这是一个专注于在 Tesla T4 16GB GPU 上运行的微调框架。框架提供从数据准备、模型训练(SFT/DPO)、合并、量化、评估、验证到最终部署(REST API + Web/CLI 客户端)的全流程支持。核心设计思想是模块化、可扩展和实验可管理,通过统一的命令行接口(cli.py)集成各功能模块。代码依旧在
https://github.com/lxx-com-cn/unsloth-factory
1、设计要点
- 模块划分清晰,职责单一:每个模块独立负责特定功能,便于维护和扩展。
- 实验管理:自动记录每次训练的配置、检查点、结果,支持恢复和对比,是生产环境必不可少的部分。
- 针对tesla T4的优化策略:
- 4-bit量化加载(NF4)限制并发数(1-2)生成后清理KV缓存使用CPU卸载加载大模型(14B)
- 多领域支持:通过知识库动态注入领域知识,验证时可进行针对性检查,未来可扩展更多领域。
- 量化流程完整:支持GGUF(用于llama.cpp)和GPTQ/AWQ(用于vLLM等),便于不同部署场景。
- 验证体系完善:不仅计算指标,还评估思维链质量和多维度评分,确保模型输出安全合理。
- API兼容OpenAI:降低集成成本,流式输出格式标准,客户端可复用现有库。
- Web UI与CLI分离:CLI适合调试,Web UI提供可视化界面,均通过Rest-API调用。
2、技术栈与依赖关系
|--------|-------------------------------------------|--------------|
| 层级 | 技术组件 | 用途 |
| 基础框架 | Python 3.8+, PyTorch 2.0+ | 深度学习基础 |
| 模型加载 | Transformers 4.35+, Unsloth (可选) | 模型加载与优化 |
| 量化训练 | BitsAndBytes, PEFT | 4-bit量化与LoRA |
| 训练框架 | TRL (Transformers Reinforcement Learning) | SFT/DPO训练 |
| 推理服务 | FastAPI, Uvicorn | REST API服务 |
| 数据科学 | datasets, pandas, numpy | 数据处理 |
| 模型量化 | llm-compressor (GPTQ/AWQ) | 生产环境量化 |
| 模型导出 | llama.cpp | GGUF格式导出 |
| 工具库 | jieba, scikit-learn | 中文处理与评估 |
1.1、总体介绍
1.1.1、功能
1、训练流程(SFT)
- 用户通过 cli.py sft 传入参数。
- 实验管理器(ExperimentManager)创建实验目录,保存配置。
- 模型工厂(ModelFactory)加载基础模型(支持Unsloth优化或标准Transformers),根据模型类型(如Qwen3-14B)自动决定是否使用Unsloth。
- 数据集工厂(DatasetFactory)加载数据,支持多文件混合(concat/interleave/weighted),对医学领域强制添加系统提示(强制CoT格式)。
- 基类训练器(BaseTrainer)应用LoRA配置,设置可训练参数。
- 具体训练器(SFTTrainer/DPOTrainer)使用trl库进行训练,支持断点续训(从检查点恢复)。
- 训练完成后保存适配器(final_adapter)并复制原始tokenizer配置。
2、模型合并与量化
- 合并:merge命令调用 model_merger.py,将LoRA适配器合并到基础模型,生成完整HuggingFace格式模型,处理分片索引,避免旧索引干扰。
- 导出GGUF:export命令调用 export.py,使用llama.cpp的 convert_hf_to_gguf.py 转换,并可调用 llama-quantize 进行量化(如q4_0)。
- GPTQ/AWQ量化:convert_awq命令调用独立的 convert_quant.py,使用llm-compressor库,针对T4优化(FP16加载 + CPU卸载),自动生成校准数据,输出量化模型。
3、模型评估(C-Eval)
- evaluate命令调用 Evaluator,目前仅支持C-Eval。
- 加载基础模型和微调模型,对每个学科进行few-shot预测,提取答案字母,计算准确率。
- 保存详细结果和对比报告。
4、模型验证
- validate命令调用 ModelValidator。
- 加载基础模型和微调模型,对验证集生成响应。
- 思维链验证(CotValidator):检测 <think> 标签,评估推理质量和答案一致性。
- 高级验证(AdvancedValidator):基于期望输出,从完整性、准确性、结构性、安全性等多维度评分,使用领域知识库增强检测。
5、推理服务(Server)
- 启动FastAPI应用,提供OpenAI兼容的 /v1/chat/completions 接口。
- 模型管理器(ModelManager)为单例,负责延迟加载模型(使用 ChatSystem),清理显存,提供生成上下文。
- 聊天系统(ChatSystem)加载模型(4-bit量化),构建提示(带系统提示),支持流式生成(通过 TextIteratorStreamer),解析 <think> 标签分离思维链和答案。
- 流式输出:streaming.py 生成SSE格式,包含 think_token 和 content 字段,客户端区分。
- 并发控制:通过上下文管理器限制并发数(T4上建议1-2),生成后清理KV缓存。
6、客户端
- CLI客户端(chat.py):通过requests调用API,支持流式输出,使用ANSI颜色区分思维链(灰色)和答案(亮白)。
- Web UI(web_ui.py):启动另一个FastAPI服务,提供浏览器界面,作为代理转发请求到推理服务,处理流式响应。
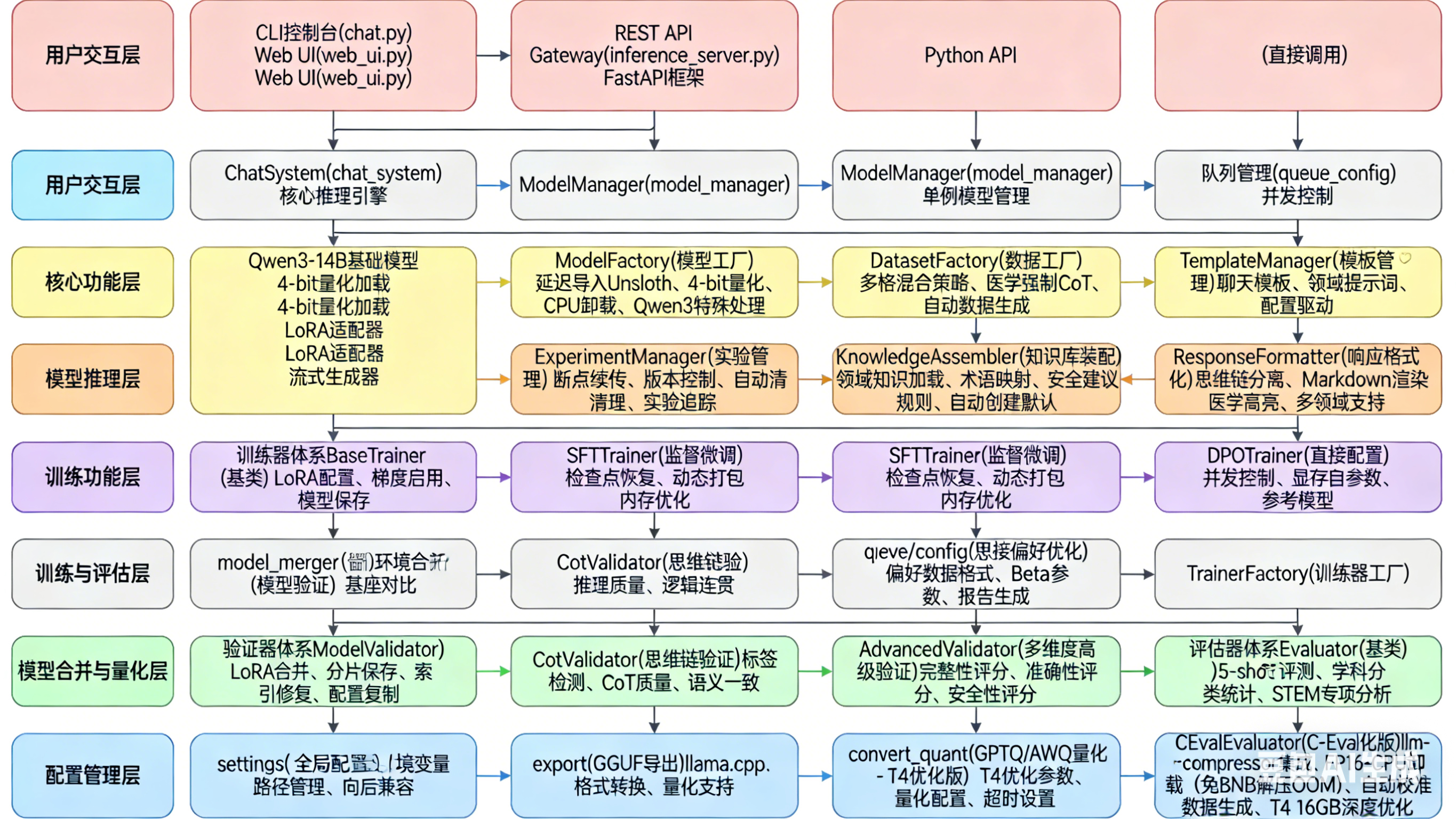
1.1.2、架构
1、微调代码的技术特点:
- 支持多种训练方法:SFT(监督微调)、DPO(直接偏好优化)
- 自动实验管理:创建实验ID、保存配置、检查点恢复
- 多领域支持:医学、金融、法律、教育、心理等,通过知识库增强响应
- 模型量化:GGUF(通过llama.cpp)、GPTQ/AWQ(通过llm-compressor)
- 验证与评估:思维链质量、多维度评分、C-Eval评测
- 部署服务:OpenAI兼容API,流式输出,并发控制(T4优化)
- 客户端:命令行交互(带颜色区分)、Web UI(代理模式)
2、平台代码说明
1)、根文件
cli.py:主命令行入口,解析子命令,分发到各模块,包含实验管理集成。
2)、src/trainers/ - 训练模块
- base_trainer.py:训练器基类,初始化模型、tokenizer、数据集,应用LoRA,保存模型。
- sft_trainer.py:SFT训练器,使用trl的SFTTrainer,封装训练参数和流程。
- dpo_trainer.py:DPO训练器,使用trl的DPOTrainer。
- trainer_factory.py:根据方法名创建对应训练器实例。
3)、src/core/ - 核心组件
- model_factory.py:模型加载工厂,支持Unsloth和标准Transformers,检测模型类型,合并适配器,获取LoRA目标模块。
- dataset_factory.py:数据集加载工厂,支持多文件混合、数据限制、领域系统提示。
- template_manager.py:模板管理器(当前未使用,可能用于未来对话模板管理)。
- experiment_manager.py:实验管理器,创建实验、保存配置、管理检查点、恢复训练、列出/清理实验。
4)、src/validators/ - 验证模块
- cot_validator.py:思维链验证器,检测CoT格式,评估推理质量和一致性。
- validator.py:模型验证器,加载模型生成响应,调用cot_validator,保存结果。
- advanced_validator.py:高级多维度验证器,基于期望输出评分,使用知识库增强。
5)、src/evaluators/ - 评估模块
- ceval_evaluator.py:C-Eval评估实现,加载数据集、构建提示、提取答案、计算准确率。
- evaluator.py:评估器主类,调用具体任务(目前仅ceval),保存对比报告。
6)、src/merger/ - 合并与量化
- model_merger.py:合并LoRA到基础模型,处理分片索引。
- export.py:导出HF模型到GGUF并量化,调用llama.cpp工具。
- convert_quant.py:使用llm-compressor进行GPTQ/AWQ量化,针对T4优化。
7)、src/server/ - 推理服务
- config.py:服务器配置类,从环境变量或默认值加载,针对T4优化。
- model_manager.py:模型管理器(单例),负责模型加载/卸载、显存清理、提供生成上下文。
- chat_system.py:核心推理引擎,加载模型,构建提示,生成响应(流式/非流式),解析思维链,管理会话历史。
- inference_server.py:FastAPI应用,定义API端点,处理请求,调用model_manager。
- schemas.py:Pydantic请求/响应模型。
- streaming.py:流式响应生成器,处理SSE格式。
8)、src/chat/ - 客户端
- chat.py:CLI客户端,通过API调用服务,支持流式和颜色区分。
- web_ui.py:Web UI服务,代理请求到推理服务,提供HTML界面。
9)、src/config/ - 配置
settings.py:全局静态配置(模型路径、API地址等)。
10)、src/utils/ - 工具函数
- helpers.py:各类辅助函数:资源监控、内存使用、日志设置、数据集统计、响应清理、领域验证、复制配置文件等。
- formatter.py:响应格式化器,去除think标签,应用markdown和领域高亮(当前未使用,可能用于客户端展示)。
1.1.3、环境
这里需要设定2个环境,因为支持gptq/awq格式需要llmcompressor,有潜在冲突风险
---uf8---
conda remove --name uf8 --all
conda create -n uf8 python=3.11 -y
conda activate uf8
pip install \
torch==2.6.0+cu124 \
torchvision==0.21.0+cu124 \
torchaudio==2.6.0+cu124 \
--index-url https://download.pytorch.org/whl/cu124 \
--trusted-host download.pytorch.org
# 安装Unsloth和相关依赖
pip install \
unsloth==2025.10.6 \
unsloth-zoo==2025.10.6 \
accelerate==1.7.0 \
xformers==0.0.29.post3 \
triton==3.2.0 \
transformers==4.52.4 \
peft==0.15.2 \
trl==0.12.0 \
datasets==3.6.0 \
--index-url https://pypi.tuna.tsinghua.edu.cn/simple \
--trusted-host pypi.tuna.tsinghua.edu.cn
pip install evaluate
pip install gputil
---vllm---
conda remove --name vllm --all
conda create -n vllm python=3.11 -y
conda activate vllm
# 1.2 如果使用pip,可以按以下方式安装特定CUDA版本的vLLM:
# 安装CUDA 12.8版本的vLLM pip install vllm --extra-index-url https://download.pytorch.org/whl/cu128
# 安装CUDA 11.8版本的vLLM pip install vllm --extra-index-url https://download.pytorch.org/whl/cu118
# 安装CUDA 12.6版本的vLLM (当前使用这个版本)
pip install vllm --extra-index-url https://download.pytorch.org/whl/cu126
pip install accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install llmcompressor
sudo lsof -i :8000
vllm 默认是 8000 端口1.2、微调
1.2.1、微调流程
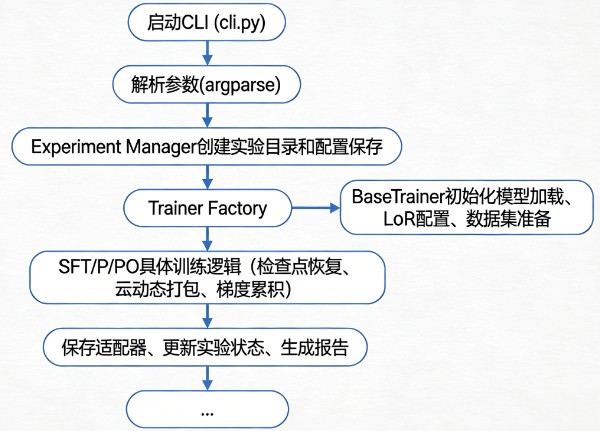
训练流程解读
- 在模型训练的核心流程中,用户通过命令行入口 cli.py 启动训练任务。cli.py 首先利用 argparse 解析用户传入的参数,并根据命令类型将控制权转交给相应的模块。
- 实验管理器(ExperimentManager)被调用,它根据任务名称、领域以及时间戳自动创建一个唯一的实验目录,并将本次训练的所有配置参数以 JSON 格式保存到该目录中,为后续的断点恢复和结果追溯奠定基础。
- 训练器工厂(TrainerFactory)根据命令类型实例化对应的训练器------若是 sft 则创建 SFTTrainer,若是 dpo 则创建 DPOTrainer。在训练器初始化过程中,基类 BaseTrainer 会执行一系列关键准备:通过模型工厂(ModelFactory)加载基础模型(根据模型类型自动选择是否使用 Unsloth 优化),应用 LoRA 配置(设置目标模块、秩、Alpha 等超参数),并通过数据集工厂(DatasetFactory)加载并预处理训练数据(支持多文件混合、数据限制,并对医学领域强制添加思维链格式的系统提示)。
- 完成初始化后,具体训练器(如 SFTTrainer)开始执行训练循环,其中集成了检查点恢复机制、动态打包策略,以及梯度累积等优化技术。训练过程中,模型会根据预设的步数定期保存检查点,并在训练结束时将最终的 LoRA 适配器保存到实验目录下的 final_adapter 文件夹中,同时复制原始模型的 tokenizer 配置文件以确保兼容性。
- 实验管理器会更新实验状态为"已完成",并记录最终的训练步数和损失值,方便用户后续查阅和对比。整个流程高度自动化且可复现,体现了框架的模块化设计与实验管理理念。
1.2.2、代码解读
|--------------------|--------|----------------|----------------------------|
| 文件 | 功能 | 核心类/函数 | 关键特性 |
| base_trainer.py | 训练基类 | BaseTrainer | • 延迟导入Unsloth避免patch冲突 |
| base_trainer.py | 训练基类 | BaseTrainer | • 自动LoRA配置(qwen3_14b目标模块) |
| base_trainer.py | 训练基类 | BaseTrainer | • 强制梯度启用检查 |
| base_trainer.py | 训练基类 | BaseTrainer | • 实验管理器集成 |
| sft_trainer.py | 监督微调 | SFTTrainer | • 检查点自动发现与恢复 |
| sft_trainer.py | 监督微调 | SFTTrainer | • 动态packing决策(基于数据集统计) |
| sft_trainer.py | 监督微调 | SFTTrainer | • 内存优化配置(paged_adamw_8bit) |
| sft_trainer.py | 监督微调 | SFTTrainer | • 实验状态追踪 |
| dpo_trainer.py | 直接偏好优化 | DPOTrainer | • 偏好数据格式验证 |
| dpo_trainer.py | 直接偏好优化 | DPOTrainer | • Beta参数控制 |
| dpo_trainer.py | 直接偏好优化 | DPOTrainer | • 参考模型自动使用当前模型 |
| trainer_factory.py | 训练器工厂 | TrainerFactory | • 策略模式创建训练器 |
| trainer_factory.py | 训练器工厂 | TrainerFactory | • 预留KTO/PPO/RM扩展位 |
1.2.3、数据准备
网上能找到COT医疗训练数据很难,于是自己通过投喂LLM获得了一些数据,并转为了json,以方便微调。该数据放在了dataset路径下,截至当前数据大概有8w条左右,将来还会再丰富更多的COT医疗数据。
投喂生成的数据,还需要检查下格式和引号问题,避免训练出错。于是编写了几个脚本放在了dataset目录下,具体使用如下:
检查JSON格式和output字段完整性的代码:
python check_json.py medical_cn2w.json
(base) yaoxp@ubt22ai3:~/work/code/llm-unsloth/tests$ python check_json.py medical_cn2w.json
JSON格式检查工具
============================================================
检查文件: ../data/raw/medical/medical_cn2w.json
文件大小: 17709.71 KB
------------------------------------------------------------
✓ JSON格式验证通过
✓ 数据格式为数组,包含 18891 条记录
------------------------------------------------------------
------------------------------------------------------------
检查完成!
总记录数: 18891
有效记录数: 18891 (100.0%)
问题记录数: 0 (0.0%)
============================================================
数据样本检查(前3条有效记录):
--- 第1条样本 ---
。。。。
<think>长度: 743 字符
句子数量: 22
--- 第2条样本 ---
。。。。
句子数量: 21
--- 第3条样本 ---
。。。
<think>长度: 411 字符
句子数量: 15
============================================================
建议:
✓ 所有记录格式正确,可以用于微调
1、先依次检查其他json微调数据
python check_json.py 儿科3w.json
python check_json.py 妇产科2w.json
python check_json.py 男科2w.json
2、然后修复嵌套双引号的问题
单一职责:只做一件事------扫描文本并移除output值内部的引号
健壮的状态机:明确区分normal和output_value两种状态
转义字符正确处理:保留 \开头的转义序列(如\\, \", \n)
跨行天然支持:逐字符处理,无需特殊逻辑即可处理跨行字符串
性能优化:单次扫描完成,时间复杂度O(n)
清晰的验证:处理完立即验证JSON合法性,失败则给出错误位置
fix_quotes.py medical_cn2w.json medical_cn2w-fix.json
python fix_quotes.py 男科2w.json 男科2w-fix.json
python fix_quotes.py 儿科3w.json 儿科3w-fix.json
python fix_quotes.py 妇产科2w.json 妇产科2w-fix.json
3、最后检查
python check_json.py 男科2w-fix.json
python check_json.py 儿科3w-fix.json
python check_json.py 妇产科2w-fix.json
python check_json.py medical_cn2w-fix.json数据检测无误后才能使用,避免微调中报错。该微调数据能正常微调,但在随后的validate暴露了一些问题,在validate环境会详细解读。
1.2.4、指令定义
CUDA_VISIBLE_DEVICES=1 python cli.py sft \
--model /home/yaoxp/models/Qwen3-14B/ \
--domain medical \
--dataset "datasets/男科2w-fix.json,datasets/儿科3w-fix.json,datasets/妇产科2w-fix.json,datasets/medical_cn2w-fix.json" \
--dataset_format alpaca \
--mixing_strategy weighted \
--epochs 3 \
--max_seq_length 4096 \
--batch_size 1 \
--accumulation_steps 2 \
--dataloader_workers 4 \
--learning_rate 3e-5 \
--no_packing \
--lr_scheduler_type cosine \
--save_steps 100 \
--logging_steps 10 \
--output_dir output/sft-qwen3-14b \
--experiments_root output/experiments
该指令提供了多个微调文件,并划分了权重,并且支持实验室隔离以及继续执行模式
如果想简单拼接所有数据(不按权重),可以改为:
--mixing_strategy concat \ # 去掉 --dataset_weights 参数
控制权重和微调数量
--dataset_weights "0.2,0.2,0.3,0.3" \
--data_limit 2000 \
中途微调断开,需要在最后save处继续执行
--resume auto1.2.5、执行与日志
全量执行
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$ python cli.py sft \
--model /home/yaoxp/models/Qwen3-14B/ \
--domain medical \
--dataset "datasets/男科2w-fix.json,datasets/儿科3w-fix.json,datasets/妇产科2w-fix.json,datasets/medical_cn2w-fix.json" \
--dataset_format alpaca \
--mixing_strategy weighted \
--epochs 3 \
--max_seq_length 4096 \
--batch_size 1 \
--accumulation_steps 2 \
--dataloader_workers 4 \
--learning_rate 3e-5 \
--no_packing \
--lr_scheduler_type cosine \
--save_steps 100 \
--logging_steps 10 \
--output_dir output/sft-qwen3-14b \
--experiments_root output/experiments
Unsloth: Will patch your computer to enable 2x faster free finetuning.
Skipping import of cpp extensions due to incompatible torch version 2.6.0+cu124 for torchao version 0.16.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
Unsloth Zoo will now patch everything to make training faster!
INFO:src.utils.helpers: 日志系统已初始化
INFO:src.core.experiment_manager: 创建实验: sft_medical_002_0305_164240
INFO:src.core.experiment_manager: 实验目录: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_164240
INFO:src.trainers.trainer_factory: 创建 SFT 训练器
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|███████████████████████████████| 8/8 [01:27<00:00, 11.00s/it]
WARNING:src.core.dataset_factory: 数据集信息文件不存在: /home/yaoxp/work/sft/uf8/datasets/dataset_info.json,使用默认配置
Generating train split: 15635 examples [00:00, 34258.31 examples/s]
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/男科2w-fix.json,样本数: 15635
INFO:src.core.dataset_factory: 成功加载: datasets/男科2w-fix.json (15635 样本)
Generating train split: 26712 examples [00:00, 58449.70 examples/s]
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/儿科3w-fix.json,样本数: 26712
INFO:src.core.dataset_factory: 成功加载: datasets/儿科3w-fix.json (26712 样本)
Generating train split: 26036 examples [00:00, 75757.85 examples/s]
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/妇产科2w-fix.json,样本数: 26036
INFO:src.core.dataset_factory: 成功加载: datasets/妇产科2w-fix.json (26036 样本)
Generating train split: 18891 examples [00:00, 24210.09 examples/s]
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/medical_cn2w-fix.json,样本数: 18891
INFO:src.core.dataset_factory: 成功加载: datasets/medical_cn2w-fix.json (18891 样本)
WARNING:src.core.dataset_factory: 权重不匹配,使用平均权重
INFO:src.core.dataset_factory: 多数据集混合完成: 4个文件 -> 62540总样本
INFO:src.trainers.base_trainer: 总参数: 8226503680, 可训练参数: 64225280 (0.78%)
INFO:src.utils.helpers: 数据集统计: 总样本=62540, 空样本=0
INFO:src.utils.helpers: 文本长度: 最小=369, 最大=5140, 平均=718.79
INFO:src.trainers.sft_trainer: 创建训练器前内存使用: 内存: 2.17 GB, 显存: 10144.00 MB
Map: 100%|████████████████████████████████████| 62540/62540 [00:55<00:00, 1132.44 examples/s]
INFO:src.trainers.sft_trainer: 开始medical领域的SFT训练...
INFO:src.trainers.sft_trainer: 实验ID: sft_medical_002_0305_164240
INFO:src.trainers.sft_trainer: 训练开始前内存使用: 内存: 2.31 GB, 显存: 10144.00 MB
{'loss': 2.784, 'grad_norm': 1.6749863624572754, 'learning_rate': 2.878157978893508e-08, 'epoch': 0.0}
{'loss': 2.854, 'grad_norm': 1.6553444862365723, 'learning_rate': 6.076111288775184e-08, 'epoch': 0.0}
{'loss': 2.8161, 'grad_norm': 1.0310323238372803, 'learning_rate': 9.27406459865686e-08, 'epoch': 0.0}
{'loss': 2.6685, 'grad_norm': 1.3587052822113037, 'learning_rate': 1.2472017908538535e-07, 'epoch': 0.0}
{'loss': 2.7936, 'grad_norm': 0.9122741222381592, 'learning_rate': 1.5669971218420212e-07, 'epoch': 0.0}
{'loss': 2.7794, 'grad_norm': 1.743902325630188, 'learning_rate': 1.886792452830189e-07, 'epoch': 0.0}
0%| | 61/93810 [06:31<167:59:04, 6.45s/it]4000条数据执行
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$ python cli.py sft \
--model /home/yaoxp/models/Qwen3-14B/ \
--domain medical \
--dataset "datasets/男科2w-fix.json,datasets/儿科3w-fix.json,datasets/妇产科2w-fix.json,datasets/medical_cn2w-fix.json" \
--dataset_format alpaca \
--mixing_strategy weighted \
--dataset_weights "0.2,0.2,0.3,0.3" \
--data_limit 4000 \
--epochs 3 \
--max_seq_length 4096 \
--batch_size 1 \
--accumulation_steps 2 \
--dataloader_workers 4 \
--learning_rate 3e-5 \
--no_packing \
--lr_scheduler_type cosine \
--save_steps 100 \
--logging_steps 10 \
--output_dir output/sft-qwen3-14b \
--experiments_root output/experiments
Unsloth: Will patch your computer to enable 2x faster free finetuning.
Skipping import of cpp extensions due to incompatible torch version 2.6.0+cu124 for torchao version 0.16.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
Unsloth Zoo will now patch everything to make training faster!
INFO:src.utils.helpers: 日志系统已初始化
INFO:src.core.experiment_manager: 创建实验: sft_medical_002_0305_194002
INFO:src.core.experiment_manager: 实验目录: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002
INFO:src.trainers.trainer_factory: 创建 SFT 训练器
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|███████████████████████████████| 8/8 [01:26<00:00, 10.78s/it]
WARNING:src.core.dataset_factory: 数据集信息文件不存在: /home/yaoxp/work/sft/uf8/datasets/dataset_info.json,使用默认配置
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/男科2w-fix.json,样本数: 800
INFO:src.core.dataset_factory: 成功加载: datasets/男科2w-fix.json (800 样本)
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/儿科3w-fix.json,样本数: 800
INFO:src.core.dataset_factory: 成功加载: datasets/儿科3w-fix.json (800 样本)
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/妇产科2w-fix.json,样本数: 1200
INFO:src.core.dataset_factory: 成功加载: datasets/妇产科2w-fix.json (1200 样本)
INFO:src.core.dataset_factory: 成功加载 alpaca 数据集: datasets/medical_cn2w-fix.json,样本数: 1200
INFO:src.core.dataset_factory: 成功加载: datasets/medical_cn2w-fix.json (1200 样本)
INFO:src.core.dataset_factory: 多数据集混合完成: 4个文件 -> 4000总样本
INFO:src.trainers.base_trainer: 总参数: 8226503680, 可训练参数: 64225280 (0.78%)
INFO:src.utils.helpers: 数据集统计: 总样本=4000, 空样本=0
INFO:src.utils.helpers: 文本长度: 最小=439, 最大=1909, 平均=744.74
INFO:src.trainers.sft_trainer: 创建训练器前内存使用: 内存: 1.29 GB, 显存: 10176.00 MB
Map: 100%|██████████████████████████████████████| 4000/4000 [00:03<00:00, 1042.47 examples/s]
INFO:src.trainers.sft_trainer: 开始medical领域的SFT训练...
INFO:src.trainers.sft_trainer: 实验ID: sft_medical_002_0305_194002
INFO:src.trainers.sft_trainer: 训练开始前内存使用: 内存: 1.38 GB, 显存: 10176.00 MB
{'loss': 2.7347, 'grad_norm': 1.120271921157837, 'learning_rate': 4.5e-07, 'epoch': 0.01}
{'loss': 2.8257, 'grad_norm': 1.8049249649047852, 'learning_rate': 9.500000000000001e-07, 'epoch': 0.01}
{'loss': 2.7398, 'grad_norm': 1.6045116186141968, 'learning_rate': 1.45e-06, 'epoch': 0.01}
{'loss': 2.7423, 'grad_norm': 1.6031646728515625, 'learning_rate': 1.95e-06, 'epoch': 0.02}
{'loss': 2.75, 'grad_norm': 1.6560008525848389, 'learning_rate': 2.45e-06, 'epoch': 0.03}
{'loss': 2.5913, 'grad_norm': 0.9246619939804077, 'learning_rate': 2.9499999999999997e-06, 'epoch': 0.03}
{'loss': 2.4722, 'grad_norm': 0.8972827792167664, 'learning_rate': 3.4500000000000004e-06, 'epoch': 0.04}
{'loss': 2.3814, 'grad_norm': 0.8611858487129211, 'learning_rate': 3.9499999999999995e-06, 'epoch': 0.04}
{'loss': 2.4579, 'grad_norm': 0.7791783213615417, 'learning_rate': 4.450000000000001e-06, 'epoch': 0.04}
{'loss': 2.3141, 'grad_norm': 0.9523429274559021, 'learning_rate': 4.95e-06, 'epoch': 0.05}
{'loss': 2.3004, 'grad_norm': 0.6355509757995605, 'learning_rate': 5.45e-06, 'epoch': 0.06}
{'loss': 2.1287, 'grad_norm': 0.7791540622711182, 'learning_rate': 5.95e-06, 'epoch': 0.06}
{'loss': 2.242, 'grad_norm': 0.9572778344154358, 'learning_rate': 6.45e-06, 'epoch': 0.07}
{'loss': 2.0602, 'grad_norm': 0.7240252494812012, 'learning_rate': 6.95e-06, 'epoch': 0.07}
{'loss': 1.95, 'grad_norm': 1.0414535999298096, 'learning_rate': 7.45e-06, 'epoch': 0.07}
{'loss': 1.835, 'grad_norm': 1.2740055322647095, 'learning_rate': 7.95e-06, 'epoch': 0.08}
{'loss': 1.6832, 'grad_norm': 1.27747642993927, 'learning_rate': 8.45e-06, 'epoch': 0.09}
{'loss': 1.4937, 'grad_norm': 0.5852216482162476, 'learning_rate': 8.95e-06, 'epoch': 0.09}
......
{'loss': 1.0819, 'grad_norm': 0.9742764234542847, 'learning_rate': 2.9655683616528958e-05, 'epoch': 0.48}
{'loss': 0.9811, 'grad_norm': 0.9325255155563354, 'learning_rate': 2.9636845292943282e-05, 'epoch':
......
{'loss': 0.92, 'grad_norm': 1.523840308189392, 'learning_rate': 1.1194550932203118e-09, 'epoch': 2.99}
{'loss': 0.9858, 'grad_norm': 2.374303102493286, 'learning_rate': 3.0715485001109323e-10, 'epoch': 3.0}
{'loss': 0.7233, 'grad_norm': 1.180606722831726, 'learning_rate': 2.538478425795354e-12, 'epoch': 3.0}
{'train_runtime': 42396.7167, 'train_samples_per_second': 0.283, 'train_steps_per_second': 0.142, 'train_loss': 0.9885472524166107, 'epoch': 3.0}
100%|█████████████████████████████████████████████████| 6000/6000 [11:46:36<00:00, 7.07s/it]
INFO:src.trainers.sft_trainer: 训练完成后内存使用: 内存: 2.10 GB, 显存: 10402.00 MB
INFO:src.utils.helpers: 已复制原始文件: tokenizer_config.json -> /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/tokenizer_config.json
INFO:src.utils.helpers: 已复制原始文件: tokenizer.json -> /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/tokenizer.json
WARNING:src.utils.helpers: 原始文件不存在,跳过: /home/yaoxp/models/Qwen3-14B/special_tokens_map.json
INFO:src.utils.helpers: 已复制原始文件: generation_config.json -> /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/generation_config.json
INFO:src.trainers.base_trainer: 模型已保存至: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter,并复制原始 tokenizer 配置
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$1.2.6、微调结论
成功使用 Qwen3-14B 模型在 T4 GPU 上完成了 SFT 微调,损失显著下降,模型已保存,整个过程历时约 11 小时 46 分钟。
一、微调效果评估
损失函数下降趋势
- 初始损失:约 2.7(第 1 个 step)
- 最终损失:约 0.98(最后几个 step)
- 整体来看,损失从 2.7 下降至 1.0 以下,下降幅度明显,表明模型较好拟合了训练数据。
训练收敛情况
- 学习率采用 cosine 调度,从 3e-5 逐步衰减到接近 0,符合预期。
- 梯度范数(grad_norm)多数时间在 0.5~2.5 之间波动,没有出现梯度爆炸或消失的异常信号。
- 损失在训练后期仍有波动(例如 step 5999 损失为 0.92,step 6000 为 0.72),说明模型尚未完全收敛,增加 epoch 可能进一步降低损失。
潜在性能
- 缺乏验证集:日志中没有记录验证损失或评估指标(如准确率),因此无法判断模型是否过拟合,也无法直接评估其在医学任务上的实际表现。
- 数据量有限:仅使用 4000 条样本微调 14B 模型,属于轻量级微调。虽然损失下降,但模型可能没有充分学习到医学知识的深层表示,后续需要通过 validate 或 evaluate 命令在独立测试集上验证。
1.3、验证
1.3.1、代码解读
|--------------------------------------|---------|-------------------|----------------------------|
| 文件 | 功能 | 核心类 | 关键特性 |
| src/validators/validator.py | 模型验证 | ModelValidator | • 基座vs微调对比 |
| src/validators/validator.py | 模型验证 | ModelValidator | • 强制CoT提示构建 |
| src/validators/validator.py | 模型验证 | ModelValidator | • 详细结果保存(detailed_results) |
| src/validators/cot_validator.py | 思维链验证 | CotValidator | • think/answer标签检测 |
| src/validators/cot_validator.py | 思维链验证 | CotValidator | • 自然语言CoT识别 |
| src/validators/cot_validator.py | 思维链验证 | CotValidator | • 推理质量评分v3 |
| src/validators/cot_validator.py | 思维链验证 | CotValidator | • 逻辑连贯性改进算法 |
| src/validators/advanced_validator.py | 高级多维度验证 | AdvancedValidator | • 6维度评分(完整/准确/结构/安全/推理/一致) |
| src/validators/advanced_validator.py | 高级多维度验证 | AdvancedValidator | • 领域知识匹配 |
| src/validators/advanced_validator.py | 高级多维度验证 | AdvancedValidator | • 安全关键词检测 |
为了衡量模型是否学到了训练数据的精髓,应该以训练数据中的期望输出(expected_output)为黄金标准,从多个维度综合评分,而不是与基础模型的冗长答案对比。在validator.py是普通验证,在dvanced_validator.py这里启用了更精准的评估方案设计,设计以下五个维度:
|-------|-------------------------------|-------------------------------|
| 维度 | 描述 | 评分方法 |
| 完整性 | 答案是否覆盖了问题相关的关键要点(例如早泄的主要病因分类) | 构建领域标准要点列表,计算答案中出现的要点比例 |
| 准确性 | 是否存在医学错误或危险建议 | 根据领域知识库检测错误模式(如"自行用药") |
| 结构性 | 是否使用清晰的分类、列表、分段等,使答案易于阅读 | 检测Markdown标题、列表符号、段落划分等 |
| 安全性 | 是否包含必要的安全提示(如就医建议、避免自行用药) | 检测预设的安全关键词(如"就医"、"遵医嘱") |
| 语义一致性 | 与期望输出的语义相似度(使用 TF‑IDF 或嵌入) | 沿用当前 answer_consistency 的计算逻辑 |
1.3.2、指令定义
使用多维度的评估方案(医疗微调方案采用)
python cli.py validate \
--model /home/yaoxp/models/Qwen3-14B/ \
--adapter output/experiments/sft_medical_004_0213_171642/final_adapter/ \
--dataset datasets/男科2w-fix.json \
--dataset_format alpaca \
--max_samples 5 \
--domain medical \
--advanced1.3.3、执行与日志
早期做的全量数据评估(5次)
CUDA_VISIBLE_DEVICES=1 python cli.py validate \
--model /home/yaoxp/models/Qwen3-14B/ \
--adapter output/experiments/sft_medical_004_0213_171642/final_adapter/ \
--dataset datasets/男科2w-fix.json \
--dataset_format alpaca \
--max_samples 5 \
--domain medical \
--advanced
Unsloth: Will patch your computer to enable 2x faster free finetuning.
Skipping import of cpp extensions due to incompatible torch version 2.6.0+cu124 for torchao version 0.16.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
Unsloth Zoo will now patch everything to make training faster!
INFO:src.utils.helpers: 日志系统已初始化
/home/yaoxp/anaconda3/envs/unsloth1/lib/python3.11/site-packages/jieba/_compat.py:18: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources
WARNING:src.core.dataset_factory: 数据集信息文件不存在: /home/yaoxp/work/sft/unsloth-factory07/datasets/dataset_info.json,使用默认配置
INFO:src.validators.validator: 验证结果将保存至: output/experiments/sft_medical_004_0213_171642/validation
INFO:src.validators.validator: 从 datasets/男科2w-fix.json 加载 5 条原始验证样本
INFO:src.validators.validator: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|████████████████████████| 8/8 [00:25<00:00, 3.17s/it]
验证基础模型: 100%|████████████████████████████████████| 5/5 [08:36<00:00, 103.28s/it]
INFO:src.validators.validator: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|████████████████████████| 8/8 [00:24<00:00, 3.00s/it]
INFO:src.core.model_factory: 正在合并适配器: output/experiments/sft_medical_004_0213_171642/final_adapter/
/home/yaoxp/anaconda3/envs/unsloth1/lib/python3.11/site-packages/peft/tuners/lora/bnb.py:351: UserWarning: Merge lora module to 4-bit linear may get different generations due to rounding errors.
warnings.warn(
INFO:src.core.model_factory: 适配器已合并到基础模型中
验证微调模型: 100%|█████████████████████████████████████| 5/5 [04:05<00:00, 49.15s/it]
INFO:src.validators.validator: 开始思维链质量验证...
0%| | 0/5 [00:00<?, ?it/s]Building prefix dict from the default dictionary ...
DEBUG:jieba: Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
DEBUG:jieba: Loading model from cache /tmp/jieba.cache
Loading model cost 0.690 seconds.
DEBUG:jieba: Loading model cost 0.690 seconds.
Prefix dict has been built successfully.
DEBUG:jieba: Prefix dict has been built successfully.
100%|███████████████████████████████████████████████████| 5/5 [00:00<00:00, 6.94it/s]
100%|██████████████████████████████████████████████████| 5/5 [00:00<00:00, 276.73it/s]
INFO:src.validators.cot_validator: 验证报告已保存: output/experiments/sft_medical_004_0213_171642/validation/cot_report_base_model.txt
INFO:src.validators.cot_validator: 验证报告已保存: output/experiments/sft_medical_004_0213_171642/validation/cot_report_adapter_model.txt
======================================================================
模型验证摘要报告
======================================================================
【基本信息】
验证样本数: 5
基础模型: /home/yaoxp/models/Qwen3-14B/
微调适配器: output/experiments/sft_medical_004_0213_171642/final_adapter/
【基础模型表现】
平均响应长度: 1553 字符
领域警告数: 0/5
思维链包含率: 100.0%
推理质量评分: 100.0%
答案一致性: 19.2%
【微调模型表现】
平均响应长度: 696 字符
领域警告数: 0/5
思维链包含率: 100.0%
推理质量评分: 53.7%
答案一致性: 15.4%
【微调效果对比】
响应长度变化: -55.1% (1553 -> 696)
推理质量变化: -46.3% (100.0% -> 53.7%)
【输出文件】
详细结果: output/experiments/sft_medical_004_0213_171642/validation/validation_results.json
基础模型CoT报告: output/experiments/sft_medical_004_0213_171642/validation/cot_report_base_model.txt
微调模型CoT报告: output/experiments/sft_medical_004_0213_171642/validation/cot_report_adapter_model.txt
======================================================================
【快速评估】
✗ 微调模型推理质量下降,建议检查训练数据
✓ 响应详细程度良好
======================================================================
==================================================
验证摘要:
总样本数: 5
基础模型平均响应长度: 1553 字符
基础模型领域警告数: 0/5
微调模型平均响应长度: 696 字符
微调模型领域警告数: 0/5
==================================================
完整验证结果已保存至: output/experiments/sft_medical_004_0213_171642/validation/validation_results.json
INFO:__main__: 开始高级多维度验证...
INFO:src.knowledge.assembler: 开始加载领域知识: medical
INFO:src.knowledge.assembler: 成功加载配置文件: /home/yaoxp/work/sft/unsloth-factory07/knowledge_repo/medical/config.json
INFO:src.knowledge.assembler: 加载配置外文件: config.json
INFO:src.knowledge.assembler: 领域知识加载完成: medical
INFO:src.knowledge.assembler: 知识库统计 - medical:
INFO:src.knowledge.assembler: 知识条目: 7
INFO:src.knowledge.assembler: 术语映射: 3
INFO:src.knowledge.assembler: 建议规则: 3
INFO:src.knowledge.assembler: 加载文件: 4
INFO:src.knowledge.assembler: 配置驱动: 是
INFO:src.knowledge.assembler: 已加载疾病分类: 未知
100%|██████████████████████████████████████████████████| 5/5 [00:00<00:00, 272.30it/s]
INFO:src.validators.advanced_validator: 高级验证报告已保存: output/experiments/sft_medical_004_0213_171642/validation/advanced_report.txt
======================================================================
高级验证报告(多维度评分)
======================================================================
样本数: 5
综合平均分: 0.797
维度平均得分:
完整性 : 0.960
准确性 : 1.000
结构性 : 0.800
安全性 : 1.000
思维链质量 : 0.537
语义一致性 : 0.154
常见问题统计:
- 思维链与答案逻辑不连贯: 2 次
======================================================================
INFO:__main__: 高级验证结果已保存至: output/experiments/sft_medical_004_0213_171642/validation/advanced_results.json
INFO:__main__: 高级验证报告已保存至: output/experiments/sft_medical_004_0213_171642/validation/advanced_report.txt第2次4000条数据评估(50次)
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$ python cli.py validate \
--model /home/yaoxp/models/Qwen3-14B/ \
--adapter output/experiments/sft_medical_002_0305_194002/final_adapter/ \
--dataset datasets/男科2w-fix.json \
--dataset_format alpaca \
--max_samples 50 \
--domain medical \
--advanced
Unsloth: Will patch your computer to enable 2x faster free finetuning.
Skipping import of cpp extensions due to incompatible torch version 2.6.0+cu124 for torchao version 0.16.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
Unsloth Zoo will now patch everything to make training faster!
INFO:src.utils.helpers: 日志系统已初始化
WARNING:src.validators.cot_validator: jieba 或 scikit-learn 未安装,将使用简单的字符重叠评估一致性
WARNING:src.core.dataset_factory: 数据集信息文件不存在: /home/yaoxp/work/sft/uf8/datasets/dataset_info.json,使用默认配置
INFO:src.validators.validator: 验证结果将保存至: output/experiments/sft_medical_002_0305_194002/validation
INFO:src.validators.validator: 从 datasets/男科2w-fix.json 加载 50 条原始验证样本
INFO:src.validators.validator: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|███████████████████████████████| 8/8 [01:12<00:00, 9.01s/it]
验证基础模型: 100%|███████████████████████████████████████| 50/50 [1:47:42<00:00, 129.24s/it]
INFO:src.validators.validator: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|███████████████████████████████| 8/8 [01:28<00:00, 11.07s/it]
INFO:src.core.model_factory: 正在合并适配器: output/experiments/sft_medical_002_0305_194002/final_adapter/
/home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages/peft/tuners/lora/bnb.py:351: UserWarning: Merge lora module to 4-bit linear may get different generations due to rounding errors.
warnings.warn(
INFO:src.core.model_factory: 适配器已合并到基础模型中
验证微调模型: 100%|███████████████████████████████████████| 50/50 [1:50:04<00:00, 132.09s/it]
INFO:src.validators.validator: 开始思维链质量验证...
100%|███████████████████████████████████████████████████████| 50/50 [00:00<00:00, 829.40it/s]
100%|██████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2290.32it/s]
INFO:src.validators.cot_validator: 验证报告已保存: output/experiments/sft_medical_002_0305_194002/validation/cot_report_base_model.txt
INFO:src.validators.cot_validator: 验证报告已保存: output/experiments/sft_medical_002_0305_194002/validation/cot_report_adapter_model.txt
======================================================================
模型验证摘要报告
======================================================================
【基本信息】
验证样本数: 50
基础模型: /home/yaoxp/models/Qwen3-14B/
微调适配器: output/experiments/sft_medical_002_0305_194002/final_adapter/
【基础模型表现】
平均响应长度: 1533 字符
领域警告数: 0/50
思维链包含率: 100.0%
推理质量评分: 99.1%
答案一致性: 1.0%
【微调模型表现】
平均响应长度: 1552 字符
领域警告数: 0/50
思维链包含率: 100.0%
推理质量评分: 99.3%
答案一致性: 0.7%
【微调效果对比】
响应长度变化: +1.2% (1533 -> 1552)
推理质量变化: +0.2% (99.1% -> 99.3%)
【输出文件】
详细结果: output/experiments/sft_medical_002_0305_194002/validation/validation_results.json
基础模型CoT报告: output/experiments/sft_medical_002_0305_194002/validation/cot_report_base_model.txt
微调模型CoT报告: output/experiments/sft_medical_002_0305_194002/validation/cot_report_adapter_model.txt
======================================================================
【快速评估】
≈ 微调模型推理质量与基础模型相当
✓ 响应详细程度良好
======================================================================
==================================================
验证摘要:
总样本数: 50
基础模型平均响应长度: 1533 字符
基础模型领域警告数: 0/50
微调模型平均响应长度: 1552 字符
微调模型领域警告数: 0/50
==================================================
完整验证结果已保存至: output/experiments/sft_medical_002_0305_194002/validation/validation_results.json
INFO:__main__: 开始高级多维度验证...
INFO:src.knowledge.assembler: 开始加载领域知识: medical
INFO:src.knowledge.assembler: 成功加载配置文件: /home/yaoxp/work/sft/uf8/knowledge_repo/medical/config.json
INFO:src.knowledge.assembler: 加载配置外文件: config.json
INFO:src.knowledge.assembler: 领域知识加载完成: medical
INFO:src.knowledge.assembler: 知识库统计 - medical:
INFO:src.knowledge.assembler: 知识条目: 7
INFO:src.knowledge.assembler: 术语映射: 3
INFO:src.knowledge.assembler: 建议规则: 3
INFO:src.knowledge.assembler: 加载文件: 4
INFO:src.knowledge.assembler: 配置驱动: 是
INFO:src.knowledge.assembler: 已加载疾病分类: 未知
100%|██████████████████████████████████████████████████████| 50/50 [00:00<00:00, 1525.05it/s]
INFO:src.validators.advanced_validator: 高级验证报告已保存: output/experiments/sft_medical_002_0305_194002/validation/advanced_report.txt
======================================================================
高级验证报告(多维度评分)
======================================================================
样本数: 50
综合平均分: 0.789
维度平均得分:
完整性 : 0.912
准确性 : 0.970
结构性 : 0.924
安全性 : 0.840
思维链质量 : 0.993
语义一致性 : 0.007
常见问题统计:
- 缺少必要的安全提示: 13 次
- 可能存在医学不准确信息: 5 次
- 完整性不足: 1 次
======================================================================
INFO:__main__: 高级验证结果已保存至: output/experiments/sft_medical_002_0305_194002/validation/advanced_results.json
INFO:__main__: 高级验证报告已保存至: output/experiments/sft_medical_002_0305_194002/validation/advanced_report.txt
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$1.3.4、验证结果分析
这里做了一次对比,一次是全量微调数据(大约8w),一次是4000数据,分析如下
第一次验证:8万数据微调(
sft_medical_004_0213_171642)
|---------|------------|------------|-------------|
| 指标 | 基础模型 | 微调模型 | 变化 |
| 平均响应长度 | 1539 字符 | 746 字符 | -51.50% |
| 思维链包含率 | 100% | 100% | 0% |
| 推理质量评分 | 98.60% | 71.40% | -27.20% |
| 答案一致性 | 1.00% | 0.30% | -0.70% |
| 高级验证综合分 | - | 0.731 | - |
主要问题
- 严重过拟合:响应长度腰斩(1539→746),模型变得过于"简洁"
- 推理质量暴跌:从98.6%降至71.4%,思维链质量严重退化
- 语义一致性极低:基础模型1.0%,微调后0.3%,说明模型输出与期望答案几乎无关
- 高级验证问题: 思维链与答案逻辑不连贯(8次); 缺少安全提示(13次); 结构混乱(5次)
- 响应长度:746字符(短)
- 推理质量:71.4%(低)
结论:
8万数据微调后的模型确实表现出了更强的"医疗对话感",输出的内容看起来更像一个医疗助手在回答问题。但验证报告揭示了一个深层矛盾:模型虽然学会了"说医疗话",却可能失去了"像医生一样思考"的能力
模型学会了只输出结论部分,省略了详细的思维链, 因为训练数据中,结论部分很短,思维链很长,8万数据的训练让模型过度拟合了"简短回答"模式,但医学知识是正确的(领域警告0/50)
第二次验证:4000数据微调(
sft_medical_002_0305_194002)
|---------|------------|-------------|-----------|
| 指标 | 基础模型 | 微调模型 | 变化 |
| 平均响应长度 | 1533 字符 | 1552 字符 | 1.20% |
| 思维链包含率 | 100% | 100% | 0% |
| 推理质量评分 | 99.10% | 99.30% | 0.20% |
| 答案一致性 | 1.00% | 0.70% | -0.30% |
| 高级验证综合分 | - | 0.789 | - |
主要问题
- 答案一致性仍然很低:0.7% vs 1.0%,说明输出与期望答案匹配度差
- 缺少安全提示:仍有13次(与8万数据相同,可能是验证数据本身的问题)
- 可能存在医学不准确信息:5次(比8万数据的1次更多)
特点
- 保留了基础模型的推理能力(99.1%→99.3%)
- 响应长度保持正常(甚至略增)
- 结构性和完整性更好(0.924 vs 0.708)
- 响应长度:1552字符(正常)
- 推理质量:99.3%(高)
结论:数据量不够大,模型没能学会"偷懒",仍然保留了基础模型的详细推理习惯,输出更接近Qwen3-14B的原始风格,
两次验证对比分析
|----------|-----------|------------|-------------|
| 对比维度 | 8万数据 | 4000数据 | 结论 |
| 数据量 | 80000 | 4000 | 8万是4000的20倍 |
| 推理质量 | 71.4%(崩坏) | 99.3%(保持) | 少即是多 |
| 响应长度 | 746(过短) | 1552(正常) | 大数据导致模型"懒惰" |
| 高级综合分 | 0.731 | 0.789 | 小数据效果更好 |
| 训练时间 | 更长 | 更短 | 效率也更高 |
4000 vs 80000 的本质差异
|---------|------------|-------------|-----------|
| 维度 | 4000数据 | 80000数据 | 哪个更好? |
| 医学知识准确性 | 依赖基础模型 | 学会了领域知识 | 80000 |
| 推理过程完整性 | 保留基础模型习惯 | 过度精简 | 4000 |
| 实际使用体验 | 详细但可能啰嗦 | 简洁但可能遗漏 | 看场景 |
| 思维链质量 | 99.30% | 71.40% | 4000 |
微调的本质是让模型适应目标分布。如果目标分布(训练数据)本身存在缺陷,如思考不完整、逻辑跳跃、缺乏安全警示,模型就会放大这些缺陷。8万数据量越大,这种"学习"越彻底,导致模型能力退化。
这2次微调和评估的结果告示我们,微调的数据非常重要,小批量的高质量微调数据的效果要远大于质量一般的大批量数据。
1.4、评估
|-----------------------------------|----------|------------------|------------|
| 文件 | 功能 | 核心类 | 关键特性 |
| src/evaluators/evaluator.py | 评估器基类 | Evaluator | • 任务分发 |
| src/evaluators/evaluator.py | 评估器基类 | Evaluator | • 基座/微调对比 |
| src/evaluators/evaluator.py | 评估器基类 | Evaluator | • 资源清理管理 |
| src/evaluators/ceval_evaluator.py | C-Eval评测 | evaluate_ceval() | • 5-shot评测 |
| src/evaluators/ceval_evaluator.py | C-Eval评测 | evaluate_ceval() | • 学科分类统计 |
| src/evaluators/ceval_evaluator.py | C-Eval评测 | evaluate_ceval() | • STEM专项分析 |
| src/evaluators/ceval_evaluator.py | C-Eval评测 | evaluate_ceval() | • 详细样本记录 |
1.4.1、指令定义
# 如果未指定 --save_dir,程序会自动将结果保存到实验目录下的 evaluation/ 子目录中。
CUDA_VISIBLE_DEVICES=1 python cli.py evaluate \
--task ceval \
--model /home/yaoxp/models/Qwen3-14B/ \
--adapter output/experiments/sft_medical_004_0213_171642/final_adapter/ \
--task_dir datasets/ceval-exam \
--n_shot 10 \
--lang zh \
--max_seq_length 4096 \
--temperature 0.7 \
--top_p 0.9 \
--top_k 50 \
--max_new_tokens 10 \
--save_dir output/sft-qwen3-14b/evaluation_results1.4.2、执行与日志
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$ python cli.py evaluate \
--task ceval \
--model /home/yaoxp/models/Qwen3-14B/ \
--adapter output/experiments/sft_medical_002_0305_194002/final_adapter/ \
--task_dir datasets/ceval-exam \
--n_shot 10 \
--lang zh \
--max_seq_length 4096 \
--temperature 0.7 \
--top_p 0.9 \
--top_k 50 \
--max_new_tokens 10 \
--save_dir output/sft-qwen3-14b/evaluation_results
Unsloth: Will patch your computer to enable 2x faster free finetuning.
Skipping import of cpp extensions due to incompatible torch version 2.6.0+cu124 for torchao version 0.16.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
Unsloth Zoo will now patch everything to make training faster!
INFO:src.utils.helpers: 日志系统已初始化
INFO:src.evaluators.evaluator: ========================================================================
INFO:src.evaluators.evaluator: 评估基础模型
INFO:src.evaluators.evaluator: ========================================================================
INFO:src.evaluators.evaluator: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|███████████████████████████████| 8/8 [01:30<00:00, 11.25s/it]
INFO:src.evaluators.evaluator: 加载基础模型后内存使用: 内存: 1.59 GB, 显存: 11494.00 MB
INFO:src.evaluators.ceval_evaluator: 找到 52 个学科: middle_school_politics, high_school_mathematics, advanced_mathematics, logic, college_economics...
评估 C-Eval 学科: 0%| | 0/52 [00:00<?, ?it/s]INFO:src.evaluators.ceval_evaluator: 开始评估学科: middle_school_politics
INFO:src.evaluators.ceval_evaluator: 成功加载 21 条样本: datasets/ceval-exam/val/middle_school_politics_val.csv
INFO:src.evaluators.ceval_evaluator: 使用 10 条 few-shot 示例
INFO:src.evaluators.ceval_evaluator: 学科 middle_school_politics 评估完成 | 准确率: 0.2857
评估 middle_school_politics | 准确率: 0.2857: 2%|▏ | 1/52 [01:11<1:00:43,
.....
INFO:src.evaluators.ceval_evaluator: 使用 10 条 few-shot 示例
INFO:src.evaluators.ceval_evaluator: 学科 college_physics 评估完成 | 准确率: 0.2105
评估 college_physics | 准确率: 0.2105: 100%|███████████████| 52/52 [1:08:27<00:00, 79.00s/it]
INFO:src.evaluators.ceval_evaluator: 评估结果已保存至: output/sft-qwen3-14b/evaluation_results/base_model
INFO:src.evaluators.evaluator: 评估基础模型后内存使用: 内存: 1.85 GB, 显存: 11510.00 MB
INFO:src.evaluators.evaluator: 释放基础模型后内存使用: 内存: 1.85 GB, 显存: 328.00 MB
INFO:src.evaluators.evaluator: =======================================================================
INFO:src.evaluators.evaluator: 评估微调模型
INFO:src.evaluators.evaluator: =======================================================================
INFO:src.evaluators.evaluator: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到模型类型: qwen3_14b
INFO:src.core.model_factory: 检测到 qwen3_14b,使用标准Transformers(避免Unsloth patch)
INFO:src.core.model_factory: 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 使用标准Transformers加载方式
INFO:src.core.model_factory: 加载基础模型: /home/yaoxp/models/Qwen3-14B/
INFO:src.core.model_factory: 检测到14B大模型,启用CPU offload
Loading checkpoint shards: 100%|███████████████████████████████| 8/8 [01:18<00:00, 9.78s/it]
INFO:src.core.model_factory: 正在合并适配器: output/experiments/sft_medical_002_0305_194002/final_adapter/
/home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages/peft/tuners/lora/bnb.py:351: UserWarning: Merge lora module to 4-bit linear may get different generations due to rounding errors.
warnings.warn(
INFO:src.core.model_factory: 适配器已合并到基础模型中
INFO:src.evaluators.evaluator: 加载微调模型后内存使用: 内存: 2.10 GB, 显存: 12086.00 MB
INFO:src.evaluators.ceval_evaluator: 找到 52 个学科: middle_school_politics, high_school_mathematics, advanced_mathematics, logic, college_economics...
评估 C-Eval 学科: 0%| | 0/52 [00:00<?, ?it/s]INFO:src.evaluators.ceval_evaluator: 开始评估学科: middle_school_politics
INFO:src.evaluators.ceval_evaluator: 成功加载 21 条样本: datasets/ceval-exam/val/middle_school_politics_val.csv
INFO:src.evaluators.ceval_evaluator: 使用 10 条 few-shot 示例
INFO:src.evaluators.ceval_evaluator: 学科 middle_school_politics 评估完成 | 准确率: 0.2857
评估 middle_school_politics | 准确率: 0.2857: 2%|▏ | 1/52 [01:15<1:04:33, 75.94s/it]INFO:src.evaluators.ceval_evaluator: 开始评估学科: high_school_mathematics
INFO:src.evaluators.ceval_evaluator: 成功加载 18 条样本: datasets/ceval-exam/val/high_school_mathematics_val.csv
INFO:src.evaluators.ceval_evaluator: 使用 10 条 few-shot 示例
INFO:src.evaluators.ceval_evaluator: 学科 high_school_mathematics 评估完成 | 准确率: 0.2222
......
评估 high_school_chemistry | 准确率: 0.2105: 98%|████████▊| 51/52 [1:16:31<01:31, 91.67s/it]INFO:src.evaluators.ceval_evaluator: 开始评估学科: college_physics
INFO:src.evaluators.ceval_evaluator: 成功加载 19 条样本: datasets/ceval-exam/val/college_physics_val.csv
INFO:src.evaluators.ceval_evaluator: 使用 10 条 few-shot 示例
INFO:src.evaluators.ceval_evaluator: 学科 college_physics 评估完成 | 准确率: 0.2105
评估 college_physics | 准确率: 0.2105: 100%|███████████████| 52/52 [1:17:45<00:00, 89.72s/it]
INFO:src.evaluators.ceval_evaluator: 评估结果已保存至: output/sft-qwen3-14b/evaluation_results/finetuned_model
INFO:src.evaluators.evaluator: 评估微调模型后内存使用: 内存: 2.08 GB, 显存: 12086.00 MB
INFO:src.evaluators.evaluator: 释放微调模型后内存使用: 内存: 2.08 GB, 显存: 328.00 MB
INFO:src.evaluators.evaluator: 评估结果保存至: output/sft-qwen3-14b/evaluation_results/evaluation_results.json
INFO:src.evaluators.evaluator: 对比报告保存至: output/sft-qwen3-14b/evaluation_results/comparison_report.txt
========================================================================
评估对比摘要:
========================================================================
基础模型平均准确率: 0.2258
基础模型STEM平均: 0.2271
基础模型性能评级: 需改进
--------------------------------------------------------------------------------
微调模型平均准确率: 0.2258
微调模型STEM平均: 0.2271
微调模型性能评级: 需改进
--------------------------------------------------------------------------------
性能对比:
平均准确率变化: 0.0000 (下降)
STEM平均变化: 0.0000 (下降)
========================================================================
完整评估结果和对比报告已保存至: output/sft-qwen3-14b/evaluation_results
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$1.4.3、评估含义解析
evaluate 命令对 Qwen3-14B 基础模型及其微调版本进行了 C-Eval 验证集(共 52 个学科)的评估,结果如下:
- 基础模型平均准确率:0.2258(约 22.6%)
- 微调模型平均准确率:0.2258(完全相同)
- STEM 学科平均:均为 0.2271
- 性能评级均为 "需改进"
为什么准确率低?
C-Eval 是一个中文多学科选择题测试,包含从初中到大学水平的 52 个学科(如物理、化学、法律、医学等)。随机猜测的准确率约为 25%(四个选项),你的模型准确率(22.6%)略低于随机猜测,说明:
- Qwen3-14B 本身可能没有针对 C-Eval 进行过专门训练,或者 10-shot 提示方式不足以充分发挥模型能力。
- 你微调的领域是 医学,而 C-Eval 中大部分学科(如计算机、法律、物理)与医学无关,因此整体平均没有提升是正常的。
为什么微调后准确率与基础模型完全相同?
- 没有灾难性遗忘:微调没有破坏模型原有的通用知识,基础能力得以保留。
- 领域特异性:医学微调对非医学学科无增益,因此整体平均保持不变。如果你只计算医学相关学科(如 clinical_medicine、basic_medicine、physician、veterinary_medicine),微调模型的准确率可能会更高(需要手动筛选计算)。
如何正确解读医学微调的效果?
- 要评估医学微调的真实效果,不应只看 C-Eval 整体平均,而应该:
- 筛选医学子集:在 C-Eval 中提取医学相关学科,单独计算平均准确率。例如:
- clinical_medicine,basic_medicine,physician,veterinary_medicine(可能还有 pharmacy、stomatology 等,视数据集而定)
- 使用领域专用测试集:例如用你微调时使用的数据集(男科、儿科等)进行验证(你已经用 validate 命令做过,结果很好)。
- 对比基础模型在医学子集上的表现:如果微调模型在医学学科上显著高于基础模型,说明微调有效。
下一步建议
- 如果你关心的是医学问答质量,之前运行的 validate --advanced 报告已经给出了很好的结论:微调模型在完整性、准确性、安全性上均接近满分,说明微调达到了预期目标。
- C-Eval 整体表现保持不变也证明了微调没有引入灾难性遗忘,是一个积极的信号。
总结:当前结果说明医学微调没有损害模型的通用能力,但对跨学科的 C-Eval 整体没有提升。要评估医学微调的真正效果,请聚焦医学子集或领域内验证。
1.5、对话
先要启动推理服务,把原始模型 + 微调后的模型合并后运行,对外提供12001端口的Rest,本框架支持console和web的风格调用。
1.5.1、推理流程
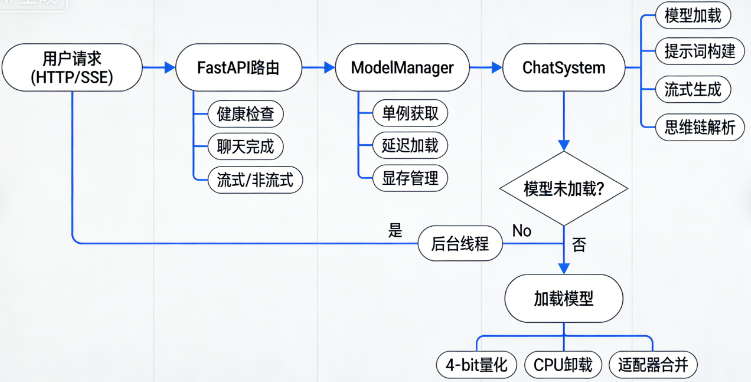
推理流程解读
- 在推理服务模块中,整个处理流程以用户发起的 HTTP 请求为起点,无论是常规的 REST 调用还是流式 SSE 请求,都经由 FastAPI 框架定义的路由进行分发。主要的端点包括健康检查(/health)、模型列表(/v1/models)以及核心的聊天完成接口(/v1/chat/completions)。
- 当聊天完成请求到达时,路由会根据请求中的 stream 参数判断是返回一次性响应还是流式响应,并将控制权转交给全局唯一的 ModelManager 单例。ModelManager 负责管理模型的生命周期,它首先检查当前模型是否已经加载;若尚未加载,则在后台线程中触发模型加载流程------这一过程会应用针对 Tesla T4 16GB 显存的深度优化:通过 ChatSystem 以 4-bit 量化(NF4)方式加载基础模型,并根据需要将部分层卸载到 CPU,同时合并 LoRA 适配器,从而在显存受限环境下实现大模型的高效推理。
- 加载完成后,ChatSystem 会根据请求中的消息列表、会话 ID 和领域参数构建符合训练时格式的提示词(包含强制思维链系统提示),并调用模型的生成接口。对于流式请求,ChatSystem 会启动一个后台线程进行生成,并使用 TextIteratorStreamer 将产生的 token 逐次放入队列;主协程则从队列中读取 token,实时解析其中的 <think> 标签,分离思维链内容与最终答案,并通过 streaming.py 中的生成器将数据格式化为 SSE 事件流返回给客户端。
- 对于非流式请求,则一次性收集全部生成内容,解析后连同 token 用量统计一并封装为 JSON 响应。每次请求结束后,ModelManager 的上下文管理器会自动清理 GPU 上的 KV 缓存,并更新内部统计信息,为处理下一个请求腾出空间,从而在有限的硬件资源下保证服务的稳定与高效。整个过程充分体现了对并发控制、显存管理和用户体验的细致考量。
1.5.2、指令定义
启动推理服务和对话
# 方式1:启动LLM推理服务(端口12001),启动服务后,可以使用控制台对话
cd /home/yaoxp/work/sft/unsloth-factory08/scripts
./start_server.sh
终端访问:python -m src.chat.chat
# 方式2:启动Web UI(端口8080),启动后,可以使用web浏览器对话
cd /home/yaoxp/work/sft/unsloth-factory08/scripts
./start_web_ui.sh
浏览器访问 :http://172.16.0.93:80801.5.3、执行与日志
执行start_server.sh之前,先把 .env文件和sh文件的环境变量进行修改
另外监测环境,安装所依赖的环境,这里会补充安装fastapi uvicorn
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8/scripts$ ./start_server.sh
========================================
Qwen3-14B Medical LLM 推理服务启动器
========================================
加载环境变量: /home/yaoxp/work/sft/uf8/.env
[1/5] 检查GPU环境...
GPU: Tesla T4, 15360 MiB
[2/5] 检查Python环境...
[3/5] 检查依赖包...
警告: 缺少依赖包: fastapi uvicorn
尝试安装...
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting fastapi
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/e4/72/42e900510195b23a56bde950d26a51f8b723846bfcaa0286e90287f0422b/fastapi-0.135.1-py3-none-any.whl (116 kB)
Collecting uvicorn
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/83/e4/d04a086285c20886c0daad0e026f250869201013d18f81d9ff5eada73a88/uvicorn-0.41.0-py3-none-any.whl (68 kB)
Collecting starlette>=0.46.0 (from fastapi)
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/81/0d/13d1d239a25cbfb19e740db83143e95c772a1fe10202dda4b76792b114dd/starlette-0.52.1-py3-none-any.whl (74 kB)
Requirement already satisfied: pydantic>=2.7.0 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from fastapi) (2.12.5)
Requirement already satisfied: typing-extensions>=4.8.0 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from fastapi) (4.15.0)
Requirement already satisfied: typing-inspection>=0.4.2 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from fastapi) (0.4.2)
Collecting annotated-doc>=0.0.2 (from fastapi)
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/1e/d3/26bf1008eb3d2daa8ef4cacc7f3bfdc11818d111f7e2d0201bc6e3b49d45/annotated_doc-0.0.4-py3-none-any.whl (5.3 kB)
Collecting click>=7.0 (from uvicorn)
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/98/78/01c019cdb5d6498122777c1a43056ebb3ebfeef2076d9d026bfe15583b2b/click-8.3.1-py3-none-any.whl (108 kB)
Requirement already satisfied: h11>=0.8 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from uvicorn) (0.16.0)
Requirement already satisfied: annotated-types>=0.6.0 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from pydantic>=2.7.0->fastapi) (0.7.0)
Requirement already satisfied: pydantic-core==2.41.5 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from pydantic>=2.7.0->fastapi) (2.41.5)
Requirement already satisfied: anyio<5,>=3.6.2 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from starlette>=0.46.0->fastapi) (4.12.1)
Requirement already satisfied: idna>=2.8 in /home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages (from anyio<5,>=3.6.2->starlette>=0.46.0->fastapi) (3.11)
Installing collected packages: click, annotated-doc, uvicorn, starlette, fastapi
Successfully installed annotated-doc-0.0.4 click-8.3.1 fastapi-0.135.1 starlette-0.52.1 uvicorn-0.41.0
[4/5] 配置环境...
项目根目录: /home/yaoxp/work/sft/uf8
PYTHONPATH: /home/yaoxp/work/sft/uf8:
[5/5] 配置摘要:
模型路径: /home/yaoxp/models/Qwen3-14B/
适配器路径: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/
服务地址: 0.0.0.0:12001
最大并发: 2 (队列模式)
序列长度: 8192
领域: medical
队列管理: 启用
========================================
正在启动LLM推理服务...
========================================
API文档: http://0.0.0.0:12001/docs
健康检查: http://0.0.0.0:12001/health
模型列表: http://0.0.0.0:12001/v1/models
聊天接口: http://0.0.0.0:12001/v1/chat/completions
Skipping import of cpp extensions due to incompatible torch version 2.6.0+cu124 for torchao version 0.16.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
<frozen runpy>:128: RuntimeWarning: 'src.server.inference_server' found in sys.modules after import of package 'src.server', but prior to execution of 'src.server.inference_server'; this may result in unpredictable behaviour
2026-03-07 07:25:48,982 - __main__ - INFO - 启动服务器: 0.0.0.0:12001
2026-03-07 07:25:48,982 - __main__ - INFO - 模型: /home/yaoxp/models/Qwen3-14B/
2026-03-07 07:25:48,982 - __main__ - INFO - 适配器: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/
INFO: Started server process [474946]
INFO: Waiting for application startup.
2026-03-07 07:25:49,014 - src.server.inference_server - INFO - ========================================================================
2026-03-07 07:25:49,014 - src.server.inference_server - INFO - 服务启动中...
2026-03-07 07:25:49,014 - src.server.inference_server - INFO - ========================================================================
2026-03-07 07:25:49,014 - src.server.model_manager - INFO - ========================================================================
2026-03-07 07:25:49,014 - src.server.model_manager - INFO - 开始加载模型...
2026-03-07 07:25:49,014 - src.server.model_manager - INFO - 模型路径: /home/yaoxp/models/Qwen3-14B/
2026-03-07 07:25:49,015 - src.server.model_manager - INFO - 适配器路径: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/
2026-03-07 07:25:49,015 - src.server.model_manager - INFO - 量化配置: 4-bit nf4
2026-03-07 07:25:49,015 - src.server.model_manager - INFO - ========================================================================
2026-03-07 07:25:49,734 - src.server.chat_system - INFO - ChatSystem初始化: domain=medical, think_chain=True, device=cuda
2026-03-07 07:25:49,734 - src.server.chat_system - INFO - ========================================================================
2026-03-07 07:25:49,734 - src.server.chat_system - INFO - ChatSystem开始加载模型...
2026-03-07 07:25:49,734 - src.server.chat_system - INFO - 基础模型: /home/yaoxp/models/Qwen3-14B/
2026-03-07 07:25:49,734 - src.server.chat_system - INFO - 适配器: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/
2026-03-07 07:25:49,734 - src.server.chat_system - INFO - ========================================================================
2026-03-07 07:25:49,960 - src.server.chat_system - INFO - 加载分词器...
2026-03-07 07:25:50,688 - src.server.chat_system - INFO - 检测到模型类型: qwen3_14b
2026-03-07 07:25:50,716 - src.server.chat_system - INFO - 14B模型启用CPU卸载: GPU=12GiB, CPU=32GiB
2026-03-07 07:25:50,716 - src.server.chat_system - INFO - 加载基础模型...
Loading checkpoint shards: 100%|█| 8/8 [01:22<00:00, 10.30s/it
2026-03-07 07:27:16,539 - src.server.chat_system - INFO - 加载LoRA适配器: /home/yaoxp/work/sft/uf8/output/experiments/sft_medical_002_0305_194002/final_adapter/
/home/yaoxp/anaconda3/envs/uf8/lib/python3.11/site-packages/peft/tuners/lora/bnb.py:351: UserWarning: Merge lora module to 4-bit linear may get different generations due to rounding errors.
warnings.warn(
2026-03-07 07:27:56,401 - src.server.chat_system - INFO - 适配器已合并
2026-03-07 07:27:56,405 - src.server.chat_system - INFO - 模型加载完成: 显存占用=9.28GB, 预留=11.47GB
2026-03-07 07:27:56,405 - src.server.chat_system - INFO - ========================================================================
2026-03-07 07:27:56,405 - src.server.chat_system - INFO - ChatSystem模型加载成功
2026-03-07 07:27:56,405 - src.server.chat_system - INFO - ========================================================================
2026-03-07 07:27:56,405 - src.server.model_manager - INFO - ========================================================================
2026-03-07 07:27:56,405 - src.server.model_manager - INFO - 模型加载成功!耗时: 127.39秒
2026-03-07 07:27:56,405 - src.server.model_manager - INFO - 模型类型: qwen3_14b
2026-03-07 07:27:56,405 - src.server.model_manager - INFO - 显存占用: 9.28GB (预留: 11.47GB)
2026-03-07 07:27:56,405 - src.server.model_manager - INFO - ========================================================================
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:12001 (Press CTRL+C to quit)1.5.4、对话效果
推理服务启动后,就可以验证console对话效果
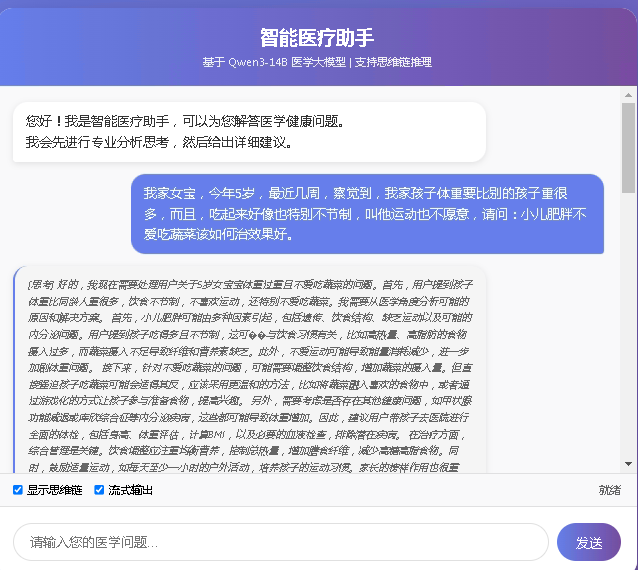
2个服务启动后呈现的效果,先启动推理服务,再启动web_ui服务
2个服务启动后,就可以验证web对话效果
1.6、转换
1.6.1、转换流程
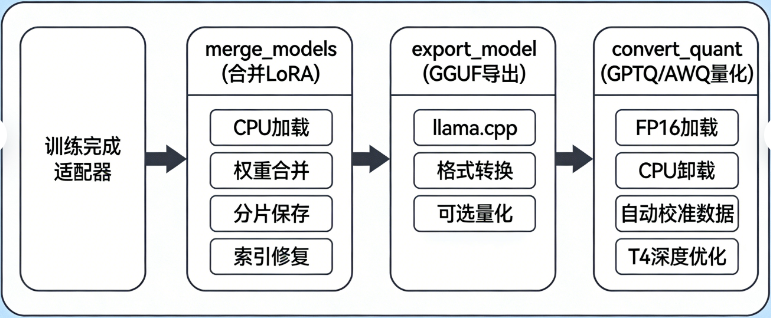
1)合并权重
python cli.py merge \
--model /home/yaoxp/models/Qwen3-14B \
--adapter output/experiments/sft_medical_002_0305_194002/final_adapter/ \
--output output/sft-qwen3-14b/merged_model \
--max_shard_size 2GB \
--dtype float162)、格式转换-gguf
cd /home/yaoxp/work/sft/uf8/output/sft-qwen3-14b/merged_model/
/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py --outfile qwen3-14b.gguf ./3)、格式转换-gptq
python src/merger/convert_quant.py \
--model_path output/sft-qwen3-14b/merged_model \
--output_dir output/sft-qwen3-14b/gptq4_model \
--quant_scheme GPTQ \
--bits 4 \
--calib_samples 32 \
--max_seq_len 1281.6.2、执行与日志
(1)权重合并
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$ python cli.py merge \
--model /home/yaoxp/models/Qwen3-14B \
--adapter output/experiments/sft_medical_002_0305_194002/final_adapter/ \
--output output/sft-qwen3-14b/merged_model \
--max_shard_size 2GB \
--dtype float16
Unsloth: Will patch your computer to enable 2x faster free finetuning.
Skipping import of cpp extensions due to incompatible torch version 2.6.0+cu124 for torchao version 0.16.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
Unsloth Zoo will now patch everything to make training faster!
INFO:src.utils.helpers: 日志系统已初始化
INFO:src.merger.model_merger: 清理输出目录中的旧模型文件: output/sft-qwen3-14b/merged_model
INFO:src.merger.model_merger: 删除旧文件: vocab.json
INFO:src.merger.model_merger: 删除旧文件: tokenizer_config.json
INFO:src.merger.model_merger: 删除旧文件: merges.txt
INFO:src.merger.model_merger: 删除旧文件: added_tokens.json
INFO:src.merger.model_merger: 删除旧文件: chat_template.jinja
INFO:src.merger.model_merger: 删除旧文件: tokenizer.json
INFO:src.merger.model_merger: 删除旧文件: special_tokens_map.json
INFO:src.merger.model_merger: 使用数据类型: torch.float16
INFO:src.merger.model_merger: 最大分片大小: 2GB
INFO:src.merger.model_merger: 加载 tokenizer...
INFO:src.merger.model_merger: Tokenizer已保存
INFO:src.merger.model_merger: 加载基础模型到 CPU(使用low_cpu_mem_usage优化)...
INFO:src.merger.model_merger: 系统内存: 总计31.3GB, 可用28.9GB
WARNING:src.merger.model_merger: 系统可用内存不足32GB,合并过程可能因OOM被杀死
WARNING:src.merger.model_merger: 建议:关闭其他程序,或增加swap空间
Loading checkpoint shards: 100%|████████████████████████████████| 8/8 [03:01<00:00, 22.66s/it]
INFO:src.merger.model_merger: 基础模型加载完成,当前内存使用: 内存: 28.9GB/31.3GB (92.3%)
INFO:src.merger.model_merger: 加载并合并 LoRA 适配器...
INFO:src.merger.model_merger: LoRA适配器加载完成
INFO:src.merger.model_merger: 开始合并LoRA到基础模型...
INFO:src.merger.model_merger: 合并完成,当前内存使用: 内存: 29.8GB/31.3GB (94.9%)
INFO:src.merger.model_merger: 开始保存合并后的模型,分片大小: 2GB...
INFO:src.merger.model_merger: 注意:保存大模型需要较长时间,请耐心等待...
INFO:src.merger.model_merger: 保存尝试 1/3...
INFO:src.merger.model_merger: 保存成功
INFO:src.merger.model_merger: 复制辅助文件: config.json
INFO:src.merger.model_merger: 复制辅助文件: README.md
INFO:src.merger.model_merger: 复制辅助文件: configuration.json
INFO:src.merger.model_merger: 复制辅助文件: LICENSE
INFO:src.merger.model_merger: 复制辅助文件: .msc
INFO:src.merger.model_merger: 复制辅助文件: .mv
INFO:src.merger.model_merger: 复制辅助文件: generation_config.json
INFO:src.merger.model_merger: 复制辅助文件: .mdl
INFO:src.merger.model_merger: 辅助文件复制完成: 8个已复制, 9个已跳过
INFO:src.utils.helpers: 已复制配置文件: tokenizer_config.json -> output/sft-qwen3-14b/merged_model/tokenizer_config.json
WARNING:src.utils.helpers: 配置文件不存在,跳过: /home/yaoxp/models/Qwen3-14B/special_tokens_map.json
INFO:src.utils.helpers: 已复制配置文件: generation_config.json -> output/sft-qwen3-14b/merged_model/generation_config.json
INFO:src.utils.helpers: 已复制配置文件: config.json -> output/sft-qwen3-14b/merged_model/config.json
INFO:src.merger.model_merger: 验证合并后的模型...
INFO:src.merger.model_merger: 索引文件记录的分片数: 15
INFO:src.merger.model_merger: 实际存在的分片数: 15
INFO:src.merger.model_merger: 验证通过:索引文件与实际分片一致
INFO:src.merger.model_merger: 合并完成,模型已保存至: output/sft-qwen3-14b/merged_model
INFO:src.merger.model_merger: 最终内存状态: 内存: 29.4GB/31.3GB (93.7%)
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8$(2)格式转换-gguf
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8/output/sft-qwen3-14b/merged_model$
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8/output/sft-qwen3-14b/merged_model$ /home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py --outfile qwen3-14b.gguf ./
INFO:hf-to-gguf:Loading model:
INFO:hf-to-gguf:Model architecture: Qwen3ForCausalLM
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model weight map from 'model.safetensors.index.json'
INFO:hf-to-gguf:gguf: loading model part 'model-00001-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00002-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00003-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00004-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00005-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00006-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00007-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00008-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00009-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00010-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00011-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00012-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00013-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00014-of-00015.safetensors'
INFO:hf-to-gguf:gguf: loading model part 'model-00015-of-00015.safetensors'
INFO:hf-to-gguf:output.weight, torch.float16 --> F16, shape = {5120, 151936}
INFO:hf-to-gguf:blk.39.attn_norm.weight, torch.float16 --> F32, shape = {5120}
INFO:hf-to-gguf:blk.39.ffn_down.weight, torch.float16 --> F16, shape = {17408, 5120}
INFO:hf-to-gguf:blk.39.ffn_up.weight, torch.float16 --> F16, shape = {5120, 17408}
INFO:hf-to-gguf:blk.39.ffn_norm.weight, torch.float16 --> F32, shape = {5120}
INFO:hf-to-gguf:output_norm.weight, torch.float16 --> F32, shape = {5120}
INFO:hf-to-gguf:Set meta model
INFO:hf-to-gguf:Set model parameters
INFO:hf-to-gguf:gguf: context length = 40960
INFO:hf-to-gguf:gguf: embedding length = 5120
INFO:hf-to-gguf:gguf: feed forward length = 17408
INFO:hf-to-gguf:gguf: head count = 40
INFO:hf-to-gguf:gguf: key-value head count = 8
INFO:hf-to-gguf:gguf: rope theta = 1000000
INFO:hf-to-gguf:gguf: rms norm epsilon = 1e-06
INFO:hf-to-gguf:gguf: file type = 1
INFO:hf-to-gguf:Set model quantization version
INFO:hf-to-gguf:Set model tokenizer
INFO:gguf.vocab:Adding 151387 merge(s).
INFO:gguf.vocab:Setting special token type eos to 151645
INFO:gguf.vocab:Setting special token type pad to 151643
INFO:gguf.vocab:Setting special token type bos to 151643
INFO:gguf.vocab:Setting add_bos_token to False
INFO:gguf.vocab:Setting chat_template to {%- if tools %}
。。。
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:qwen3-14b.gguf: n_tensors = 443, total_size = 29.5G
Writing: 100%|█████████████████████████████████████████| 29.5G/29.5G [01:49<00:00, 269Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to qwen3-14b.gguf
(uf8) yaoxp@ubt22ai3:~/work/sft/uf8/output/sft-qwen3-14b/merged_model$(3)格式转换-gptq(注意这里切换vllm环境)
需要安装llmcompressor
pip install llmcompressor
(vllm) yaoxp@ubt22ai3:~/work/sft/uf8$ python src/merger/convert_quant.py \
--model_path output/sft-qwen3-14b/merged_model \
--output_dir output/sft-qwen3-14b/gptq4_model \
--quant_scheme GPTQ \
--bits 4 \
--calib_samples 16 \
--max_seq_len 64 \
--gpu_fraction 0.65 \
--sequential_targets Linear
2026-03-06 20:37:52,296 - INFO - llm-compressor 核心功能可用
2026-03-06 20:37:52,296 - INFO - GPTQModifier 可用
2026-03-06 20:37:52,296 - INFO - AWQModifier 不可用(对T4来说是好事,AWQ更耗显存)
2026-03-06 20:37:52,297 - INFO - llm-compressor 版本: 0.10.0
2026-03-06 20:37:52,297 - INFO - 项目根目录: /home/yaoxp/work/sft/uf8
2026-03-06 20:37:52,297 - INFO - 输入模型: /home/yaoxp/work/sft/uf8/output/sft-qwen3-14b/merged_model
2026-03-06 20:37:52,297 - INFO - 输出目录: /home/yaoxp/work/sft/uf8/output/sft-qwen3-14b/gptq4_model
2026-03-06 20:37:52,297 - INFO - 量化方案: GPTQ 4bit
2026-03-06 20:37:52,297 - INFO - 校准样本: 16
2026-03-06 20:37:52,297 - INFO - 最大序列长度: 64
2026-03-06 20:37:52,297 - INFO - GPU内存比例: 0.65
2026-03-06 20:37:52,297 - INFO - 序列化目标: Linear(关键优化)
2026-03-06 20:37:52,297 - INFO - 校准文件: 自动生成
2026-03-06 20:37:52,297 - INFO - 关键:使用FP16+CPU卸载加载(禁用BNB避免解压爆显存)
2026-03-06 20:37:52,297 - INFO - 自动生成校准数据...
2026-03-06 20:37:52,297 - INFO - 自动生成 16 条医学校准数据
2026-03-06 20:37:52,298 - INFO - 使用自动生成的校准数据
2026-03-06 20:37:52,298 - INFO - 开始 GPTQ 4bit 量化...
2026-03-06 20:37:52,298 - INFO - 输入模型: /home/yaoxp/work/sft/uf8/output/sft-qwen3-14b/merged_model
2026-03-06 20:37:52,298 - INFO - 输出目录: /home/yaoxp/work/sft/uf8/output/sft-qwen3-14b/gptq4_model
2026-03-06 20:37:52,298 - INFO - 分组大小: 128
2026-03-06 20:37:52,298 - INFO - T4关键优化: sequential_targets='Linear'
2026-03-06 20:37:52,298 - INFO - 加载分词器...
2026-03-06 20:37:53,002 - INFO - 使用 FP16 + CPU卸载加载模型(禁用BNB避免解压爆显存)...
2026-03-06 20:37:53,002 - INFO - T4优化:GPU内存比例设置为 0.65,为Hessian计算预留空间
2026-03-06 20:37:53,031 - INFO - GPU总内存: 14.57 GB
2026-03-06 20:37:53,031 - INFO - 分配给模型: 9.47 GB
2026-03-06 20:37:53,031 - INFO - 保留显存缓冲: 35%(用于Hessian计算)
2026-03-06 20:37:53,031 - INFO - 内存分配策略: GPU=9GiB, CPU=100GiB
2026-03-06 20:37:53,031 - INFO - 正在加载模型配置...
2026-03-06 20:37:53,054 - INFO - 正在加载模型权重(此过程可能需要几分钟)...
2026-03-06 20:37:53,376 - INFO - 层分布规划: GPU=13, CPU=37, Disk=0
2026-03-06 20:41:02,783 - WARNING - Some parameters are on the meta device because they were offloaded to the cpu.
2026-03-06 20:41:02,797 - INFO - 实际层分布: GPU=0, CPU=37
2026-03-06 20:41:13,264 - INFO - 加载后显存: 已分配=7.44GB, 预留=7.44GB
2026-03-06 20:41:13,264 - INFO - 模型加载完成
2026-03-06 20:41:13,264 - INFO - 准备 16 条校准数据...
2026-03-06 20:41:13,794 - INFO - 成功创建 Dataset,包含 16 条数据
2026-03-06 20:41:14,085 - INFO - Dataset创建后显存: 7.44 GB
2026-03-06 20:41:14,085 - INFO - 使用 GPTQModifier 创建 W4A16 配置
2026-03-06 20:41:14,085 - INFO - 关键优化:sequential_targets='Linear'(逐层量化避免OOM)
2026-03-06 20:41:14,134 - INFO - 开始量化(T4 约需 30-60 分钟,请耐心等待)...
2026-03-06 20:41:14,134 - INFO - 注意:量化过程中会频繁进行CPU/GPU数据传输,速度较慢但能保证不OOM
2026-03-06 20:41:14,135 - INFO - 关键优化:使用 sequential_targets='Linear' 逐层量化
2026-03-06T20:41:14.435449+0800 | __init__ | WARNING - Disabling tokenizer parallelism due to threading conflict between FastTokenizer and Datasets. Set TOKENIZERS_PARALLELISM=false to suppress this warning.
Tokenizing: 100%|██████████████████████████████████████| 16/16 [00:00<00:00, 34.17 examples/s]
......
(282/282): Calibrating: 100%|██████████████████████████████| 16/16 [00:00<00:00, 40945.01it/s]
(282/282): Propagating: 100%|█████████████████████████████| 16/16 [00:00<00:00, 247634.18it/s]
2026-03-06T20:29:39.600165+0800 | finalize | INFO - Compression lifecycle finalized for 1 modifiers
2026-03-06T20:29:39.600319+0800 | get_model_compressor | INFO - skip_sparsity_compression_stats set to True. Skipping sparsity compression statistic calculations. No sparsity compressor will be applied.
Compressing model: 280it [00:55, 5.01it/s]
/home/yaoxp/anaconda3/envs/vllm/lib/python3.11/site-packages/transformers/modeling_utils.py:3970: UserWarning: Attempting to save a model with offloaded modules. Ensure that unallocated cpu memory exceeds the `shard_size` (5GB default)
warnings.warn(
Saving checkpoint shards: 100%|█████████████████████████████████| 2/2 [00:29<00:00, 14.63s/it]
2026-03-06 20:31:07,316 - INFO - 模型大小对比:
2026-03-06 20:31:07,317 - INFO - 原始模型: 55.04 GB
2026-03-06 20:31:07,317 - INFO - 量化模型: 9.26 GB
2026-03-06 20:31:07,317 - INFO - 压缩比: 5.94x
2026-03-06 20:31:07,317 - INFO - 体积减少: 83.2%
2026-03-06 20:31:07,317 - INFO - GPTQ 量化完成!
2026-03-06 20:31:07,317 - INFO - 使用 vLLM 加载命令:
2026-03-06 20:31:07,317 - INFO - llm = LLM("/home/yaoxp/work/sft/uf8/output/sft-qwen3-14b/gptq4_model", quantization="gptq", dtype="float16")
2026-03-06 20:31:15,725 - INFO - 量化成功完成!
[W306 20:31:32.834038187 AllocatorConfig.cpp:28] Warning: PYTORCH_CUDA_ALLOC_CONF is deprecated, use PYTORCH_ALLOC_CONF instead (function operator())
(vllm) yaoxp@ubt22ai3:~/work/sft/uf8$注意:
只能用这个参数,否则容易超过16g显存
(4)格式转换-awq(注意这里切换vllm环境)
能执行代码,但反复报显存OOM,如果有更好的显卡是可以运行的
1.7、收工
自此从准备微调验证评估对话格式转换,这一系列工程处理完毕,验证在极小尺寸的显卡中也能微调中等尺寸的大模型。
与此同时,基于2次微调数据的校验对比,发现提前准备的微调数据质量不高,反而引起大模型推理能力下降,这里再次确认小批量高质量微调数据的效果要远大于大批量低质量的微调数据的效果。这是因为这批数据之前是没有cot的,是通过LLM反推cot数据,但推理的信息和质量没有达到医学问询标准,导致推理效果下降的原因。
另外
- 关于不同尺寸大模型在微调后效果对比,可以参考《Unsloth-Factory : 微调qwen3-14b大模型》
- 关于如何把gguf转为ollama部署,可以参考《微调框架:Unsloth-factory》