倒数排名融合(Reciprocal Rank Fusion, RRF) 是一种在信息检索系统中广泛使用的算法,主要用于合并多个搜索结果列表。
它的核心优势在于:不需要知道各个列表的具体相关性分数(Score),仅凭文档在每个列表中的排名位置(Rank),就能有效地将它们融合成一个高质量的统一列表。
这使得 RRF 成为混合检索(Hybrid Search,即结合稀疏检索 BM25 和稠密检索 Dense Retrieval)以及 RAG-Fusion(多查询检索)中的标准融合策略。
1. 为什么需要 RRF?(解决的问题)
在混合检索场景中,我们通常有两个或多个来源的搜索结果:
- 列表 A (BM25):基于关键词匹配,分数范围可能是 0.1 到 5.0。
- 列表 B (向量检索):基于语义相似度,分数范围可能是 0.6 到 0.95(余弦相似度)。
直接相加分数的痛点:
- 量纲不同:两个列表的分数分布完全不同,直接相加会导致某一种检索方法主导结果(例如向量分数普遍较高,淹没了 BM25 的结果)。
- 归一化困难:虽然可以做 Min-Max 归一化,但这对异常值敏感,且计算复杂。
- 缺乏可比性:一个列表中的 0.8 分和另一个列表中的 0.8 分代表的置信度可能完全不同。
RRF 的解决方案 :
RRF 完全忽略原始分数,只关注排名 。它假设:如果一个文档在多个列表中都能排在前面,那么它极有可能是真正相关的文档。
2. RRF 的计算公式
对于每一个出现在至少一个结果列表中的文档,其 RRF 得分计算如下:
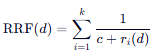
其中:
-
k :结果列表的数量(例如在混合检索中 k=2 ,在 RAG-Fusion 中 k=生成的查询数量)。
-
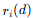 :文档 dd 在第 ii 个列表中的排名位置(第1名则 r=1 ,第2名则 r=2r=2 ,以此类推)。如果文档不在该列表中,则不计入该项。
:文档 dd 在第 ii 个列表中的排名位置(第1名则 r=1 ,第2名则 r=2r=2 ,以此类推)。如果文档不在该列表中,则不计入该项。 -
:一个平滑常数(Ranking Constant),通常设置为 60。
-
作用:防止分母为零(虽然排名从1开始不会为零,但主要是为了调节权重衰减的速度),并控制排名靠后的文档对总分的贡献。
-
经验值 :TREC 等权威检索会议的研究表明, c=60c=60 在大多数情况下能取得最佳效果。
- 如果 c 太小(如 1),排名第 1 和第 2 的差距巨大,导致只有榜首文档有机会胜出。
- 如果 c 太大(如 1000),所有排名的权重差异变小,融合效果趋近于简单的出现次数统计。
- c=60 能在"头部效应"和"长尾贡献"之间取得良好平衡。
3. 计算示例
假设有两个检索系统返回了以下结果(我们要找文档 D2 和 D4 的最终得分):
| 排名 | 列表 1 (BM25) | 列表 2 (向量检索) |
|---|---|---|
| 1 | D1 | D3 |
| 2 | D2 | D1 |
| 3 | D3 | D4 |
| 4 | D5 | D2 |
| 5 | D4 | D6 |
计算过程 ():
-
文档 D1:
- 列表 1 排名: 1
- 列表 2 排名: 2
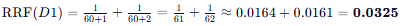
-
文档 D2:
- 列表 1 排名: 2
- 列表 2 排名: 4
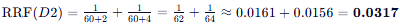
-
文档 D3:
- 列表 1 排名: 3
- 列表 2 排名: 1
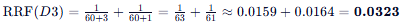
文档 D4:
- 列表 1 排名: 5
- 列表 2 排名: 3
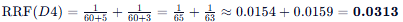
-
文档 D5 (只在列表 1):
- 列表 1 排名: 5
- 列表 2 排名: 未出现
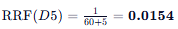
最终排序结果:
- D1 (0.0325) - 在两个列表中都极高
- D3 (0.0323) - 一个第一,一个第三
- D2 (0.0317) - 一个第二,一个第四
- D4 (0.0313) - 一个第五,一个第三
- D5 (0.0154) - 只在一个列表中出现,分数断崖式下跌
结论 :可以看到,D1、D2、D3、D4 因为同时在两个列表中出现,分数非常接近且远高于只在一个列表中出现的 D5。这体现了 RRF 的"共识机制"。
4. RRF 的核心优势
-
无需归一化 (Normalization Free) :
这是最大的优点。无论底层引擎是 BM25、向量模型、还是人工排序,只要给出一个有序列表,RRF 就能工作。不需要关心分数是 0-1 还是 0-1000。
-
鲁棒性强 (Robustness) :
对异常分数不敏感。即使某个检索器给了一个文档极高的错误分数,只要其他检索器把它排得很后,RRF 也能通过排名将其拉下来。
-
简单高效 :
计算复杂度低,仅仅是倒数和加法,非常适合实时检索系统。
-
适用于多路召回 :
无论是 2 路(稀疏+稠密),还是 N 路(RAG-Fusion 中的多个变体查询),公式形式不变,扩展性极好。
5. 应用场景总结
- 混合检索 (Hybrid Search):Elasticsearch (BM25) + Vector DB (Dense) 的结果合并。目前 LangChain, LlamaIndex, Weaviate, Milvus 等主流框架默认都支持 RRF。
- RAG-Fusion:将用户的一个问题扩展为 5-10 个子问题,分别检索后,用 RRF 合并结果,消除单一查询的偏差。
- 元搜索引擎 (Meta-Search Engines):合并 Google, Bing, DuckDuckGo 等多个搜索引擎的结果。
代码实现逻辑 (Python 伪代码)
def reciprocal_rank_fusion(lists_of_docs, k=60):
"""
lists_of_docs: 列表的列表,每个子列表是按顺序排列的文档 ID
k: 平滑常数,默认 60
"""
rrf_scores = {}
# 遍历每一个结果列表
for doc_list in lists_of_docs:
# 遍历列表中的每个文档及其排名
for rank, doc_id in enumerate(doc_list):
current_rank = rank + 1 # 排名从 1 开始
if doc_id not in rrf_scores:
rrf_scores[doc_id] = 0
# 累加倒数排名分数
rrf_scores[doc_id] += 1 / (k + current_rank)
# 按 RRF 分数降序排序
sorted_results = sorted(rrf_scores.items(), key=lambda x: x[1], reverse=True)
return sorted_results总之,RRF 是解决"如何公平地合并不同来源的搜索结果"这一问题的工业界标准答案,它以极简的数学形式实现了强大的共识过滤效果。