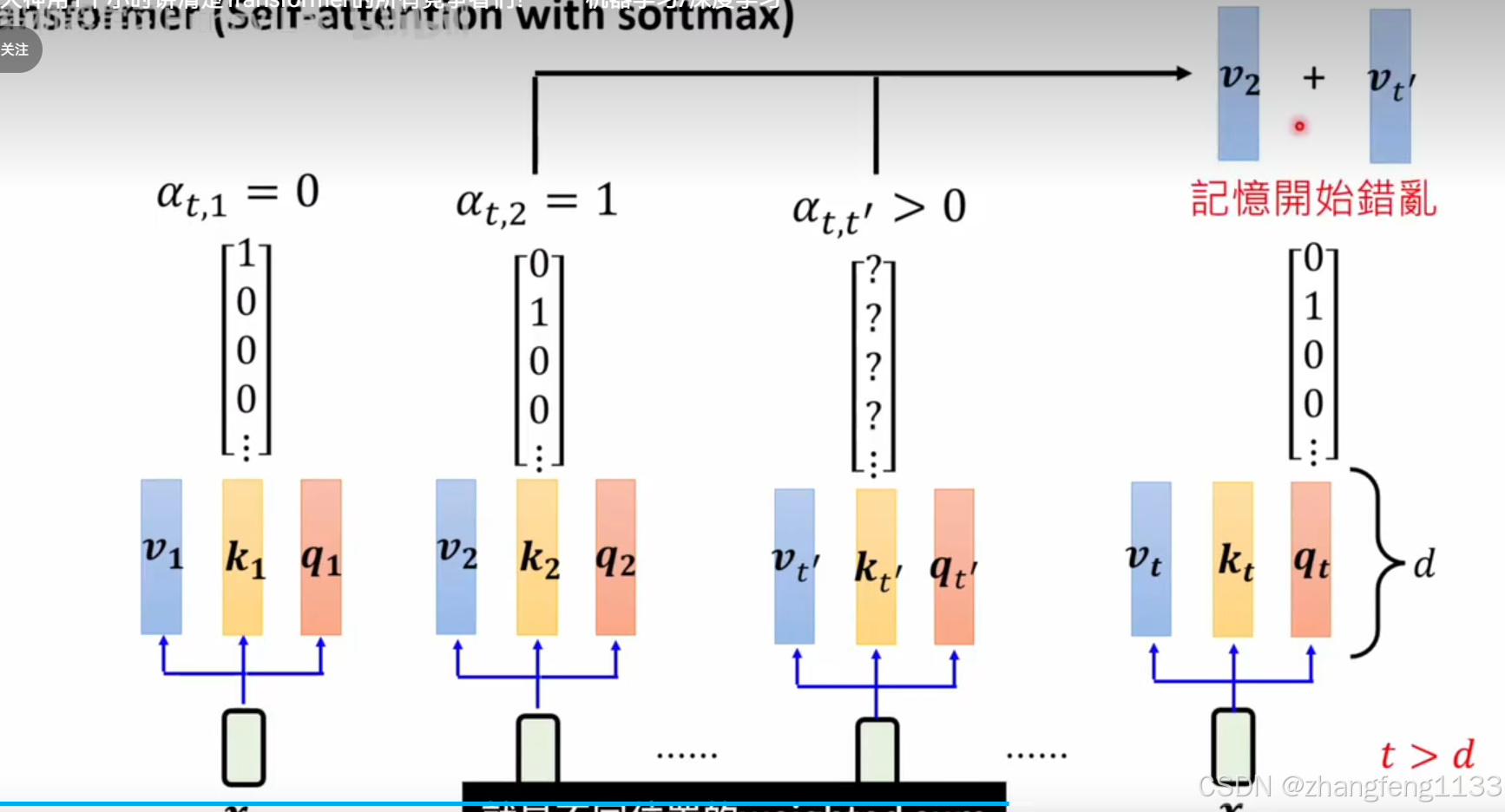
在低维空间中 ,只能找到第一个正交的向量
linear attteion 真正的问题,不会遗忘,固定



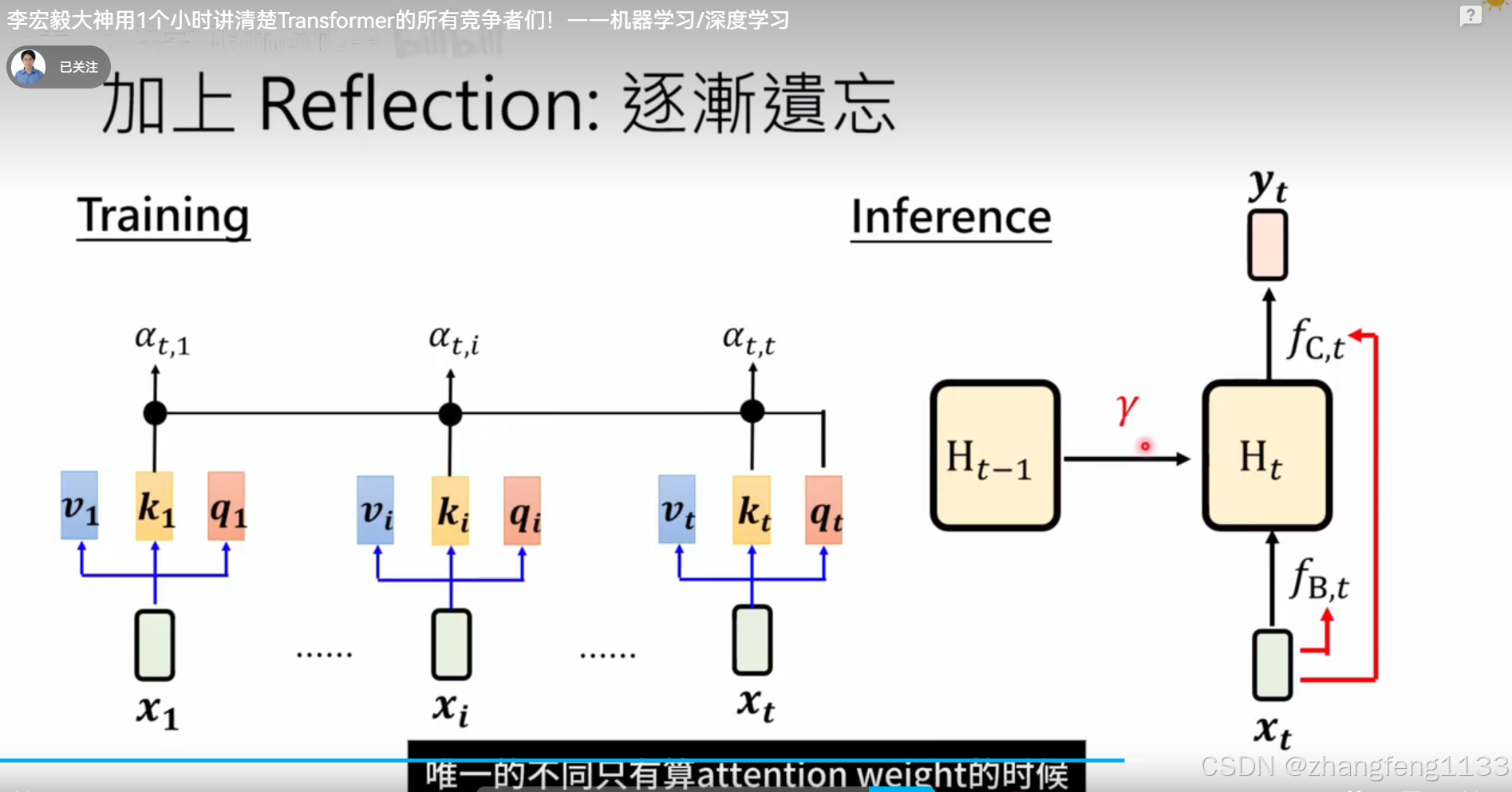

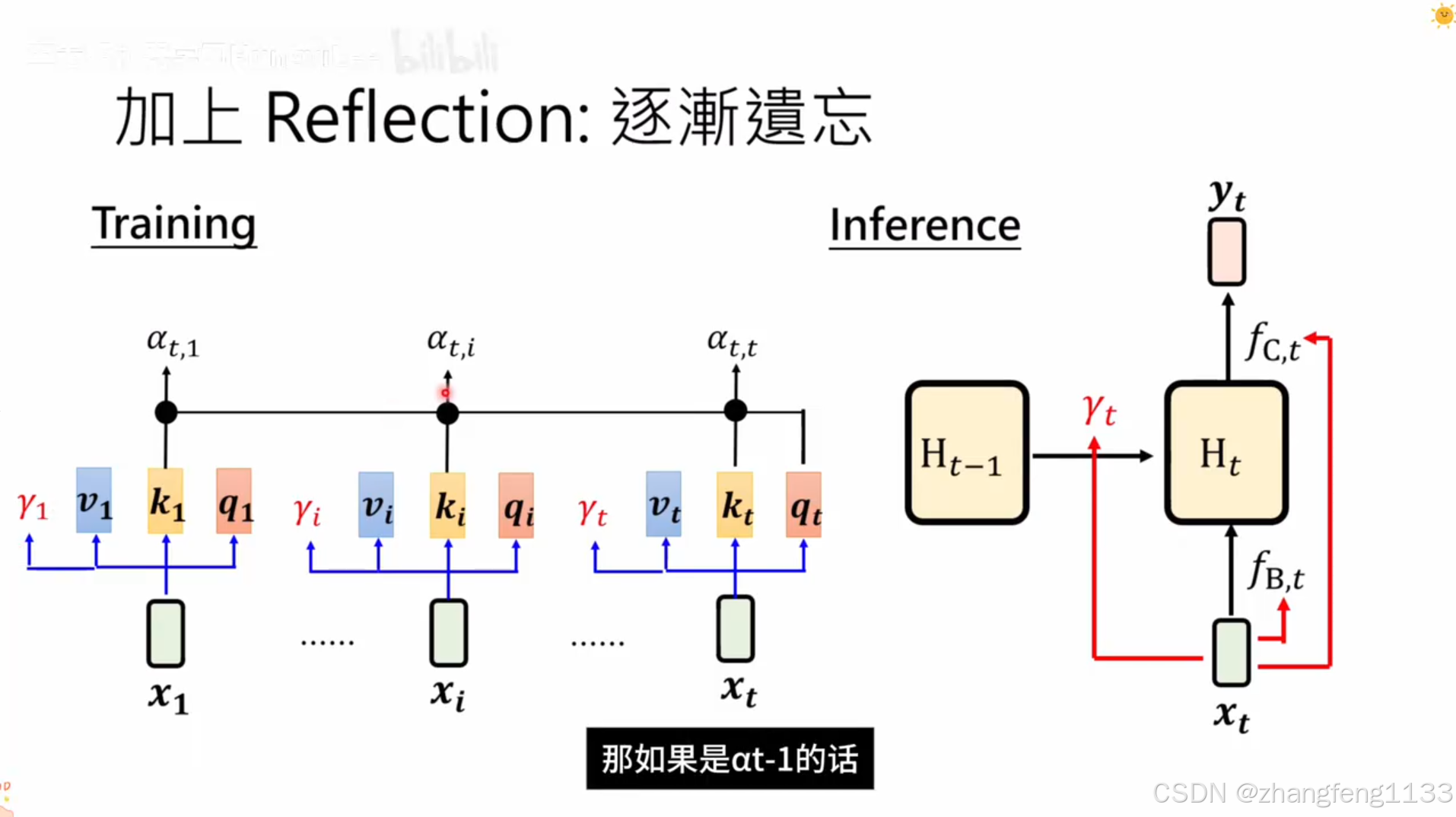
所有lineeare attention 模型列表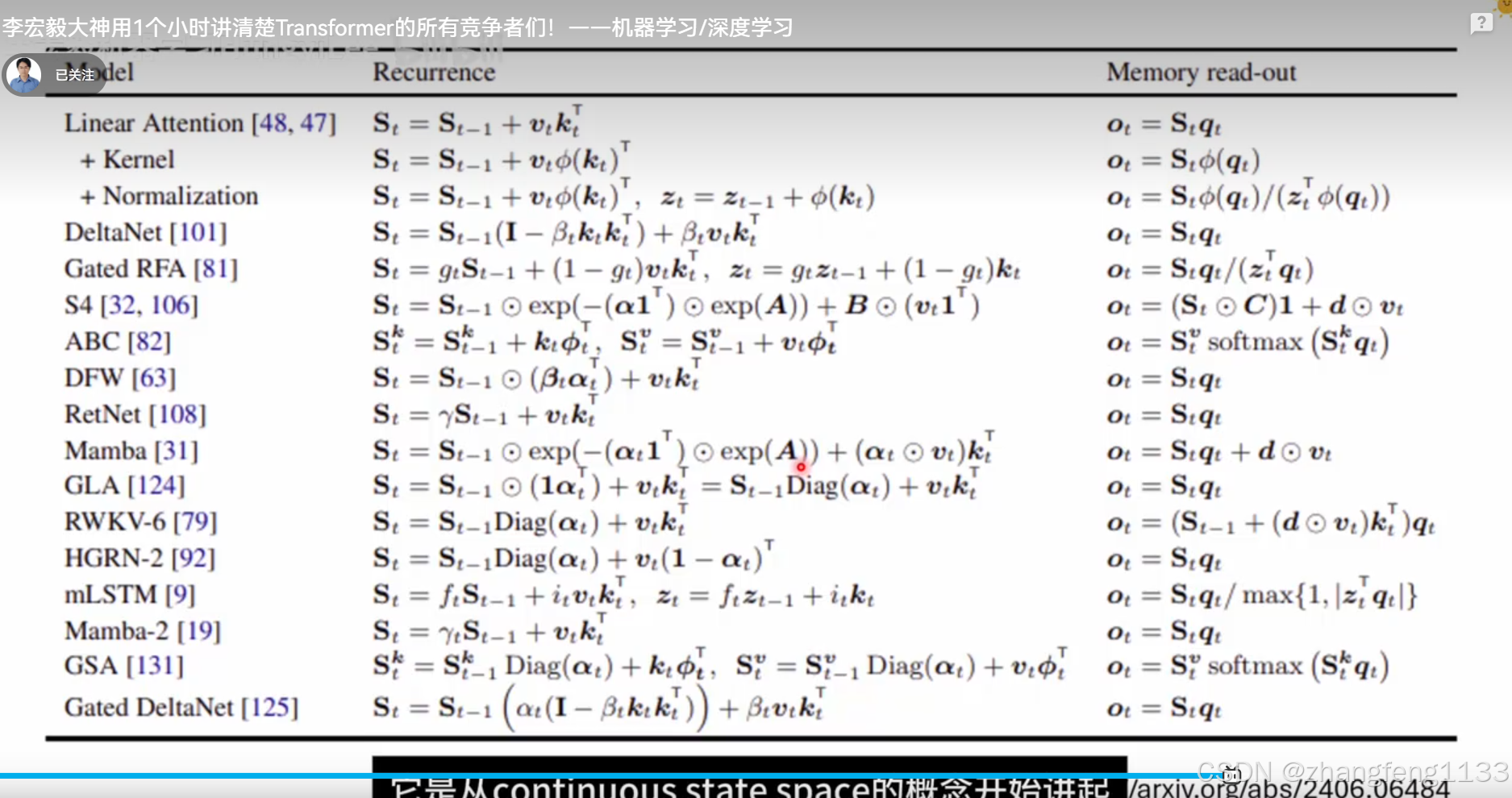
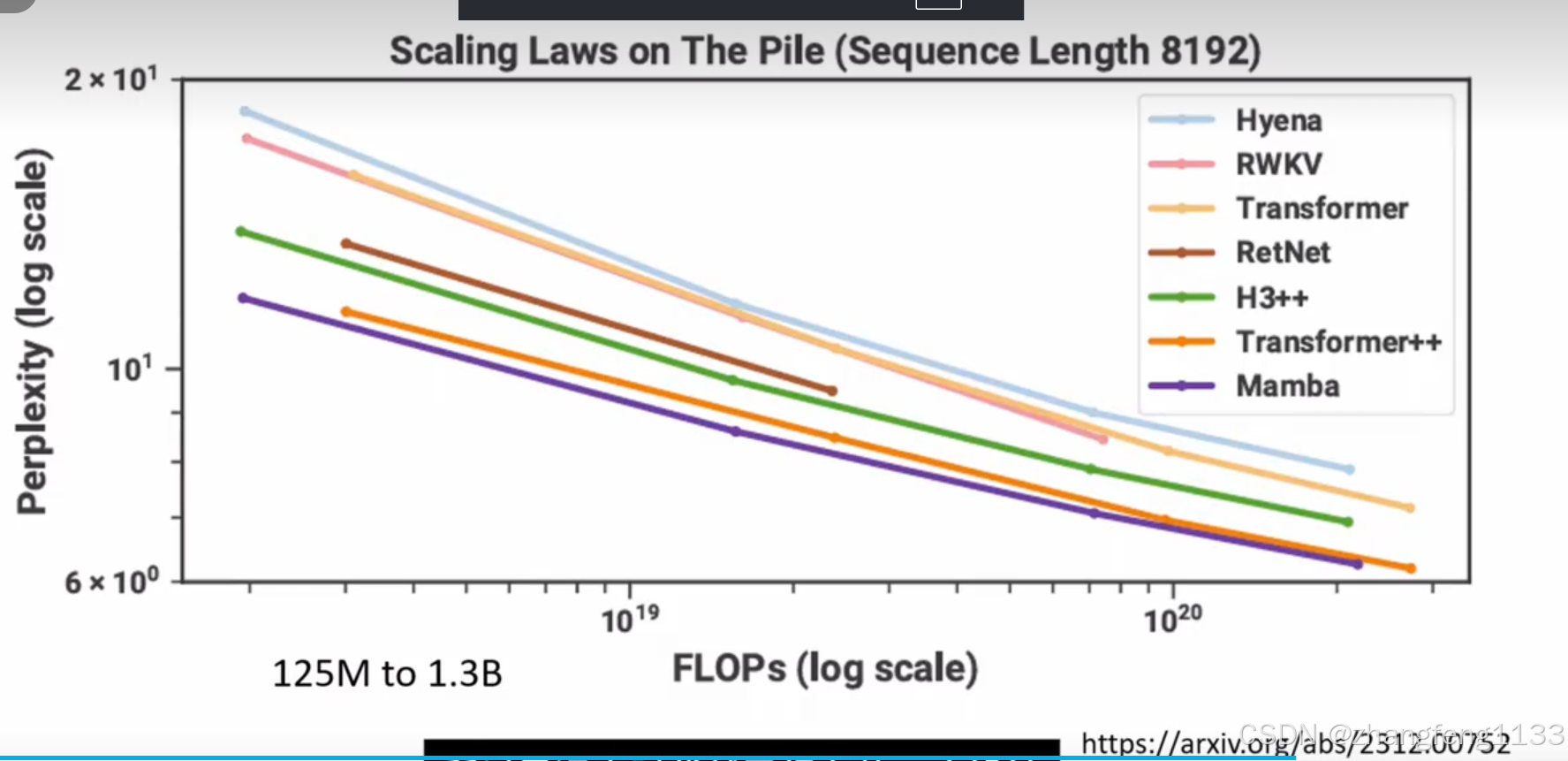
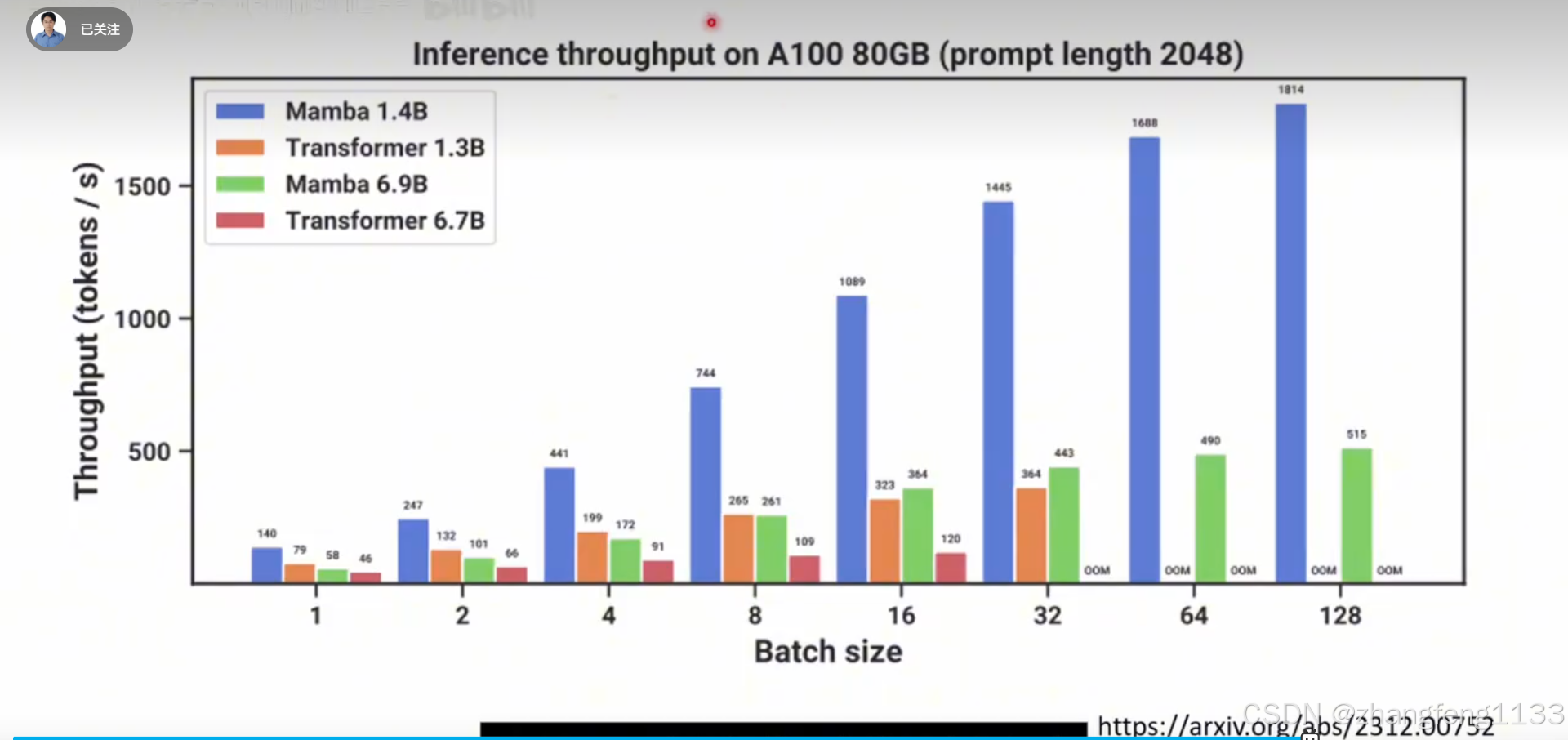
deltanet

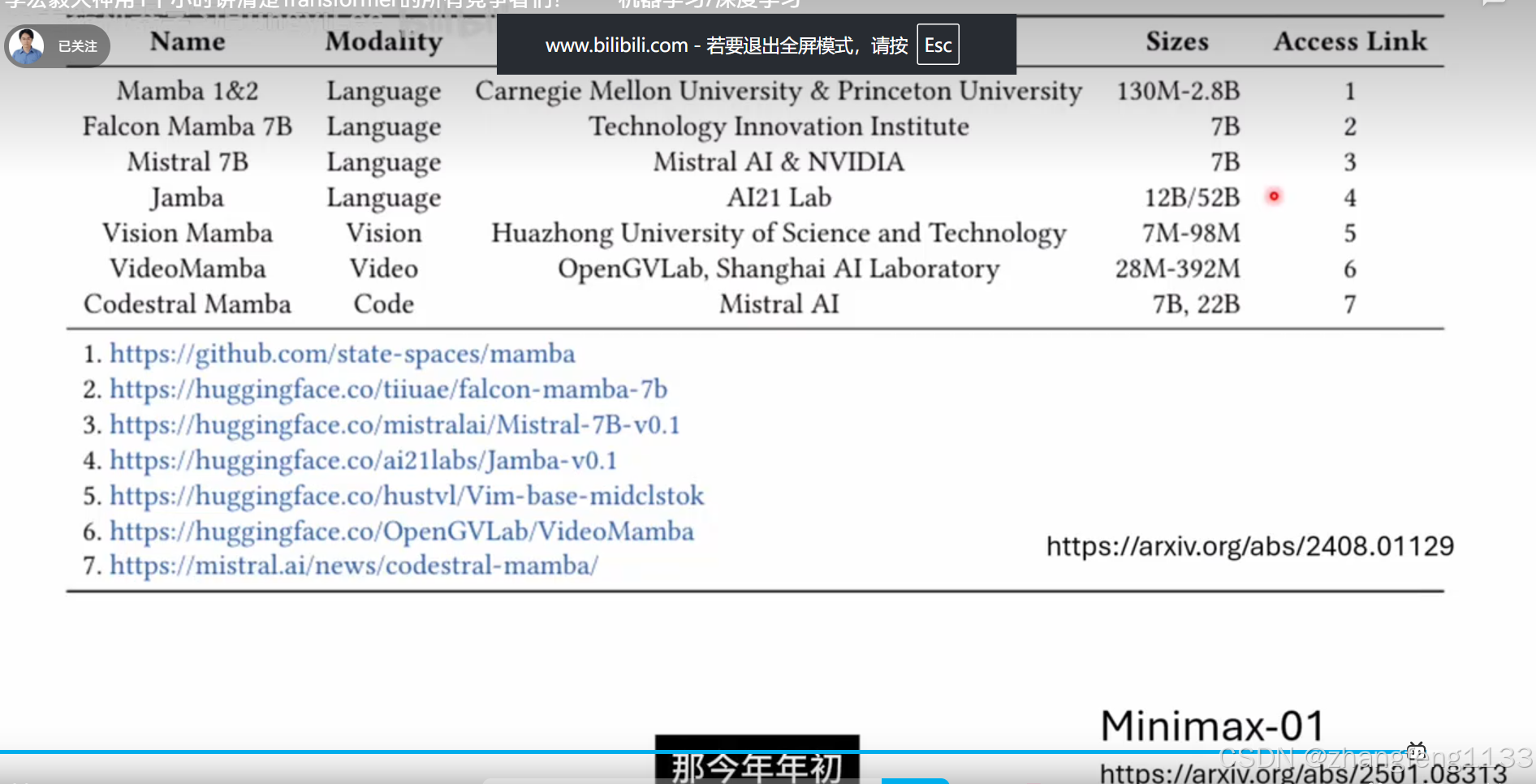
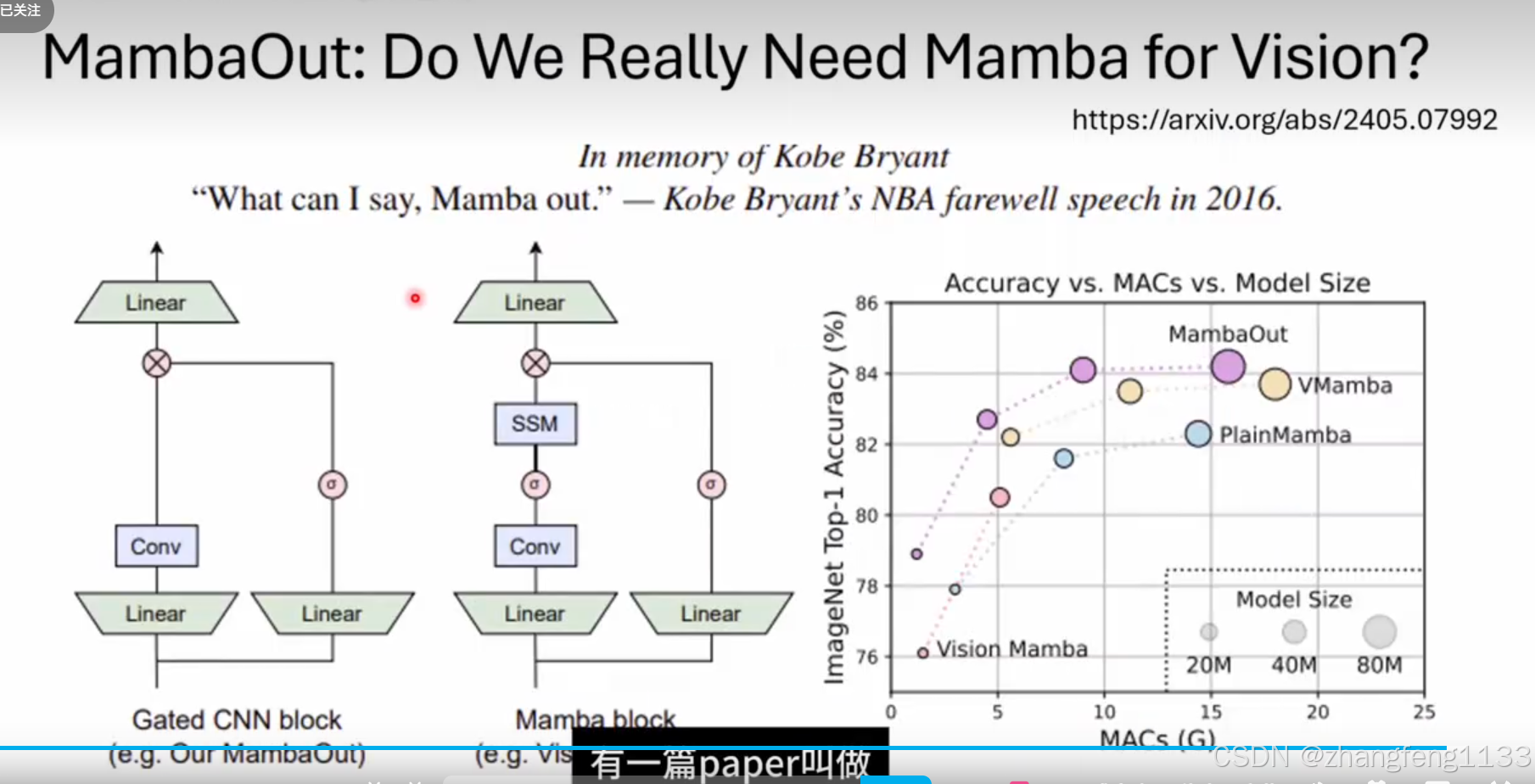
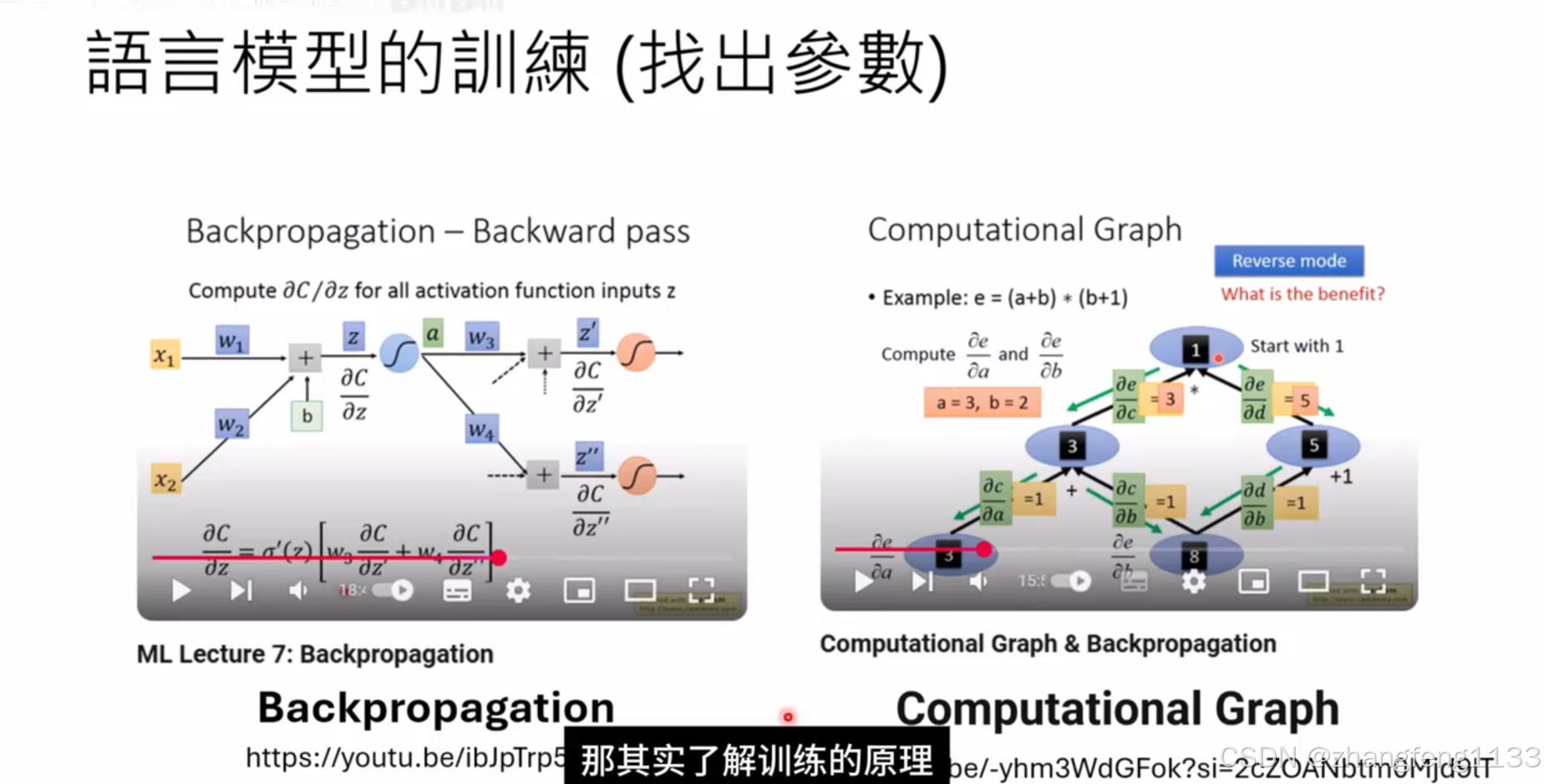
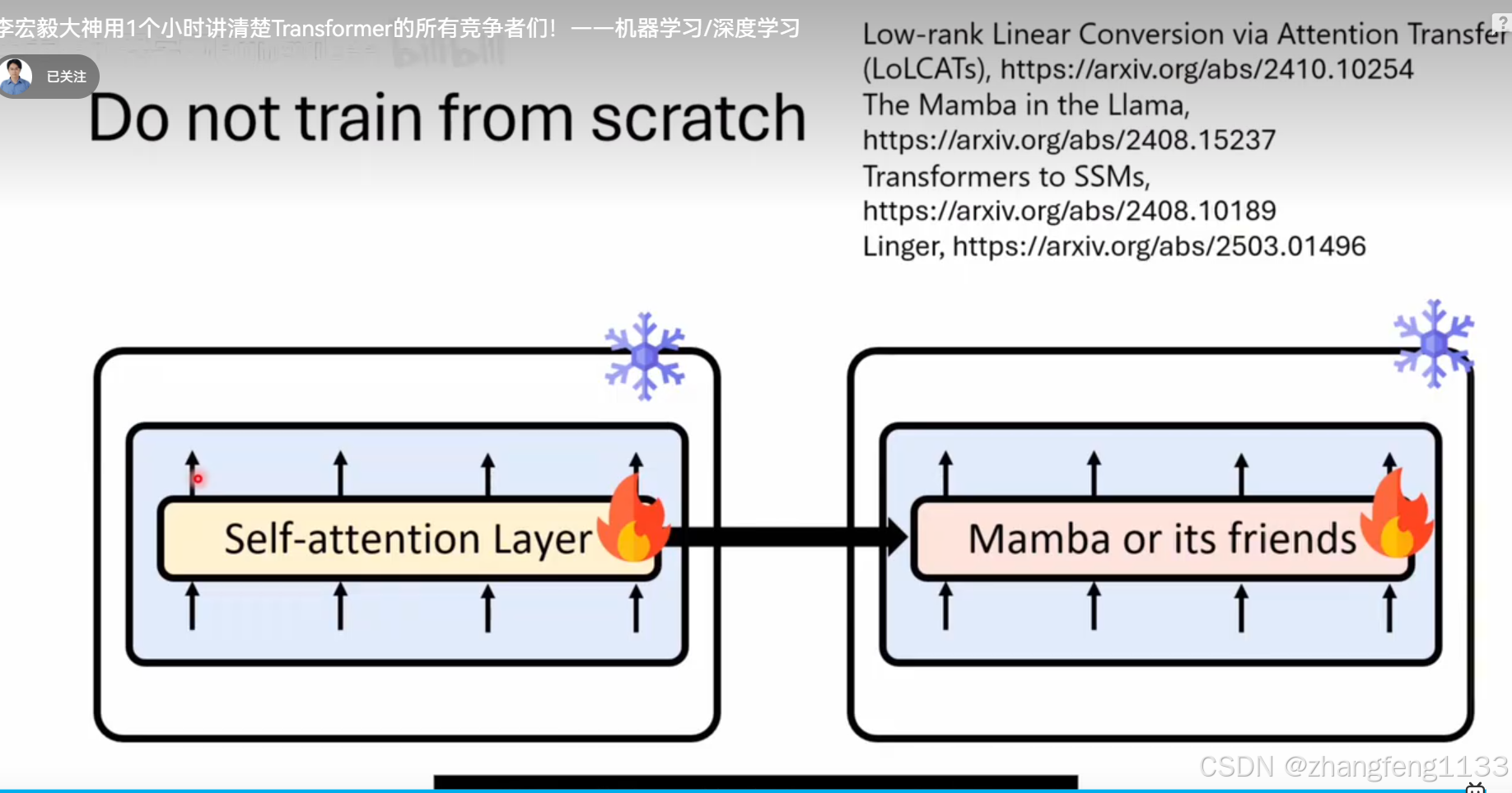
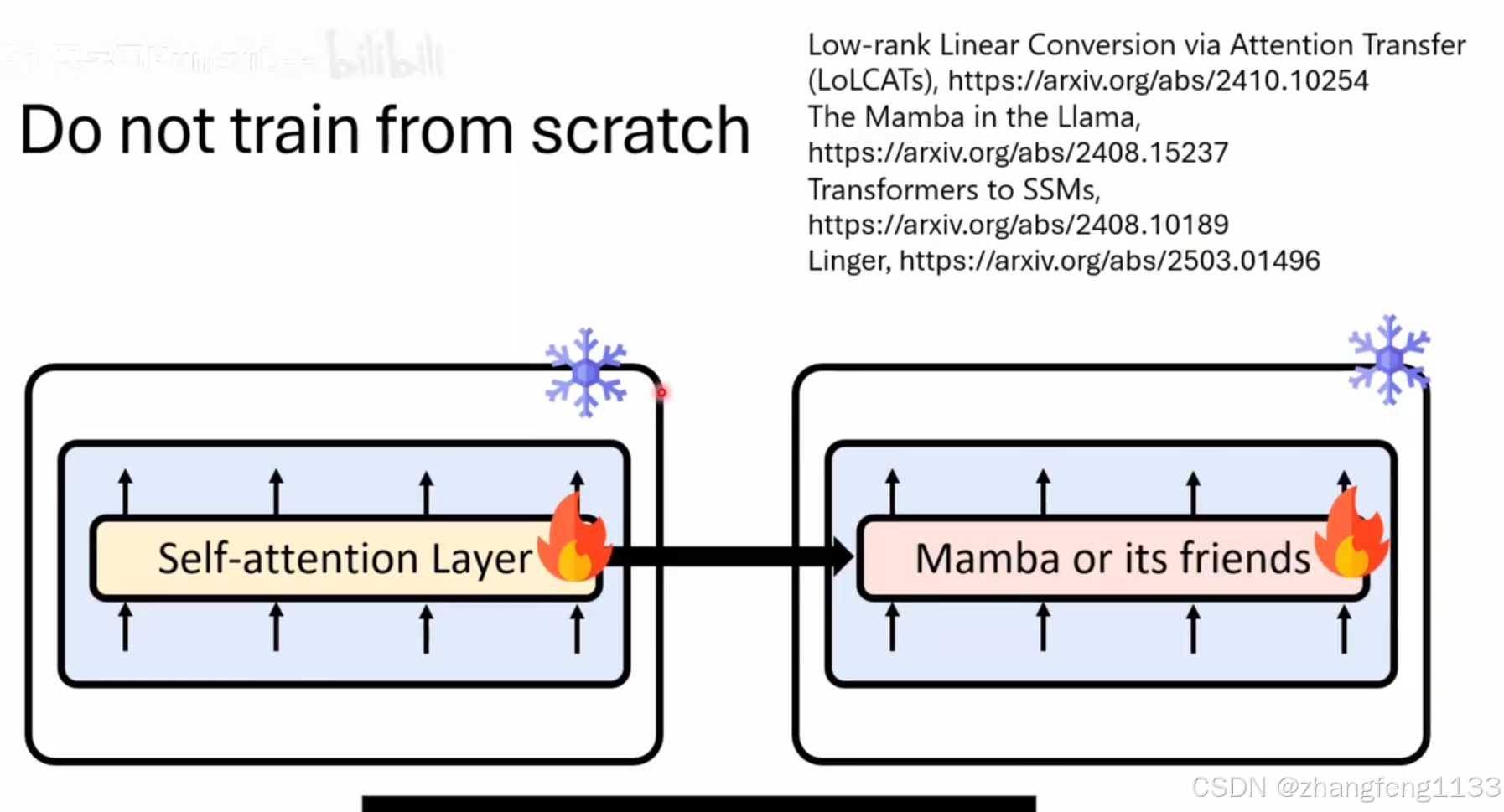
如何训练mamba 现有语言模型,去掉selft-attiion 。然后训练,或者不去掉selft-attention
du局
视频资料
l另外一个视频,